
- 1Springboot整合JavaMail实现邮件发送
- 2沉浸式翻译(immersive-translate):解决谷歌翻译无法使用的问题_沉浸式翻译插件谷歌
- 3YOLOv8引入渐进特征金字塔网络AFPN结构_yolov8+apfn渐进金字塔
- 4怎样使用Photoshop 的操控变形功能_新建一个副本图层,并抠去背景色
- 5给还在迷茫的你分享我从零基础的日语文科生半路出家搞Python如何上岸的
- 6python123程序设计方法测试_Python程序设计答案
- 7[监督学习] 分类(K近邻算法)_k近邻算法 and “分类”
- 8C++显示调用析构函数_显式调用析构函数
- 9软件测试怎么投简历才会增加面试通过率?_测试发版成功率简历
- 10电商技术揭秘十七:浅析电商数据安全与保护
OCR技术简介_通用物体和场景识别简称
赞
踩
其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
光学字符识别(Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。
OCR的应用场景
根据识别场景,可大致将OCR分为识别特定场景的专用OCR和识别多种场景的通用OCR。比如现今方兴未艾的证件识别和车牌识别就是专用OCR的典型实例。通用OCR可以用于更复杂的场景,也具有更大的应用潜力。但由于通用图片的场景不固定,文字布局多样,因此难度更高。根据所识别图片的内容,可将场景分为清晰且具有固定模式的简单场景和更为复杂的自然场景。自然场景文本识别的难度极高,原因包括:图片背景极为丰富,经常面临低亮度、低对比度、光照不均、透视变形和残缺遮挡等问题,而且文本的布局可能存在扭曲、褶皱、换向等问题,其中的文字也可能字体多样、字号字重颜色不一的问题。因此自然场景中的文字识别技术,也经常被单列为场景文字识别技术(Scene Text Recognition, STR),相关内容可回顾往期SigAI的文章。
OCR的技术路线
典型的OCR的技术路线如下图所示

其中影响识别准确率的技术瓶颈是文字检测和文本识别,而这两部分也是OCR技术的重中之重。
在传统OCR技术中,图像预处理通常是针对图像的成像问题进行修正。常见的预处理过程包括:几何变换(透视、扭曲、旋转等)、畸变校正、去除模糊、图像增强和光线校正等
文字检测即检测文本的所在位置和范围及其布局。通常也包括版面分析和文字行检测等。文字检测主要解决的问题是哪里有文字,文字的范围有多大。
文本识别是在文本检测的基础上,对文本内容进行识别,将图像中的文本信息转化为文本信息。文字识别主要解决的问题是每个文字是什么。识别出的文本通常需要再次核对以保证其正确性。文本校正也被认为属于这一环节。而其中当识别的内容是由词库中的词汇组成时,我们称作有词典识别(Lexicon-based),反之称作无词典识别(Lexicon-free)
图像预处理
传统OCR基于数字图像处理和传统机器学习等方法对图像进行处理和特征提取。常用的二值化处理有利于增强简单场景的文本信息,但对于复杂背景二值化的收效甚微。
传统方法上采用HoG对图像进行特征提取,然而HoG对于图像模糊、扭曲等问题鲁棒性很差,对于复杂场景泛化能力不佳。由于深度学习的飞速发展,现在普遍使用基于CNN的神经网络作为特征提取手段。得益于CNN强大的学习能力,配合大量的数据可以增强特征提取的鲁棒性,面临模糊、扭曲、畸变、复杂背景和光线不清等图像问题均可以表现良好的鲁棒性。[1]

文字检测
对于文字检测任务,很自然地可以想到套用图像检测的方法来框选出图像中的文本区域。常见的一些物体检测方法如下:
Faster R-CNNFaster R-CNN采用辅助生成样本的RPN(Region Proposal Networks)网络,将算法结构分为两个部分,先由RPN 网络判断候选框是否为目标,再经分类定位的多任务损失判断目标类型,整个网络流程都能共享卷积神经网络提取的的特征信息,节约计算成本,且解决Fast R-CNN 算法生成正负样本候选框速度慢的问题,同时避免候选框提取过多导致算法准确率下降。对于受限场景的文字检测,Faster R-CNN的表现较为出色。可以通过多次检测确定不同粒度的文本区域。[2]

FCN相较于Faster R-CNN 算法只能计算ROI pooling 层之前的卷积网络特征参数,R-FCN 算法提出一种位置敏感分布的卷积网络代替ROI pooling 层之后的全连接网络,解决了Faster R-CNN 由于ROI Pooling 层后面的结构需要对每一个样本区域跑一次而耗时比较大的问题,使得特征共享在整个网络内得以实现,解决物体分类要求有平移不变性和物体检测要求有平移变化的矛盾,但是没有考虑到候选区域的全局信息和语义信息。[3]所以当面对自然场景的通用OCR,适于多尺度检测的FCN较之Faster R-CNN有着更好的表现。当采用FCN时,输出的掩膜可以作为前景文字的二值图像进行输出。

但是与其他日常场景的物体检测所不同的是,文字图像的分布更接近于均匀分布而非正态分布,即文字总体的均值图像并不能体现文字这一抽象概念的特征。除此之外,文字的长宽比与物体的长宽比不同,导致候选锚定框不适用;文字的方向仍然不能确定,对非垂直的文字方向表现佳;自然场景中常出现一些结构与文字非常接近,导致假阳性率升高。因此需要对现有模型进行调整。
一种常见的做法是调整候选锚定框,例如
RRPN(Rotation Region Proposal Networks)在faster R-CNN的基础上,将垂直的候选锚定框进行旋转满足非垂直文本的检测,这样一来就可以满足非垂直文字的检测需求。[4]

TextBoxes是基于SSD改进的一个算法。调整了锚定框的长宽比,以适应文字的高长宽比。输出层也利用了利用非标准的卷积核。更适应文字细长的宽高比这一特点。[5]

DMPNet(Deep Matching Prior Network)采用非矩形四边形的候选锚定框进行检测。通过Monte-Carlo方法计算标注区域与矩形候选框和旋转候选框的重合度后重新计算顶点坐标,得到非矩形四边形的顶点坐标。[6]

另一种改进的方法是通过自底向顶的方法,检测细粒度文本后将其连接成更粗粒度的文本
CTPN(Connectionist Text Proposal Network)是目前应用最广的文本检测模型之一。其基本假设是单个字符相较于异质化程度更高的文本行更容易被检测,因此先对单个字符进行类似R-CNN的检测。之后又在检测网络中加入了双向LSTM,使检测结果形成序列提供了文本的上下文特征,便可以将多个字符进行合并得到文本行。[7]

SegLink则是在SSD的启发下得出的。采用临近连接的方法对上下文进行连接。并且通过将连接参数的学习整合进了神经网络的学习过程,使得模型更容易训练。[8]
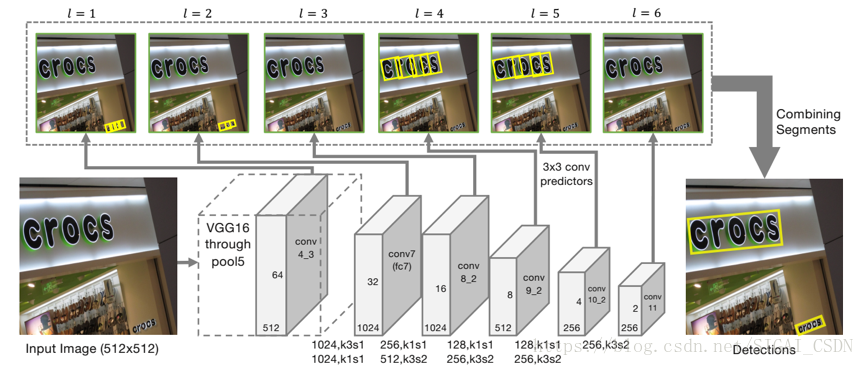
标题
有一些研究引入了注意力机制,如下图模型采用Dense Attention模型来对图像的权重进行评估。这样有利于将前景图像和背景图像分离,对于文本内容较之背景图像有着更高的注意力,使检测结果更准确。[9]
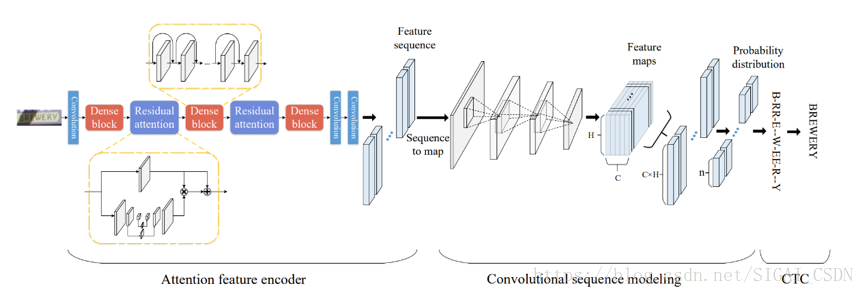
文本识别
文本识别在传统技术中采用模板匹配的方式进行分类。但是对于文字行,只能通过识别出每一个字符来确定最终文字行从内容。因此可以对文字行进行字符切分,以得到单个文字。这种方式中,过分割-动态规划是最常见的切分方法。由于单个字符可能会由于切分位置的原因产生多个识别结果,例如“如”字在切分不当时会被切分成“女_口”,因此需要对候选字符进行过分割,使其足够破碎,之后通过动态规划合并分割碎片,得到最优组合,这一过程需要人工设计损失函数。还有另一种方法是通过滑动窗口对每一个可能的字符进行匹配,这种方法的准确率依赖于滑动窗口的滑动窗尺寸,如果滑动窗尺寸过大会造成信息丢失,而太小则会使计算力需求大幅增加。
以上的传统方法通过识别每个单字符以实现全文的识别,这一过程导致了上下文信息的丢失,对于单个字符有较高的识别正确率,其条目识别正确率也难以保证。以身份证识别为例,识别18位的身份号的场景下,即使单字符识别正确率高达99%,其条目正确率只能到0.9918=83%,如果切分也存在1%的损失(即正确率99%),条目正确率则只有(0.99*0.99)18=70%。
因此引入上下文的信息,成为了提升条目准确率的关键。从深度学习的角度出发,要引入上下文这样的序列信息,RNN和LSTM等依赖于时序关系的神经网络是最理想的选择。

常见的一种做法是利用CRNN模型。以CNN特征作为输入,双向LSTM进行序列处理使得文字识别的效率大幅提升,也提升了模型的泛化能力。先由分类方法得到特征图,之后通过CTC对结果进行翻译得到输出结果。[10]

另一种方法是引入注意力机制。以CNN特征作为输入,通过注意力模型对RNN的状态和上一状态的注意力权重计算出新一状态的注意力权重。之后将CNN特征和权重输入RNN,通过编码和解码得到结果。[11]
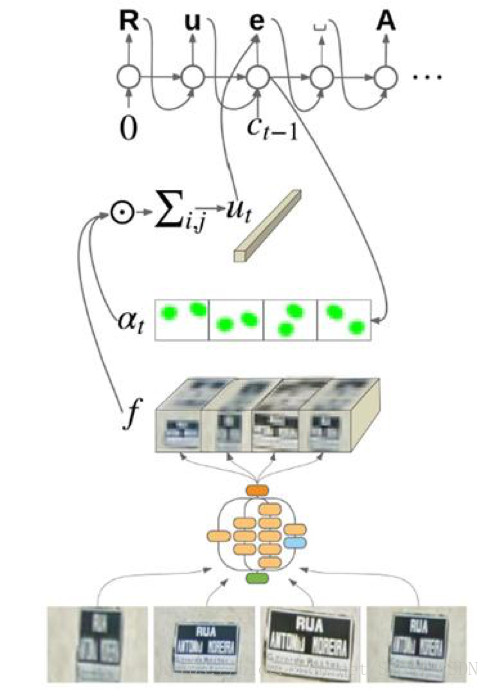
端到端的OCR
与检测-识别的多阶段OCR不同,深度学习使端到端的OCR成为可能,将文本的检测和识别统一到同一个工作流中。目前比较受到瞩目的一种端到端框架叫做FOTS(Fast Oriented Text Spotting)。FOTS的检测任务和识别任务共享卷积特征图。一方面利用卷积特征进行检测,另一方面引入了RoIRotate,一种用于提取定向文本区域的算符。得到文本候选特征后,将其输入到RNN编码器和CTC解码器中进行识别。同时,由于所有算符都是可微的,因此端到端的网络训练成为可能。由于简化了工作流,网络可以在极低运算开销下进行验证,达到实时速度。[12]

总结
尽管基于深度学习的OCR表现相较于传统方法更为出色,但是深度学习技术仍需要在OCR领域进行特化,而其中的关键正式传统OCR方法的精髓。因此我们仍需要从传统方法中汲取经验,使其与深度学习有机结合进一步提升OCR的性能表现。另一方面,作为深度学习的推动力,数据起到了至关重要的作用,因此收集广泛而优质的数据也是现阶段OCR性能的重要举措之一。
参考文献
[1] Lécun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11):2278-2324.
[5] Liao M, Shi B, Bai X, et al. TextBoxes: A Fast Text Detector with a Single Deep Neural Network[J]. 2016.
[6] Liu Y, Jin L. Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection[C]//: IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[7] Tian Z, Huang W, He T, et al. Detecting Text in Natural Image with Connectionist Text Proposal Network[C]//: European Conference on Computer Vision, 2016.
[9] Gao Y, Chen Y, Wang J, et al. Reading Scene Text with Attention Convolutional Sequence Modeling[J]. 2017.
[11] Wojna Z, Gorban A N, Lee D S, et al. Attention-Based Extraction of Structured Information from Street View Imagery[J]. 2017:844-850.
[12] Liu X, Liang D, Yan S, et al. FOTS: Fast Oriented Text Spotting with a Unified Network[J]. 2018.

