
- 1将ElasticSearch的查询结果转为实体类_searchhits转list
- 2苹果 m1 芯片下运行 flink 程序使用 rocksdb 状态后端兼容性问题_flink硬件系统兼容
- 3在做题中学习(54):点名
- 4HT1656 串口配置
- 52024就业热门方向有哪些?这个行业竟然排第一!_优橙教育
- 6公共数据库周报:孟德尔随机化方法
- 7docker部署kafka_docker 部署kafka
- 8rust打包编译为mac或者linux可执行文件,发送到别的电脑不能运行
- 9R数据分析:工具变量回归与孟德尔随机化,实例解析_孟德尔随机化共定位
- 10第四篇【传奇开心果微博系列】Python微项目技术点案例示例:美女颜值判官(1)
大模型部署手记(19)Ubuntu+JupyterLab+Nemo+Llama2+llama-index+语音对话机器人_ubuntu 大模型
赞
踩

参考 大模型部署手记(18)Windows+JupyterLab+Nemo+Llama2+llama-index+语音对话机器人-云社区-华为云
我们把标题换一个单词,然后试试。
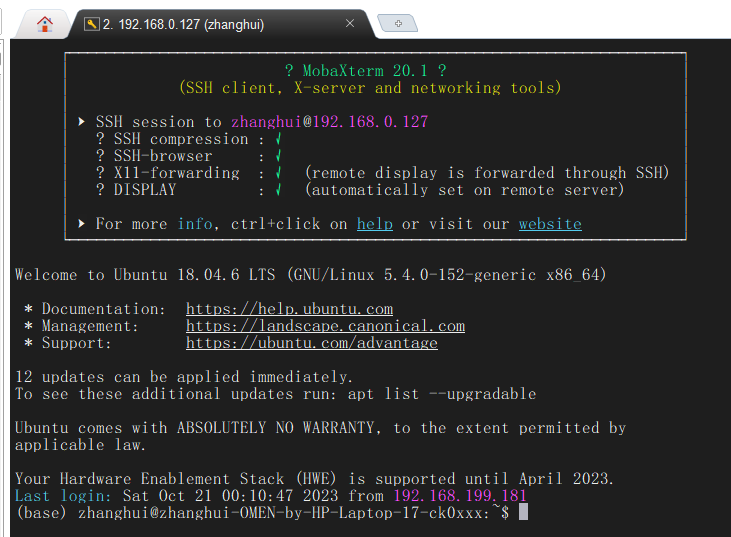
首先,我们使用一台Windows电脑连上这台装了双系统的暗影精灵的ubuntu系统,
使用MobaXterm登录:
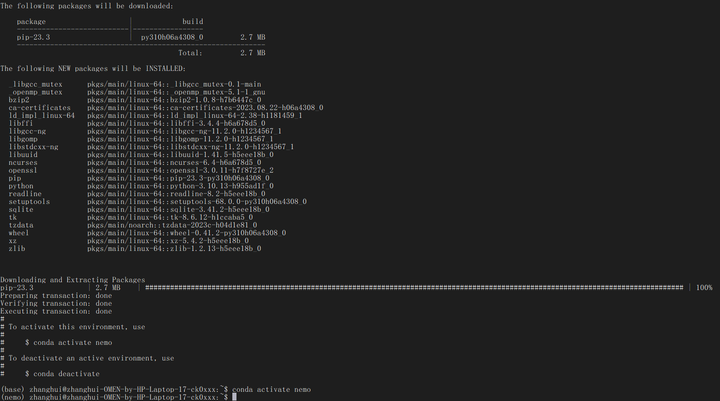
conda create -n nemo python=3.10 -y
conda activate nemo
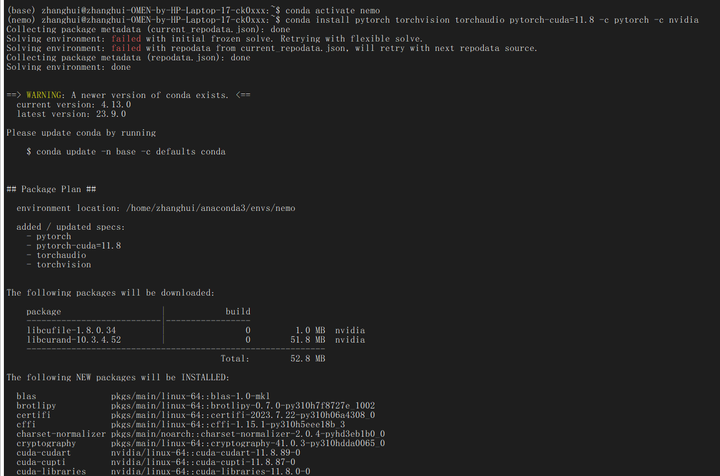
安装Pytorch:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
安装Nemo:
sudo apt-get update
sudo apt-get install -y libsndfile1 ffmpeg

pip install Cython -i https://pypi.tuna.tsinghua.edu.cn/simple

pip install nemo_toolkit['all'] -i https://pypi.tuna.tsinghua.edu.cn/simple
需要经过漫长的安装过程,请耐心等待:
cd ~
#git clone https://github.com/NVIDIA/NeMo.git
#git clone https://github.com/wnger/nemo-api.git
#cd nemo-api
#python test.py
安装llama-index
pip install llama-index -i https://pypi.tuna.tsinghua.edu.cn/simple
安装下jupyterLab
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple

pip install jupyterlab -i https://pypi.tuna.tsinghua.edu.cn/simple
好像确实不需要装。
在ubuntu创建 nemo-llama目录:
cd ~
mkdir nemo-llama
将两个模型目录LinkSoul和sentence-transformers、test.wav、tts_hifigan.nemo和 nemo_llama2.ipynb 、电子书book目录等都传到ubuntu后台:
在ubuntu后台运行:
jupyter-lab --generate-config

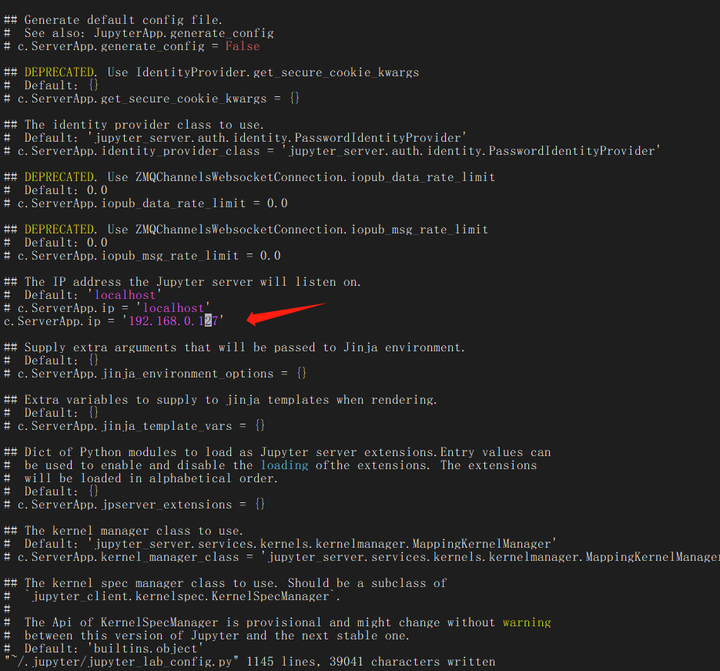
打开配置文件/home/zhanghui/.jupyter/jupyter_lab_config.py,修改代码:
c.ServerApp.allow_origin ='*'
c.ServerApp.ip ='192.168.0.127'
设置成服务器ip

jupyter lab --no-browser
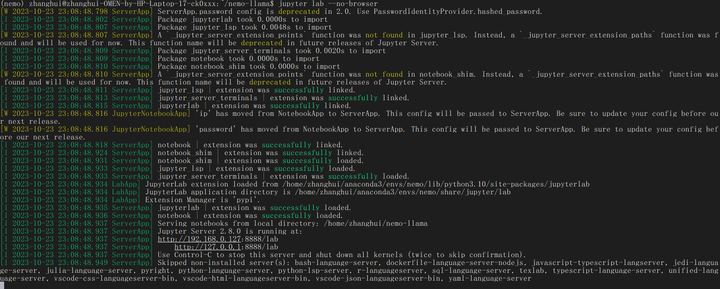
浏览器打开 http://192.168.0.127:8888/lab
居然要输入密码,通过jupyter lab passwd设置下看看:(密码:zhanghui)
输入密码后,耐心等待:
进入第一个notebook:
双击打开左边的 jupyter脚本:nemo_llama2.ipynb

依次执行看看:
0.导入Nemo工具库及相关工具类
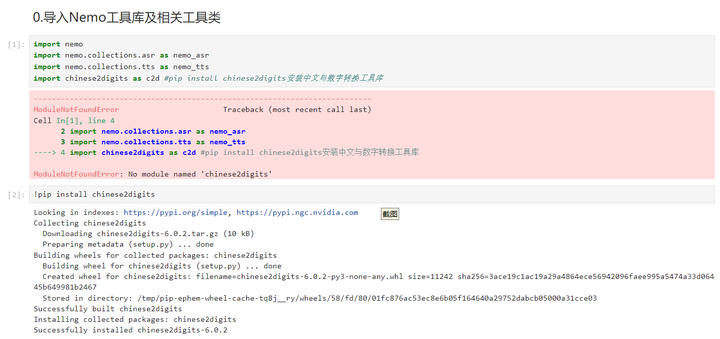
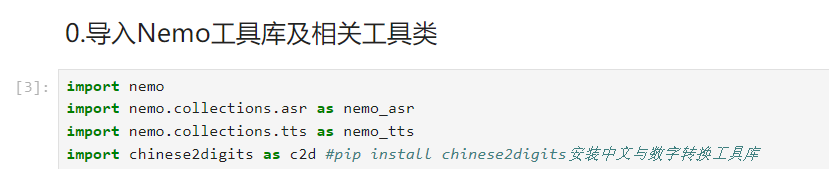
1.构建机器的“耳朵”实现听写的过程

下载了很久,终于执行完毕。

语音转文字没有问题。
2.构建机器的“大脑” 实现检索问答的过程
先执行 !pip install accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple

此时需要重启下JupyterLab,清空输出,重新执行前面的部分,然后执行本cell:

继续处理:

修改/etc/hosts文件:

修复punkt:

构建通道:
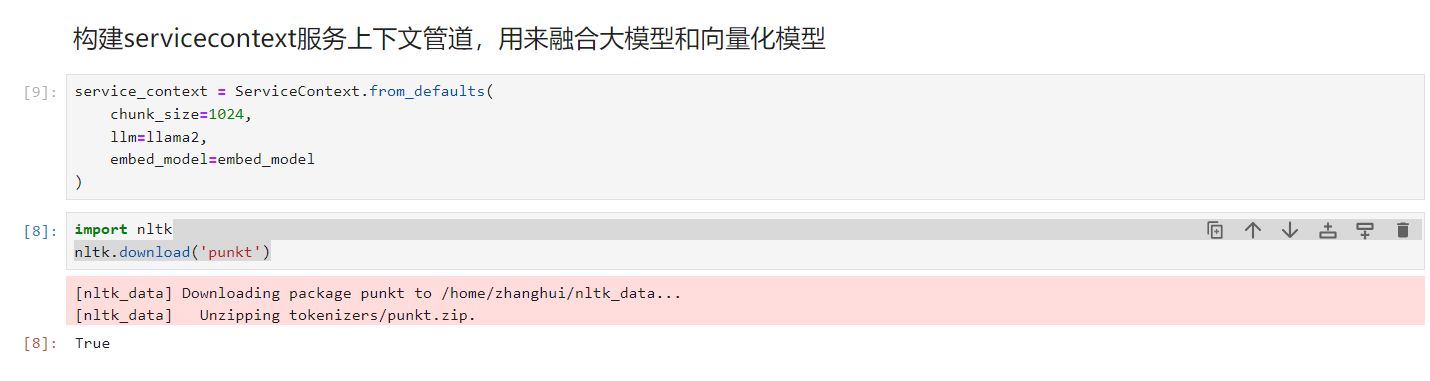
读取电子书:

这次不打印了,书的内容太多了,相信它能成功加载。。
构建向量索引数据库:

输入文字问题,并从向量数据库获得结果:

3.构建机器的“嘴巴”将文字用声音说出来
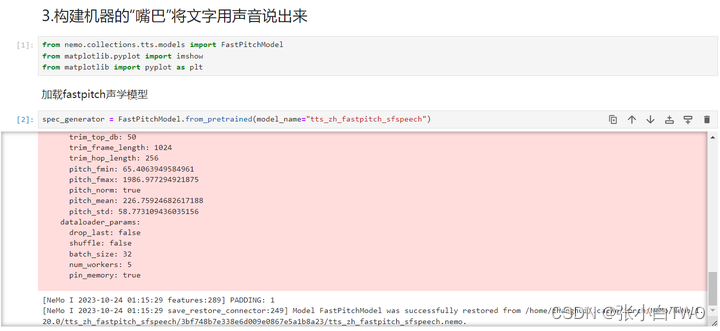
加载fastpitch声学模型

耐心等待下载完毕:

通过Fastpitch声学模型将文字转换成对应频谱图

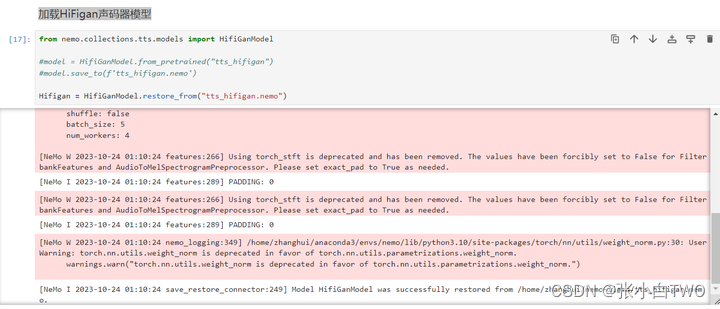
加载HiFigan声码器模型
使用HiFigan声码器将频谱图合成出语音
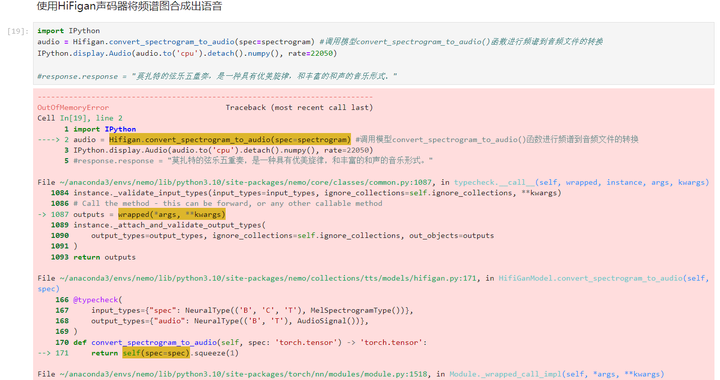

报显存不足了。重启内核,只做后面文字转语音的动作看看:
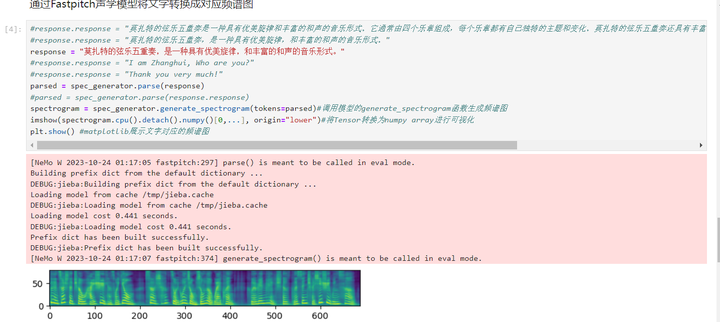

使用HiFigan声码器将频谱图合成出语音
这次语音也成功生成了!

