
- 1next 14 appRouter redux数据持久化_nextjs redux 持久化存储
- 2mac与windows服务器 访问和共享
- 3Android 15全面解读:性能飙升、隐私守护与智能生活新纪元_安卓15
- 4标题:怎样通过Dialogflow构建一个聊天机器人?React版。_dialogflow机器人
- 5连接Mongodb数据库的步骤以及注意事项_如何连接mongodb数据库
- 6小程序公告php实现,小程序两种滚动公告栏的实现方法
- 7Git仓库完整迁移全过程_gitee 将a仓库的克隆到b仓库
- 8FP6381AS5CTR原厂SOT23-5 1.2A同步降压IC DC-DC变频器
- 9STM32参考代码,编译时出现“cannot open source input file, no such file or directory"错误
- 10微信小程序用户隐私保护指引设置指南_mp后台-设置-基本设置-服务内容声明-用户隐私保护指引]中声明“剪切板”隐私收集
【数据结构导论】第 3 章:栈、队列和数组_数据结构导论课程中三元组表在那一章出现
赞
踩
目录
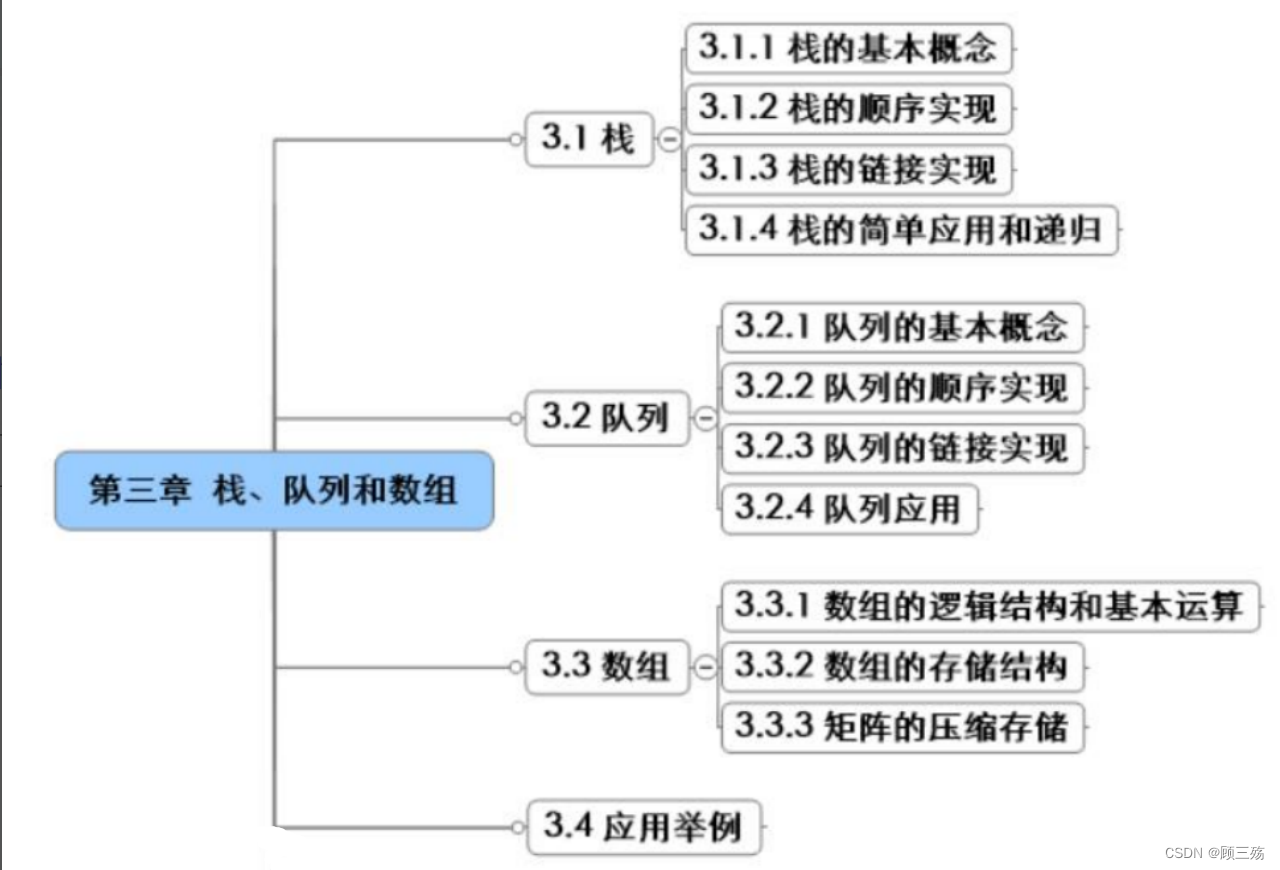
一、栈
描述栈和队列实现的头文件如下:
- Seqstack.h:顺序栈的定义及其实现。
- Lkstack.h:链栈的定义及其实现。
- Sequeue.h:顺序队列定义及其实现。
- Lkqueue.h:链队列的定义及其实现。
(1)栈的基本概念
① 定义
栈:是只能在表的一端(表尾)进行插入和删除的线性表
- 允许插入及删除的一端(表尾)称为栈顶(Top)
- 另一端(表头)称为栈底(Bottom)
- 当表中没有元素时称为空栈

- 进栈 —— 在栈顶插入一元素
- 出栈 —— 在栈顶删除一元素
- 栈和队列可看作是特殊的线性表,它们是运算受限的线性表
② 示意图
【示例】一叠书或一叠盘子
【示意图】
③ 栈的特点
后进先出:
- 栈中元素按 a1,a2,a3,…an 的次序进栈,出栈的第一个元素应为栈顶元素。
- 换句话说,栈的修改是按后进先出的原则进行的。
- 因此,栈称为后进先出线性表(LIFO)。
栈的用途 —— 常用于暂时保存有待处理的数据
④ 栈的基本运算
- 初始化栈:InitStack(S);
- 判栈空:EmptyStack (S);
- 进栈:Push (S,x);
- 出栈:Pop (S);
- 取栈顶: GetTop(S);
(2)栈的顺序实现
① 顺序栈及常用名词
- 顺序栈 —— 即栈的顺序实现
- 栈容量 —— 栈中可存放的最大元素个数
- 栈顶指针 top —— 指示当前栈顶元素在栈中的位置
- 栈空 —— 栈中无元素时,表示栈空
- 栈满 —— 数组空间已被占满时,称栈满
- 下溢 —— 当栈空时,再要求作出栈运算,则称 “下溢”
- 上溢 —— 当栈满时,再要求作进栈运算,则称 “上溢”
② 顺序栈的类型定义
【顺序栈类型】
【示意图】
【代码详解】
- 在这段代码中,我们定义了一个顺序栈的结构体
seqstack,其中包含了一个存储元素的数组data和一个顶部指针top。顶部指针top用于指示栈顶元素的下标位置,而存储元素的数组data则用于存放栈中的元素。- 此外,我们使用了
const int关键字来定义了一个常量maxsize,表示了栈的最大大小,这样可以方便地在整个程序中使用该常量。- 请注意,上述代码中的
DataType是一个占位符,表示数据类型,你可以根据实际需求将其替换为你需要的数据类型。【说明】
SeqStk *s ; /*定义一顺序栈s*/约定栈的第 1 个元素存在 data[1] 中,则:
- s -> top==0 代表顺序栈 s 为空
- s -> top==maxsize-1 代表顺序栈 s 为满
③ 顺序栈的基本运算
Ⅰ. 初始化
【示例代码】
【示意图】
【代码详解】
1. 这段代码实现了一个初始化栈的函数
Initstack。2. 函数的参数是一个指向
SeqStk结构体的指针stk,通过该指针我们可以操作栈的相关属性。3. 代码中的注释解释了每一行的作用:
stk->top = 0;将栈的顶部指针 top设置为 0,表示栈为空。return 1;返回 1,表示初始化栈成功。4. 该函数的目的是将栈的顶部指针初始化为 0,以便后续的入栈和出栈操作。
5. 需要注意的是,函数返回 1 可以作为一个成功的标志,可以根据实际需求进行适当修改。

Ⅱ. 判栈空
【示例代码】
【代码详解】
1. 这段代码实现了一个判断栈是否为空的函数
EmptyStack。2. 函数的参数是一个指向
SeqStk结构体的指针 stk,通过该指针我们可以获取栈的顶部指针top。3. 代码中的注释解释了每一行的作用:
if (stk->top == 0)如果栈的顶部指针 top为 0,表示栈为空。return 1;返回1,表示栈为空。else return 0;如果栈的顶部指针 top不为 0,表示栈不为空,返回 0。4. 该函数的目的是判断栈是否为空,可以根据返回值 0 或 1 进行相应的逻辑判断。
5. 需要注意的是,在条件判断中,需要使用
==来表示相等关系,而不是单个的=赋值运算符。6. 栈空时返回值为 1,否则返回值为 0
Ⅲ. 进栈
【示例代码】
【代码详解】
1. 这段代码实现了一个入栈操作的函数
Push。2. 函数的参数包括一个指向
SeqStk结构体的指针 stk,以及要入栈的数据元素x。3. 代码中的注释解释了每一行的作用:
if (stk->top == maxsize - 1)判断栈顶指针 top是否等于maxsize - 1,即栈是否已满。error("栈满");如果栈已满,则输出错误信息 "栈满"。return 0;返回 0,表示入栈失败。stk->top++;栈顶指针 top自增,指向新的栈顶位置。stk->data[stk->top] = x;将元素 x插入新的栈顶位置。return 1;返回 1,表示入栈成功。4. 该函数的目的是将数据元素
x压入顺序栈中,如果栈已满则输出错误信息。5. 返回值 0 表示入栈失败,返回值 1 表示入栈成功。

Ⅳ. 出栈
【示例代码】
【代码详解】
1. 这段代码实现了一个出栈操作的函数
Pop。2. 函数的参数是一个指向
SeqStk结构体的指针stk。3. 代码中的注释解释了每一行的作用:
if (stk->top == 0)判断栈顶指针 top是否为 0,即栈是否为空。error("栈空");如果栈为空,则输出错误信息"栈空"。return 0;返回 0,表示出栈失败。stk->top--;栈顶指针 top自减,指向新的栈顶位置。return 1;返回 1,表示出栈成功。4. 该函数的目的是将顺序栈
stk的栈顶元素退栈,如果栈已空则输出错误信息。5. 返回值 0 表示出栈失败,返回值 1 表示出栈成功。
6. 最后的
/* Pop */是针对函数的注释,说明该代码段实现了出栈操作。
Ⅴ. 取栈顶元素
【示例代码】
【代码详解】
1. 这段代码实现了一个获取栈顶元素的函数
GetTop。2. 函数的参数是一个指向
SeqStk结构体的指针stk。3. 代码中的注释解释了每一行的作用:
if (EmptyStack(stk))调用 EmptyStack函数判断栈是否为空。return NULLData;如果栈为空,返回空的数据元素。else return stk->data[stk->top];如果栈不为空,返回栈顶元素。4. 该函数的目的是获取顺序栈
stk的栈顶元素,如果栈为空,则返回一个空的数据元素。5. 否则,返回栈顶元素的值。
6. 需要注意的是,根据实际情况,
NULLData可以根据数据类型进行适当修改。
(3)栈的链接实现 —— 栈链
① 栈链的定义
- 栈的链式存储结构称为链栈,它是运算受限的单链表,插入和删除操作仅限制在表头位置上进行
- 栈顶指针就是链表的头指针

② 链式栈的类型说明
【链栈类型】
【注意】
- 下溢条件:LS -> next==NULL
- 上溢:不考虑栈满现象
【代码详解】
1. 这段代码定义了一个链式栈节点的结构体
LkStk。2. 它包含了以下两个成员变量:
DataType data;存储数据元素的变量,这里假设 DataType是一个自定义的数据类型。struct node* next;指向下一个节点的指针,用于实现链式结构。3. 该结构体表示链式栈中的一个节点,每个节点包含一个数据元素和一个指向下一个节点的指针。
4. 通过不断连接节点,便可构成一个链式栈的结构。
③ 链栈的基本运算
Ⅰ. 初始化
【示例代码】
【代码详解】
1. 这段代码实现了一个初始化链式栈的函数
InitStack。2. 函数的参数是一个指向
LkStk结构体的指针LS。3. 代码中的注释解释了每一行的作用:
LS = (LkStk*)malloc(sizeof(LkStk));使用malloc动态分配内存空间,将指针LS指向新的栈顶节点。LS->next = NULL;将栈顶节点的指针 next赋值为NULL,表示链式栈为空。4. 该函数的目的是初始化链式栈。
5. 通过动态分配内存空间,创建一个栈顶节点,并将其指针指向
NULL,表示链式栈为空。6. 需要注意的是,由于参数是指针,我们在函数内部修改指针的值并不会影响到调用函数时传入的实参。
7. 所以,如果希望在调用函数后能够访问到新分配的栈顶节点,建议将函数参数改为双重指针,或者返回新分配的栈顶节点指针。
Ⅱ. 判栈空
【示例代码】
【代码详解】
1. 这段代码实现了一个判断链式栈是否为空的函数
EmptyStack。2. 函数的参数是一个指向
LkStk结构体的指针 LS。3. 代码中的注释解释了每一行的作用:
if (LS->next == NULL)判断栈顶节点的指针 next是否为空,即链式栈是否为空。return 1;如果栈为空,返回 1,表示栈为空。return 0;如果栈不为空,返回 0,表示栈不为空。4. 该函数的目的是判断链式栈是否为空。
5. 通过判断栈顶节点的指针是否为空,来确定链式栈的状态。
6. 如果栈顶节点的指针为空,则表示栈为空;否则,表示栈不为空。
7. 返回值 1 表示栈为空,返回值 0 表示栈不为空。
Ⅲ. 进栈
【定义】进栈 —— 在栈顶插入一元素 x
- 生成新结点(链栈不会有上溢情况发生)
- 将新结点插入链栈中并使之成为新的栈顶结点
【示例代码】
【示意图】
【代码详解】
1. 这段代码实现了一个将元素入栈的函数
Push。2. 函数的参数包括一个指向
LkStk结构体的指针 LS和一个 DataType类型的元素x,表示要入栈的元素。3. 代码中的注释解释了每一行的作用:
LkStk* temp;定义一个临时指针变量temp,用于指向新创建的节点。temp = (LkStk*)malloc(sizeof(LkStk));使用 malloc动态分配内存空间,创建一个新的节点。temp->data = x;将要入栈的元素 x赋值给新节点的数据域。temp->next = LS->next;将新节点的 next指针指向原来栈顶节点的 next指针,实现链式结构的连接。LS->next = temp;将栈顶指针 LS->next指向新节点,使新节点成为新的栈顶节点。4. 该函数的目的是将元素
x入栈。5. 首先创建一个新的节点,并将元素赋值给新节点的数据域。
6. 然后将新节点的
next指针指向原栈顶节点的 next指针,再将栈顶指针指向新节点,实现入栈操作。
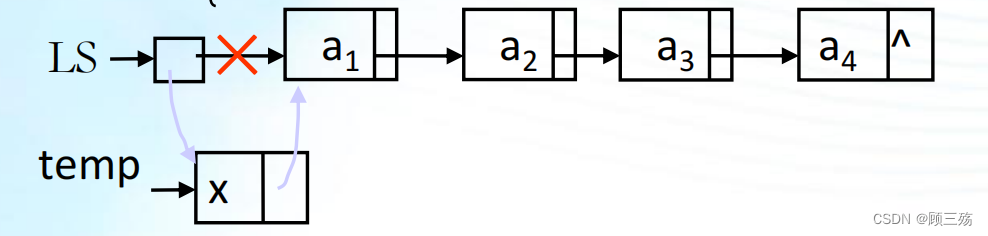
Ⅳ. 出栈
【定义】出栈 —— 在栈顶删除一元素,并返回
- 考虑下溢问题
- 不下溢,则取出栈顶元素,从链栈中删除栈顶结点并将结点回归系统
【示例代码】
【示意图】
【代码详解】
1. 这段代码实现了一个将元素出栈的函数
Pop。2. 函数的参数是一个指向
LkStk结构体的指针LS,用于表示要操作的链式栈。3. 代码中的注释解释了每一行的作用:
LkStk* temp;定义一个临时指针变量temp,用于指向当前栈顶节点。if (!EmptyStack(LS))判断栈是否为空,使用EmptyStack()函数来辅助判断。temp = LS->next;将临时指针变量 temp指向栈顶节点。LS->next = temp->next;将栈顶指针指向栈顶节点的下一个节点,跳过当前栈顶节点。free(temp);释放当前栈顶节点的内存空间,即将其从链式栈中移除。return 1;返回 1 表示出栈成功。return 0;如果链式栈为空,返回 0 表示栈为空,无法进行出栈操作。4. 该函数的目的是实现元素的出栈操作。
5. 首先判断栈是否为空,如果不为空,则将栈顶指针指向栈顶节点的下一个节点,同时释放当前栈顶节点的内存空间。
6. 如果栈为空,则表示无法进行出栈操作。
7. 返回值 1 表示出栈成功,返回值 0 表示栈为空,无法进行出栈操作。

Ⅴ. 取栈顶元素
【示例代码】
【代码详解】
1. 这段代码实现了一个获取栈顶元素的函数
GetTop。2. 函数的参数是一个指向
LkStk结构体的指针LS,用于表示要操作的链式栈。3. 代码中的注释解释了每一行的作用:
if (!EmptyStack(LS))判断栈是否为空,使用 EmptyStack()函数来辅助判断。return LS->next->data;如果栈不为空,返回栈顶节点的数据域值。return NULLData;如果栈为空,返回空数据(NULLData),即表示栈中没有元素。4. 该函数的目的是获取栈顶元素的值,而不对栈进行修改。
5. 首先判断栈是否为空,如果不为空,返回栈顶节点的数据域值;如果栈为空,返回空数据(
NULLData)表示栈中没有元素。
(4)栈的应用和递归
① 栈的基本应用实例
【示例一】 设栈的输入序列依次为 1,2,3,4,则所得的输出序列哪个符合?
【题目解析】正确答案:d
- 栈是一种遵循 “后进先出”(Last In First Out, LIFO)原则的数据结构,所以当我们按顺序依次将元素 1、2、3、4 入栈,得到的输出序列只能是
d 3,4,2,1。- 其他选项(a 1,2,3,4;b 4,2,3,1;c 1,3,2,4)都不可能是栈的输出序列。
- 选项 d 3,4,2,1 是唯一符合栈的特性,并且与输入序列为 1,2,3,4 的情况相对应的输出序列。
【答案详解】
- 选项 a 1,2,3,4:栈会按照后进先出的原则输出元素,所以输出序列会是 4,3,2,1,与所给选项不符。
- 选项 b 4,2,3,1:栈会先输出最后入栈的元素,所以输出序列会是 4,3,2,1,与所给选项不符。
- 选项 c 1,3,2,4:栈会输出元素 4 之前,需要先输出元素 3,而选项 c 给出的序列是 1,3,与栈的特性不符。
- 选项 d 3,4,2,1:栈是一种后进先出(LIFO)的数据结构,元素的出栈顺序与入栈顺序相反。根据题目中的输入序列为 1,2,3,4,按照栈的特性,元素 4 首先入栈,然后是元素3,接着是元素 2,最后是元素 1。因此,栈中的顺序是 4,3,2,1。对应选项 d 的输出序列 3,4,2,1 也与栈的特性一致,首先出栈的是元素 3,然后是元素 4,接着是元素 2,最后出栈的是元素 1。所以选项 d 是符合栈的规则并与输入序列一致的正确输出序列。

【示例二】顺序栈的操作
【示例代码】
【代码详解】
1. 代码的功能是创建一个顺序栈,并进行初始化,然后将字符 ‘A’ 到 ‘K’ 依次入栈,接着打印入栈的字符,最后依次出栈并打印出栈的字符。
2. 详解如下:
const int maxsize = 50;定义一个常量maxsize,表示栈的最大大小。typedef struct seqstack定义一个新的数据类型seqstk,表示顺序栈。char data[maxsize];在seqstk结构体中定义一个字符数组data,用于存储栈中的元素。int top;在seqstk结构体中定义一个整型变量top,表示栈顶指针的位置。int main()主函数入口。seqstk stk;声明一个seqstk类型的变量stk,用于表示顺序栈。Initstack(&stk);调用函数Initstack()初始化栈stk。for (ch = 'A'; ch <= 'A' + 10; ch++)循环,将字符 ‘A’ 到 ‘A’ + 10 依次入栈。Push(&stk, ch);调用函数Push()将字符ch压入栈stk。printf("%c", ch);打印字符ch。while (!Emptystack(&stk))当栈不为空时执行循环。ch = GetTop(&stk);调用函数GetTop()获取栈顶元素,并赋值给变量ch。Pop(&stk);调用函数Pop()弹出栈顶元素。printf("%c", ch);打印变量ch的值。return 0;返回主函数执行成功的标志。3. 总结起来,该代码的功能是创建一个顺序栈,将一系列字符依次入栈并打印出来,然后将栈中的元素依次出栈并打印出来,最终输出的结果是 “ABCDEFGHIJK”。
【执行结果】
- 在执行过程中,首先将字符 ‘A’ 到 ‘K’ 依次入栈,所以第一行输出为 “ABCDEFGHIJK”。
- 然后,在每次循环中,将栈顶元素出栈并打印出来,直到栈为空。
- 因此,第二行输出为 “KJIHGFEDCBA”,它是字符 ‘K’ 到 ‘A’ 的逆序。
【示例三】写一个算法,借助栈将下图所示的带头结点的单链表逆置。
【示例代码】
【代码详解】
1. 这段代码的功能是实现链表的反转操作,具体实现步骤如下:
- 声明一个指向链栈的指针变量
S。- 声明一个临时变量
x,用于存储链表节点的数据。- 初始化链栈
S。- 将指针
p指向链表的第一个节点。- 遍历链表,将节点的数据入栈。
- 重新将指针
p指向链表的第一个节点。- 遍历栈,依次将栈顶元素赋值给链表节点的数据,并弹出栈顶元素。
- 将指针
p指向下一个节点,即向后遍历链表。- 完成链表的反转操作。
2. 详解如下:
void ReverseList(LkStk *head)函数名称为ReverseList,参数为指向链表头节点的指针head,表示对链表进行反转操作。Lkstk *S;声明一个Lkstk类型的指针变量S,表示链栈的指针。DataType x;声明一个数据类型为DataType的变量x,用于临时存储链表节点的数据。InitStack(S);调用函数InitStack()对链栈S进行初始化。p = head->next;将指针p指向链表的第一个节点。while (p != NULL)当指针p不为空时执行循环。Push(s, p->data);调用函数Push()将链表节点的数据入栈。p = p->next;将指针p指向链表的下一个节点,即向后遍历链表。p = head->next;重新将指针p指向链表的第一个节点。while (!EmptyStack(S))当链栈S不为空时执行循环。p->data = GetTop(S);将栈顶元素赋值给链表节点的数据。Pop(S);调用函数Pop()弹出栈顶元素。p = p->next;将指针p指向链表的下一个节点,即向后遍历链表。3. 总结起来,该函数通过借助一个链栈和临时变量,将链表节点的数据先入栈后出栈的方式实现链表的反转。

② 递归的定义
如果一个函数在完成之前又调用自身,则称之为 递归函数 。
【示例】求整数 n 的阶乘函数:
【示例代码】
【代码详解】
int f(int n)函数名称为f,参数为整数n,表示计算阶乘的函数。if (n == 0)如果 n 等于 0,表示已经递归到最基本的情况,阶乘的结果是 1。return 1;返回结果 1。else如果 n 不等于 0,表示还需要继续递归计算阶乘。return n * f(n - 1);递归调用函数 f,传入 n-1,并将结果乘以 n 返回。递归调用的目的是计算 n 的阶乘等于 n 乘以 n-1 的阶乘。
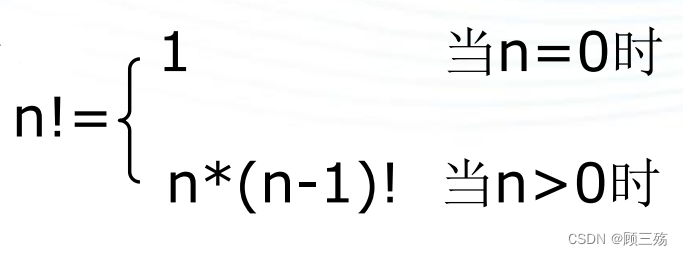
③ 递归的一般形式
- void fname(参数表)
- {
- if (数据作为递归出口)
- {
- // 简单操作
- }
- else
- {
- // 简单操作
- fname(参数表);
- // 简单操作
- // [fname(参数表); 简单操作;]
- // 可能有多次递归调用
- }
- }
【详解】以上是递归函数的一般形式,具体解释如下:
void fname(参数表):函数名称为fname,带有一组参数。if (数据作为递归出口):当满足某个条件时,数据作为递归的出口,即递归结束。// 简单操作:在递归出口时执行的简单操作。else:如果条件不满足,执行下面的操作。// 简单操作:在递归调用之前或之后执行的简单操作。fname(参数表):递归调用函数fname,并传入参数表。// 可能有多次递归调用:在递归调用之后,可能继续调用函数fname进行递归,可能会有多次递归调用。【注意】递归函数需要满足递归结束的条件,否则会进入无限递归导致程序崩溃。同时,递归函数需要考虑递归调用的顺序和终止条件的设置,确保递归能够正常结束。
二、队列
描述栈和队列实现的头文件如下:
- Seqstack.h:顺序栈的定义及其实现。
- Lkstack.h:链栈的定义及其实现。
- Sequeue.h:顺序队列定义及其实现。
- Lkqueue.h:链队列的定义及其实现。
(1)队列的基本概念
① 定义
队列(Queue):也是一种运算受限的线性表。
- 队列 —— 是只允许在表的一端进行插入,而在另一端进行删除的线性表。
- 允许删除的一端称为队头(front)
- 允许插入的另一端称为队尾(rear)
- 队列 Q=(a1,a2,a3,…an )
② 示意图

【示例】 排队购物
- 操作系统中的作业排队
- 先进入队列的成员总是先离开队列
- 因此队列亦称作先进先出(First In First Out)的线性表,简称 FIFO 表。
- 当队列中没有元素时称为空队列。
- 在空队列中依次加入元素 a1,a2,…an 之后,a1 是队头元素,an 是队尾元素。
- 显然退出队列的次序也只能是 a1,a2,…an ,也就是说队列的修改是依先进先出的原则进行的。
③ 队列的特点
先进先出(FIFO) :
队列的用途 —— 常用于暂时保存有待处理的数据。
④ 队列的基本操作
➢ 队列初始化 InitQueue(Q):
- 设置一个空队列 Q
➢ 判队列空 EmptyQueue(Q):
- 若队列 Q 为空,则返回值为 1,否则返回值为 0
➢ 入队列 EnQueue(Q,x):
- 将数据元素 x 从队尾一端插入队列,使其成为队列的新尾元素
➢ 出队列 OutQueue(Q):
- 删除队列首元素
➢ 取队列首元素 GetHead(Q):
- 返回队列首元素的值
(2)队列的顺序实现
① 顺序队列
【定义】 顺序队列 —— 只能从数组的一头插入、另一头删除。【说明】 SeqQue sq ;
- 上溢条件:sq.rear = = maxsize-1 ( 队满 )
- 下溢条件:sq.rear = = sq.front ( 队列空 )
【注意】 假溢出 :sq.rear == maxsize-1 ,但队列中实际容量并未达到最大容量的现象。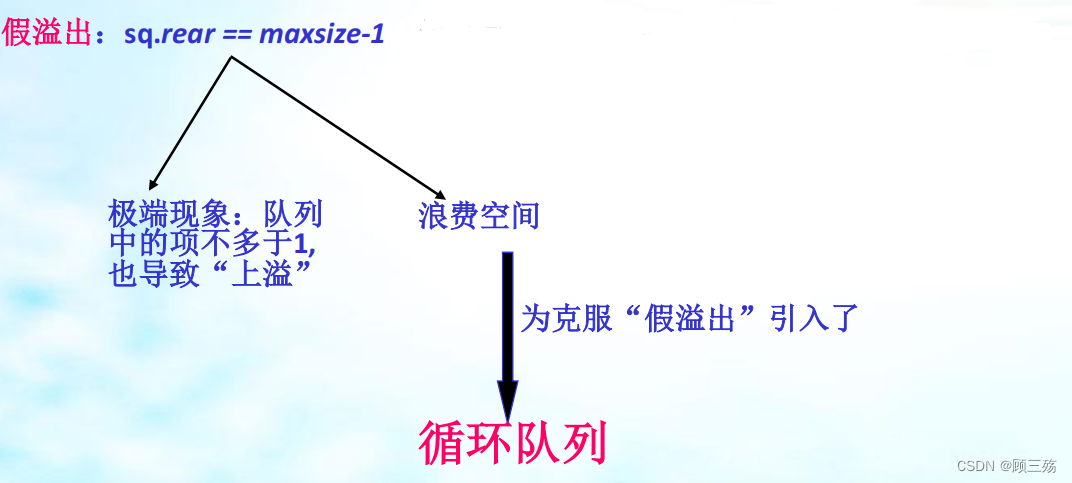
② 循环队列
【定义】 队列的顺序实现 —— 循环队列
- 用一维数组作为队列的存储结构
- 队列容量 —— 队列中可存放的最大元素个数
【示意图】

【约定】
- 初始: front=rear=0
- 进队: rear 增 1,元素插入尾指针所指位置
- 出队: front 增 1,取头指针所指位置元素
【说明】
- 队头指针 front —— 始终指向实际队头元素的前一位置
- 队尾指针 rear —— 始终指向实际队尾元素
➢ 入队列操作:
- sq.rear=sq.rear+1;
- sq.data[sq.rear]=x;
➢ 出队列操作:
- sq.front=sq.front+1;
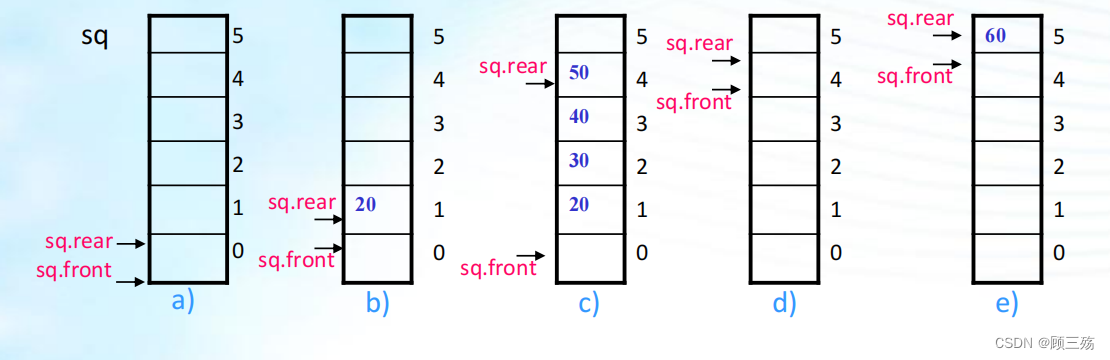
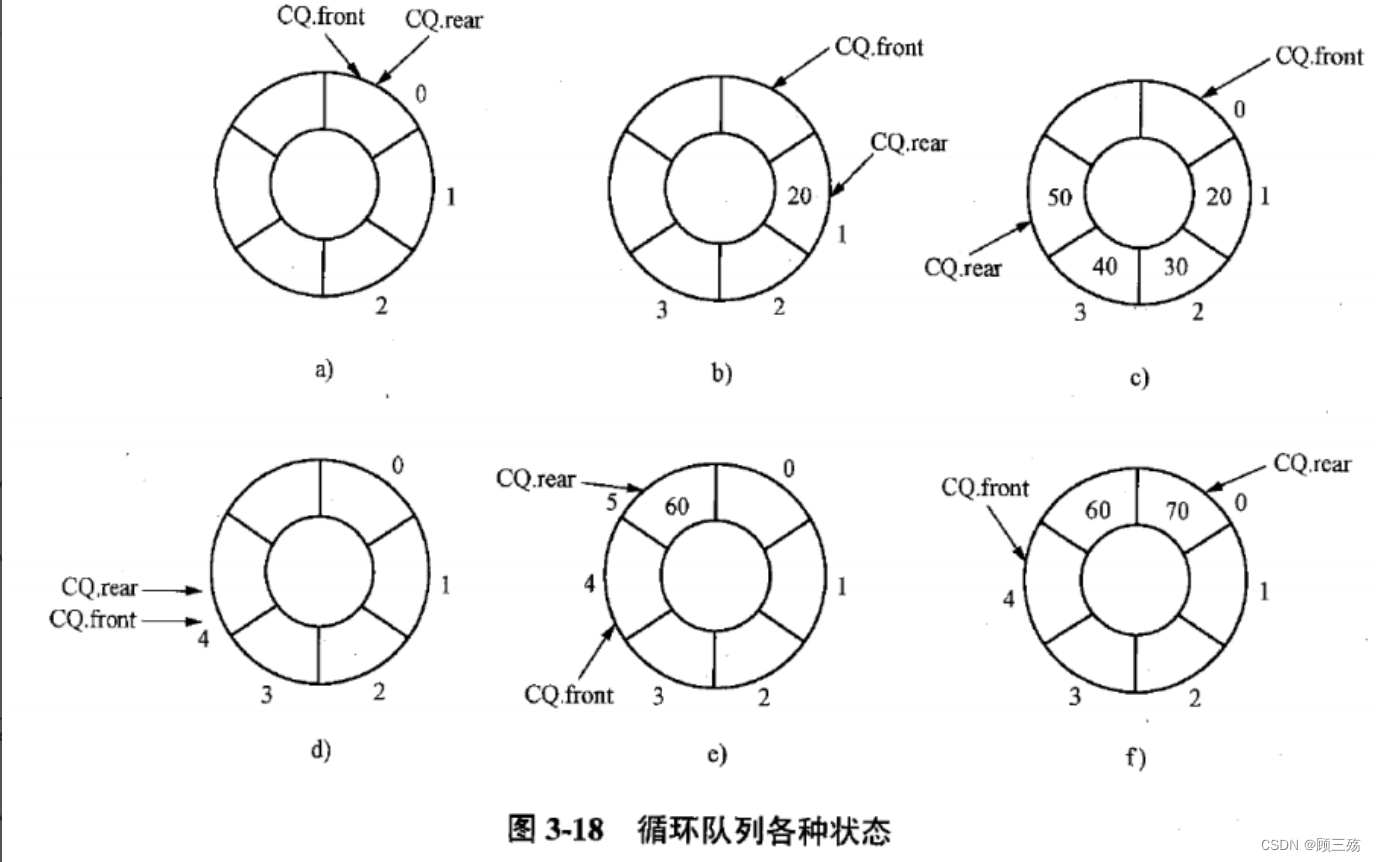
- 图 a 为空队列,sq.rear=0,sq.front=0。
- 图 b 为 20 入队列后,sq.rear=1,sq.front=0。
- 图 c 为 30,40,50 依次入队列后,sq.rear=4,sq.front=0。
- 图 d 为 20,30,40,50 依次出队列后,sq.rear=4,sq.front=4。
- 图 e 为 60 入队列后,sq.rear=5,sq.front=4。
【示例代码】
1. 以下是对每行代码的注释解释:
const int maxsize = 20;定义了一个常量maxsize,表示队列的最大容量为20。typedef struct seqqueue定义了一个名为seqqueue的结构体类型。DataType data[maxsize];在seqqueue结构体中定义了一个数组data,用于存储队列中的元素。该数组的大小为maxsize。int front, rear;在seqqueue结构体中定义了两个整型变量front和rear,分别表示队头指针和队尾指针。SeqQue sq;声明了一个顺序队列变量sq,类型为SeqQue。2. 这段代码定义了一个顺序队列的数据结构
SeqQue,它包含一个固定大小的数组data和两个指示队头和队尾位置的指针front和rear。3. 通过声明
sq变量,我们可以使用SeqQue结构体来创建顺序队列对象。
Ⅰ. 循环队列的定义
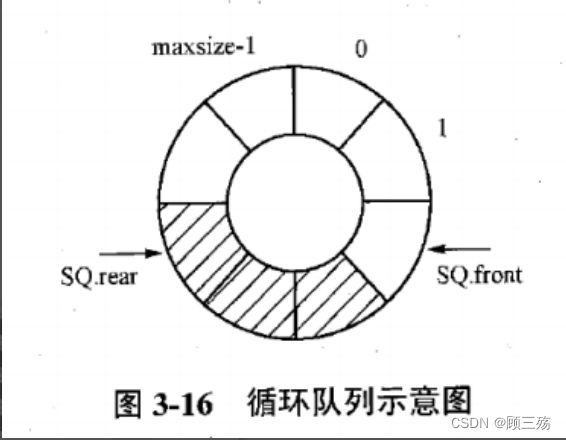
【定义】 循环队列 —— 为队列分配一块存储空间 ( 数组表示 ) ,并将 这一块存储空间看成头尾相连接的。【示意图】
 【注意】
【注意】
- 头指针 front —— 顺时针方向落后于实际队头元素一个位置
- 尾指针 rear —— 指向实际队尾元素
Ⅱ. 循环队列循环的实现
➢ 对插入即入队: 队尾指针增 1Sq.rear=(sq.rear+1)%maxsize➢ 对删除即出队:队头指针增 1
Sq.front=(sq.front+1)%maxsize
Ⅲ. 循环队列的类型定义
【示例代码】
【代码详解】
typedef struct Cycqueue表示定义一个结构体类型Cycqueue。{}在大括号内定义结构体的成员。DataType data[maxsize];声明一个名为data的数组,用于存储数据,数组大小为maxsize。int front, rear;声明两个整型变量front和rear,分别表示循环队列的队头和队尾指针。} CycQue;表示结构体类型定义结束,并将其重命名为CycQue。CycQue CQ;声明一个循环队列实例CQ,使用上面定义的结构体类型。
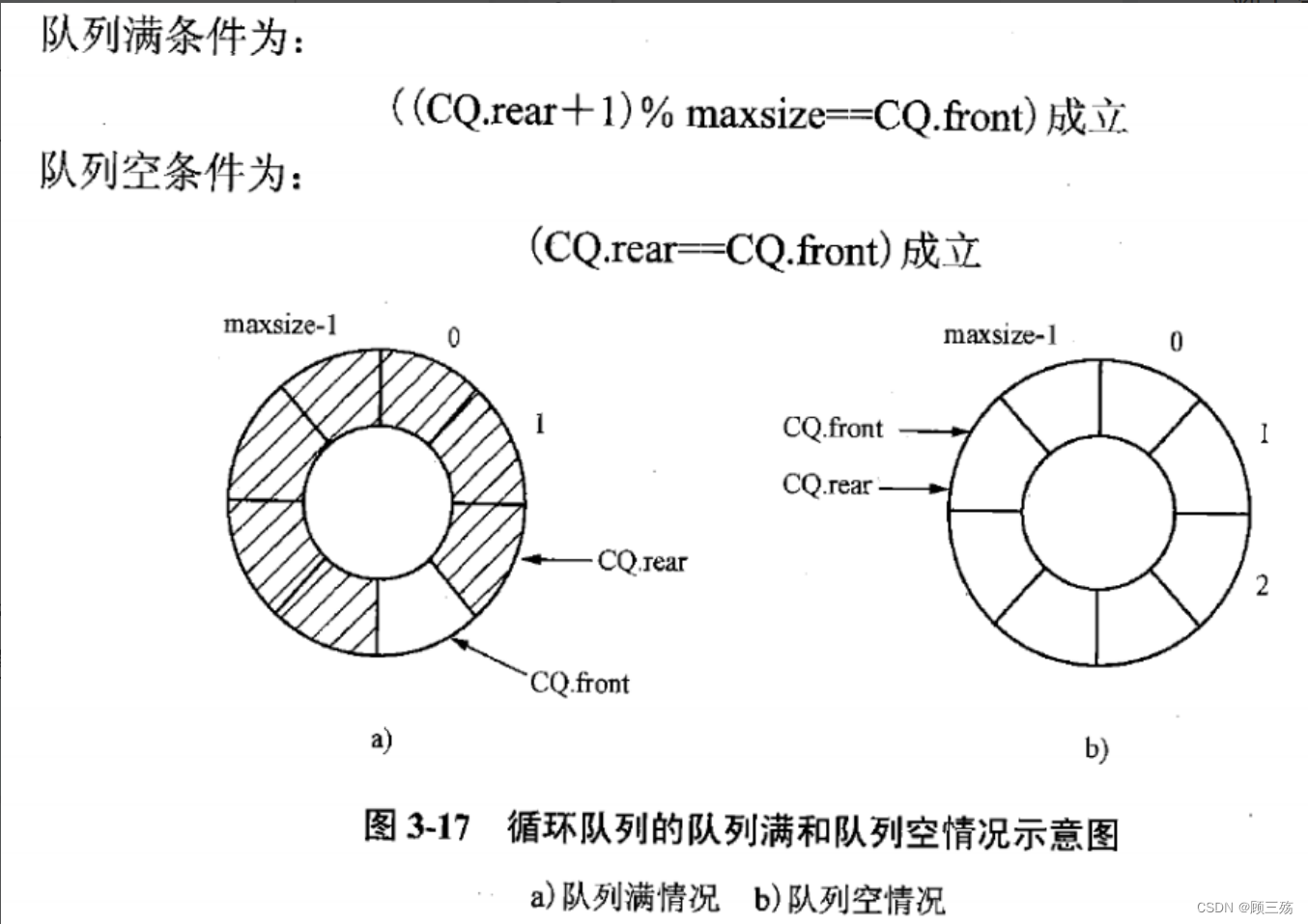
Ⅳ. 规定
循环队列 CQ
- 下溢条件即队列空: CQ.front==CQ.rear
- 上溢条件即队列满: 尾指针从后面追上头指针
即: (CQ.rear+1)%maxsize==CQ.front ( 尾赶头 )
- 浪费一个空间,队满时实际队容量 = maxsize-1
③ 循环队列的基本运算
Ⅰ. 初始化
【示例代码】
【代码详解】
1. 该函数用于初始化循环队列,将队头和队尾指针都置为 0,表示队列为空。
2. 详细解释如下:
void InitQueue(CycQue CQ)表示定义一个函数InitQueue,参数为循环队列CQ。CQ.front = 0;将循环队列的队头指针front初始化为 0,表示队列为空。CQ.rear = 0;将循环队列的队尾指针rear初始化为 0,表示队列为空。
Ⅱ. 判队列空
【示例代码】
【代码详解】
1. 该函数用于判断循环队列是否为空。
2. 当队尾指针等于队头指针时,表示队列为空;否则,表示队列不为空。
3. 返回值为 1 表示队列为空,返回值为 0 表示队列不为空。
4. 详细解释如下:
int EmptyQueue(CycQue CQ)表示定义一个函数EmptyQueue,参数为循环队列CQ。if (CQ.rear == CQ.front)判断队尾指针rear是否等于队头指针front。return 1;如果队尾指针等于队头指针,说明队列为空,返回 1。return 0;如果队尾指针不等于队头指针,说明队列不为空,返回 0。
Ⅲ. 入队列
【定义】入队 —— 在队尾插入一新元素 x
- 判上溢否?是,则上溢返回;
- 否则修改队尾指针(增 1),新元素 x 插入队尾。
【示例代码】
【代码详解】
1. 这段代码实现了在循环队列中插入元素的操作。
2. 详细解释如下:
CycQue是循环队列的结构体类型。DataType是队列中元素的数据类型。maxsize是队列的最大容量。3. 在函数中,我们首先判断队列是否已满,这通过以下条件判断:
(CQ.rear + 1) % maxsize == CQ.front。如果条件成立,则说明队列已满,此时会输出错误信息并返回0。4. 如果队列未满,则会执行
else后面的语句。首先,将队尾指针向后移动一个位置:CQ.rear = (CQ.rear + 1) % maxsize。然后,将元素x插入到队尾:CQ.data[CQ.rear] = x。最后,函数返回 1 表示插入成功。5. 注意,这里的
CQ参数是按值传递,所以在函数内部修改 CQ.rear和 CQ.data不会影响到外部。如果要在函数内部修改外部的结构体,应该使用指针或引用作为函数参数。
Ⅳ. 出队列
【定义】出队 —— 删除队头元素,并返回
- 判下溢否?是,则下溢返回;
- 不下溢,则修改队头指针,取队头元素。
【示例代码】
【代码详解】
1. 代码的功能是从循环队列中取出元素。
2. 详细解释如下:
CycQue是循环队列的结构体类型。maxsize是队列的最大容量。3. 在函数中,我们首先判断队列是否为空,这通过调用函数
EmptyQueue(CQ)来判断。如果队列为空,会输出错误信息并返回 0。4. 如果队列不为空,将执行
else后面的语句。首先,将队头指针向后移动一个位置:CQ.front = (CQ.front + 1) % maxsize。然后,函数返回 1 表示取出元素成功。5. 请注意,与前面的
EnQueue()函数一样,这里的 CQ参数也是按值传递的,所以在函数内部修改 CQ.front不会影响到外部。如果要在函数内部修改外部的结构体,应该使用指针或引用作为函数参数。
Ⅴ. 取队列首元素
【示例代码】
【代码详解】
1. 代码的功能是获取循环队列的队头元素。
2. 详细解释如下:
DataType是队列中元素的数据类型。CycQue是循环队列的结构体类型。maxsize是队列的最大容量。NULLData是表示空数据的特定值。3. 在函数中,我们首先判断队列是否为空,这通过调用函数
EmptyQueue(CQ)来判断。如果队列为空,则直接返回空数据NULLData。4. 如果队列不为空,则执行
else后面的语句。这里使用(CQ.front + 1) % maxsize来计算队头的下一个位置,并返回该位置上的元素CQ.data[(CQ.front + 1) % maxsize]。5. 请注意,与之前的函数一样,这里的
CQ参数也是按值传递的,所以在函数内部修改CQ.front不会影响到外部。如果要在函数内部修改外部的结构体,应该使用指针或引用作为函数参数。另外,请根据实际情况在代码中定义并初始化NULLData。
(3)队列的链接实现
① 链式队列的定义
【定义】 链式队列 —— 用链表表示的队列,即它是限制仅 在 表头删除 和 表尾插入 的单链表。【示意图】 【说明】显然仅有单链表的头指针不便于在表尾做插入操作,为此再增加一个尾指针,指向链表的最后一个结点。【注意】 附设两指针:
【说明】显然仅有单链表的头指针不便于在表尾做插入操作,为此再增加一个尾指针,指向链表的最后一个结点。【注意】 附设两指针:
- 头指针 front —— 指向表头结点;队头元素结点为 front->next
- 尾指针 rear —— 指向链表的最后一个结点(即队尾结点)
② 链队列类型说明
【说明】 可将队头和队尾这两个指针封装在一起,将链队列的类型定义为一个结构类型【示例代码】
【代码详解】
1. 代码定义了链式队列的结构体类型并创建了队列实例。
2. 下面是对代码的注释解释:
DataType是队列中元素的数据类型。3. 定义链式队列结点的结构体类型
LinkQueueNode:
data是结点中存储的数据。next是指向下一个结点的指针。4. 定义链式队列的结构体类型
LkQueue:
front是队头指针,指向队列中的第一个结点。rear是队尾指针,指向队列中的最后一个结点。
5.LkQue LQ;创建了一个链式队列的实例LQ,用于操作链式队列的相关操作。请注意,以上代码中使用了
typedef关键字来定义了新的类型名LkQueNode和LkQue,方便后续使用。【注意】
- LQ.front —— 链式队的队头指针
- LQ.rear —— 链式队的队尾指针
- 链式队的上溢:可不考虑;(因动态申请空间)
- 链式队的下溢:即链式队为空时,还要求出队;
➢ 此时链表中无实在结点:
➢ 规定:
- 链队列空时,令 rear 指针也指向表头结点。
➢ 链队列下溢条件:
- LQ.front->next==NULL
- 或:LQ. front==LQ. rear;

③ 链队列的基本运算
Ⅰ. 初始化
【示例代码】
【示意图】
【代码详解】
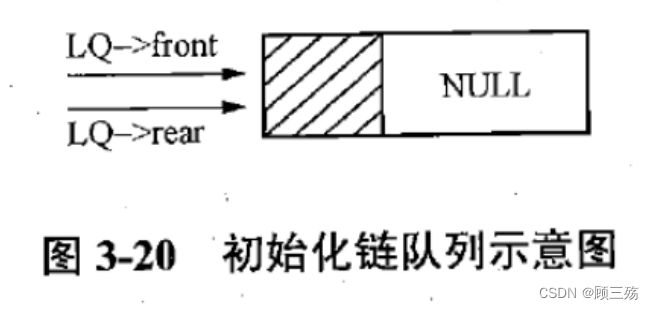
1. 代码的功能是初始化链式队列。
2. 以下是对每行代码的注释解释:
LkQue* LQ:传入的链式队列指针参数,用于操作相关的队列。LkQueNode* temp:创建一个临时的链式队列结点指针。3. 在函数中,我们首先使用
malloc函数为临时结点temp分配内存,以便存储链式队列结点。sizeof(LkQueNode)用于指定要分配的内存大小。然后,将队头指针
LQ->front和队尾指针LQ->rear都设置为指向临时结点temp,这样初始时队列中只有这一个结点。4. 最后,将临时结点的下一个结点指针
(LQ->front)->next设置为NULL,表示该结点没有后继结点。5. 这样,初始化队列的操作就完成了。
Ⅱ. 判队列空
【示例代码】
【代码详解】
1. 代码的功能是判断链式队列是否为空。
2. 以下是对每行代码的注释解释:
int:函数返回类型为整型,表示队列是否为空。LkQue LQ:传入的链式队列结构体参数,用于判断队列是否为空。3. 在函数中,我们首先通过判断队尾指针
LQ.rear是否与队头指针LQ.front相同来确定队列是否为空。如果相同则表示队列为空,因为队列中没有元素。4. 如果队尾指针和队头指针不相同,则表示队列非空。
5. 最后,函数返回 1 表示队列为空,返回 0 表示队列非空。
6. 这样,判断队列是否为空的操作就完成了。
Ⅲ. 入队列
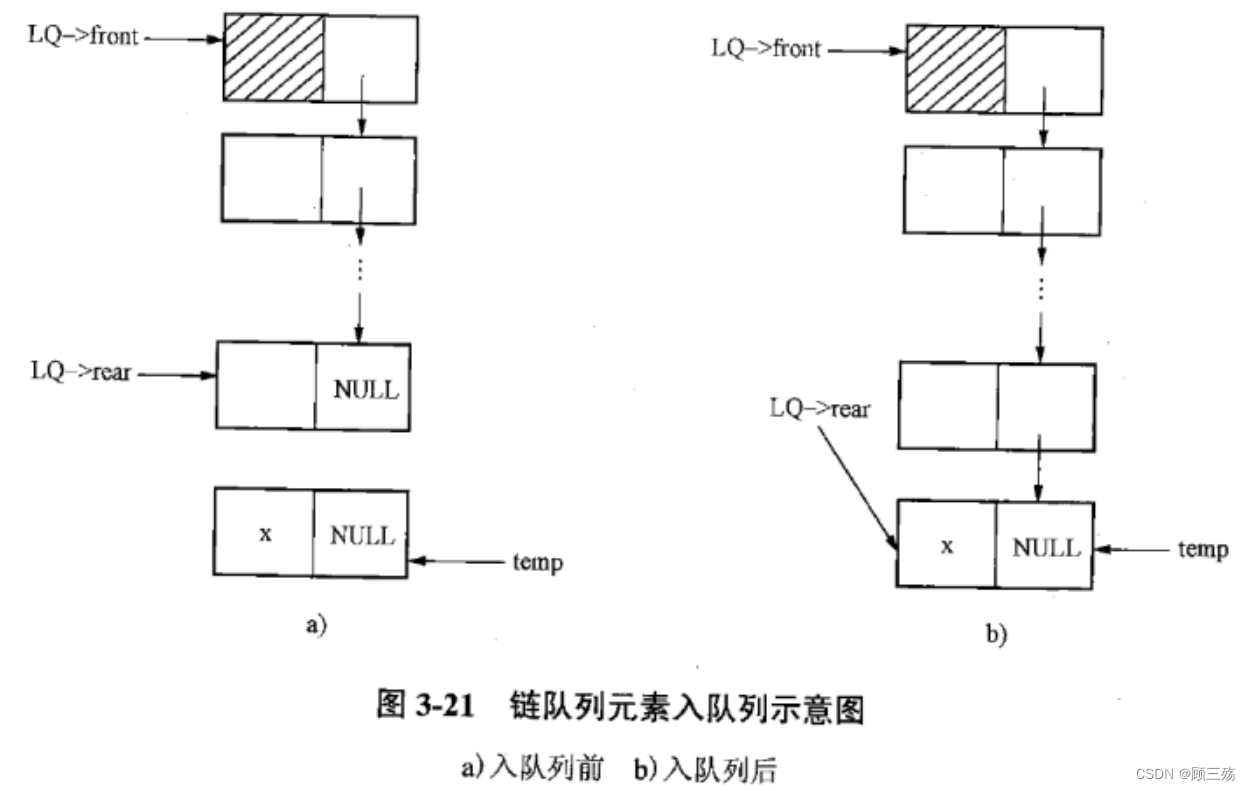
【定义】入队 —— 在队尾即链表尾部插入一元素 x
【示意图】
【示例代码】
【代码详解】
1. 代码的功能是实现链式队列的入队操作。
2. 以下是对每行代码的注释解释:
LkQue* LQ:传入的链式队列指针参数,用于操作相关的队列。DataType x:入队的数据。3. 在函数中,我们首先使用
malloc函数为新结点temp分配内存,以便存储数据。sizeof(LkQueNode)用于指定要分配的内存大小。4. 然后,我们将新结点
temp的数据设置为参数x,表示新加入队列的数据。接下来,将临时结点的下一个结点指针
(LQ->rear)->next设置为temp,将新结点添加到队尾结点的后面。5. 最后,更新队尾指针
LQ->rear,将其指向新的队尾结点temp。6. 这样,入队操作就完成了。

Ⅳ. 出队列
【定义】出队 —— 在链式队中删除队头元素,并送至 e 中
- 考虑下溢否
- 不下溢,则:
- 取队头结点temp;
- 送队头元素至x;
- 从链式队中删除队头结点;
- 若链式队中原只有一个元素,则删除后队列为空,应修改队尾指针;
- 结点temp回归系统。
【示意图】
【示例代码】
【代码详解】
1. 代码的功能是实现链式队列的出队操作。
2. 以下是对每行代码的注释解释:
LkQue* LQ:传入的链式队列指针参数,用于操作相关的队列。3. 在函数中,我们首先判断队列是否为空,通过调用
EmptyQueue(*LQ)函数来判断。如果为空,则输出错误提示信息"队空",并返回 0 表示出队失败。4. 如果队列非空,则执行出队操作。
5. 我们首先将临时结点指针
temp指向队头结点的下一个结点,即要出队的结点。6. 然后,将队头结点的下一个结点指针
(LQ->front)->next设置为temp->next,即将队头指针指向出队结点的下一个结点。7. 接着,我们检查出队操作后队列是否为空,通过判断
temp->next是否为NULL来确定。如果是,则表示出队后队列为空,需要更新队尾指针LQ->rear为队头指针LQ->front。8. 最后,使用
free函数释放掉出队的结点空间,防止内存泄漏。9. 函数返回 1 表示出队成功。这样,出队操作就完成了。


Ⅴ. 取队列首元素
【示例代码】
【代码详解】
1. 代码的功能是获取链式队列的队头元素的值。
2. 以下是对每行代码的注释解释:
DataType GetHead(LkQue LQ):获取队头元素的值,返回值类型为DataType。LkQue LQ:传入的链式队列参数,用于获取队头元素。3. 在函数中,我们首先判断队列是否为空,通过调用
EmptyQueue(LQ)函数来判断。如果队列为空,则直接返回空数据NULLData。4. 如果队列非空,则执行获取队头元素的操作。
5. 我们首先将临时结点指针
temp指向队头结点的下一个结点,即要获取的队头元素。6. 然后,返回队头结点的数据
temp->data。7. 这样,获取队头元素的值的操作就完成了。
三、数组
数组:可看成是一种特殊的线性表,其特殊在于,表中的数组元 素本身也是一种线性表。
(1)数组的逻辑结构和基本运算
【定义】数组 —— 是线性表的推广,其每个元素由一个值和一组下标组成,其中下标个数称为数组的维数。
- 数组是我们最熟悉的数据类型,在早期的高级语言中,数组是唯一可供使用的数据类型。
- 由于数组中各元素具有统一的类型,并且数组元素的下标一般具有固定的上界和下界,因此,数组的处理比其它复杂的结构更为简单。
- 多维数组是线性表的推广。
【注意】 数组一旦被定义,它的维数和维界就不再改变。因 此,除了结构的初始化和销毁之外,数组通常只有两种基本运算:
- 读 —— 给定一组下标,读取相应的数据元素
- 写 —— 给定一组下标,修改相应的数据元素
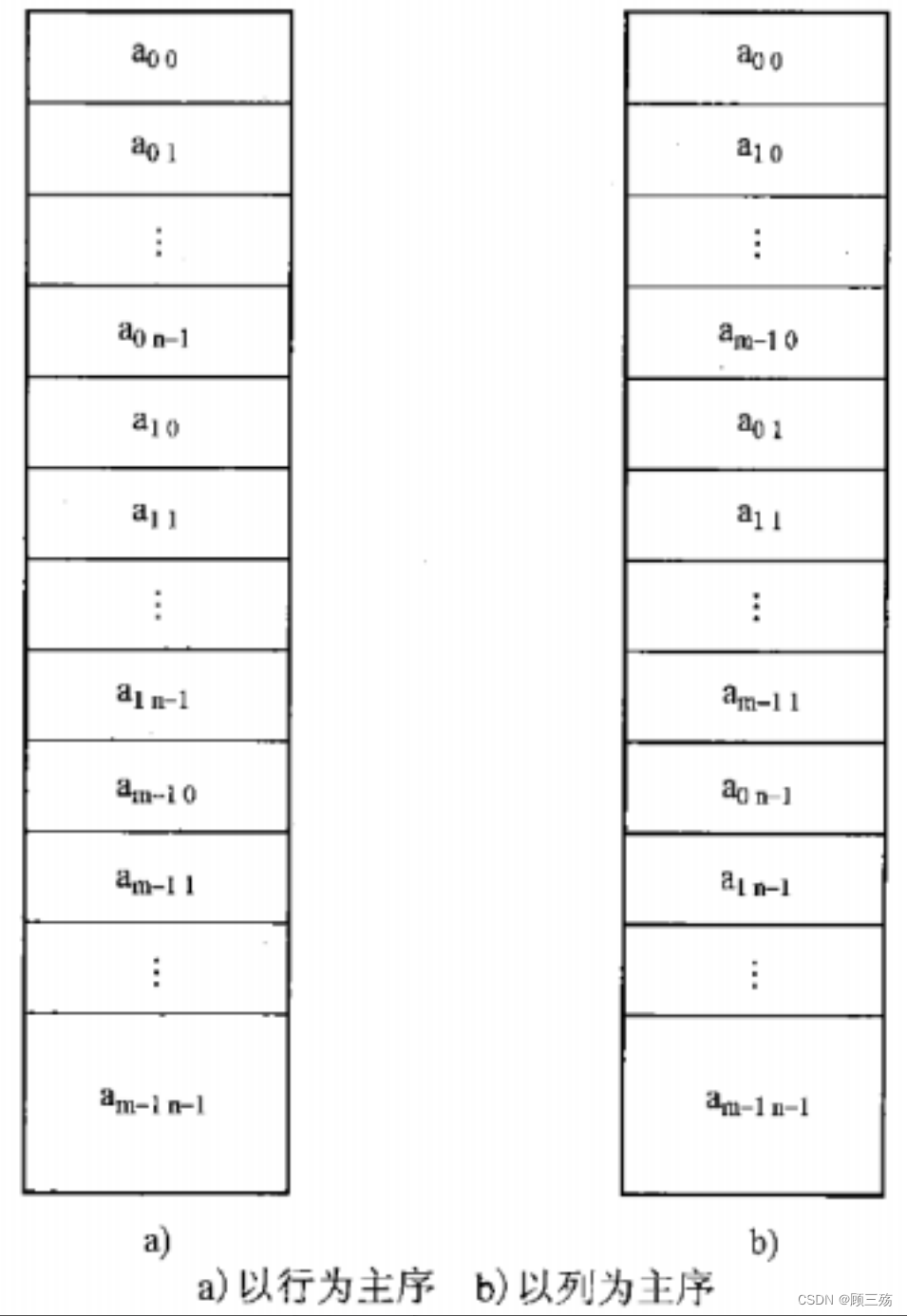
【二维数组】二维数组:二维数组 Amn 可以看成是由 m 个行向量组成的向量,也可以看成是 n 个列向量组成的向量。
【示意图】

(2)数组的存储结构
① 存储结构 —— 顺序存储结构
- 由于计算机的内存结构是一维的,因此用一维内存来表示多维数组,就必须按某种次序将数组元素排成一列序列,然后将这个线性序列存放在存储器中。
- 又由于对数组一般不做插入和删除操作,也就是说,数组一旦建立,结构中的元素个数和元素间的关系就不再发生变化。因此,一般都是采用顺序存储的方法来表示数组。
② 寻址公式(以行为主存放)
二维数组 Amn 按 “行优先顺序” 存储在内存中,假设 每个元素占用 k 个存储单元 :
- 元素 aij 的存储地址应是数组的基地址加上排在 aij 前面的元素所占用的单元数。
- 因为 aij 位于第 i 行、第 j 列,前面 i 行一共有 i×n 个元素,第 i 行上 aij 前面又有 j 个元素,故它前面一共有 i×n+j 个元素,因此,aij 的地址计算函数为:
LOC(aij)=LOC(a00)+(i*n+j)*k
(3)矩阵的压缩存储
为了 节省存储空间 , 我们可以对这类矩阵进行 压缩存储 : 即为多个相 同的非零元素只分配一个存储空间;对零元素不分配空间 。
① 特殊矩阵
特殊矩阵 —— 即 指非零元素或零元素的分布有一定规律 的矩阵 。
几种特殊矩阵的压缩存储:
- 对称矩阵
- 三角矩阵
- 稀疏矩阵
② 特殊矩阵:对称矩阵
Ⅰ. 定义
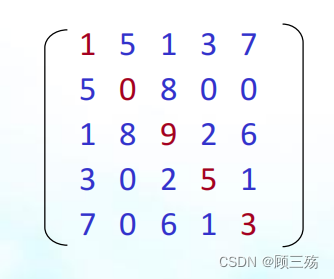
【定义】 在一个 n 阶方阵 A 中,若元素满足下述性质,则称 A 为对称矩阵:
- aij=aji
- 0≤i
- j≤n-1
【示例】如下图便是一个 5 阶对称矩阵:
Ⅱ. 物理存储
- 对称矩阵中的元素关于主对角线对称,故只要存储矩阵中上三角或下三角中的元素,让每两个对称的元素共享一个存储空间,这样,能节约近一半的存储空间。
- 不失一般性,我们按 “行优先顺序” 存储主对角线(包括对角线)以下的元素,其存储形式如图所示:
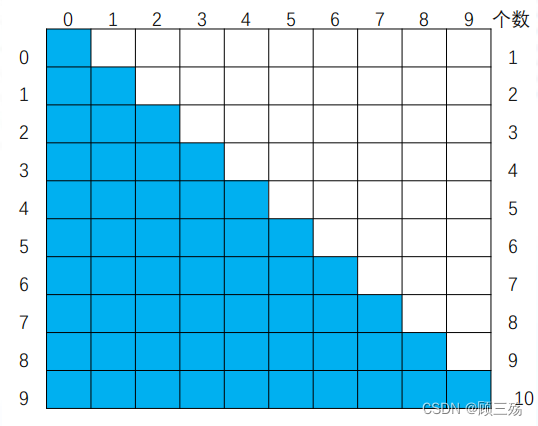
- 在这个下三角矩阵中,第 i 行恰有 i 个元素,元素总数为:
∑(i)=n(n+1)/2- 因此,我们可以按图中箭头所指的次序将这些元素存放在一个一维数组 S[0..n(n+1)/2-1] 中。
- 为了便于访问对称矩阵 A 中的元素,我们必须在 aij 和 S[k] 之间找一个对应关系。
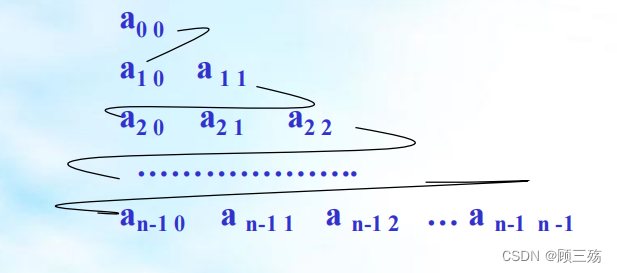
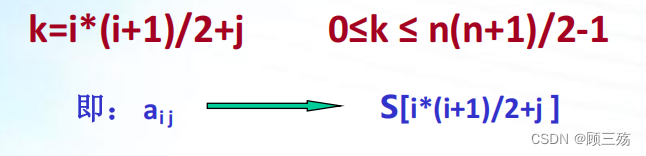
下标变换公式:(以下三角表示)
- 若 i≥j,则 aij 在下三角形中:aij 之前的 i 行(从第 0 行到第 i-1 行)一共有 1+2+…+i=i(i+1)/2 个元素,在第 i 行上, aij 之前恰有 j 个元素(即 ai0 ,ai1 ,ai2 ,ai3 ,…,ai j-1),因此有:
- 若 i<j,则 aij 是在上三角矩阵中:因为 aij=aji,所以只要交换上述对应关系式中的i和j即可得到:
- 有了上述的下标交换关系,对于任意给定一组下标 (i,j), 均可在 S[k] 中找到矩阵元素 aij,反之,对所有的 k=0,1,2,3,…n(n+1)/2-1,都能确定 S[k] 中的元素在矩阵中的位置 (i,j)。由此,称 S[n(n+1)/2] 为对称矩阵 A 的压缩存储,见下图:

- 例如 a31 和 a13 均存储在 sa[7] 中,这是因为:
k=i*(i+1)/2+j=3*(3+1)/2+1=7

③ 特殊矩阵:三角矩阵
Ⅰ. 定义
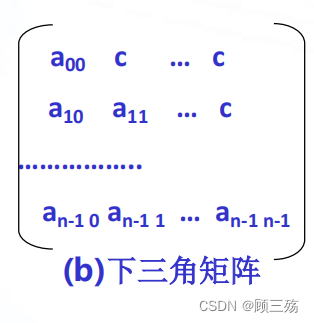
【定义】 以主对角线划分,三角矩阵有上三角和下三角两种:
- 上三角矩阵如图所示,它的下三角(不包括主对角线)中的元素均为常数。
- 下三角矩阵正好相反,它的主对角线上方均为常数,如图所示。
- 在大多数情况下,三角矩阵常数为零。
【示例】
【说明】
三角矩阵中的重复元素 c 可共享一个存储空间,其余的元素正好有 n(n+1)/2 个,因此,三角矩阵可压缩存储到向量 s[0..n(n+1)/2] 中,其中 c 存放在向量的最后一个分量中。

Ⅱ. 上三角矩阵
【说明】 上三角矩阵中 ,主对角线之上的第 p 行 (0≤p<n) 恰有 n-p 个 元素,按行优先顺序存放上三角矩阵中的元素 a ij 时,a ij 之前的 i 行一共有 (n-p)=i(2n-i+1)/2 个元素,在第 i 行上,a ij 前恰好有 j-i 个元素:a ij ,a ij+1 , … a ij-1 。【公式】因此,s[k] 和 aij 的对应关系是:

Ⅲ. 下三角矩阵
【公式】下三角矩阵的存储和对称矩阵类似,s[k] 和 aij 对应关系是:
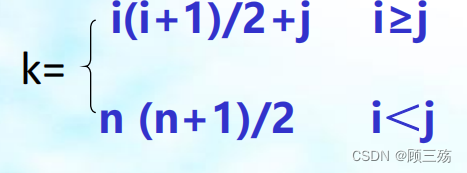
④ 特殊矩阵:稀疏矩阵
Ⅰ. 定义
稀疏矩阵:设矩阵 A 中有 s 个非零元素, 若 s 远远小于矩阵元素的总数,则称 A 为稀疏矩阵。
- 稀疏矩阵的压缩存储 —— 即只存储稀疏矩阵中的非零元素。
- 目的:节省存储空间。
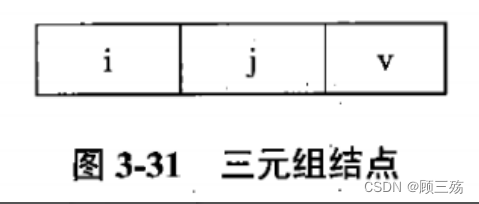
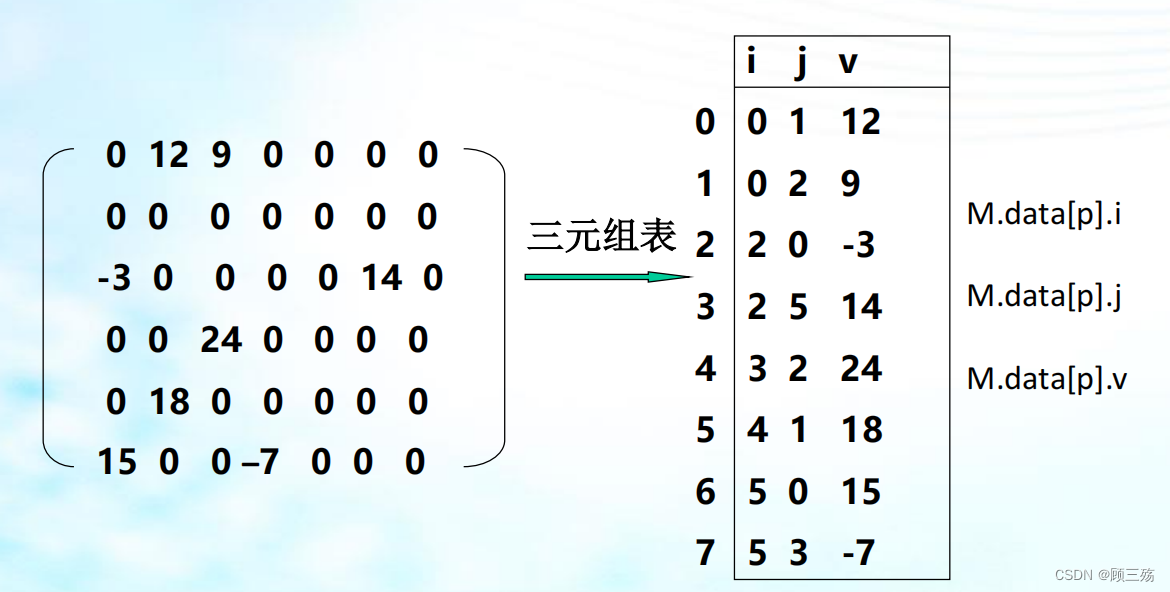
Ⅱ. 三元组
- 由于非零元素的分布一般是没有规律的,因此在存储非零元素的同时,还必须同时记下它所在的行和列的位置 (i,j)。
- 反之,一个三元组 (i,j,aij) 唯一确定了矩阵 A 的一个非零元。
- 因此,稀疏矩阵可由表示非零元的三元组及其行列数唯一确定。
Ⅲ. 三元组表
下列三元组表:
( (0,1,12),(0,2,9),(2,0,- 3),(2,5,14),(3,2,24), (4,1,18),(5,0,15),(5,3,-7) )
- 加上 (5,6) 这一对行、列值便可作为下列矩阵 M 的另一种描述。
- 而由上述三元组表的不同表示方法可引出稀疏矩阵不同的压缩存储方法。


Ⅳ. 三元组顺序表
【表示法】 稀疏矩阵的三元组顺序表表示法 —— 将矩阵中的非零元素化成三元组形式并按行的不减次序(同行按列的递增次序)存放在内存中。【三元组表结构】 三元组表结构: 假设以顺序存储结构来表示三元组表,则可得到稀疏矩阵的一种压缩存储方法 —— 三元组顺序表。【示例代码】 稀疏矩阵三元组表存储类型:
【示意图】设: SpMtrx M ; 则下图中所示的稀疏矩阵的三元组的表示如右:
 【代码详解】
【代码详解】1. 以下是对每行代码的注释解释:
const int maxnum = 10;定义了一个常量maxnum,表示非零元素的最大个数为10。typedef struct node定义了一个名为node的结构体类型。int i, j;在node结构体中定义了两个整型变量i和j,分别表示非零元的行下标和列下标。DataType v;在node结构体中定义了一个DataType类型的变量v,表示非零元素的值。NODE;定义了NODE类型,是一个三元组结构体。typedef struct spmatrix定义了一个名为spmatrix的结构体类型。NODE data[maxnum];在spmatrix结构体中定义了一个数组data,用于存储非零元的三元组表。数组的大小为maxnum,即最大非零元素个数。int mu, nu, tu;在spmatrix结构体中定义了三个整型变量mu、nu和tu,分别表示矩阵的行数、列数和非零元素个数。SpMtx;定义了SpMtx类型,是一个稀疏矩阵结构体。2. 这段代码定义了一个稀疏矩阵的数据结构
SpMtx,它由一个三元组数组data和三个整型变量mu、nu和tu组成。3. 其中
data数组用于存储稀疏矩阵的非零元素的三元组表,而mu、nu和tu分别表示矩阵的行数、列数和非零元素个数。4.
maxnum限制了非零元素的最大个数。

