
- 1如何使用potplayer在公网环境访问内网群晖NAS中储存在webdav中的影视资源_nas中电影怎么访问
- 2Git回滚版本并push到远端master_git reset之后需要push吗
- 3git将其他分支的某个提交合到当前分支_git把其他分支某一次提交的内容合并到当前分支
- 4Mac电脑使用:判断ARM64 or x64的方法_mac arm
- 5达梦数据库DM8(一):新建数据库实例_达梦数据库创建实例
- 6简单调用智谱API实现场景对话和问答_质谱清言的api怎么实现连续对话
- 7车牌自动生成器软件设计与实现_车牌生成器
- 8【GitHub项目推荐--不错的 Java 开源项目】【转载】_github java开源项目
- 9Git常用命令_* branch head -> fetch_head
- 10kafka内存不断增加_【赵强老师】Kafka的持久化
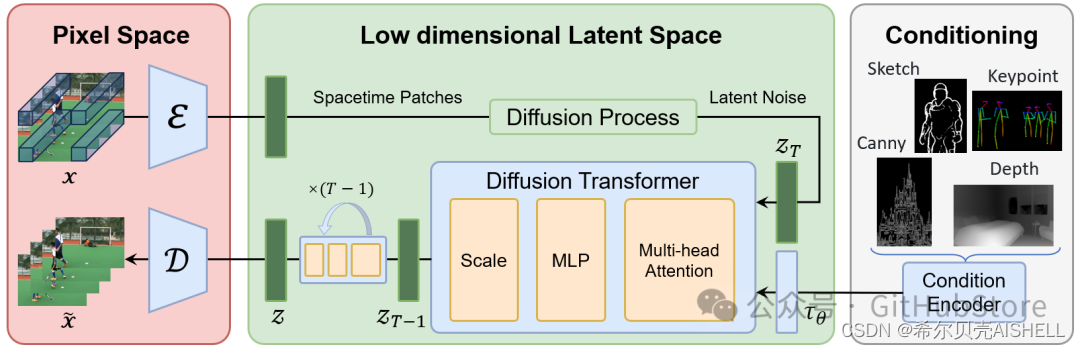
Open-Sora:开源版的Sora
赞
踩
项目简介
本项目希望通过开源社区的力量复现Sora,由北大-兔展AIGC联合实验室共同发起,当前我们资源有限仅搭建了基础架构,无法进行完整训练,希望通过开源社区逐步增加模块并筹集资源进行训练,当前版本离目标差距巨大,仍需持续完善和快速迭代,欢迎Pull request!!!
项目阶段:
-
基本的
-
设置代码库并在景观数据集上训练无条件模型。
-
训练可提高分辨率和持续时间的模型。
-
扩展
-
在景观数据集上进行text2video实验。
-
在 video2text 数据集上训练 1080p 模型。
-
具有更多条件的控制模型。
-
在 video2text 数据集上训练 1080p 模型。
-
具有更多条件的控制模型。

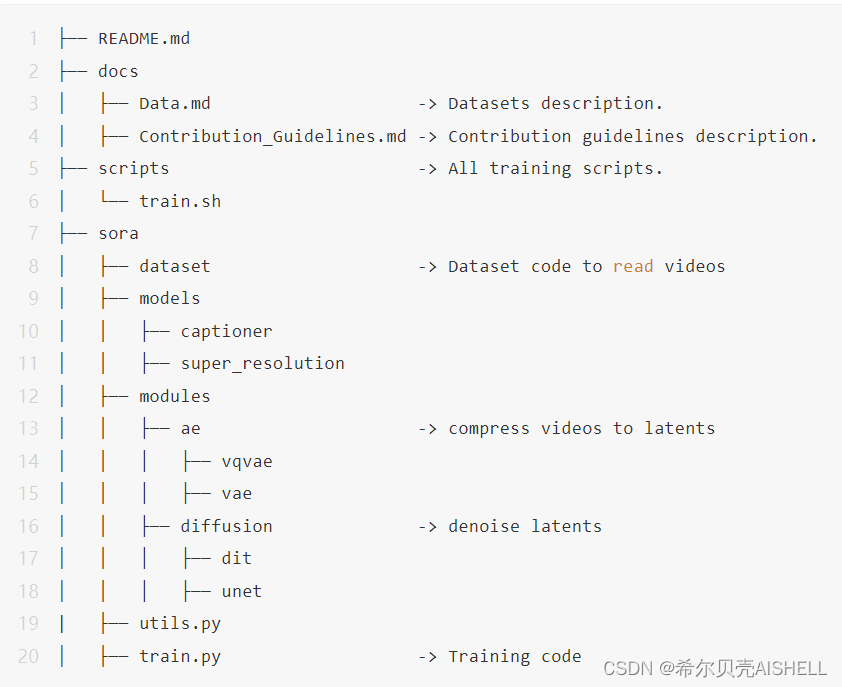
仓库结构
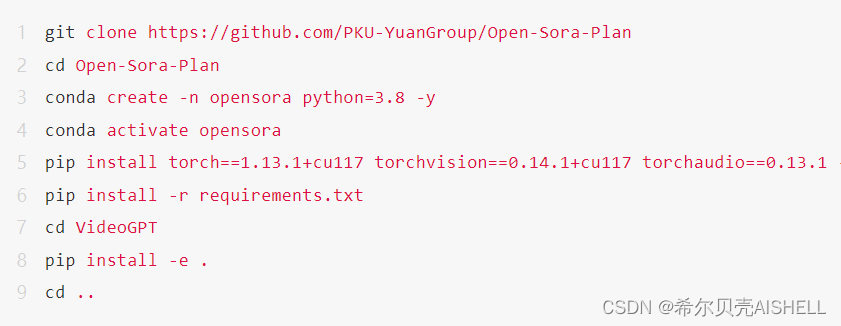
要求和安装
推荐要求如下。
-
Python >= 3.8
-
Pytorch >= 1.13.1
-
CUDA 版本 >= 11.7
-
安装所需的包:
用法
数据集
参考Data.md
Video-VQVAE (VideoGPT)
训练

请参阅原始存储库。使用 scripts/train_vqvae.py 脚本训练 Video-VQVAE。执行 python scripts/train_vqvae.py -h 以获取有关所有可用训练设置的信息。下面列出了更多相关设置的子集以及默认值。
VQ-VAE 特定设置
-
--embedding_dim :码本嵌入的维数
-
--n_codes 2048 :码本中的代码数量
-
--n_hiddens 240 :残差块中隐藏特征的数量
-
--n_res_layers 4 :剩余块的数量
-
--downsample 4 4 4 :编码器的 T H W 下采样步长
训练设置
-
--gpus 2 :分布式训练的GPU数量
-
--sync_batchnorm :使用 > 1 GPU 时使用 SyncBatchNorm 而不是 BatchNorm3d
-
--gradient_clip_val 1 :训练的梯度裁剪阈值
-
--batch_size 16 :每个 GPU 的批量大小
-
--num_workers 8 :每个 DataLoader 的工作人员数量
数据集设置
-
--data_path <path> : hdf5 文件或包含 train 和 test 文件夹以及视频子目录的文件夹的路径
-
--resolution 128 :训练的空间分辨率
-
--sequence_length 16 :时间分辨率,或视频剪辑长度
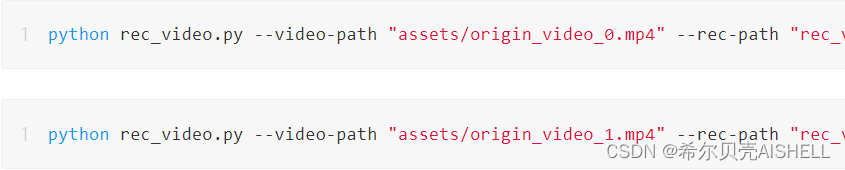
重建
项目链接


