
热门标签
热门文章
- 1电脑办公最佳拍档 夸克网盘升级低耗能备份、PDF阅读器等功能
- 2java 导出word_Java使用word模板导出word
- 3基于Python(Django框架)的毕业设计作品成品(40)网上书城图书购物商城系统设计与实现_django书店
- 4基于javaweb+SpringBoot的宿舍管理系统(java+SpringBoot+JSP+bootstrap+Maven+mysql)_springboot宿舍管理系统的宿舍评分模块
- 5 云服务器ECS出现速度变慢 以及突然断开怎么办? ...
- 6Wenet:下一代开源语音识别框架
- 7@Transactional与synchronized同时使用synchronized失效_同时提交 synchronized有用嘛?
- 82024年中国杭州|网络安全技能大赛(CTF)正式开启竞赛报名_2024年ctf网络安全大赛
- 9操作系统实验报告②_编写c语言程序,模拟实现首次、最佳、最坏适应三种算法的内存块分配和回收。假
- 10计算机视觉会议(CVPR,ECCV,ICCV,NIPS,AAAI,ICLR等)_iccv官网
当前位置: article > 正文
XCTF-Misc1 USB键盘流量分析_键盘流量脚本
作者:2023面试高手 | 2024-05-27 00:05:59
赞
踩
键盘流量脚本
m0_01
附件是一个USB流量文件
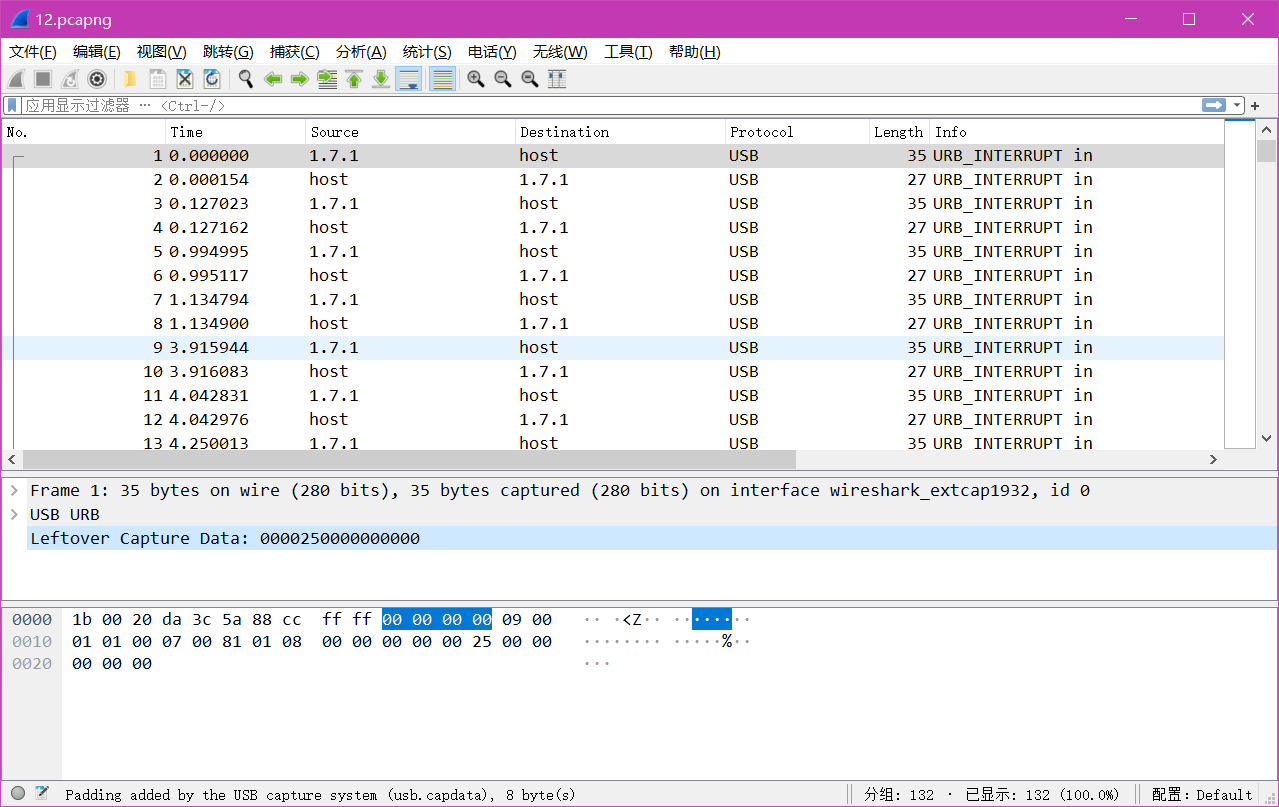
分析
1.键盘流量
USB协议数据部分在Leftover Capture Data域中,数据长度为八个字节,其中键盘击健信息集中在第三个字节中。
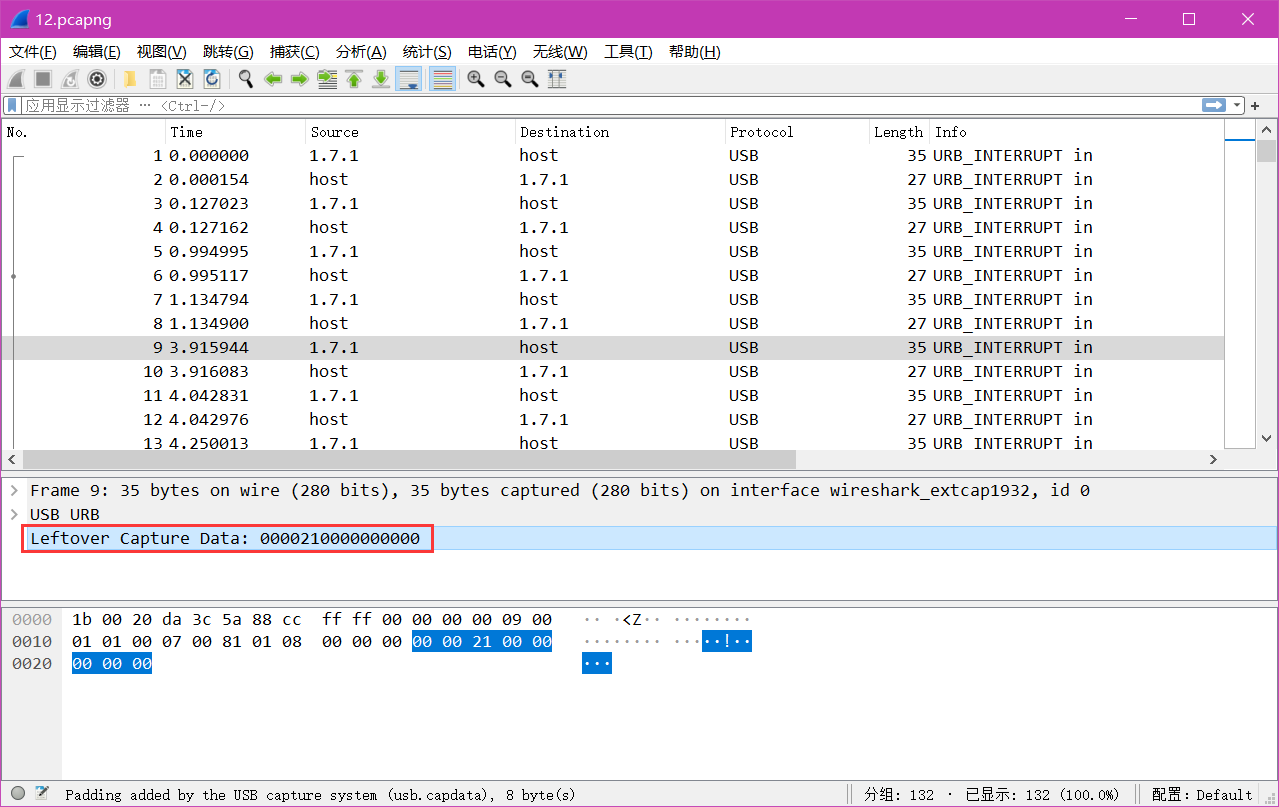
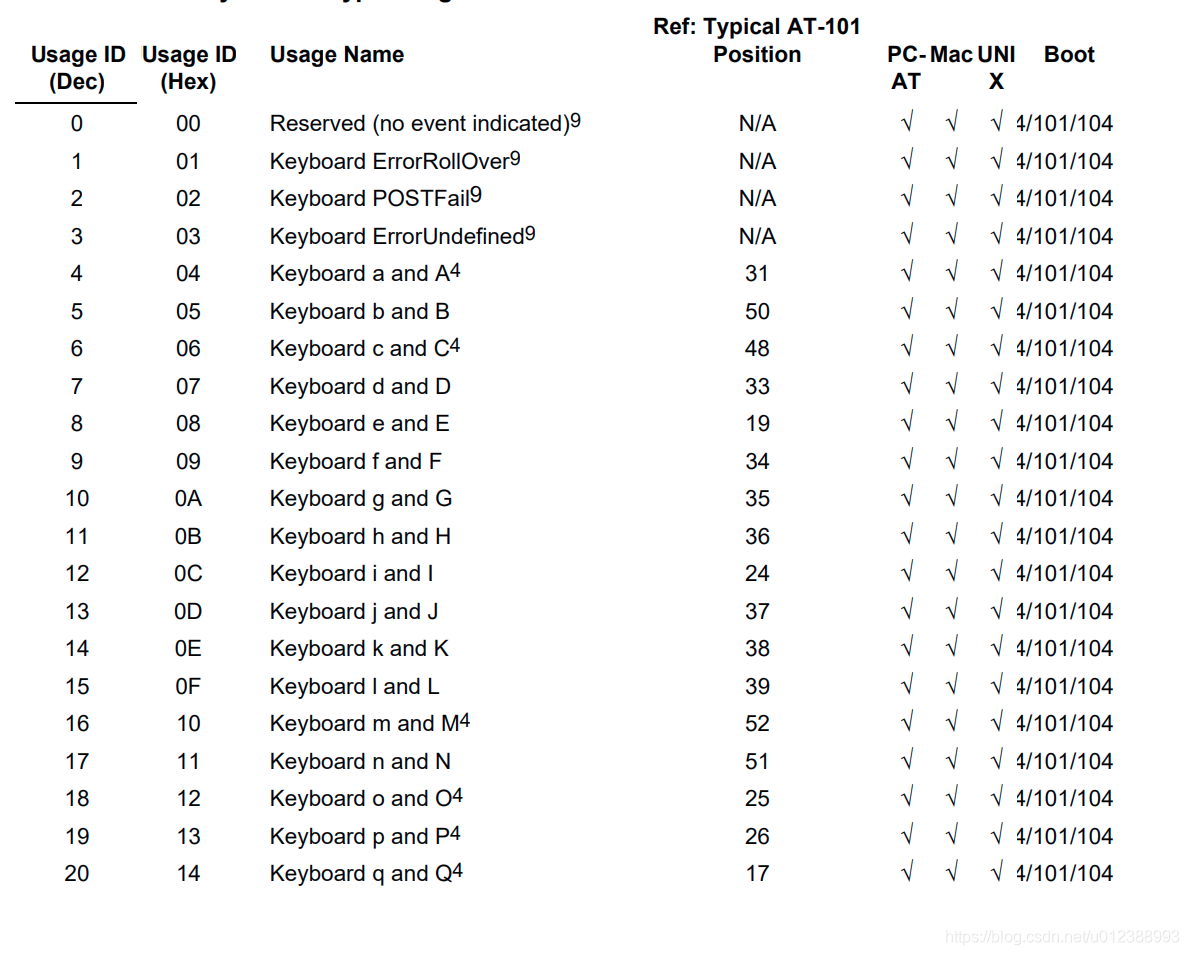
usb keyboard映射表:USB协议中HID设备描述符以及键盘按键值对应编码表
2.USB流量提取
USB协议的数据部分在 Leftover Capture Data 域中,可使用tshark提取流量
tshark -r xxx.pcapng -T fields -e usb.capdata > usbdata.txt

3.处理data文件,提取键盘信息
由于得到的USB文件中含有空行,常见的usbdata中以两字节加冒号的格式(如例子)。
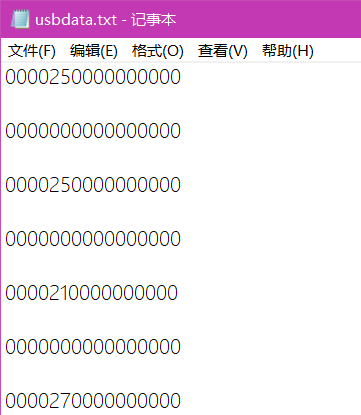
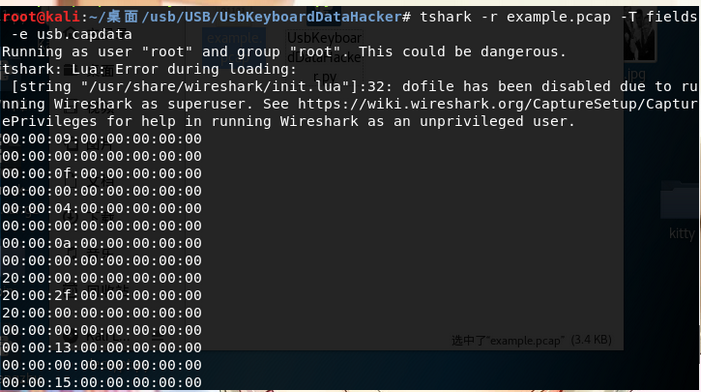 例子
例子
对文件进行处理:
#1.使用脚本删除空行
with open('usbdata.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
lines = filter(lambda x: x.strip(), lines)
with open('usbdata.txt', 'w', encoding='utf-8') as f:
f.writelines(lines)
#2.将上面的文件用脚本分隔,加上冒号;
f=open('usbdata.txt','r')
fi=open('out.txt','w')
while 1:
a=f.readline().strip()
if a:
if len(a)==16:#键盘流量的话len为16鼠标为8
out=''
for i in range(0,len(a),2):
if i+2 != len(a):
out+=a[i]+a[i+1]+":"
else:
out+=a[i]+a[i+1]
fi.write(out)
fi.write('\n')
else:
break
fi.close()
#3.最后用脚本提取
# print((line[6:8])) #输出6到8之间的值
#取出6到8之间的值
mappings = { 0x04:"A", 0x05:"B", 0x06:"C", 0x07:"D", 0x08:"E", 0x09:"F", 0x0A:"G", 0x0B:"H", 0x0C:"I", 0x0D:"J", 0x0E:"K", 0x0F:"L", 0x10:"M", 0x11:"N",0x12:"O", 0x13:"P", 0x14:"Q", 0x15:"R", 0x16:"S", 0x17:"T", 0x18:"U",0x19:"V", 0x1A:"W", 0x1B:"X", 0x1C:"Y", 0x1D:"Z", 0x1E:"1", 0x1F:"2", 0x20:"3", 0x21:"4", 0x22:"5", 0x23:"6", 0x24:"7", 0x25:"8", 0x26:"9", 0x27:"0", 0x28:"\n", 0x2a:"[DEL]", 0X2B:" ", 0x2C:" ", 0x2D:"-", 0x2E:"=", 0x2F:"[", 0x30:"]", 0x31:"\\", 0x32:"~", 0x33:";", 0x34:"'", 0x36:",", 0x37:"." }
nums = []
keys = open('out.txt')
for line in keys:
if line[0]!='0' or line[1]!='0' or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0':
continue
nums.append(int(line[6:8],16))
keys.close()
output = ""
for n in nums:
if n == 0 :
continue
if n in mappings:
output += mappings[n]
else:
output += '[unknown]'
print ('output :\n' + output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
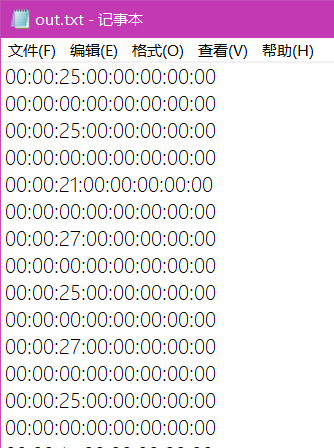
运行脚本,将对应的USB转换出来是一串数字
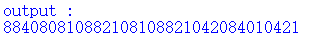
4.云影解码
这一串数字,我也不知道是啥,搜吧
云影密码(01248码)
- 这种加密方式仅使用01248这5种数字来进行,其中0用来唯一表示间隔,其他数字用加法和表示替换密文。再使用数字1-26表示字母A-Z。
如:18 = 1+8 = 9 = I,1248 = 1+2+4+8 = 15 = O- 特点:密文中仅存在01248,加密对象仅有字母。
- 加密方式:
题目:12401011801180212011401804
- 注意(3个及以上数字时):虽然是相加,但是可以在数字内不按顺序相加,如124可写成(12)4和1(24)结果分别是7和16,只要保证不大于26即可
- 第一步分割:即124 、1、118、118、212、114、18、4
- 第二步基本翻译:例如124可以表示7,也可以表示16(但不可能是34,因为不会超过26),所以可以放弃来翻译其他没有异议的,可得:124、a、s、s、w、o、18、d
- 第三步推测得出明文:可以推测后面的18表示r,前面的为p最合适。
所以最后明文:password(密码)
解密脚本:
##with open(r'F:/桌面/tmp/2.txt','r') as f:
## data = f.read()
## print(data)
data = "884080810882108108821042084010421"
list = data.split('0')
print(list)
datalist=[]
def dlist(list):
d = 0
for i in list:
for j in i:
d += int(j)
datalist.append(d)
d=0
return datalist
datalist = dlist(list)
def str(datalist):
s=''
for i in datalist:
s += chr(i+64)
return s
print(str(datalist))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

最终得到flag
参考链接:
https://blog.csdn.net/ON_Zero/article/details/130528679
https://www.cnblogs.com/yuanchu/p/13492904.html
CTF密码学总结 https://blog.csdn.net/xiao__1bai/article/details/121089114
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/628988
推荐阅读
相关标签

