
- 1基于Python+Django+Vue+MYSQL的个人博客网站系统_diango4+vue3开发个人博客
- 2CAS 原理和缺陷_介绍下 cas,存在什么问题
- 3PT100高精度测温电路 AD623+REF3030(很稳定)_温度探头pt100接上3.3v
- 4centos内网ntp时间同步,centos输出重定向,linux定时任务
- 5轻快好用的Docker版云桌面(不到300M、运行快、省流量).md_docker 云桌面
- 6谁说女生不可以学编程?维密超模放弃年薪千万,一心只当程序媛_超模 编程
- 7Linux系统ubuntu中创建anaconda虚拟环境,安装pytorch_ubuntu pytorch
- 8coursera 吴恩达机器学习 machine learning 作业/习题 归纳 + 脚本测试 (ex12345678)_吴恩达machine learning作业
- 9FPGA设计基础04——modelsim仿真_modelsim后仿真
- 10需求分析——验收测试的步骤_需求验收
ACL2021(之)命名实体识别
赞
踩
文章目录
1. A Unified Generative Framework for Various NER Subtasks
第一篇来看看复旦大学邱锡鹏老师团队做的能够解决多种NER任务的统一框架。

熟悉NER的小伙伴都知道,Flat NER可以转化为序列标注的任务,但是一些特殊的NER,比如嵌套(nested) NER,不连续(discontinuous) NER都无法简单地转化为序列标注任务。用不连续NER举个例子:
“have much muscle pain and fatigue.”中,“muscle pain”和“muscle fatigue”为两个不同的命名实体,muscle是两个不同实体的start,因此无法使用简单的序列标注。
所以,本文提出一个生成式的NER统一框架,旨在同时解决不同的类型的NER子任务。针对于不同的子任务,重点是如何为其标签进行统一建模处理。本文通过Seq2Seq模型(本文采用预训练的BART),将实体线性化为实体指针索引序列,一举解决了三种子任务不兼容的问题。具体来说,给定一个输入token序列 X = [ x 1 , . . . x n ] X=[x_1,...x_n] X=[x1,...xn],目标序列为 Y = [ s 11 , e 11 . . . s 1 j , e 1 j , t 1 . . . , s i 1 , e i 1 . . . s i j , e i j , t 1 ] Y=[s_{11},e_{11}...s_{1j} , e_{1j},t_1...,s_{i1},e_{i1}...s_{ij} , e_{ij},t_1] Y=[s11,e11...s1j,e1j,t1...,si1,ei1...sij,eij,t1]。这里的 s , e s,e s,e分别表示一个实体的开始以及结束token, t i t_i ti表示实体的tag类型index。因为一个句子中同一个tag下可能有许多不同的实体,因此表述起来就是 s 11 , e 11 . . . s 1 j , e 1 j s_{11},e_{11}...s_{1j} , e_{1j} s11,e11...s1j,e1j对应一个 t 1 t_1 t1。使用 G = [ g 1 , . . . g l ] G=[g_1,...g_l] G=[g1,...gl]来表示 l l l个不同的tag组成的token,假如有两组不同的实体类型:Person以及Organization,那么这里的 G G G就是[Person,Organization]。然后,可以把原句子和tag组成的token拼接在一起,这样就就能使用索引共同表示了,并且需要强调的是, t i ∈ ( n , n + l ] t_i\in (n,n+l] ti∈(n,n+l]。
Method
接下来就可以借助Seq2Seq进行学习了。生成目标tag的过程可以视为一个求解概率分布的过程:

y
0
y_0
y0为表示decoder开始的特殊字符。为了求解这个概率,首先需要对token进行encoder:

注意这里的token不是与tag拼接的token,而是原token,所以
H
e
∈
R
n
×
d
H^e\in R^{n×d}
He∈Rn×d。之后,在decoder的时候,需要整合目标序列
Y
Y
Y。但是实际上
Y
Y
Y是一个index组成的序列,因此无法使用预训练的模型BART进行计算,所以需要将index转化为token:

这样,借助转化之后的token以及encoder的输出,就可以计算decoder的最后一个隐藏状态了:

在encoder和decoder的输出都已知的情况下,本文采用了如下方式计算index的概率分布
P
t
P_t
Pt:

这里的TokenEmbed参数是对
X
X
X与
G
G
G共享的。在训练的过程中,使用negative
log-likelihood loss以及teacher forcing method(不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案的对应上一项作为下一个state的输入。),在预测的时候采用自回归的方式生成目标序列。
2. A Span-Based Model for Joint Overlapped and Discontinuous Named Entity Recognition

尽管都作用于重叠实体以及不联系实体的联合抽取,但与第一篇不一样,本文使用的是穷举text span的思路,而非生成式模型。之后,对每一个穷举的text span进行二分类,判断是否是一个实体。然后,通过预定义实体之间的关系进一步判断实体之间是Overlapping还是Succession。总体来说,模型依旧是两段式:encoder和decoder,并在encoder的过程中引入了句法图结构,并借助GCN进行增强。之后,联合实体之间的关系识别任务,构建了一个多任务的decoder框架。如图所示,模型一共分为四个模块:(1)单词表示,(2)图卷积网络,(3)span表示,(4)联合解码。
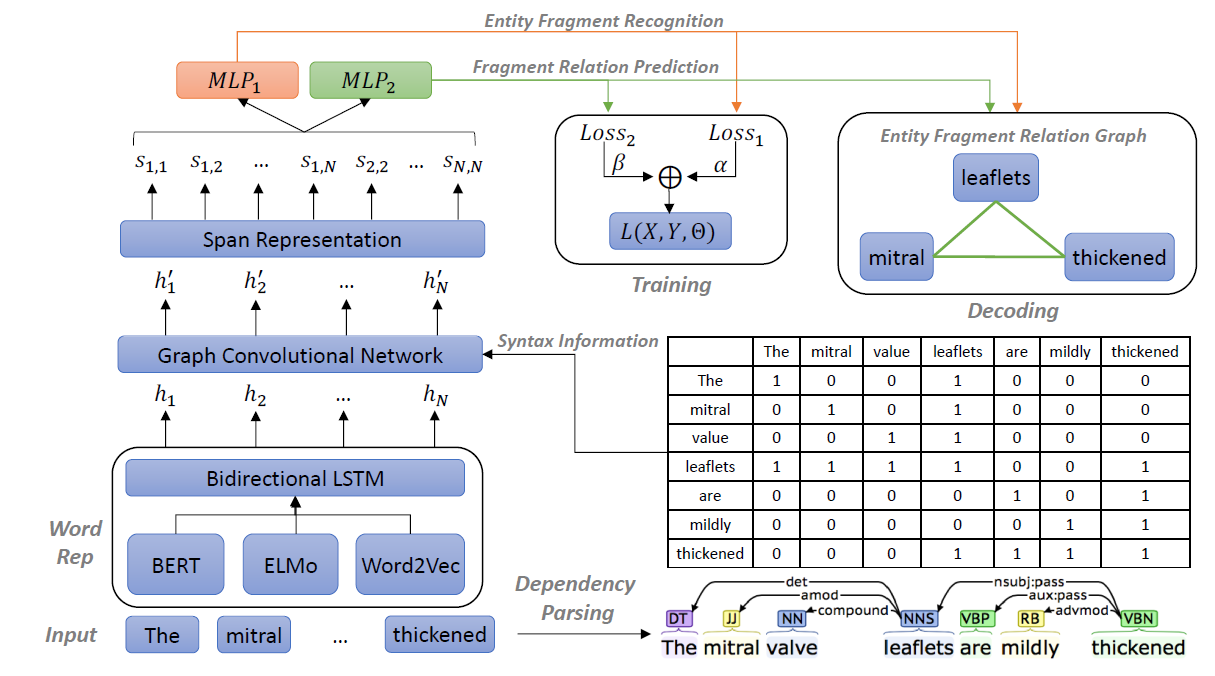
Method
Word Representation
首先,借助Bert对单词进行表示。而Bert在tokenizer的时候,会将一个单词分成词素,目的是降低英文单词中时态的多样性,比如,单词 f e v e r s fevers fevers会分为 f e v e r fever fever以及 # # s \#\#s ##s。在这样的情况下,就使用开头的单词块作为最终的单词表示。这样,就会得到一个矩阵 H = { h 1 , . . . h n } ∈ R N × d h H=\{h_1,...h_n\}\in R^{N×d_h} H={h1,...hn}∈RN×dh。
Graph Convolutional Network
在之后,使用图卷积,引入Dependency syntax。这里使用了AGGCN:

这里将
H
t
∈
R
N
×
d
h
e
a
d
H^t\in R^{N×d_{head}}
Ht∈RN×dhead映射到一个query和一个key,并计算注意力系数作为图卷积的卷积核。因为是多头,所以在这一步要根据不同的
A
~
t
\tilde{A}^t
A~t执行多次卷积,然后再经过一个全连接得到
H
~
t
∈
R
N
×
d
n
\tilde{H}^t\in R^{N×d_{n}}
H~t∈RN×dn。多头再进行拼接就会得到一个整合之后的特征:

这里
W
1
∈
R
(
N
h
e
a
d
×
d
h
)
×
d
h
W_1\in R^{(N_{head}×d_h)×d_h}
W1∈R(Nhead×dh)×dh,将拼接之后的特征重新映射回
d
h
d_h
dh维,然后将
H
H
H与之拼接,得到最终的特征表示。
Span Representation
举个例子来说明span的形式。对于“The mitral valve leaflets are mildly thickened”,span如下:
“The”, “The mitral”, “The mitral valve”, …,“mildly”, “mildly thickened” “thickened”.
对于超过两个的span,采用头单词和尾单词的拼接作为表示,span的特征用
s
i
j
s_{ij}
sij表示:

这里
w
w
w是一个固定的20维度的维度。
Decoding
现在有了所有的span的维度了,首先识别出所有有效的实体片段,然后对这些片段进行两两分类,以揭示它们之间的关系。这部分就很简单啦,使用一个MLP然后进行分类:

p
1
p_1
p1是当前span属于不同实体的概率。同样,用MLP识别两个实体span之间的关系:

尽管可以在第一步识别出重叠的实体,但这里我们使用overlapped作为一个辅助策略来进一步增强模型。decode的算法描述如下:

小感悟
实际上个人觉得穷举span可能时间复杂度也没有那么高,因为对于实体识别来说,不连续的实体不太可能出现在两个不同的句子中,因此在做span穷举的时候,只需要关注一个子句就可以了,子句越短效率越高。而对于Seq2Seq模型,自回归的方式慢得一。当然,哪种方法更好,大家见仁见智吧。
3. Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter

既然有关NER,怎么能少得了词汇增强呢!首先要说明,Lexicon是一个中文NER的分支,可以通过引入一些词库(Lexicon)来提升NER的效果,毕竟中文是不带有空格的。本文最大的创新点就是将Lexicon与Bert集成到一起,提出LEBERT并在命名实体识别、分词和词性标注三个任务上提升了实验结果。这里没有过多的背景需要介绍,直接看提出的模型。
Method

模型有三个主要部分组成:Char-words Pair Sequence;Lexicon Adapter;Lexicon Enhanced BERT。
Char-Words Pair Sequence
首先需要强调一下,在中文里,每一个字,是character;而使用分词方法得到的词,才是word,而英文是每一个单词叫一个word。为了充分利用Lexicon信息,我们将字符序列扩展为字符-词对序列。给定一个Lexicon,用
D
D
D表示,一个句子用
s
c
=
{
c
1
,
.
.
.
c
n
}
s_c=\{c_1,...c_n\}
sc={c1,...cn}表示。通过匹配字符
c
i
c_i
ci,找到在
D
D
D中包含
c
i
c_i
ci的所有词,然后组成
s
c
w
=
{
(
c
1
,
w
s
1
)
,
.
.
.
(
c
n
,
w
s
n
)
}
s_{cw}=\{(c_1,ws_1),...(c_n,ws_n)\}
scw={(c1,ws1),...(cn,wsn)}。如图所示:

Lexicon Adapter
这个的目的是将Lexicon与Bert相结合。对于
s
c
s_c
sc的第
i
i
i个输入,使用两个向量表示:
(
h
i
c
,
x
i
w
s
)
(h_i^c, x_i^{ws})
(hic,xiws)。前者是
c
i
c_i
ci对应的字符向量,在论文里是Bert的某一层的输出,后者是字符对应的所有增强词汇的一组词嵌入,也就是
x
i
w
s
=
{
x
i
1
w
,
.
.
.
,
x
i
m
w
}
x_i^{ws}=\{x_{i1}^{w},...,x_{im}^{w}\}
xiws={xi1w,...,ximw}。其中
x
i
j
w
x_{ij}^{w}
xijw通过一个预训练的单词嵌入lookup table
e
w
e^w
ew表示:

为了对齐这两种不同的表示,对单词向量应用非线性变换:

如此一来,每一个增强的单词都会有一个特有的表示,一个字符对应的所有增强单词表示构成一个集合
V
i
=
{
v
i
1
w
,
.
.
.
,
v
i
m
w
}
V_i=\{v_{i1}^{w},...,v_{im}^{w}\}
Vi={vi1w,...,vimw}。在这里,考虑到不同的单词表示对字符的增强程度不同,因此使用一个注意力机制去计算加权和:


最终,增强之后的字符的表示为原字符与增强单词的和:

总体的流程如图所示:

Lexicon Enhanced BERT
Lexicon增强的Bert由Lexicon Adapter(LA)与Bert组成。首先,对于第一层(
l
=
0
l=0
l=0)Bert来说,需要对
s
c
s_c
sc做embedding,然后输入到Transformer中:

这里
s
c
s_c
sc embedding的输出就是
H
0
H^0
H0。MHAttn是多头注意力,FFN是2层的前馈网络,LN是layer normalization。在第
k
k
k层,输出
H
k
H^k
Hk并与增强词汇的表示做LA:

最终,经过
L
−
k
L-k
L−k次encoder得到了输出
H
L
H^L
HL。之后就都是Bert的套路了,做一个维度变换使之适配最终的分类:

然后是相应的损失函数:



