- 1机器学习笔记之分类算法(二)朴素贝叶斯_6.对于二分类问题,朴素贝叶斯输出的是什么?
- 2Linux 声音系统_audiolinux
- 3C++ SAPI5设置输出设备(声卡)_linux下使用microsoft sapi5进行输出声音
- 4网络安全 hw 蓝队实战之溯源(仅供参考学习)_hw蓝队
- 5UE使用UnLua(一)
- 6Python+GDAL 将数组写入栅格tiff文件_将数据数组保存为栅格
- 7OpenHarmony 3D显示框架详解
- 8JS学习19(Ajax与Comet)_ajax设置contenttype:'text/event-stream
- 9ChatGPT-5传闻将于2023年底推出,它会实现AGI吗?_chatgpt5
- 10GPT实战系列-Baichuan2本地化部署实战方案_baichuan2 部署
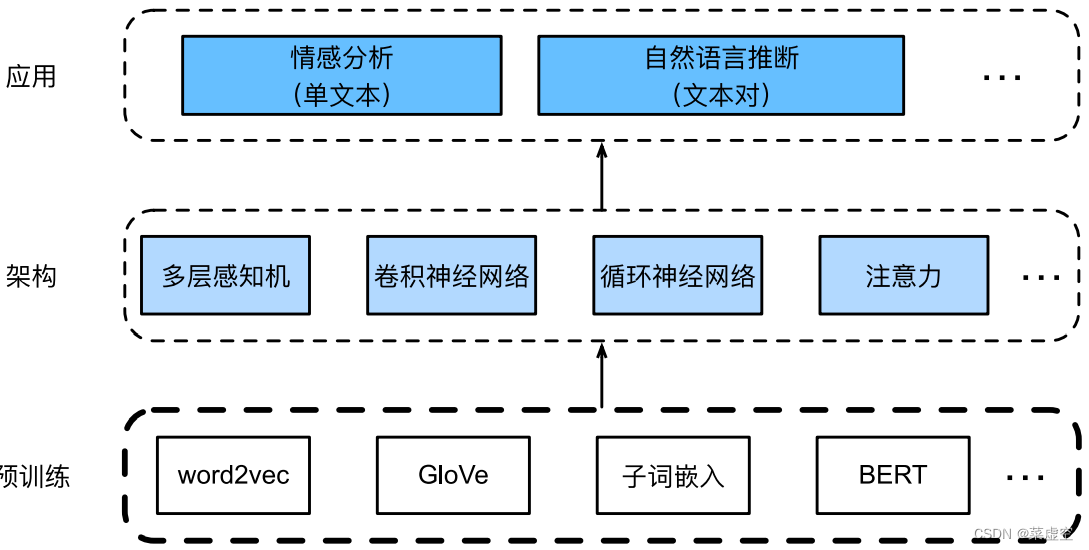
NLP:预训练_nlp预训练任务有哪些
赞
踩
预训练好的⽂本表⽰可以放⼊各种深度学习架构,应⽤于不同⾃然语⾔处理任务(本章主要研究上 游⽂本的预训练)
1.词嵌入
词向量:是⽤于 表⽰单词意义的向量,并且还可以被认为是单词的特征向量或表⽰。
词嵌入:将单词映射到实向量的技术称为词嵌⼊。
1.1独热编码(one-hot)
简介:假设某个词典的大小为N;词典中的词从0—N-1的整数进行表示;现将词典中的每个单词用长度为N的向量进行表示。例如:
“我叫菜虚空”为一个长度为5的词典词典表示为[0,1,2,3,4]
每个字的词向量表示为:
我:[1,0,0,0,0]
叫:[0,1,0,0,0]
...
缺点:独热编码无法表示词向量之间的相似度
1.2自监督的Word2Vec
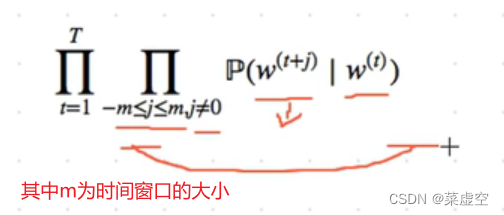
word2vec⼯具包含两个模型,即跳元模型(skip-gram)和连续词袋(CBOW)模型
这两种模型都是依赖于条件概率。
经过训练后的,每个单词都可以表示为一个向量,且不管上下文是什么都不吃不变
1.2.1跳元模型(skip-gram)
利用中心词预测周围词

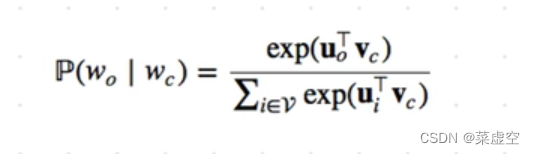
上式中:V为中心词向量;
U为背景词表达式;
c为中心词的索引;
o为背景词的表达式。

1.2.2连续词袋(CBOW)
利用周围的词预测中心词

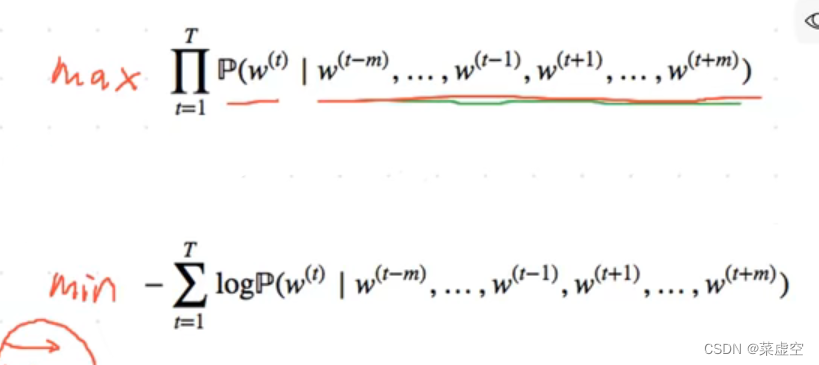
1.3近似训练法
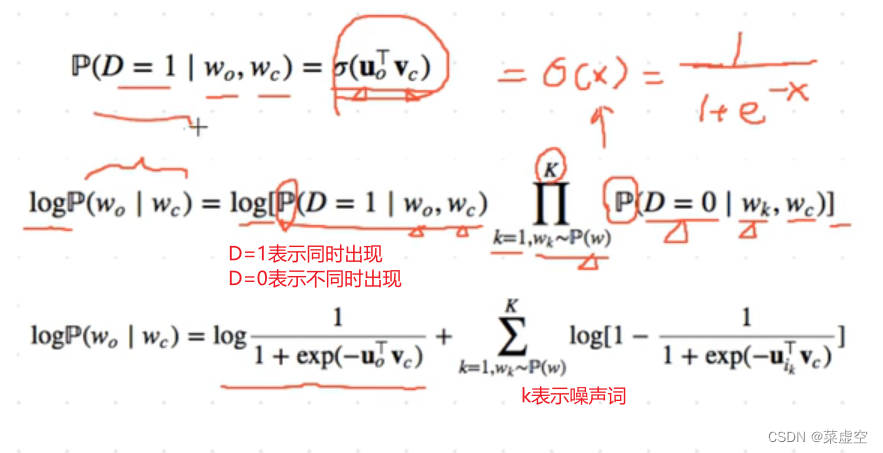
 1.3.1负采样
1.3.1负采样
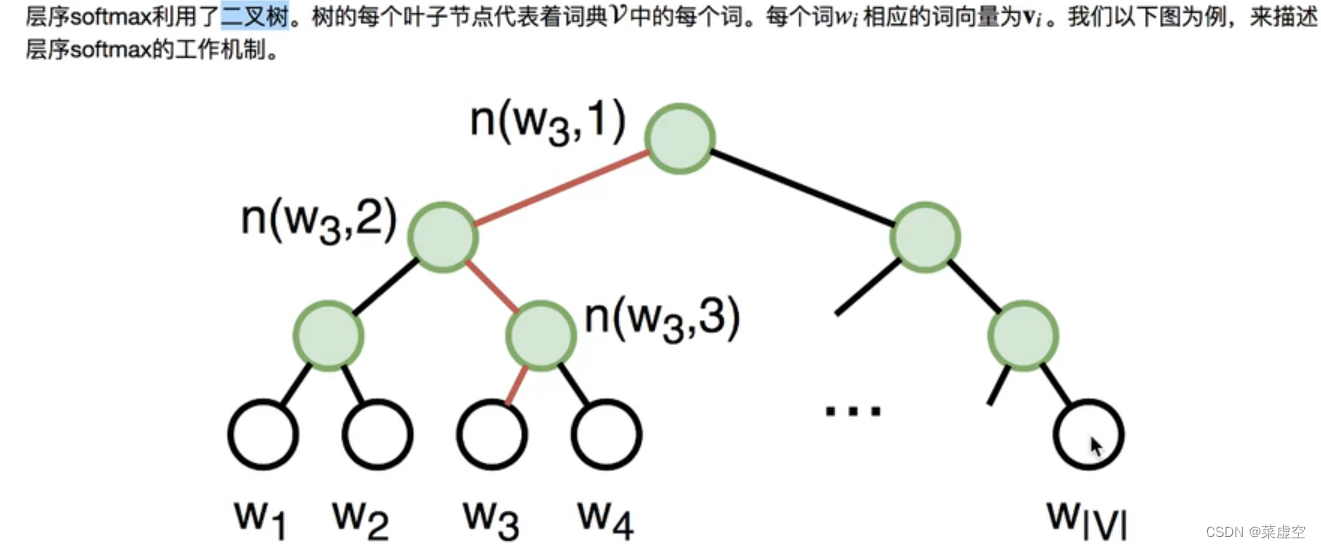
1.3.2层序softmax
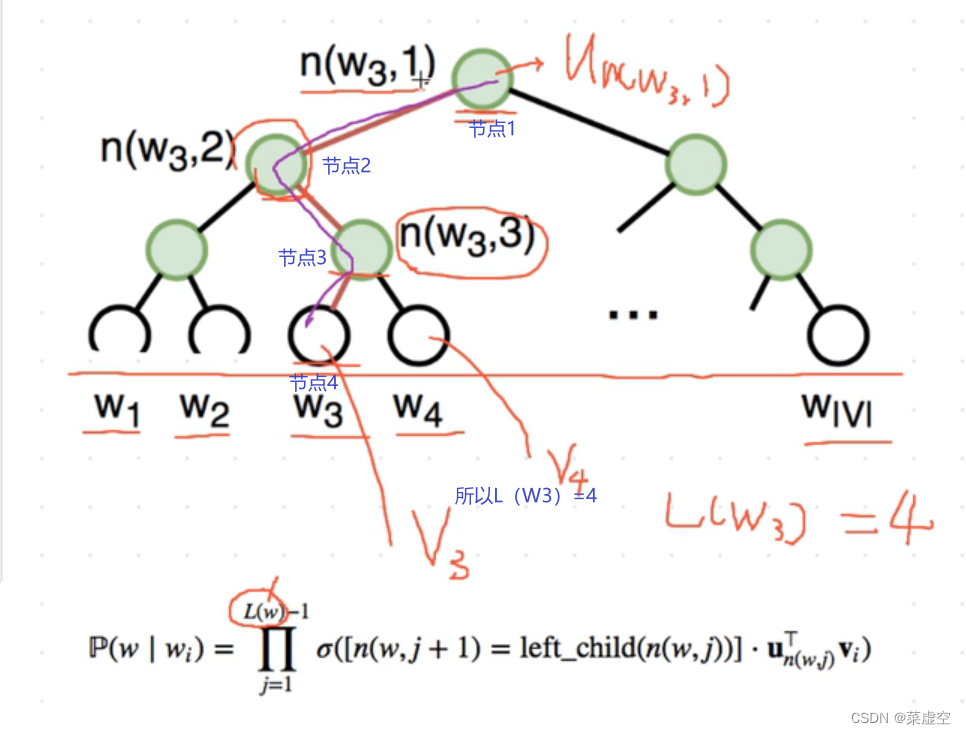
分支往左走结果为1;
分支往右走结果为-1
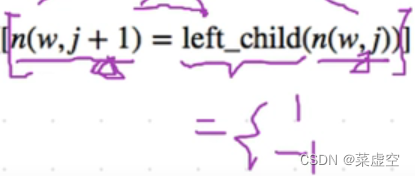

最下面的节点Wi对应一个词
2.B站案例

2.1构建向量

2.2训练过程
Word_size 为词表中唯一不重复的词词个数=500(无法主观选择,需要统计)
embedding_num为表示一个词元的向量长度=50(可以主观选择)
2.2.1跳元模型(skip-gram)
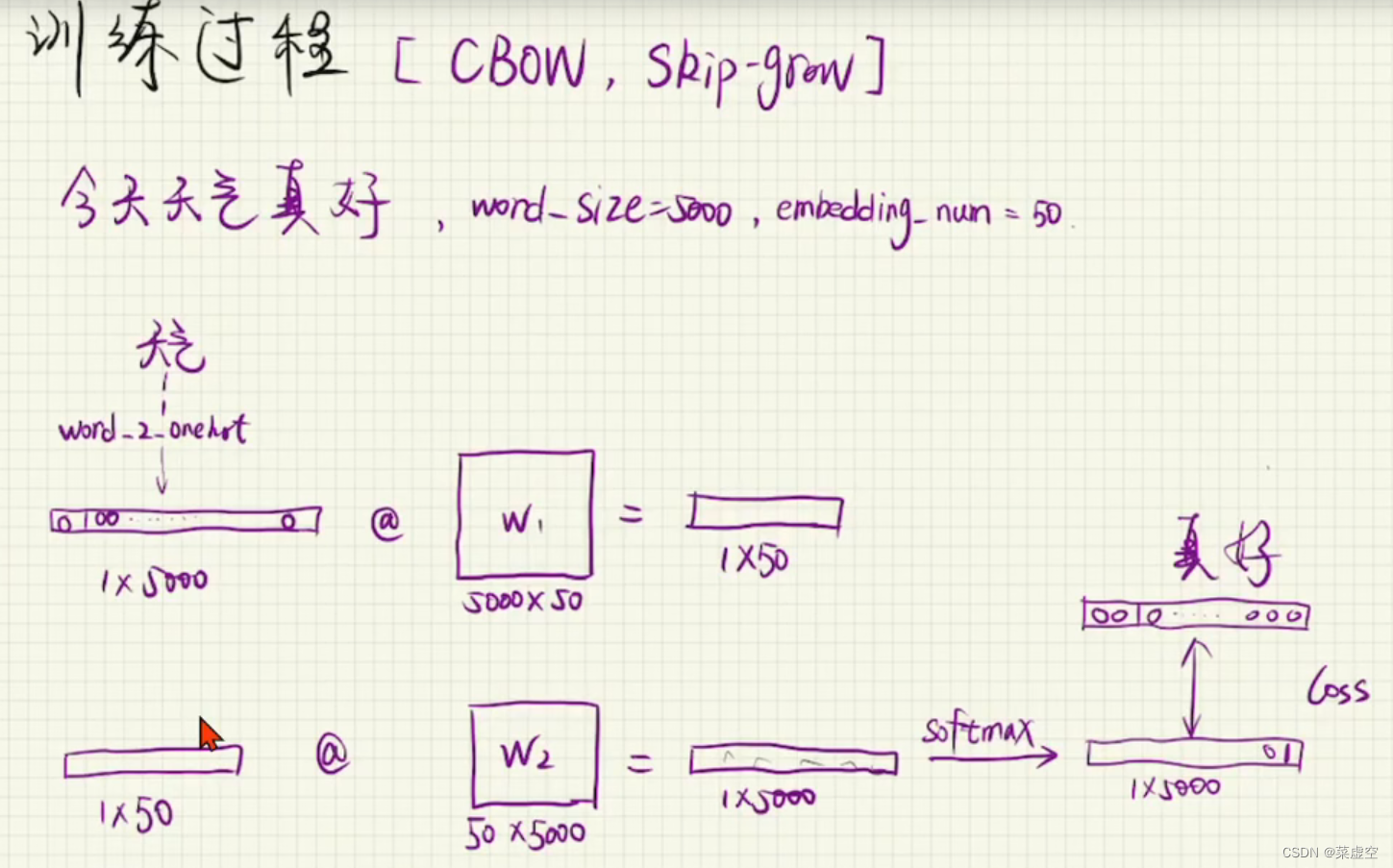
上图中将word-2-onehot这样一个高纬度的稀疏向量乘以一个矩阵之后达到了降维的目的;
最后又要乘以一个矩阵将其还原为原来的维度,最终进行归一化处理;
最终会得到一个与输入维度相同的向量该向量为输入词向量对下一个词向量的预测。
3.用于预训练词嵌入的数据集
3.1读取数据集
①首先将文本按照行进行分割;
②然后将每个句子的中的按此拆分;
sentences = read_ptb()是读取文本并将文本每个句子存为序列,最后将所有句子合并为一个序列
③构建词表,同时将单词频数低于10的单词全部替换为<unk>。
vocab = d2l.Vocab(sentences,min_freq=10)
3.2下采样
简单来说是将出现频率过高的单词删减掉,例如:a、the等没有实际意义的单词
subsampled,countert = subsample(sentences,vocab);
下采样结束后,将词元隐射到他们的语料库中索引。
3.3中心词和上下文词的提取
上下文窗口i:中心词前i个单词和中心词后i个单词;
定义函数:get_centers_and_contexts(corpus,max_windows_size)

4.负采样
我们定义以下RandomGenerator类,其中采样分布通过变量sampling_weights传递。
5.小批量加载训练实例
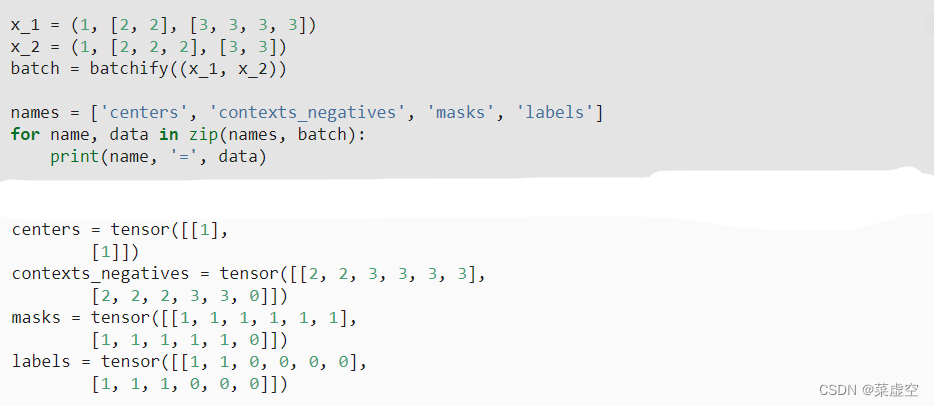
使用batchify函数:
①可以将上下文词及噪声词合并为一个向量:contexts_negatives,由于中心词的位置不,所以产生的上下文词的维度不全一样,为了使得contexts_negatives的维度相同将缺失的位置用0填充;
②产生masks向量来与contexts_negatives向量中元素对应,其中实际的上下文词和噪声词位置为1,填充的位置为0;
③为了区分正反例,我们在contexts_negatives中通过一个labels变量将上下文词与噪声词分开其中labels中的1(否则为0)对应于contexts_negatives中的上下文词的正例。
6.整合代码
读取PTB数据集并返回数据迭代器和词表的load_data_ptb函数:
![]()
其中batch_size 为每个批量的大小;

7.预训练Word2Vec
7.1跳元模型
跳元模型时通过嵌入层和批量矩阵乘法实现的。
7.1.1嵌入层
1.嵌入层将词元的索引映射到其特征向量;
2.该层的权重是一个矩阵,其行数等于字典大小(input_dim),列数等于每个标记的向量维数(output_dim);
3.即每个词元的索引对应矩阵的每一行元素,该行元素的组成的向量就是该词元的特征向量。

其中:num_embedding为字典的大小,embedding_dim为每一个词元特征向量的长度(对!没错 词元特征向量的长度可以自己指定)。
上述的embed输入的参数,对应输出的权重矩阵形状为(20,4);
测试:

7.2训练
7.2.1二元交叉熵损失
7.2.2初始化模型参数

7.2.3定义训练代码
![]()

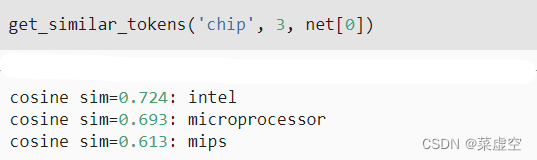
7.3应用词嵌入
在训练word2vec模型之后,我们可以使用训练好模型中词向量的余弦相似度来从词表中找到与输入单词语义最相似的单词。
![]()