
- 1被卖到 2w 的 ChatGPT 提示词 Prompt 你确定不想要吗?
- 2spark rdd java_Spark之RDD(含Java运行环境配置)
- 3DevOps学习指南:从基础到专家(持续更新,新增20篇,5月19)
- 4一览大模型长文本能力
- 5数据结构:常见的排序算法(五):堆排序(C++实现)_堆排序c++
- 6IDEA的全新UI可以在配置里启用了,快来试试吧!
- 7c++有趣的代码_C++开源项目:十行代码15个BUG,你入坑了吗?
- 8华为OD机考,二分查找问题_华为机试 二分图
- 9【linux】程序找不到动态库.so的解决办法|查看.so动态库信息|.so动态库加载顺序_linux-vdso.so.1找不到
- 10Mac系统安装Node_mac离线安装node要安装哪个包后缀名
学习笔记:使用Ollama项目快速本地化部署Qwen 1.5模型_ollama qwen
赞
踩
Ollama简介
Ollama是一个开源框架,专门设计用于在本地运行大型语言模型。它的主要特点是将模型权重、配置和数据捆绑到一个包中,从而优化了设置和配置细节,包括GPU使用情况,简化了在本地运行大型模型的过程。Ollama支持macOS和Linux操作系统,并且已经为Windows平台发布了预览版。
Ollama的一个重要优势是其易用性。安装过程简单,例如在macOS上,用户可以直接从官网下载安装包并运行。对于Windows用户,官方推荐在WSL 2中以Linux方式使用命令安装。安装完成后,用户可以使用命令行工具来下载和运行不同的模型。
Ollama还提供了对模型量化的支持,这可以显著降低显存要求。例如,4-bit量化可以将FP16精度的权重参数压缩为4位整数精度,从而大幅减小模型权重体积和推理所需显存。这使得在普通家用计算机上运行大型模型成为可能。
此外,Ollama框架还支持多种不同的硬件加速选项,包括纯CPU推理和各类底层计算架构,如Apple Silicon。这使得Ollama能够更好地利用不同类型的硬件资源,提高模型的运行效率。
Ollama部署qwen1.5模型
Ollama目前对于国产开源大模型只集成了Qwen1.5以及零一万物系列模型。
以下是我本地部署和运行Qwen1.5 7B模型的过程:
Ollama开源项目地址:
下载windows安装包:
双击进行安装:
傻瓜式安装:
安装完成,打开应用:
通过终端命令行,查看是否安装成功:
ollama --version出现版本就说明安装成功:
![]()
下载模型
点击ollama的模型仓库(开源项目地址)
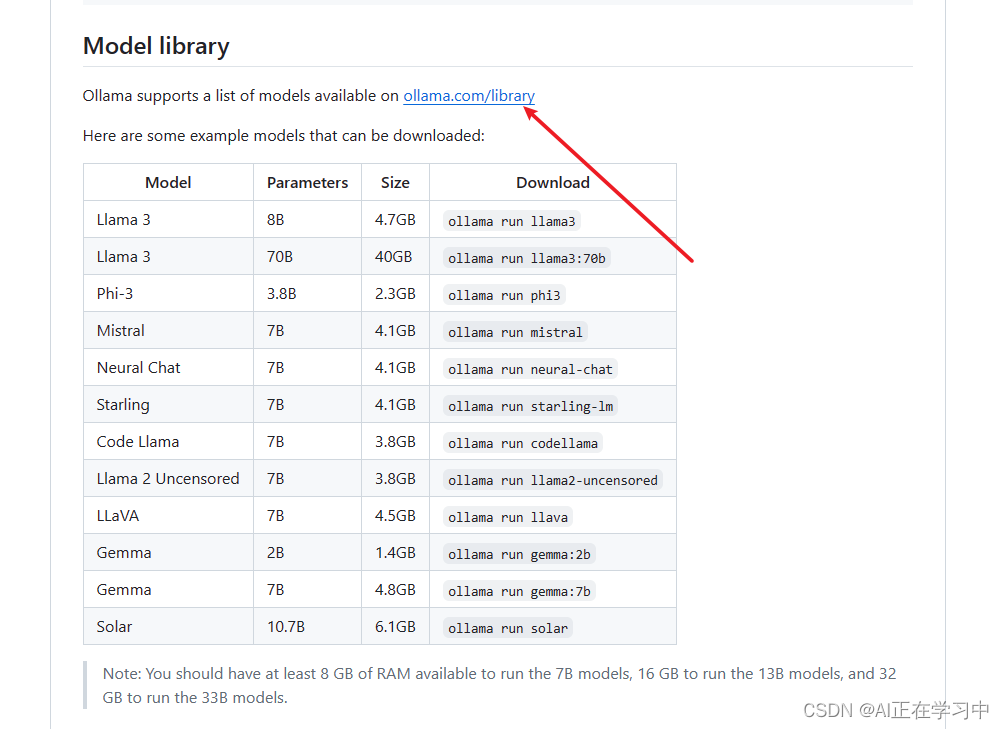
搜索qwen
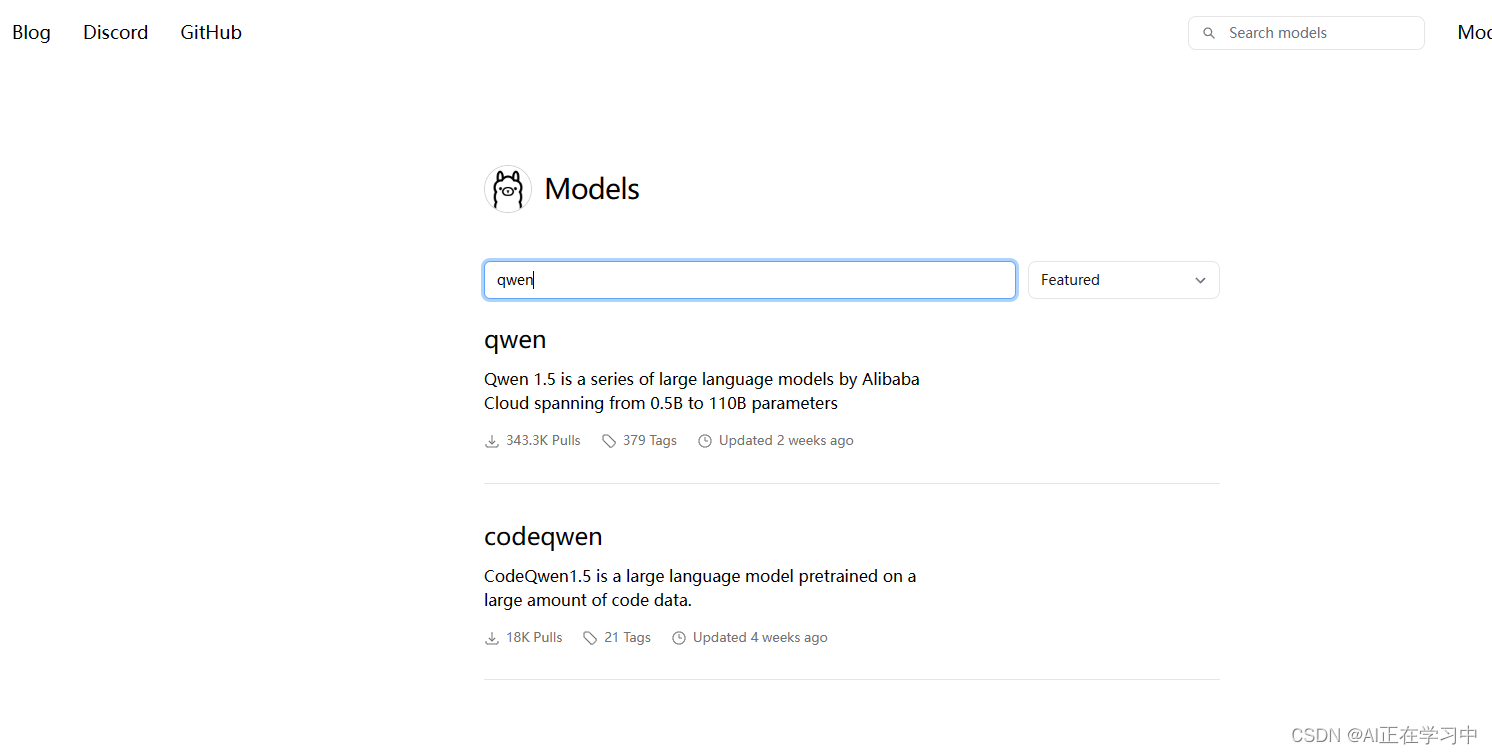
选择需要的模型版本:
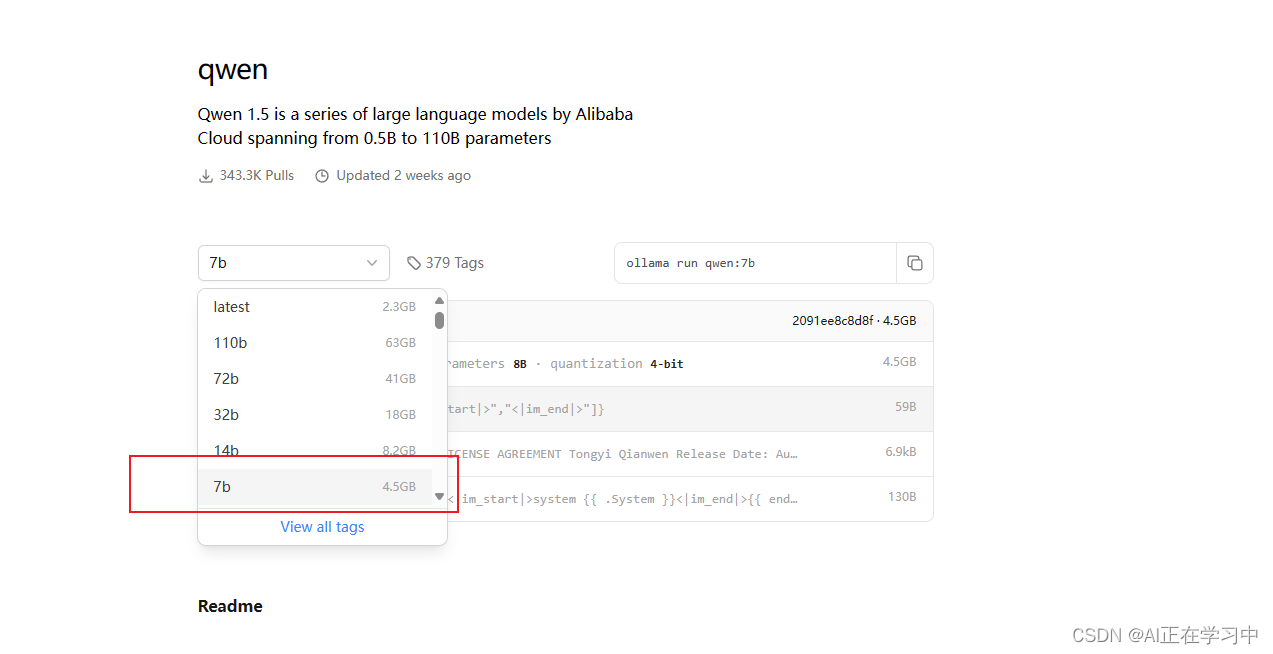
拉取模型文件:
pull后边跟需要的模型名称即可:
ollama pull qwen:7b可以看到,下载速度很快:

下载完毕后,可以到默认的下载路径查看:(不支持修改下载路径,应该是后续加载运行模型也会从此处开始,如果大家C盘空间不够,可以进行扩容,采用工具![]() ,可以将属于同一块硬盘的其他盘空间转移给C盘,也是非常方便的,有需要可以出教程)
,可以将属于同一块硬盘的其他盘空间转移给C盘,也是非常方便的,有需要可以出教程)

可以在终端中查看下载的模型:
ollama list可以看到我们下载了qwen 7B:
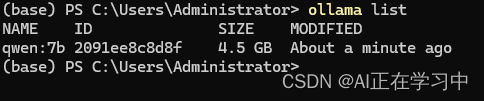
运行模型
直接在终端输入命令:
ollama run qwen:7b启动非常的快速(没截到图):
![]()
推理也是非常的快

我们看看显存占用:
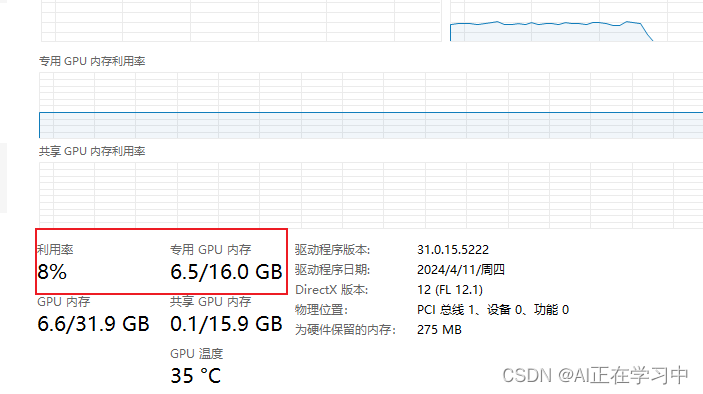
7B模型,居然才占用6.5GB的显存,这种降低也太明显了。
之前直接启动模型,最低也是13GB的显存占用,推理时差不多15GB了,呜呜..
目前就部署到这里,可以通过命令行对话。
后续,如果学习了如何将Ollama集成到langchain框架,再进行记录。

