
- 1ROS1和ROS2RVIZ 代码详解_rviz源码解析
- 2聊 一聊 maven 测试相关的插件_maven-surefire-plugin 版本
- 3vue-resource请求超时timeout设置_vue-resource 设置过期时间
- 4selenium源码学习
- 5Wireshark抓包ethercat数据问题记录_ethercat抓包
- 6Llama3本地部署与高效微调入门_llama3-8b开源如何部署微调
- 7LeetCode力扣每日一题(Java):27、移除元素_leecode 27 27. 移除元素 java
- 8Stable Diffusion vs Midjunery的区别和选择_sd和mj
- 9华为手机发展史
- 10Flutter编译卡在Running Gradle task ‘assembleDebug_running gradle task 'assembledebug'...
今日arXiv最热NLP大模型论文:揭露大语言模型短板,北京大学提出事件推理测试基准
赞
踩
人工智能领域又一里程碑时刻!北京大学、北京智源人工智能研究院等机构联合推出大型事件推理评测基准 。这是首个同时在知识和推理层面全面评估大模型事件推理能力的数据集。
总所周知,事件推理需要丰富的事件知识和强大的推理能力,涉及多种推理范式和关系类型。而 的出现,让我们对大模型在这一重要领域的能力有了全新的认知。
研究人员在 上对多个常见大模型进行了全面测评,结果令人惊喜又意料之中:
-
大模型已初步具备事件推理能力,但距离人类还有不小差距;
-
不同大模型的能力参差不齐;
-
大模型能掌握事件知识,却不懂得如何高效运用。
3.5研究测试:
4研究测试:
Claude-3研究测试:
基于这些发现,研究人员进一步探索了引导大模型更好进行事件推理的新方法。他们设计的知识引导方案,让大模型的表现获得了显著提升。下面就让我们一起深入解读这篇文章,看看研究人员的智慧结晶如何推动人工智能跨越式发展。 为业界树立了创新性工作的标杆,必将激发更多学者投身于这一领域的探索。人工智能的明天,值得我们所有人满怀期待!
论文标题:
A Comprehensive Evaluation on Event Reasoning of Large Language Models
论文链接:
https://arxiv.org/pdf/2404.17513
——全面评估大模型事件推理能力的“试金石”
随着人工智能的飞速发展,大模型在各类自然语言任务中取得了令人瞩目的成绩。然而,对于事件推理这一重要能力,我们对大模型的真实水平却知之甚少。业界迫切需要一个能够全面评估其事件推理能力的“试金石”。 的诞生,正是为了填补这一空白。
那么 有哪些独特之处呢?让我们一探究竟。
首先, 开创了全新的评估模式。传统的评估方法往往只关注结果,忽视了过程。而事件推理是一个复杂的过程,既需要丰富的事件知识作为基础,又需要灵活运用各种推理技巧。 巧妙地从Schema(模式)和Instance(实例)两个层面入手,全面考察大模型的事件知识储备和推理能力,这在业界尚属首次。
其次, 的考察内容非常全面,它涵盖了因果、时序、层次等多种事件关系类型,设计了事件关系推理、事件分类等不同形式的任务。这种多维度、多角度的考察,能够全方位地测试大模型的事件推理能力,让我们对其优势和短板有更清晰的认识。
最后, 的构建过程颇具特色。它并非少数研究人员闭门造车的产物,而是融合了人工智能和人类智慧的结晶。研究团队利用 GPT-4 自动生成海量事件数据,以此保证数据规模;同时,人工标注团队对数据质量进行了严格把关,确保了数据的准确性和可靠性。这种人机协作的方式极大地提升了 的数据质量。
总的来说, 是一个全新的事件推理能力评估基准,它在评估模式、考察内容和构建方法上都有独到之处。这为全面评估大模型的事件推理能力提供了重要工具,有助于推动人工智能领域的进一步发展。
背后的“智慧密码”
要探究大模型的事件推理能力,科学的研究方法和严谨的实验设计必不可少。接下来,就让我们走进研究团队,看看他们是如何开展这项开创性工作。
评测模型与任务设计
研究人员首先精心挑选了9个在业界具有代表性的大模型,作为评测的"参赛选手"。这些模型都是自然语言处理领域的佼佼者,例如GPT-4、GPT-3.5、Qwen1.5-7B等。但它们在事件推理上的真实水平如何,还是未知数。通过在 基准上对这些模型进行系统评测,我们就能一探究竟。
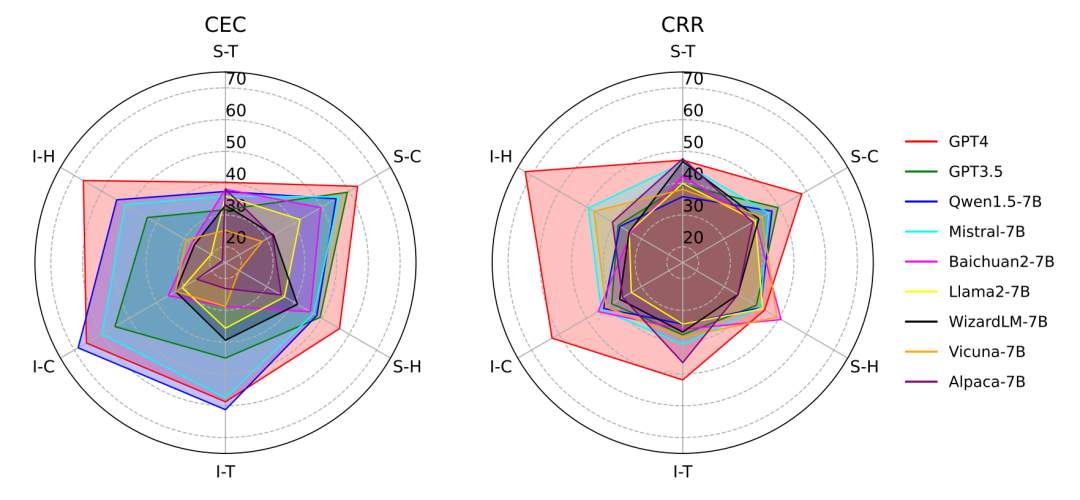
为了全面考察大模型的事件推理能力,研究团队精心设计了两大类任务:上下文事件分类(CEC)和上下文关系推理(CRR)。下图展示了CEC和CRR两类任务的一般步骤:
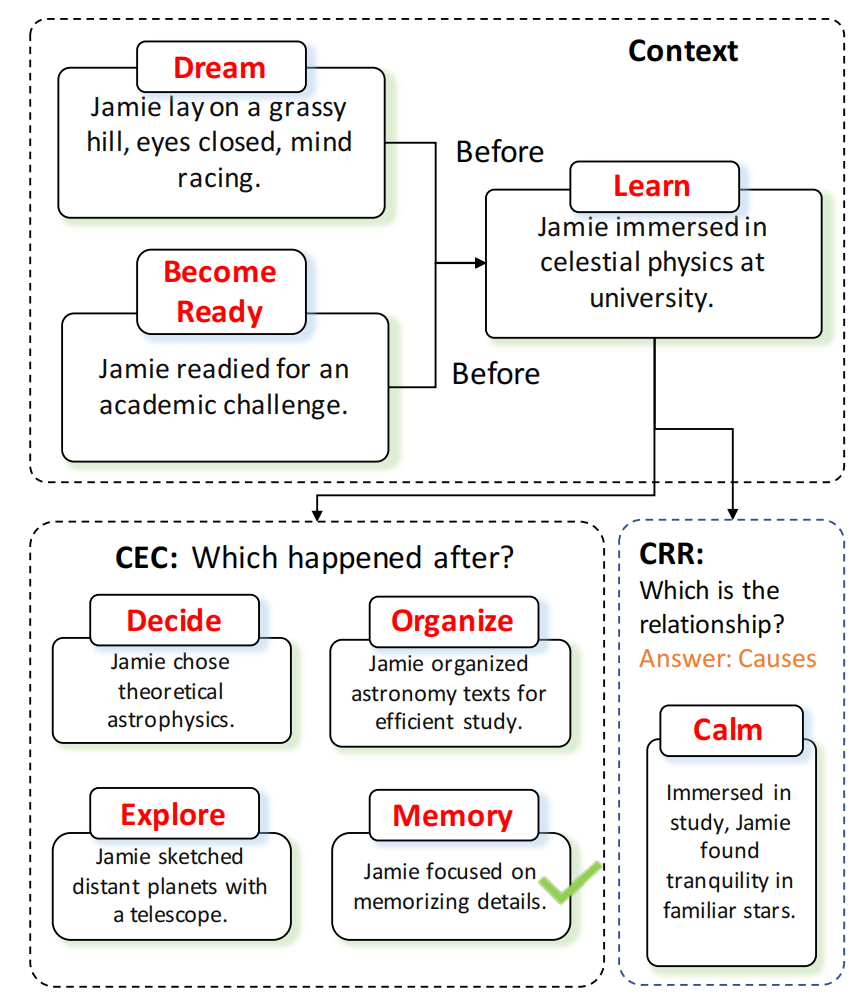
CEC任务主要考察模型在特定背景下识别事件的能力:给定一个事件和特定的关系类型,模型需要从候选事件中选出正确答案。而CRR任务则侧重于考察模型理解事件间关系的能力:给定两个事件,模型要正确判断它们之间的关系类型。这两类任务相辅相成,可以多角度评估模型的事件推理水平。
数据集构建流程
众所周知,数据质量对于模型评测至关重要。为了构建高质量的评测数据集,研究人员可谓"下足了功夫"。他们采用了三步走的策略:
-
基于EECKG知识库构建模式图。该图涵盖了丰富的事件类型及其关系,为后续工作奠定了坚实的基础;
-
利用GPT-4的生成能力,将模式图转化为实例图。通过这种方式,研究人员获得了海量的真实可信的事件实例;
-
由人工标注团队在模式图和实例图的基础上,构建CEC和CRR任务的问答数据集。标注团队的加入,进一步保证了数据的准确性和可靠性。
这种先自动生成、再人工标注的方式,既保证了数据规模,又兼顾了数据质量。可以说, 的数据集是人工智能和人类智慧协作的结晶。
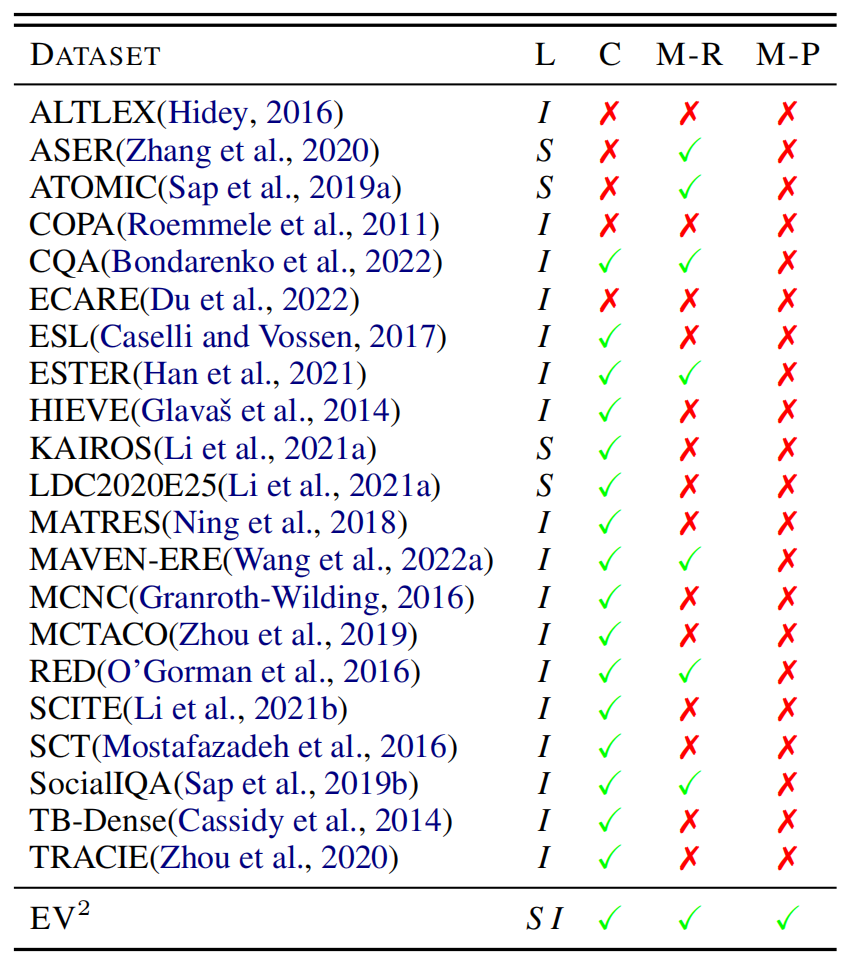
下图表示了 数据集与现有事件推理数据集之间的比较,其中表示数据集包含的层面,和分别表示模式和实例层面,表示是否符合上下文,和分别表示是否具有多重关系或范式。
知识引导方法探索
除了评测大模型的事件推理能力,研究人员还探索了如何进一步提升其表现。他们别出心裁地设计了两种知识引导方法:直接引导和基于**思维链的引导(CoT)**。
直接引导的思路很简单,就是在输入文本中直接提供事件类型知识,给模型"划重点"。而CoT引导则更有"烧脑"的味道,它启发模型先预测事件类型,再基于预测结果进行推理。通过这种思维链的方式,模型可以更好地利用事件知识进行判断。
综上所述,这项研究采用了严谨的实验设计和创新的研究方法。通过系统评测和知识引导,研究人员全面考察了大模型的事件推理能力,并探索了提升其表现的新思路。
揭秘大模型的事件推理能力
在介绍了 基准的特点和研究方法后,你是不是迫不及待地想知道实验结果了呢?别着急,接下来我就为你一一道来,让我们一起来看看大模型们在这场"考试"中的表现如何。
大模型已初具事件推理能力,但离人类还有差距
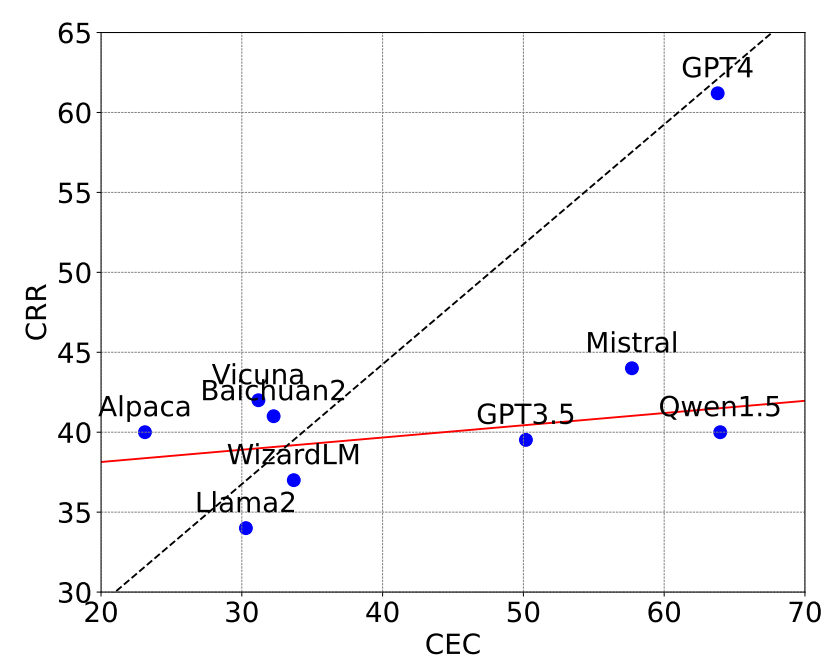
首先,让我们来看看大模型在事件推理任务上的整体表现。在实例层面的评测中,GPT-4在CEC和CRR任务上的准确率分别达到了63.80%和61.20%,远超其他模型。这个结果表明,以GPT-4为代表的大模型已经具备了一定的事件推理能力。它们能够在给定背景下正确识别事件,并判断事件之间的关系。
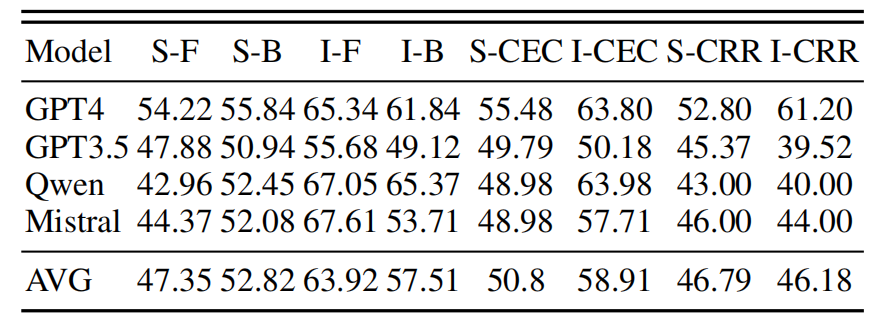
然而我们也要看到,即使是表现最好的GPT-4,其准确率也还没有达到令人满意的程度。这说明,大模型在事件推理上虽然已经初具能力,但离人类的水平还有不小的差距。要让它们真正具备人类般的事件推理能力,还需要进一步的提升。
模型在不同关系类型和任务上的表现不平衡
接下来,让我们再来看看模型在不同类型的事件关系和任务上的表现差异。
实验结果显示,所有模型在处理因果关系时的表现最好,其次是时序关系和层次关系。这说明,大模型对于不同类型的事件关系,掌握的程度是不一样的。它们似乎更擅长处理因果关系,而在时序和层次关系上还有待加强。
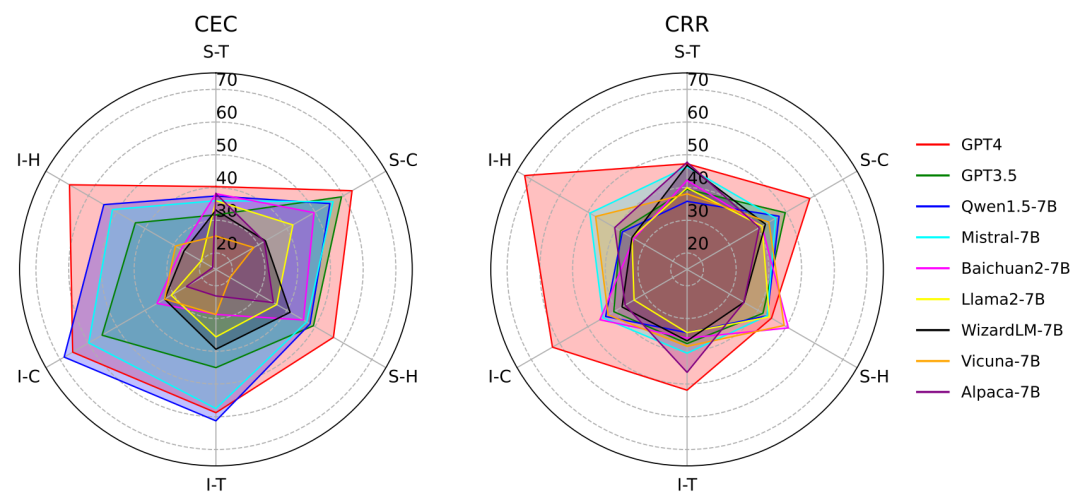
同时我们也发现,模型在CEC任务上的表现普遍优于CRR任务。这表明大模型在识别事件方面的能力,要强于理解事件间关系。这也许是因为判断事件间的关系需要更深入的推理和分析能力。
总的来说,实验结果揭示了大模型在事件推理能力上的不平衡性。它们在不同的关系类型和任务上表现出了明显的差异。这提示我们在未来的研究中要更加注重提升模型在薄弱环节上的能力,实现全面而均衡的发展。
事件模式知识的运用仍有待加强
除了考察大模型的事件推理能力,研究人员还探究了它们运用事件模式知识的情况。
随着模型发展,模型在实例层面的推理表现要好于模式层面,这表明事件模式知识落后于事件实例知识。这一发现表明,加强事件模式知识可以进一步提高模型的能力,从而获得更好的通用LLM。
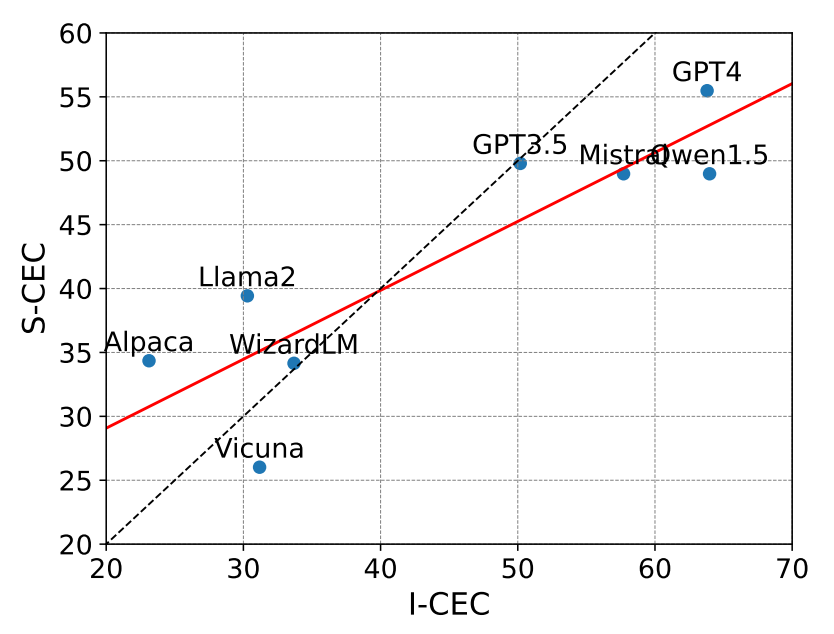
此外,作者还探讨了大语言模型在利用事件模式知识进行推理时,与人类是否一致。结果表示大语言模型在利用事件模式知识进行推理时,其方式可能与人类存在差异。换句话说,它们并没有很好地与人类的思维方式对齐。
这一发现很有启发性。它提示我们,让大语言模型学会像人类一样利用事件模式知识进行推理,可能是显著提升其事件推理能力的关键。
知识引导为大模型指明前进方向
最后,让我们来看看知识引导方法对大模型事件推理能力的影响。
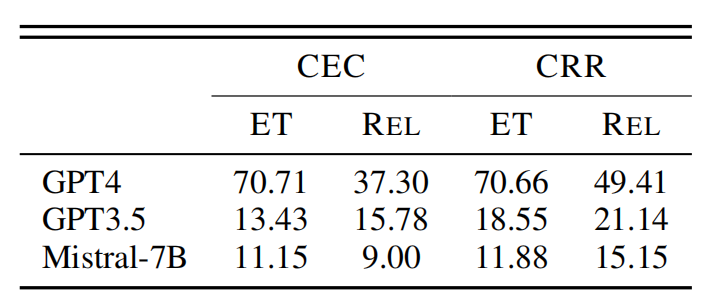
实验结果显示,无论是直接引导还是CoT引导,都能够显著提升大模型在事件推理任务上的表现。其中,直接引导对多个模型的CEC和CRR任务准确率提升最为明显,平均提升幅度超过5%。而CoT引导目前在GPT-4上也取得了积极的效果。
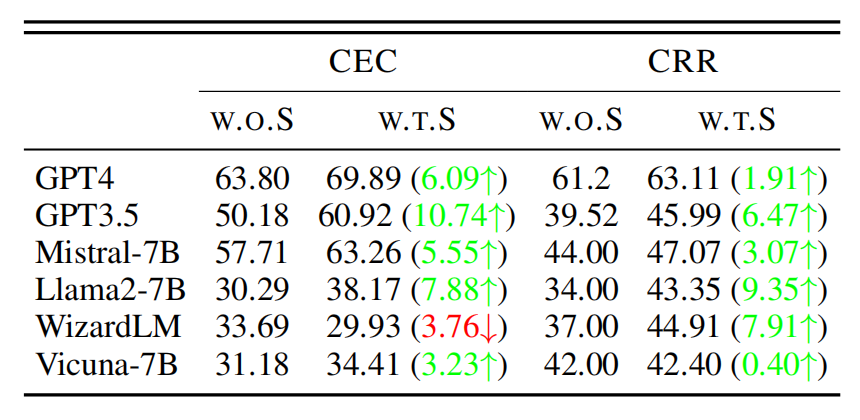

这些结果充分证明了知识引导方法的有效性。通过恰当的引导,我们可以帮助大模型更好地利用事件知识进行推理,从而大幅提升它们的表现。这为进一步提高大模型的事件推理能力指明了方向。
总的来说,通过 基准的实验,我们对大模型的事件推理能力有了更全面、更深入的认识。一方面,我们看到了它们已经初步具备了这一能力;另一方面,我们也发现了它们在不同方面还存在短板,这需要我们在未来的研究中重点关注和改进。同时,知识引导方法的初步成功也为我们指明了一条有潜力的研究道路。
大模型来了,事件推理还会远吗?
基准的提出及随后的系列研究,无疑是人工智能领域的一次重大突破。它们不仅揭示了大模型在事件推理方面的优势与不足,更为后续研究指明了方向。
的研究结果告诉我们,大模型已经初步具备了事件推理能力,这是一个令人惊喜的发现。然而我们也要清醒地认识到,当前大模型的事件推理能力还存在诸多限制。它们在处理不同类型的事件关系时表现出明显的不平衡性,尤其是在时序和层次关系的理解上还有很大的提升空间。此外,大模型在灵活运用事件知识方面也存在不足。
的研究只是一个开始,它为我们探索大模型的事件推理能力提供了一个全新的视角和方法论,开启了这一领域的新纪元。随着 及后续研究工作的不断深入,大模型的事件推理能力必将得到长足的进步。在不久的将来,机器或许就能够像人类一样,甚至比人类更好地理解和推理世间万物的因果联系、时序规律和层次结构。这将极大地拓展人工智能的应用边界,为人类认识世界、改变世界提供更强大的智能工具。


