
- 1Current existing ChromeDriver binary is unavailable, proceding with download and extraction.
- 2Windows 10 安装 ADB (Android Debug Bridge,Android 调试桥)
- 3Shiro 权限管理_shiro权限管理
- 4【pyQt5】Python在PyQt5中使用ECharts绘制图表_pyecharts - kline可以在pyqt5中渲染吗
- 5MySql监控工具断网部署Percona Monitoring and Management ,Perocona的官方监控工具Docker安装教程_mysql monitoring and managment
- 6【人民网注册_登录安全分析报告】
- 7Java获取当前进程ID以及所有Java进程的进程ID_java如何获取某个进程的id
- 8Fast Planner——代码解读参考资料整理_egoswarm在gazebo仿真
- 9刚刚用华为鸿蒙跑了个“hello world”,2024最新HarmonyOS鸿蒙面试题及答案
- 10计算机毕设(附源码)JAVA-SSM基于Java家庭财务管理系统_家庭理财系统用例图
(2024,Attention-Mamba,MoE 替换 MLP)Jamba:混合 Transformer-Mamba 语言模型_如何将transform改成mamba
赞
踩
Jamba: A Hybrid Transformer-Mamba Language Model
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
我们介绍了 Jamba,这是一个基于新型混合 Transformer-Mamba 专家组合 (mixture-of-experts,MoE) 架构的大型语言模型。具体来说,Jamba 交错使用 Transformer 和 Mamba 层的块,享受两个模型系列的好处。在其中一些层中添加 MoE 可以增加模型容量,同时保持活跃参数的可管理性。这种灵活的架构允许资源和目标特定的配置。在我们实现的特定配置中,我们得到了一个强大的模型,可以适应单个 80GB 的 GPU。在大规模构建的情况下,与普通 Transformer 相比,Jamba 提供了高吞吐量和小内存占用,并且同时在标准语言模型基准测试和长上下文评估方面达到了最先进的性能。值得注意的是,该模型在长达 256K token 的上下文长度上呈现出强大的结果。我们研究了各种架构决策,例如如何结合 Transformer 和 Mamba 层,以及如何混合专家,并展示了其中一些在大规模建模中至关重要的因素。我们还描述了这些架构的几个有趣属性,这些属性是通过 Jamba 的训练和评估所揭示的,并计划发布来自各种削减运行的检查点,以鼓励进一步探索这种新型架构。我们以宽松的许可证公开发布了我们实现的 Jamba 的权重。
Model:https://huggingface.co/ai21labs/Jamba-v0.1
1. 简介
我们介绍了 Jamba,这是一个新的公开可用的大型语言模型。Jamba 基于一种新颖的混合架构,将 Transformer 层 [46] 与 Mamba 层 [16]、最近的状态空间模型(state-space model) [17, 18] 以及专家组件 (MoE) [13, 41] 结合起来。因此,Jamba 结合了两种正交的架构设计,使其在提高性能和吞吐量的同时保持了可管理的内存占用。我们发布的基于 7B 的 Jamba 模型 (12B 活跃参数,52B 总可用参数) 是为了适应单个 80GB 的 GPU 设计的,但是 Jamba 架构支持其他设计选择,取决于硬件和性能要求。

Jamba 的基本新颖之处在于其混合的 Transformer-Mamba 架构(尽管请参见下文有关最近相关努力的提及)。尽管 Transformer 作为主导语言模型的架构非常受欢迎,但它存在两个主要缺点。
- 首先,其高内存和计算要求阻碍了对长上下文的处理,其中键值 (KV) 缓存大小成为限制因素。
- 其次,由于缺乏单个摘要状态(single summary state),它的推理速度缓慢,吞吐量低,因为每个生成的 token 都对整个上下文进行计算。
- 相比之下,旧的循环神经网络 (RNN) 模型在单个隐藏状态中总结任意长的上下文,不会受到这些限制的影响。然而,RNN 模型也有其缺点。它们训练成本高,因为训练不能在时间步骤之间并行化。而且,它们在处理长距离关系方面存在困难,而隐藏状态仅能在有限程度上捕捉这些关系。
最近的状态空间模型 (SSM) 如 Mamba 模型比 RNN 更容易训练,并且更能处理长距离关系,但仍然落后于性能相当的 Transformer 语言模型。利用这两个模型系列的优势,Jamba 在一定比例上结合了 Transformer 和 Mamba 层。改变 Transformer / Mamba 层的比例可以平衡内存使用、高效训练和长上下文功能。
最近还有一些其他将 Attention 和 SSM 模块结合的尝试值得注意。
- [50] 将 S4 层 [17] 与局部注意力层混合,然后是一系列局部注意力层;它展示了对小型模型和简单任务的实验。
- [16] 报告称,参数量达到 1.3B 的模型,使用交错 Mamba 和注意力层仅在困惑度方面略优于纯 Mamba。
- [33] 以 SSM 层开始,然后是基于块的 Transformer,参数量达到 1.3B 的模型显示出改进的困惑度。
- [12] 在 Transformer 层的自注意力之前添加了一个 SSM 层,而 [38] 在自注意力之后添加了 SSM,都在语音识别方面显示出了改进。
- [32] 将 Transformer 中的 MLP 层替换为 Mamba 层,并在简单任务中展示了好处。
这些努力与 Jamba 在 SSM 组件与注意力组件混合的特定方式以及实现规模上有所不同。
- 也许最接近的是 H3 [14],这是一个专门设计的 SSM,能够实现归纳能力,以及一个称为 Hyena [35] 的泛化模型。前者提出了一个混合架构,将第二和中间层替换为自注意力层,并且实现了多达 2.7B 参数和 400B 训练 token 的模型。然而,如 [16] 所示,它的性能落后于纯 Mamba。
- 基于 Hyena,StripedHyena [36] 在一个 7B 参数模型中交错了注意力和 SSM 层。然而,它在仅注意力的 Mistral-7B [22] 方面落后。
所有这些使 Jamba 成为第一个生产级别的注意力-SSM 混合模型。扩展混合 Jamba 架构需要克服几个障碍,我们将在第 6 节讨论。
Jamba 还包括 MoE 层 [13, 41],它允许增加模型容量 (总可用参数数量) 而不增加计算要求 (活跃参数数量)。MoE 是一种灵活的方法,可以训练具有强大性能的极大模型 [23]。在 Jamba 中,MoE 应用于一些 MLP 层。MoE 层越多,每个 MoE 层的专家越多,模型参数的总数就越大。相反,我们在每个前向传递中使用的专家越多,活跃参数的数量和计算要求就越大。在我们的 Jamba 实现中,我们在每隔一个层应用 MoE,每个 token 使用 16 个专家和前 2 个专家 (有关模型架构的更详细讨论将在下面提供)。
我们对 Jamba 的实现进行了广泛的基准测试,并发现其性能与 Mixtral-8x7B [23] 相当,后者具有类似数量的参数,并且与更大的 Llama-2 70B [45] 相当。此外,我们的模型支持 256K token 的上下文长度 —— 这是生产级公开可用模型支持的最长上下文长度。在长上下文评估中,Jamba 在大多数评估数据集上优于 Mixtral。同时,Jamba 非常高效;例如,对于长上下文,其吞吐量是 Mixtral-8x7B 的 3 倍。此外,我们的模型甚至在上下文超过 128K token 的情况下也适合于单个 GPU (带有 8 位权重),而对于类似尺寸的仅注意力模型,如 Mixtral-8x7B,这是不可能的。
对于一个新的架构来说,不寻常的是我们以 Apache 2.0 许可证发布了 Jamba (12B 活跃参数,52B 总可用参数。我们这样做是因为我们认为 Jamba 的新颖架构需要社区进一步研究、实验和优化。我们的设计基于我们进行的各种消融实验,以探索不同的权衡和设计选择的影响,以及从中获得的见解。这些消融实验在多达 7B 参数的规模上进行,训练 token 数多达 250B。我们计划发布来自这些运行的模型检查点。
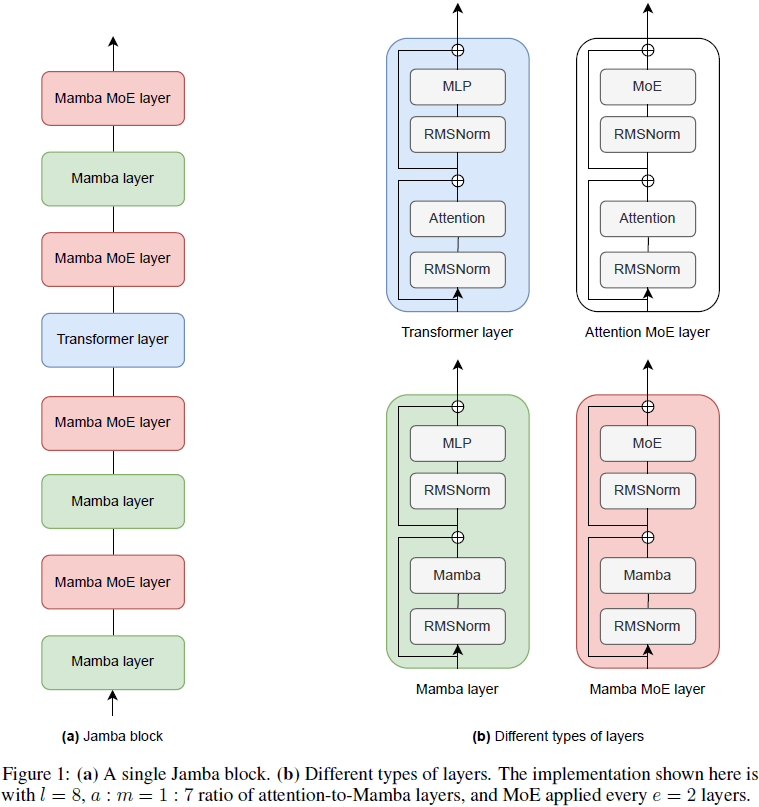
2. 模型架构
Jamba 是一种混合解码器架构,将 Transformer 层 [46]、Mamba 层 [16]、最近的状态空间模型 (SSM) [17, 18],以及专家组件 (MoE) 模块 [13, 41] 结合在一起。我们将这三个元素的组合称为 Jamba 块,请参见图 1。
将 Transformer、Mamba 和 MoE 元素结合起来,可以在低内存使用、高吞吐量和高质量之间灵活平衡,这些目标有时是相互冲突的。在内存使用方面,注意,比较模型参数的总大小可能会产生误导。在 MoE 模型中,参与任何给定前向步骤的活跃参数数量可能比总参数数量要小得多。另一个重要考虑因素是 KV 缓存 —— 存储上下文中注意力键和值所需的内存。当将 Transformer 模型扩展到长上下文时,KV 缓存成为一个限制因素。通过在注意力层和 Mamba 层之间进行权衡,可以减少 KV 缓存的总大小。我们的架构旨在不仅提供少量的活跃参数,而且相对于纯 Transformer,KV 缓存减小 8 倍。表 1 比较了 Jamba 与最近公开可用模型,显示了即使在 256K token 上下文中,它仍能保持较小的 KV 缓存的优势。

就吞吐量而言,对于短序列,注意力操作占推理和训练 FLOPS 的一小部分 [6]。然而,对于长序列,注意力占用了大部分计算资源。相比之下,Mamba 层更加计算效率高。因此,增加 Mamba 层的比例特别是对于长序列可以提高吞吐量。
以下是主要配置的描述,该配置提供了改进的性能和效率。第 6 节包含支持设计选择的消融实验结果。基本组件是一个 Jamba 块,可以在序列中重复。每个 Jamba 块是 Mamba 层或注意力层的组合。每个这样的层包含一个注意力模块或一个 Mamba 模块,后面跟着一个多层感知器 (MLP)。图 1(b) 展示了不同类型的层。(注意,该图显示了有潜力的 Attention MoE 层,我们的架构未使用该层,但未来的变体可以使用该层。)一个 Jamba 块包含 L 层,这些层以 a:m 的比例混合,意味着每 m 个 Mamba 层有 a 个注意力层。
在 Jamba 中,一些 MLP 可能会被 MoE 层替换,这有助于增加模型的容量,同时保持活跃参数的数量,从而使计算量保持较小。MoE 模块可以每 e 层应用到 MLP。使用 MoE 时,每层有 n 个可能的专家,路由器(router)在每个 token 上选择前 K 个专家。总之,Jamba 架构中的不同自由度是:
- L:层的数量。
- a:m:注意力与 Mamba 层的比例。
- e:多久使用 MoE 而不是单个 MLP。
- n:每层的总专家数量。
- K:每个 token 使用的顶级专家数量。
在这个设计空间中,Jamba 提供了优先考虑某些属性而不是其他属性的灵活性。例如,增加 m 并减小 a,即以注意力层为代价增加 Mamba 层的比例,减少了存储键值缓存所需的内存。这减小了总体内存占用,这对于处理长序列尤为重要。增加 Mamba 层的比例也提高了吞吐量,特别是在长序列时。然而,减小 a 可能会降低模型的能力。
此外,平衡 n、K 和 e 影响了活跃参数与总可用参数之间的关系。增加 n 会增加模型的容量,但以内存占用为代价,而增加 K 会增加活跃参数的使用和计算要求。相反,增加 e 会减小模型的容量,同时减少计算 (当 K>1 时) 和内存要求,并且减少通信依赖性 (减少内存传输以及在专家并行训练和推断期间的跨 GPU 通信)。
Jamba 对 Mamba 层的实现包括几个归一化,有助于稳定大型模型规模下的训练。特别地,我们在 Mamba 层应用了 RMSNorm [48]。
我们发现,使用 Mamba 层时,不需要位置嵌入或类似 RoPE [42] 的机制,因此我们不使用任何显式的位置信息。其他架构细节是标准的,包括分组查询注意力 (GQA)、SwiGLU 激活函数 [6, 40, 45],以及 MoE 的负载平衡 [13]。词汇量大小为 64K。分词器(tokenizer)使用 BPE 进行训练 [15, 29, 39],每个数字都是一个单独的标记 [6]。我们还删除了 Llama 和 Mistral 分词器中用于更一致和可逆分词的虚拟空格。
3. 收获的好处
3.1 单个 80GB GPU 的 Jamba 实现
我们的实现中选择的特定配置是为了适应单个 80GB GPU,同时在质量和吞吐量方面实现最佳性能。在我们的实现中,我们有一个由 4 个 Jamba 块组成的序列。每个 Jamba 块具有以下配置:
- L = 8:层的数量。
- a : m = 1 : 7:注意力与 Mamba 层的比例。
- e = 2:多久使用 MoE 而不是单个 MLP。
- n = 16:专家的总数。
- K = 2:每个 token 使用的顶级专家数量。
a : m = 1 : 7 比例是根据初步消融选择的,如第 6 节所示,因为在质量方面性能最好的变体中,这个比例是最计算效率最高的变体之一。
专家的配置是为了使模型适应单个 80GB GPU (带有 int8 权重),同时包含足够的内存用于输入。特别地,n 和 e 被平衡以使每层平均有 ∼8 个专家。此外,我们平衡了 n、K 和 e,以确保高质量,同时保持计算需求和通信依赖性 (内存传输) 受控。因此,我们选择在每隔一个层将 MLP 模块替换为 MoE,并且总共有 16 个专家,其中每个 token 使用两个专家。这些选择受到了先前关于 MoE 的工作的启发 [7, 49],并在初步实验中得到了验证。
图 2 显示了我们的 Jamba 实现与 Mixtral 8x7B 和 Llama-2-70B 相比在单个 80GB GPU 上适合的最大上下文长度。Jamba 提供的上下文长度是 Mixtral 的 2 倍,是 Llama-2-70B 的 7 倍。
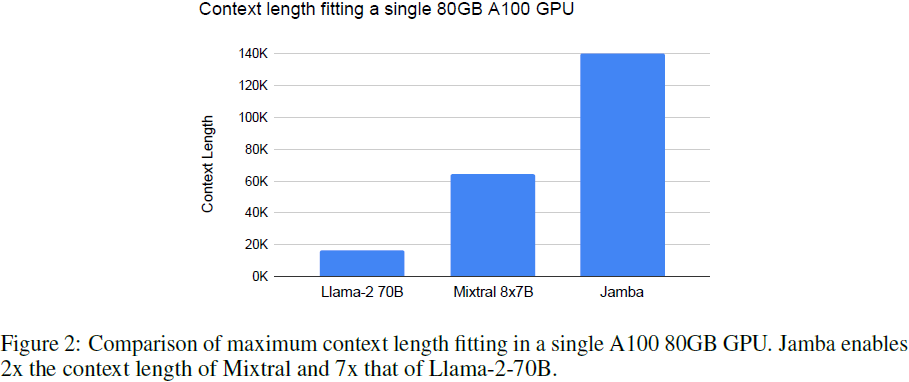
总体而言,我们的 Jamba 实现已成功训练了长达 1M token 的上下文长度。发布的模型支持长达 256K token 的长度。
3.2 吞吐量分析
为了具体说明,我们提供了两种特定设置下的吞吐量结果。在第一个设置中,我们有不同的批处理大小,一个单独的 A100 80GB GPU,int8 量化,8K 上下文长度,生成 512 个令牌的输出。如图 3a 所示,Jamba 允许处理大批量,导致吞吐量 (令牌/秒) 达到 Mixtral 的 3 倍,尽管 Mixtral 的活跃参数数量与其相似,但不适合批量为 16。
在第二个设置中,我们有一个单独的批处理,4 个 A100 GPU,没有量化,不同的上下文长度,生成 512 个令牌的输出。如图 3b 所示,在小的上下文长度下,所有模型的吞吐量相似。Jamba 在长上下文上表现出色;以 128K 令牌计,其吞吐量是 Mixtral 的 3 倍。需要注意的是,这是尽管 Jamba 尚未享受到社区在过去六年中为纯 Transformer 模型开发的优化。我们可以期待随着这样的优化也应用于 Jamba,吞吐量差距会增加。

4. 训练基础设施和数据集
模型是在 NVIDIA H100 GPU 上进行训练的。我们使用了一个内部专有框架,可以进行高效的大规模训练,包括 FSDP、张量并行、序列并行和专家并行。 Jamba 是在一个内部数据集上进行训练的,该数据集包含来自网络、图书和代码的文本数据,最后更新于 2024 年 3 月。我们的数据处理流水线包括质量过滤和去重。
5. 评估
一般来说,我们谨慎对待基准测试,因为它们只部分相关于实际应用中重要的内容,并且还容易引发操纵系统以夸大数据。尽管如此,我们还是提供了一些指示性结果。
5.1 学术基准测试
我们报告了一系列标准学术基准测试的结果:
- 常识推理:HellaSwag (10-shot) [47],WinoGrande (5-shot) [37],ARC-E (0-shot) 和 ARC-Challenge (25-shot) [9],以及 PIQA (zero-shot) [3]。
- 阅读理解:BoolQ (10-shots) [8] 和 QuAC (zero-shot) [5]。
- 其他:GSM8K (3-shot CoT) [10],HumanEval (pass@1) [4],Natural Questions closed-book (NQ; 5-shot) [26],以及 TruthfulQA (zero-shot) [27]。
- 聚合基准测试(Aggregate benchmarks):MMLU (5-shot) [20] 和 BBH (3-shot) [43]。

表 2 比较了 Jamba 与几个公开可用的模型在评估语言模型的常见学术基准测试上的表现。我们将其与具有大致相同数量的活跃参数的 Llama-2 13B [45] 进行了比较,还有比我们的模型更大的Llama-2 70B,具有 7B 参数的 Gemma [44],以及与我们的模型大致相同数量的活跃参数和总参数的 Mixtral [23]。
值得注意的是,Jamba 的性能与相似或更大尺寸的最先进公开可用模型相当,包括 Llama-2 70B 和 Mixtral。与此同时,我们的模型的总可用参数比 Llama-2 少(52B vs 70B)。此外,作为一个稀疏模型,Jamba 只有 12B 活跃参数,与 Mixtral 的 12.9B 活跃参数相似。然而,作为一个完全注意力的模型,Mixtral 在长序列下具有很大的内存占用,需要 32GB 的 KV 缓存来处理 256K 个 token。相比之下,由于其混合 Attention-Mamba 架构,即使在这样的长的上下文下,Jamba 的 KV 缓存也只需 4GB(第 2 节)。重要的是,我们的 Jamba 在具有比 Llama-2 70B 和 Mixtral 更好的吞吐量的同时,实现了如此强大的性能提升(第 3.2 节)。
总之,Jamba 展示了混合架构达到与相同尺寸级别的最先进的基于 Transformer 的模型相当的性能的能力,同时具有 SSM 的优势。
5.2 长上下文评估
我们已成功训练了上下文长度长达 1M 个 token 的 Jamba 模型。发布的模型可以处理长达 256K 个 token 的上下文长度。在本节中,我们评估了它在合成和自然基准测试中对长上下文的能力。
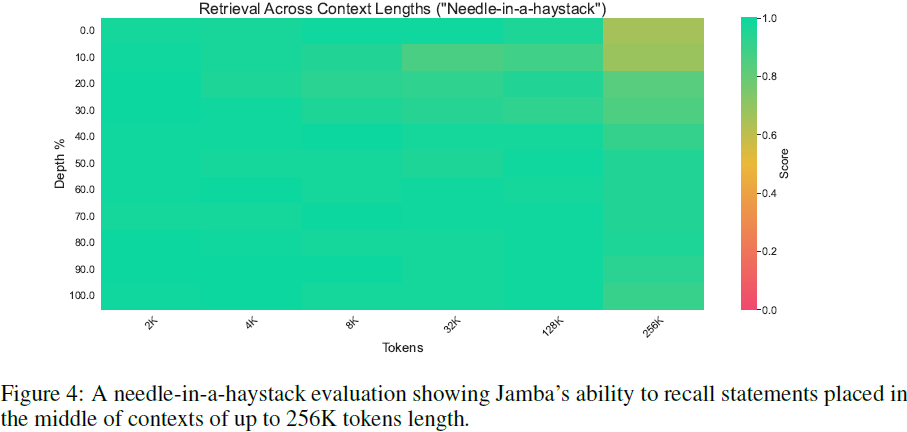
5.2.1 稻草堆中的针
如图 4 所示,Jamba 在稻草堆中的针(Needle-in-a-haystack)评估中表现出色,该评估要求在一个长的上下文窗口中检索一个简单的语句 [24]。特别是考虑到我们对 Jamba 的实现仅使用了 4 个注意力层,这一结果值得注意。
5.2.2 自然主义长上下文评估
我们评估了 Jamba 处理长上下文的能力,使用包含长输入的问答基准测试。为此,我们重新利用了 L-Eval [2] 中最长上下文数据集中的五个数据集,将它们结构化为少量示例格式(在所有实验中我们使用了 3 个示例)。具体来说,我们在以下数据集上评估了模型:NarrativeQA(叙述问答;[25]),LongFQA(金融;[2]),自然问题(NQ;维基百科;[26]),CUAD(法律;[21])和SFiction(科幻小说)。这些数据集中的平均输入长度范围从 6K 到 62K 个 token。这些上下文长度通过少量示例格式进一步扩展。

表 3 总结了评估结果,以 F1 为标准。Jamba 在大多数数据集上以及平均水平上均优于 Mixtral。此外,由于这些长上下文任务需要大量计算,在这里 Jamba 的效率得到了充分体现,具有更好的长上下文吞吐量(第 3.2 节)。
6. 消融和见解
本节讨论了我们在实现 Jamba 架构时针对不同设计选择进行的消融实验。首先,我们展示了结合 Attention 和 Mamba 层的好处,以及它们应该以何种比例结合以及如何交错它们。我们调查了纯 Mamba 失败的情况,表明它在开发上下文学习能力方面存在困难,而 Attention-Mamba 混合体表现出与纯 Transformer 相似的上下文学习能力。然后,我们展示了在混合 Attention-Mamba 模型之上添加 MoE 的好处。最后,我们分享了两个我们发现有用的额外发现:在 Jamba 中不需要显式的位置信息,而 Mamba 层需要特殊的归一化来稳定大规模训练。
对于这些消融实验,我们报告了以下指标,即使在小数据或模型规模下也显示出信息性能。
- 学术基准测试:HellaSwag(10-shot)[47],WinoGrande(5-shot)[37],Natural Questions closed-book(NQ;5-shot)[26]。
- HuggingFace OpenLLM 排行榜(OLLM)[11]:几个数据集的摘要统计。我们报告了我们的再现结果。
- 困惑度评估:我们报告了来自三个领域的文本的 log-prob(每字节)。
注:在所有的剔除实验中,“纯 Mamba” 指的是 Mamba 层与 MLP 层交错的模型。

6.1 结合注意力和 Mamba 的好处
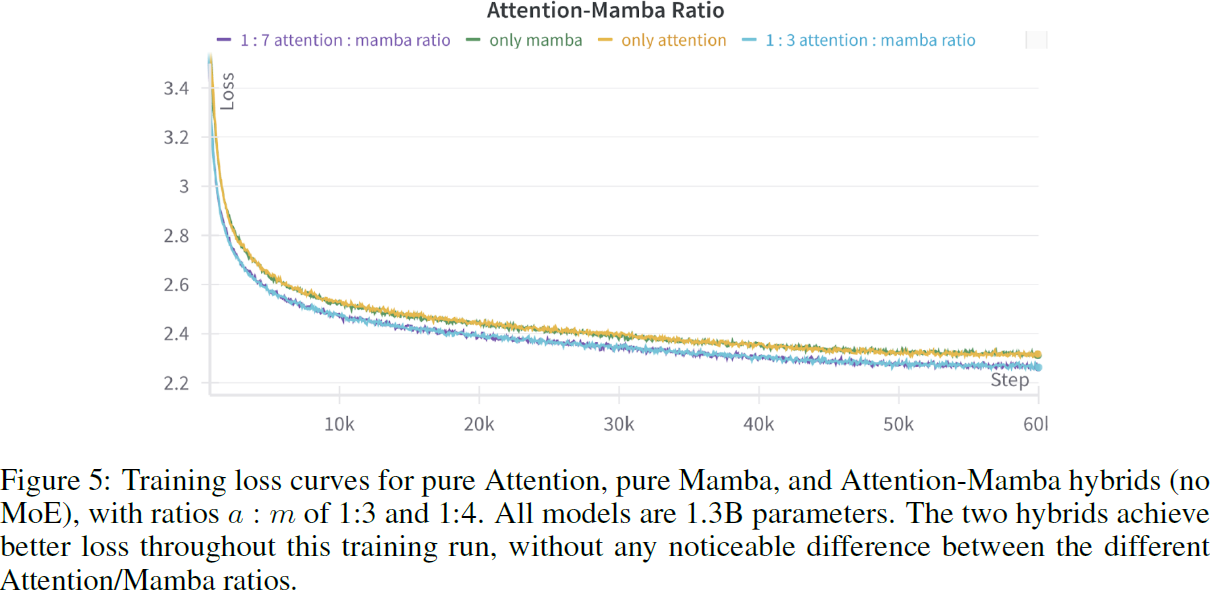
我们首先调查了注意力层和 Mamba 层的比例(a:m),使用了具有 13 亿参数的模型,训练了250亿个 token。如表 4 所示,混合 Jamba 模型的性能优于纯注意力或纯 Mamba 模型。注意力层与 Mamba 层的比例可以是 1:3 或 1:7,几乎没有性能差异。图 5 显示了这些模型的训练损失,其中 Jamba 在训练期间表现出改进的损失。鉴于 1:7 的比例更具有计算效率并且表现类似,我们选择在我们的更大规模实验中采用它。
接下来,我们比较了在 7B 模型大小下,在训练了 50B token 后,纯 Transformer、纯 Mamba 和注意力-Mamba 混合模型的性能。如表 5 所示,纯 Mamba 层相当有竞争力,但稍逊于纯Attention。而混合的注意力-Mamba(没有MoE)在获得比纯 Transformer 更好的吞吐量的同时,表现优于纯模型。


图 6 显示了这三种架构的训练损失。虽然纯 Transformer 和 Mamba 模型的收敛情况相似,但混合的 Jamba(没有 MoE)在整个运行过程中具有更低的损失。
6.2 为什么组合起来会有效?
纯 Mamba 模型在大多数任务中表现相当不错,包括一般的困惑度评估。然而,在三个常见的基准任务(IMDB [28],QuAC [5]和NarrativeQA [25])中,它的表现明显不如纯 Attention 模型。相比之下,混合的 Attention-Mamba 在这些数据集上的表现与 Attention 模型类似。表 6 显示了 250B token 后 1.3B 模型的结果。

进一步研究这些结果,我们发现纯 Mamba 模型经常不遵循正确的格式。例如,在 IMDB 数据集中,答案选择是 “正面” 或 “负面”。虽然 Attention 模型遵循这个格式,但纯 Mamba 模型经常产生其他答案,比如 “非常好”,“非常积极”,“有趣”,“坏”,“poor” 和 “3/10”。虽然这些可能被认为是正确的答案,但是 Mamba 难以遵循格式的困难暗示着潜在的问题。事实上,要进行成功的上下文学习,模型捕获输入-输出格式是很重要的。混合的 Attention-Mamba 模型成功地遵循了这个格式,就像纯 Attention 模型一样。
我们假设这种现象指向了 SSM 的一个局限性——在上下文学习(in-context learning,ICL)方面的潜在困难。事实上,在训练过程中,Transformer 语言模型出现了所谓的归纳头部(induction heads),这些头部执行了支持 ICL 的近似复制操作。我们推测,纯 Mamba 模型缺乏注意力机制,使得它难以进行上下文学习。虽然 Mamba 可能会在明确训练的情况下学会复制和执行简单的 ICL,但 SSM 中的 ICL 是否是一种新型能力尚不清楚,而这种能力在 Transformer 模型中是典型的。相比之下,混合的 Attention-Mamba 模型执行了成功的 ICL,即使其中只有 1 层是 Attention 层。
作为新出现的归纳机制的案例证据,我们在图 7 中可视化了 1.3B Attention-Mamba 混合模型(无MoE)中的一个示例头的注意力,在纯 Mamba 失败且混合模型成功的 IMDB 示例中。显然,最后一个标记(“:”)的注意力集中在少样本示例的标签上。在我们的混合模型中,我们发现了 12 个这样的头部,它们分别对应模型的第 4、12 和 20 层的所有三个注意力层。

未来的工作可以进一步探究大规模混合模型中内部学习能力的出现。我们发布的检查点希望能够促进这样的研究。最近的研究尝试从 Mamba 等状态空间模型中提取类似于注意力的分数,这打开了在状态空间模型中寻找归纳能力的另一个方向。
6.3 混合专家模型(MoE)的影响
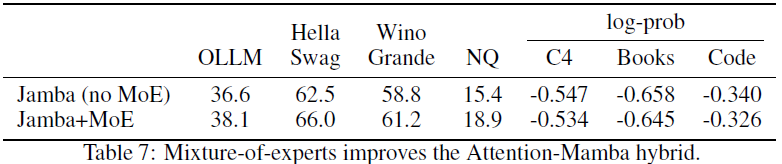
最近的研究表明,MoE 可以提高 Transformer 语言模型的性能,同时保持计算可管理性。(此外,也有初步证据表明,MoE 在小模型和数据规模上有助于 Mamba 层。) 然而,尚不清楚 MoE 是否与大规模状态空间模型以及我们的混合 Attention-Mamba 架构很好地集成。实际上,表 7 显示了 MoE 在大规模(7B 参数,训练了 50B token)的混合 Attention-Mamba 架构中的性能提升。MoE 变体的总专家数为 n = 16,每个 token 使用的专家数为 K = 2,并且 MoE 每隔 e = 2 个层应用一次,如第 3.1 节所述。
6.4 在大规模情况下稳定 Mamba
当训练参数多达 1.3B 的 Jamba 模型时,我们观察到训练稳定,没有特殊问题。然而,当扩展到本文发布的最大模型(7B 型,具有 12B/52B 的活跃/总参数)时,我们遇到了大的损失峰值。调查发现,Mamba 层的内部部分存在较大的激活值,导致峰值。因此,我们在内部激活中添加了RMSNorm [48]。如图 8 所示,这稳定了训练并防止了额外的损失峰值。


6.5 Jamba 不需要显式的位置信息
表 8 显示了使用 Jamba 架构(带有 MoE)且没有位置信息以及在注意力层应用 RoPE [42] 时的结果(1.3B 参数模型,250B token)。结果是相似的,这表明混合架构可能不需要显式的位置信息。可能,位于注意力层之前的 Mamba 层提供了隐式位置信息。(一些先前的证据表明, Transformer 解码器模型不需要位置编码。然而,所有现有的大规模模型都使用某种显式位置信息。)
7. 结论
我们介绍了 Jamba,这是一个新颖的架构,结合了注意力和 Mamba 层,具有 MoE 模块,并对其进行了开放实现,达到了最先进的性能并支持长上下文。我们展示了 Jamba 如何在平衡性能和内存需求的同时保持高吞吐量方面提供了灵活性。我们尝试了几种设计选择,例如 Attention- Mamba 层的比率,并讨论了开发过程中做出的一些发现,这将为混合注意力-状态空间模型的未来工作提供参考。为了促进这样的研究,我们计划发布从较小规模的训练运行中获得的模型检查点。在此次发布中,我们提供的最大模型具有 12B 的活跃参数和 52B 的总可用参数,支持长达 256K 个 token 的上下文长度,并且即使在处理 140K 个 token 的文本时,也适合于单个 80GB GPU。

