
- 1flutter弹起键盘页面布局超限问题_flutter 键盘弹起布局错误
- 2到处出bug? 到处给你挖坑? 这样的程序员其实很可爱_程序员交接挖坑
- 3《信息系统项目管理师教程(第4版)》软考高级 第七章 项目立项 知识点、思维导图整理_信息系统项目管理 高级 第4版 资料
- 4使用Arduino开发ESP32(09):WebServer使用演示与说明_arduino webserver
- 5开源网站流量统计系统Piwik源码分析——参数统计(一)_matomo gt_ms参数
- 6毕业季 | 新的开始,不说再见
- 7使用Ollama实现本地部署大模型
- 8@SCHEDULED(CRON = "0 0 * * * ?")实现定时任务
- 9Axure 高仿真 elementUI 日期区间选择元件_axure日期区间设置
- 10信贷风控技术十分钟精通7(特征选择和降维)
使用Python中的pytesseract模块实现抓取图片中文字_pytesseract 识别汉字
赞
踩
目录
一、需求分析
最近同事用网上提供扫描软件进行扫描识别文字,每天上线只能够做两次扫描,请求我研发一个小工具帮助解决识别图片的中文字。
二、方案选择
使用pytesseract模块可以解决这个需求问题,pytesseract是光识别图片的模块。需要安装第三方资源库进行搜索。
三、实验实操
3.1、配置环境
Anaconda3.0,pycharm2022版,python3.7.0,win10
3.2、 Anaconda配置
先配置Anaconda3的环境,找到默认安装路径C:\Users\Administrator\.condarc(看自己环境安装哪里)

将.condarc文件备份一个,然后加载源的配置项拷贝进去,重启Anaconda3程序,生效配置项。

加载源:
- channels:
- - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- - http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- - http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- - http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- show_channel_urls: true
- ssl_verify: true
3.3、安装tesseract程序
下载tesseract的exe安装文件,安装包地址:https://github.com/UB-Mannheim/tesseract/wiki
我下的是 tesseract-ocr-w64-setup-v5.0.1.20220118.exe版本。(本机是64位操作系统)
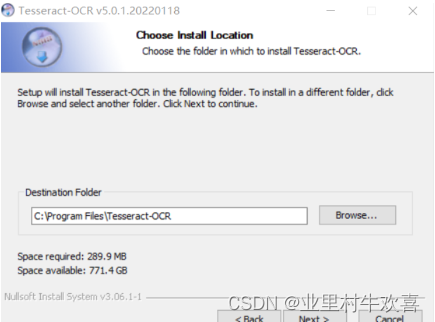
选配项中记得选择中文的语言,后期识别中文字体做准备。

配置tesseract系统环境变量,将 tesseract-ocr的绝对路径配置在系统变量中。
【从C:\Program Files\Tesseract-OCR安装目录下,直接把tessdata 文件夹里的内容都复制到C:\Users\Administrator\Anaconda3,另外tessdata 文件夹里chi_sim.traineddata,eng.traineddata文件需要复制到C:\ProgramData\Anaconda3下,不然后面运行程序会提示找不到文件,配置好环境变量也不行!】(据说是霸王条款)
重启系统让变量生效。

3.4、安装pytesseract模块
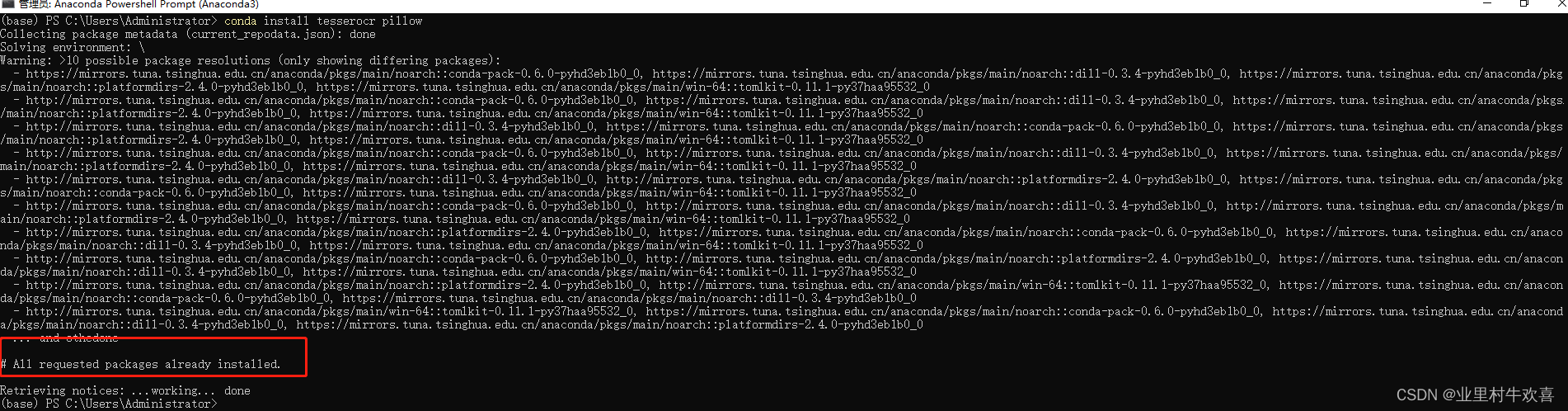
运行Anaconda 终端命令,执行conda install tesserocr pillow

系统已经显示我已经安装。(安装的时间有一些长,需要耐性等待。)
执行另外一个指令conda install pytesseract (安装pytesseract,这个安装需要一点时间等待了)
使用python语句进行验证。

3.5、见证奇迹的环节
测试1:
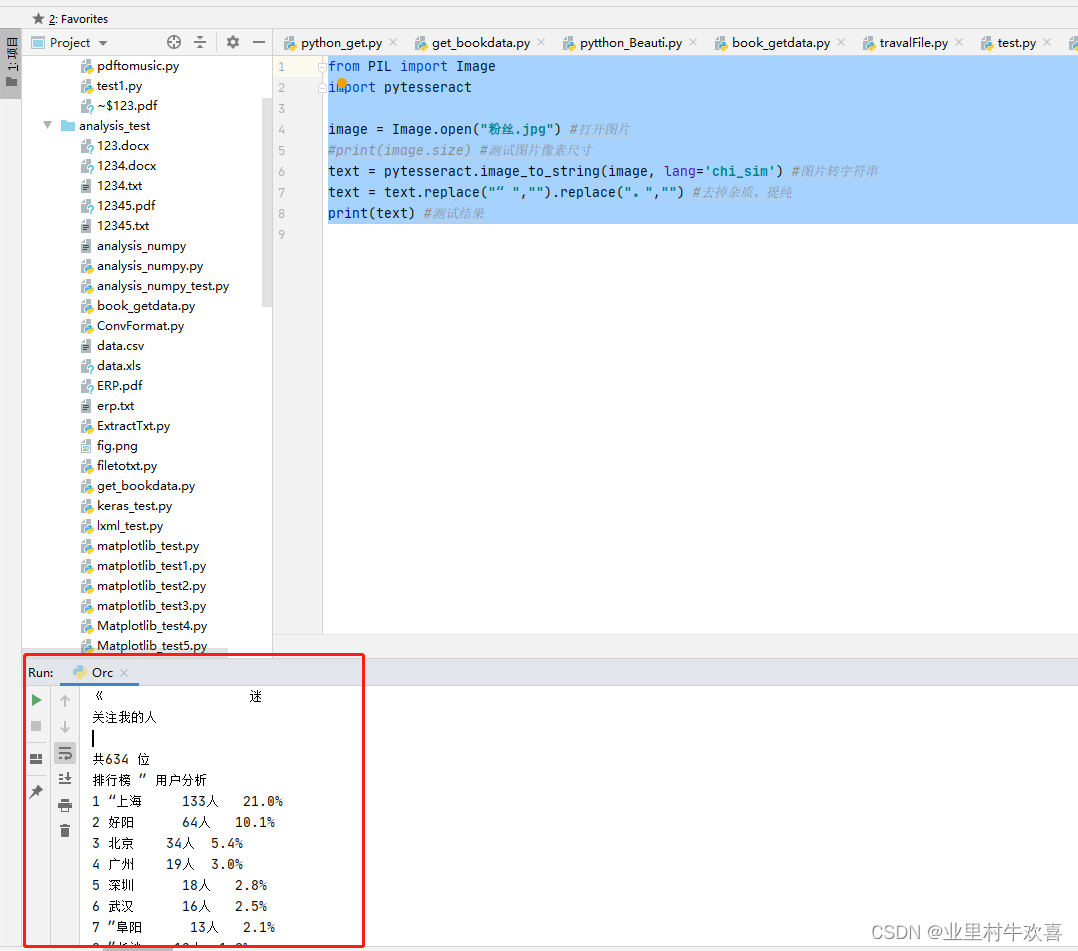
在pycharm编译器中执行语句操作:
- from PIL import Image
- import pytesseract
-
- image = Image.open("粉丝.jpg") #打开图片
- #print(image.size) #测试图片像素尺寸
- text = pytesseract.image_to_string(image, lang='chi_sim') #图片转字符串
- text = text.replace("“ ","").replace("。","") #去掉杂质,提纯
- print(text) #测试结果
原图片粉丝.jpg:
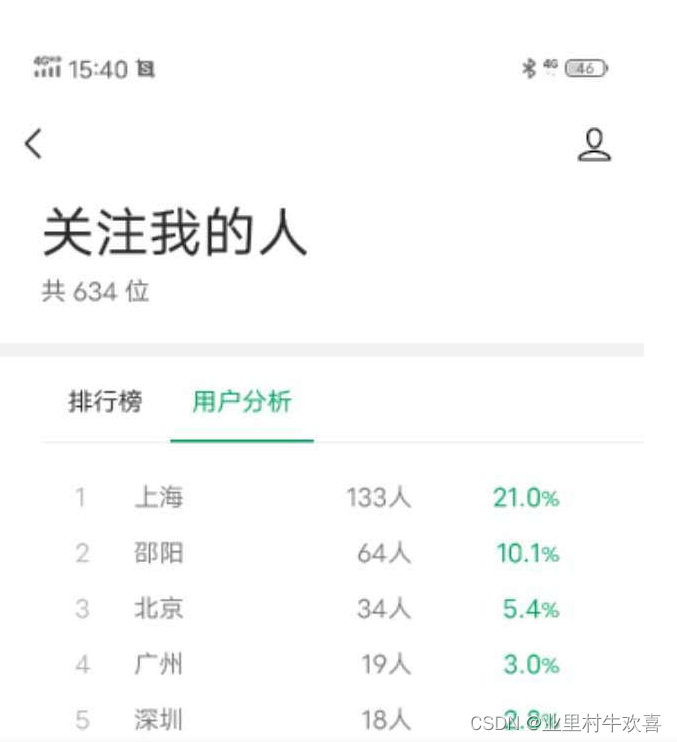
编译结果:.(已经成功识别图片内部的文字,进行呈现。)
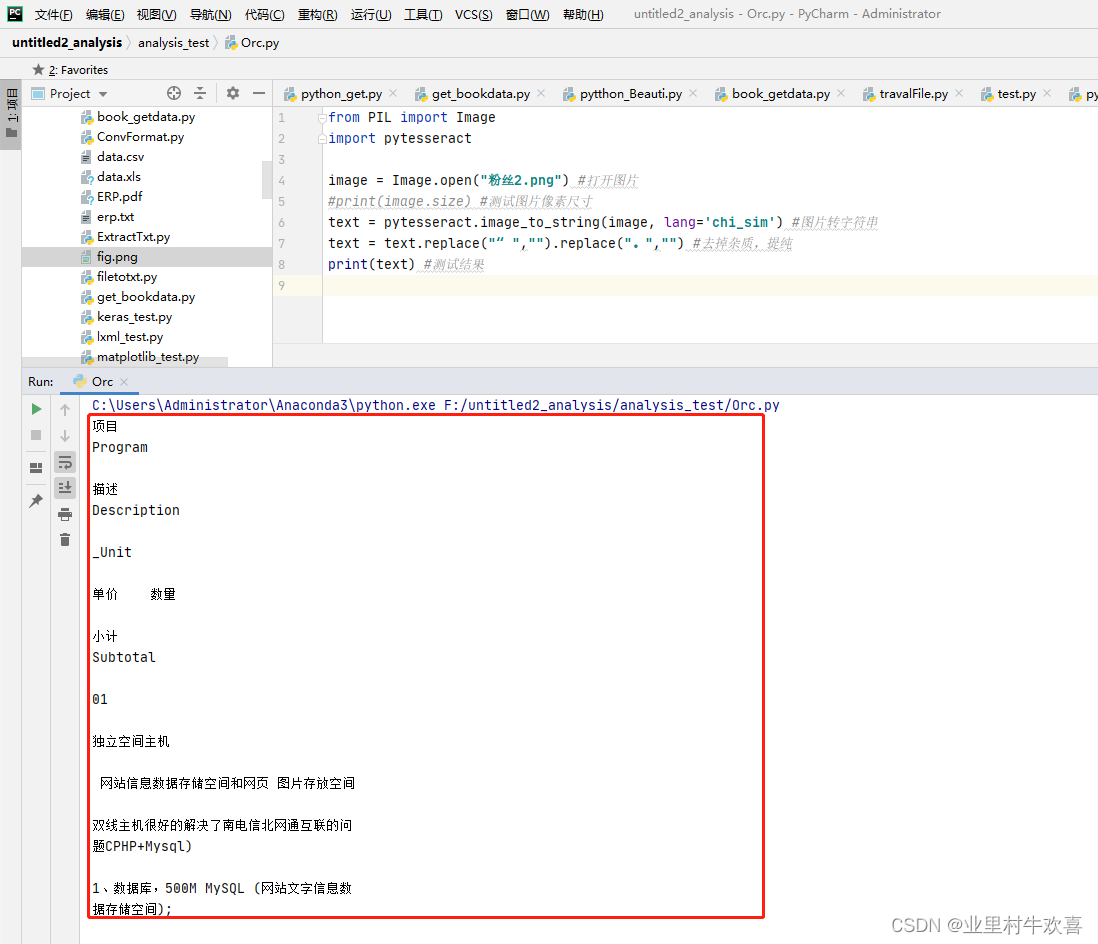
测试2:
原图2

测试结果:可以正常识别图片文字出来了。
参考网友知识:
python提取图片中的文字_帅帅de三叔的博客-CSDN博客_python提取图片文字
anaconda+python+tesseract安装,亲试可用_icanfly728的博客-CSDN博客_anaconda安装库 pytesseract

