
- 1随笔记录(面试题
- 2armbian 安装libreoffice 转换word为PDF
- 3Docker入门实践_docker入门到实践
- 4基于Java Springboot-MySQL实现学生信息成绩管理系统(含源码+数据库+简易报告)_基于springboot的管理系统源码报告
- 5Kafka最全讲解,通俗易懂
- 6glsl算法绘图之形状(二)
- 7java实现双向循环链表(循环双链表)_java双向循环链表
- 8Do Not Go Gentle Into That Good Night
- 9centos7下安装python-pip
- 10Spark3 on Yarn分布式集群安装部署(YARN模式)_spark 3.3 安装-yarn模式
Python 万能代码模版:爬虫代码篇
赞
踩
你好,我是悦创。
很多同学一听到 Python 或编程语言,可能条件反射就会觉得“很难”。但今天的 Python 课程是个例外,因为今天讲的 **Python 技能,不需要你懂计算机原理,也不需要你理解复杂的编程模式。**即使是非开发人员,只要替换链接、文件,就可以轻松完成。
并且这些几个实用技巧,简直是 Python 日常帮手的最佳实践。比如:
- 爬取文档,爬表格,爬学习资料;
- 玩转图表,生成数据可视化;
- 批量命名文件,实现自动化办公;
- 批量搞图,加水印、调尺寸。
接下来,我们就逐一用 Python 实现,其中我提供的代码是万能代码,只用替换成你想爬的网页链接、文件位置、照片就可以进行处理了。
如果你没有安装 Python 及相关环境搭建,你可以参考我之前写的文章:
**Tips:**因为不同的章节的数据可能会交叉引用,所以建议你首先在桌面建立一个工作夹,然后每个章节都单独建立一个 Python 文件进行实验。比如可以新建一个 pytips 的目录,然后在该目录下,每个章节创建一个 tips 文件夹,里面创建对应的 .py 文件。(按你具体的来,我的文件夹也和这个不一样)
1. 巧用 Python 爬虫,实现财富自由
首先可以用 Python 来进行爬虫,什么是爬虫?简单理解来说就是抓取网络上的数据(文档、资料、图片等)。比如你考研可以爬文档和学习资料,要网络上的表格数据做分析,批量下载图片等。
下面我们来看看如何一一实现。
1.1 爬取文档、学习资料
首先,你得先确定你要爬的网站是什么?你要获取的目的是什么?比如,小悦想爬青岩帮网站中的报考指南,所以他想搜集目前该网页的所有文章的标题和超链接,以方便后续浏览。
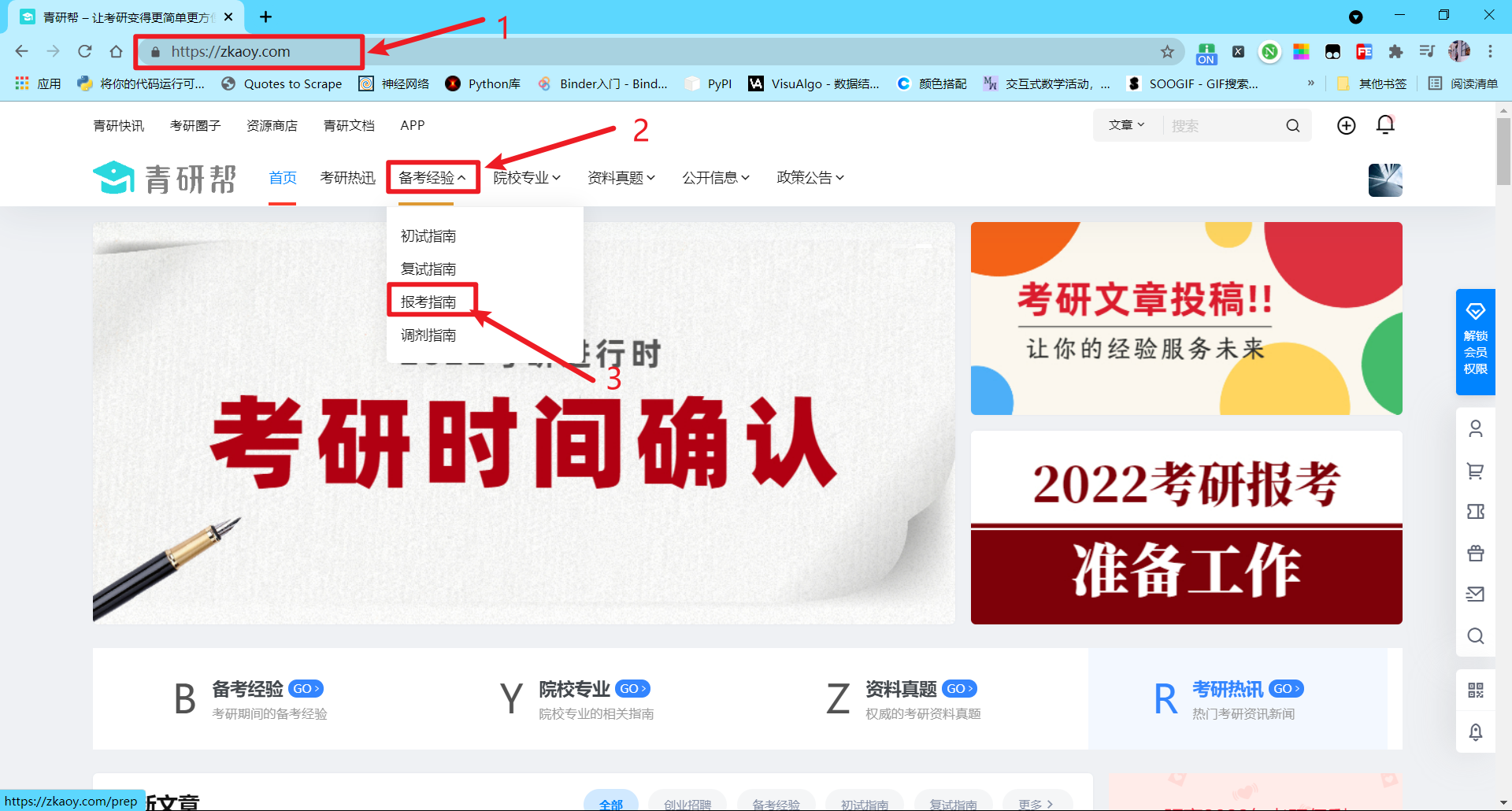
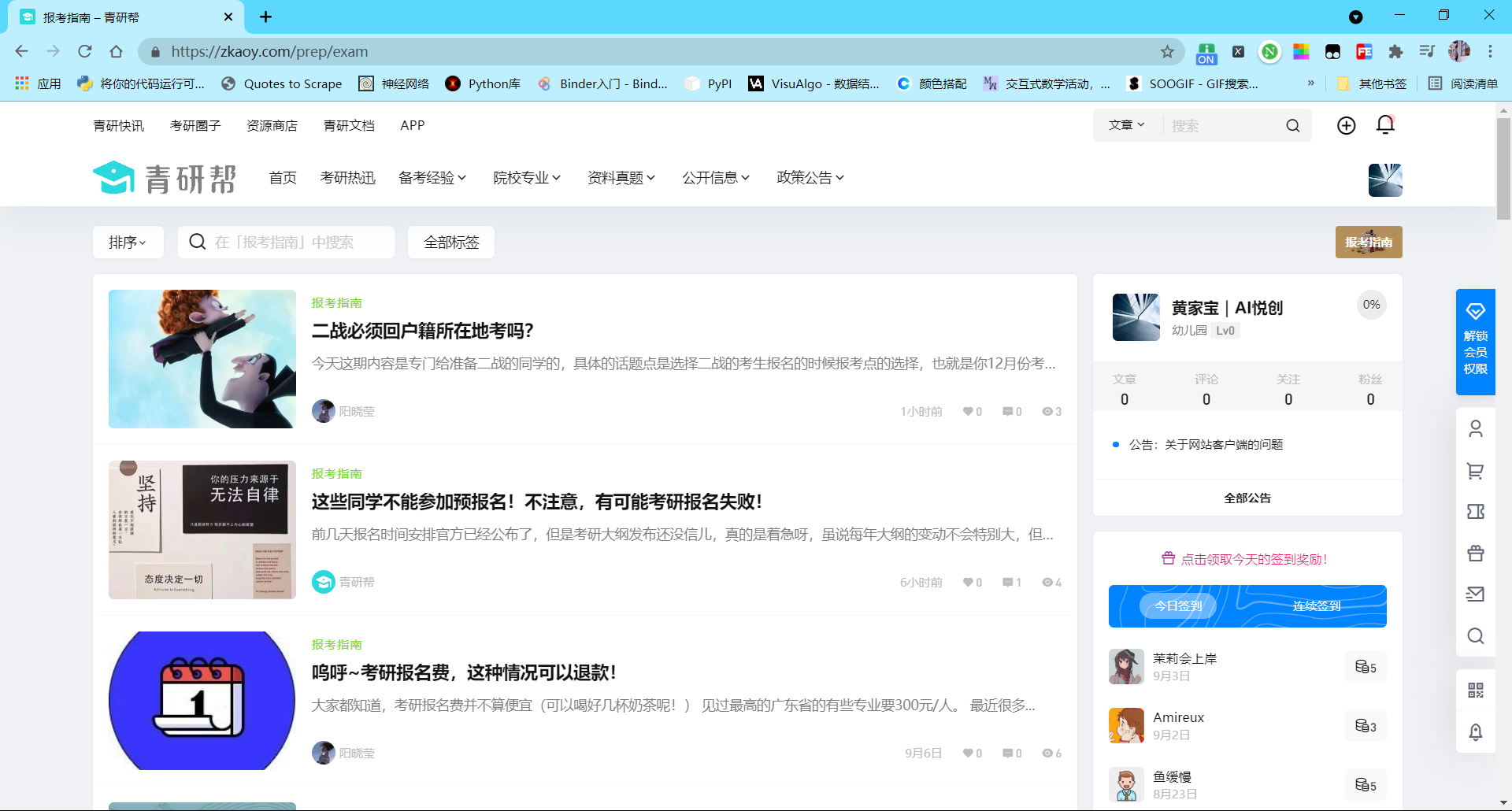
爬取网站的链接:https://zkaoy.com/sions/exam
目的:收集目前该网页的所有文章的标题和超链接
那使用 Python,可以参考以下两步的代码模板实现(提示:需要先安装 Python 依赖:urllib3 bs4)。
安装所需要的库:
pip install urllib3 BeautifulSoup4
- 1
第一步,下载该网页并保存为文件,代码如下。
**PS:**这里,我为了清晰一些,拆成两个代码文件,后面我再来一个合并成一个代码文件。
# urllib3 的方法 # file_name:Crawler_urllib3.py import urllib3 def download_content(url): """ 第一个函数,用来下载网页,返回网页内容 参数 url 代表所要下载的网页网址。 整体代码和之前类似 """ http = urllib3.PoolManager() response = http.request("GET", url) response_data = response.data html_content = response_data.decode() return html_content # 第二个函数,将字符串内容保存到文件中 # 第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量 def save_to_file(filename, content): fo = open(filename, "w", encoding="utf-8") fo.write(content) fo.close() def main(): # 下载报考指南的网页 url = "https://zkaoy.com/sions/exam" result = download_content(url) save_to_file("tips1.html", result) if __name__ == '__main__': main() # requests 代码 # file_name:Crawler_requests.py import requests def download_content(url): """ 第一个函数,用来下载网页,返回网页内容 参数 url 代表所要下载的网页网址。 整体代码和之前类似 ""

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47

