
- 1双目相机视差测距_双目测距算法
- 2AI一键自动生成论文神器|如何3小时快速搞定论文?超全ChatGPT论文技巧【建议收藏】
- 3RAGFlow:引领OCR与文档解析技术革新的下一代RAG引擎
- 4FPGA控制AD7606_AD7606解读_csdn ad7606
- 5jenkins持续集成接口自动化测试_jenkins 自动化接口测试
- 6关于Windows10系统启用SMB文件共享支持服务_win10 smb服务
- 7Python量化交易——投资组合的评价和可视化(上):计算收益率、波动率、最大回撤、阿尔法alpha、贝塔beta、夏普率Sharp等指标【源码+详解】_基于python的投资组合收益率与波动率的数据分析
- 8Three.js杂记(十四)———— 汽车展览·上
- 9Java下载安装JDK教程-MacOS M_mac 安装jdk21
- 10定时炸弹(闹钟)
小白也会SQL:大模型改变交互方式(中)_基于text-to-sql(文本转结构化查询语言)技术的resdsql模型
赞
踩
大模型技术论文不断,每个月总会新增上千篇。这个专栏的解读的精选论文均围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。当然最重要的是订阅跟随“鲁班模锤”。
在人工智能与自然语言处理交汇点,有一种技术正悄然改变与数据交互的方式——将日常语言转化为精准SQL查询。这一“text-to-sql”转换任务,使非专业人士也能轻松驾驭复杂的数据库操作,极大地拓宽了数据应用的边界。
然而,现有前沿方法往往依赖于封闭源代码的大型语言模型,它们虽然功能强大,却伴随着模型透明度缺失、数据隐私风险增大以及高昂推理成本等难题。有没有既开放、高效又安全的替代方案呢?鲁班模锤今天带来的论文《CodeS: Towards Building Open-source Language Models for Text-to-SQL》正在尝试破局。本章节将承接上一篇,有兴趣的同学可以仔细推敲。

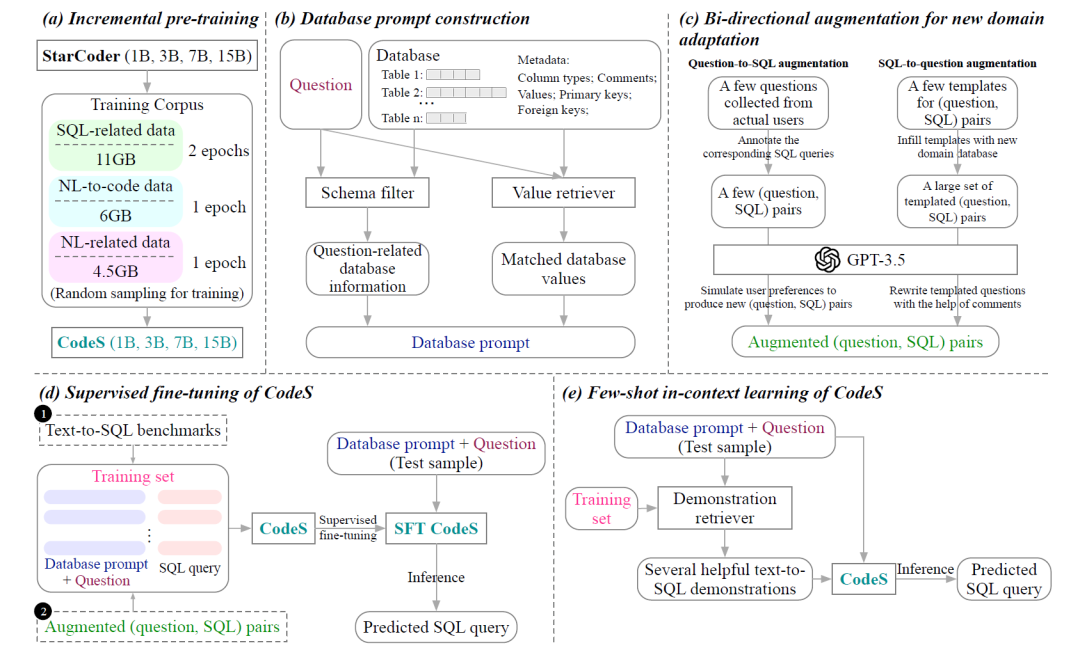
模块A:增强的预训练
要让模型能够从文本生成SQL,模型必须具备两种能力:SQL生成能力和自然语言理解能力。为了增强模型的生成能力,训练数据集从三个方向收集了语料:SQL相关数据(SQL-related data)、自然语言相关数据(natural language-related data)、自然语言转代码数据(natural language-to-code data)。
SQL相关数据一共11GB,采用了StarCoder的预训练语料库中的SQL段。
自然语言相关数据一共4.5GB,从3个途径获得:
途径一:Alpaca-cleaned ,斯坦福大学发布的原始羊驼数据集的清理版本。Alpaca是一个包含52,000条指令和演示的数据集,这些指令和演示由OpenAI(text-davinci-003)的引擎生成。此指令数据可用于对语言模型进行指令调整,从而使语言模型更好地遵循指令。
text-davinci-003是OpenAI推出的一个基于这些理念的大规模语言模型,它经过专门训练,能够理解和执行更加复杂、具体的指令,从而在多项任务中展现出更高的灵活性和准确性。
途径二:Unnatural-instructions是大规模的指令遵循数据集,其收集过程几乎不需要人工。使用三个上下文演示 x1、x2、x3 的种子来创建一个包含指令、输入和输出的大型 NLP 任务数据集。第一步,先从语言模型M中对指令、输入和约束进行采样。第二步,使用 M 生成相应的输出。最后,数据可用于指令调优。这里的M用的是GPT-3 的text-davinci-002。

途径三:UltraChat多回合对话数据集,通过迭代调用两个不同的GPT-3.5 API 生成,其中一个扮演用户角色生成查询,另一个生成响应。通过设计过的提示来指导用户模型,使其模仿人类用户的行为,并迭代地调用这两个API,最后,生成的对话会再次处理和过滤来提高质量。
其中,途径一和二为单轮对话,途径三为多轮对话数据集。
自然语言转代码数据一共6GB。为了弥补自然语言提问与SQL查询之间的差距,预训练的语料从4中途径获得。
途径一:CoNaLa 和 StaQC从 Stack Overflow 自动衍生而来,涵盖了大量自然语言到Python代码以及自然语言到SQL查询语句的配对样本。CoNaLa从网站爬取,经过自动筛选后,再由注解员进行细致整理,最终分为2,379个训练样本和500个测试样本。

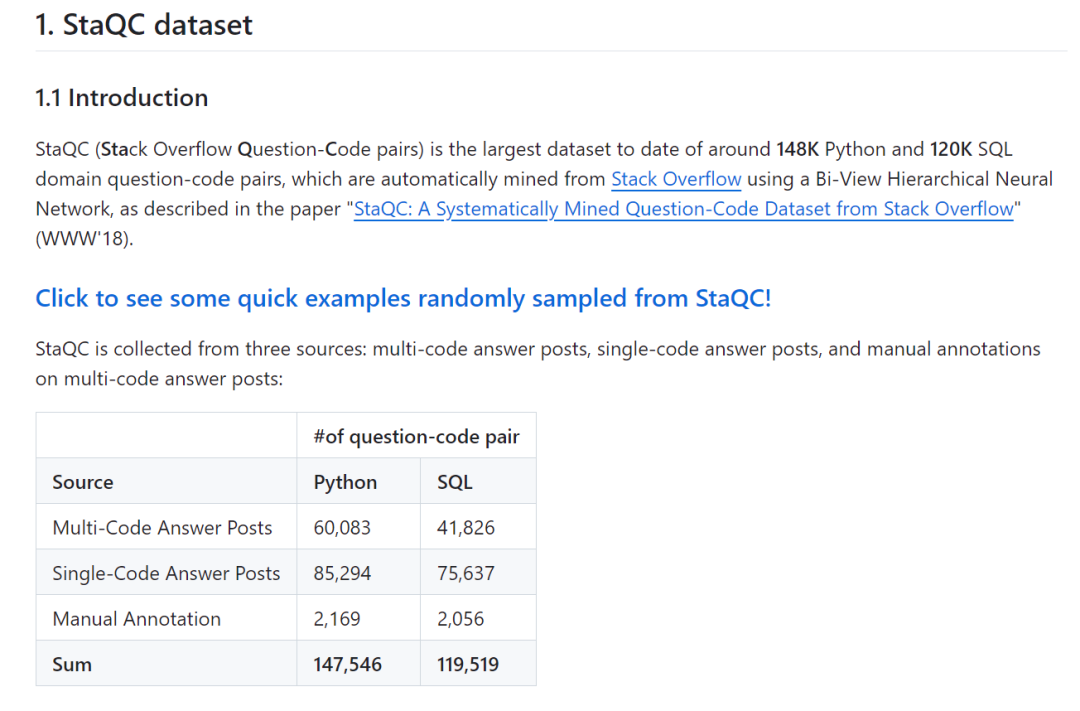
StaQC 是一个大型数据集,包含大约14.8万个Python领域和12万个SQL领域的问题-代码对,这些数据对是通过使用双向视图层次神经网络自动从Stack Overflow上挖掘得到的。StaQC的数据收集自三个来源:含有多代码答案的帖子、含单一代码答案的帖子,以及对含多代码答案帖子的手动注解。
途径二:CodeAlpaca-20k,通过Self-Instruct论文技术生成的20k条指令遵循数据集,该数据集用于Code Alpaca 模型微调
途径三:Jupyter-structured-clean-dedup,StarCoder 预训练语料库的一部分,它包含了一个庞大的结构化 Jupyter Notebook集合。这些Notebook不仅包含了代码,还附有相应的自然语言说明,为理解和执行代码提供了丰富的上下文
途径四:NL-SQL-458K,论文作者们创建的数据集,首先使用正则表达式从三大开源语料库:The Pile 、The Stack以及 GitHub Code5 中提取所有“SELECT”查询。接着,滤除有语法错误的查询,最终得到45.8万个SQL查询。为了为每个SQL查询生成相应的自然语言提问,利用了GPT-3.5,借助8个配对(SQL,问题)示范的提示来进行生成。

CodeS训练小细节
在完成语料的准备之后。CodeS基于StarCoder构建,对StarCoder 进行增量预训练时,在SQL相关数据上进行了两个epoch,在自然语言相关数据和自然语言转代码数据上各进行一个epoch。这种自然语言与代码的混合训练方式为两个领域的广泛任务带来了好处。
训练过程中通过采用 AdamW 优化器来最大化序列的概率,学习率设定为5

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

