
- 1新平面视觉:多种艺术风格ai转换技巧_平面场景风格转换
- 2小白也会SQL:大模型改变交互方式(中)_基于text-to-sql(文本转结构化查询语言)技术的resdsql模型
- 3GitHub Actions CI/CD 解放码农双手_github upload artifact不保留路径
- 4【2024最强最火教程】一文搞定 Postman 接口自动化测试!_2024postman 使用教程
- 5车路协同 智能路侧决策系统总体架构及应用_车联网协同决策
- 6大麦网抢票软件工具开发系列(一)_大麦抓包
- 7《编程人生》读书笔记
- 8网络攻防--网络防御技术
- 9多台服务器免密登录_aix免密钥互相登陆
- 10今日热点 | RedisJson 横空出世,惊呆ES和Mongo_redisjson官网
Spark的模块组成(入门必看)_spark组成
赞
踩
前言
上期文章,介绍了Spark不仅能够在内存中进行高效运算,还是一个大一统的软件栈,可以适用于各种各样原本需要多种不同的分布式平台的场景。接下来简要介绍Spark的模块组成。
本期学习目标
- Spark的模块组成
- Spark Core
- Spark SQL
- Spark Streaming
- MLlib
- GraphX
- SparkR
Spark的模块组成
Spark的各个组成模块如下:
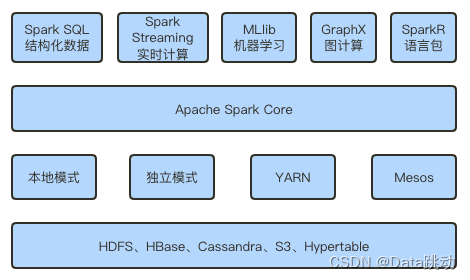
- Spark 基于 Spark Core 建立了 Spark SQL、Spark Streaming、MLlib、GraphX、SparkR等核心组件;
- 基于这些不同组件又可以实现不同的计算任务;
- 这些计算任务的运行模式有:本地模式、独立模式、YARN、Mesos等;
- Spark任务的计算可以从HDFS、HBase、Cassandra等多种数据源中存取数据。
Spark Core
Spark Core实现了Spark基本的核心功能,如下:
-
基础设施
SparkConf :用于定义Spark应用程序的配置信息;
SparkContext :为Spark应用程序的入口,隐藏了底层逻辑,开发人员只需使用其提供的API就可以完成应用程序的提交与执行;
SparkRPC :Spark组件之间的网络通信依赖于基于Netty实现的Spark RPC框架;
SparkEnv :为Spark的执行环境,其内部封装了很多Spark运行所需要的基础环境组件;
ListenerBus :为事件总线,主要用于SparkContext内部各组件之间的事件交互;
MetricsSystem :为度量系统,用于整个Spark集群中各个组件状态的监控; -
存储系统
用于管理Spark运行过程中依赖的数据的存储方式和存储位置,Spark的存储系统首先考虑在各个节点的内存中存储数据,当内存不足时会将数据存储到磁盘上,并且内存存储空间和执行存储空间之间的边界也可以灵活控制。 -
调度系统
DAGScheduler :负责创建job、将DAG中的RDD划分到不同Stage中、为Stage创建对应的Task、批量提交Task等;
TaskScheduler :负责按照FIFO和FAIR等调度算法对Task进行批量调度; -
计算引擎
主要由内存管理器、任务管理器、Task、Shuffle管理器等组成。
Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的程序包,支持使用 SQL 或者 Hive SQL 或者与传统的RDD编程的数据操作结合的方式来查询数据,使得分布式数据的处理变得更加简单。
Spark Streaming
Spark Streaming 提供了对实时数据进行流式计算的API,支持Kafka、Flume、TCP等多种流式数据源。此外,还提供了基于时间窗口的批量流操作,用于对一定时间周期内的流数据执行批量处理。
MLlib
Spark MLlib 作为一个提供常见机器学习(ML)功能的程序库,包括分类、回归、聚类等多种机器学习算法的实现,其简单易用的 API 接口降低了机器学习的门槛。
GraphX
GraphX 用于分布式图计算,比如可以用来操作社交网络的朋友关系图,能够通过其提供的 API 快速解决图计算中的常见问题。
SparkR
SparkR 是一个R语言包,提供了轻量级的基于 R 语言使用 Spark 的方式,使得基于 R 语言能够更方便地处理大规模的数据集。
以上是本期分享,如有帮助请大家记得 点赞+关注+收藏 支持下哦~
下期讲解 Spark 的集群架构。
Spark系列 :
干货!Spark概述(入门必看)


