
FlinkSQL Join总结_flink哪种join支持回撤
赞
踩
一、Regular Join
常规 JOIN(Regular JOIN)是语法最简单的一类 JOIN,和传统数据库的 JOIN 语法完全一致。对于左表和右表的任何变动,都会触发实时计算和更新,因此它的结果是“逐步逼近”最终的精确值,也就是下游可能看到变来变去的结果。为了支持结果的更新,下游目的表需要 定义主键 (PRIMARY KEY NOT ENFORCED)。
不支持时间窗口以及时间属性,任何一侧数据流有更改都是可见的,直接影响整个 join 结果。如果有一侧数据流增加一个新纪录,那么它将会把另一侧的所有的过去和将来的数据合并在一起,因为regular join 没有剔除策略,这就影响最新输出的结果; 正因为历史数据不会被清理,所以 regular join 支持数据流的任何更新操作(插入、更新、删除)。
这种 JOIN 要求 JOIN 两边数据都永久保留在 Flink state 中,才能保证输出结果的准确性,这将导致 State 的无限膨胀。
可以配置 state 的TTL(time-to-live:table.exec.state.ttl)来避免其无限增长,但注意这可能会影响查询结果的准备性。
tableEnvironment.getConfig().setIdleStateRentention(Duration.ofMillis(20000));
ttl时间在访问时,leftjoin会刷新左流时效,rightjoin会刷新右流时效。
如果双流join的时间跨度巨大,也不要通过超长的ttl来解决,建议双流join改为流和表的join;应当将很久之前的数据保存在如hbase的存储系统中,类似维度表,和流进行join,下文lookup join。
使用语法:目前,仅支持等值连接,INNER JOIN,LEFT JOIN,RIGHT JOIN,FULL OUTER JOIN
适用场景:双流的数据几乎同步产生,只有少量的网络延迟;如一条订单数据产生,同时产生若干条订单商品明细数据,以及订单消费券使用数据;
- SELECT *
- FROM Orders
- INNER JOIN Product
- ON Orders.product_id = Product.id
-
- SELECT *
- FROM Orders
- LEFT JOIN Product
- ON Orders.product_id = Product.id
-
- SELECT *
- FROM Orders
- RIGHT JOIN Product
- ON Orders.product_id = Product.id
-
- SELECT *
- FROM Orders
- FULL OUTER JOIN Product
- ON Orders.product_id = Product.id

P.S. 关于Regular Join中回撤流的问题
以left join为例,如果左边先到,会产生半边数据,当右边到了后,会将之前的数据回撤掉,再产生一条完整数据,这即回撤流;
若使用kafka作为sink,普通的kafka不支持update和delete,需要使用upsert-kafka,在语句中需要定义主键;主键的作用是将相同主键的分区发到同一个kafka broker中,kafka单分区内数据是有序的;
当kafka中出现回撤流时,回撤操作会变为null,而insert数据会保留2次,没有完美解决这个问题,

会写入一条null数据,可以通过下游对撤回流进行处理.
- 下游直接写入数据库:利用数据库的幂等性特点进行处理
| 数据库 | 处理方式 |
| Hbase | put |
| phoenix | upsert |
| mysql | insert into values() on duplicate update name = 'zhangsan' || replace into |
| clickhouse | ReplacingMerge Tree |
| redis | sadd/incr/hset等 |
- 下游进行聚合统计,4种处理方案
1.下游需求简单,且本身就需要做去重,不需要额外处理,比如说独立访客,页面去重等;
2.下游需求只需要左表数据,那么任取一条数据即可,一般选择第一条,其他数据通过状态编程过滤;
3.下游需求左右数据都需要,且需求为累加型,第一条数据正常输出,后续数据如果前面已经输出该字段,则改为0输出
4.通用情况:需要数据最全的一条,在上游输出数据时添加处理时间,下游使用状态编程+定时器输出处理时间最大的一条.如果是从kafka消费,甚至不需要处理时间,因为upsert-kafka为sink表定义了主键,分区内的数据是有序的,因此取最后一条数据即是完整的;示例如下
- //按照订单明细ID分组,去重数据(由LeftJOIN产生的)
- SingleOutputStreamOperator<JSONObject> filterDS = jsonObjDS.keyBy(json -> json.getString("id"))
- .process(new KeyedProcessFunction<String, JSONObject, JSONObject>() {
-
- private ValueState<JSONObject> valueState;
-
- @Override
- public void open(Configuration parameters) throws Exception {
- valueState = getRuntimeContext().getState(new ValueStateDescriptor<JSONObject>("value-state", JSONObject.class));
- }
-
- @Override
- public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception {
-
- JSONObject state = valueState.value();
- //第一条数据来的时候,设置一个定时器,这里设置为10s
- if (state == null) {
- TimerService timerService = ctx.timerService();
- long ts = timerService.currentProcessingTime();
- timerService.registerProcessingTimeTimer(ts + 10000L);
- }
- //将当前数据认为最后的数据并放入状态中
- valueState.update(value);
- }
-
- //定时器触发后,将状态里的数据输出,即认为是最后来的,最完整的join数据,同时清理状态
- @Override
- public void onTimer(long timestamp, OnTimerContext ctx, Collector<JSONObject> out) throws Exception {
- JSONObject value = valueState.value();
- valueState.clear();
- out.collect(value);
- }
- });
二、Interval Join
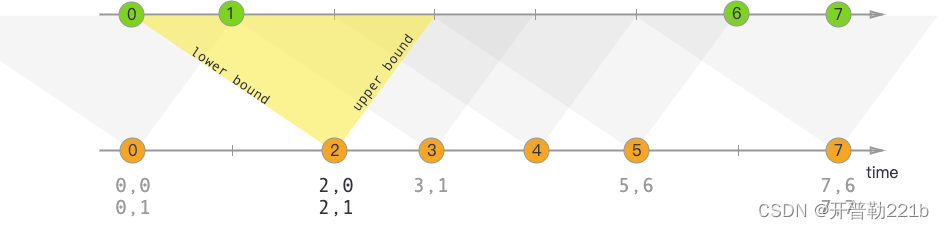
时间区间 JOIN 是另一种关联策略,它与上述的常规 JOIN 不同之处在于,左右表仅在某个时间范围(给定上界和下界)内进行关联,且只支持普通 Append 数据流,不支持含 Retract 的动态表。如上图(来自 Flink 官方文档)。它其实是一种开窗的regular join,它的好处是由于给定了关联的区间,因此只需要保留很少的状态,内存压力较小,并且状态会自动清理,只根据给定的时间区间保留状态数据。但是缺点是如果关联的数据晚到或者早到,导致落不到 JOIN 区间内,就可能导致结果不准确。此外,只有当区间过了以后,JOIN 结果才会输出,因此会有一定的延迟存在。
用法:
- CREATE TABLE `Order`
- (
- id INT,
- product_id INT,
- quantity INT,
- order_time TIMESTAMP(3),
- WATERMARK FOR order_time AS order_time,
- PRIMARY KEY (id) NOT ENFORCED
- ) WITH (
- 'connector' = 'datagen',
- 'fields.id.kind' = 'sequence',
- 'fields.id.start' = '1',
- 'fields.id.end' = '100000',
- 'fields.product_id.min' = '1',
- 'fields.product_id.max' = '100',
- 'rows-per-second' = '1'
- );
-
- CREATE TABLE `Product`
- (
- id INT,
- name VARCHAR,
- price DOUBLE,
- record_time TIMESTAMP(3),
- WATERMARK FOR record_time AS record_time,
- PRIMARY KEY (id) NOT ENFORCED
- ) WITH (
- 'connector' = 'datagen',
- 'fields.id.min' = '1',
- 'fields.id.max' = '100',
- 'rows-per-second' = '1'
- );
-
- CREATE TABLE `OrderDetails`
- (
- id INT,
- product_name VARCHAR,
- total_price DOUBLE,
- order_time TIMESTAMP
- ) WITH (
- 'connector' = 'print'
- );
-
-
- INSERT INTO `OrderDetails`
- SELECT o.id, p.name, o.quantity * p.price, o.order_time
- FROM `Order` o,
- `Product` p
- WHERE o.product_id = p.id
- AND o.order_time BETWEEN p.record_time - INTERVAL '5' MINUTE AND p.record_time;
如何设置上下界:
The following predicates are examples of valid interval join conditions:
ltime = rtime
ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
注意事项:
使用interval join,需要定义好时间属性字段(即处理时间或事件时间), 且将该时间戳字段用作 WATERMARK FOR 语句指定的时间字段。如果表实在没有时间戳字段,则可以使用 PROCTIME() 函数来生成一个Processing Time。如果定义的是 Processing Time,则Flink 框架本身根据系统划分的时间窗口定时清理数据;如果定义的是 Event Time,Flink 框架分配 Event Time 窗口并根据设置的 watermark 来清理数据。
使用watermark事件时间
1.把时间ts或者date转换成flink timestamp
row_time as TO_TIMESTAMP(FROM_UNIXTIME(cast(ts as bigint)))
2.把time_stamp字段声明为watermark
watermark for row_time as row_time
特别注意:请不要直接使用未定义 WATERMARK 或 PROCTIME() 的原始 TIMESTAMP 类型字段,否则可能会退回到上述的 “常规 JOIN”。
三、LookUp Join
loopup join通常用于使用从外部系统查询的数据来丰富表。连接要求一个表具有处理时间属性,而另一个表由查找源连接器支持。
适用场景:流表join
- -- Main Table
- CREATE TABLE Orders (
- `order_id` string,
- `total` decimal(16,2),
- `ts` string,
- `proc_time` as proctime()
- ) WITH(……)
-
- -- LookUp Table
- CREATE TEMPORARY TABLE Customers (
- id INT,
- name STRING,
- country STRING,
- zip STRING
- ) WITH (
- 'connector' = 'jdbc',
- 'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
- 'table-name' = 'customers'
- );
-
- -- LookUp Join
- SELECT o.order_id, o.total, c.country, c.zip
- FROM Orders AS o
- JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
- ON o.customer_id = c.id;
四、Temporal Join

