
- 1用css+div实现网页的简单布局(一)_利用div+css技术设计出下图网页world trans
- 220191208_神经网络交叉验证_神经网络1000 500 50 2
- 3云原生✖️ AI 时代的微服务架构最佳实践—— CloudWeGo 技术沙龙·北京站报名开启
- 4[数学] 线性微分方程中的“线性性“_微分的线性运算
- 5小程序从入门到入坑:事件系统
- 6前端代码生成
- 7Java基于springboot+vue的药品销售商城系统-含进销存模块_基于springboot+vue药店销售系统
- 8Flutter中的生命周期详解_flutter 界面切换resumed
- 9手机免root安装kali linux 步骤,离线版(最终可行版)_kali linux手机版安装
- 10如何辨别AI文章?四招教你识破_识别ai文章
【论文阅读】ERNIE系列
赞
踩
代码地址:https://github.com/PaddlePaddle/ERNIE/
ERNIE1.0:
总体思路:
在一般的bert模型预训练的过程中,加入了KG(知识图谱信息),这里说的文本中的知识,比如 文本的中的人名、地名、成语、短语等都是知识。
优点:这可以为更好的语言理解提供丰富的结构化知识事实。有利于知识驱动的应用,比如说entity typing和relation classifification
具体细节
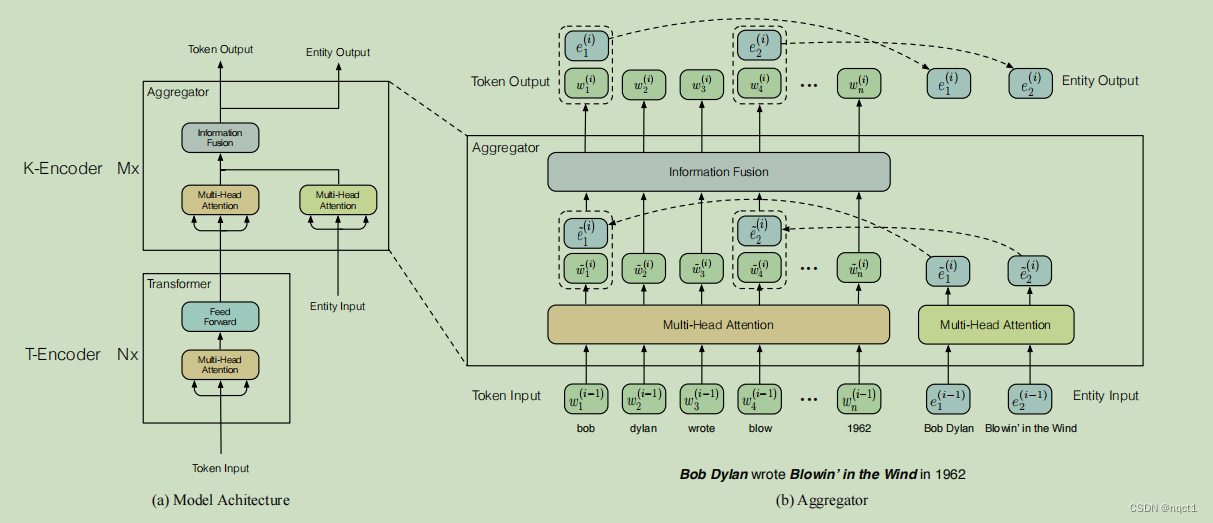
框架分成两个部分:
T-Encoder
(和Bert的encoder架构差不多)
K-Encoder
(主要创新点,将知识信息融入语言的representation中)
两个输入:
(1)T-Encoder的输出的token的 embedding
(2)Entity Input:
初始的时候是由TransE这个model得到的【TransE模型是一种基于深度学习的知识表示方法】
两个输入分别经过Multi-Head attention(这部分就是常见的attention模块)
之后一起进入information fusion
Information fusion网络:就是融合token和Entity的。
(1)有实体输出的token:
 (2)没有实体输出的token
(2)没有实体输出的token
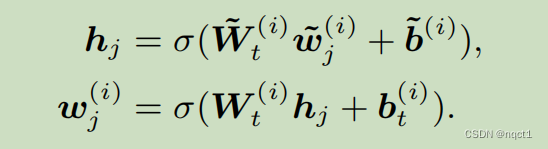
预训练过程:
预训练任务:NSP+MLM+新任务。
新任务:它随机屏蔽一些token-entity对,然后要求系统根据对齐的token预测所有相应的entity。
类似于 降噪自编码器的训练过程,所以loss函数是dEA(denoising entity auto-encoder)
另外,由于实体库比较大,所以这里只要求系统根据给定的实体序列来预测实体,而不是根据KG中的所有实体。然后根据预测结果计算其cross-entropy loss
ERNIE2.0:面向NLU
论文地址:https://arxiv.org/abs/1907.12412
ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
技术核心:
多任务学习和持续训练。就是一个模型可以不忘记之前学习到的知识持续学习,从而处理多任务。
持续训练:ERNIE 2.0 框架能通过多任务学习持续更新预训练模型,这也就是「持续预训练」的含义。在每一次微调中,ERNIE 会首先初始化已经预训练的权重,然后再使用具体任务的数据微调模型。这里的持续训练过程分为2个步骤,即构建无监督预训练任务和通过多任务学习增量地更新 ERNIE 模型。这里不同的任务是一个序列,因此模型在学习新任务时能记住已经学到过的知识。
具体细节:
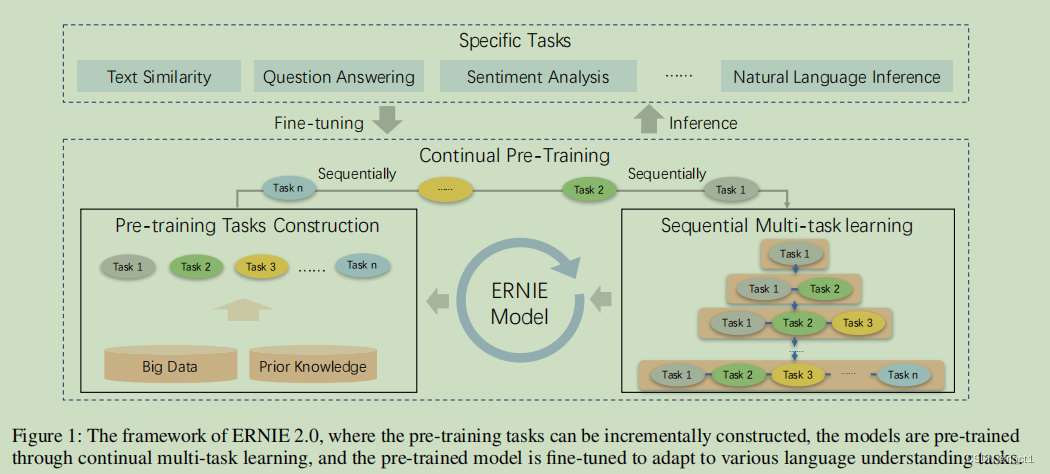
Continual Learning两个模块:
Pre-training Tasks Construction:构建各种要训练的任务。
Continual Multi-task Learning:多任务学习的方式,就是多个任务持续学习,训练新的任务的时候,上一个任务也拿来一起训练。
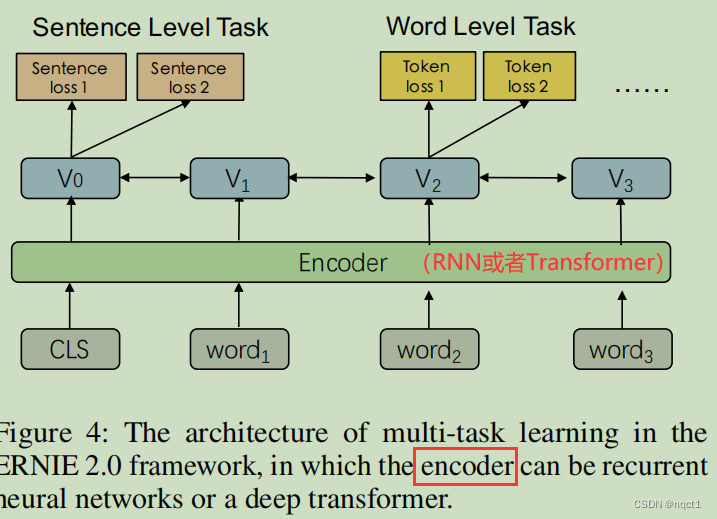
Continual Multi-task Learning
input部分改变:加上task embedding(就是说有0~N个任务,属于第i个任务,那么这句话的task embedding就是[i,i,i,i,…])
多任务训练的model:
理论上Encoder部分可以是RNN或者Transformer等,这里Encoder采用Transformer。
Pre-training Tasks Construction
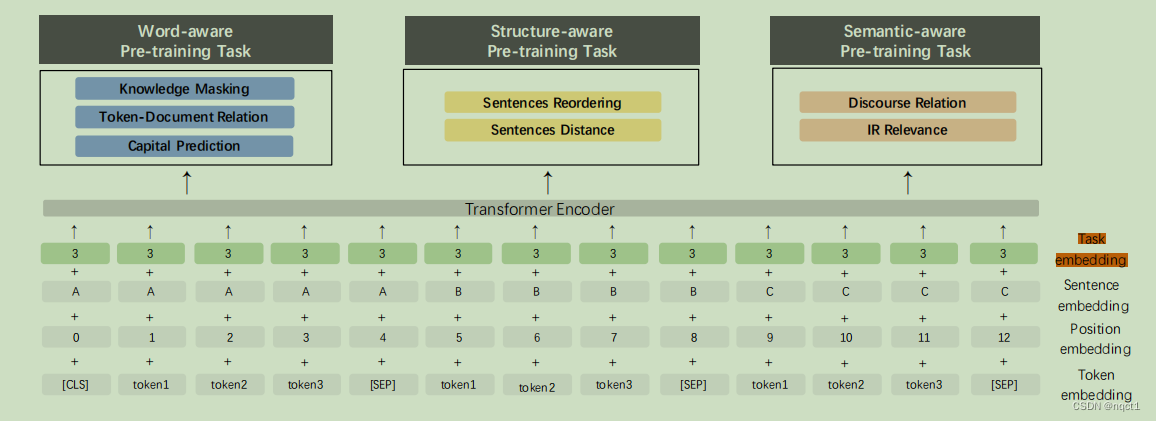
多任务:ERNIE2.0主要包含以下三类预训练任务
选定一些任务做预训练(7个):
● Word-aware Pre-training Task: 词汇 (lexical) 级别信息的学习
○ Knowledge Masking Task:参照ERNIE1中的Mask,将token-entity对Mask
○ Capitalization Prediction Task ??
○ Token-Document Relation Prediction Task:此任务将预测段中的标记是否会出现在原始文档的其他段中。
● Structure-aware Pre-training Task: 语法 (syntactic) 级别信息的学习
○ Sentence Reordering Task
○ Sentence Distance Task
● Semantic-aware Pre-training Task: 语义 (semantic) 级别信息的学习
○ Discourse Relation Task
○ IR Relevance Task:我们建立了一个预训练任务来学习信息检索中的短文本相关性。
ERNIE3.0:面向NLU和NLG
大致思路:
融合了自回归网络和自编码网络,使训练后的模型可以很容易地定制地用zero-shot learning, few-shot learning or fifine-tuning来做NLU和NLG任务。依旧是融入知识,用Knowledge Enhanced Models
具体细节:
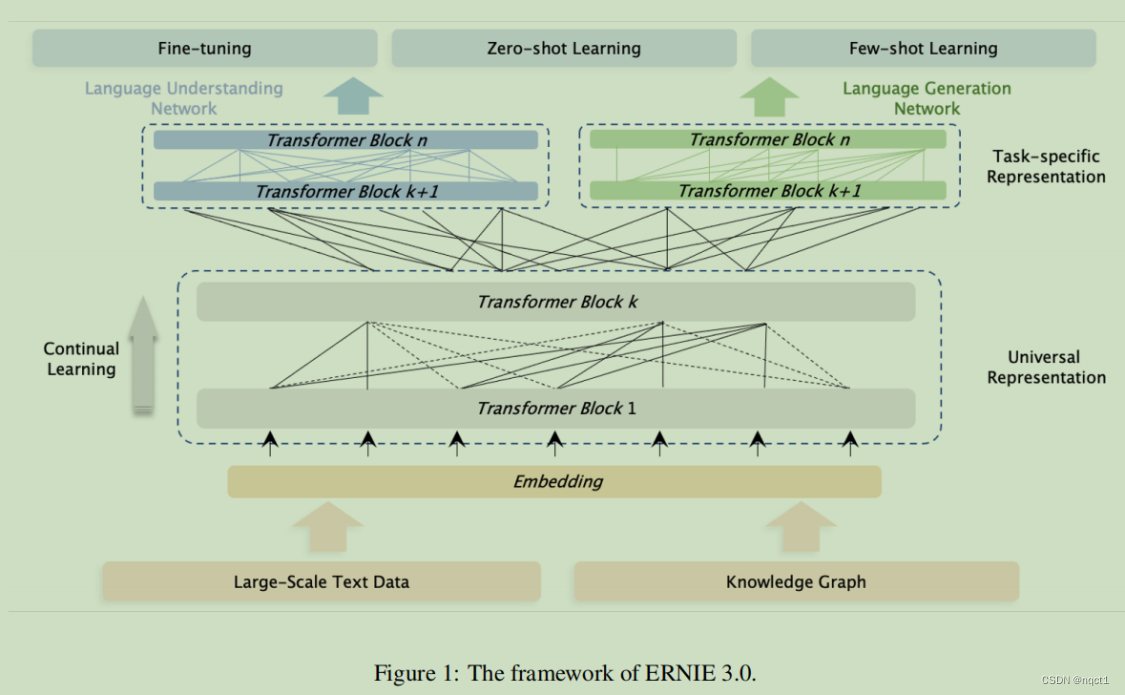
模型架构受经典的多任务学习模型架构的启发,其中较低的层在所有任务中共享,而顶层是特定于任务。
框架分成两大部分
backbone shared network
Universal Representation Module (语义特征提取器)
组成:a multi-layer Transformer-XL【Transformer XL与Transformer类似,但引入了一个辅助递归存储模块,以帮助对较长的文本进行建模】
task-specifific networks
Task-specifific Representation Modules(提取任务特定语义特征)
组成:a multi-layer Transformer-XL(和backbone一样)
ERNIE 3.0将特定于任务的表示模块设置为一个可管理的大小,即一个基本模型大小,而不是在多任务学习中常用的多层感知器或浅层变压器。优点:
■ 首先,基础网络比多层感知器和浅层转换器具有更强的语义信息转换能力
■ 第二,具有基本模型大小的任务特定网络使ERNIE 3.0能够区分不同任务范式之间的顶级语义信息,而不显著增加大规模模型的参数;
■ 最后,当只对特定任务的表示模块进行微调时,特定任务网络的模型规模比共享网络要小会使得大规模预训练模型可实现实际应用
最后,ERNIE 3.0构建了两个特定于任务的表示模块,即NLU特定表示模块和NLG特定表示模块,其中前者是双向建模网络,后者是单向建模网络。最后用few-shot learning、zero-shot learning或者finetuning做具体任务。
依旧指定预训练任务Pre-training Tasks:
● Word-aware Pre-training Task: 词汇 (lexical) 级别信息的学习
○ Knowledge Masked Language Modeling
○ Document Language Modeling:可以建模比传统递归变换器更大的有效上下文长度ERNIE-Doc
● Structure-aware Pre-training Task: 语法 (syntactic) 级别信息的学习(和2没变化)
○ Sentence Reordering
○ Sentence Distance :NSP)任务的扩展
● Knowledge-aware Pre-training Tasks
○ Universal Knowledge-Text Prediction

