
- 1Untracked Files Prevent Checkout (AndroidStudio切换分支报错)_android studio move or commit them before checkout
- 2十大优秀编程项目,让你的简历金光闪闪_积极向上的编程创意
- 3【python】flask模板渲染引擎Jinja2,通过后端数据渲染前端页面_你的 html 文件正在被 flask 的 jinja2 模板引擎正确渲染
- 4【文末送书】如何在时间循环里最优决策?
- 5ubuntu 20 安装 velodyne_simulator_uuvsimulator noetic
- 6免费-华为od-C卷-javascript-动态规划-贪心歌手.js
- 7写一个Python程序计算身体质量指数BMI_p106 实例代码5.2, 计算bmi
- 8深入理解深度学习——Transformer:解码器(Decoder)的多头注意力层(Multi-headAttention)_transformer解码器
- 9DeepLearning.AI笔记:二、神经网络编程基础_dify.ai
- 102021高通人工智能应用创新大赛--创新赛道-决赛阶段小结_sam 与 sgd 对比
目标检测:YOLOX 解读
赞
踩
摘要
YOLOX把YOLO 系列的检测头换成了anchor free的方式,并且采取了一些优化策略:样本分配策略:simOTA,decoupled head(解耦头)的思想。
1.介绍
YOLO家族一直以来都是把最流行的技术加入,并进行优化,追求精度和速度的最佳平衡(比如YOLOv2中引入的Anchor,YOLOV3中引入的残差块,YOLOv4中的Mosich数据增强)最近出的YOLOv5,性能达到了最高,但是近两年大热的Anchor free、先进的标签分配策略、端到端检测(NMS-free)没有被考虑进去,因此YOLOX诞生了。
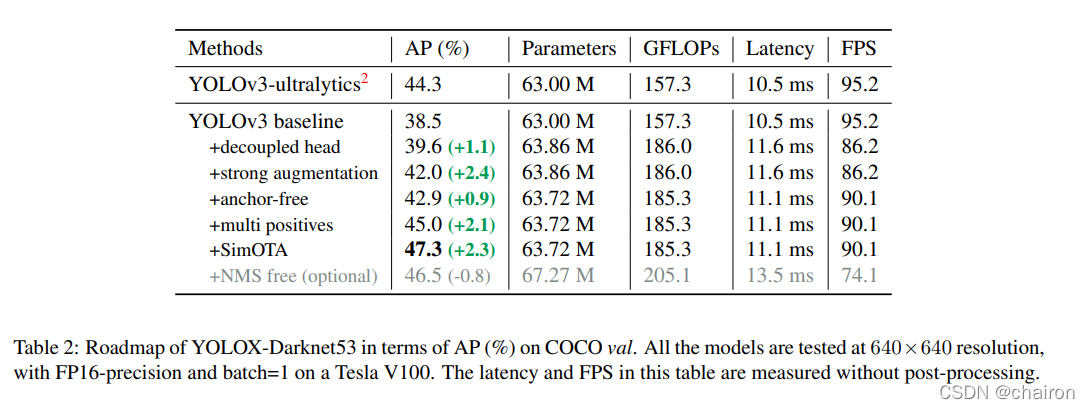
由于考虑到YOLOv4、v5基于Anchor base可能有限过度优化,因此YOLOX基于YOLOv3-SPP版本进行改进。加入上述策略之后,我们boost the YOLOv3 to 47.3%;再加入YOLOV5里面的CSP结构和PAN结构,YOLOX-L achieves 50.0%。
2. YOLOX
2.1 YOLOX-DarkNet53
采用Darknet53作为BackBonend an SPP layer,具体训练设置如下:
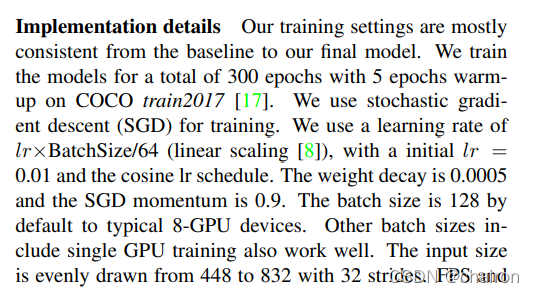
在YOLOV3的backbone上基础上进行了如下训练策略改进:
- 添加了EMA权重更新
- 余弦学习率衰减策略
- ,IoU损失和IoU感知分支。 我们使用 BCE Loss 来训练 cls 和 obj 分支,使用 IoU Loss 来训练 reg 分支。这些一般的训练技巧与YOLOX的关键改进是正交的,因此我们把它们放在基线上。
- 只进行RandomHorizontalFlip,ColorJitter(颜色抖动)和多尺度的数据增强。
并放弃了RandomResizeCrop策略,因为我们发现RandomResizeCrop与采用的的Mosich增强有点重叠。
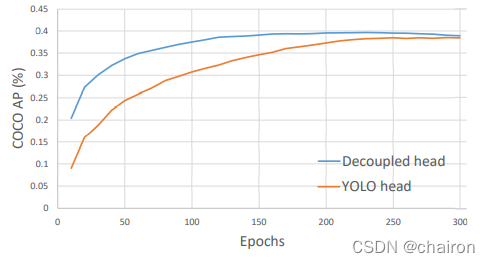
通过这些增强功能,我们的基线在COCO val上实现了38.5%的AP,如下图所示
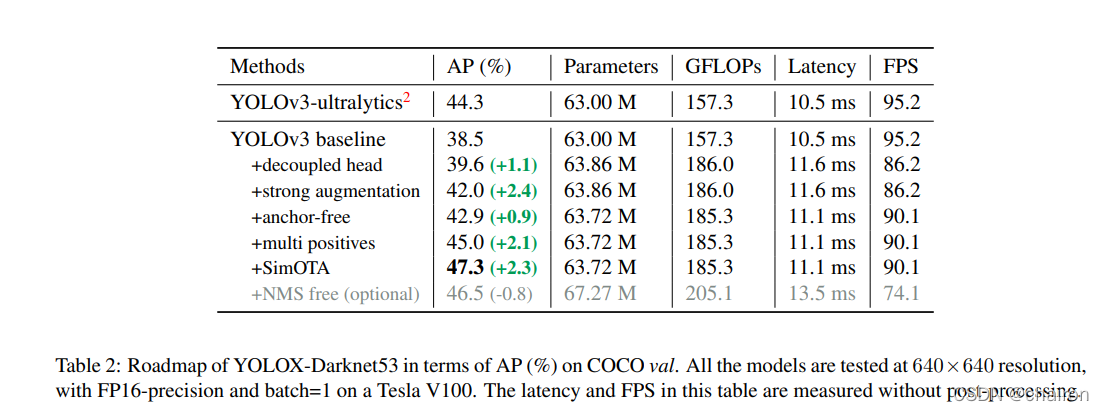
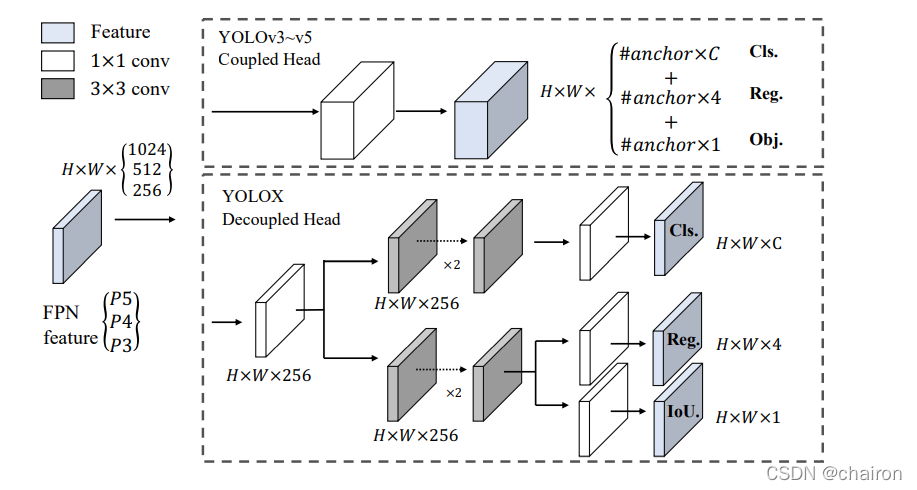
2.2 Decoupled head
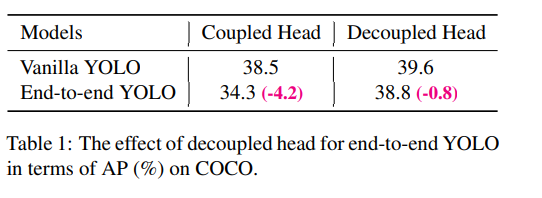
我们的两个分析实验表明,耦合检测头可能会损害性能。
1)用解耦的头代替YOLO的头可以大大提高收敛速度。
2)解耦头对于YOLO的端到端版本至关重要(将在下面描述)。从下图可以看出,对于耦合磁头,端到端属性降低了 4.2% 的 AP,而对于解耦磁头,端到端属性的 AP 降低到 0.8%。因此,我们将YOLO检测头替换为精简版解耦头。
具体而言,它包含一个1×1个Conv层来减小每个FPN对应的输出通道尺寸到256,然后是两个平行分支,分别具有两个3×3个Conv层。
2.3 Strong data augmentation
增加Mosaic and MixUp数据增强,并且在最后15epoch关闭。
实验发现数据增强后,预训练没有意义,因此,实验都是从头开始训练以下所有模型。
2.4 Anchor-free
YOLv4和YOLOv5都是基于Anchor base的,基于Anchor的机制有许多缺点:
- 首先,为了实现最佳检测性能,需要在训练之前进行聚类分析以确定一组最佳锚点。
- 其次,锚定机制增加了检测头的复杂性,以及每个图像的预测数量
Anchor free 机制大大减少了需要手动设计参数的数量和涉及的许多技巧(例如,锚点聚类[24],网格敏感[11]),以获得良好的性能,使检波器,特别是其训练和解码阶段,相当简单[29]。
1. 对每个位置只进行1次预测,生成一个预测框(YOLO系列是3次),预测四个信息(左上角和右下角信息,预测框的高、宽)
2. 我们将每个物体的中心位置指定为正样本并预先定义一个范围,对于每个对象设计一个FPN尺寸。这种修改减少了检测头的参数和GFLOP,并使其更快,同时获得更好的性能 – 42.9% AP。
- 1
- 2
2.5 Multi positives
- 对每个目标选择多个正样本,如FCOS一样,设置3*3大小的区域为正样本区域,命名为“center sampling” 。
- 多个正样本能减缓训练时正负样本之间的不平衡现象。
2.6 SimOTA
优秀的标签分配是近年来目标检测的另一个重要进步。基于我们自己的研究OTA [4],我们总结了先进的标签分配的四个关键点:
1).损失/质量感知,
2)中心先验,
3)每个ground-truth的positive anchor的动态数量(缩写为动态top-k),
4)全局视图。
OTA符合上述所有四条规则,因此我们选择它作为候选标签分配策略。
- 1
- 2
- 3
- 4
- 5
- 6
具体而言,OTA 从全局角度分析标签分配,并将分配过程表述为最佳传输(OT)问题,从而在当前分配策略中产生SOTA性能。
然而,在实践中,我们发现通过Sinkhorn-Knopp算法解决OT问题会带来25%的额外训练时间,这对于训练300个epoch来说是相当昂贵的。因此,我们将其简化为名为SimOTA的动态top-k策略,以获得近似的解决方案。
SimOTA首先计算成对匹配度,用每个predict-gt对的成本或质量表示。例如,在 SimOTA 中,gt g i 和 prediction pj 之间的成本计算公式为:
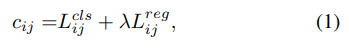
其中 λ 是平衡系数。
L
i
j
c
l
s
L^{cls}_{ij}
Lijcls 和
L
i
j
r
e
g
L^{reg}_{ij}
Lijreg 是 gt
g
i
g^i
gi 和 prediction
p
j
p^j
pj 之间的分类损失和回归损失。
然后,对于
g
t
g
i
g^t g^i
gtgi ,我们选择固定中心区域内成本最低的前 k 个预测作为其正样本。最后,这些正预测的相应网格被指定为正数,而其余网格为负数。注意值 k 因不同的ground truth而异。有关更多详细信息,请参阅 OTA 中的动态 k 估计策略。
SimOTA不仅减少了训练时间,还避免了SinkhornKnopp算法中额外的求解器超参数。
2.7 End-to-end YOLO
我们按照 [39] 添加两个额外的 conv 层、一对一标签分配和停止渐变。 这使得检测器能够以端到端的方式执行,但性能和推理速度会略有下降,如表 2 中所列。因此,end-to-end的设计没有加入YOLOX的最终模型。
3. Other Backbones
将YOLOX的Backbone替换成其他不同size的Backbone,均在原始数据的基础上带来了的提升。(论文中无数据)
3.1 Modified CSPNet in YOLOv5
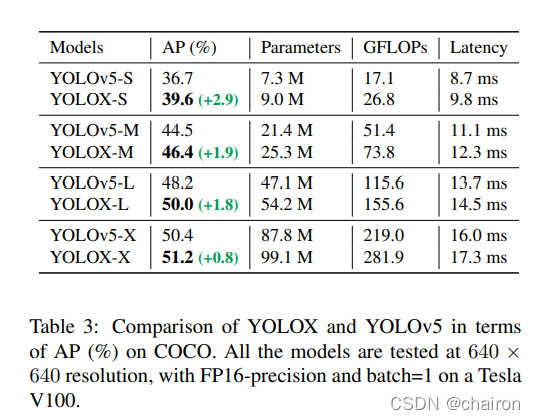
为了进行公平的比较,我们采用了YOLOv5的Backbone,包括改进的CSPNet [31],SiLU激活和PAN [19]头。我们还遵循其缩放规则来生产YOLOXS,YOLOX-M,YOLOX-L和YOLOX-X型号。与表 3 中的 YOLOv5 相比,我们的模型以 ∼3.0% 至 ∼1.0% AP 持续改进,只有边际时间增加(来自解耦头)。
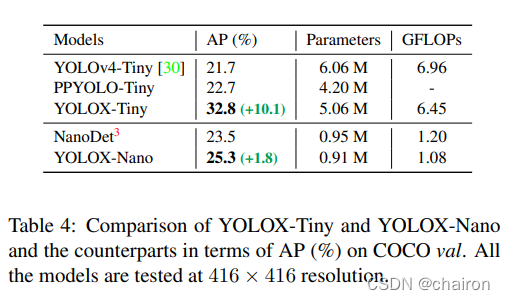
3.2 Tiny and Nano detectors
对于移动设备,我们采用深度卷积来构建YOLOX-Nano模型,该模型只有0.91M参数量和1.08G FLOPS。
如表 4 所示,YOLOX 在模型尺寸更小的情况下表现良好。
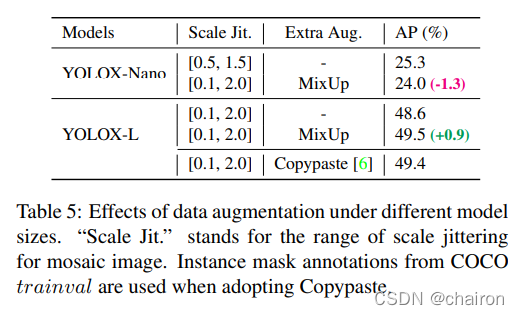
3.3 Model size and data augmentation
数据增强对于大的模型来说是有用的。
事实上,我们的 MixUp 实现比的原始版本更复杂。受Copypaste 的启发,我们在图像进行混合之前通过随机采样的比例因子对两个图像进行了抖动。为了理解具有尺度抖动的Mixup的强大功能,我们将它与YOLOX-L上的Copypaste进行了比较。请注意,Copypaste需要额外的实例掩码标签,而 MixUp 则不需要。但如表 5 所示,这两种方法实现了具有竞争力的性能,这表明在没有实例掩码注释可用时,具有缩放抖动的 MixUp 是 Copypaste 的合格替代品。
4 Comparison with the SOTA
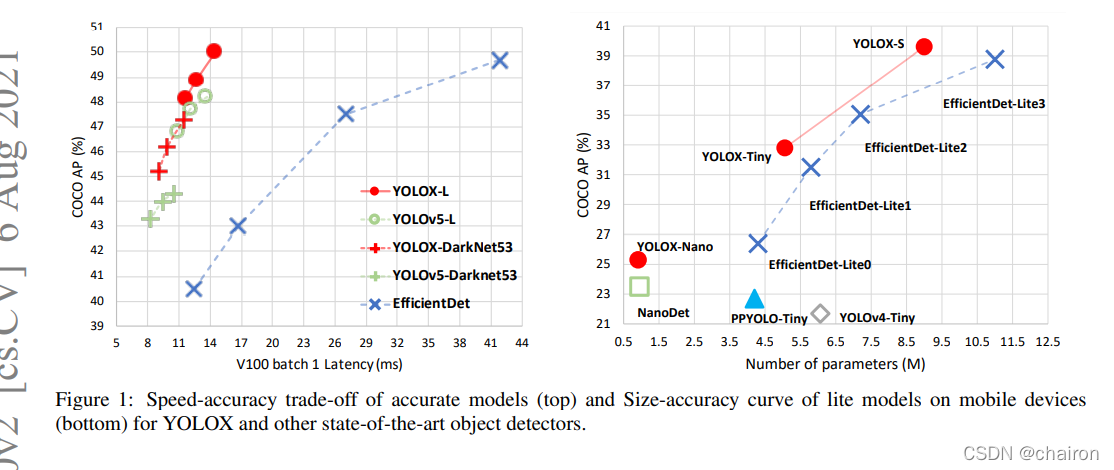
在不同的软件和硬件设备上推理时间会不同。因此,实验在相同的软硬件上,实现了YOLO系列的精度/速度的曲线图。
6 Conclusion
在这文章中,我们对YOLO系列进行了一些经验更新,它拥有一个高性能的Anchor free 的检测器,命名为YOLOX。它配备了一些先进的检测技术,如解耦头,Anchor free,和先进的标签分配策略( decoupled head,
anchor-free, and advanced label assigning strategy)。
YOLOX实现了速度和精度之间的更好的权衡。值得注意的是,我们改进的YOLOv3的架构,仍然是最广泛使用的detector之一,行业由于其广泛的兼容性,在COCO 数据集上 47.3% AP,超越当前的最佳实践 3.0% AP。

