
热门标签
热门文章
- 1深度学习模型PyTorch训练并转ONNX与TensorRT部署_转onnx模型,再转tensorrt 部署服务器
- 2关于Bin文件的解析_单片机怎么读取bin文件内容
- 3Docker:基础概念、常用命令
- 4xCode5.0使用iOS6.1SDK及模拟器_ios 6.1sdk下载
- 5【附源码】仓库管理系统(源码+毕业论文+答辩ppt齐全)java开发ssm框架javaweb,可做计算机毕业设计或课程设计_仓库管理系统代码
- 6git-怎样把连续的多个commit合并成一个?_git 合并中间相邻的commit
- 7C/C++:动态内存管理_使用c++连续动态内存管理模拟实现
- 8java中string 类型的对象间比较的学习笔记
- 9SpringBoot 项目_springboot项目
- 10Vue.js的发展史(一)
当前位置: article > 正文
大模型部署手记(14)Chinese-LLaMA-Alpaca-2+Ubuntu+vLLM_vllm大模型部署教程
作者:从前慢现在也慢 | 2024-05-17 13:30:09
赞
踩
vllm大模型部署教程

1.简介:
组织机构:Meta(Facebook)
代码仓:https://github.com/facebookresearch/llama https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
模型:chinese-alpaca-2-7b-hf
下载:使用百度网盘下载
硬件环境:暗影精灵7Plus
Ubuntu版本:18.04
内存 32G
GPU显卡:Nvidia GTX 3080 Laptop (16G)
2.代码和模型下载
chinese-alpaca-2-7b-hf的模型从官网下载:
将chinese-alpaca-2-7b-hf的模型传到 ~/models目录下:

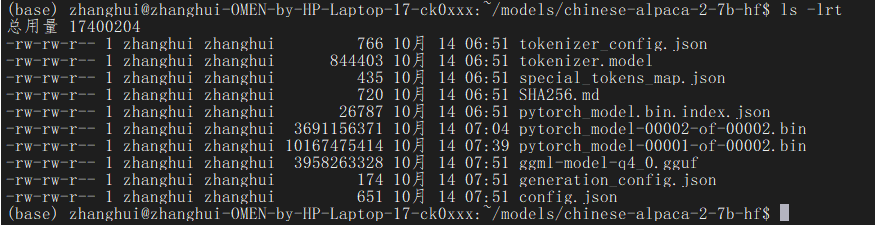
3.安装依赖
conda create -n vllm310 python=3.10 -y
conda activate vllm310
pip install chardet

pip install vllm



4.部署验证
准备脚本:
cd ~/vllm
vi test_vllm.py
- # 导入 vLLM 所需的库
-
- from vllm import LLM, SamplingParams
-
- # 定义输入提示的列表,这些提示会被用来生成文本
-
- prompts = [
-
- "[INST] <<SYS>>\nYou are a helpful assistant. 你是一个乐于助人的助手。\n<</SYS>>\n\n [/INST] 你好,我叫",
-
- "[INST] <<SYS>>\nYou are a helpful assistant. 你是一个乐于助人的助手。\n<</SYS>>\n\n [/INST] 意大利国的总统是",
-
- "[INST] <<SYS>>\nYou are a helpful assistant. 你是一个乐于助人的助手。\n<</SYS>>\n\n [/INST] 尼日利亚的首都是",
-
- "[INST] <<SYS>>\nYou are a helpful assistant. 你是一个乐于助人的助手。\n<</SYS>>\n\n [/INST] 人工智能的未来是",
-
- ]
-
- # 定义采样参数,temperature 控制生成文本的多样性,top_p 控制核心采样的概率
- sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=512)
-
-
- # 初始化 vLLM 的离线推理引擎,这里选择的是 "/root/chinese-llama2" 模型
- llm = LLM(model="/home/zhanghui/models/chinese-alpaca-2-7b-hf")
-
- # 使用 llm.generate 方法生成输出文本。
- # 这会将输入提示加入 vLLM 引擎的等待队列,并执行引擎以高效地生成输出
- outputs = llm.generate(prompts, sampling_params)
-
- # 打印生成的文本输出
- for output in outputs:
- prompt = output.prompt # 获取原始的输入提示
- generated_text = output.outputs[0].text # 从输出对象中获取生成的文本
- print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

运行脚本:
python test_vllm.py
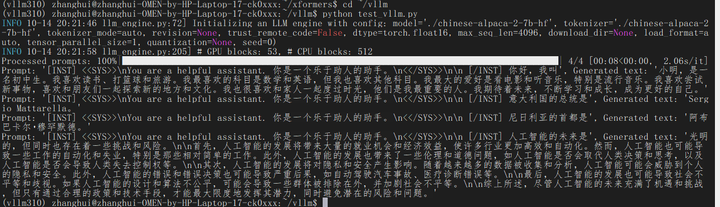
运行成功。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/583792
推荐阅读
相关标签

