
- 1你的 VSCode 上 还没有 GitHub Copilot ?看这里_vscode copilot
- 2探索 TieBa-API-Sentiment:一款强大的贴吧情感分析工具
- 3极验滑块验证码逆向分析(文末含轨迹算法)_今天头条 登录滑块
- 4开源项目-财务管理系统_会计系统开源
- 5如何在快手批量下载高清无水印视频方法
- 6MySQL B+树如何实现联合索引_mysql联合索引b+树结构
- 7CVPR 2024 超分辨率大模型!华为和清华提出CoSeR:基于认知的万物超分大模型
- 8【ROS2机器人入门到实战】单片机开发平台_ros可以在单片机上跑吗
- 9Verilog HDL门级建模_verilog门级建模
- 10交叉编译下/arm-fslc-linux-gnueabi/gcc/arm-fslc-linux-gnueabi/7.3.0/real-ld: cannot find -lglib-2.0_arm-fslc-linux,交叉编译下/arm-fslc-linux-gnueabi/gcc/ar
深度学习 | Transformer模型及代码实现_transformer模型代码
赞
踩
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
一、Transformer模型
1、模型结构
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构。
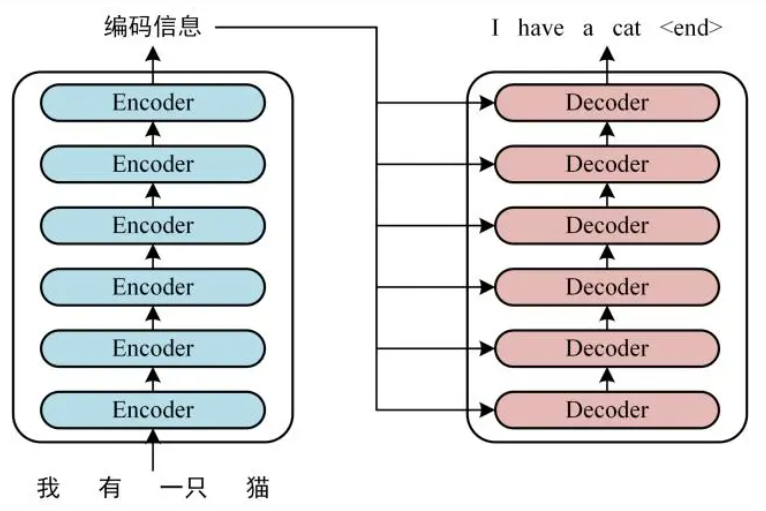
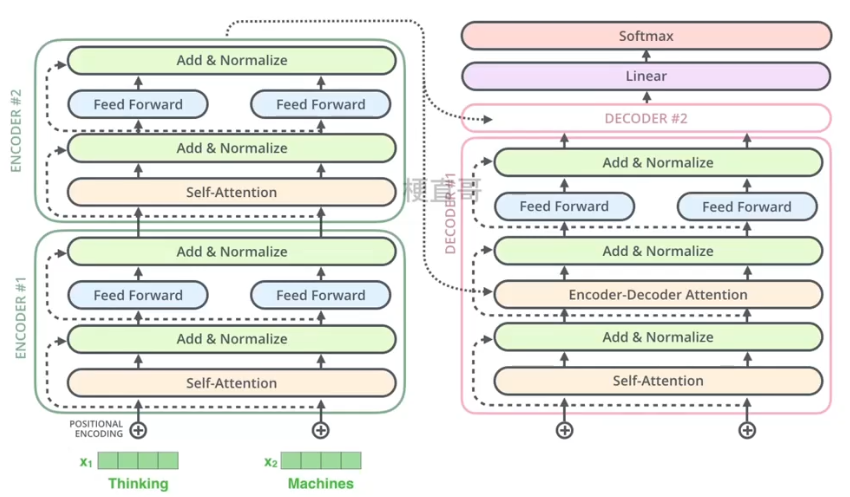
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。 6是随机选择的数字,也可以是其他的数字。我们可以将这个结构看成是串联在一起的电池组,彼此之间通过多次的非线性变换在不同的空间提取更多的信息。
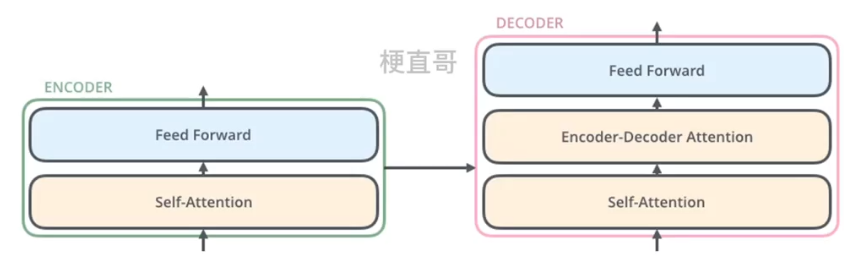
编码器的结构相同,但不共享权重。每个编码器具体来说由两个子层组成。
自注意力层能够帮助编码器在编码特定单词时考虑句子中其他的单词,输出会输入到一个独立的前馈神经网络中,每个编码器都有相同的前馈神经网络运行。
解码器又嵌入了一个 Encoder-Decoder注意力层,帮助解码器专注于输入句子的相关部分,类似于seq2seq中的注意力机制。
在自然语言处理中,注意首先需要使用嵌入算法将每个单词转换为向量,每个词都会嵌入到一个512维的向量中,512是一个超参数,代表训练数据集中句子的最大长度。
注意 每个词的流动路径都是独立的。词语之间的依赖关系是通过自注意力层来表达的,前向反馈层没有相互之间的计算,所以前向反馈层可以并行计算。

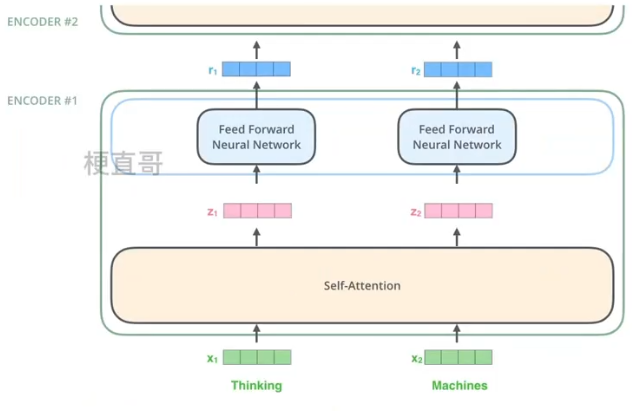
2、编码器
1)、位置嵌入 Embedding
Transformer 中单词的输入表示 x 由单词 Embedding 和位置 Embedding 相加得到。
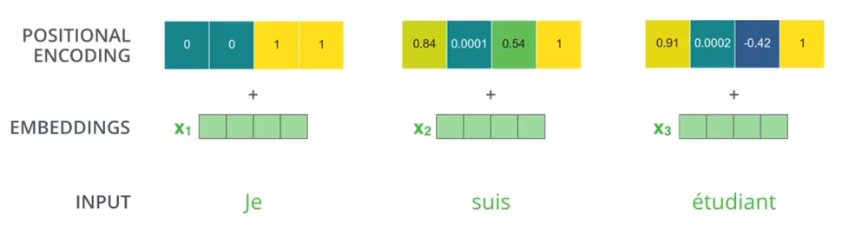
其中单词的 Embedding (嵌入向量) 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
而位置Embedding(位置编码向量)的则是通过定义的正余弦函数来得到的。

其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。
使用这种公式计算 PE 有以下的好处:
使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。将单词的词 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量 x,x 就是Transformer 的输入。
我们之前学习的RNN模型中,并没有使用过位置Embedding,那为什么Transformer中要引入位置信息呢?
这是因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。 所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
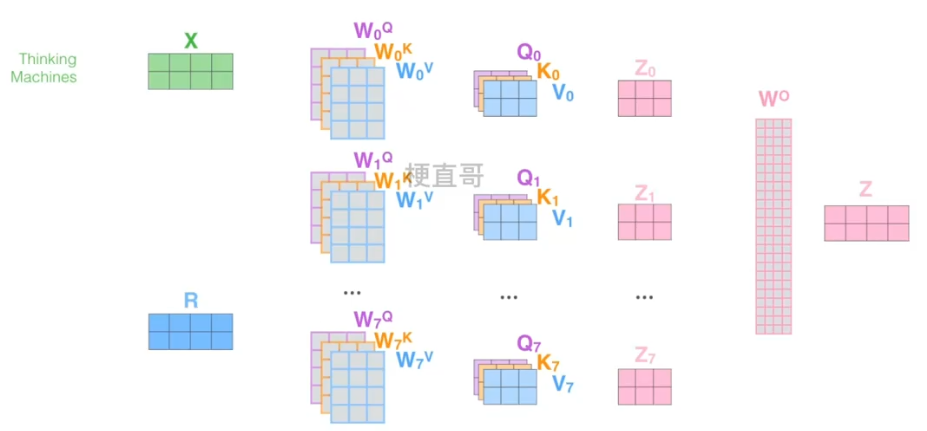
2)Transformer 中的多头注意力机制
在 Transformer 论文中,通过添加多头注意力机制,进一步完善了自注意力层。
也就是说一个输入向量会分别生成不同的 Q K V 的组合,从而得到不同的注意力权重 Z,再拼接到一起,这样的话扩展了模型关注不同位置的能力,为注意力层提供了表示子空间。有点类似CNN中不同的卷积核,用于捕捉输入数据不同维度特征,这样在句子比较长 容易产生歧义或一词多义的情况下也能更好的提取特征信息。
这些 Q K V 变换矩阵都是通过训练得到的,Transformer中就是用了八个头。
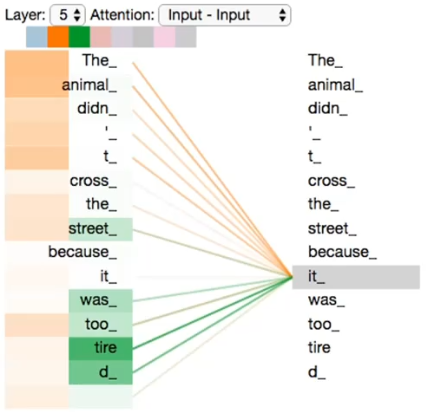
举个例子:当我们在对下面句子中的 it 进行编码时
不同的颜色代表不同头,颜色深浅代表自注意力权重,
以it为例,编码时关注重点The animal、tired。
下面是一个演示,不同颜色表示不同的头Q K V,类似CNN中不同的卷积核,捕获不同中的注意力权重。

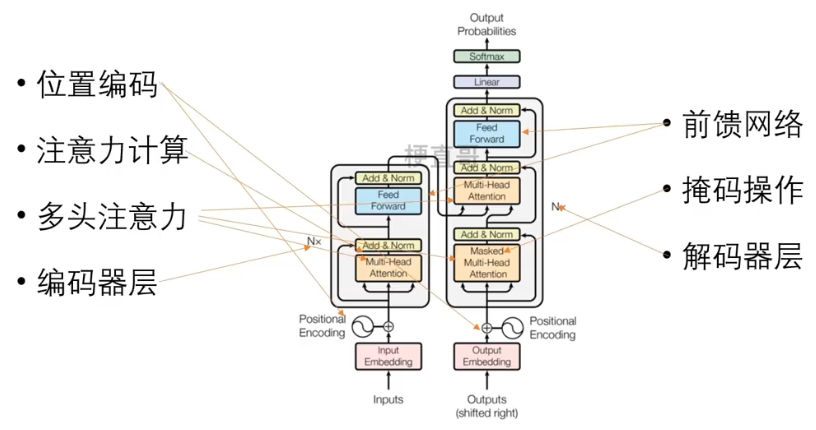
论文中给出的模型架构如下:
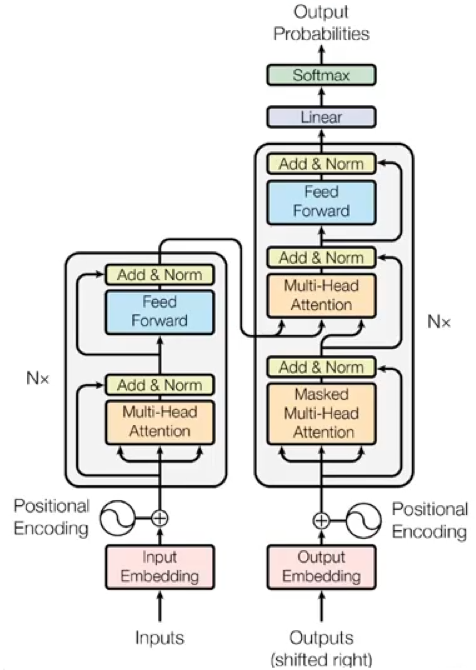
左侧为编码器块,右侧为解码器块。橙色框中的部分就是Multi-Head Attention,它是由多个Self-Attention组成的,可以看到 Encoder block 包含一个Multi-Head Attention,而Decoder block 包含两个Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个Add & Norm 层,这里Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
关于多头注意力和自注意力的内容,我们上一节已经介绍过,这里不再赘述。
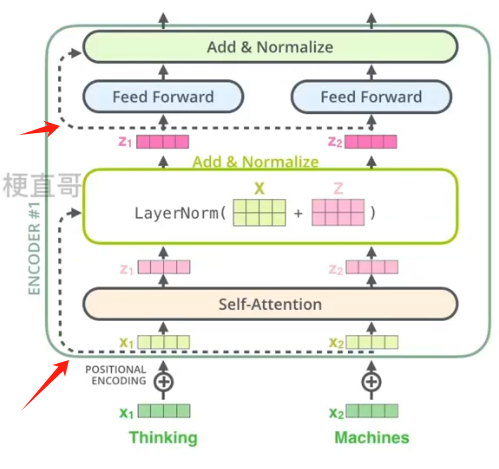
3)残差结构
在每个编码器子层和解码器子层中都使用了残差连接和归一化,他们可以让网络更容易学习复杂特征,从而避免梯度消失和爆炸的问题,同时训练更稳定,层归一化可以加速模型的收敛过程,有助于提高模型的泛化能力和稳定性。
3、解码器
解码器需要同时链接编码器的输出。就像RNN一样,换句话说每一步解码都要使用编码器的输出来生成序列中下一个单词的表示。
通过连接编码器和解码器模型可以有效的利用编码器对输入序列的理解从而生成更加准确的输出序列,同时也可以避免信息丢失的问题,从而提高模型的整体性能和稳定性。
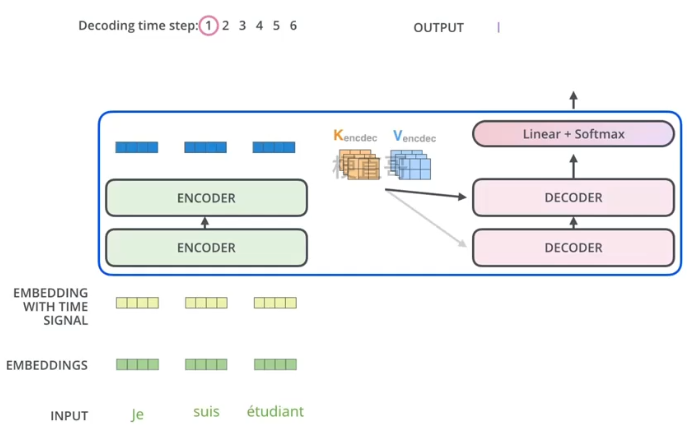
4、编解码器协同工作
编码器首先处理输入序列,然后将顶部的输出转换为 一组注意力向量 K 和 V,这些向量被每个解码器在他的编码器-解码器注意力层中使用,用于帮助解码器将注意力集中在输入序列中的恰当位置。
在解码器阶段,每一步都会从输出序列中输出一个元素,这个元素的生成既依赖于之前的输出同时也依赖于编码器-解码器注意力层中的注意力向量,通过多次迭代计算,解码器可以逐渐生成完整的输出序列。
整个过程中,编码器和解码器的协同工作是通过多头注意力机制和残差链接等技术实现的,这使得 Transformer 模型在各种NLP任务中取得了很好的性能。
重复上述步骤,直到一个特殊的到达符号表示解码器已经完成了输出。可以说解码器的自注意力层和编码器的自注意力层是非常类似的,但是运行方式不同,解码器的自注意力层只允许关注输出序列中之前的位置,以避免信息泄露和信息未来化的问题,在每个解码器中,输入序列要经过多头注意力机制和前馈神经网络进行编码,然后通过编码器-解码器注意力层与编码器的输出 再进行交互,最后生成解码器最后的输出序列。整个过程中位置编码向量也被用来保留单词在序列中的位置信息。
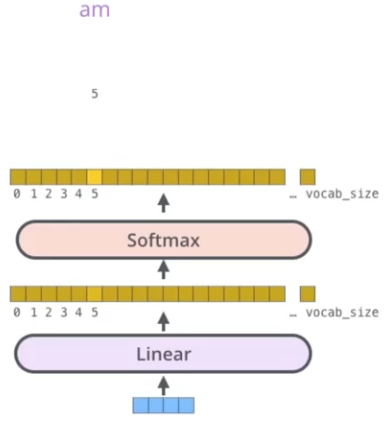
5、线性层和softmax层
对于解码器的输出,他是一个浮点向量,如何把他转换成一个单词呢?这就是线性层和softmax层的工作了。
线性层:一个全连接神经网络,将解码器堆叠生成的向量映射到一个更大的向量,通常称为logits向量。
每个单元格对应一个单词分数。
Softmax层:将单词分数转化为概率,选择具有最高概率的单词作输出。
6、工作流程
Transformer模型的工作流程主要包含三个步骤:
第一步:获取输入句子的每一个单词的表示向量 X,X 由单词的 Embedding 和单词位置的 Embedding 相加得到。
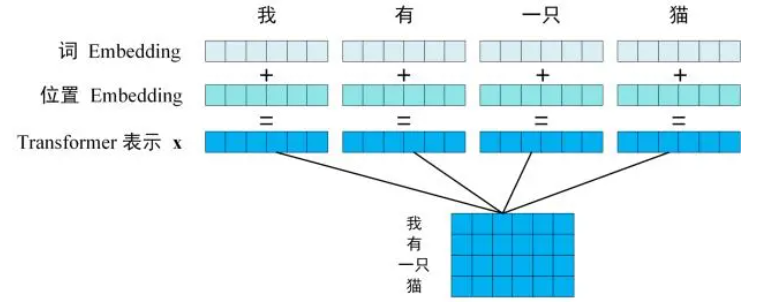
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x ,传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图 2。
单词向量矩阵用 X(n×d)表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
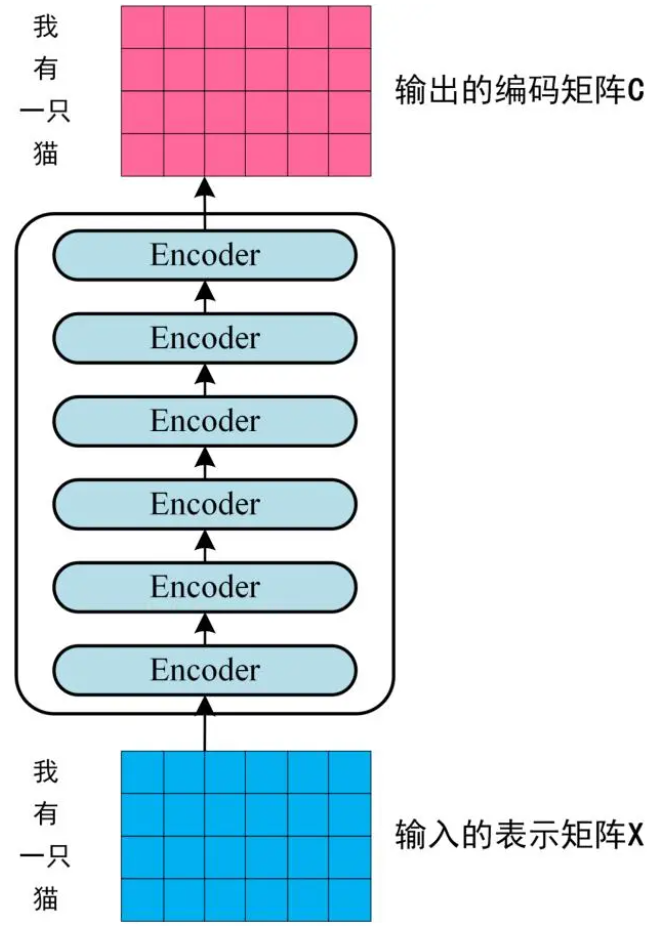
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
需要特别说明的是Transformer中使用了多头注意力机制。
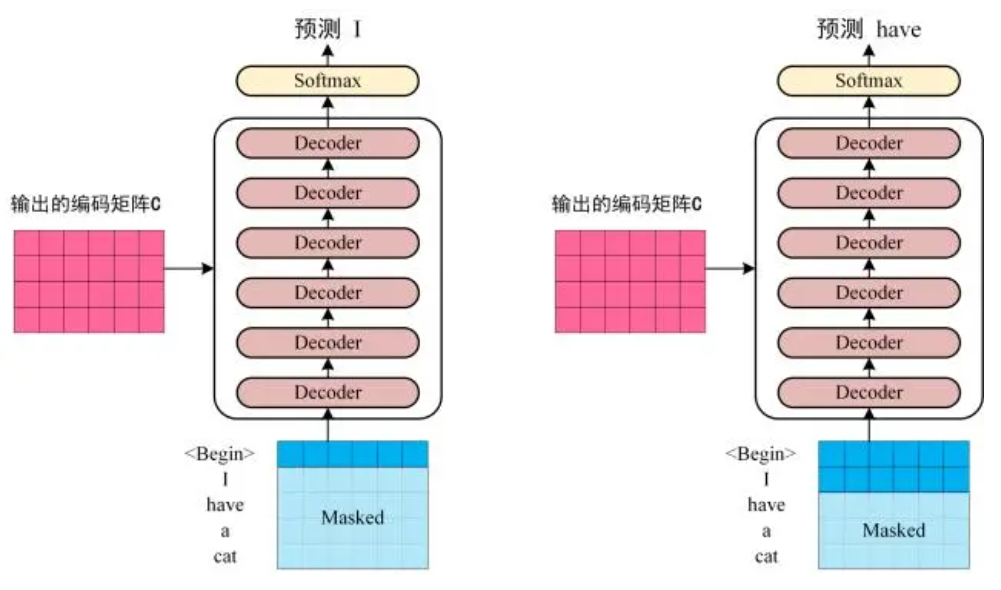
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 Begin,预测第一个单词 I;然后输入翻译开始符 Begin 和单词 I,预测单词 have,以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。
7、优缺点总结
Transformer 与 RNN 不同,可以比较好地并行训练。
Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
二、Transformer模型代码实现
1、数据准备
(1)代码包引入
- import torch
- import torch.nn as nn
- import torch.utils.data as Data
- import numpy as np
- from torch import optim
- import random
- from tqdm import *
- import matplotlib.pyplot as plt
(2)数据集生成
- # 数据集生成
- soundmark = ['ei', 'bi:', 'si:', 'di:', 'i:', 'ef', 'dʒi:', 'eit∫', 'ai', 'dʒei', 'kei', 'el', 'em', 'en', 'əu', 'pi:', 'kju:',
- 'ɑ:', 'es', 'ti:', 'ju:', 'vi:', 'd∧blju:', 'eks', 'wai', 'zi:']
-
- alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q',
- 'r','s','t','u','v','w','x','y','z']
-
- t = 1000 #总条数
- r = 0.9 #扰动项
- seq_len = 6
- src_tokens, tgt_tokens = [],[] #原始序列、目标序列列表
-
- for i in range(t):
- src, tgt = [],[]
- for j in range(seq_len):
- ind = random.randint(0,25)
- src.append(soundmark[ind])
- if random.random() < r:
- tgt.append(alphabet[ind])
- else:
- tgt.append(alphabet[random.randint(0,25)])
- src_tokens.append(src)
- tgt_tokens.append(tgt)
- src_tokens[:2], tgt_tokens[:2]

([['kju:', 'kei', 'em', 'i:', 'vi:', 'pi:'], ['bi:', 'kju:', 'eit∫', 'eks', 'ef', 'di:']], [['q', 'k', 'm', 'e', 'v', 'p'], ['b', 'q', 'h', 'x', 'f', 'd']])
- from collections import Counter # 计数类
-
- flatten = lambda l: [item for sublist in l for item in sublist] # 展平数组
- # 构建词表
- class Vocab:
- def __init__(self, tokens):
- self.tokens = tokens # 传入的tokens是二维列表
- self.token2index = {'<pad>': 0, '<bos>': 1, '<eos>': 2, '<unk>': 3} # 先存好特殊词元
- # 将词元按词频排序后生成列表
- self.token2index.update({
- token: index + 4
- for index, (token, freq) in enumerate(
- sorted(Counter(flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))
- })
- # 构建id到词元字典
- self.index2token = {index: token for token, index in self.token2index.items()}
-
- def __getitem__(self, query):
- # 单一索引
- if isinstance(query, (str, int)):
- if isinstance(query, str):
- return self.token2index.get(query, 3)
- elif isinstance(query, (int)):
- return self.index2token.get(query, '<unk>')
- # 数组索引
- elif isinstance(query, (list, tuple)):
- return [self.__getitem__(item) for item in query]
-
- def __len__(self):
- return len(self.index2token)
(3)数据集构造
- from torch.utils.data import DataLoader, TensorDataset
-
- #实例化source和target词表
- src_vocab, tgt_vocab = Vocab(src_tokens), Vocab(tgt_tokens)
- src_vocab_size = len(src_vocab) # 源语言词表大小
- tgt_vocab_size = len(tgt_vocab) # 目标语言词表大小
-
- #增加开始标识<bos>和结尾标识<eos>
- encoder_input = torch.tensor([src_vocab[line + ['<pad>']] for line in src_tokens])
- decoder_input = torch.tensor([tgt_vocab[['<bos>'] + line] for line in tgt_tokens])
- decoder_output = torch.tensor([tgt_vocab[line + ['<eos>']] for line in tgt_tokens])
-
- # 训练集和测试集比例8比2,batch_size = 16
- train_size = int(len(encoder_input) * 0.8)
- test_size = len(encoder_input) - train_size
- batch_size = 16
-
- # 自定义数据集函数
- class MyDataSet(Data.Dataset):
- def __init__(self, enc_inputs, dec_inputs, dec_outputs):
- super(MyDataSet, self).__init__()
- self.enc_inputs = enc_inputs
- self.dec_inputs = dec_inputs
- self.dec_outputs = dec_outputs
-
- def __len__(self):
- return self.enc_inputs.shape[0]
-
- def __getitem__(self, idx):
- return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
-
- train_loader = DataLoader(MyDataSet(encoder_input[:train_size], decoder_input[:train_size], decoder_output[:train_size]), batch_size=batch_size)
- test_loader = DataLoader(MyDataSet(encoder_input[-test_size:], decoder_input[-test_size:], decoder_output[-test_size:]), batch_size=1)
2、模型构建
(1)位置编码
- def get_sinusoid_encoding_table(n_position, d_model):
- def cal_angle(position, hid_idx):
- return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
- def get_posi_angle_vec(position):
- return [cal_angle(position, hid_j) for hid_j in range(d_model)]
- sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
- sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # 偶数位用正弦函数
- sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # 奇数位用余弦函数
- return torch.FloatTensor(sinusoid_table)
print(get_sinusoid_encoding_table(30, 512))tensor([[ 0.0000e+00, 1.0000e+00, 0.0000e+00, ..., 1.0000e+00,
0.0000e+00, 1.0000e+00],
[ 8.4147e-01, 5.4030e-01, 8.2186e-01, ..., 1.0000e+00,
1.0366e-04, 1.0000e+00],
[ 9.0930e-01, -4.1615e-01, 9.3641e-01, ..., 1.0000e+00,
2.0733e-04, 1.0000e+00],
...,
[ 9.5638e-01, -2.9214e-01, 7.9142e-01, ..., 1.0000e+00,
2.7989e-03, 1.0000e+00],
[ 2.7091e-01, -9.6261e-01, 9.5325e-01, ..., 1.0000e+00,
2.9026e-03, 1.0000e+00],
[-6.6363e-01, -7.4806e-01, 2.9471e-01, ..., 1.0000e+00,
3.0062e-03, 1.0000e+00]])
(2)掩码操作
- # mask掉没有意义的占位符
- def get_attn_pad_mask(seq_q, seq_k): # seq_q: [batch_size, seq_len] ,seq_k: [batch_size, seq_len]
- batch_size, len_q = seq_q.size()
- batch_size, len_k = seq_k.size()
- pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # 判断 输入那些含有P(=0),用1标记 ,[batch_size, 1, len_k]
- return pad_attn_mask.expand(batch_size, len_q, len_k)
-
- # mask掉未来信息
- def get_attn_subsequence_mask(seq): # seq: [batch_size, tgt_len]
- attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
- subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成上三角矩阵,[batch_size, tgt_len, tgt_len]
- subsequence_mask = torch.from_numpy(subsequence_mask).byte() # [batch_size, tgt_len, tgt_len]
- return subsequence_mask
(3)注意力计算函数
- # 缩放点积注意力计算
- class ScaledDotProductAttention(nn.Module):
- def __init__(self):
- super(ScaledDotProductAttention, self).__init__()
- def forward(self, Q, K, V, attn_mask):
- '''
- Q: [batch_size, n_heads, len_q, d_k]
- K: [batch_size, n_heads, len_k, d_k]
- V: [batch_size, n_heads, len_v(=len_k), d_v]
- attn_mask: [batch_size, n_heads, seq_len, seq_len]
- '''
- scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
- scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
- attn = nn.Softmax(dim=-1)(scores)
- context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
- return context, attn
-
- #多头注意力计算
- class MultiHeadAttention(nn.Module):
- def __init__(self):
- super(MultiHeadAttention, self).__init__()
- self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
- self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
- self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
- self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
- def forward(self, input_Q, input_K, input_V, attn_mask):
- '''
- input_Q: [batch_size, len_q, d_model]
- input_K: [batch_size, len_k, d_model]
- input_V: [batch_size, len_v(=len_k), d_model]
- attn_mask: [batch_size, seq_len, seq_len]
- '''
- residual, batch_size = input_Q, input_Q.size(0)
- # (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
- Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
- K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
- V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
- attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
- # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
- context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
- context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
- output = self.fc(context) # [batch_size, len_q, d_model]
- return nn.LayerNorm(d_model)(output + residual), attn
(4)构建前馈网络
- class PoswiseFeedForwardNet(nn.Module):
- def __init__(self):
- super(PoswiseFeedForwardNet, self).__init__()
- self.fc = nn.Sequential(
- nn.Linear(d_model, d_ff, bias=False),
- nn.ReLU(),
- nn.Linear(d_ff, d_model, bias=False))
-
- def forward(self, inputs): # inputs: [batch_size, seq_len, d_model]
- residual = inputs
- output = self.fc(inputs)
- return nn.LayerNorm(d_model)(output + residual) # 残差 + LayerNorm
(5)编码器模块
- # 编码器层
- class EncoderLayer(nn.Module):
- def __init__(self):
- super(EncoderLayer, self).__init__()
- self.enc_self_attn = MultiHeadAttention() # 多头注意力
- self.pos_ffn = PoswiseFeedForwardNet() # 前馈网络
- def forward(self, enc_inputs, enc_self_attn_mask):
- '''
- enc_inputs: [batch_size, src_len, d_model]
- enc_self_attn_mask: [batch_size, src_len, src_len]
- '''
- # enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
- enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
- enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
- return enc_outputs, attn
-
- # 编码器模块
- class Encoder(nn.Module):
- def __init__(self):
- super(Encoder, self).__init__()
- self.src_emb = nn.Embedding(src_vocab_size, d_model)
- self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_vocab_size, d_model), freeze=True)
- self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
- def forward(self, enc_inputs):
- '''
- enc_inputs: [batch_size, src_len]
- '''
- word_emb = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
- pos_emb = self.pos_emb(enc_inputs) # [batch_size, src_len, d_model]
- enc_outputs = word_emb + pos_emb
- enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
- enc_self_attns = []
- for layer in self.layers:
- # enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
- enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
- enc_self_attns.append(enc_self_attn)
- return enc_outputs, enc_self_attns
(6)解码器模块
- # 解码器层
- class DecoderLayer(nn.Module):
- def __init__(self):
- super(DecoderLayer, self).__init__()
- self.dec_self_attn = MultiHeadAttention()
- self.dec_enc_attn = MultiHeadAttention()
- self.pos_ffn = PoswiseFeedForwardNet()
- def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
- '''
- dec_inputs: [batch_size, tgt_len, d_model]
- enc_outputs: [batch_size, src_len, d_model]
- dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
- dec_enc_attn_mask: [batch_size, tgt_len, src_len]
- '''
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
- dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
- # dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
- dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
- dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
- return dec_outputs, dec_self_attn, dec_enc_attn
-
- # 解码器模块
- class Decoder(nn.Module):
- def __init__(self):
- super(Decoder, self).__init__()
- self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
- self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_vocab_size, d_model),freeze=True)
- self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
- def forward(self, dec_inputs, enc_inputs, enc_outputs):
- '''
- dec_inputs: [batch_size, tgt_len]
- enc_intpus: [batch_size, src_len]
- enc_outputs: [batsh_size, src_len, d_model]
- '''
- word_emb = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
- pos_emb = self.pos_emb(dec_inputs) # [batch_size, tgt_len, d_model]
- dec_outputs = word_emb + pos_emb
- dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len]
- dec_self_attn_subsequent_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len]
- dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) # [batch_size, tgt_len, tgt_len]
- dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
- dec_self_attns, dec_enc_attns = [], []
- for layer in self.layers:
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len,src_len]
- dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
- dec_self_attns.append(dec_self_attn)
- dec_enc_attns.append(dec_enc_attn)
- return dec_outputs, dec_self_attns, dec_enc_attns
(7)Transformer模型
- class Transformer(nn.Module):
- def __init__(self):
- super(Transformer, self).__init__()
- self.encoder = Encoder()
- self.decoder = Decoder()
- self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
- def forward(self, enc_inputs, dec_inputs):
- '''
- enc_inputs: [batch_size, src_len]
- dec_inputs: [batch_size, tgt_len]
- '''
- # tensor to store decoder outputs
- # outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
- # enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
- enc_outputs, enc_self_attns = self.encoder(enc_inputs)
- # dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
- dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
- dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
- return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
3、模型训练
- d_model = 512 # 字 Embedding 的维度
- d_ff = 2048 # 前向传播隐藏层维度
- d_k = d_v = 64 # K(=Q), V的维度
- n_layers = 6 # 有多少个encoder和decoder
- n_heads = 8 # Multi-Head Attention设置为8
- num_epochs = 50 # 训练50轮
- # 记录损失变化
- loss_history = []
-
- model = Transformer()
- criterion = nn.CrossEntropyLoss(ignore_index=0)
- optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.99)
-
- for epoch in tqdm(range(num_epochs)):
- total_loss = 0
- for enc_inputs, dec_inputs, dec_outputs in train_loader:
- '''
- enc_inputs: [batch_size, src_len]
- dec_inputs: [batch_size, tgt_len]
- dec_outputs: [batch_size, tgt_len]
- '''
- # enc_inputs, dec_inputs, dec_outputs = enc_inputs.to(device), dec_inputs.to(device), dec_outputs.to(device)
- # outputs: [batch_size * tgt_len, tgt_vocab_size]
- outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
- loss = criterion(outputs, dec_outputs.view(-1))
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- total_loss += loss.item()
- avg_loss = total_loss/len(train_loader)
- loss_history.append(avg_loss)
- print('Epoch:', '%d' % (epoch + 1), 'loss =', '{:.6f}'.format(avg_loss))
2%|▏ | 1/50 [00:21<17:16, 21.15s/it]Epoch: 1 loss = 2.633762 4%|▍ | 2/50 [00:42<17:06, 21.39s/it]Epoch: 2 loss = 2.063002 6%|▌ | 3/50 [01:04<16:48, 21.47s/it]Epoch: 3 loss = 1.866944 8%|▊ | 4/50 [01:25<16:16, 21.23s/it]Epoch: 4 loss = 1.802783 10%|█ | 5/50 [01:45<15:49, 21.10s/it]Epoch: 5 loss = 1.643217 12%|█▏ | 6/50 [02:07<15:27, 21.07s/it]Epoch: 6 loss = 1.803471 14%|█▍ | 7/50 [02:27<15:04, 21.02s/it]Epoch: 7 loss = 1.518794 16%|█▌ | 8/50 [02:48<14:41, 20.99s/it]Epoch: 8 loss = 1.632840 18%|█▊ | 9/50 [03:10<14:23, 21.06s/it]Epoch: 9 loss = 1.446730 20%|██ | 10/50 [03:31<14:02, 21.06s/it]Epoch: 10 loss = 1.340348 22%|██▏ | 11/50 [03:52<13:40, 21.04s/it]Epoch: 11 loss = 1.366917 24%|██▍ | 12/50 [04:13<13:20, 21.06s/it]Epoch: 12 loss = 1.499715 26%|██▌ | 13/50 [04:34<13:01, 21.12s/it]Epoch: 13 loss = 1.371446 28%|██▊ | 14/50 [04:55<12:41, 21.14s/it]Epoch: 14 loss = 1.380498 30%|███ | 15/50 [05:16<12:19, 21.14s/it]Epoch: 15 loss = 1.298183 32%|███▏ | 16/50 [05:37<11:53, 20.99s/it]Epoch: 16 loss = 1.107512 34%|███▍ | 17/50 [05:57<11:27, 20.85s/it]Epoch: 17 loss = 1.015355 36%|███▌ | 18/50 [06:18<11:04, 20.76s/it]Epoch: 18 loss = 0.891573 38%|███▊ | 19/50 [06:39<10:41, 20.69s/it]Epoch: 19 loss = 1.035157 40%|████ | 20/50 [06:59<10:19, 20.64s/it]Epoch: 20 loss = 1.059943 42%|████▏ | 21/50 [07:20<09:58, 20.64s/it]Epoch: 21 loss = 0.995347 44%|████▍ | 22/50 [07:40<09:38, 20.65s/it]Epoch: 22 loss = 0.828730 46%|████▌ | 23/50 [08:01<09:18, 20.68s/it]Epoch: 23 loss = 0.717403 48%|████▊ | 24/50 [08:22<08:59, 20.77s/it]Epoch: 24 loss = 0.768870 50%|█████ | 25/50 [08:43<08:39, 20.80s/it]Epoch: 25 loss = 0.713927 52%|█████▏ | 26/50 [09:04<08:18, 20.75s/it]Epoch: 26 loss = 0.797918 54%|█████▍ | 27/50 [09:24<07:57, 20.74s/it]Epoch: 27 loss = 0.680246 56%|█████▌ | 28/50 [09:45<07:36, 20.76s/it]Epoch: 28 loss = 0.611770 58%|█████▊ | 29/50 [10:06<07:16, 20.77s/it]Epoch: 29 loss = 0.810355 60%|██████ | 30/50 [10:27<06:57, 20.86s/it]Epoch: 30 loss = 0.537487 62%|██████▏ | 31/50 [10:48<06:37, 20.93s/it]Epoch: 31 loss = 0.484650 64%|██████▍ | 32/50 [11:09<06:15, 20.86s/it]Epoch: 32 loss = 0.447033 66%|██████▌ | 33/50 [11:30<05:54, 20.83s/it]Epoch: 33 loss = 0.399072 68%|██████▊ | 34/50 [11:51<05:34, 20.90s/it]Epoch: 34 loss = 0.379649 70%|███████ | 35/50 [12:12<05:13, 20.92s/it]Epoch: 35 loss = 0.270823 72%|███████▏ | 36/50 [12:32<04:52, 20.91s/it]Epoch: 36 loss = 0.337878 74%|███████▍ | 37/50 [12:53<04:30, 20.81s/it]Epoch: 37 loss = 0.235440 76%|███████▌ | 38/50 [13:14<04:09, 20.77s/it]Epoch: 38 loss = 0.337393 78%|███████▊ | 39/50 [13:35<03:49, 20.85s/it]Epoch: 39 loss = 0.260191 80%|████████ | 40/50 [13:56<03:28, 20.89s/it]Epoch: 40 loss = 0.210084 82%|████████▏ | 41/50 [14:17<03:09, 21.03s/it]Epoch: 41 loss = 0.168616 84%|████████▍ | 42/50 [14:38<02:47, 20.97s/it]Epoch: 42 loss = 0.213607 86%|████████▌ | 43/50 [14:58<02:25, 20.82s/it]Epoch: 43 loss = 0.110551 88%|████████▊ | 44/50 [15:19<02:04, 20.74s/it]Epoch: 44 loss = 0.183562 90%|█████████ | 45/50 [15:39<01:43, 20.62s/it]Epoch: 45 loss = 0.095172 92%|█████████▏| 46/50 [16:00<01:22, 20.57s/it]Epoch: 46 loss = 0.132387 94%|█████████▍| 47/50 [16:20<01:01, 20.52s/it]Epoch: 47 loss = 0.163805 96%|█████████▌| 48/50 [16:41<00:40, 20.49s/it]Epoch: 48 loss = 0.152195 98%|█████████▊| 49/50 [17:01<00:20, 20.49s/it]Epoch: 49 loss = 0.086681 100%|██████████| 50/50 [17:22<00:00, 20.84s/it]Epoch: 50 loss = 0.085496
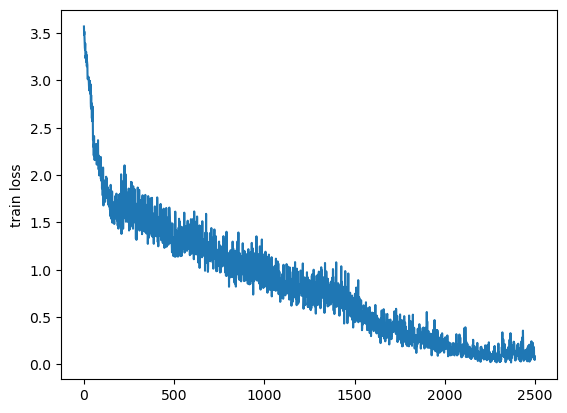
- plt.plot(loss_history)
- plt.ylabel('train loss')
- plt.show()
4、模型预测
- model.eval()
- translation_results = []
-
- correct = 0
- error = 0
-
- for enc_inputs, dec_inputs, dec_outputs in test_loader:
- '''
- enc_inputs: [batch_size, src_len]
- dec_inputs: [batch_size, tgt_len]
- dec_outputs: [batch_size, tgt_len]
- '''
- # enc_inputs, dec_inputs, dec_outputs = enc_inputs.to(device), dec_inputs.to(device), dec_outputs.to(device)
- # outputs: [batch_size * tgt_len, tgt_vocab_size]
- outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
- # pred形状为 (seq_len, batch_size, vocab_size) = (1, 1, vocab_size)
- # dec_outputs, dec_self_attns, dec_enc_attns = model.decoder(dec_inputs, enc_inputs, enc_output)
-
- outputs = outputs.squeeze()
-
- pred_seq = []
- for output in outputs:
- next_token_index = output.argmax().item()
- if next_token_index == tgt_vocab['<eos>']:
- break
- pred_seq.append(next_token_index)
-
- pred_seq = tgt_vocab[pred_seq]
- tgt_seq = dec_outputs.squeeze().tolist()
-
- # 需要注意在<eos>之前截断
- if tgt_vocab['<eos>'] in tgt_seq:
- eos_idx = tgt_seq.index(tgt_vocab['<eos>'])
- tgt_seq = tgt_vocab[tgt_seq[:eos_idx]]
- else:
- tgt_seq = tgt_vocab[tgt_seq]
- translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))
-
- for i in range(len(tgt_seq)):
- if i >= len(pred_seq) or pred_seq[i] != tgt_seq[i]:
- error += 1
- else:
- correct += 1
-
- print(correct/(correct+error))
0.3333333333333333
translation_results[('h x n y e k', 'h y y y k'),
('y l z k i t', 't i t j i t y'),
('t s x e e v', 's s v e e v'),
('e g a m t h', 'f i h h h'),...................
参考
Chapter-11/11.7 Transformer代码实现.ipynb · 梗直哥/Deep-Learning-Code - Gitee.com

