
热门标签
热门文章
- 1PyCharm报错:Non-zero exit code (2)_pycharm报错non-zero exit code(2)
- 2Android Studio实现简单的自定义钟表_android studio时钟
- 3社交口才艺术:如何成为一个会说话的人
- 4python 股票数据挖掘_Python源代码,数据挖掘股票交易数据
- 5Docker安装mysql8.0
- 6数据结构之线性表算法的构建与应用_l->length >= maxsize
- 7SparkSQL Driver ClassNotFoundException的解决方案
- 8Qt/C++开源作品4-网络调试助手_网络调试助手4
- 9android应用去掉状态栏_android去掉状态栏
- 10MacOS安装python,报错“zsh: command not found: python”_mac zsh: command not found: python
当前位置: article > 正文
LLaMA系列模型_llama模型
作者:2023面试高手 | 2024-05-19 22:17:28
赞
踩
llama模型
1.LLama
1.1 简介
Open and Efficient Foundation Language Models (Open但没完全Open的LLaMA)
2023年2月,Meta(原Facebook)推出了LLaMA大模型,使用了1.4T token进行训练,虽然最大模型只有65B,但在相关评测任务上的效果可以媲美甚至超过千亿级大模型,被认为是近期开源大模型百花⻬放的开端之一,“羊驼”系列模型及其生态快速发展。
LLaMA 所采用的 Transformer 结构和细节,与标准的 Transformer 架构不同的地方包括采用了前置层归一化(Pre-normalization)并使用 RMSNorm 归一化函数 (Normalizing Function)、激活函数更换为 SwiGLU,并使用了旋转位置嵌入(RoP),整体 Transformer 架构与 GPT-2 类似。
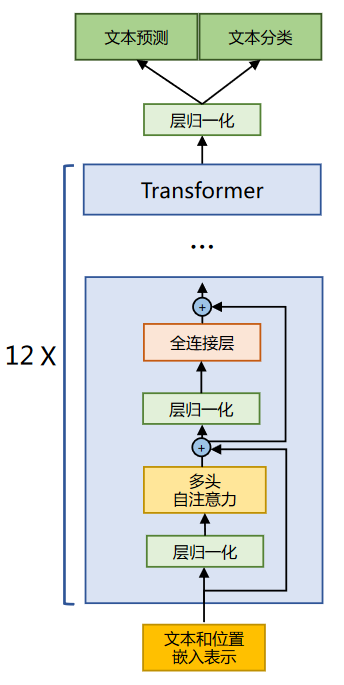
1.2 RMSNorm归一化函数
为了使得模型训练过程更加稳定,GPT-2 相较于 GPT 就引入了前置层归一化方法,将第一个层归一化移动到多头自注意力层之前,第二个层归一化也移动到了全连接层之前,同时残差连接的位置也调整到了多头自注意力层与全连接层之后。层归一化中也采用了 RMSNorm 归一化函数。 针对输入向量 aRMSNorm 函数计算公式如下
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/594881
推荐阅读
相关标签

