
- 1AI辅写疑似度怎么查:降低perplexity和burstiness的实用指南_perplexity度评估文本生成质量
- 2Kafka学习笔记_kafka segment.index.bytes
- 3java web项目 使用elfinder 实现文件管理器
- 4【idea】idea 中 git 分支多个提交合并一个提交到新的分支_idea中已经push到远端的提交记录合并成一个
- 5嵌入式~PCB专辑54_为什么采样频率是3-5倍
- 6查找算法总结(3)--二叉查找树_二分搜索树的查找效率与该树的高度有关
- 7机器学习项目(五) 电影推荐系统(二)_imdb电影评分预测 推荐系统
- 8Gitlab仓库迁移指南_gitlab 仓库迁移
- 9Linux离线安装Redis
- 10Python正则表达式抽取身份证号_python利用正则表达式提取文本中身份证号码
《计算机网络》学习笔记_当使用udp进行广播通信时,需要将套接字选项设置为什么并指定什么作为目标地址
赞
踩
文章目录
- 第1章 计算机网络和因特网
- 第2章 应用层
- 第3章 运输层
- 第4章 网络层:数据平面
- 第5章 网络层:控制平面
- 第6章 链路层和局域网
- 第7章 无线网络和移动网络
- 第8章 计算机网络中的安全
- 第9章 多媒体网络
第1章 计算机网络和因特网
1.1 什么是因特网
定义
因特网是一个世界范围的计算机网络,即它是一个互联了遍及全世界数十亿计算设备的网络。
所有这些设备(桌面PC、Linux、智能手机、电视、游戏机等)都称为主机(host)或端系统(end system)。

端系统通过**通信链路(communication link)和分组交换机(packet switch)连接到一起。链路的传输速率(transmission rate)**以比特/秒(bit/s,或bps)度量。
当一台端系统要向另一台端系统发送数据时,发送端系统将数据分段,并为每段加上首部字节,由此形成的信息包称为分组(packet)。这些分组通过网络发送到目的端系统,在那里被装配成初始数据。
分组交换机从它的一条入通信链路接收到达的分组,并从它的一条出通信链路转发该分组。在当今的因特网中,两种最著名的分组交换机是路由器(router)和链路层交换机(link-layer switch)。链路层交换机通常用于接入网中,而路由器通常用于网络核心中。
在许多方面,分组类似于卡车,通信链路类似于高速公路和公路,分组交换机类似于交叉口,端系统类似于建筑物。
端系统通过**因特网服务提供商(Internet Service Provider,ISP)**接入因特网。每个ISP自身就是一个由多台分组交换机和多段通信链路组成的网络。
端系统、分组交换机和其他因特网部件都要运行一系列协议(protocol),这些协议控制因特网中信息的接收和发送。TCP(Transmission Control Protocol,传输控制协议)和IP(Internet Protocol,网际协议)是因特网中两个最重要的协议。IP协议定义了在路由器和端系统之间发送和接收的分组格式,因特网的主要协议统称TCP/IP。
因特网标准(Internet standard)由因特网工程任务组(IETF)研发。IETF的标准文档称为请求评论(Request For Comment,RFC)。RFC文档定义了TCP、IP、HTTP和SMTP等协议。目前已经有将近7000个RFC。
与因特网相连的端系统提供了一个套接字接口(socket interface),该接口规定了运行在一个端系统上的程序请求因特网基础设施向运行在另一个端系统上的特定目的地程序交付数据的方式。因特网套接字接口是一套发送程序必须遵循的规则集合,因此因特网能够将数据交付给目的地。
什么是协议

在网络中,为了完成一项工作,要求两个(或多个)通信实体运行相同的协议。
在因特网中,涉及两个或多个远程通信实体的所有活动都受协议的制约。
**协议(protocol)**定义了在两个或多个通信实体之间交换的报文的格式和顺序,以及报文发送或接收一条报文或其他事件所采取的动作。
因特网广泛地使用了协议,不同的协议用于完成不同的通信任务。掌握计算机网络领域知识的过程就是理解网络协议的构成、原理和工作方式的过程。
1.2 网络边缘
端系统也称为主机,主机有时又被进一步划分为两类:客户端(client)和服务器(server)。
接入网是指将端系统物理链接到其**边缘路由器(edge router)**的网络
-
家庭接入:DSL、电缆、FTTH、拨号和卫星
宽带住宅接入有两种最流行的类型:**数字用户线(Digital Subscriber Line,DSL)**和电缆。当使用DSL时,用户的本地电话公司也是它的ISP。
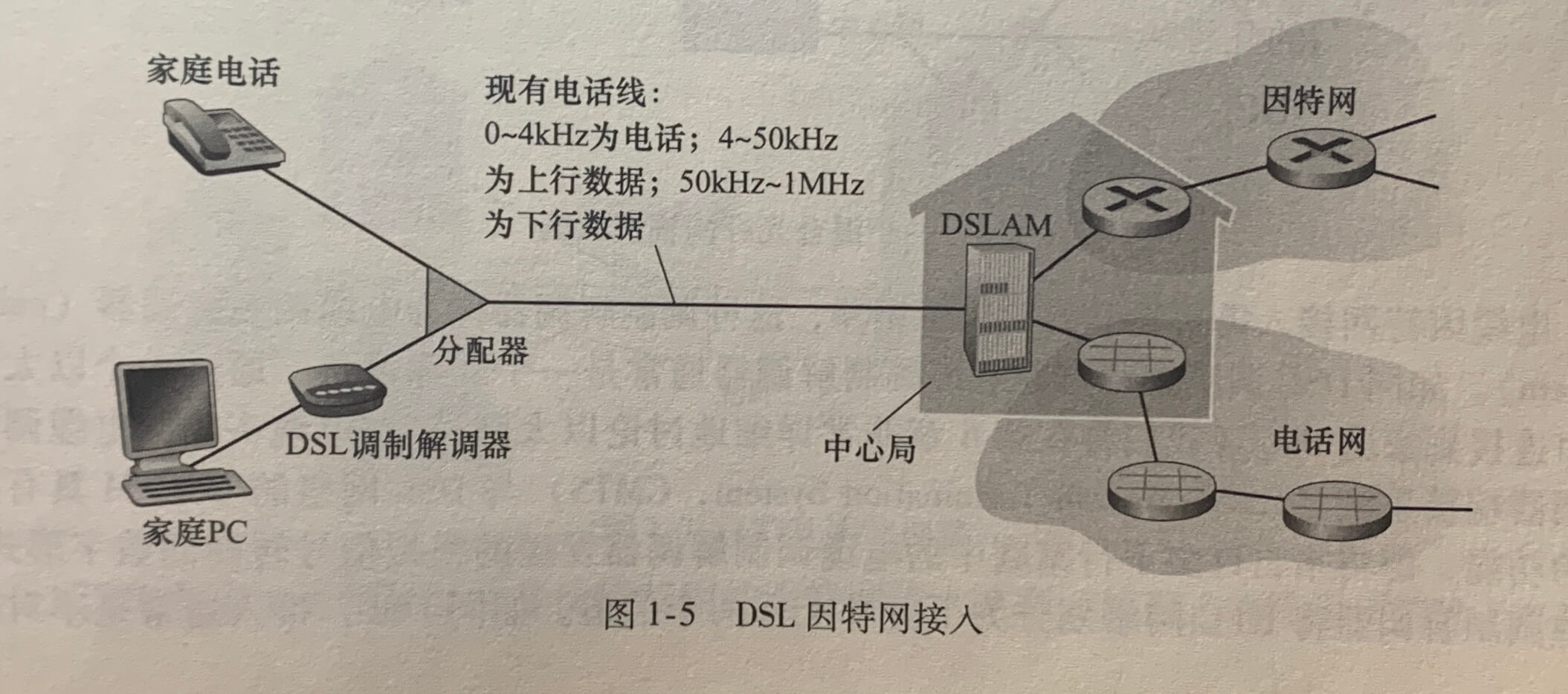
每个用户的DSL调制解调器使用现有的电话线与位于电话公司的本地中心局(CO)中的数字用户线接入复用器(DSLAM)交换数据。
家庭电话线同时承载了数据和传统的电话信号,它们用不同的频率进行编码。这种方法使单根DSL线路看起来就像有3根单独的线路一样。
**电缆因特网接入(cable Internet access)**利用了有线电视公司的有线电视基础设施。
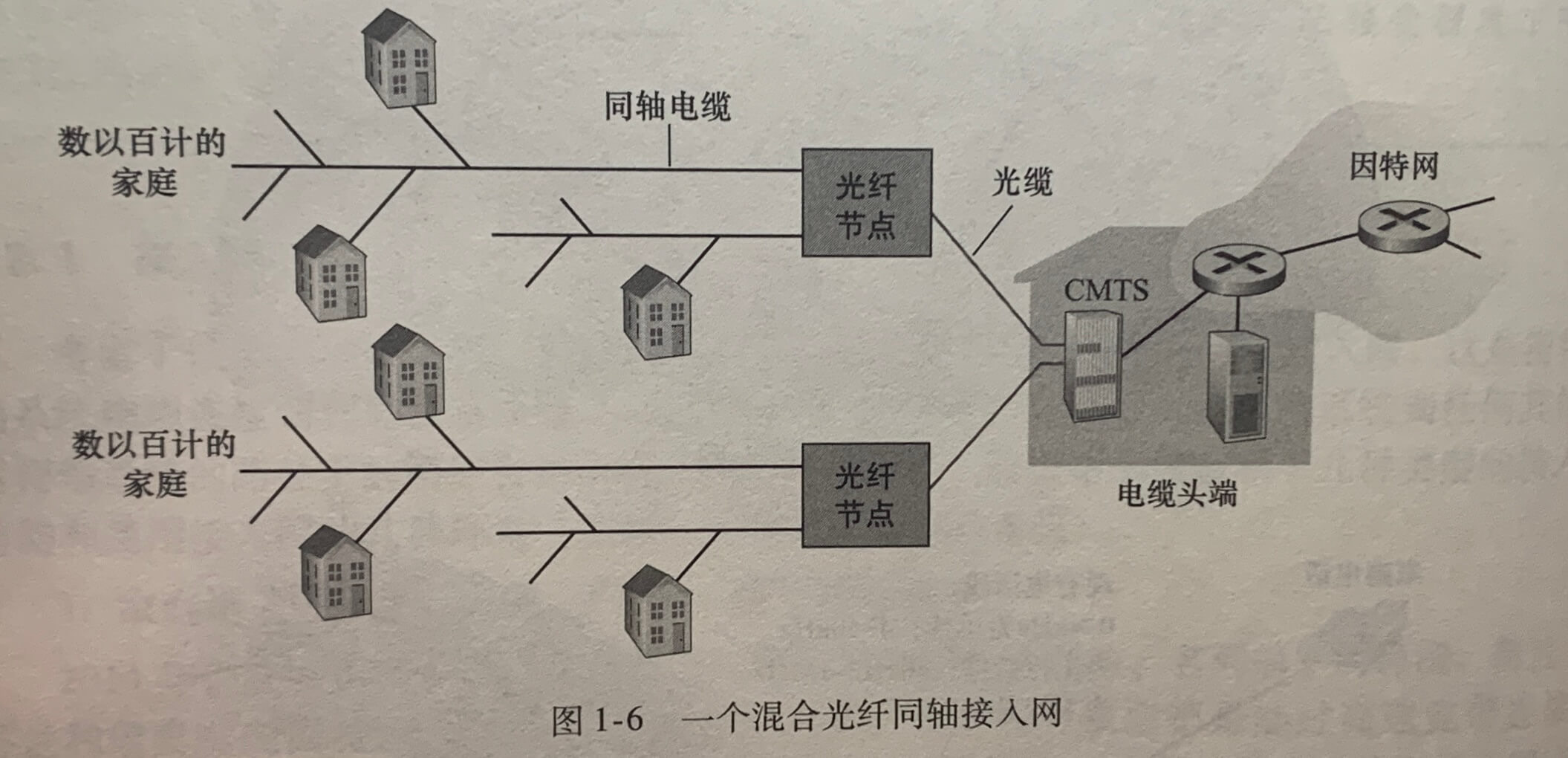
电缆因特网接入需要特殊的调制解调器,这种调制解调器称为电缆调制解调器(cable modem)。
电缆调制解调器系统(Cable Modem Termination System,CTMS)与DSL网络的DSLAM具有类似的功能,即将来自许多下行家庭中的电缆调制解调器发送的模拟信号转换回数字信号。电缆调制解调器将混合光纤同轴系统(HFC)网络分为下行和上行两个信道,如同DSL,接入通常是不对称的,下行信道分配的传输速率通常比上行信道的高。
一种更高速的新兴技术是光纤到户(Fiber To The Home,FTTH),从本地中心局直接到家庭提供了一条光纤路径。实际上从本地中心局出来的每根光纤由许多家庭共享,直到相对接近这些家庭的位置,该光纤才分成每户一根光纤。
进行这种分配有两种竞争性的光纤分布体系结构:有源光纤网络(Active Optical Network,AON)和无源光纤网络(Passive Optical Network,PON)。AON本质上就是交换以太网。
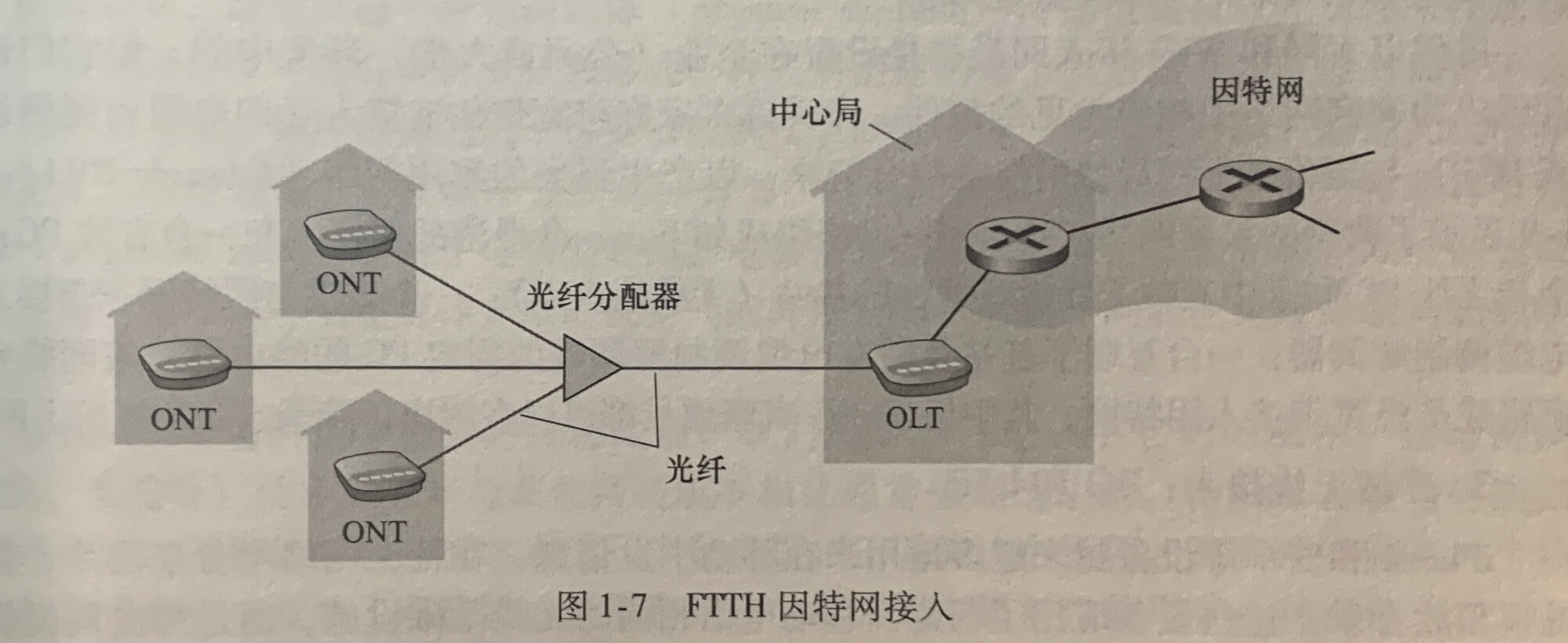
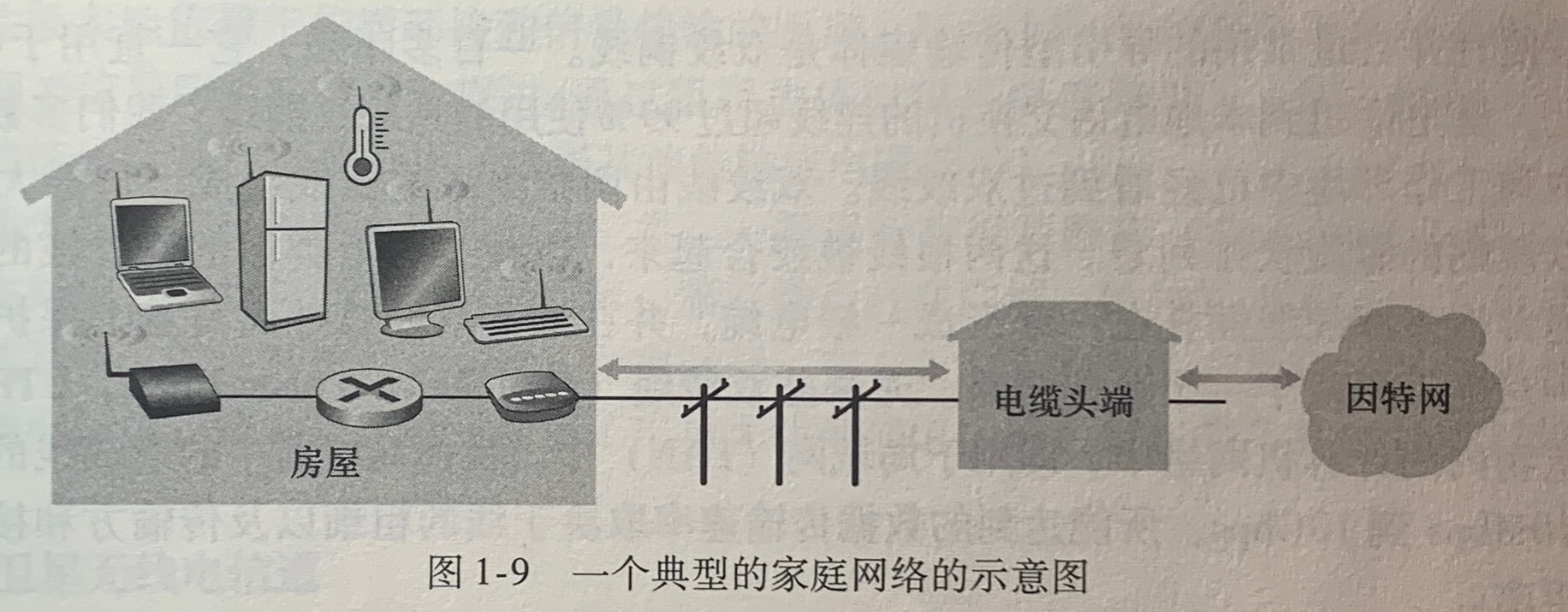
上图显示了使用PON分布体系结构的FTTH。每个家庭具有一个光纤网络端接器(Optical Network Terminator,ONT),它由专门的光纤连接到邻近的分配器(splitter),该分配器把一些家庭集结到一根共享的光纤,该光纤再连接到本地电话和公司的中心局中的光纤线路端接器(Optical Line Terminator,OLT),该OLT提供了光信号和电信号之间的转换,经过本地电话公司路由器和因特网相连。
-
企业(和家庭)接入:以太网和WIFI
在越来越多的公司、家庭、校园环境中,使用局域网(LAN)将端系统连接到边缘路由器。
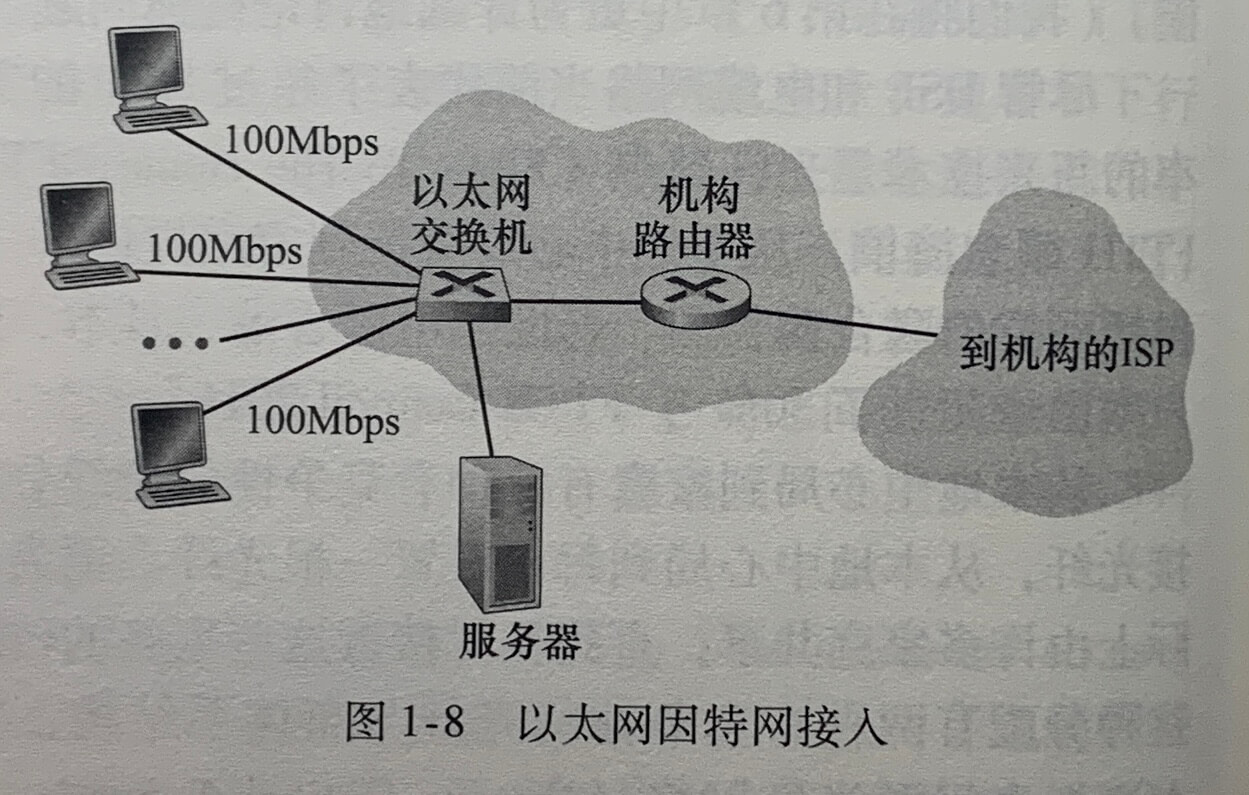
以太网用户使用双绞铜线与一台以太网交换机相连。在无线LAN环境中,无线用户从/到一个接入点发送/接受分组,该接入点与企业网连接(很可能使用了有线以太网),企业网再与有线因特网相连。一个无线LAN用户通常必须位于接入点的几十米范围内,基于IEEE 802.11 技术(简称WIFI)的无线LAN接入,目前几乎无处不在。
-
广域无线接入:3G和LTE
物理媒体
思考一比特的传输过程,当这个比特从源目的地传输时,通过一系列“发射器-接收器”对,对于每个发射器-接收器对,通过跨越一种**物理媒体(physical medium)**传播电磁波或光脉冲来发送该比特。物理媒体可具有多种形状或形式,并且对沿途的每个发射器-接收器对而言不必具有相同的类型。
物理媒体分为导引型媒体(guided media)和非导引型媒体(unguided media),对于导引型媒体,电波沿着固体媒体前行,如光缆、双绞铜线或同轴电缆。对于非导引型媒体,电波在空气或外层空间中传播,例如在无线局域网或数字卫星频道中。
-
双绞铜线
最便宜并且最常用的导引型传输媒体是双绞铜线。一百多年来,它一直用于电话网。
双绞铜线由两根绝缘的铜线组成,每根大约1mm粗,以规则的螺旋状排列。一对电线构成了一个通信链路。无屏蔽双绞线(Unshielded Twisted Pair,UTP)常用在建筑物内的计算机网络中,即用于LAN中。目前LAN的双绞线的数据速率从10Mbps 到 10Gbps。
双绞线已经作为高速LAN联网的主导性解决方案。
-
同轴电缆
与双绞线类似,同轴电缆由两个铜导体组成,但是这两个导体是同心的而不是并行的。同轴电缆在电缆电视系统中相当普遍。
-
光纤
光纤是一种细而柔软的、能够导引光脉冲的媒体,每个脉冲表示一个比特。一根光纤能够支持极高的比特速率,高达数十甚至数百Gbps。它们不受电磁干扰,长达100km的光缆信号衰减极低,并且很难窃听。
-
陆地无线电信道
无线电信道承载电磁频谱中的信号。它不需要安装物理线路,并且具有穿透墙壁、提供与移动用户的连接以及长距离承载信号的能力。
无线电信道极大地依赖于传播环境和信号传输的距离。环境上的考虑取决于路径损耗和遮挡衰落、多径衰落(由于干扰对象的信号反射)以及干扰(由于其他传输或电磁信号)。
陆地无线电信道大致分为三类:一类运行在很短距离(如1米或2米);另一类运行在局域(跨域数十到几百米);第三类运行在广域(跨越数万米)。个人设备如无线头戴式耳机、键盘等跨短距离运行;无线LAN使用局域无线电信道;蜂窝接入技术使用广域无线电信道。
-
卫星无线电信道
一颗通信卫星连接地球上的两个或多个微波发射器/接收器,他们被称为地面站。通常使用两类卫星:同步卫星和近地轨道卫星。
1.3 网络核心
分组交换
在各种网络应用中,端系统彼此交换报文(message)。报文能够包含协议设计者需要的任何东西。报文可以执行一种控制功能,也可以包含数据,例如电子邮件数据、JPEG图像或MP3音频文件。
为了从源端系统向目的端系统发送一个报文,源将长报文划分为较小的数据块,称之为分组(packet)。在源和目的地之间,每个分组都通过通信链路和分组交换机传送。(分组交换机主要有两类:路由器(router)和链路层交换机(link-layer switch))。
-
存储转发传输
多数分组交换机在链路的输入端使用**存储转发传输(store-and-forward transmission)**机制。存储转发传输是指在交换机能够开始向输出链路传输该分组的第一个比特之前,必须接收到整个分组。

-
排队时延和分组丢失
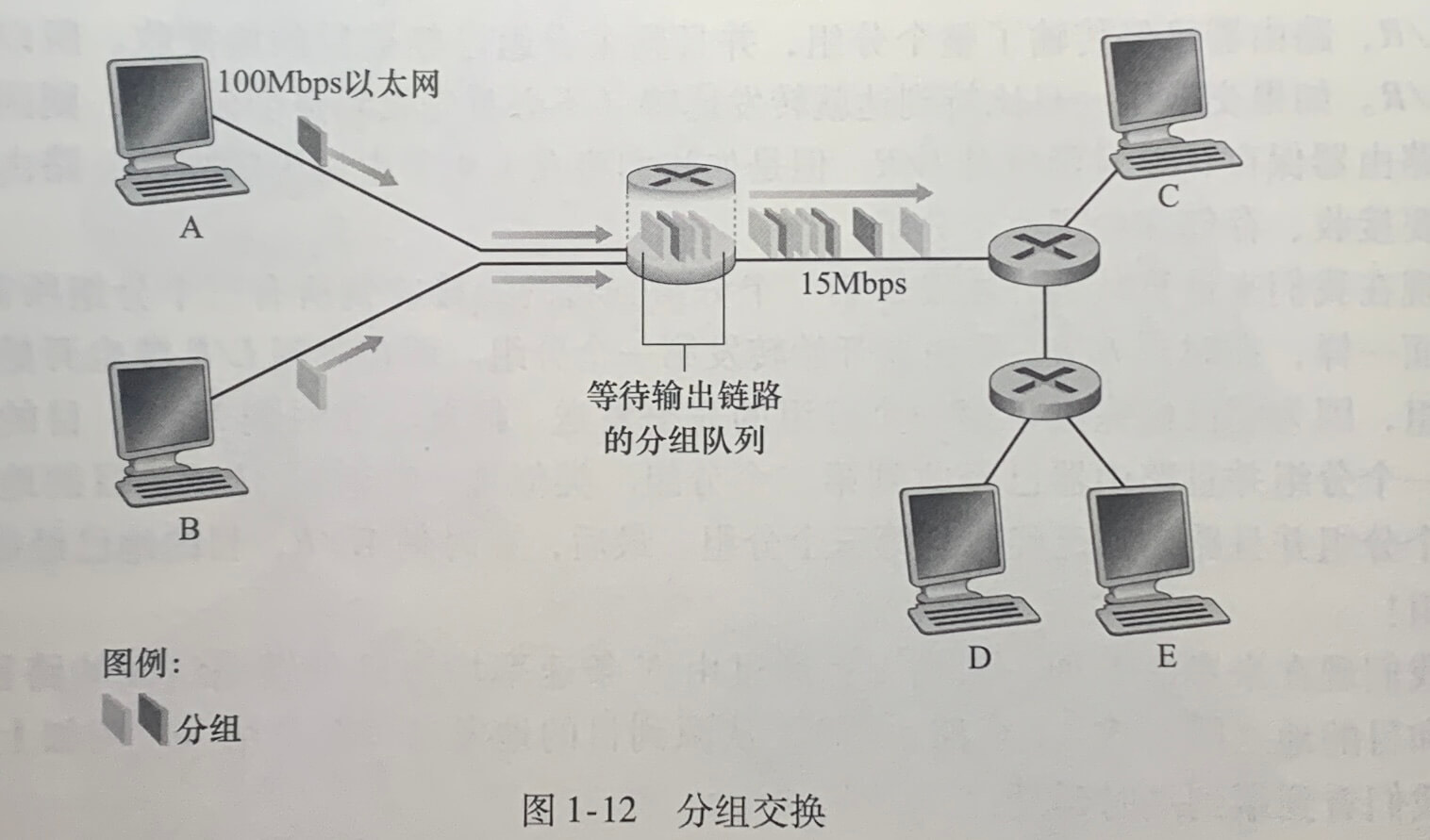
每台分组交换机有多条链路与之相连。对于每条相连的链路,该分组交换机具有一个输出缓存(output buffer,也称为输出队列(output queue)),它用于存储路由器准备发往那条链路的分组。
如果到达的分组需要传输到某条链路,但发现该链路正忙于传输其他分组,该到达分组必须在输出缓存中等待。因此,除了存储转发时延之外,分组还要承受输出缓存的排队时延(queuing delay)。这些时延是变化的,变化的程度取决于网络的拥塞程度。因为缓存空间的大小有限,一个到达的分组可能发现该缓存已被其他等待传输的分组完全充满,此时将出现分组丢失(丢包)(packet loss)。
-
转发表和路由选择协议
在因特网中,每个端系统具有一个称为IP地址的地址。当源主机要向目的端系统发送一个分组时,源在该分组的首部包含了目的地的IP地址。当一个分组到达网络中的路由器时,路由器检查该分组的目的地址的一部分,并向一台相邻路由器转发该分组。
每台路由器具有一个转发表(forwarding table),用于将目的地址(或目的地址的一部分)映射成为输出链路。因特网具有一些特殊的路由选择协议(routing protocol),用于自动地设置这些转发表。
电路交换
通过网络链路和交换机移动数据有两种基本方法:电路交换(circuit switching)和分组交换(packet switching)。
在电路交换网络中,在端系统间通信会话期间,预留了端系统间沿路径通信所需要的资源(缓存,链路传输速率)。传统的电话网络是电路交换网的例子。

上图中,用4条链路互联了4台电路交换机。这些链路中的每条都有4条电路,因此每条链路支持4条并行的连接。当两台主机要通信时,该网络在两台主机之间创建一条专用的端到端连接(end-to-end connection)。
-
电路交换网络中的复用
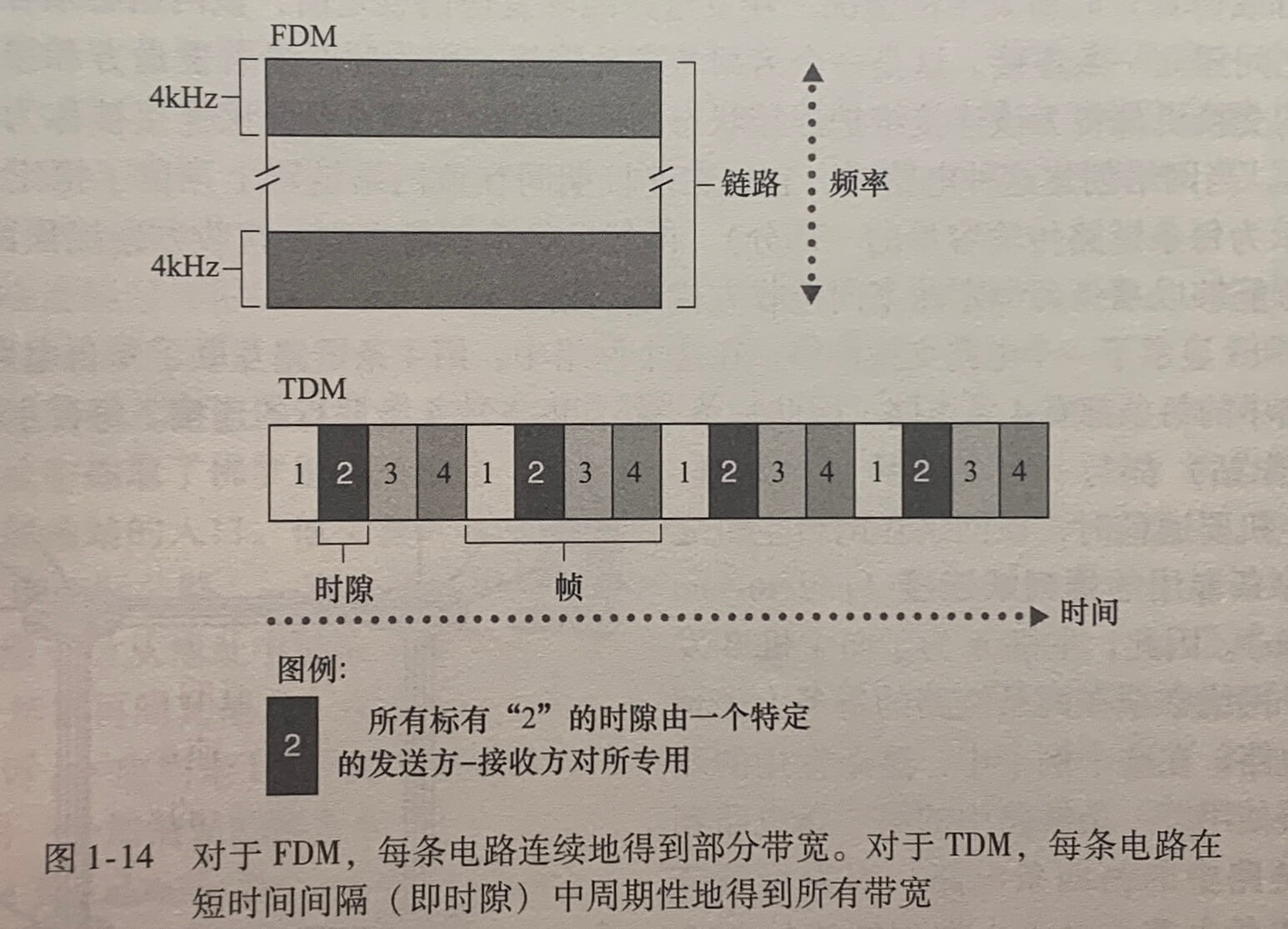
链路中的电路是通过**频分复用(Frequency-Division Multiplexing,FDM)或时分复用(Time-Division Multiplexing,TDM)**来实现的。
对于 FDM,链路的频谱由跨越链路创建的所有连接共享。在连接期间链路为每条连接专用一个频段,该频段的宽度称为带宽(bandwidth)。调频无线电台也使用FDM来共享88MHz~108MHz的频谱,其中每个电台被分配一个特定的频段。
对于一条 TDM 链路,时间被划分为固定期间的帧,并且每个帧又被划分为固定数量的时隙。
电路交换的缺点是当连接建立之后但没有使用,此时连接就被浪费了。
-
分组交换与电路交换的对比
分组交换优点:1.它提供了比电路交换更好的带宽共享;2.它比电路交换更简单、更有效,实现成本更低。
分组交换缺点:分组交换不适合实时服务(例如,电话和视频会议),因为它的端到端时延是可变的和不可预测的。
电路交换不考虑需求,而预先分配了传输链路的使用,这使得已分配而并不需要的链路时间未被利用。
当今趋势是朝着分组交换方向发展,甚至许多电路交换电话网都正在缓慢地向分组交换迁移。
网络的网络
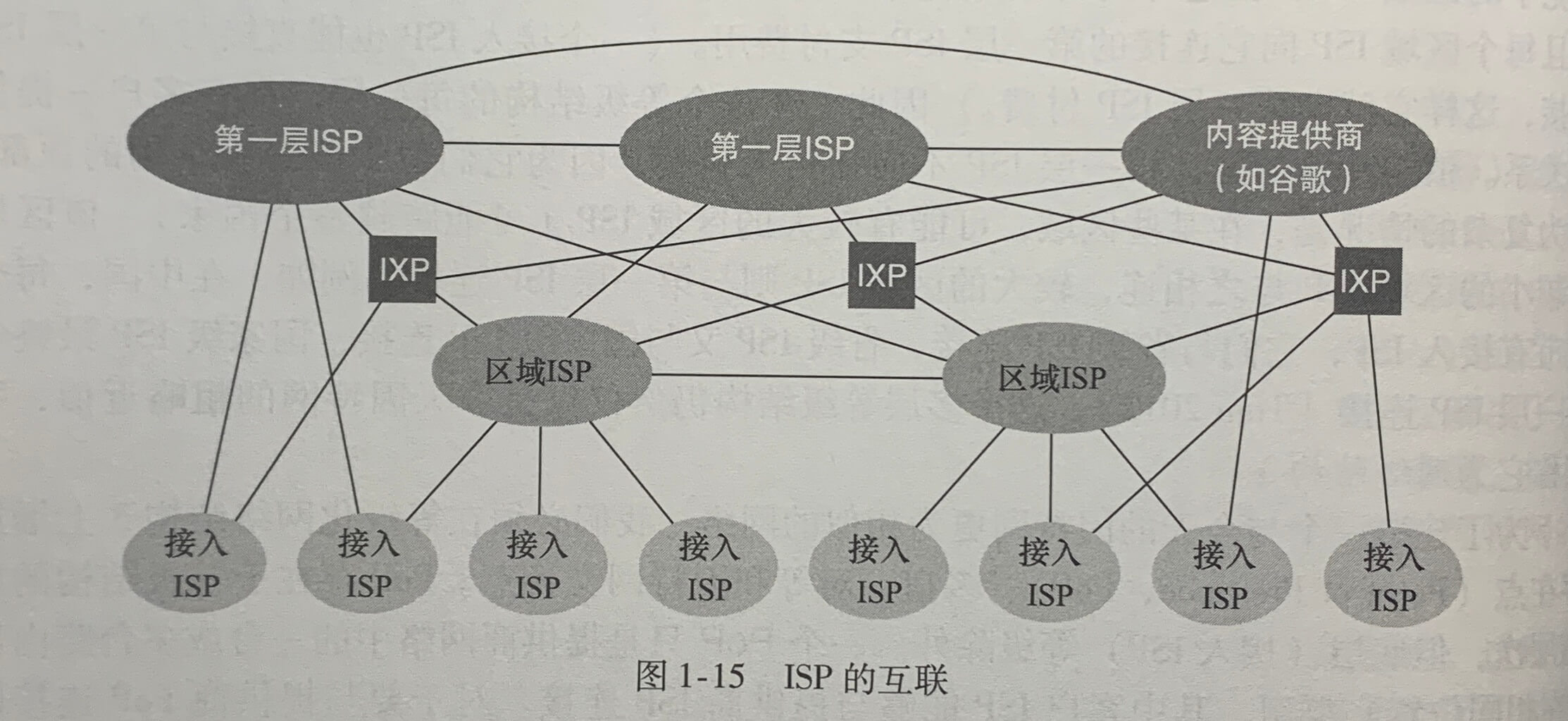
今天的因特网是一个网络的网络,其结构复杂,由十多个第一层ISP和数十万个底层ISP组成。ISP覆盖的区域多种多样,有些跨越多个大洲和大洋,有些限于狭窄的地理区域。较低层的ISP与较高层的ISP相连,较高层ISP彼此互联。用户和内容提供商是较低层ISP的客户,较低层ISP是较高层ISP的客户。近年来,主要的内容提供商也已经创建自己的网络,直接在可能的地方与较低层ISP互联。
1.4 分组交换网中时延、丢包和吞吐量
吞吐量(每秒能够传送的数据量)。
分组从源主机到目的主机的过程中,分组在沿途的每个节点经受了集中不同类型的时延。这些时延最为重要的是节点处理时延(nodal processing delay)、排队时延(queuing delay)、传输时延(transmission delay)和传播时延(propagation delay),这些时延总体累加就是节点总时延(total nodal delay)。
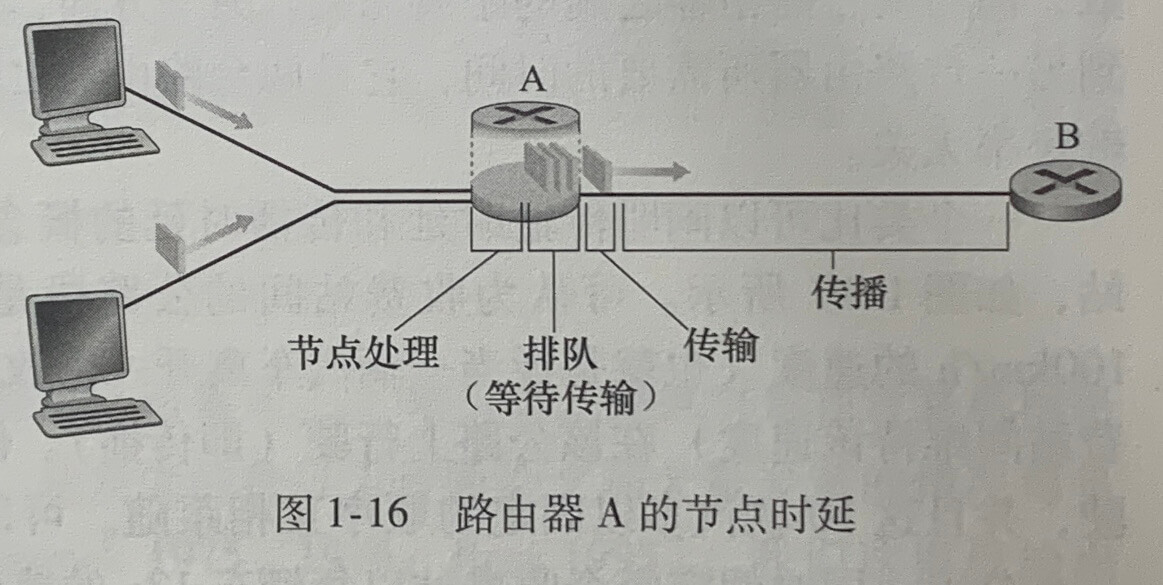
只有当该链路没有其他分组正在传输并且没有其他分组排在该队列前面时,才能在这条链路上传输该分组。
-
处理时延
检查分组首部和决定将该分组导向何处所需要的时间是处理时延的一部分。
-
排队时延
当分组在链路上的队列中等待传输时,它经受排队时延。实际排队时延可以是毫秒到微秒量级。
-
传输时延
所有分组的比特推向链路所需要的时间。实际的传输时延在毫秒到微秒量级。
-
传播时延
从该链路的起点到路由器B传播所需要的时间是传播时延。在广域网中,传播时延为毫秒量级。
-
传输时延和传播时延比较
传输时延是路由器推出分组所需要的时间,它是分组长度和链路传输速率的函数,与两台路由器之间的距离无关。
传播时延是一个比特从一台路由器传播到另外一台路由器所需要的时间,它是两台路由器之间的距离的函数,与分组长度或链路传输速率无关。
排队时延取决于流量到达该队列的速率、链路的传输速率和到达流量的性质。当到达的分组发现一个满的队列时,由于没有地方存储这个分组,路由器将丢弃(drop)该分组,即该分组将会丢失(lost)。分组丢失的比例随着流量增加而增加。
**瞬间吞吐量(instantaneous throughput)**是指主机在任何时间瞬间接收到文件的速率(以bps计)。

吞吐量取决于数据流过的链路的传输速率。
1.5 协议层次及其服务模型
分层的体系结构
1.协议分层
网络设计者以**分层(layer)**的方式组织协议以及实现这些协议的网络硬件和软件。每个协议属于这些层次之一。每层通过在该层执行某些动作或使用直接下层的服务来提供服务。
协议分层的优点是有利于模块化,使更新系统组件更为容易。而缺点是一层可能冗余较低层的功能。
各层的所有协议被称为协议栈(protocol stack)。因特网的协议栈由5个层次组成:物理层、链路层、网络层、运输层和应用层。

-
应用层
应用层是网络应用程序及它们的应用层协议存留的地方。应用层包括许多协议比如HTTP、SMTP、FTP等。
应用层协议分布在多个端系统上,而一个端系统中的应用程序使用协议与另一个端系统中的应用程序交换信息分组,这种信息分组称为报文(message)。
-
运输层/传输层
运输层在应用程序端点之间传送应用层报文。运输层有两种协议,TCP和UDP。
TCP 提供面向连接的服务,将长报文划分为短报文,并提供拥塞控制机制。
UDP 提供无连接服务,没有可靠性,没有流量控制,也没有拥塞控制。
运输层的分组称为报文段(segment)。
-
网络层
网络层负责将称为**数据报(datagram)**的网络层分组从一台主机移动到另一台主机。运输层协议向网络层递交运输层报文段和目的地址。
网络层的协议是网际协议IP,该协议定义了在数据报中的各个字段以及端系统和路由器如何作用于这些字段。IP仅有一个,所有具有网络层的因特网组件必须运行IP。通常把网络层简称为IP层。
-
链路层
网络层将数据报下传给链路层,链路层沿着路径将数据报传递给下一个节点。在该下一个节点,链路层将数据报上传给网络层。
链路层提供的服务取决于应用于该链路的特定链路层协议。链路层的例子包括以太网、WIFI和电缆接入网的 DOCSIS 协议。
一个数据报可能被沿途不同链路上的不同链路层协议处理。
链路层分组称为帧(frame)。
-
物理层
物理层的任务是将该帧中的一个个比特从一个节点移动到下一个节点。
物理层的协议比如双绞铜线、同轴电缆、光纤等等。
2.OSI模型
**国际标准化组织(ISO)提出计算机网络围绕7层来组织,称为开放系统互连(OSI)**模型。
OSI模型的5层的功能大致与因特网模型对应层的功能相同。表示层的作用是使通信的应用程序能够解释交换数据的含义。这些服务包括数据压缩和数据加密以及数据描述。会话层提供数据交换的定界和同步功能,包括建立检查点和恢复方案的方法。
封装
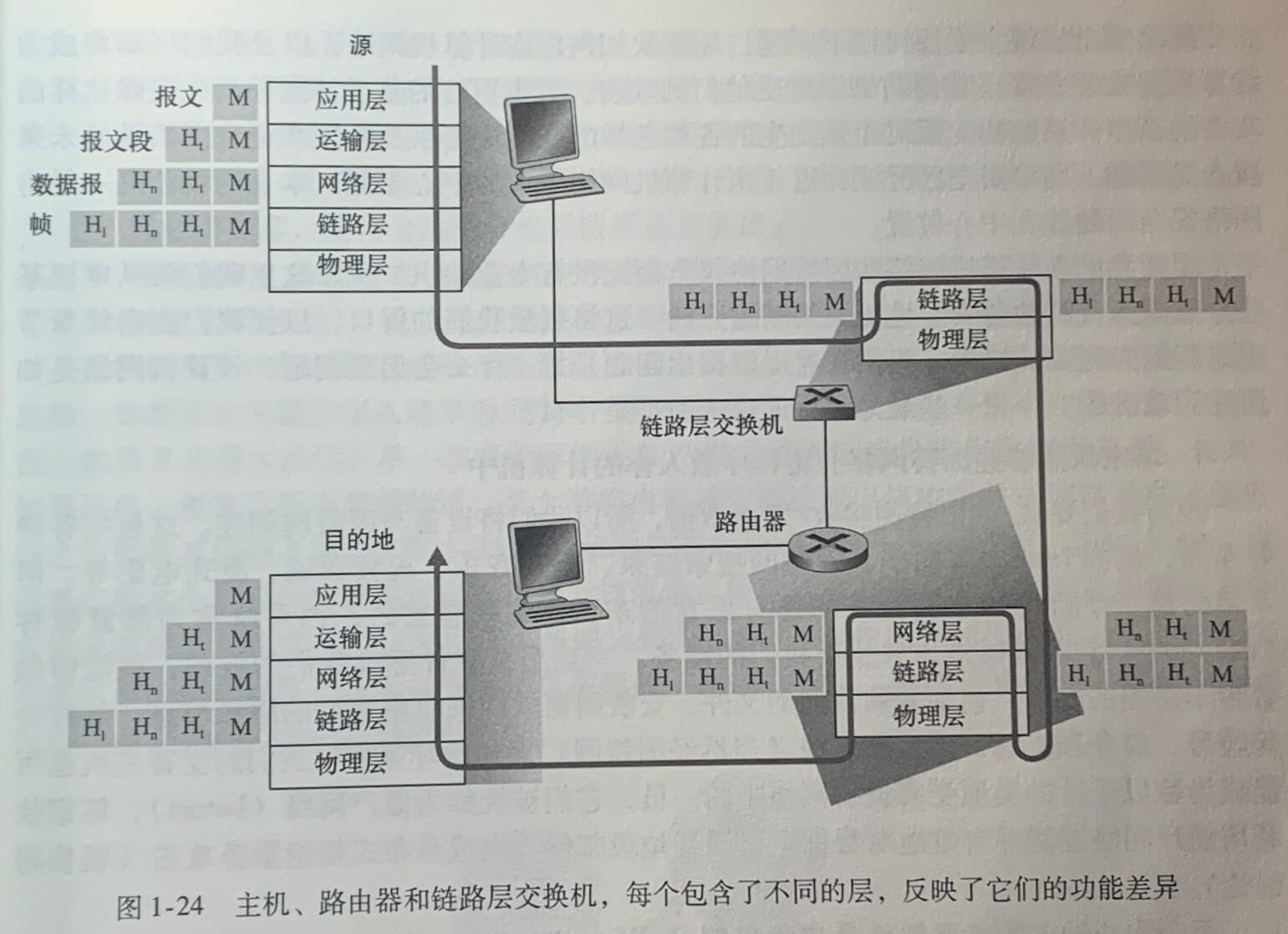
路由器和链路层交换机并不实现协议栈中的所有层次。
在每一次,一个分组具有两种类型的字段:首部字段和有效载荷字段(payload field)。有效载荷字段来自上一层的分组。
1.6 面对攻击的网络
-
黑客能够经因特网将有害程序放入你的计算机中
恶意软件(malware)能够进入并感染我们的设备,受害主机将成为数以千计的类似受害设备网络中的一员,它们被统称为僵尸网络(botnet),黑客利用僵尸网络控制并有效对目标主机展开垃圾邮件分发或分布式拒绝服务攻击。
多数恶意软件是自我负责的,一旦它感染了一台主机,就会从那台主机寻求进入因特网的其他主机,形成新的感染,这种将以指数式快速扩散。**病毒(virus)**是一种需要某种形式的交互用户来感染用户设备的恶意软件。**蠕虫(worm)**是一种无须任何明显用户交互就能进入设备的恶意软件。
-
黑客能够攻击服务器和网络基础设施
**拒绝服务攻击(Denial-of-Service (Dos) attack)**简称Dos攻击使得网络、主机或其他基础设施部分不能由合法用户使用。因特网 Dos 攻击极为常见,每年会出现数以千计的 Dos 攻击。
Dos攻击分为三种类型:
- 弱点攻击:向目标主机运行易受攻击的应用程序或操作系统发送制作精细的报文。该服务器可能会停止运行,或者主机崩溃。
- 带宽洪泛:攻击者像目标主机发送大量的分组,分组数量之多使得目标的接入链路变得拥塞,使得合法的分组无法到达服务器。
- 连接洪泛:攻击者在目标主机中创建大量的半开或全开TCP连接。该主机因这些伪造的连接而陷入困境,并停止接受合法的连接。

上图为分布式Dos(Distributed Dos, DDos)。
-
黑客能够嗅探分组
记录每个流经的分组副本的被动接收机被称为分组嗅探器(packet sniffer)。
Wireshark就是一种分组嗅探器。
防御嗅探的方法是使用密码学,对分组进行加密。
-
黑客能够伪装成你信任的人
将具有虚假源地址的分组注入因特网的能力被称为IP哄骗(IP spoofing)。
解决这个问题的方式是使用端点鉴别。
1.7 计算机网络和因特网的历史
分组交换的发展:1961 ~ 1972
在1969年的劳动节,第一台分组交换机在 Kleinrock 的监管下安装在美国加州大学洛杉矶分校。
专用网络和网络互联: 1972 ~ 1980
最初的 ARPAnet 是一个单一的、封闭的网络。之后出现了其他产商的各种网络,比如Telenet的BBN,IBM的SNA,此时,创建网络的网络的时机已经成熟,它的本质本质就是网络互联。
一开始的 TCP 协议具有IP协议的转发功能,之后IP转发功能被分离了出来。在20世纪70年代,TCP、UDP和IP的概念已经完成。
网络的激增:1980 ~ 1990
到了20世纪70年代末,大约200台主机与APRAnet相连。而到了80年代末,连到公共因特网的主机数量达到100 000台。
1983年1月1日,TCP/IP 作为 ARPAnet 新的标准主机协议,替代了NCP协议。80年代后期,TCP实现基于主机的拥塞控制,还研制出DNS(域名系统)。
因特网的爆炸:20世纪90年代
20世纪90年代的主要事件是万维网(World Wide Web)应用程序的出现,它将因特网带入世界上数以百万计的家庭和商业中。
Web 是由 Tim Berners-Lee 于1989 ~ 1991 年间在 CERN 发明的。 Tim Berners-Lee 和他的同事还研制了HTML、HTTP、Web服务器和浏览器的初始版本。到1993年年底前后,大约有200台Web服务器在运行。到了1995年,大学生们每天都在使用 Netscape 浏览器在Web上冲浪。1996年,微软开始开发浏览器,在几年后微软公司的 IE 战胜了 Netscape。
到了2000年末,因特网已经支持数百流行的应用程序,下面4种备受欢迎的应用程序:电子邮件、Web(包括Web浏览和因特网商务)、即时讯息、MP3的对等文件共享。
最新发展
下列进程值得特别关注:
- 自2000年开始,家庭宽带因特网接入的积极部署。
- 高速公共 WIFI 网络和经过4G 蜂窝电话网的中速因特网接入越来越普及。
- 诸如脸书、Instagram、推特和微信这样的在线社交网络已经在因特网之上构建了巨大的人际网络。
- 在线服务提供商如谷歌和微软已经广泛部署了自己的专用网络。
- 许多因特网商务公司在“云”中运行它们的应用。
第2章 应用层
2.1 应用层协议原理
研发网络应用程序的核心是写出能够运行在不同的端系统和通过网络彼此通信的程序。
现代网络应用程序中所使用的的两种主流体系结构:客户 - 服务器体系结构、对等(P2P)体系结构。

在**客户 - 服务体系结构(client-server architecture)**中,有一个总是打开的主机称为服务器,它服务于来自许多其他称为客户的主机的请求。具有这种结构的非常著名的应用程序包括Web、FTP、Telnet和电子邮件。
在一个**P2P体系结构(P2P architecture)中,对位于数据中心的专用服务器有最小(或者没有)依赖。应用程序的间断连接的主机对之间使用直接通信,这些主机对被称为对等方。这些对等方并不为服务提供商所有。这种对等方通信不必通过专门的服务器,该体系结构被称为对等方到对等方的。P2P体系最引人入胜的特性之一是它们的自拓展性(self-scalability)。**目前流行的P2P体系结构应用包括文件共享(例如 BitTorrent)、对等方协助下载加速器(例如迅雷)、因特网网络和视频会议(例如Skype)。未来P2P应用由于高度非集中式结构,面临安全性、性能和可靠性等挑战。
某些应用可能具有混合的体系结构,每个体系结构应用于不同的功能。
进程通信
在操作系统中,进行通信的实际上是**进程(process)**而不是程序。
1.客户和服务器进程
网络应用程序由成对的进程组成,这些进程通过网络相互发送报文。对于每对通信进程,通常将两个进程之一标识为客户(client),而另一个进程标识为服务器(server)。
在一对进程之间的通信会话场景中,发起通信(即在该会话开始时发起与其他进程的练习)的进程被标识为客户,在会话开始是等待联系的进程时服务器。
在Web中,浏览器进程是客户,Web服务器进程是服务器。在P2P文件共享中,当对等方A请求对等方B发送一个特定的文件时,对等方A是客户,对等方B是服务器。
2.进程与计算机网络之间的接口
进程通过一个称为套接字(socket)的软件接口向网络发送报文和从网络接收报文。套接字是同一台主机内应用层与运输层之间的接口。由于该套接字是建立网络应用程序的可编程接口,因此套接字也称为应用程序和网络之间的应用程序编程接口(Application Programming Interface, API)。

应用程序开发者可以控制套接字在应用层端的一切,但是对该套接字的运输层端几乎没有控制权。应用程序开发者对于运输层的控制仅限于:1.选择运输层协议;2.也许能设定几个运输层参数,如最大缓存或最大报文段长度等。一旦应用程序开发者选择了一个运输层协议,则应用程序就建立在由该协议提供的运输层服务之上。
3.进程寻址
为了标识接收进程,需要定义两种信息:1.主机的地址;2.在目的主机中指定接收进程的标识符。
在因特网中,主机有其**IP地址(IP address)**标识。端口号(port number用于标识接收进程。例如,Web服务器用端口号80来表示,邮件服务器进程(使用SMTP协议)用端口号25来标识。
可供应用程序使用的运输服务
当开发一个应用时,必须选择一种可用的运输层协议。从四个方面对应用程序服务要求进行分类:可靠数据传输、吞吐量、定时和安全性。
-
可靠数据传输
对于一些需要保证数据正确的应用,选择可靠数据传输的运输层协议是必要的,比如电子邮件、文件传输远程主机访问以及金融应用等等。
能容忍分组丢失的应用,比如交谈式音频/视频,能够承受一定量的数据丢失。
-
吞吐量
运输层协议提供确保吞吐量将对需要应用程序有吸引力。具有吞吐量要求的应用程序被称为带宽敏感的应用(bandwidth-sensitive application)。许多当前的多媒体应用是带宽敏感的。
-
定时
一个定时保证的例子如:发送方注入进套接字中的每个比特到达接收方的套接字不迟于100ms。比如因特网电话、虚拟环境、电话会议和多方游戏等,所有这些服务为了有效性而要求数据交付有严格的时间限制。
-
安全性
运输协议能够为应用程序提供一种或多种安全性服务。
因特网提供的运输服务
因特网(更一般的是TCP/IP网络)为应用程序提供两个运输层协议,即 UDP 和 TCP。

1.TCP服务
TCP 服务模型包括面向连接服务和可靠数据传输服务。
- 面向连接服务:在应用层数据报文开始流动之前,TCP 让客户和服务器互相交换运输层控制信息。这个所谓的握手过程提醒客户和服务器,让它们为大量分组的到来做好准备。在握手阶段后,一个**TCP连接(TCP connection)**就在两个进程的套接字之间建立了。这条连接是全双工的,即连接双方的进程可以在此连接上同时进行报文收发。当应用程序结束报文发送时,必须拆除该连接。
- 可靠的数据传送服务:通信进程能够依靠TCP,无差错、按适当顺序交付所有发送的数据。当应用程序的一端将字节流传送进套接字时,它能够依靠TCP将相同的字节流交付给接收方的套接字,而没有字节的丢失和冗余。
TCP协议还具有拥塞控制机制,当发送方和接收方之间的网络出现拥塞时,TCP的拥塞控制机制会抑制发送进程(客户或服务器)。
原本的TCP和UDP都没有提供任何加密机制,也就是说传送进套接字的数据都是明文传输,容易被窃听,因此因特网研制了TCP的加强版,称为安全套接字层(Secure Sockets Layer,SSL)。用SSL加强后的TCP不仅能够做传统的TCP所能做的一切,而且提供了关键的进程到进程的安全性服务,包括加密、数据完整性和端点鉴别。SSL不是与TCP和UDP在相同层次上的第三种因特网运输协议,而是一种对TCP的加强,这种强化是在应用层上实现的。
如果一个应用程序要使用SSL的服务,它需要在该应用程序的客户端和服务器端包括SSL代码。SSL有它自己的套接字API,这类似于传统的TCP套接字API。
2.UDP服务
UDP是一种不提供不必要服务的轻量级运输协议,它仅提供最小服务。UDP是无连接的,因此在两个进程通信前没有握手过程。UDP协议提供一种不可靠数据传送服务,UDP没有包括拥塞控制机制,所以UDP的发送端可以用它选定的任何速率向其下层(网络层)注入数据。
3.因特网运输协议所不提供的服务
对吞吐量和定时保证的服务在目前的因特网运输协议并没有提供。应用被设计成尽最大可能对付这种保证的缺乏。

应用层协议
**应用层协议(application - layer protocol)**定义了运行在不同端系统上的应用程序如何相互传递报文。特别是应用层协议定义了:
- 交换的报文类型,例如请求报文和响应报文。
- 各种报文类型的语法,如报文中的各个字段及这些字段是如何描述的。
- 字段的语义,即这些字段中的信息的含义。
- 确定一个进程何时以及如何发送报文,对报文进行响应的规则。
有些应用层协议是由 RFC 文档定义的,因此他们位于公共域中。例如,Web的应用层协议HTTP(超文本传输协议 [RFC 2616])就作为一个RFC可供使用。还有许多别的应用层协议是专用的,有意不为公共域使用。
2.2 Web 和 HTTP
20世纪90年代初期,一个主要的新型应用即万维网(World Wide Web)登上了历史舞台。Web极大地改变了人们与工作环境内外交流的方式。它将因特网从只是很多数据网之一的地位提升为仅有的一个数据网。
HTTP 概况
Web 应用层协议是超文本传输协议(HyperText Transfer Protocol, HTTP),它是 Web 的核心。HTTP 由两个程序实现:一个客户端程序和一个服务器程序。客户程序和服务器程序运行在不同的端系统中,通过交换 HTTP 报文进行会话。HTTP 定义了这些报文的结构以及客户和服务器进行报文交换的方式。
Web页面(Web page)(也叫文档)是由对象组成。一个对象只是一个文件,诸如一个 HTML 文件、一个 JPEG 图形、一个 Java 小程序或一个视频片段等等,且它们可通过一个 URL 地址寻址。多数 Web 页面含有一个 HTML基本文件(base HTML file)以及几个引用对象。流行的 Web 服务器有 Apache 、 Microsoft Internet Information Server 和 Nginx。
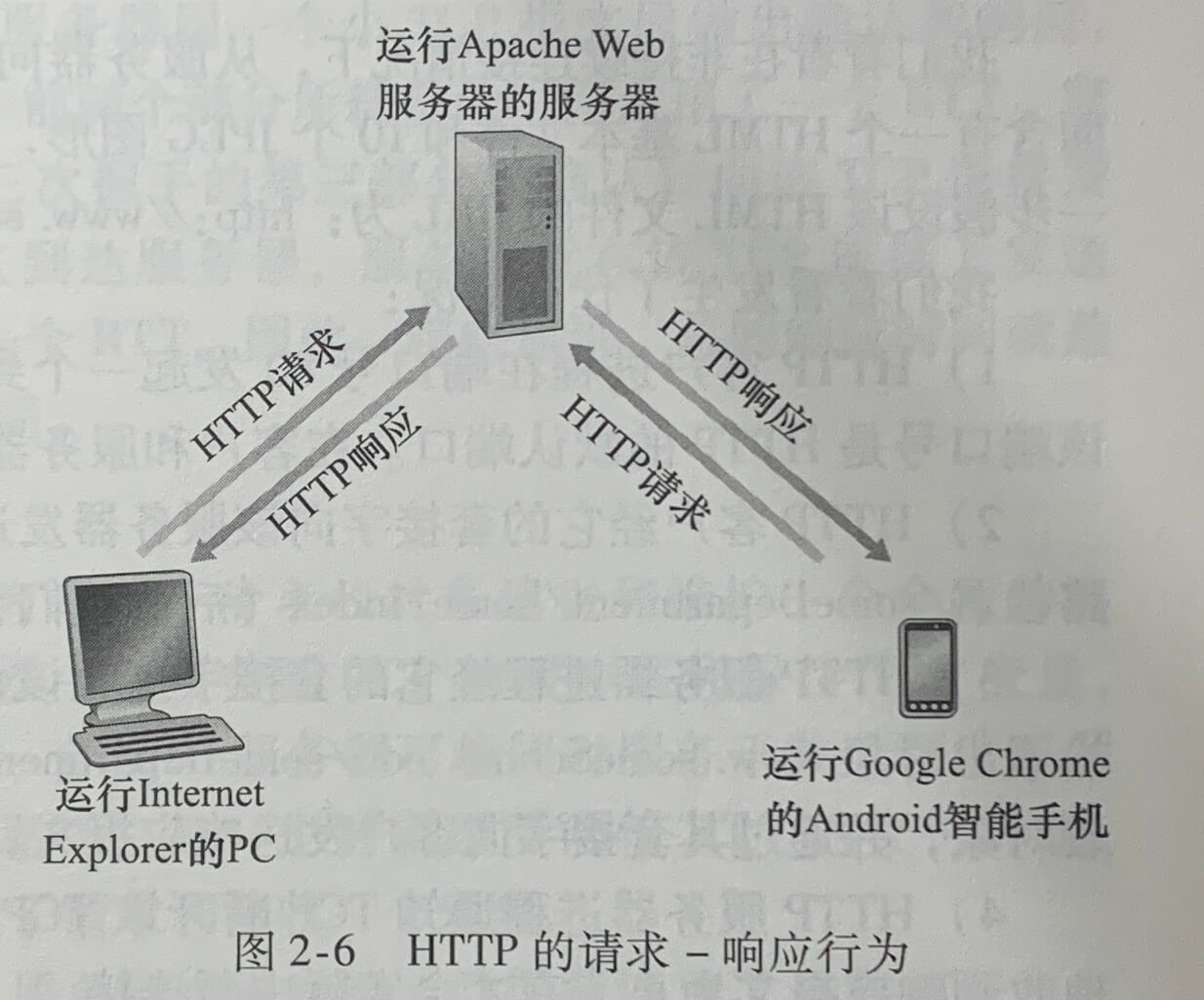
HTTP协议是一个无状态协议(stateless protocol)。Web 服务器总是打开的,具有一个固定的 IP 地址,且它服务与可能来自数以百万计 的不同浏览器的请求。
非持续连接和持续连接
每个请求/响应对是经一个单独的 TCP 连接发送,称为非持续连接(non-persistent connection),所有的请求及其响应经相同的 TCP 连接发送,称为持续连接(persitent connection)。
**往返时间(Round - Trip Time, RTT)**指一个短分组从客户到服务器然后再返回客户所花费的时间。
持续连接的性能优于非持续连接。
HTTP报文格式
HTTP 报文有两种:请求报文和响应报文。
-
HTTP 请求报文
GET /somedir/page.html HTTP/1.1 Host: www.somescholl.edu # 告诉服务器不用使用持续连接 Connection: close; # 浏览器的类型 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36 Accept-language: zh-CN,zh;q=0.9,en;q=0.8- 1
- 2
- 3
- 4
- 5
- 6
- 7
HTTP 请求报文的第一行叫做请求行(request line),其后续的行叫做首部行(header line)。请求行由3个字段:方法字段、URL 字段和 HTTP 版本字段。
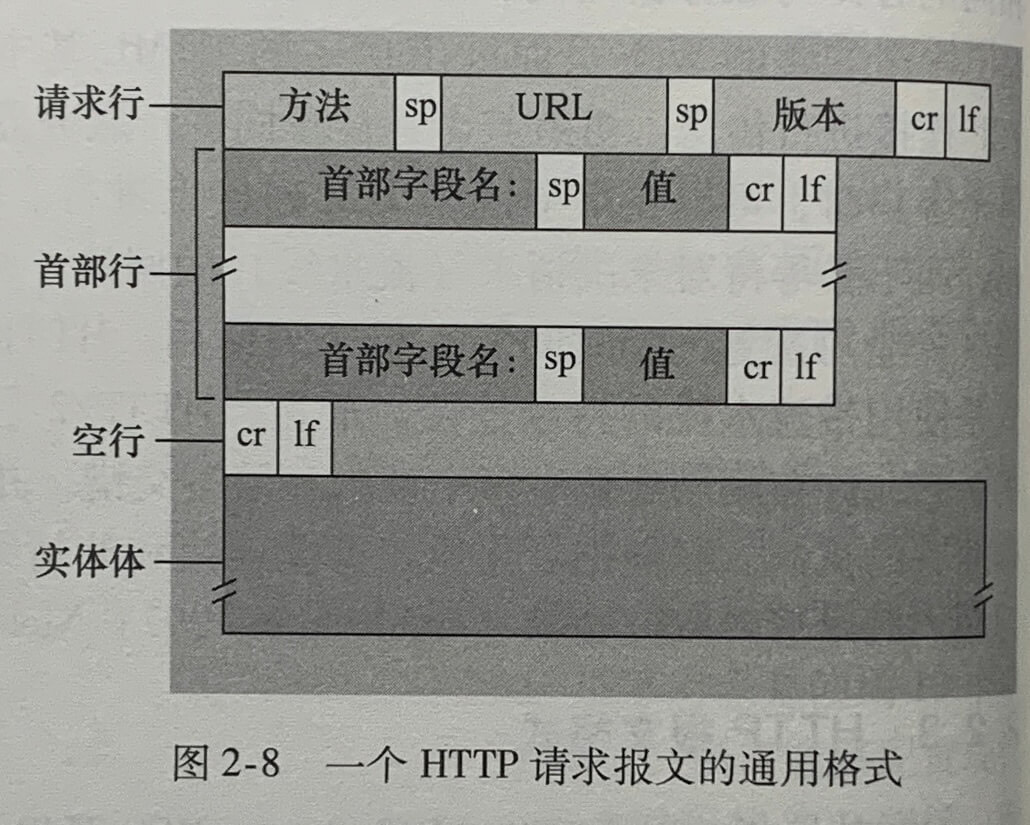
使用 GET 方法时实体体为空,使用 POST 方法时才使用该实体体。
-
HTTP 响应报文
HTTP/1.1 200 OK Connection: close # 服务器产生并发送该响应报文的日期和时间 Date: Tue, 18 Aug 2022 11:58:03 GMT Server: nginx/1.16.1 # 对象创建或最后修改的日期和时间 last-modified: Tue, 18 Aug 2022 12:31:44 GMT content-type: text/html content-length: 9521 (data data data ...)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
响应报文有三个部分:一个初始状态行(status line),6个首部行(header line),然后是实体体(entity body)。

用户与服务器的交互:cookie
cookie 允许站点对用户进行跟踪。

Web缓存
Web缓存器(Web cache)也叫代理服务器(proxy server),它是能够代表初始 Web 服务器来满足 HTTP 请求的网络实体。Web 缓存器有自己的磁盘存储空间,并在存储空间中保存最近请求过的对象的副本。
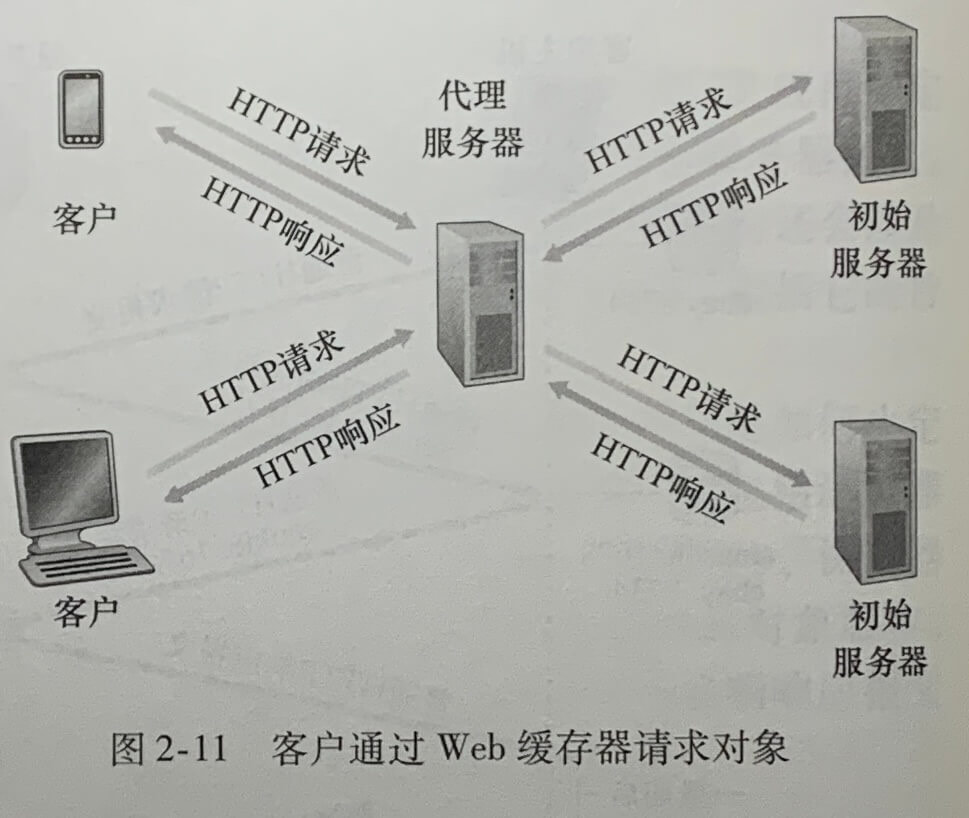
Web 缓存器即是服务器也是客户。Web 缓存区通常由 ISP 购买并安装。一个主要的住宅 ISP 可能在它的网络上安装一台或多台 Web 缓存器,并且预先配置其配套的浏览器指向这些缓存器。
Web 缓存器可以大大减少对客户请求的响应时间,特别是当客户与初始服务器之间的瓶颈带宽远低于客户与 Web 缓存器之间的瓶颈带宽时更是如此。Web 缓存器能大大减低因特网上的 Web 流量,从而改善所有应用的性能。
通过使用内容分发网络(Content Distribution Network,CDN),Web 缓存器正在因特网中发挥着越来越重要的作用。CDN 公司在因特网上安装了许多地理上分散的缓存器,因而使大量流量实现了本地化。
条件GET方法
为了证明保存在服务器上的对象是最新的,HTTP 协议有一种机制,允许缓存器证明它的对象是最新的,这种机制就是**条件GET(conditional GET)**方法。
- 请求报文使用 GET 方法
- 请求报文中包含一个“If-Modified-Since”的首部行
一个代理缓存器代表一个请求浏览器,像某 Web 服务器发送一个请求报文,该 Web 请求报文想缓存器发送带有Last-Modified的响应报文,缓存器会存储该日期值,当下次请求时,会在If-Modified-Since带上该值,如果值由变更则返回新的对象,如果没有变更,Web 服务器向该缓存器发送一个空body的响应报文,状态码是304 Not Modified
2.3 因特网中的电子邮件
电子邮件系统由3个主要部分组成:用户代理(user agent)、邮件服务器(mail server)和简单邮件传输协议(SMTP)。
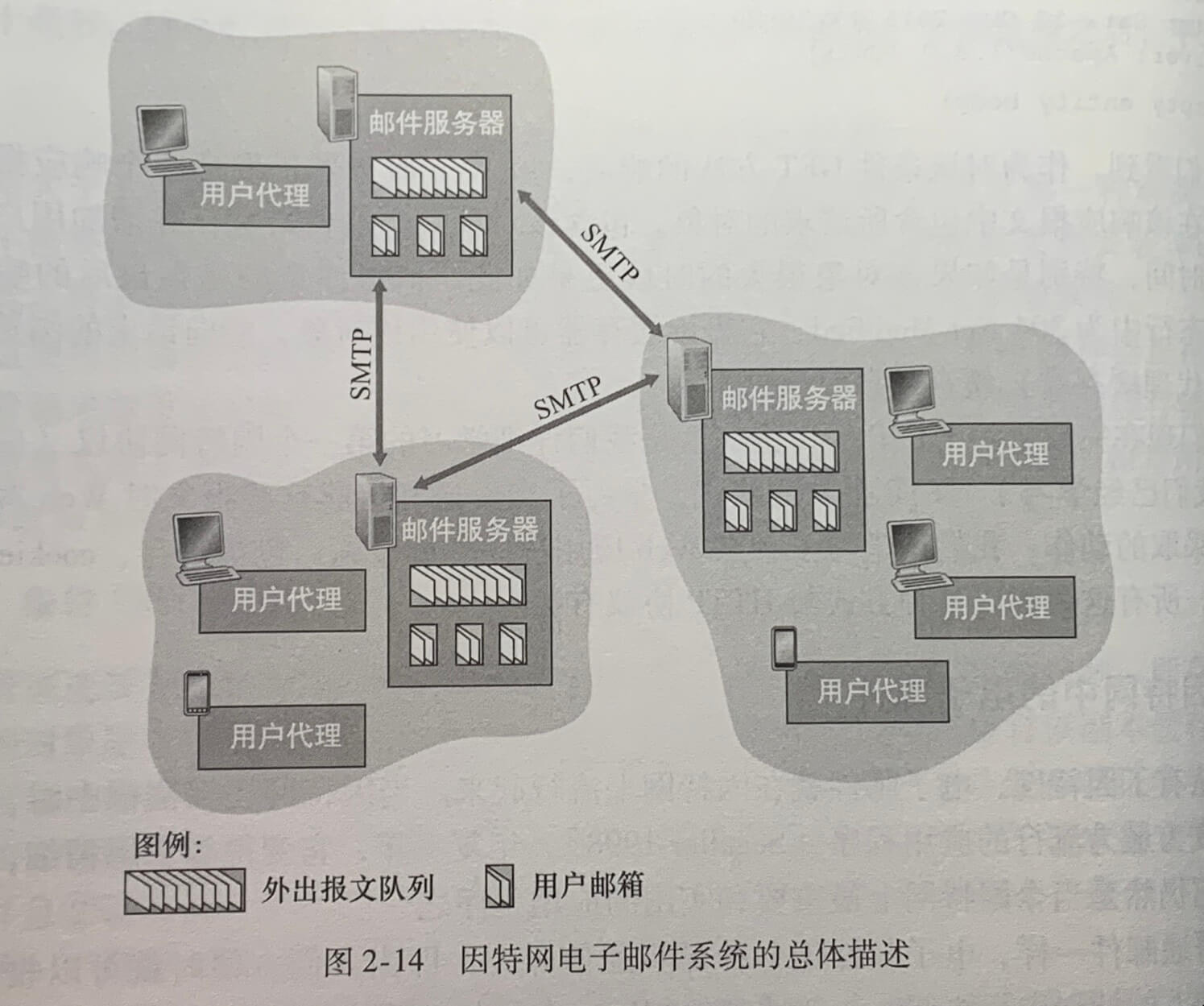
用户代理允许用户阅读、回复、转发、保存和撰写报文。微软的 Outlook 和 Apple Mail 是电子邮件用户代理的例子。
邮件服务器形成了电子邮件体系结构的核心。每台邮件服务器上既能运行 SMTP 的客户端也运行 SMTP 的服务器端。
SMTP
SMTP 用于从发送方的邮件服务器发送报文到接收方的邮件服务器。SMTP 限制所有邮件报文的体部分(不只是其首部)只能采用简单的7比特 ASCII 表示。
SMTP 一般不使用中间邮件服务器发送邮件,即使这两个邮件服务器位于地球的两端也是这样。如果接收方的邮件服务器没有开机,则发送方的报文将会保留在发送的邮件服务器上并等待新的尝试。
SMTP使用的是25端口。SMTP用的是持续连接。
与HTTP的对比
HTTP 是一个拉协议(pull protocol),即 TCP 连接是由想接受文件的机器发起的。而 SMTP 是推协议(push protocol),即发送邮件服务器把文件推向接收邮件服务器。
SMTP 要求每个报文采用7比特 ASCII 码格式,如果某报文包含了非7比特 ASCII字符或二进制数据,则该报文必须按照7比特 ASCII 码进行编码。HTTP 数据则不受这种限制。
HTTP 把每个对象封装到它自己的 HTTP 响应报文中,而 SMTP 则把所有报文对象放在一个报文中。
邮件报文格式
首部行和报文的体用空行(回车换行)进行分割。
每个首部必须包含一个From、To、Subject,由关键词后跟冒号及其值组成。
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Searching for the meaning of life
- 1
- 2
- 3
邮件访问协议
20世纪90年代,接收邮件的人通过登录到服务器主机,并在主机运行一个邮件阅读程序来阅读他的邮件。而在今天,邮件访问使用客户 - 服务器体系结构来进行访问,用户通过在端系统运行邮件客户程序进行查看,用户能享受一系列丰富的特性如查看多媒体报文和附件的能力。
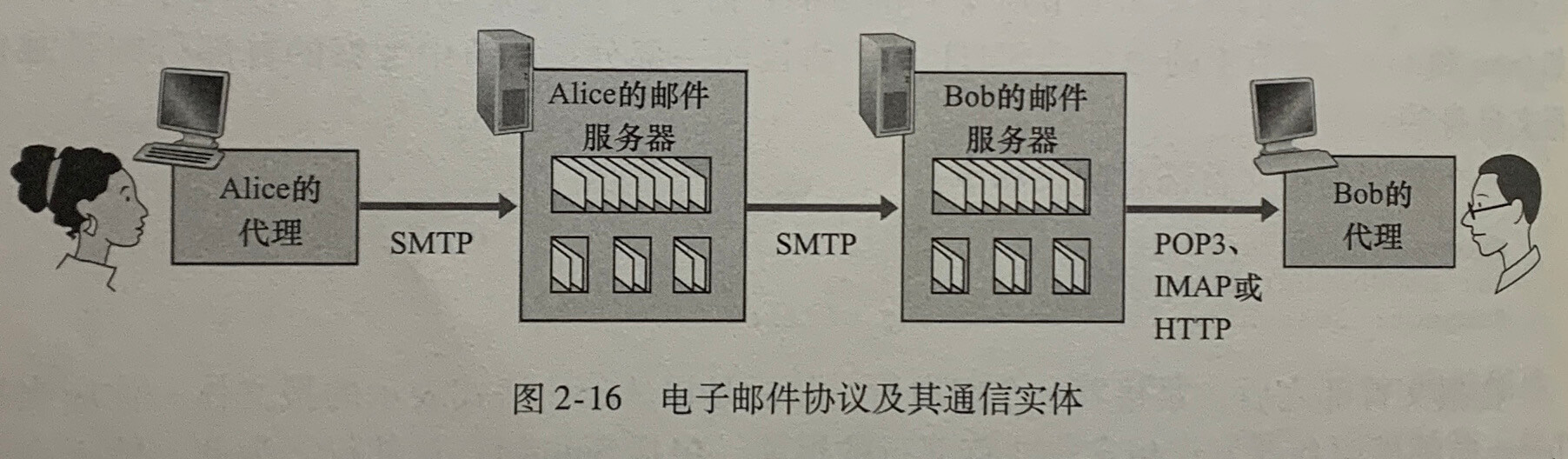
接收方不能直接使用 SMTP 得到报文,因为取报文是一个拉操作,而 SMTP 协议是一个推协议,通过引入一个特殊的邮件访问协议来解决。目前有一些流行的邮件访问协议,包括第三版的邮局协议(Post Office Protocol——Version 3,POP3)、**因特网邮件访问协议(Internet Mail Access Protocol,IMAP)**以及HTTP。
1.POP3
POP3 协议使用110端口,当用户代理(客户)打开一个到邮件服务器(服务器)的TCP连接后,POP3 就开始工作了。POP3按照三个阶段进行工作:特许(authorization)、事务处理以及更新。
在特许阶段,用户代理发送(以明文形式)用户名和口令以鉴别用户。在事务处理阶段,用户代理取回报文,同时还能对报文做删除标记,取消报文删除标记,以及获取邮件的统计信息。在更新阶段,客户发出quit命令之后结束会话,此时邮件服务器会删除那些被标记为删除的报文。
# 使用 telnet 连接到 pop.163.com 邮件服务器的110端口
telnet pop.163.com 110
Trying 220.181.12.110...
Connected to pop3.163.idns.yeah.net.
Escape character is '^]'.
+OK Welcome to coremail Mail Pop3 Server (163coms[10774b260cc7a37d26d71b52404dcf5cs])
# 输入用户名
user czl624824554
+OK core mail
# 输入密钥
pass xxxx
# 登录成功,进入事务处理阶段
+OK 11 message(s) [221897 byte(s)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
进入事务处理阶段,有4个命令,list显示邮件列表,retr查阅邮件,dele删除邮件,quit退出事务
2.IMAP
POP3不支持用户创建远程文件夹并为报文指派文件夹的方法。IMAP 比 POP3 具有更多的特色,不过也比 POP3 复杂得多。
IMAP 服务器把每个报文与一个文件夹联系起来,当报文第一次到达服务器时,它与收件人的 INBOX 文件夹相关联。IMAP 协议为用户提供创建文件夹以及将邮件从一个文件夹移动到另一个文件夹的命令。
3. 基于Web的电子邮件
如今越来越多用户使用 Web 浏览器收发电子邮件,用户代理是普通的浏览器,用户和它的远程邮箱之间的通信通过 HTTP 进行,当发送人要发送一封电子邮件时,使用的是 HTTP 而不是 SMTP,不过邮件服务器与其他邮件服务器之间还是使用 SMTP 协议。
2.4 DNS:因特网的目录服务
主机的一种标识方法是用它的主机名(hostname),如 www.facebook.com、www.google.com等等。主机也可以使用IP地址进行标识。一个 IP 地址由4个字节组成,并有着严格的层次结构。
DNS提供的服务
**域名系统(Domain Name System,DNS)提供主机名到 IP 地址转换的目录服务。DNS是:1.一个由分层的DNS服务器(DNS server)**实现的分布式数据库;2.一个使得主机能够查询分布式数据库的应用层协议。DNS 服务器通常运行 BIND(Berkeley Internet Name Domain)软件的 UNIX 机器。DNS 协议运行在 UDP 上,使用 53 号端口。
DNS 不是一个直接和用户打交道的应用。DNS是为因特网上的用户应用程序以及其他软件提供主机名转换为其背后的IP地址功能。DNS 通常采用位于网络边缘的客户和服务器,实现了关键的名字到地址转换功能。
DNS 通常是由其他应用层协议所使用,包括 HTTP、SMTP 和 FTP。
DNS还提供一些重要的服务:
- 主机别名(host aliasing),主机可以拥有一个或多个别名。
- 邮件服务器别名(mail server aliasing),例如
123455@163.com,电子邮件应用程序可以调用DNS,对提供的主机名别名进行解析,以获得该主机的规范主机名及其 IP 地址。MX 记录允许一个公司的邮件服务器和 Web 服务器使用相同的主机名。 - 负载分配(load distribution),站点被冗余分布在多台服务器上,每台服务器均允许在不同的端系统上,每个都有着不同的 IP 地址。这个服务同样适用于邮件服务器。
DNS工作机理概述
当用户端系统上的某些应用程序需要将主机名转换为 IP 地址时,应用程序将调用 DNS 的客户端,并指明需要转换的主机名,用户主机上的 DNS 接收到后,向网络发送一个 DNS 查询报文,DNS 请求和响应都使用 UDP 协议,经 53 端口。
1.分布式、层次数据库
DNS 服务器采用了分布式的设计方案。
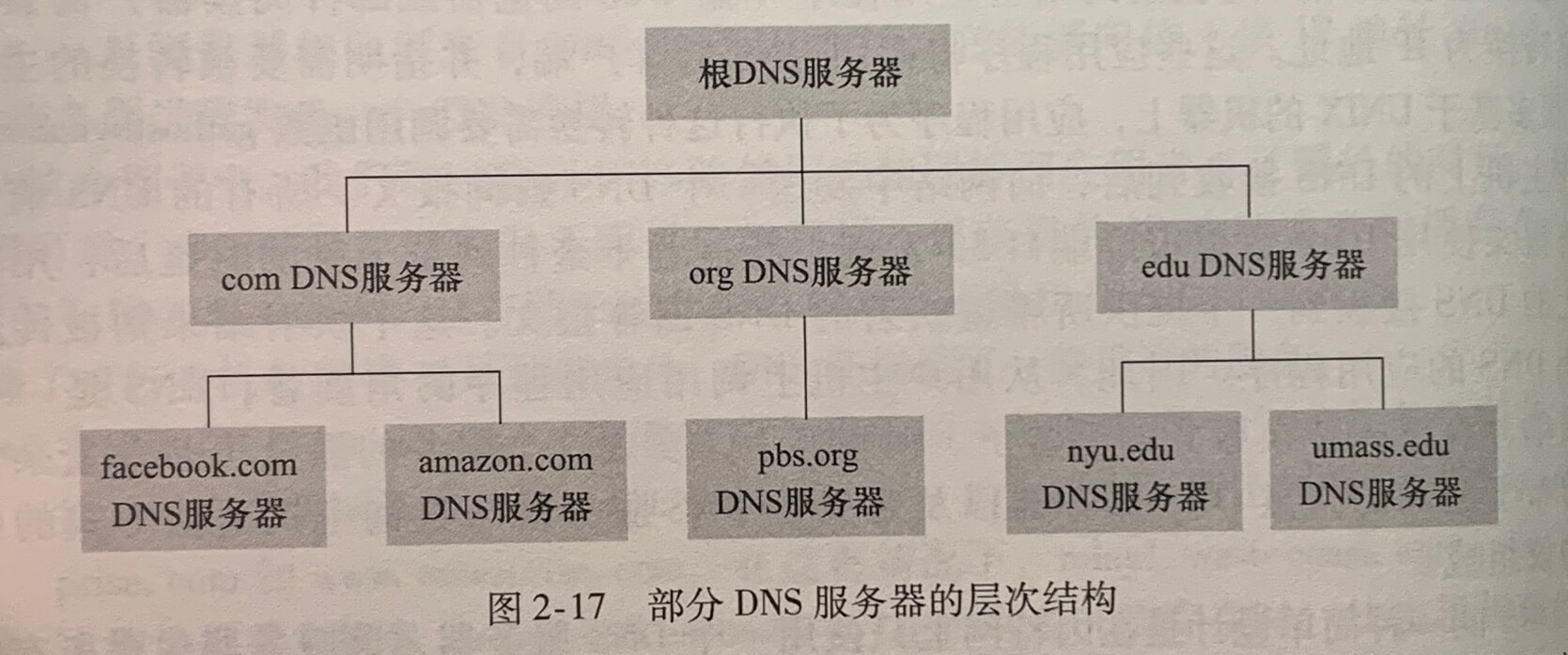
假设一个 DNS 客户要访问主机名www.amazon.com的 IP 地址,客户首先与根服务器之一联系,它将访问顶级域名 com 的 TLD 服务器的IP地址,客户与这些 TLD 服务器联系,它将访问 amazon.com 权威服务器的IP地址,客户最后与 amazon.com 权威服务器联系,它为主机名www.amazon.com返回其IP地址。
- 根 DNS 服务器,有400多个根名字服务器遍及全世界。这些根名字服务器由 13个不同的组织管理。根名字服务器提供 TLD 服务器的 IP 地址。
- 顶级域(DNS)服务器,顶级域(如com、org、net、edu和gov)和所有国家的顶级域(如cn、fr、ca和jp)都有 TLD 服务器(或服务器集群)。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
- 权威 DNS 服务器,在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。另一种方法是该组织支付费用让某个服务提供商存储该组织的记录。
**本地 DNS 服务器(local DNS server)**不属于服务器的层次结构,但它对 DNS 层次结构至关重要。每个 ISP 都有一台本地 DNS 服务器。当主机与某个 ISP 连接时,该 ISP 提供一台主机的 IP 地址,该主机具有一台或多台其本地 DNS 服务器的 IP 地址(通常通过DHCP)。通过访问 Windows 或 UNIX 的网络状态窗口,用户能够容易地确定它的本地 DNS 服务器的 IP 地址。

上图中利用了递归查询(recursive query)和迭代查询(iterative query)。cse.nyu.edu 到 dns.nyu.edu 是递归查询,后续的3个查询是迭代查询。
对某些机构 ISP 而言,主机的本地 DNS 服务器可能就与主机在同一个局域网中,对于某些居民区 ISP,本地 DNS 服务器通常与主机相隔不超过几台路由器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 服务器层次结构中。
2.DNS缓存
**DNS缓存(DNS caching)**是为了改善时延性能并减少在因特网上到处传输的 DNS 报文数量。在一个请求链中,当某 DNS 服务器接收一个 DNS 回答时,它会进行查询,并将其主机名/IP地址缓存起来,供下次直接使用。DNS 服务器一般在一段时间后(通常是两天)将丢弃缓存的信息。
本地 DNS 服务器还能够缓存 TLD 服务器的 IP 地址,因而允许本地 DNS 绕过查询链中的根 DNS 服务器。事实上,因为缓存,除了少数 DNS 查询意外,根服务器被绕过了。
DNS 记录和报文
实现 DNS 分布式数据库的所有 DNS 服务器存储了资源记录(Resource Record,RR),RR提供了主机名到 IP 地址的映射。
资源记录是一个4元组:(Name, Value, Type, TTL)。
TTL 是该记录的生存时间,即该记录缓存删除的时间,下面忽略掉 TTL 字段。
- 如果 Type = A,则 Name 是主机名,Value 是该主机名对应的 IP 地址。因此,一条类型为 A 的资源记录提供了标准的主机名到 IP 地址的映射。例如(relay1.bar.foo.com, 145.36.23.126, A)。
- 如果 Type = NS,则 Name 是个域(如 foo.com ),而 Value 是个知道如何获取该域中主机 IP 地址的权威 DNS 服务器的主机名。这个记录用于沿着查询链来路由 DNS 查询。例如(foo.com, dns.foo.com, NS)。
- 如果 Type = CNAME,则 Value 是别名为 Name 的主机名对应的规范主机名。该记录能根据主机名返回对应的规范主机名。例如(foo.com, relay1.bar.foo.com, CNAME)。
- 如果 Type = MX,则 Value 是个别名为 Name 的邮件服务器的规范主机名。例如(foo.com, mail.bar.foo.com, MX)。
如果一台 DNS 服务器是一台权威 DNS 服务器,那么该 DNS 服务器会包含用于主机名的类型 A 记录。如果服务器不是用于某主机名的权威服务器,那么该服务器将包含一条类型 NS 记录,还将包括一条类型 A 记录。
1.DNS报文
DNS 只有查询和回答报文,且这两种格式相同。

- 标识符的作用用于客户用它来匹配发送的请求和接收到的回答。
- 问题区域包含正在进行的查询信息。该区域包括主机名和类型字段。
- 回答区域包含了对最初请求的名字的资源记录,在回答区域中可以包含多条RR。
- 权威区域包含了其他权威服务器的记录。
- 附加区域包含其他有帮助的记录。
nslookup程序用于查询 DNS 记录。
➜ ~ nslookup
> www.baidu.com
# DNS服务器地址
Server: 202.96.134.133
Address: 202.96.134.133#53
Non-authoritative answer:
# 规范主机名
www.baidu.com canonical name = www.a.shifen.com.
Name: www.a.shifen.com
# IP 地址
Address: 14.215.177.39
Name: www.a.shifen.com
# IP 地址
Address: 14.215.177.38
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.在DNS数据库中插入记录
当你要注册域名(如abc.com)的时候,第一件事是在注册登记机构注册域名,注册登记机构(register)是一个商业实体,它验证该域名的唯一性,将该域名输入 DNS 数据库,对提供的服务收取费用。你需要向该机构提供你的基本和辅助权威 DNS 服务器的名字和 IP 地址。之后注册等级机构将一个类型 NS 和一个类型 A 的记录输入 TLD 服务器。
一旦完成上述步骤,人们将能够访问你的 Web 站点。
DNS 安全性:到目前为止,还没有一个攻击能妨碍 DNS 服务。
2.5 P2P 文件分发
P2P 不依赖于 客户 - 服务器体系结构,而是使用P2P 体系结构,对总是打开的基础设施服务器有最小的(或者没有)依赖,成对间歇连接的主机(称为对等方)彼此直接通信。这些对等方不为服务提供商所拥有,而是受用户控制的桌面计算机和膝上计算机。
当分发一个大文件时,在客户 - 服务器体系结构,服务器需要承担极大的负担,它必须向每个对等方发送该文件的一个副本,且消耗了大量的服务器带宽。在 P2P 文件分发中,每个对等方能够将收到的文件发给其他任何对等方,从而在分发过程中协助该服务器。
目前最流行的 P2P 文件分发协议是 BitTorrent。
-
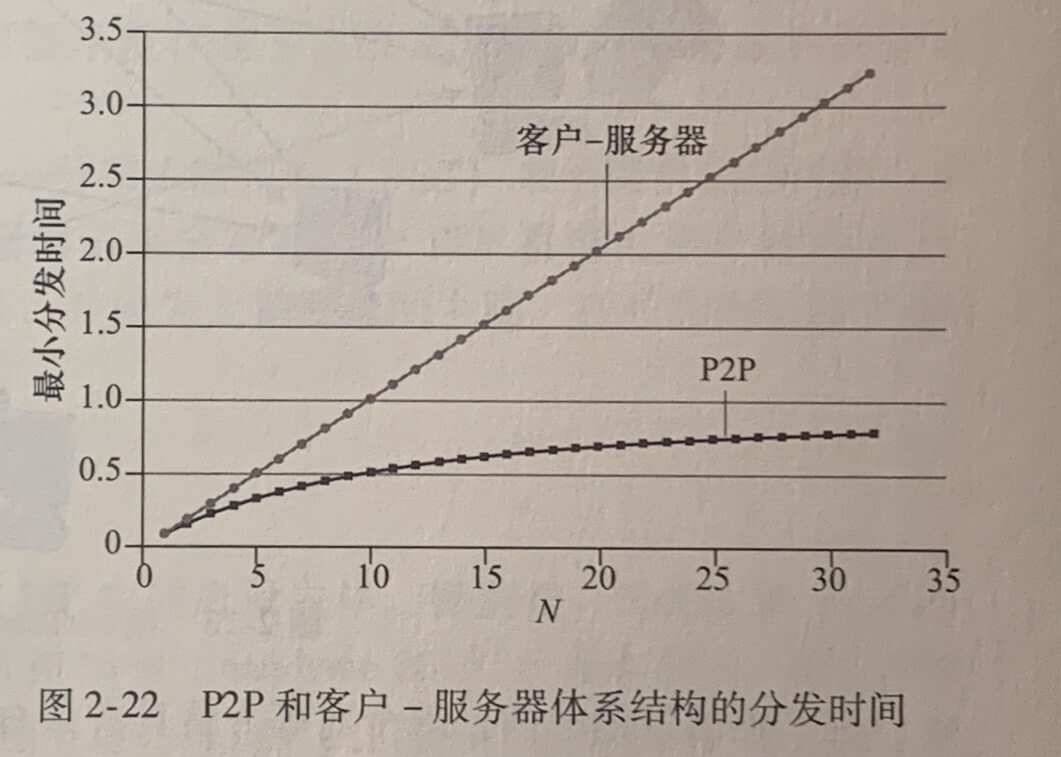
P2P 体系结构的扩展性
客户 - 服务器体系结构随着对等方数量的增加,分发时间呈线性增长并且没有界。在 P2P 体系结构,对等方除了是比特的消费者还是它们的重新分发者。
-
BitTorrent
BitTorrent 是一种用于文件分发的流行 P2P 协议。参与一个特定文件分发的所有对等方的集合被称为一个 洪流(torrent)。
在一个洪流中的对等方彼此下载等长度的文件块(chunk),当一个对等方首次加入一个洪流时,它没有块,随着时间的流逝,它累积了越来越多的块。当它下载块时,也为其他对等方上载了多个块。一旦某个对等方获得了整个文件,它也许离开洪流,或留在该洪流中并继续向其他对等方上载块。
每个洪流具有一个基础设施节点,称为 追踪器(tracker)。当一个对等方加入某洪流时,它向追踪器注册自己,并周期性地通知追踪器它仍在该洪流中。一个给定的洪流可能在任何时候具有数以百计或数以千计的对等方。
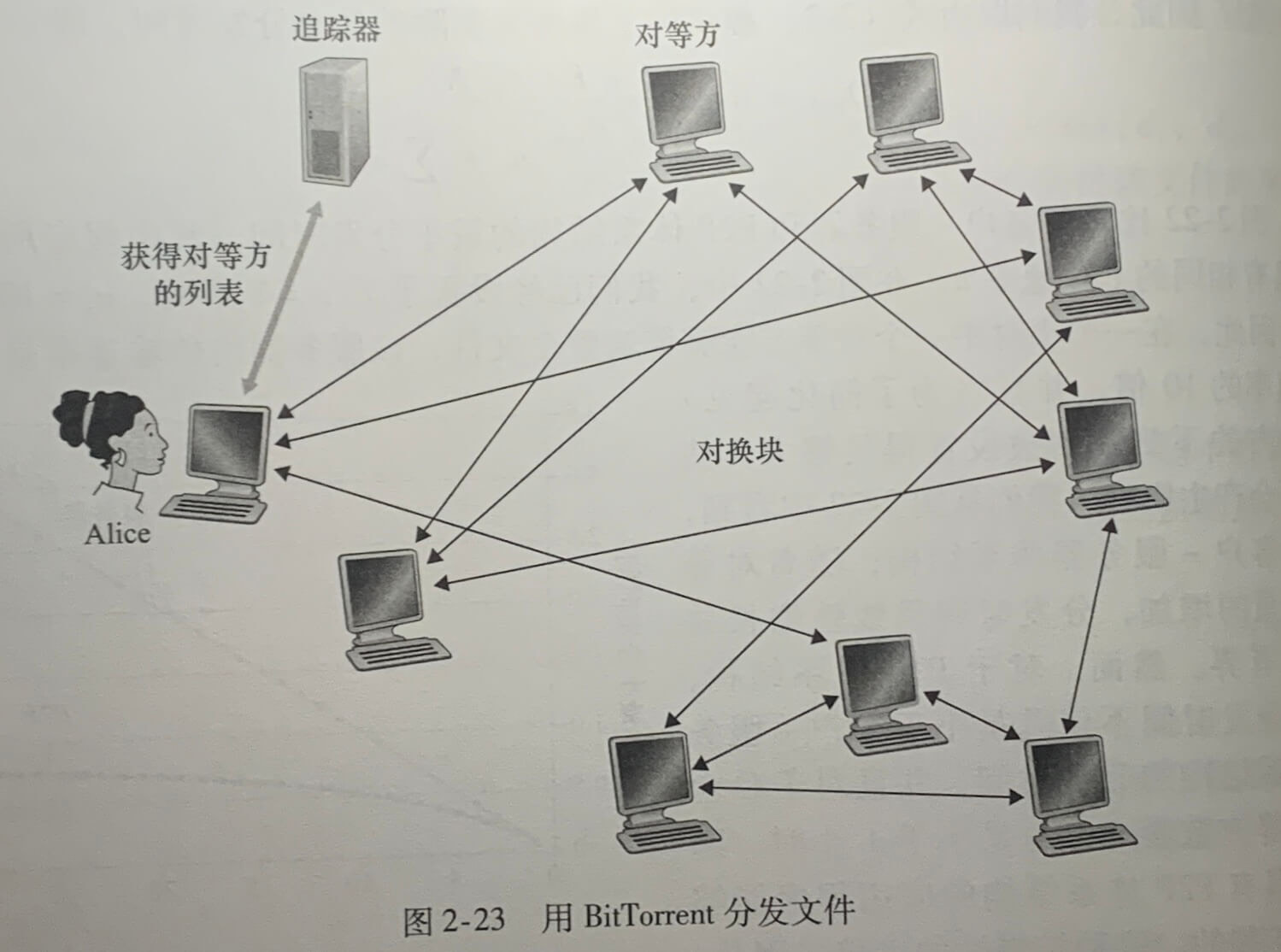
上图中,Alice加入该洪流,并从追踪器获取对等方的列表,Alice会尝试与该列表上的所有对等方创建并行的 TCP 连接,我们称这种为“邻近对等方”。随着时间流逝,其他对等方可能离开,其他新加入的对等方可能试图与 Alice 创建 TCP 连接。因此一个对等方的邻近对等方将随时间而波动。
在任何给定的时间,每个对等方将具有来自该文件的块的子集,并且不同的对等方具有不同的子集。Alice 周期性(经 TCP 连接)询问每个邻近对等方它们所具有的块列表。如果 Alice 具有 L 个不同的邻居,她将获得 L 个块列表。Alice 将对她当前还没有的块发出请求。
**最稀缺优先(rarest first)**技术,优先请求最稀缺的块,从而达到均衡每个块在洪流中的副本数量。
2.6 视频流和内容分发网
因特网视频
比特率用来衡量视频质量,今天现成的压缩算法能够将一个视频压缩成所希望的任何比特率。比特率越高,图像质量越好。
HTTP流和DASH
在 HTTP 流中,当用户要看视频时,客户与服务器创建一个 TCP 连接并发送对该 URL 的 HTTP GET 请求。服务器以底层网络协议和流量条件允许的尽可能快的速率发送该视频文件。在客户一侧,字节被收集在客户应用缓存中。一旦该缓存中的字节数量超过预先设定的门限,应用程序就开始播放。
尽管 HTTP 流在实践中已经得到广泛部署,但它具有严重缺陷,即所有客户接收到相同编码的视频,由于客户的带宽大小不同,这将对带宽小的客户产生卡顿现象。为了解决这个问题,**经 HTTP 的动态适应性流(Dynamic Adaptive Streaming over HTTP,DASH)**出现了。
在 DASH 中,视频编码被分为不同版本,每个版本对应不同的比特率,客户动态请求来自不同版本且长度为几秒的视频端数据块。当可用带宽提高时,客户自然选择来自高速率版本的块。当可用带宽较低时,客户自然选择低速率版本的块。客户用 HTTP GET 请求报文一次选项一个不同的块。
使用 DASH 后,每个视频版本存储在 HTTP 服务器中,每个版本都有一个不同的 URL。HTTP 服务器有一个告示文件(manifest file),为每个版本提供一个 URL 及其比特率。客户首先请求该告示文件并且得知各种各样的版本。然后客户通过 HTTP GET 请求报文中对每块指定一个 URL 和一个字节范围,一次选择一块。DASH 允许客户自由地在不同的质量等级之间切换。
内容分发网
内容分发网(Content Distribution Network,CDN)管理分在多个地理位置上的服务器,在它的服务器中存储视频(和其他类型的 Web 内容,包括文档、图片和音频)的副本,并且所有试图将每个用户请求定向到一个将提供最好的用户体验的 CDN 位置。
CDN 可以是专用CDN(private CDN),例如谷歌的 YouTube视频自家的CDN,也可以是第三方CDN(third-party CDN),它为多个内容提供商分发内容。
CDN 采用两种不同的服务器安置原则
- 深入,通过在遍及全球的接入 ISP 中部署服务器集群来深入到 ISP 的接入网中。目标是靠近端用户,减少端用户和 CDN 集群之间链路和路由器的数量,从而改善用户感受的时延和吞吐量。但维护和管理集群的任务成为了挑战。
- 邀请做客,通过在少量(例如10个)关键位置建造大集群来邀请到 ISP 做客,这些 CDN 通常将它们的集群放置在因特网交换点(IXP)。这种设计原则产生较低的维护和管理开销,但可能以对端用户的较高时延和较低吞吐量为代价。
1.CDN 操作
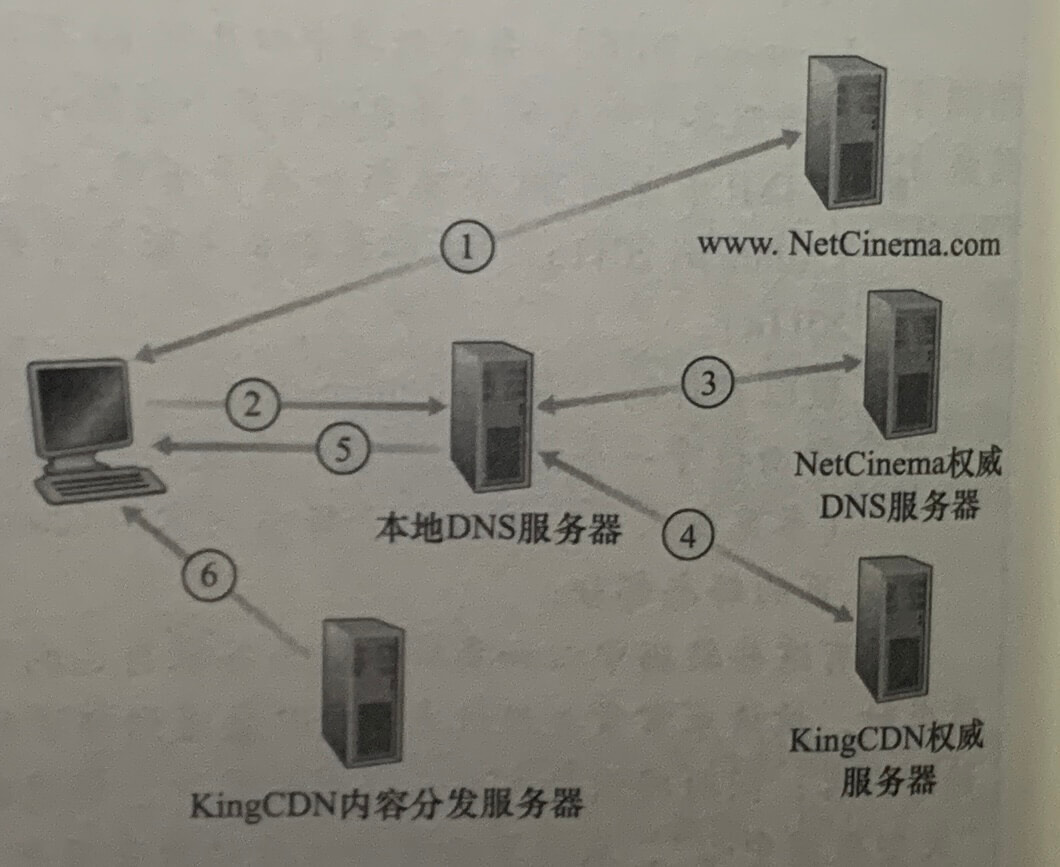
当用户主机中的一个浏览器请求一个特定的视频(URL)时,CDN 截获该请求,以便能够:1.确定此时适应于该客户的 CDN 服务器集群;2.将客户的请求重定向到该集群的某台服务器。
大多数 CDN 利用 DNS来截获和重定向请求。
2.集群选择策略
集群选择策略即动态地将客户定向到 CDN 中的某个服务器集群或数据中心的机制。
一种简单的策略是指派客户到地理上最为邻近的集群。使用商用地理位置数据库,每个 LDNS IP 地址都映射到一个地理位置。CDN 选择地理上最为接近的集群。该策略的缺点是可能执行的效果差,因为地理最邻近的集群可能并不是最近的集群,还有一个问题是某些用户使用位于远地的 LDNS。
为了基于当前浏览条件为客户决定最好的集群,CDN 对其集群和客户之间的时延和丢包性能执行周期性的实时测量。
2.7 套接字编程:生成网络应用
典型的网络应用由一对程序(客户程序和服务器程序)组成,它们位于两个不同的端系统。当运行这两个程序时,创建了一个客户进程和一个服务器进程,它们通过从套接字读出和写入数据在彼此之间进行通信,
网络应用程序有两类。一类是由协议标准中所定义的操作的实现,这样的应用程序称为“开放”的。客户程序和服务器程序必须遵循由该 RFC 所规定的规则。另一类是专用的网络应用程序,这种情况下的客户和服务器程序应用的应用层协议没有公开发布在某 RFC 中或其他地方。
UDP套接字编程
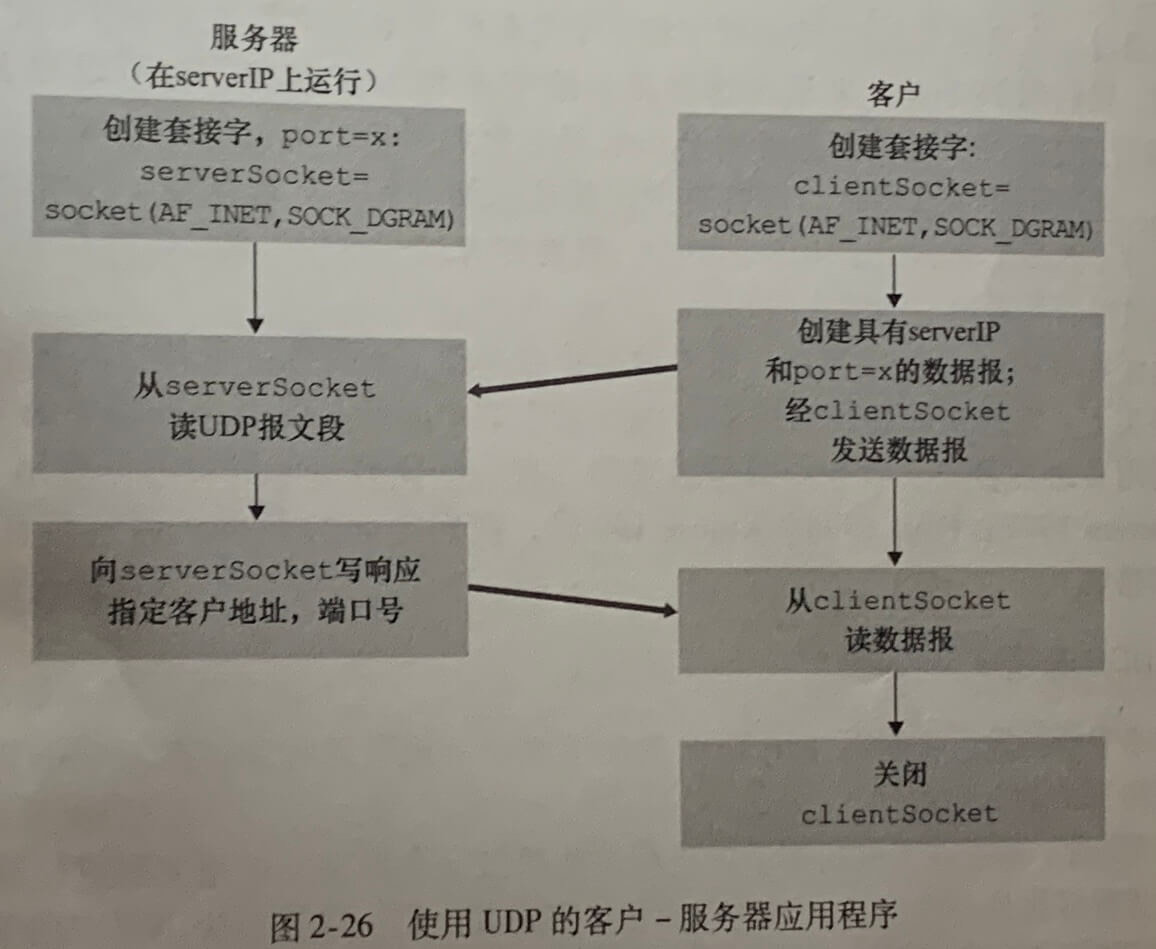
DGRAM代表UDP的套接字。
# 客户端 from socket import * serverName = '127.0.0.1' serverPost = 12000 clientSocket = socket(AF_INET, SOCK_DGRAM) message = input('input lowercase sentence:') # 发送需要指定地址和端口 clientSocket.sendto(message.encode(), (serverName, serverPost)) modifiedMessage, serverAddress = clientSocket.recvfrom(2048) print(modifiedMessage.decode()) clientSocket.close() # 服务器端 from socket import * serverPort = 12000 serverSocket = socket(AF_INET, SOCK_DGRAM) serverSocket.bind(('', serverPort)) print('The server is ready to receive') while True: message, clientAddress = serverSocket.recvfrom(2048) print('收到消息:', message.decode()) modifiedMessage = message.decode().upper() serverSocket.sendto(modifiedMessage.encode(), clientAddress)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
TCP套接字编程
在 TCP 连接中,发送分组之前需要进行3次握手。服务器为了能够对客户的初始接触做出反应,服务器必须已经开启,即服务器进程运行起来。
当客户生成其 TCP 套接字时,它指定了服务器主机的 IP 地址和服务器欢迎套接字的端口号,客户生成其套接字后,客户发起一个三次握手并创建于服务器的一个 TCP 连接。三次握手发生在运输层,对客户和服务器程序是完全透明的。
在三次握手期间,当服务器接收到客户进程的请求连接时,它将生成一个新的套接字,这个新套接字专门用于特定的客户,称为连接套接字(connectionSocket)。

客户进程可以向连接套接字发送任意字节,TCP 保证服务器进程能够按发送的顺序接收每个字节(可靠服务)。客户和服务器既能接收字节也能发送字节。
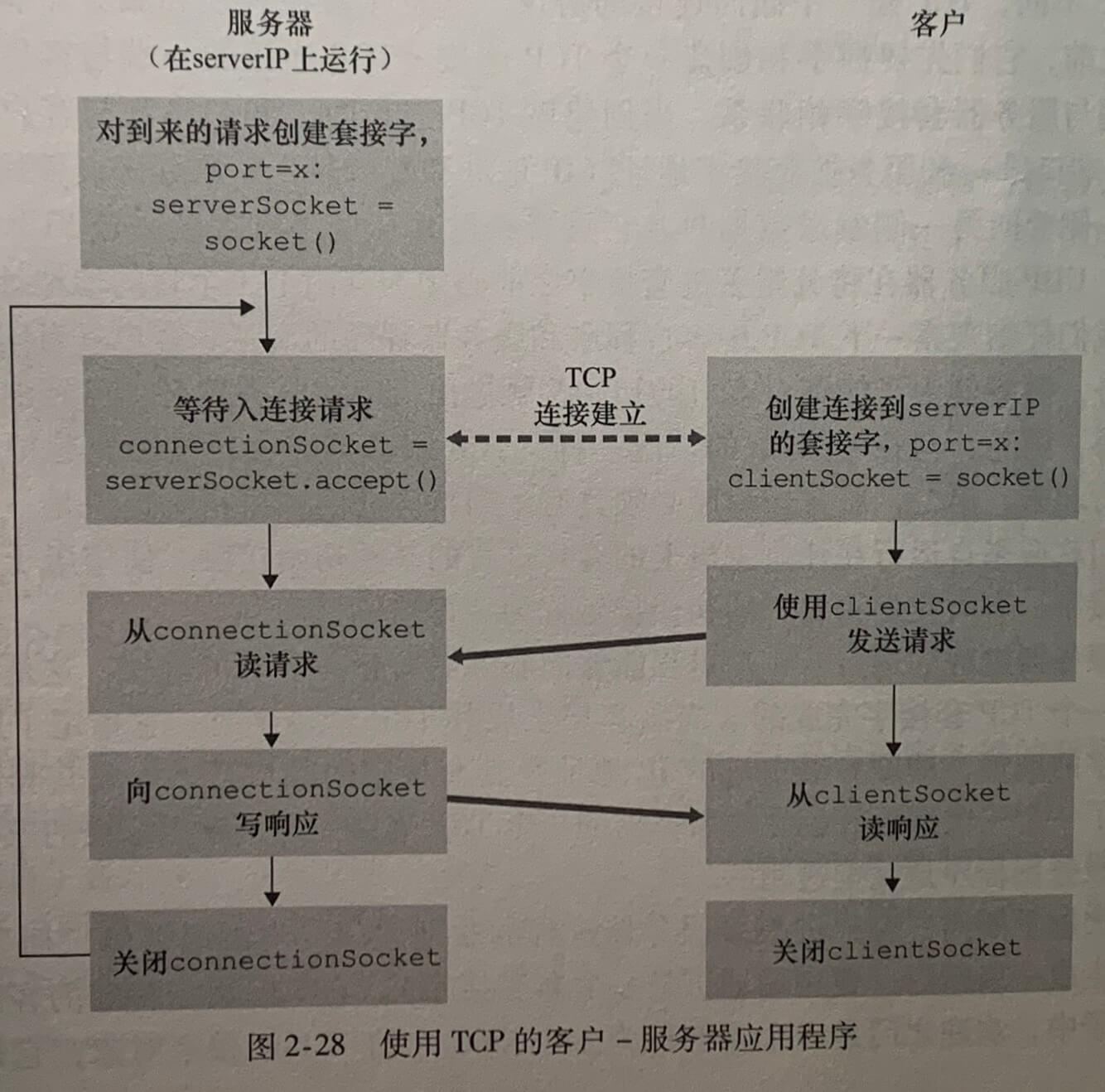
# 客户 from socket import * serverName = 'localhost' serverPort = 12000 clientSocket = socket(AF_INET, SOCK_STREAM) # 建立与服务器的TCP连接,执行三次握手 clientSocket.connect((serverName,serverPort)) sentence = input('Input lowercase sen tence:') # 与 UDP 不同,发送不需要传 IP 和端口 clientSocket.send(sentence.encode()) modifiedSentence = clientSocket.recv(2048) print('From Server: ', modifiedSentence.decode()) clientSocket.close() # 服务器 from socket import * serverPort = 12000 # 创建欢迎套接字 serverSocket = socket(AF_INET, SOCK_STREAM) # 将服务器的端口号域该套接字关联起来 serverSocket.bind(('', serverPort)) # 监听,等待客户敲门,最大连接数为1 serverSocket.listen(1) print('The server is ready to receive') while True: # 客户敲门,创建连接套接字,由这个特定的客户专用 connectionSocket, addr = serverSocket.accept() sentence = connectionSocket.recv(2048).decode() capitalizedSentence = sentence.upper() connectionSocket.send(capitalizedSentence.encode()) connectionSocket.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
第3章 运输层
3.1 概述和运输层服务
运输层协议为运行在不同主机上的应用进程之间提供了**逻辑通信(logic communication)**功能。应用程序使用运输层提供的逻辑通信功能彼此发送报文,而无须考虑承载这些报文的物理基础设施的细节。

运输层协议是在端系统中而不是在由器中实现的。运输层将从发送应用程序进程接收到的报文转换成运输层分组,该分组称为运输层报文段(segment)。实现的方法是将应用报文划分为较小的块,并为每块加上一个传输层首部以生成运输层报文段,然后在发送端系统中在传输层将这些报文段传递给网络层,网络层将其封装成网络层分组(即数据报)并向目的地发送。
网络路由器仅作用于该数据报的网络层字段,它们不检查封装在该数据报的运输层报文段的字段。
3.1.1 运输层和网络层的关系
网络层提供主机之间的逻辑通信,而运输层为运行在不同主机上的进程之间提供逻辑通信。运输层协议只工作在端系统中。在端系统中,运输层协议将来自应用进程的报文移动到网络边缘(即网络层)。
运输层协议能够提供的服务受制于底层网络层协议的服务模型。如果网络层无法为主机之间发送的运输层报文段提供时延或带宽保证的话,运输层协议也就无法为进程之间发送的应用程序报文提供时延或带宽保证。
3.1.2 因特网运输层概述
因特网为应用程序提供了两种截然不同的可用运输层协议,**UDP(用户数据报协议)**为调用它的应用程序提供了一种不可靠、无连接的服务。**TCP(传输控制协议)**为调用它的应用程序提供了一种可靠的、面向连接的服务。
网络层 IP 的服务模型是尽力而为交付服务,IP 尽最大努力在通信的主机之间交付报文段,但它并不做任何确保,它不确保报文段的交付,不确保报文段的按序交付,不确保报文段中数据的完整性。由于这些原因,IP 被称为不可靠服务(unreliable service)。
UDP 和 TCP 最基本的责任是,将两个端系统间 IP 的交付服务扩展为运行在端系统上的两个进程之间的交付服务。将主机间交付扩展到进程间交付被称为运输层的多路复用与多路分解。UDP 和 TCP 还可以通过在其报文段中包括差错检查字段而提供完整性检查。进程到进程的数据交付和差错检查是两种最低限度的运输层服务,也是 UDP 所能提供的仅有的两种服务。
TCP 为应用程序提供了几种附加服务,可靠数据传输(reliable data transfer)、**拥塞控制(congestion control)**等。
3.2 多路复用与多路分解
在目的主机,运输层从紧邻其下的网络层接收报文段,运输层负责将这些报文段中的数据交付给在主机上运行的适当应用程序进程。
一个进程有一个或多个套接字(可以有多个端口),套接字相当于从网络向进程传递数据和从进程向网络传递数据的门户。
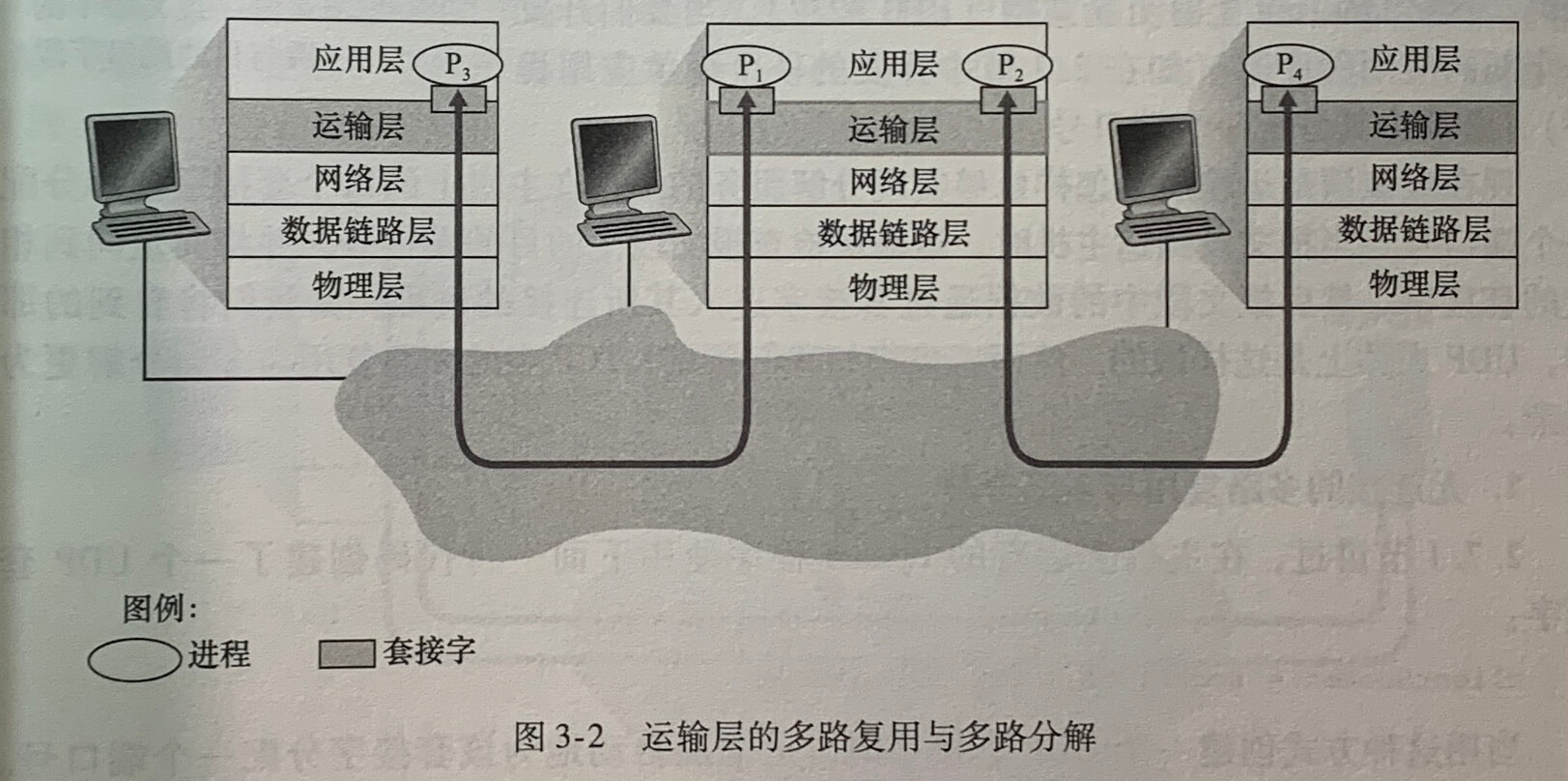
在接收主机中的运输层实际上并没有直接将数据交付给进程,而是将数据交给一个中间的套接字。由于在任一时刻,在接收主机上可能不止一个套接字,所以每个套接字都有唯一的标识符。标识符的格式取决于它是 UDP 还是 TCP 套接字。
在运输层报文段中的数据交付到正确的套接字的工作称为多路分解(demultiplexing)(从下往上)。在源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息(这将用于分解)从而生成报文段,然后将报文段传递到网络层,所有这些工作称为多路复用(multiplexing)(从上往下)。

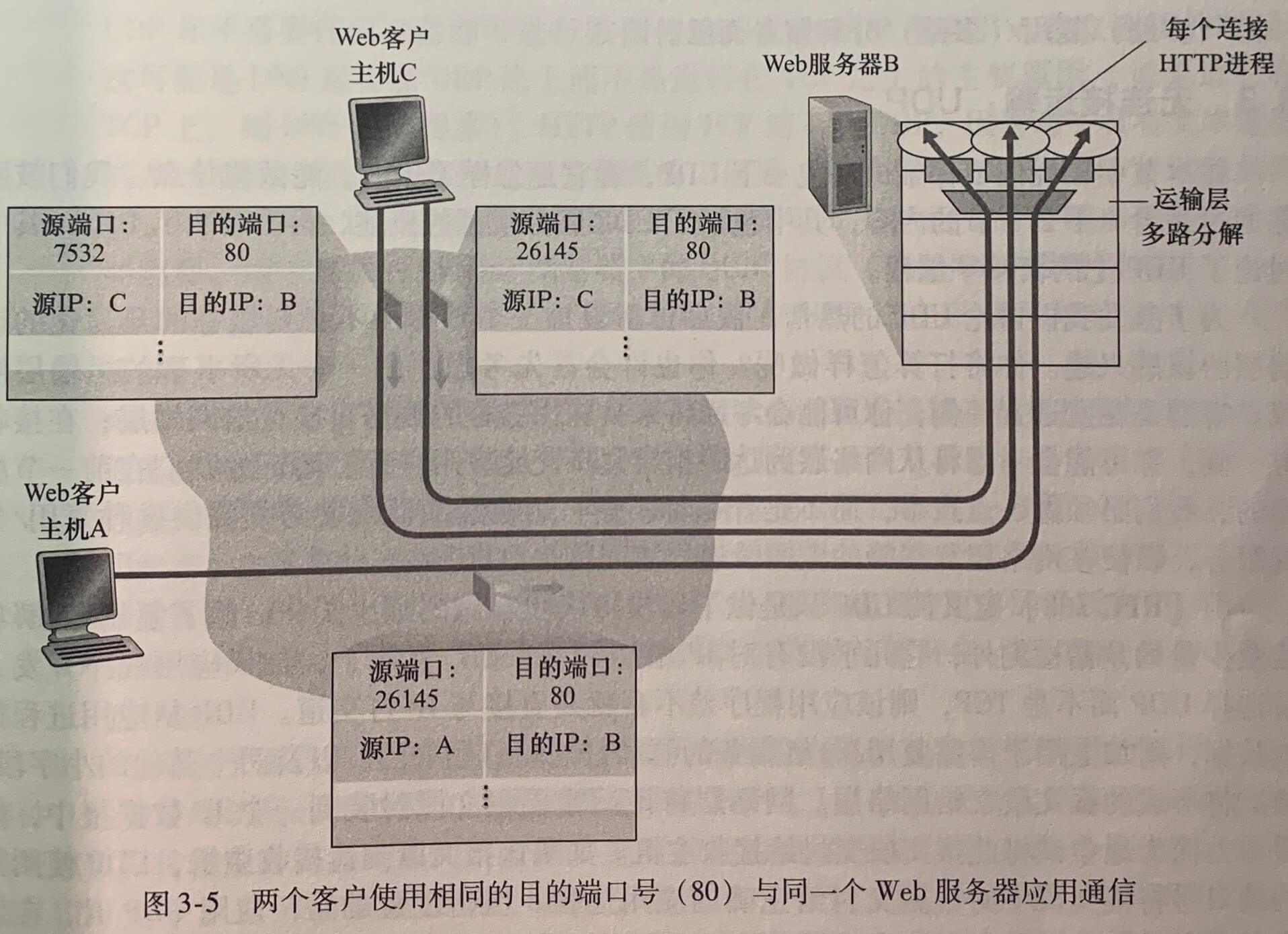
如上图,端口号是一个16比特的数,其大小在065535之间。01023范围的端口号称为周知端口号(well-known port number),是受限制的,它们用来保留给诸如 HTTP 和 FTP(21端口号)之类的周知应用层协议。当我们开发一个新的应用程序时,必须为其分配一个端口号。
TCP 的多路复用与多路分解比较复杂。
1.无连接的多路复用与多路分解
UDP 的套接字由一个二元组(包含一个目的IP地址和一个目的端口号)来标识。如果两个 UDP 报文段有不同的源 IP 地址和/或源端口号,但具有相同的目的 IP 地址和目的端口号,那么这两个报文段将通过相同的目的套接字被定向到相同的目的进程。
clientSocket = socket(AF_INET, SOCK_DGRAM)
- 1
当用这种方式创建 UDP 套接字时,运输层会自动为该套接字分配一个 1024 ~ 65535 之间的一个端口号,该端口号是当前未被主机其他 UDP 端口使用的号。当然也可以手动绑定端口号,如下。
clientSocket.bind(('', 19157))
- 1
如果开发的应用程序所编写的代码实现是一个“周知协议”的服务器端,那就必须为其分配一个相应的周知端口号。通常情况下,应用程序的客户端让运输层自动地分配端口号,而服务器端则分配一个特定的端口号。
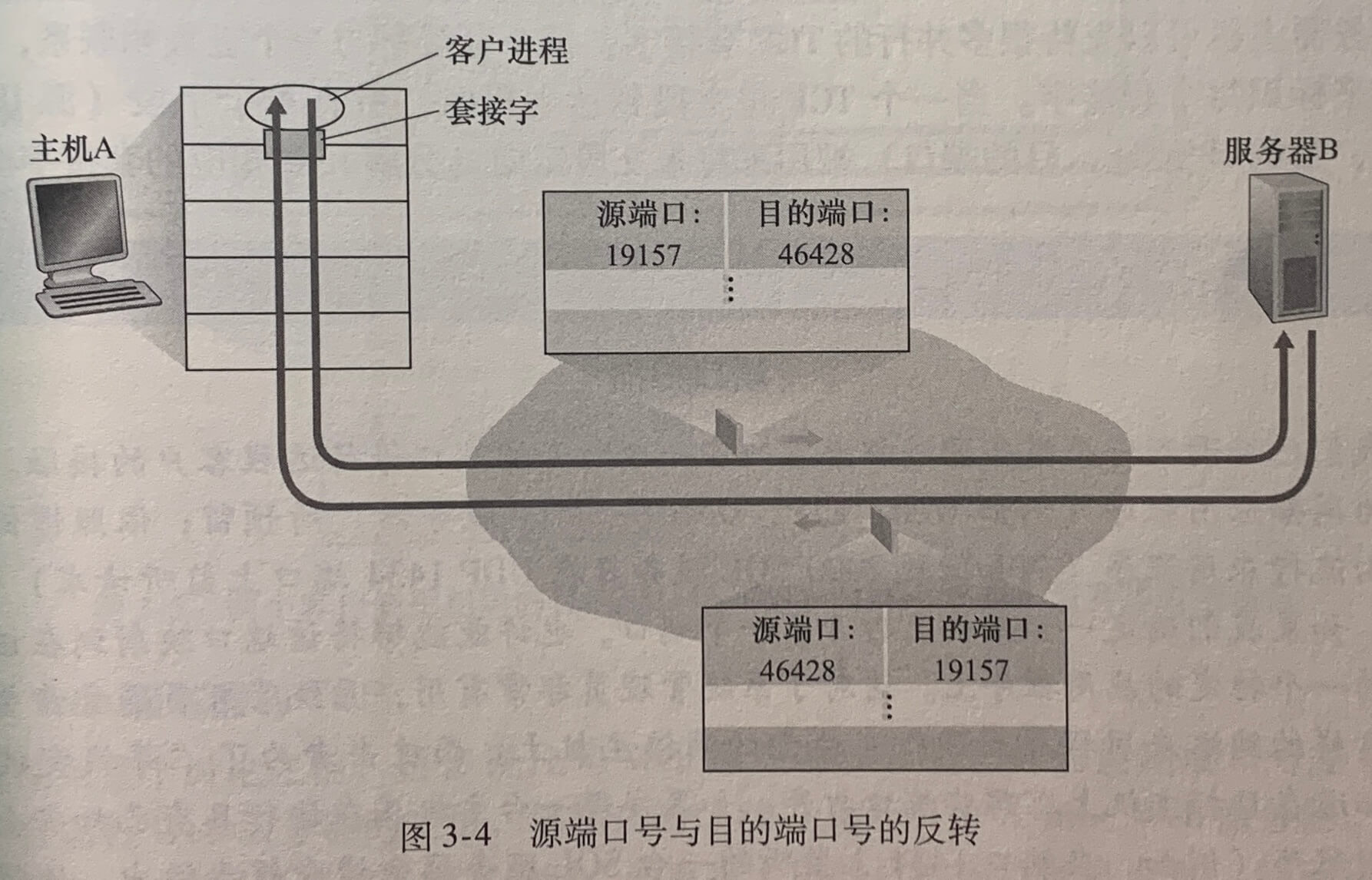
源端口号的目的是用作“返回地址”的一部分来使用。
2.面向连接的多路复用与多路分解
TCP 的套接字由一个四元组(源 IP 地址,源端口号,目的 IP 地址,目的端口号)来标识。与 UDP 不同的是,两个具有不同源 IP 地址或源端口号的到达 TCP 报文段将被定向到两个不同的套接字(无论它们目的 IP 地址或目的端口号是否一样),除非 TCP 报文段携带了初始创建连接的请求(即源 IP 地址、源端口号、目的 IP 地址、目的端口号一致)。
服务器主机可以支持很多并行的 TCP 套接字,每个套接字与一个进程相联系,并由其四元组来标识每个套接字。当一个 TCP 报文段到达主机时,所有4个字段被用来将报文段定向到相应的套接字。
nmap软件可用于扫描主机端口服务属于开启状态。
3.Web服务器与TCP
当今的高性能 Web 服务器通常只使用一个进程,但是会为每个新的客户连接创建一个具有新连接套接字的新线程。
如果客户与服务器使用持续 HTTP,则在整条连接持续期间,客户与服务器之间经由同一个服务器套接字交换 HTTP 报文。然而,如果客户与服务器使用非持续 HTTP,则每一对请求/响应都创建一个新的 TCP 连接并在随后关闭。
3.3 无连接运输:UDP
UDP 只做了运输协议能做的最少工作。除了复用/分解功能以及少量的差错检测外,它几乎没有对 IP 增加别的东西。
DNS 是一个通常使用 UDP 的应用层协议的例子。
有许多应用更适合用 UDP,原因主要以下几点:
- 关于发送什么数据以及何时发送的应用层控制更为精细。
- 无须连接建立。谷歌的 Chrome 浏览器中的 QUIC 协议(快速 UDP 因特网连接)将 UDP 作为其支撑运输协议并在 UDP 之上的应用层协议中实现可靠性。
- 无连接状态。TCP 需要在端系统中维护连接状态,此连接状态包括接收和发送缓存、拥塞控制参数以及序号与确认号的参数。而 UDP 不维护连接状态。
- 分组首部开销小。每个 TCP 报文段都有 20 字节的首部开销,而 UDP 仅有 8 字节。
3.3.1 UDP报文段结构
UDP 首部只有 4 个字段,每个字段两个字段组成。长度字段指示了 UDP 报文段中的字节数(首部加数据)。接收方使用检验和来检查在该报文段中是否出现了差错。


3.3.2 UDP检验和
UDP 检验和提供了差错检验功能。检验和用于确定当 UDP 报文段从源到达目的地移动时,其中的比特是否发生了改变。
许多链路层协议也提供了差错检测,对于 UDP 为什么提供检验和,是因为不能保证源和目的之间的所有链路都提供差错检测。
尽管 UDP 提供差错检测,但它对差错恢复无能为力。
3.4 可靠数据传输原理
可靠数据传输的实现问题不仅在运输层出现,也会在链路层以及应用层出现。

借助可靠信道,传输数据比特不会受到损坏(由0变为1,或者相反)或丢失,而且所有数据都是按照其发送顺序进行交付。实现这种服务是利用可靠数据传输协议(reliable data transfer protocol)。TCP 是在不可靠的(IP)端到端网络层之上实现的可靠数据传输协议。
3.4.1 构造可靠数据传输协议
1.经完全可靠信道的可靠数据传输:rdt1.0
考虑最简单的情况,即底层信道是完全可靠的,我们称该协议为rdt1.0,

**有限状态机(Finite-State Machine,FSM)**定义了发送方或接收方的操作。rdt 的发送端通过 rdt_send(data) 事件接受来自较高层的数据,产生一个包含该数据的分组(经由 make_pkt(data) 动作),并将分组发送到信道中。在接受端,rdt 通过 rdt_rcv(packet) 事件从底层信道接收一个分组,从分组中取出数据(经由 extract(packet, data) 动作),并将数据上传给较高层(通过 deliver_data(data) 动作)。
2.经具有比特差错信道的可靠数据传输:rdt2.0
底层信道更为实际的模型是分组中的比特可能受损的模型。
当接收方接收到损失的分组时,会通知发送方该分组缺失并让其重传。基于这样重传机制的可靠数据传输协议称为**自动重传请求(Automatic Repeat Request,ARQ)**协议。
ARQ 协议中还需要另外三种协议功能来处理存在比特差错的情况:
- 差错检测。这些技术要求有额外的比特从发送方发送到接收方,这些比特将被汇集在 rdt2.0 数据分组的分组检验和字段中。
- 接收方反馈。接收方提供明确的反馈信息给发送。在口述报文情况下回答“肯定确认”(ACK)和“否定确认”(NAK)就是这种反馈的例子。理论上,这些分组只需要一个比特长;如用0表示 NAK,用1表示 ACK。
- 重传。
当发送方调用 udt_send 发送分组之后,它将等待接收方的 ACK 或 NAK,在这期间,发送方的 rdt_send() 事件不可能出现,只有当接收到 ACK 并离开该状态时才能发生这样的事件。rdt2.0 这样的协议被称为**停等(stop-and-wait)**协议。
rdt2.0 协议存在一个致命的缺陷,就是没有考虑到 ACK 或 NAK 分组受损的可能性。
解决这个问题的方法是在数据分组中添加一新字段,让发送方对其数据分组编号,即将发送数据分组的**序号(sequence number)**放在该字段。接收方只需要检查序号即可确定收到的分组是否是一次重传。
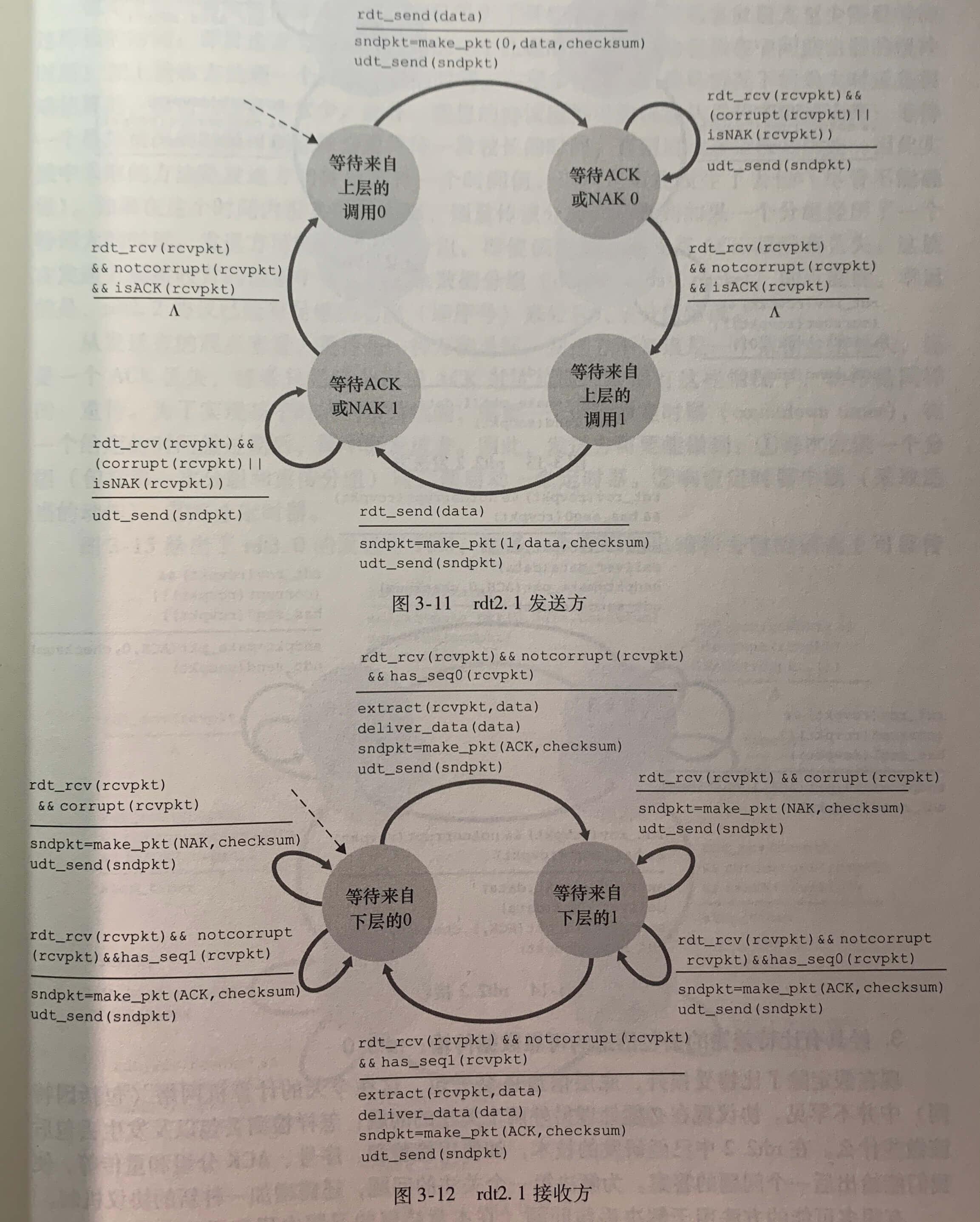
上图是 rdt2.0 的修订版,即 rdt2.1 。 rdt2.1 的发送方和接收方 FSM 的状态树都是以前的两倍。
rdt2.2 是在有比特差错信道上实现一个无 NAK 的可靠数据传输协议。

3.经具有比特差错的丢包信道的可靠数据传输:rdt3.0
现在假定除了比特受损外,底层信道还会丢包。这里探讨的是如何检测丢包以及发生丢包后该做些什么。
发送方负责检测和恢复丢包工作。当发送方长时间未收到 ACK 时,发送方将重传该分组。每当发送方发送分组时,便启动一个定时器,当定时器触发时,便进行重传,如果定时器时间内收到 ACK,则终止定时器。
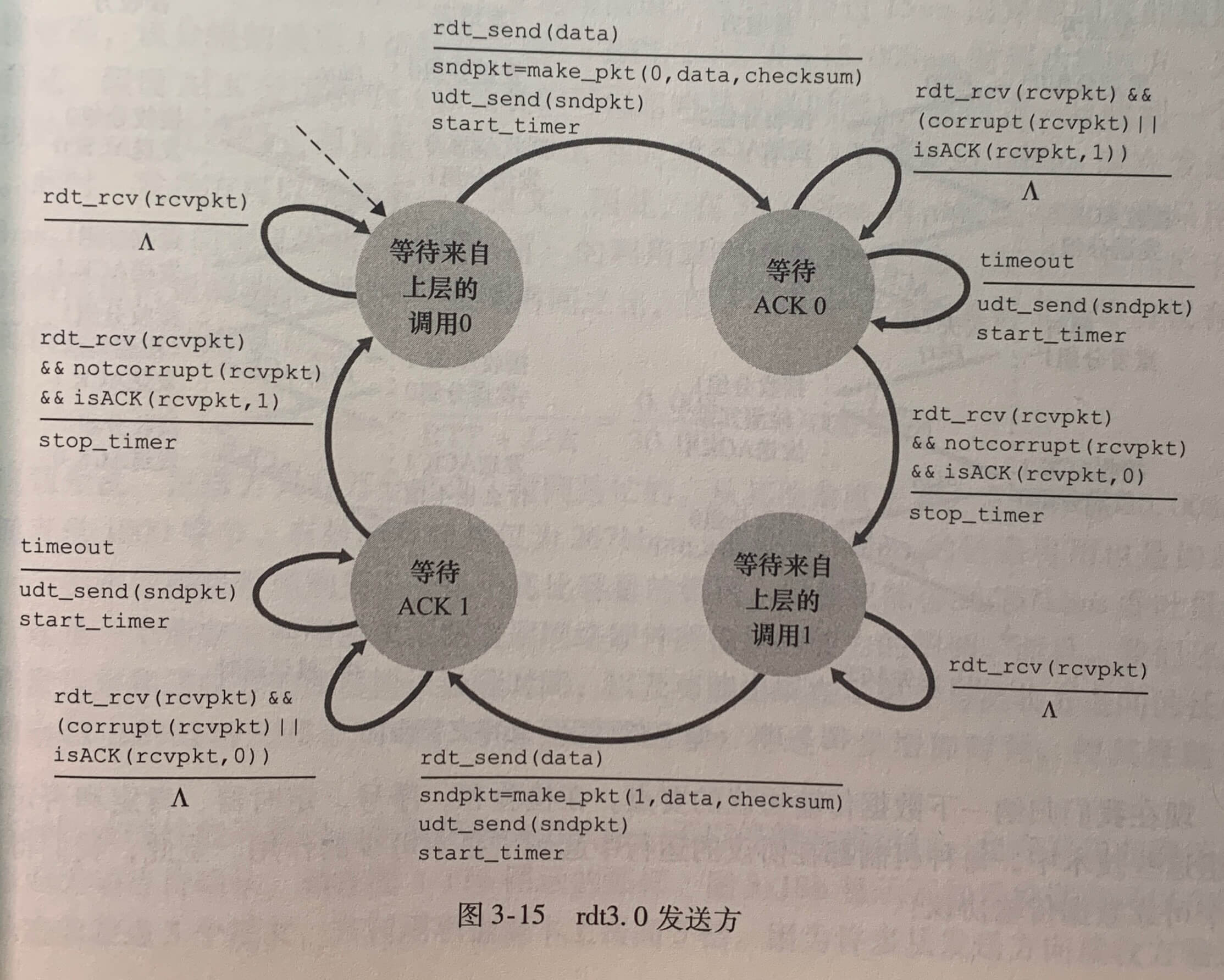
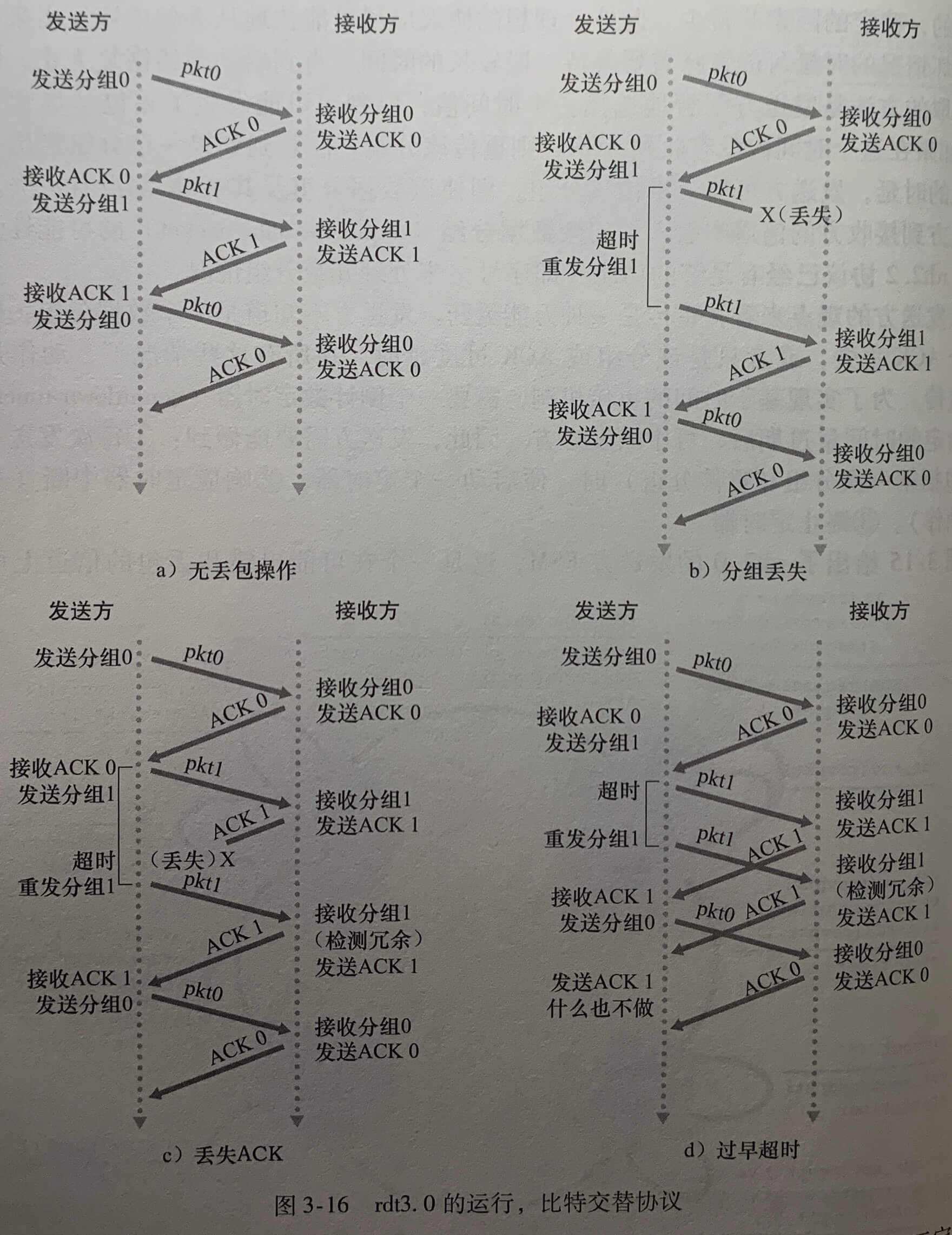
数据传输协议 TCP 的要点,可靠数据传输协议需要具备检验和、序号、定时器和否定确认分组这些技术。
3.4.2 流水线可靠数据传输协议
rdt3.0 是一个功能正确的协议,但 rat3.0 存在着性能问题,因为它是一个停等协议。

解决这个问题的方法是:允许发送方发送多个分组而无须等待确认。
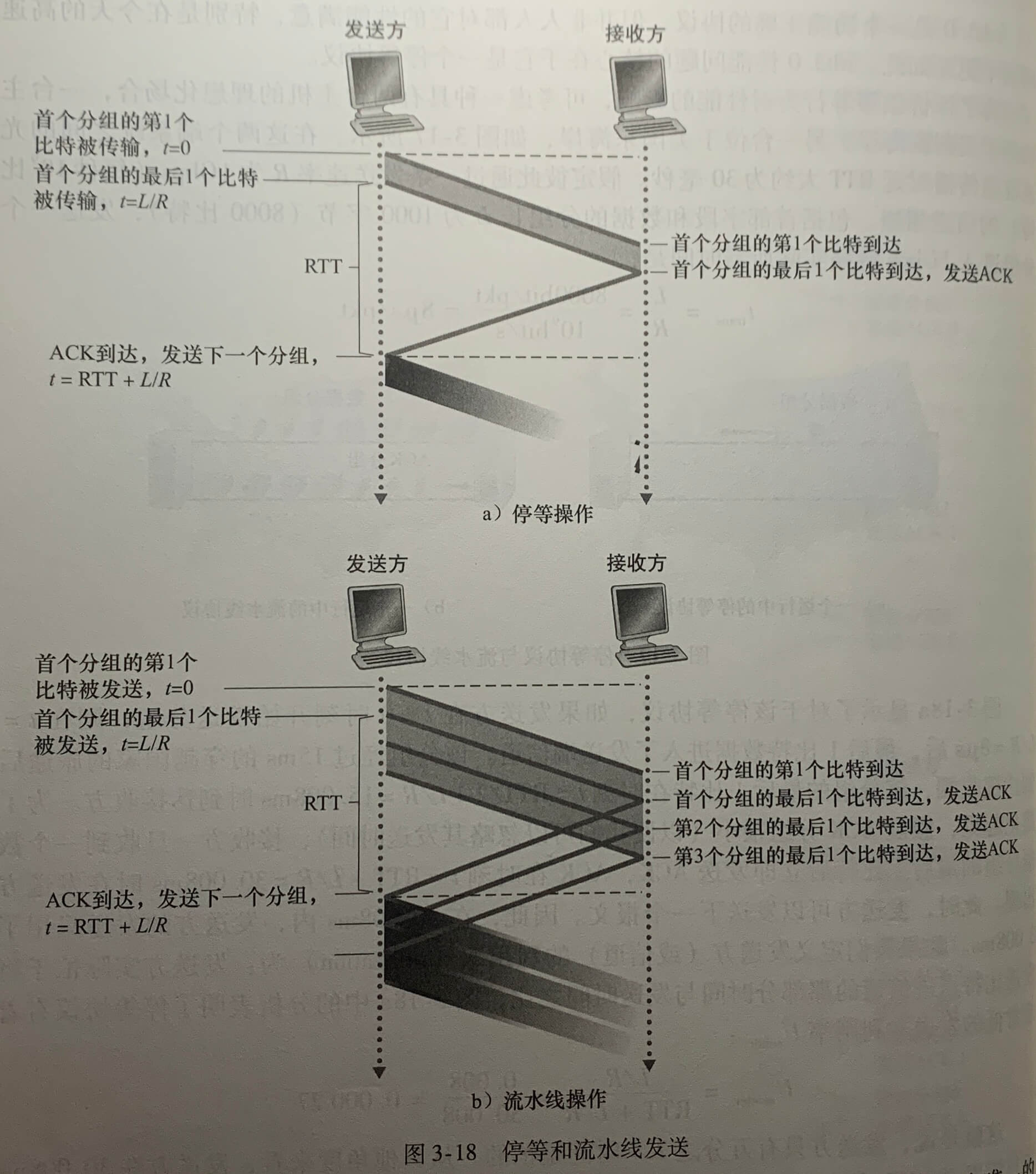
**流水线(pipelining)**技术对可靠数据传输协议带来如下影响:
- 必须增加序号范围。因为每个输送中的分组必须有一个唯一的序号。
- 协议的发送方和接收方两端也不得不缓存多个分组。
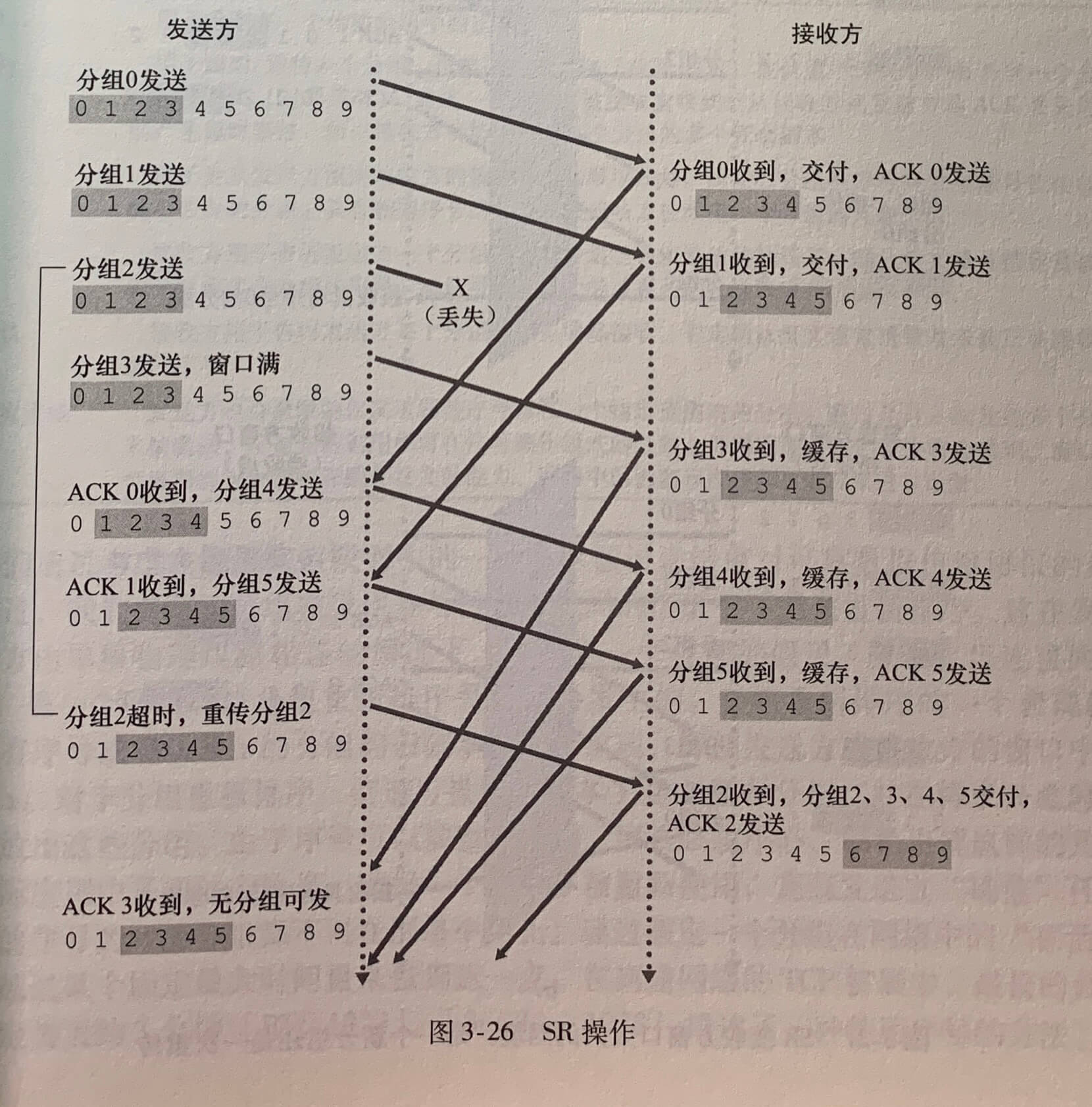
- 所需序号范围和对缓存的要求取决于数据传输协议如何处理丢失、损坏及延时过大的分组。解决流水线的差错恢复有两种基本方法:回退N步(Go-Back-N)和选择重传(Selective Repeat,SR)。
3.4.3 回退N步
在回退 N 步协议中,允许发送方发送多个分组(当有多个分组可用时)而不需等待确认,但它也受限于在流水线中未确认的分组数不能超过某个最大允许数 N。N 常被称为窗口长度(window size),GBN 协议被称为滑动窗口协议(sliding-window protocol)。


GBN 发送方必须响应三种类型的事件:
- 上层的调用。当上层调用 rdt_send() 时,发送方先检查发送窗口 N 是否已满。如果窗口未满则产生一个分组将其发送并更新变量。如果窗口已满,发送方通知上层该窗口已满,然后上层过一会儿再试。
- 收到一个 ACK。在 GBN 协议中,对序号为 n 的分组的确认采取**累积确认(cumulative acknowledgment)**的方式,表明接收方已正确接收到序号为 n 的以前且包括 n 在内的所有分组。
- 超时确认。如果出现超时,发送方重传所有已发送但还未被确认过的分组。发送方仅使用一个定时器,它可被当作是最早的已发送但未被确认的分组所使用的定时器。如果收到一个 ACK,但仍有已发送但未确认的分组,则定时器被重新启动,如果没有已发送但未被确认的分组,则停止该定时器。
GBN 接收方会丢弃所有失序分组。这种方法的优点是接收缓存简单,即接收方不需要缓存任何失序分组。接收方需要维护的唯一信息就是下一个按序接收的分组的序号。
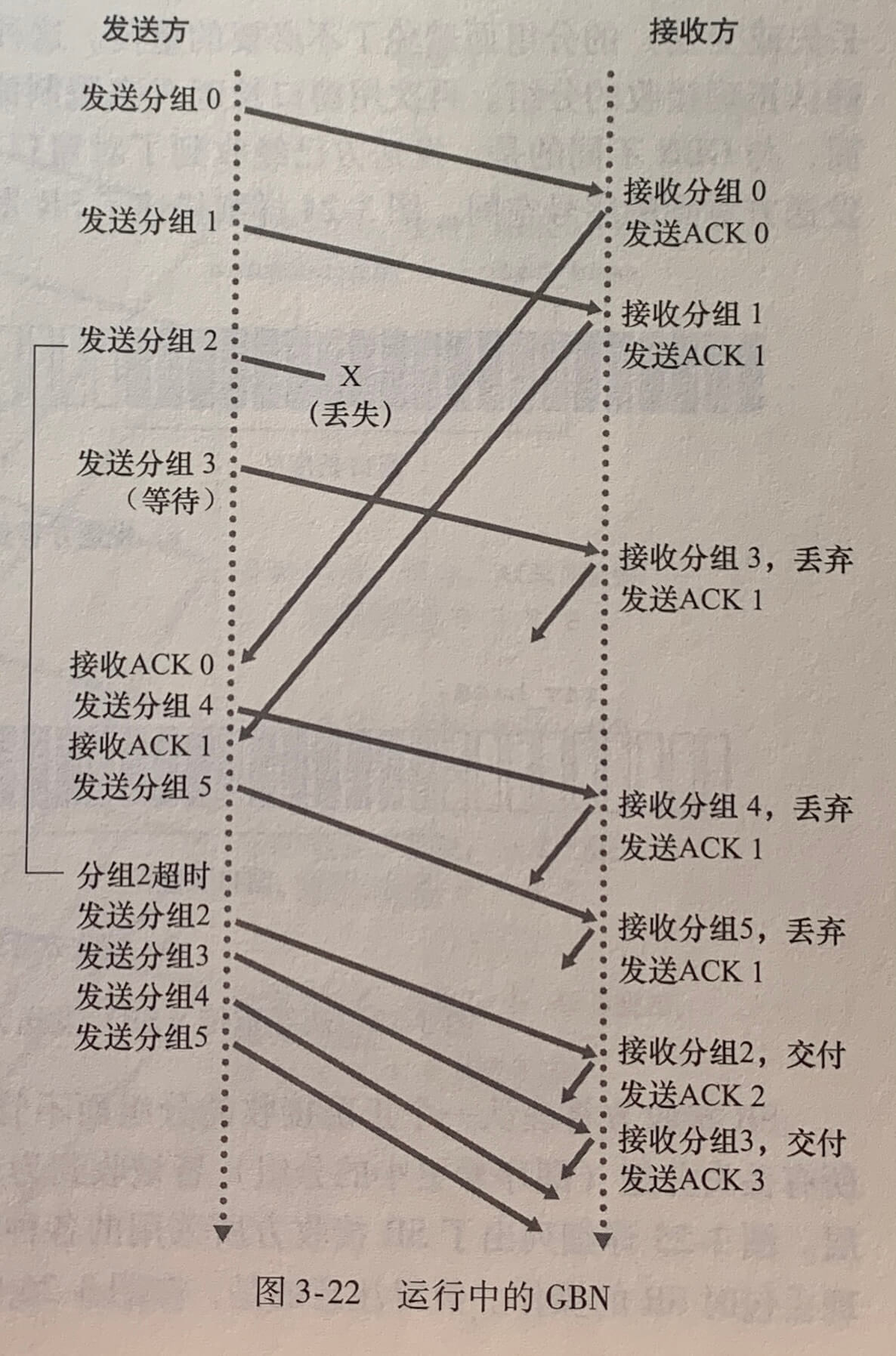
3.4.4 选择重传
GBN 的缺点是当窗口长度和带宽时延很大时,单个分组的差错会引起重传大量分组,而许多分组根本没有必要重传。
重传(SR)协议通过让发送方仅重传那些它怀疑在接收方出错(丢失或受损)的分组而避免不必要的重传。个别的、按需的重传要求接收方逐个地确认正确接收的分组。
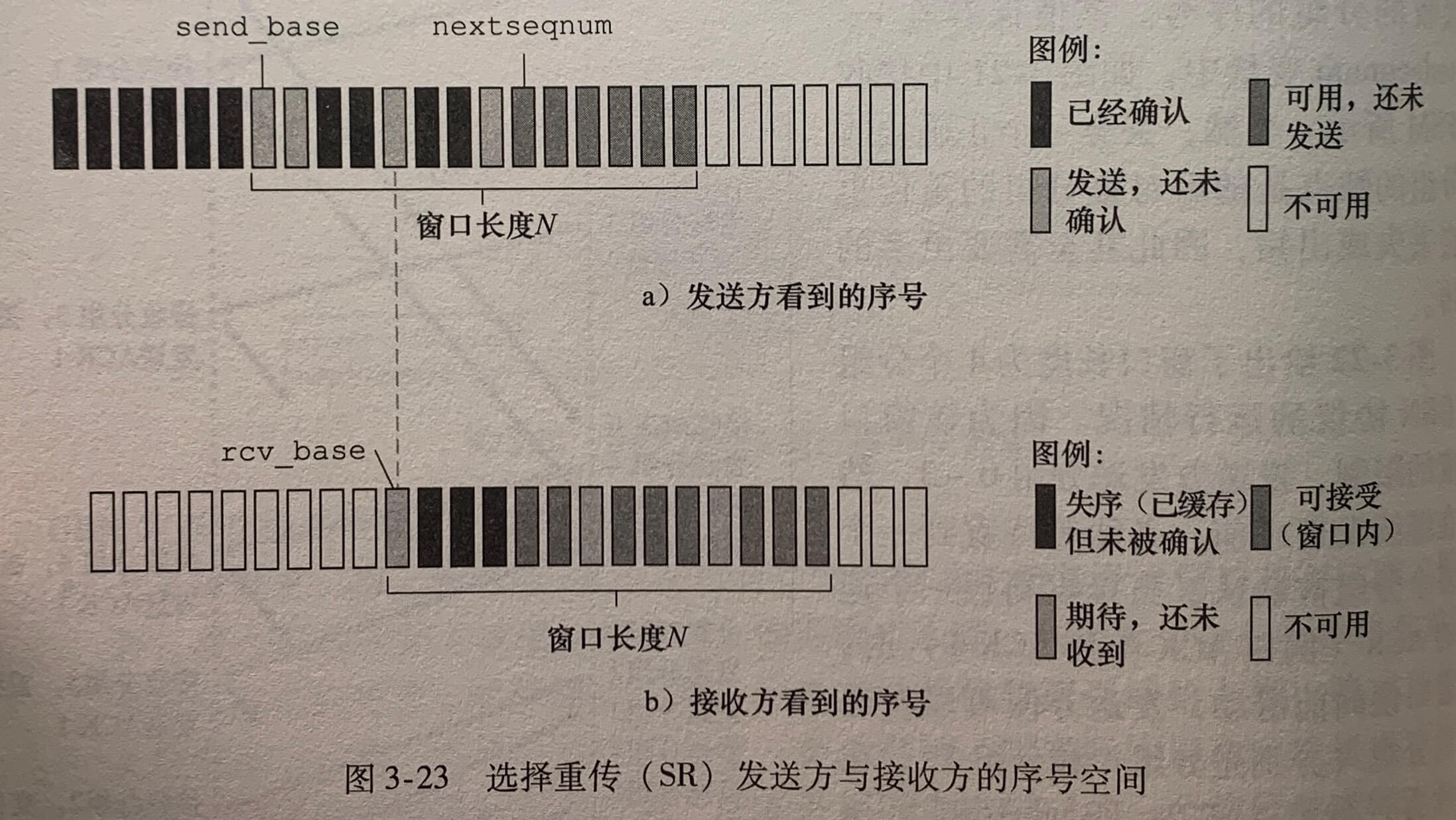
SR 接收方将确认一个正确接收的分组而不管其是否按序。失序的分组将被缓存直到所有丢失分组(即序号更小的分组)皆被收到为止,这时才将一批分组交付给上层。


3.5 面向连接的运输:TCP
TCP 是因特网运输层的面向连接的可靠的运输协议。
3.5.1 TCP连接
在一个应用程序进程可以开始向另一个应用进程发送数据之前,这两个进程必须先相互“握手”,它们必须相互发送某些预备报文端,以建立确保数据传输的参数。连接的双方将初始化与 TCP 连接相关的许多 TCP 状态变量。
TCP/IP 协议在一开始是一个整体,后来才将它分成单独运行的两个部分:TCP 和 IP。
TCP 连接是一条逻辑连接,其共同状态仅保留在两个通信端系统的 TCP 程序中。事实上,中间路由器对 TCP 连接完全视而不见,它们看到的是数据报,而不是连接。
TCP 连接提供的是全双工服务(fulll-duplex service)。一旦建立起一条 TCP 连接,两个应用进程之间就可以相互发送数据了。
应用层数据一旦通过套接字传递数据流,它就由运行的 TCP 控制了。TCP 将这些数据引导到该连接的**发送缓存(send buffer)**里,发送缓存是发起三次握手期间设置的缓存之一。接下来 TCP 就会不时从发送缓存里取出一块数据,并将数据传递到网络层。
TCP 可从缓存中取出并放入报文段中的数据数量受限于最大报文段长度(Maximum Segment Size,MSS)。MSS 通过根据最初确定的由本地发送主机发送的最大链路层帧长度(最大传输单元(Maximum Transmission Unit,MTU))来设置。
TCP 为每块客户数据配上一个 TCP 首部,从而形成多个 TCP报文段(TCP segment)。这些报文段被下传给网络层,网络层将其分别封装在网络层 IP 数据报中,然后这些 IP 数据报被发送到网络中。当 TCP 的另一端接收到一个报文段后,该报文段的数据就被放入该 TCP 连接的接收缓存中。应用从此缓存中读取数据流。该连接的每一端都有各自的发送缓存和接收缓存。

TCP 连接的组成包括:一台主机上的缓存、变量和与进程连接的套接字,以及另一台主机上的另一组缓存、变量和进程连接的套接字。在两台主机之间的网络元素(路由器、交换机和中继器)中,没有为该连接分配任何缓存和变量。
3.5.2 TCP报文段结构

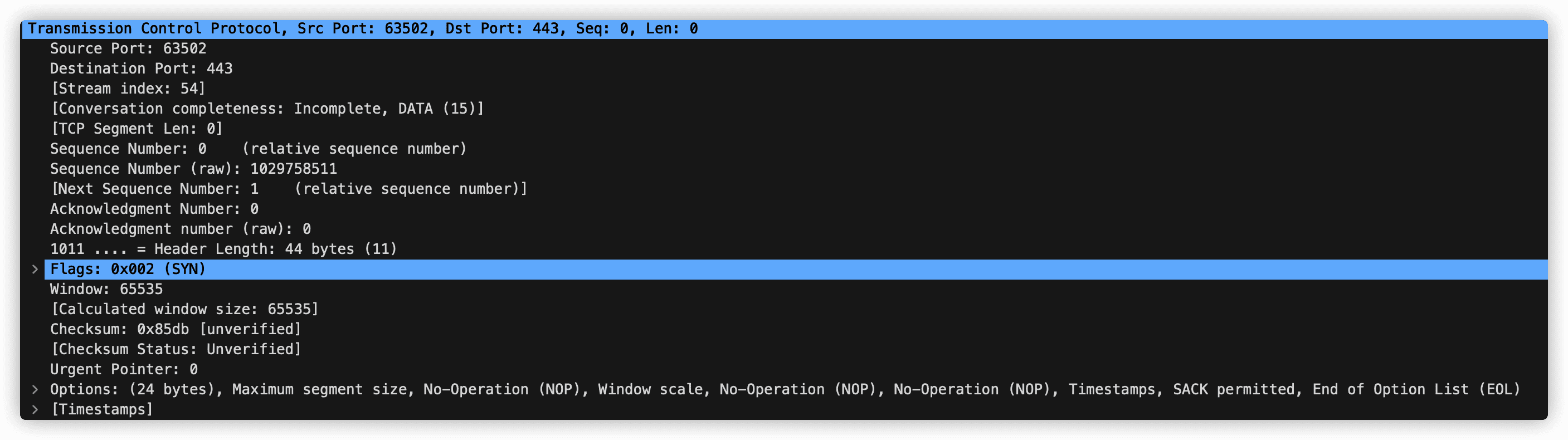
TCP 报文段和 UDP 同样包含源端口号、目的端口号和检验和字段。同时 TCP 报文段首部还包含下列字段:
- 32比特的序号字段(sequence number field)和32比特的确认号字段(acknowledgment number field)。这些字段被 TCP 发送方和接收方用来实现可靠数据传输服务。
- 16比特的接受窗口字段(receive window field),该字段用于流量控制。
- 4比特的首部长度字段(header length field),该字段指示以32比特的字为单位的 TCP 首部长度。TCP 首部的长度是可变的。TCP 首部的典型长度是20字节。
- 可选与变长的选项字段(options field),该字段用于发送方与接收方协商最大报文端长度(MSS)时,或在高速网络环境下用作窗口调节因子时使用。
- 6比特的标志字段(flag field)。ACK比特用于指示确认字段中的值是有效的,即该报文段包括一个对已被成功接收报文段的确认。RST、SYN和FIN比特用于连接建立和拆除,PSH比特指示接收方是否应立即将数据交给上层,URG比特用来指示报文段里存在着被发送端的上层实体置为“紧急”的数据。紧急数据的最后一个字节由16比特的**紧急数据指针字段(urgent data oiunter field)**指出。当紧急数据存在并给出指向紧急数据尾指针的时候,TCP 必须通知接收端的上层实体。
-
序号和确认号
TCP 把数据看成一个无结构的、有序的字节流。序号是建立在传送的字节流之上,而不是建立在传送的报文段的序列之上。**一个报文段的序号(sequence number for a segment)**因此是该报文段首字节的字节流编号。
假设数据流由一个包含 500000 字节的文件组成,其 MSS 为 1000 字节,则 TCP 将该数据流构建 500 个报文段。给第一个报文段分配序号 0,第二个报文段分配序号 1000, 第三个报文段分配序号 2000,以此类推。每一个序号被填入到相应的 TCP 报文段首部的序号段中。
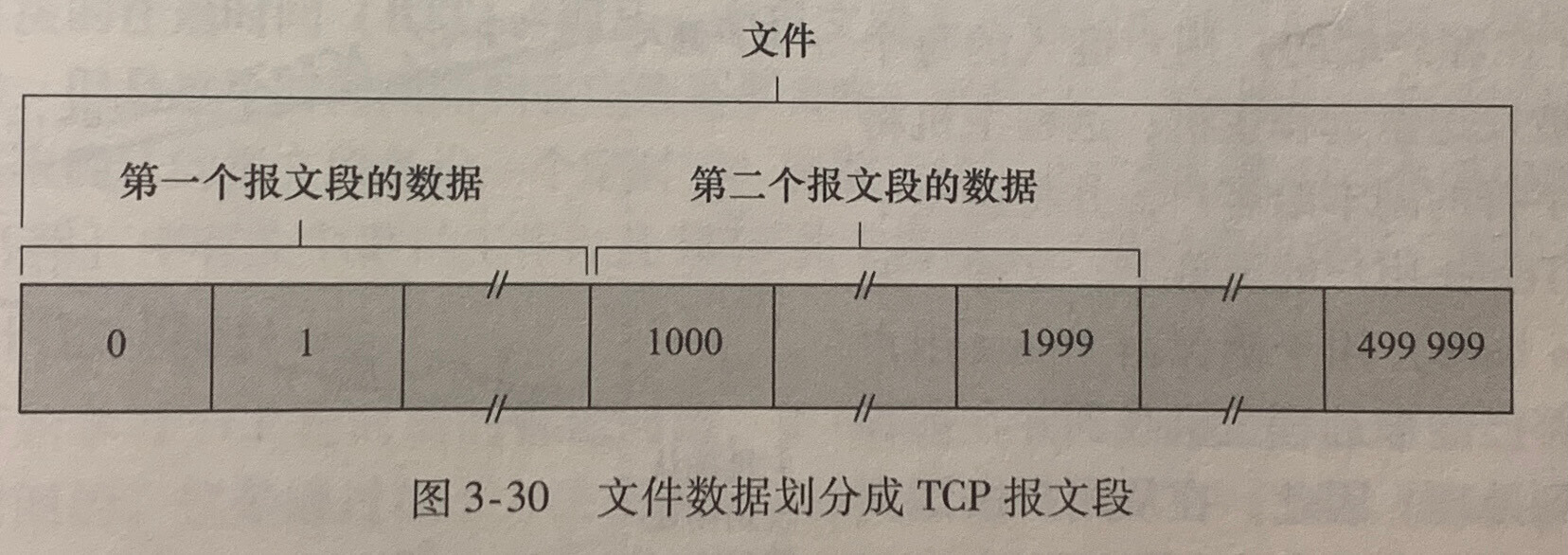
主机A填充进报文段的确认号(ack)是主机A期望从主机B收到的下一字节的序号。
TCP 提供累计确认(cumulative acknowledgment),即主机A没有收到主机B 536899的报文段,而却收到了0535 和 900~1000的报文段,那么主机A会在下一个报文段将在确认号字段包含536。
一条 TCP 连接的双方均可随机地选择初始序号。这样做可以减少将那些仍在网络中存在的来自两台主机之间先前已终止的连接的报文段,误认为是后来这两台主机之间新建连接所产生的有效报文段的可能性(它碰巧与旧连接使用了相同的端口号)。
-
Telnet:序号和确认号的一个学习案例
Telnet 是一个用于远程登录的流行应用层协议,它运行在 TCP 之上,被设计成可在任意一对主机之间工作。现在许多用户更愿意采用 SSH 协议而不是 Telnet,因为 Telnet 连接中发送的数据是没有加密的。
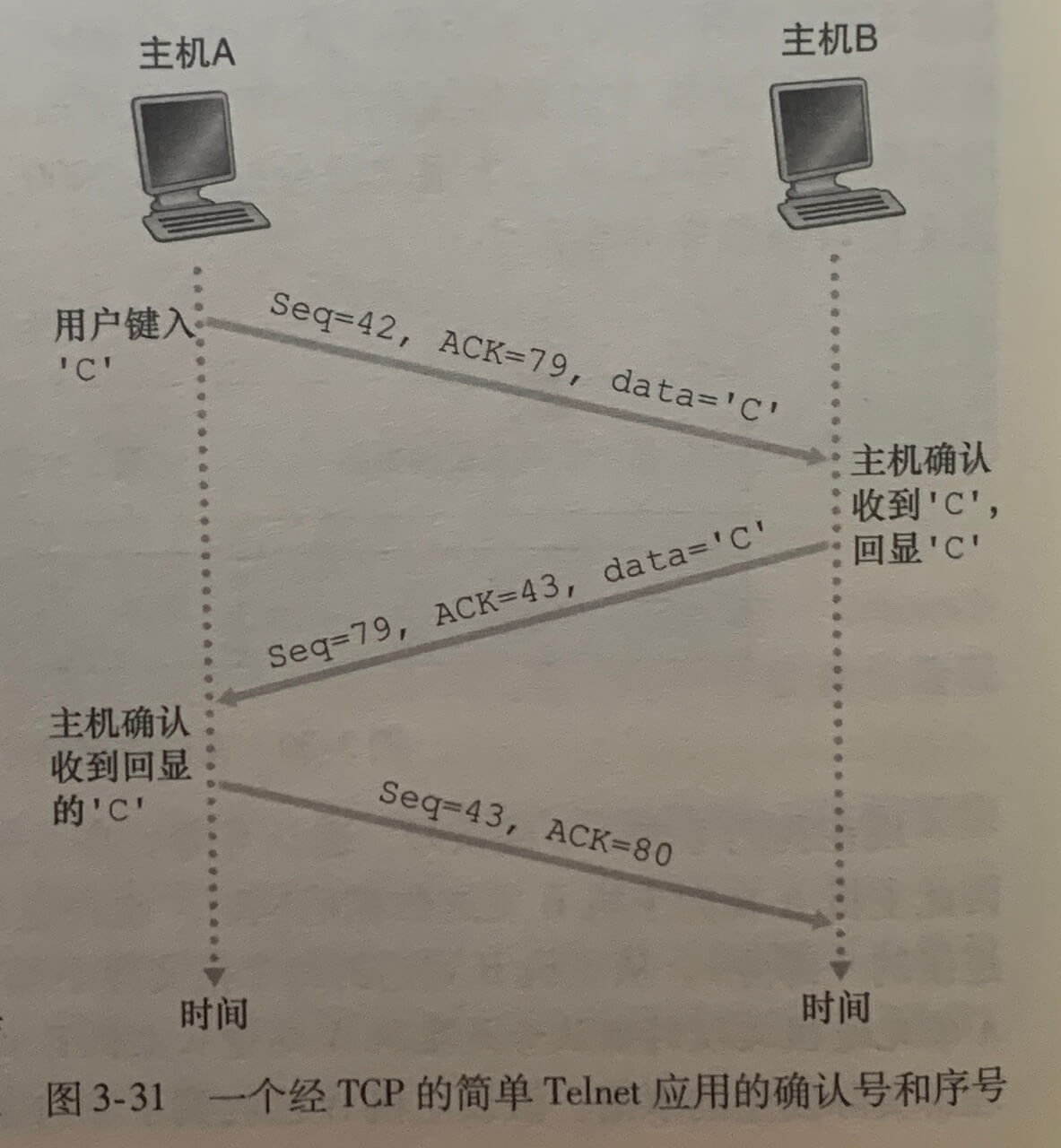
假设客户和服务器的起始序号是42和79。一个报文段的序号(seq)就是该报文段数据首字节的序号。确认号(ack)就是主机正在等待的数据的下一个字节序号。
3.5.3 往返时间的估计与超时
TCP 采用超时/重传机制来处理报文段的丢失问题。超时间隔必须大于该连接的往返时间(RTT),即从一个报文段发出到它被确认的时间。
1.估计往返时间
报文段的样本 RTT(表示为 SampleRTT )就是从某报文段被发送(即交给 IP)到对该报文段的确认被收到之间的时间量。大多是 TCP 的实现仅在某个时刻做一次 SampleRTT 测量,而不是为每个发送的报文段测量一个 SampleRTT。TCP 不会为已被重传的报文段计算 SampleRTT,它仅为传输一次的报文段测量 SampleRTT。
由于每个 SampleRTT 值会随之波动,为了估量一个典型的 RTT,TCP维持一个 SampleRTT 的均值(称为 EstimatedRTT)。
DevRTT 计算了 RTT 的偏差,即 SampleRTT 偏离 EstimatedRTT 的程度。
2.设置和管理重传超时间隔
TCP 超时间隔必须大于 EstimatedRTT,但不能大太多,不然 TCP 不能很快地重传该报文段。
计算超时间隔公式为: T i m e o u t I n t e r v a l = E s t i m a t e d R T T + 4 ∗ D e v R T T TimeoutInterval=EstimatedRTT+4 * DevRTT TimeoutInterval=EstimatedRTT+4∗DevRTT。
推荐的 TimeoutInterval 初始值为1秒。

3.5.4 可靠数据传输
因特网的网络层服务(IP 服务)是不可靠的。IP 不保证数据报的交付,不保证数据报的按序交付,也不保证数据报中数据的完整性。
TCP 在 IP 不可靠的尽力而为服务之上创建一种可靠数据传输服务。TCP 使用单一的重传定时器管理多个已发送但还未被确认的报文段。

1.一些有趣的情况


上图3-36 由于累计确认,避免了第一个报文段的重传。
2.超时间隔加倍
每当超时时间发生时,TCP 重传具有最小序号的还未被确认的报文段。每次 TCP 重传时都会将下一次的超时间隔设置为先前值的两倍,而不是用从 EstimatedRTT 和 DevR 推算出的值。超时间隔在每次重传后会呈指数型增长。然而,每当定时器在另两个事件(即收到上层应用的数据和收到 ACK)中任意一个启动时,TimeoutInterval 由 最近的 EstimatedRTT 与 DevRTT 值推算得到。
3.快速重传
超时触发重传存在的问题之一是超时周期可能相对较长。幸运的是,发送方通常可在超时时间发生之前通过注意所谓冗余 ACK 来较好地检测到丢包情况。**冗余ACK(duplicate ACK)**就是再次确认某个报文段的 ACK,而发送方先前已经收到对该报文段的确认。
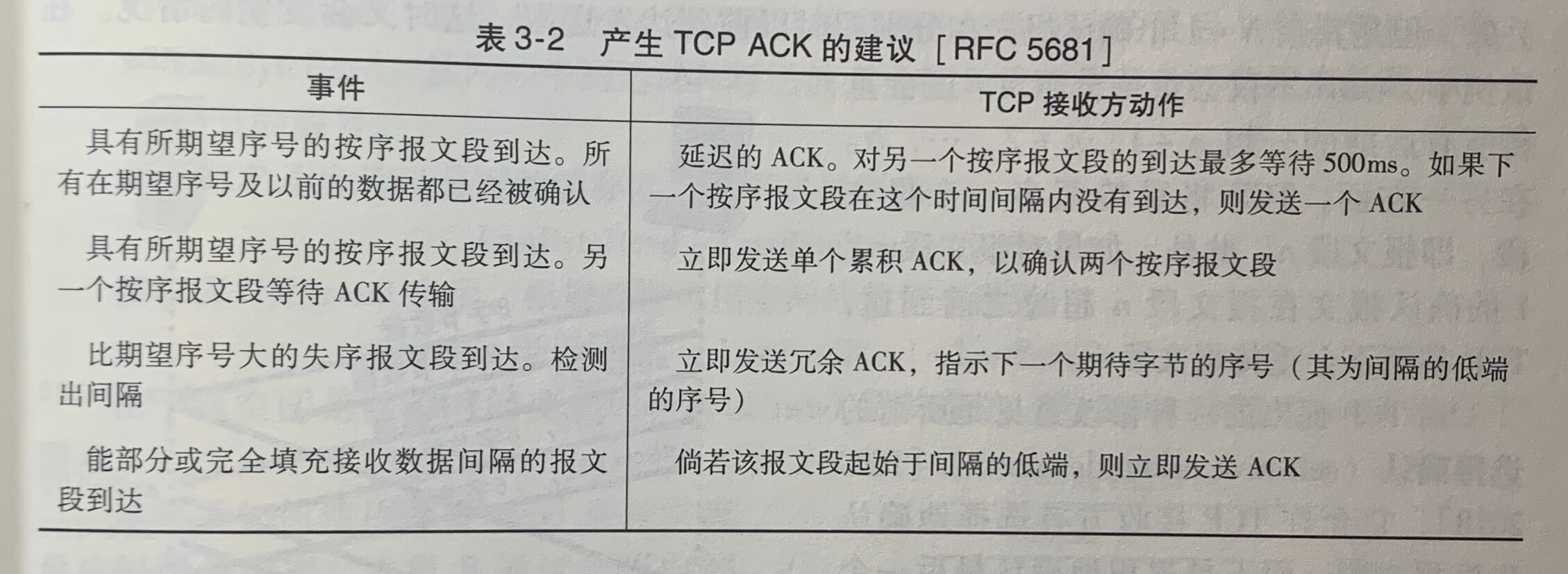
一旦发送方收到相同数据的3个冗余 ACK,TCP就执行快速重传(fast retransmit),即在该报文段的定时器过期之前重传丢失的报文段。

4.是回退N步还是选择重传
TCP 发送方仅需维持已发送过但未被确认的字节的最小序号(SendBase)和下一个要发送的字节的序号(NextSeqNum)。TCP 看起来更像一个 GBN 风格的协议,但 TCP 和 GBN之间有些显著的区别,许多 TCP 实现会将正确接收但失序的报文段缓存起来。
TCP 的差错恢复机制也许最好被分类为 GBN 协议与 SR 协议的混合体。
3.5.5 流量控制
当该 TCP 连接收到正确、按需的字节后,它就将数据放入接收缓存。相关联的应用进程会从该缓存中读取数据,但不必是数据刚一到达就立即读取。事实上,接收方应用也许正忙于其他任务,甚至要过很长时间后才去读取该数据。如果某应用程序读取数据时相对缓慢,而发送方发送得太多、太快,发送的数据就会很容易地使该连接的接收缓存溢出。
TCP 为它的应用程序提供了**流量控制服务(flow-control service)**以消除发送方使接收方缓存溢出的可能性。流量控制因此是一个速度匹配服务,即发送方的发送速率与接收方应用程序的读取速率相匹配。
TCP 发送方也可能因为 IP 网络的拥塞而被遏制,这种形式的发送方的控制被称为拥塞控制(congestion control)。即使流量控制和拥塞控制采取的动作非常相似(对发送方遏制),但是它们显然是针对完全不同的原因而采取的措施。
TCP 通过让发送方维持一个称为**接收窗口(receive window)**的变量来提供流量控制。接收窗口用于给发送方一个指示——该接收方还有多少可用的缓存空间。因为 TCP 是全双工通信,在连接两端的发送方都各自维护一个接收窗口。

假设主机A向主机B发送一个大文件。主机B通过把当前的 rwnd(接收窗口) 值放入它发给主机A的报文段接收窗口字段中,通知主机A它在该连接的缓存中还有多少可用空间。主机A轮流跟踪 LastByteSent 和 LastByteAcked 两个变量,这两个变量的差就是主机A发送到连接中但未被确认的数据量,将未确认的数据量控制在值 rwnd 内就可以保证主机A不会使主机B的接收缓存溢出,因此,主机A在该连接的整个生命周期必须保证 L a s t B y t e S e n t − L a s t B y t e A c k e d ≤ r w n d LastByteSent-LastByteAcked\le rwnd LastByteSent−LastByteAcked≤rwnd。
当主机B的接收窗口为0时,主机A继续发送只有一个字节数据的报文段,这些报文段将会被接收方确认,最终缓存将开始清空。
相比 TCP,UDP 不提供流量控制,报文段由于缓存溢出可能在接收方丢失。
3.5.6 TCP连接管理
TCP 连接的建立会显著增加人们感受到的时延。
当一台主机(客户)上的进程向与另一台主机(服务器)上的一个进程建立一条连接,客户中的 TCP 会用以下方式与服务器中的 TCP 建立一条 TCP 连接:
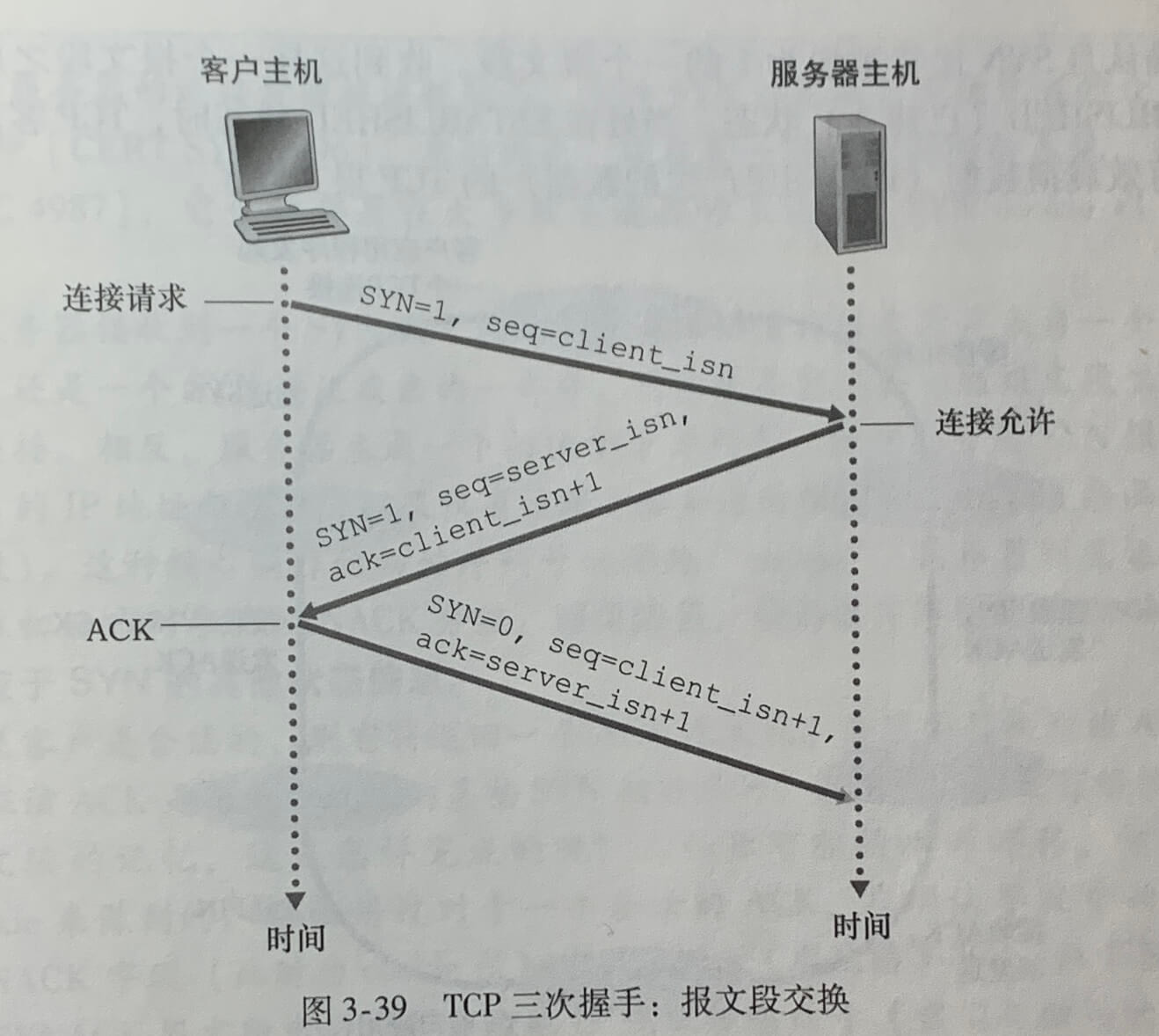
- 第一步:客户端的 TCP 首先向服务器端的 TCP 发送一个特殊的 TCP 报文段。该报文段不包含应用层数据。在报文段的首部中的一个标志位(即 SYN(同步序列化 Synchronize Sequence Numbers)) 比特)被置为1,这个特殊报文段被称为 SYN 报文段。另外,客户会随机地选择一个初始序号(client_isn),并将此编号放置于该起始的 TCP SYN 报文段的序号字段中。该报文段会被封装在一个 IP 数据报中,并发送给服务器。
- 第二步:一旦包含 TCP SYN 报文段的 IP 数据到达服务器主机,服务器会从该数据报中提取出 TCP SYN 报文段,为该 TCP 连接分配 TCP 缓存和变量,并向该客户 TCP 发送允许连接的报文段)。这个允许连接的报文段也不包含应用层数据。在报文段的首部包含3个重要的信息,首先,SYN 被置为1。其次,该 TCP 报文段首部的确认号字段(ack)被置为 client_isn+1。最后,服务器选择自己的初始序号(server_isn),并将其放置到 TCP 报文段首部的序号字段中。该允许连接的报文段被称为SYNACK报文段(SYNACK segement)。
- 第三步:在收到 SYNACK 报文段后,客户也要给该连接分配缓存和变量。客户主机向服务器发送另外一个报文段,这最后一个报文段对服务器的允许连接的报文段进行确认(该客户通过将值 server_isn+1 放置到 TCP 报文段首部的确认字段(ack)中来完成)。因为连接已经建立了,所以该 SYN 比特被置为0。该三次握手的第三个阶段可以在报文段负载中携带客户到服务区的数据。
一旦完成这3个步骤,客户和服务器主机就可以相互发送包括数据的报文段了。在以后每一个报文段中,SYN 比特都将被置为0。为了创建该连接,在两台主机之间发送了 3 个分组,这种连接创建过程被称为3次握手(three-way handshake)。
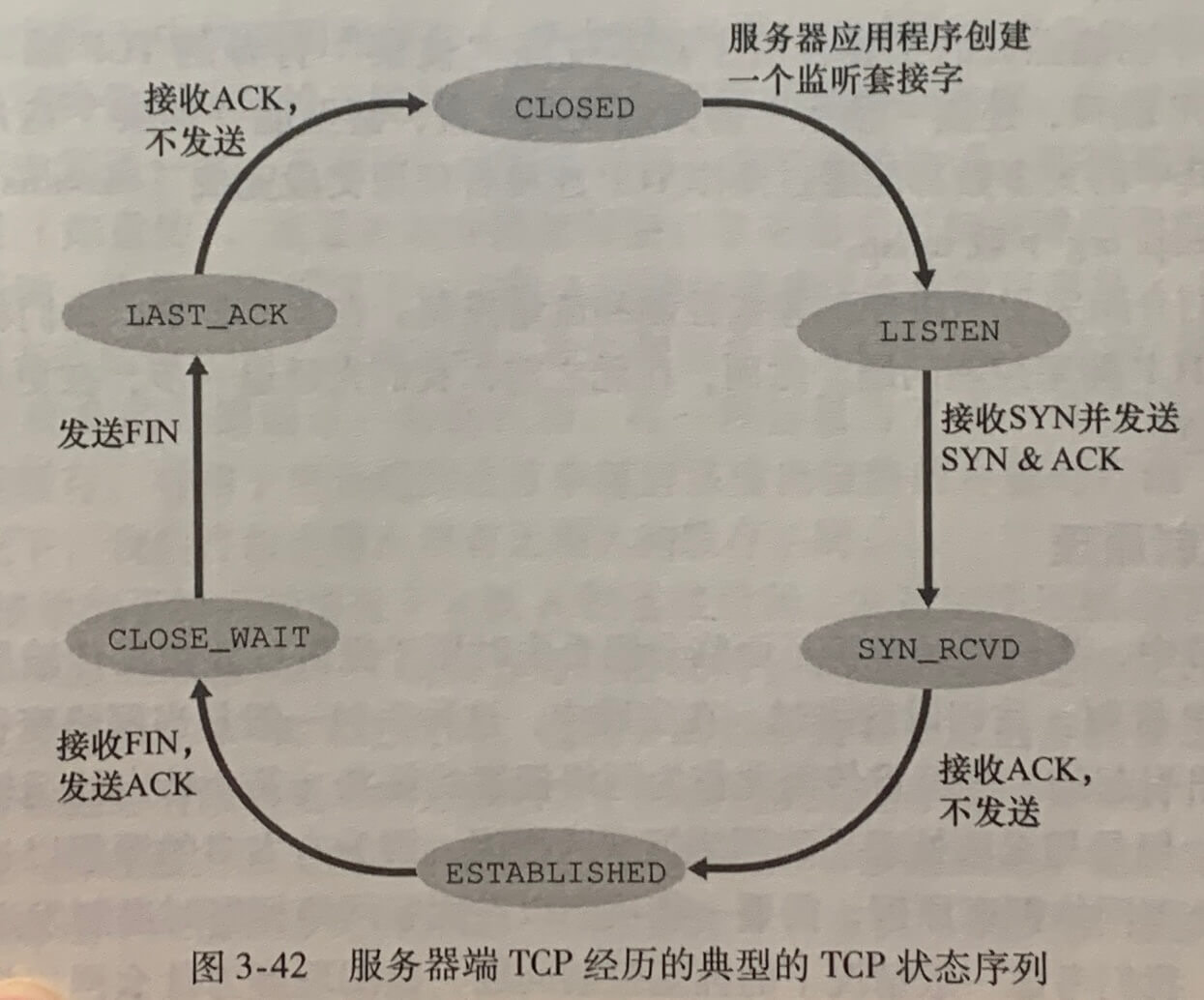
参与一条 TCP 连接的两个进程中的任何一个都能终止该连接。当连接结束后,主机中的“资源”(即缓存和变量)将被释放。

当客户打算关闭连接时,客户应用进程发出一个连接关闭命令,发送 FIN比特 并将其置为1。当服务器收到该报文段后就向发送方回送一个确认报文段。然后服务器发送自己的终止报文段,其 FIN 比特被置为1,最后客户对服务器的终止报文段进行确认。
在一个 TCP 连接的生命周期内,运行在每台主机中的 TCP 协议在各种 TCP 状态之间变迁。

SYN 洪泛攻击
服务器为了响应一个收到的 SYN,分配并初始化连接变量和缓存。如果某客户不发送 ACK 来完成该三次握手的第三步,最终服务器将终止该半开连接并回收资源。
在这种攻击中,攻击者发送大量的 TCP SYN 报文段,而不完成第三次握手的步骤。随着这种 SYN 报文段纷至沓来,服务器不断为这些半开连接分配资源(但从未使用),导致服务器的连接资源被消耗殆尽。
现在有一种有效的防御系统,称为SYN cookie,它们被部署在大多数主流操作系统中。
- 当服务器收到一个 SYN 报文段时,服务器不会为该报文段生成一个半开连接,而是生成一个初始 TCP 序号,该序列号是 SYN 报文段的源和目的 IP 地址与端口号以及仅有该服务器知道的秘密数的一个复杂函数(散列函数),这种初始序列号被称为 cookie。服务器发送具有这种特殊初始序列号的 SYNACK 分组。服务器并不记忆该 cookie 或任何对应于 SYN 的其他状态信息。
- 如果客户是合法的,它将返回一个 ACK 报文段。当服务器收到该 ACK,需要验证该 ACK 是与前面发送的某些 SYN 相对应的。如果服务器计算之后认为它是合法的,则生成一个具有套接字的全开的连接。
- 如果客户没有返回 ACK 报文段,初始的 SYN 并没有对服务器产生危害,因为服务器没有为它分配任何资源。
当一台主机接收到一个 TCP 报文段,其端口号或源 IP 地址与该主机上进行中的套接字不匹配时,在 TCP 中,主机将发送一个重置报文段,将 RST 标志位置为1。在主机接收一个 UDP 分组时,该主机发送一个特殊的 ICMP 数据报。
3.6 拥塞控制原理
为了处理网络拥塞原因,需要一些机制以在面临网络拥塞时遏制发送方。
3.6.1 拥塞原因与代价
接下来分析3个复杂性越来越高的发生拥塞的情况。
-
情况1:两个发送方和一台具有无穷大缓存的路由器


上图中 R 为共享式输出链路的容量。无论主机A和主机B将其发送速率设置为多高,它们都不会看到超过R/2的吞吐量。上图b显示了接近链路容量的速率运行时产生的后果,当发送速率接近R/2时,平均时延就会越来越大。当发送速率超过 R/2 时,路由器中的平均排队分组数就会无限增长。
拥塞代价一:即当分组的到达速率接近链路容量时,分组经历巨大的排队时延。
-
情况2:两个发送方和一台具有有限缓存的路由器
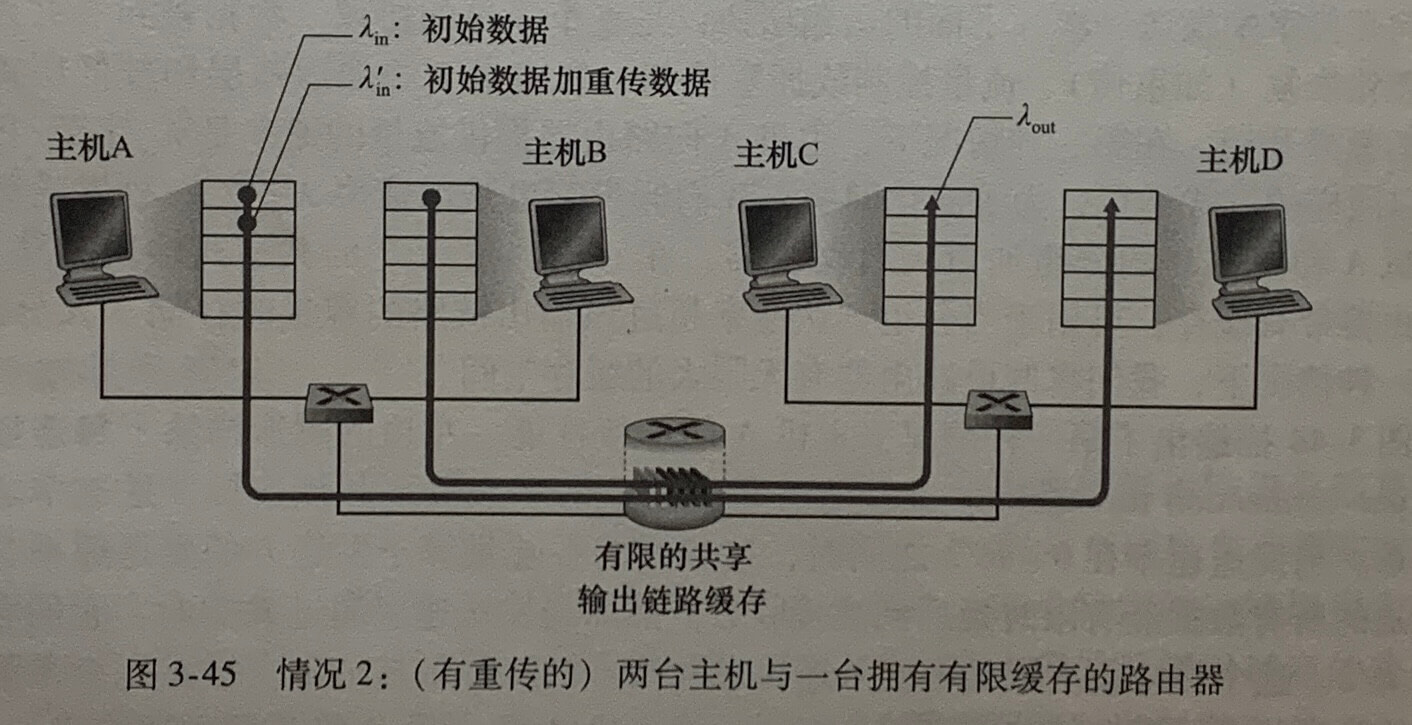
拥塞代价二:发送方必须执行重传以补偿因为缓存溢出而丢弃(丢失)的分组。
拥塞代价三:发送方在遇到大时延时所进行的不必要重传会引起路由器利用其链路带宽来转发不必要的分组副本。
-
情况3:4个发送方和具有有限缓存的多台路由器及多跳路径
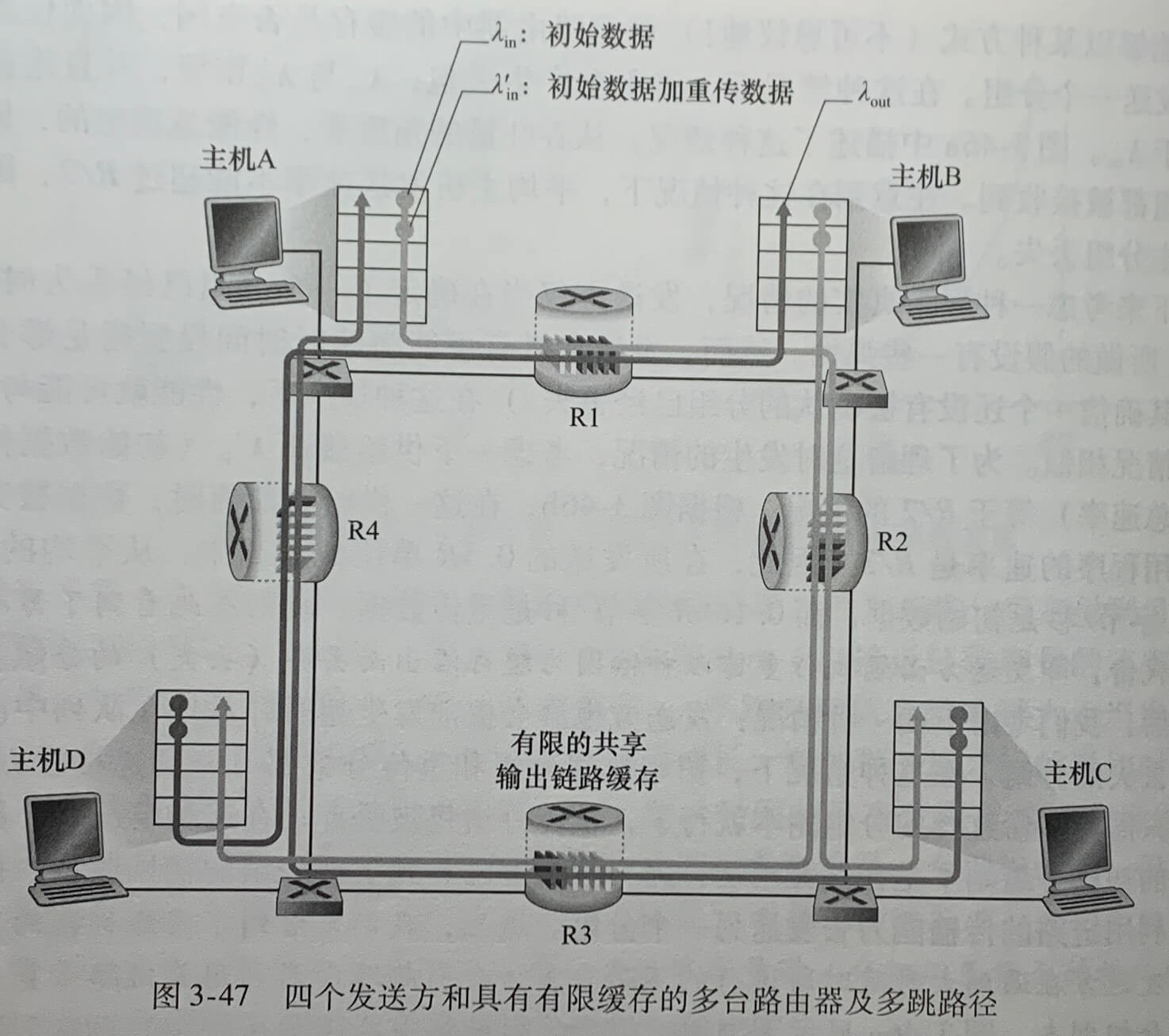

拥塞代价四:当一个分组沿一条路径被丢弃时,每个上游路由器用于转发该分组到丢弃该分组而使用的传输容量最终被浪费掉了。
3.6.2 拥塞控制方法
下列指出在实践中所采用的两种主要拥塞控制方法。
- 端到端拥塞控制。在端到端拥塞控制方法中,网络层没有为运输层拥塞控制提供显式支持。
- 网络辅助的拥塞控制。在网络辅助的拥塞控制中,路由器向发送方提供关于网络中拥塞状态的显式反馈信息。最近 IP 和 TCP 也能够选择性地实现网络辅助拥塞控制。
对于网络辅助的拥塞控制,拥塞信息从网络反馈到发送方通常由两种方式。
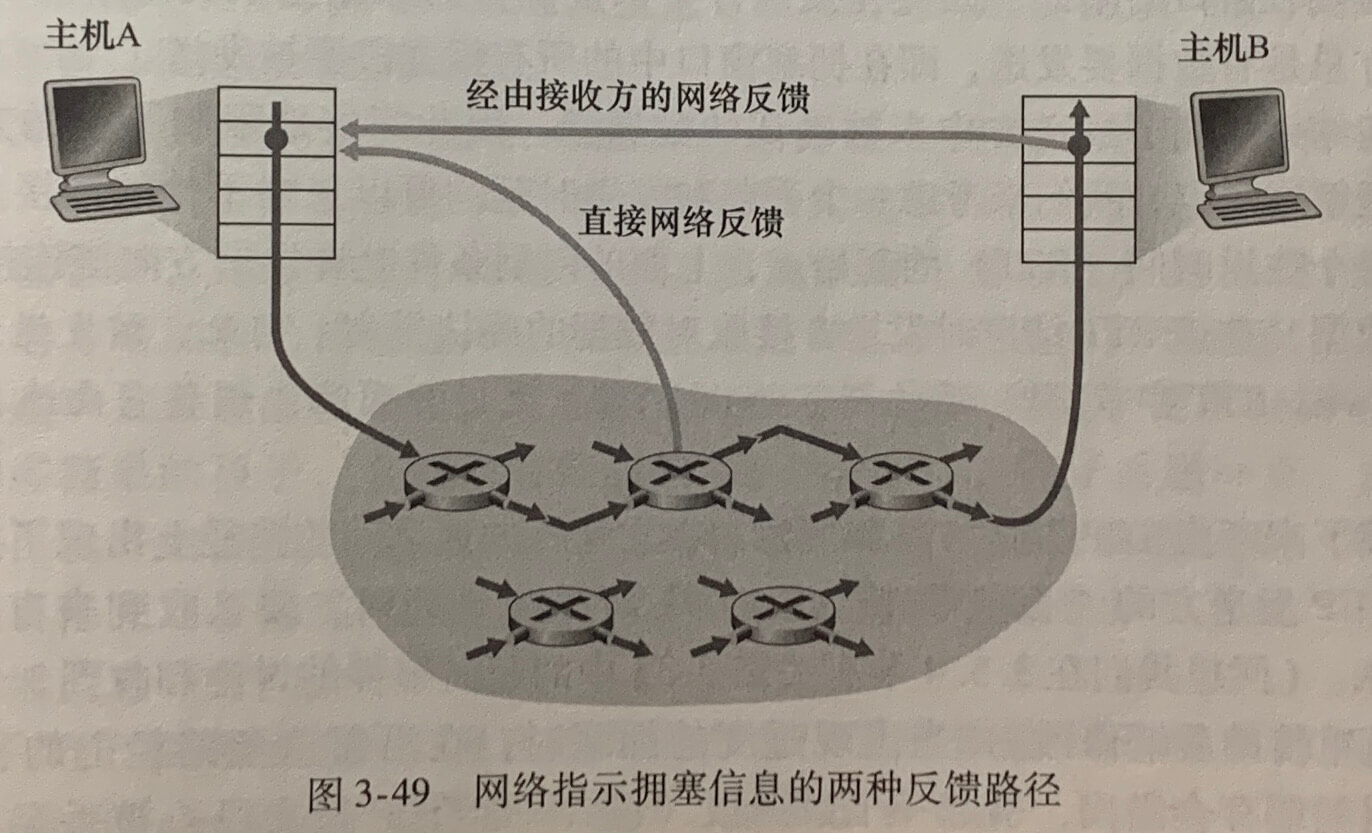
- 直接反馈信息由网络路由器发给发送方。
- 路由器标记或更新从发送方流向接收方的分组中的某个字段来指示拥塞的产生。一旦收到一个标记的分组后,接收方就会向发送方通知该网络拥塞指示,这种通知至少要经历一个完整的RTT。
3.7 TCP拥塞控制
TCP 所采用的方法是让每一个发送方根据所感知到的网络拥塞程度来限制其能向连接发送流量的速率。如果一个 TCP 发送方感知从它到目的地之间的路径上没什么拥塞,则 TCP 发送方增加其发送速率;如果发送方感知沿着该路径有拥塞,则发送方就会降低其发送速率。
TCP 发送方限制向其连接发送流量通过运行在发送方的 TCP 拥塞控制机制跟踪一个额外的变量,即拥塞窗口(congestion window)。拥塞窗口表示为 cwnd,它对一个 TCP 发送方能向网络中发送流量的速率进行限制。在一个发送方中未被确认的数据量不会超过 cwnd 与 rwnd 中的最小值。
一个发送方将丢包定义为要么出现超时,要么收到来自接收方的3个冗余 ACK。当发生丢包时,发送方就认为在发送方到接收方的路径上出现了拥塞的指示。
TCP 使用确认(即接收方的 ACK)来增加窗口长度(及其传输速率),如果确认以相当慢的速率到达,则该拥塞窗口将以相当慢的速率增加。如果确认以高速率到达,则该拥塞窗口将会更为迅速地增大。TCP 使用确认来触发(或及时)增大它的拥塞窗口长度, TCP 被说成是**自计时(self-clocking)**的。
TCP 用下列的方法来设置它们的发送速率
- 一个丢失的报文段表意味着拥塞,因此当丢失报文段时应当降低 TCP 发送方的速率。
- 一个确认报文段指示该网络正在向接收方交付发送的报文段,因此,当对先前未确认报文段的确认到达时,能够增加发送方的速率。
- 带宽探测。TCP 发送方增加它的传输速率,从该速率后退,进而再次开始探测,看看拥塞开始速率是否发生了变化。
TCP拥塞控制算法包括3个主要部分:1.慢启动;2.拥塞避免;3.快速恢复。慢启动和拥塞避免是 TCP 的强制部分,快速恢复是推荐部分。
拥塞控制算法
1.慢启动
cwnd 的初始值通常是一个 MSS(最大报文长度) 的较小值,初始发送速率为 MSS/RTT。通常可用带宽会比 MSS/RTT 大得多,为了找到可用带宽的数量,在**慢启动(slow-start)**状态下,cwnd(拥塞窗口)的值以 1 个 MSS 开始并且每当传输的报文段首次被确认就增加 1 个MSS。
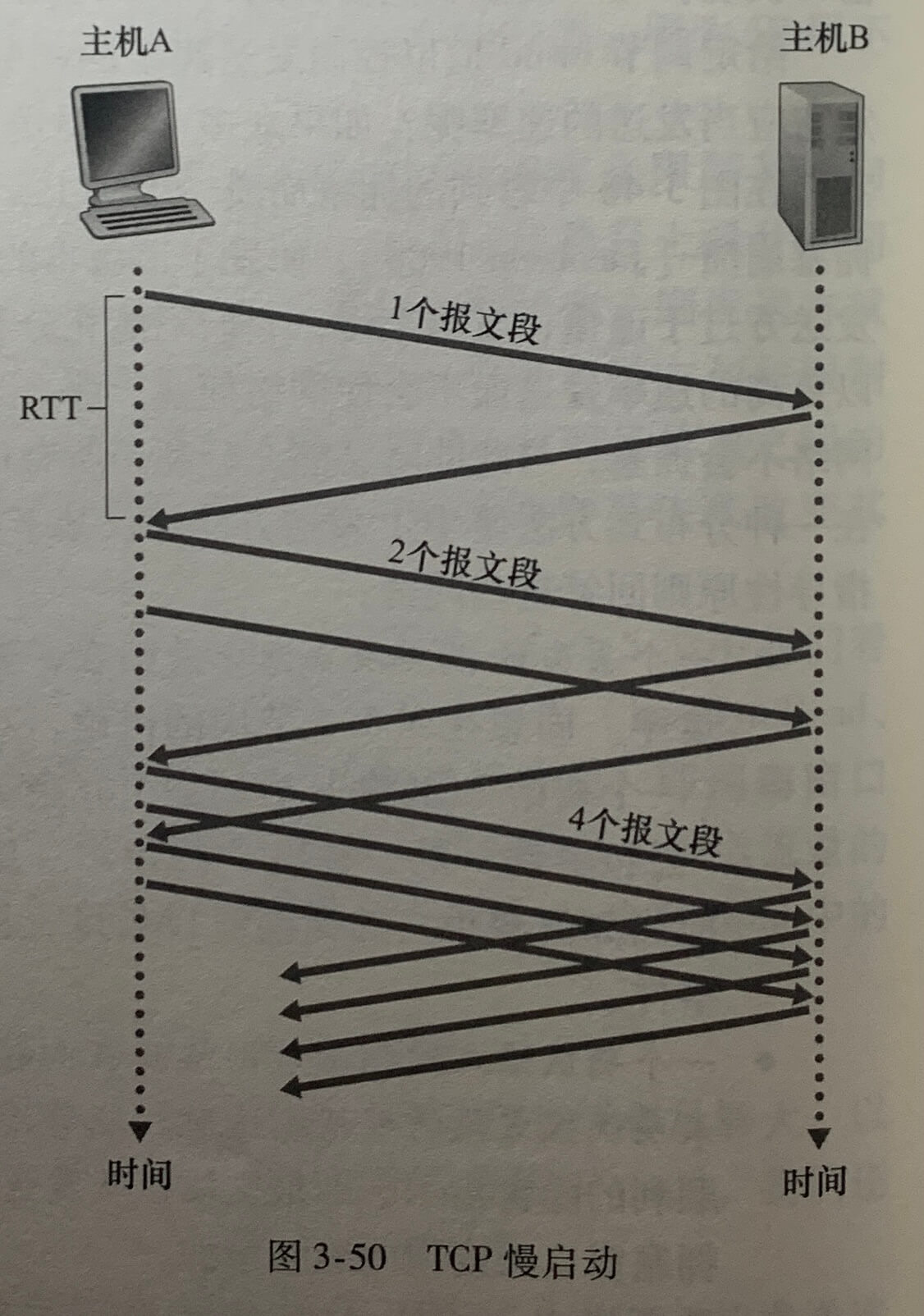
TCP 发送速率起始慢,但在慢启动阶段以指数增加。当满足以下条件时,结束慢启动:
- 存在一个由超时指示的丢包事件(即拥塞),TCP 发送方将 cwnd 设置为 1 并重新开始慢启动过程。将 ssthresh(慢启动阀值)设为 cwnd 的值一半。
- 直接与 ssthresh 的值相关联,当到达或超过 ssthresh 的值时,结束慢启动并且 TCP 转移到拥塞避免模式。
- 检测到 3 个冗余 ACK。

2.拥塞避免
一旦进入拥塞避免状态,cwnd 的值大约是上次遇到拥塞时的值的一半,即距离拥塞可能并不遥远。拥塞避免采用保守的方式增加 cwnd。当一个确认到达时,就将 cwnd 增加一个 MSS(MSS/cwnd)字节。
当出现超时时,拥塞避免算法与慢启动的情况一样。不过对收到三个冗余 ACK 这种丢包行为,会采取将 cwnd 的值减半,将 sshresh 值记录为 cwnd 值的一半。接下来进入快速恢复状态。
3.快速恢复
进入快速恢复状态,对收到的每个冗余 ACK,cwnd 的值增加一个 MSS。当对丢失报文段的一个 ACK 到达时,TCP 在减低 cwnd 后进入拥塞避免状态。如果出现超时事件,快速恢复执行慢启动和拥塞避免中相同的动作后,迁移到慢启动状态。
4.TCP拥塞控制:回顾
TCP 拥塞控制常常被称为**加性增、乘性减(AIMD)**拥塞控制方式。
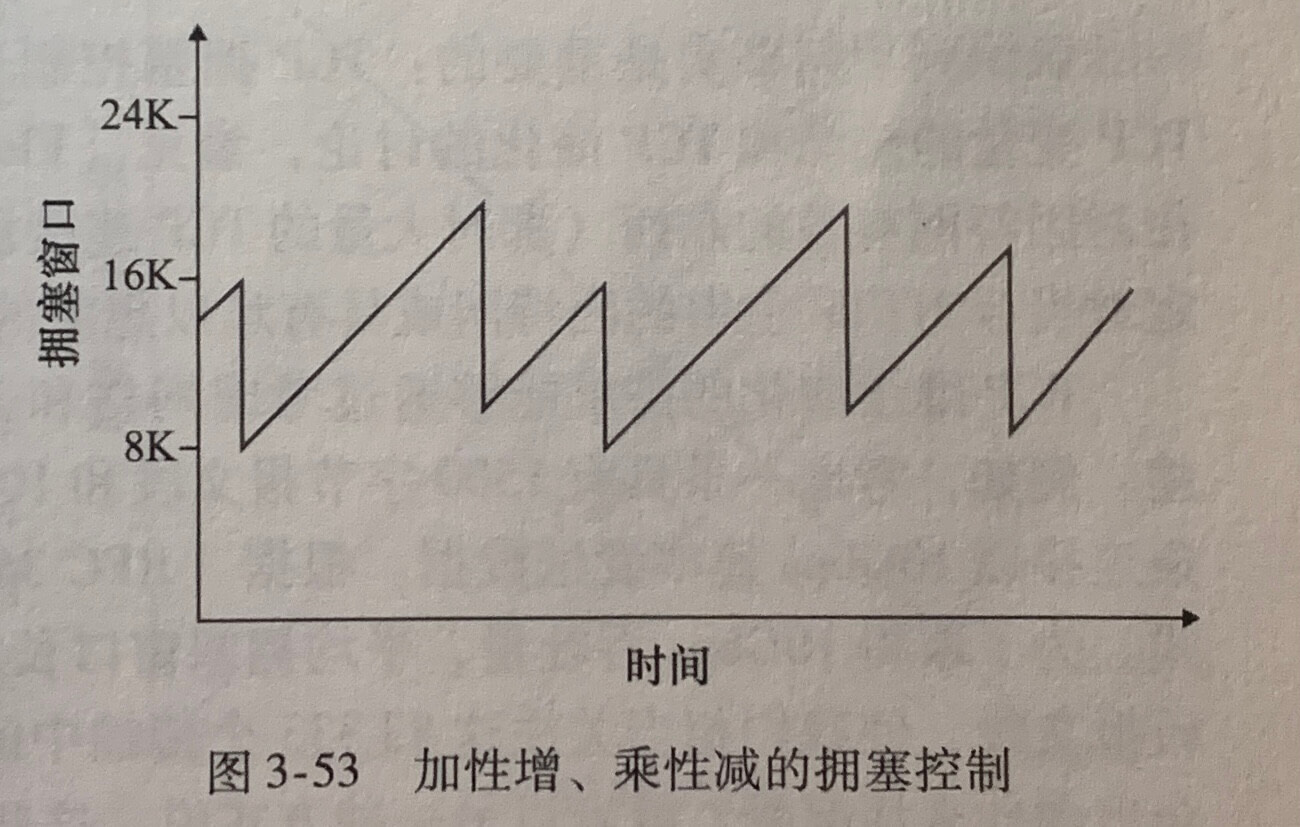
3.7.1 公平性
TCP 趋于在竞争的多条 TCP 连接之间提供对一段瓶颈链路带宽的平等分享。
在实际中,通常是那些有较小 RTT 的连接抢到更多的可用带宽(即较快地打开其拥塞窗口)。
1.公平性和UDP
UDP没有内置的拥塞控制,所以 UDP 的应用能以恒定的发送速率将其数据注入网络之中并且偶尔会丢失分组。由于 TCP 拥有拥塞控制,UDP 源有可能压制 TCP 流量。当今的一个主要研究领域是开发一种因特网中的拥塞控制机制,用于阻止 UDP 流量不断压制直至中断因特网吞吐量的情况。
2.公平性和并行TCP连接
有些 TCP 应用是基于多个并行连接,比如 Web 浏览器通常使用多个并行 TCP 连接来传送一个 Web 页中的多个对象。这其中就对其他如使用一条 TCP 连接的应用失去了公平性。
3.7.2 明确拥塞通告:网络辅助拥塞控制
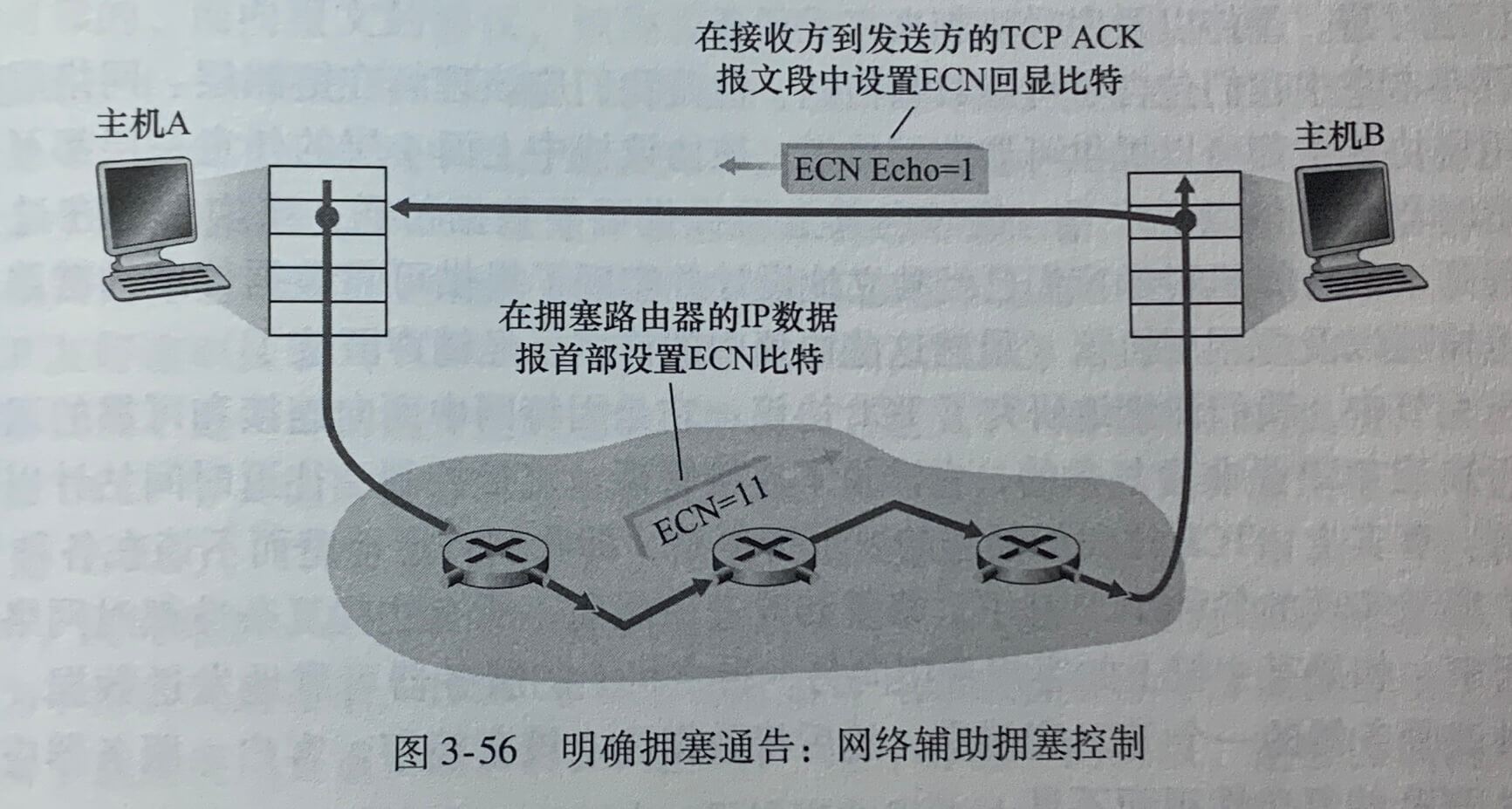
**明确拥塞通告(Explicit Congestion Notification,ECN)**允许网络明确向 TCP 发送方和接收方发出拥塞信号。拥塞指示由被标记的 IP 数据报所携带,送给目的主机,再由目的主机通知发送主机。
小结
UDP 和 TCP 是因特网运输层的两匹“驮马”。然而这两个协议并不是完美无缺的,研究人员在忙于研制其他的运输层协议,以下集中是现在已经成为 IETF 建议的标准:
- 数据报拥塞控制协议(Datagram Congestion Control Protocol,DCCP)提供一种低开销、面向报文、类似于 UDP 的不可靠服务,但是具有应用程序可选择的拥塞控制形式,该机制与 TCP 相兼容。DCCP 被设想用于诸如流媒体等应用程序中。
- QUIC(Quick UDP Internet Connection)协议,该协议通过重传以及差错检测、快速连接建立和基于速率的拥塞控制算法提供可靠性,而基于速率的拥塞控制算法是以 TCP 友好特性为目标,这些机制都是在 UDP 之上作为应用层协议实现的。
- DCTCP(数据中心 TCP)是一种专门为数据中心网络设计的 TCP 版本,使用 ECN 以更好地支持短流和长流的混合流。
- 流控制传输协议(Stream Control Transmission Protocol,SCTP)是一种可靠的、面向报文的协议,该协议允许几个不同的应用层次的“流”复用到单个 SCTP 连接上。
- TCP 友好速率控制(TFRC)协议是一种拥塞控制协议而不是一种功能齐全的运输层协议。它定义了一种拥塞控制机制,该机制能被用于诸如 DCCP 等其他运输协议。TFRC 的目标是平滑在 TCP 拥塞控制中的“锯齿”行为,同时维护一种长期的发送速率。TFRC 非常适合诸如 IP 电话或流媒体等多媒体应用,这种平滑的速率对于这些应用是重要的。
第4章 网络层:数据平面
网络层是在协议栈中是最复杂的层次。
4.1 网络层概述
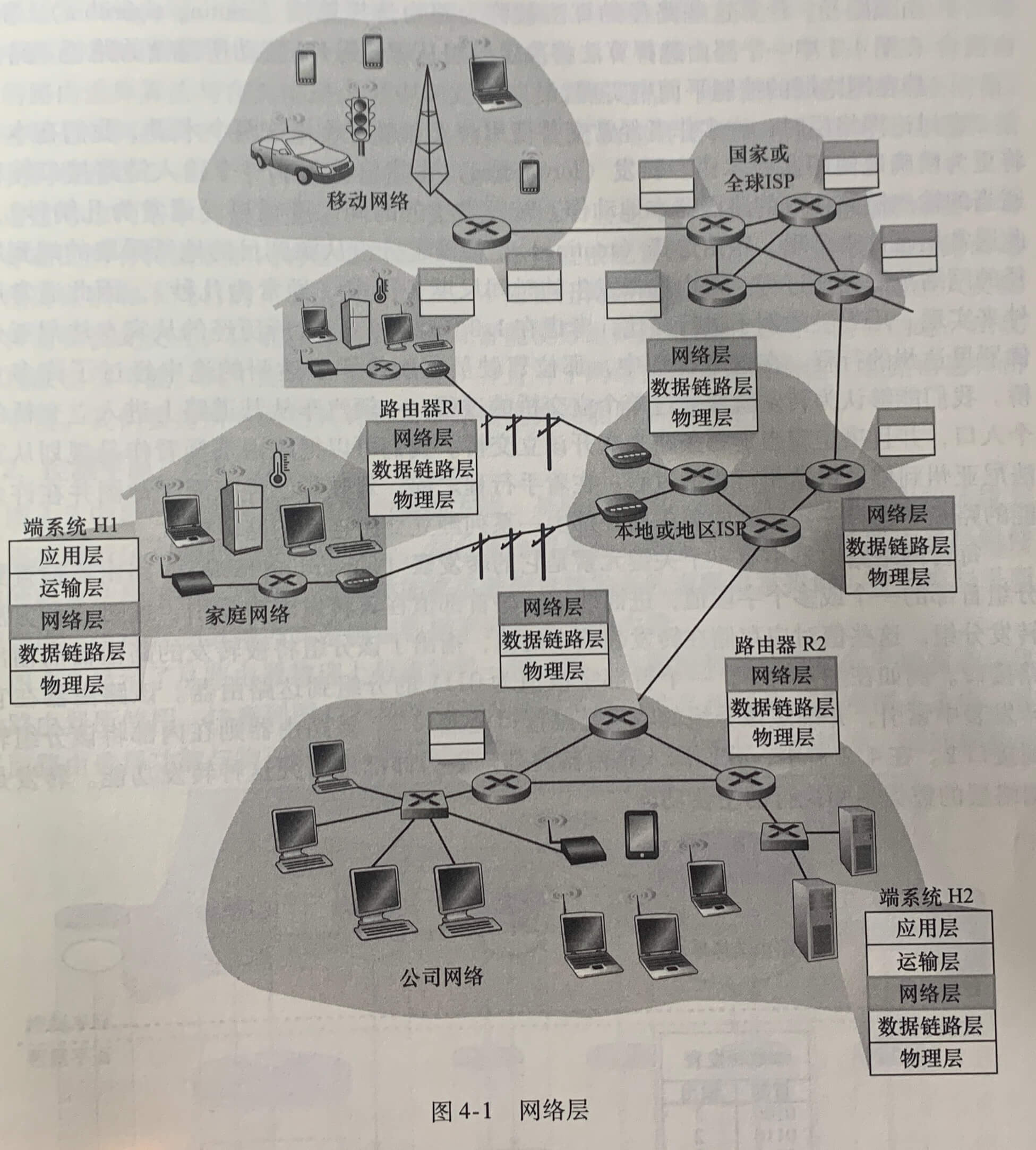
每台路由器的数据平面的主要作用是从其输入链路向其输出链路转发数据报。控制平面的主要作用是协调这些本地的路由器转发动作,使得数据报沿着源和目的地主机之间的路由器路径最终进行端到端传送。
4.1.1 转发和路由选择:数据平面和控制平面
网络层的作用是将分组从一台发送主机移动到一台接收主机上,为此,需要使用两种重要的网络层功能:
- 转发。当一个分组到达某路由器的一条输入链路时,该路由器必须将该分组移动到适当的输出链路。转发是在数据平面中实现的唯一功能。
- 路由选择。当分组从发送方流向接收方时,网络层必须决定这些分组所采用的路由或路径。计算这些路径的算法被称为路由选择算法(routing algorithm)。
**转发(forwarding)**是指将分组从一个输入链路接口转移到适当的输出链路接口的路由器本地动作。转发发生的时间尺度很短(通常为几纳秒),因此通常用硬件来实现。**路由选择(routing)**是指确定分组从源到目的地所采取的端到端路径的网络范围处理过程。路由选择发生的时间尺度长得多(通常为几秒),因此通常用软件来实现。
每台网络路由器中有一个关键元素是它的转发表(forwarding table)。路由器检查到达分组首部的一个或多个字段值,进而使用这些首部值在其转发表中索引,通过这种方法来转发分组。这些值对应存储在转发表项中的值,指出了该分组将被转发的路由器的输出链路接口。
1.控制平面:传统的方法
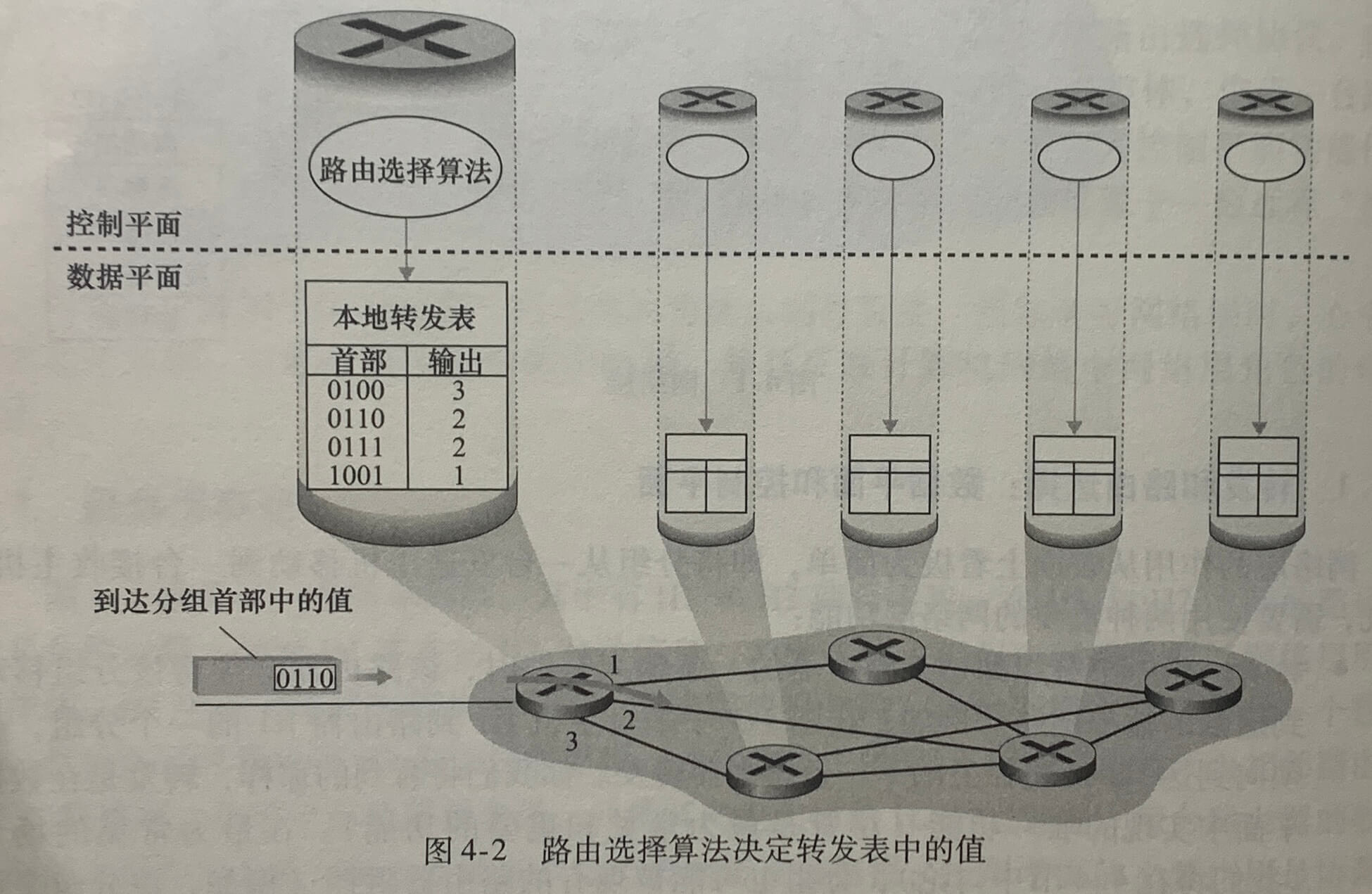
路由选择算法决定了插入该路由器转发表的内容。路由器选择算法运行在每台路由器中,并且在每台路由器中都包含转发和路由选择两种功能。
在一台路由器中的路由选择算法与在其他路由器中的路由选择算法通信,以计算出它的转发表的值。
2.控制平面:SDN(软件定义网络(Software-Defined Networking))方法
到近期,路由选择产品在其产品中采用的是传统方法,使用该方法,每台路由器都有一个与其他路由器的路由选择组件通信的路由选择组件。
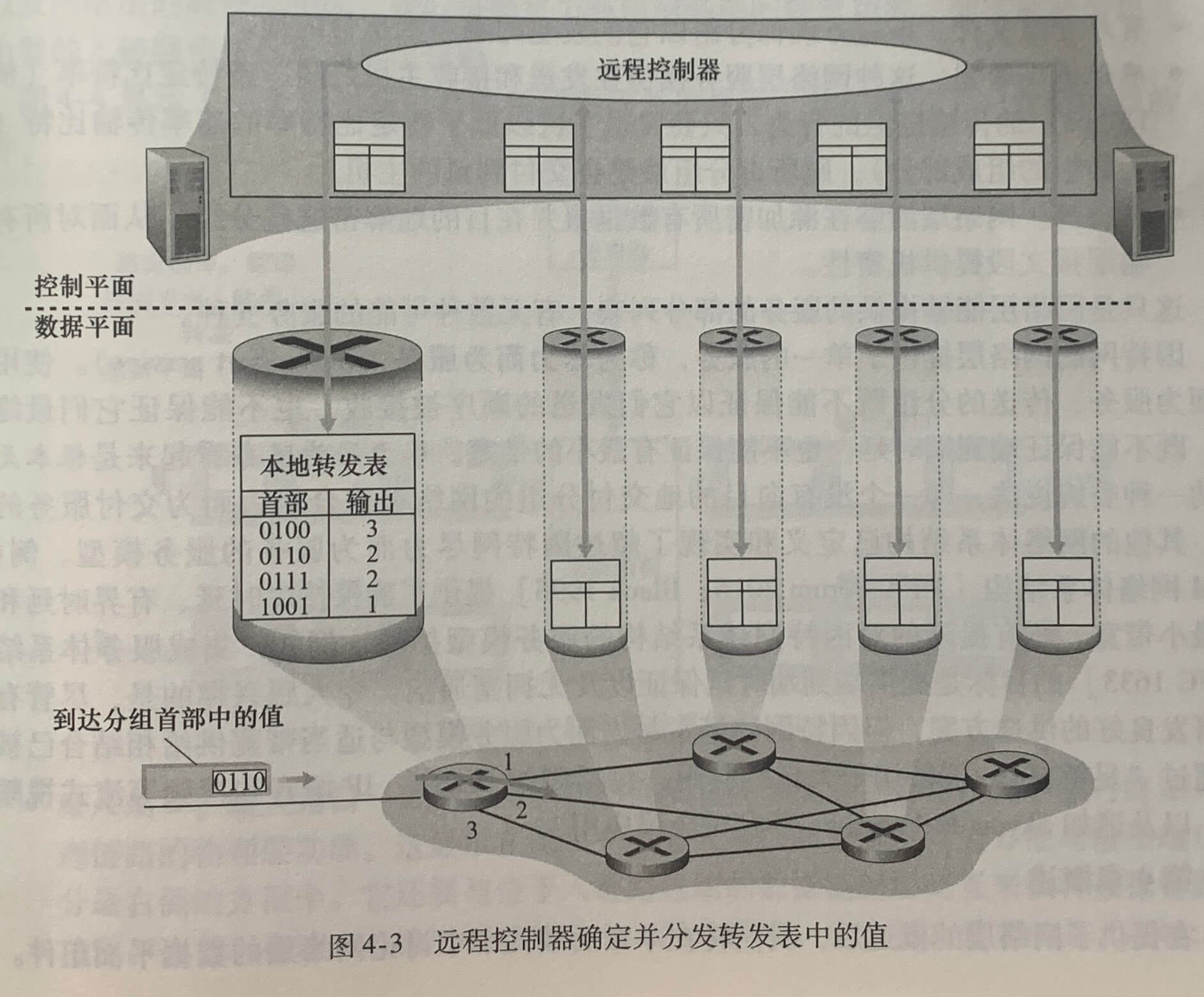
上图显示的是另一种方法,即远程控制器计算和分发转发表以供每台路由器所使用。控制平面路由选择功能与物理的路由器是分离的,路由选择设备仅执行转发,而远程控制器执行并分发转发表。
远程控制器可能实现在具有高可靠性和冗余的远程数据中心中,并可能由 ISP 或某些第三方管理。路由器和远程控制通过交换包含转发表和其他路由选择信息的报文来实现通信。这就是**软件定义网络(Software-Defined Networking,SDN)**的本质,因为计算转发表并与路由器交互的控制器是用软件实现的。
4.1.2 网络服务模型
**网络服务模型(network service model)**定义了分组在发送与接收端系统之间的端到端运输特性。
网络层能提供的某些可能的服务,这些服务可能包括:
- 确保交付。
- 具有时延上界的确保交付。
- 有序分组交付。
- 确保最小带宽。
- 安全性。
因特网的网络层提供了单一的服务,称为尽力而为服务(best - effirt service)。使用尽力而为服务,传送的分组既不能保证以它们发送的顺序被接收,也不能保证它们最终交付。既不能保证端到端时延,也不能保证有最小的带宽。因特网的基本尽力而为服务模型与适当带宽供给相结合已被证明超过“足够好”,能够用于大量的应用。
分组交换机是指一台通用分组交换设备,它根据分组首部字段中的值,从输入链路接口到输出链路接口转移分组。某些分组交换机被称为链路层交换机(link - layer switch),基于链路层帧中的字段值做出转发决定,这些交换机因此被称为链路层设备。其他分组交换机称为路由器(router),基于网络层数据报中的首部字段做出转发决定,路由器是网络层设备。
4.2 路由器工作原理

-
输入端口。**输入端口(input port)**执行几项重要功能。它在路由器中执行终结入物链路的物理层功能。它要与位于入链路远端的数据链路层交互来执行数据链路层功能。输入端口还要执行查找功能,通过查找转发表决定路由器的输出端口,到达的分组通过路由器的交换结构转发到输出端口。
这里“端口”指的是路由器的物理输入和输出接口。
-
交换结构。交换结构将路由器的输入端口连接到它的输出端口。这种交换结构完全包含在路由器之中,即它是一个网络路由器中的网络。
-
输出端口。输出端口存储从交换结构接收的分组,并通过执行必要的链路层和物理层功能在输出链路上传输这些分组。当一条链路是双向的时候,输入端口通常与该链路的输入端口成对出现在同一线路卡上。
-
路由选择处理器。路由选择处理器执行控制平面功能。
在传统的路由器中,它执行路由选择协议,维护路由选择表与关联链路状态信息,并为该路由器计算转发表。
在 SDN 路由器中,路由选择处理器负责与远程控制器通信,目的是接收由远程控制器计算的转发表项,并在该路由器的输入端口安装这些表项。
路由器的输入输出端口和交换结构几乎总是用硬件实现的,即数据平面。控制平面的功能通常用软件实现并在路由选择处理器上执行。
4.2.1 输入端口处理和基于目的地转发

在输入端口中执行的查找对于路由器运行是至关重要的。路由器使用转发表来查找输出端口,使得到达的分组能经过交换结构转发到该输出端口。转发表是由路由选择处理器计算和更新的(使用路由器选择协议与其他网络路由器中的路由选择处理器进行交互),或者转发表接收来自远程 SDN 控制器的内容。
转发表从路由选择处理器经过独立总线复制到线路卡。
路由器用分组的目的地址(例如32位比特)的前缀(prefix)与该转发表中的表项进行匹配,如果存在一个匹配项,则路由器向与该匹配项相关联的链路转发分组。当有多个匹配时,该路由器使用最长前缀匹配规则(longest prefix matching rule),即在该表中寻找最长的匹配项,并向与最长前缀匹配相关联的链路接口转发分组。
一旦通过查找确定了某分组的输出端口,该分组就能够发送进入交换结构。一个被阻塞的分组必须要在输入端口处排队,并等待稍后被及时调度以通过交换结构。
输入端口除了执行查找动作,还有执行其他动作:1.物理层和链路层处理;2.检查分组的版本号、检验和以及寿命字段,并重写后两个字段;3.更新用于网络管理的计数器;
“匹配加动作”抽象不仅作用大,而且在网络设备中无处不在。
防火墙是一种过滤所选择的入分组的设备。
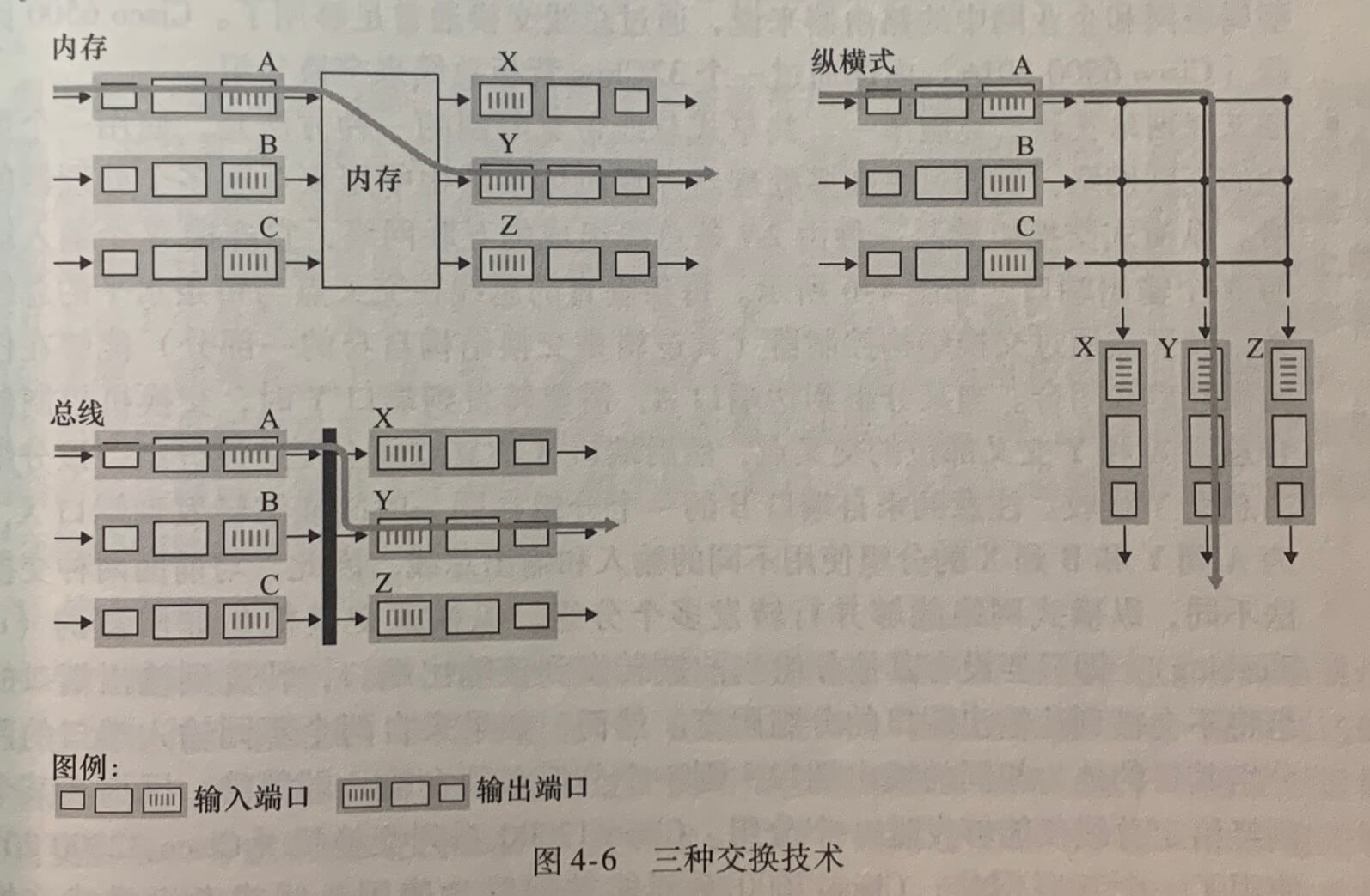
4.2.2 交换
交换结构位于一台路由器的核心部位。
-
经内存交换。最简单、最早的路由器是传统的计算机,在输入端口与输出端口之间的交换是在 CPU(路由选择处理器)的直接控制下完成的。一个分组到达一个输入端口时,该端口会先通过中断方式向路由选择处理器发出信号,于是该分组从输入端口处被复制到处理器内存中。路由选择处理器从其首部中提取目的地址,在转发表中找出适当的输出端口,并将该分组复制到输出端口的缓存中。
许多现代路由器通过内存进行交换。与早期路由器的一个主要差别是,目的地址的查找和将分组存储(交换)进适当的内存存储位置是由输入线路卡来处理的。
-
经总线交换。在这种方法中,输入端口经一根共享总线将分组直接传送到输出端口,不需要路由器选择处理器的干预。通常按以下方式完成该任务:让输入端口为分组预先计划一个交换机内部标签(首部),指示本地输出端口,使分组在总线上传送和传输到输出接口。该分组能由所有输出端口收到,但只有与该标签匹配的端口才能保存该分组。然后标签在输出端口被去除,因为其仅用于交换机内部来跨越总线。如果多个分组同时到达路由器,一次只有一个分组能够跨越总线。对于运行在小型局域网或企业网中的路由器来说,通过总线交换通常足够用了。
-
经互联网络交换。克服单一、共享式总线带宽限制的一种方法是,使用一个更复杂的互联网络。纵横式交换机就是一种由2N条总线组成的互联网络,它连接N个输入端口和N个输出端口。每条垂直的总线在交叉点与每条水平的总线交叉,交叉点通过交换结构控制器能够在任何时候开关和闭合。纵横式网络能够并行转发多个分组。纵横式交换是非阻塞的(non-blocking)。
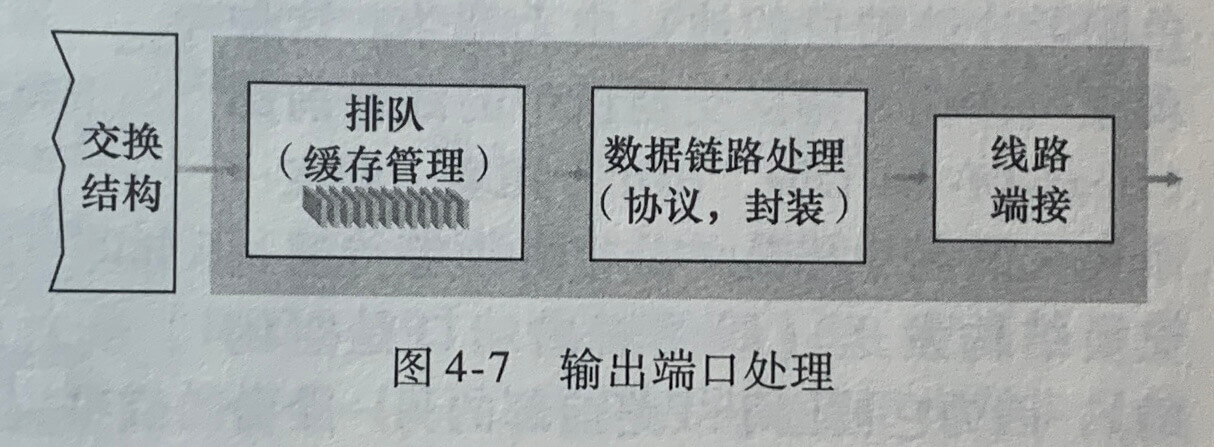
4.2.3 输出端口处理
输出端口处理取出已经存放在输出端口内存中的分组并将其发送到输出链路上。
4.2.4 何处出现排队
排队的位置和程度取决于流量负载、交换结构的相对速率和线路速率。随着这些队列的增长,路由器的缓存空间将会耗尽,并且当无内存可用于存储到达的分组时将会出现丢包。
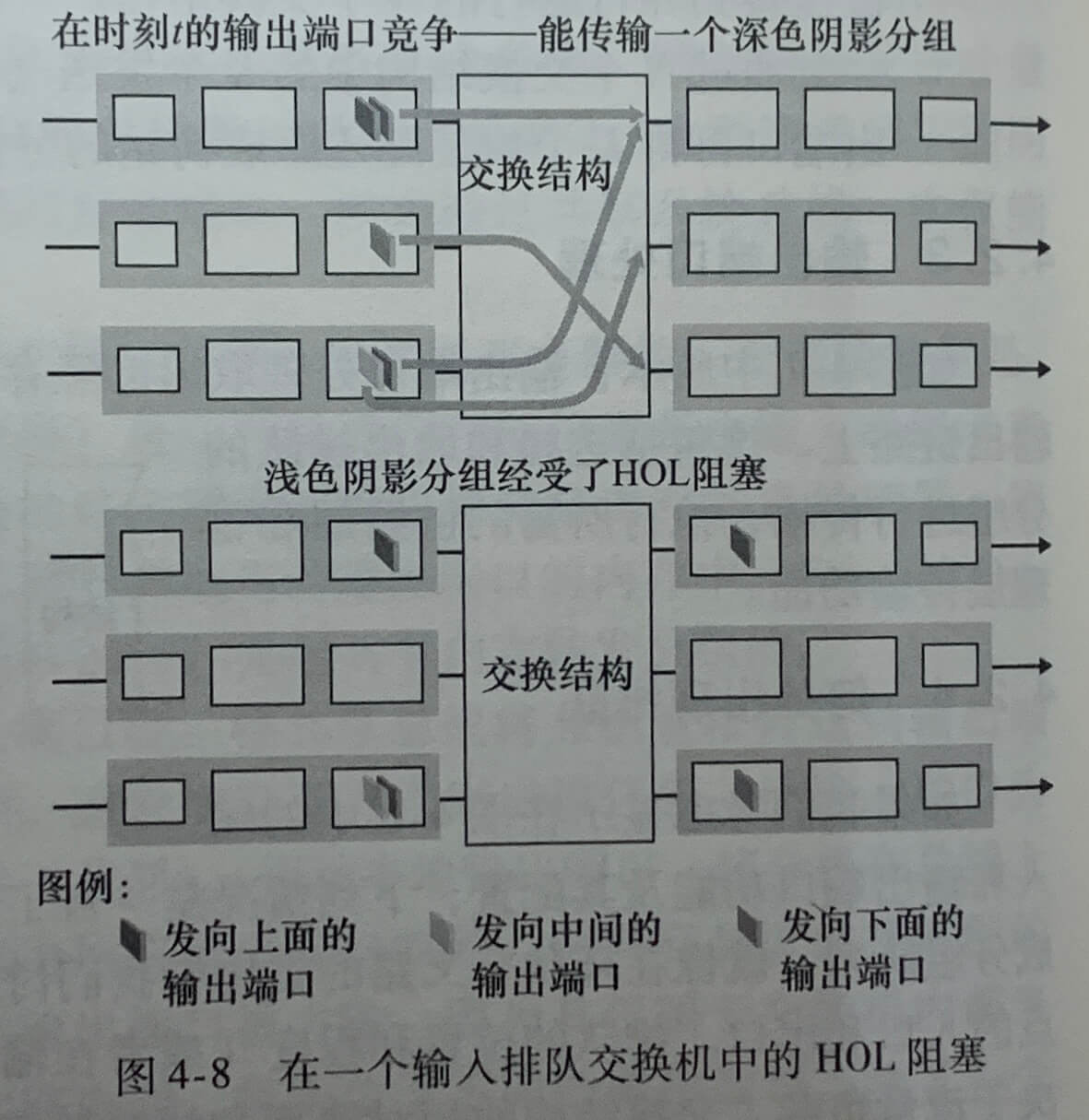
1.输入排队
如果交换结构的传送速率比输入线路的速率慢,此时输入端口将出现分组排队。
线路前部(Head-Of-the-Line,HOL)阻塞,即在一个输入队列中排队的分组必须等待通过交换结构发送(即使输出端口是空闲的),因为它被位于线路前部的另一个分组所阻塞。
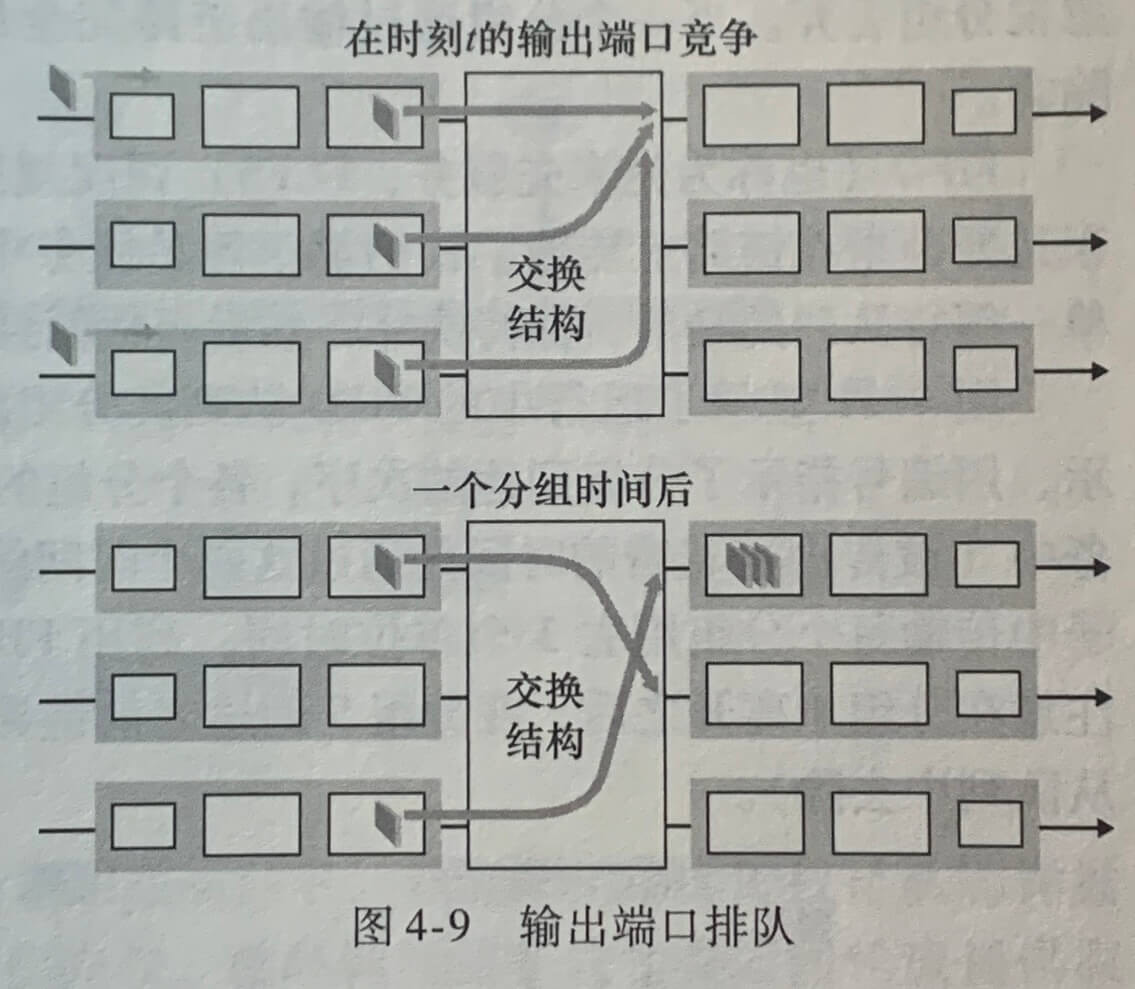
2.输出排队
假定交换结构的传送速率比输入线路和输出线路的速率快 N 倍,并且到达 N 个输入端口的每个端口的分组的目的地都是相同的输出端口,此时输出端口将出现分组排队。
在缓存填满之前便丢弃一个分组(或在其首部加上标记)的做法是有利的,这可以向发送方提供一个拥塞信号。
4.2.5 分组调度
1.先进先出
**先进先出(First-In-First-Out,FIFO)**链路调度规则,如果链路当前忙于传输另一个分组,到达链路输出队列的分组要排队等待传输。FIFO也称为先来先服务,FCFS。

2.优先权排队
在**优先权排队(priority queueing)**中,到达输出链路的分组被分类放入输出队列中的优先权类。每个优先权通常都有自己的队列。当选择一个分组传输时,优先权排队规则将从队列为非空的最高优先权类中传输一个分组。在同一优先权类的分组之间的选择通常以 FIFO 方式完成。
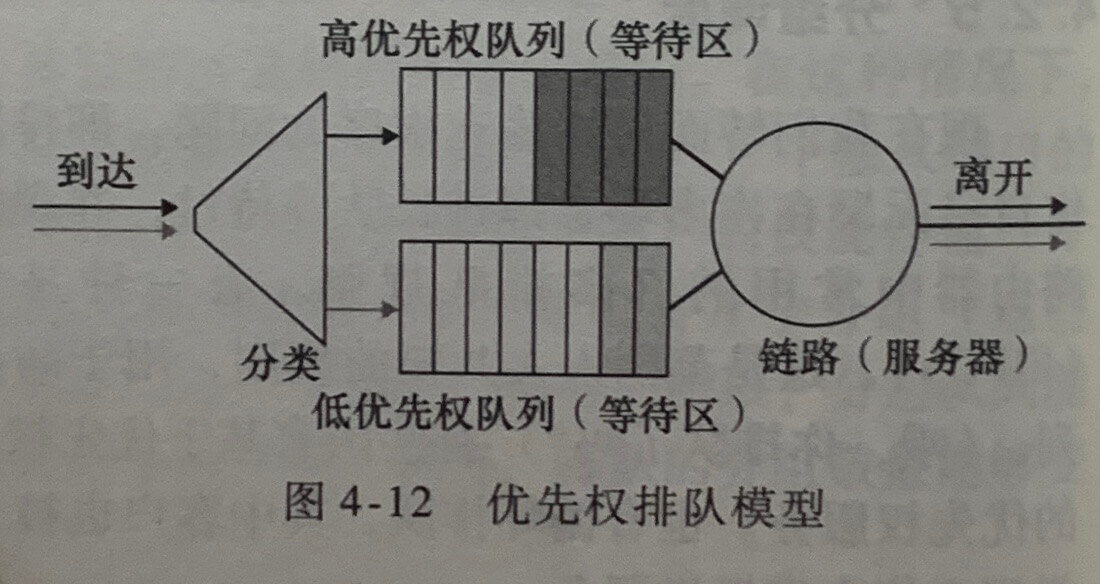
3.循环和加权公平排队
在**循环排队规则(round robin queuing discipline)**下,分组像使用优先权排队那样被分类。然而,在类之间不存在严格的服务优先权,循环调度器在这些类之间轮流提供服务。所有服务类被同等对待,也就是说,没有任何服务类比任何其他服务类具有优先级。
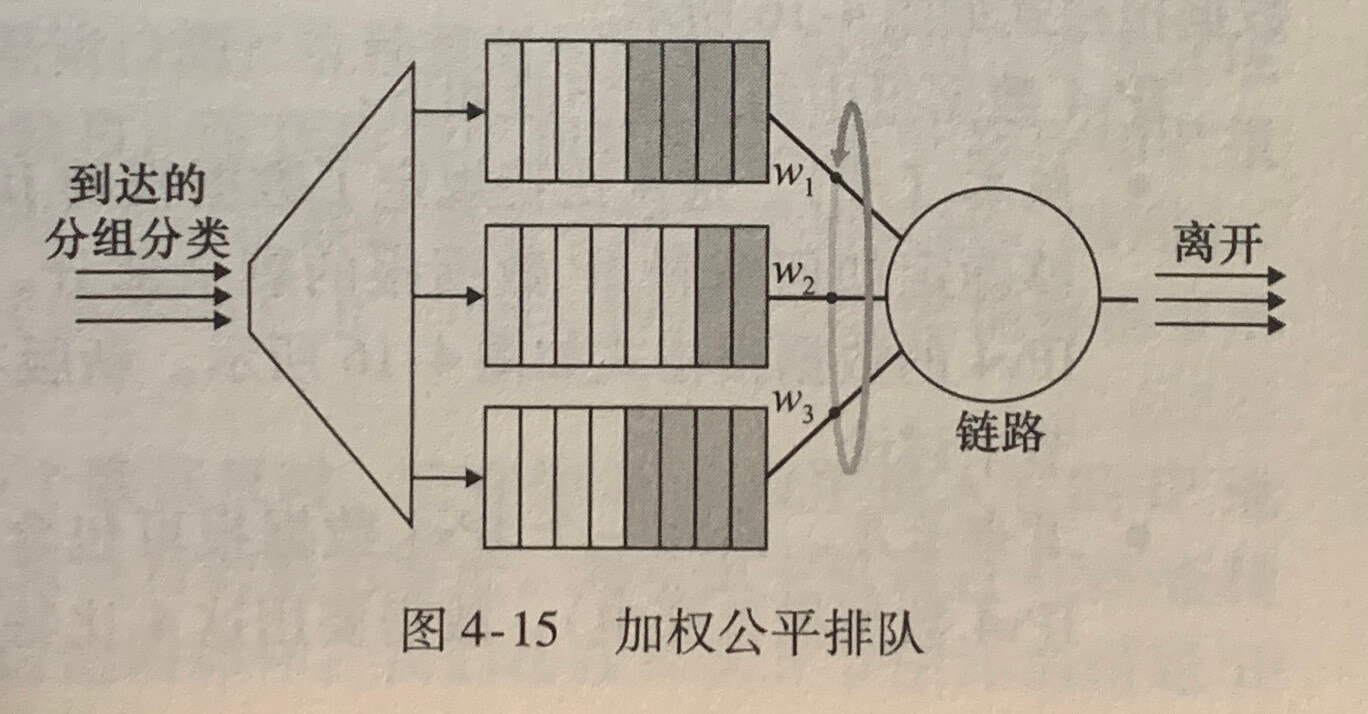
**加权公平排队(Weighted Fair Queuing,WFQ)**规则,到达的分组被分类并在合适的每个类的等待区域排队,与使用循环调度一样,WFQ 调度器以循环的方式为各个类提供服务。WFQ 与循环排队不同之处在于,服务类被不同的对待,也就是说,每个类在任何时间间隔内都可以接收到不同的服务量。当WFQ的所有类都具有相同的服务权重时,WFQ与RR是相同的。
4.3 网际协议:IPv4、寻址、IPv6及其他
今天有两个版本的 IP 正在使用,IPv4 和 IPv6。
4.3.1 IPv4数据报格式

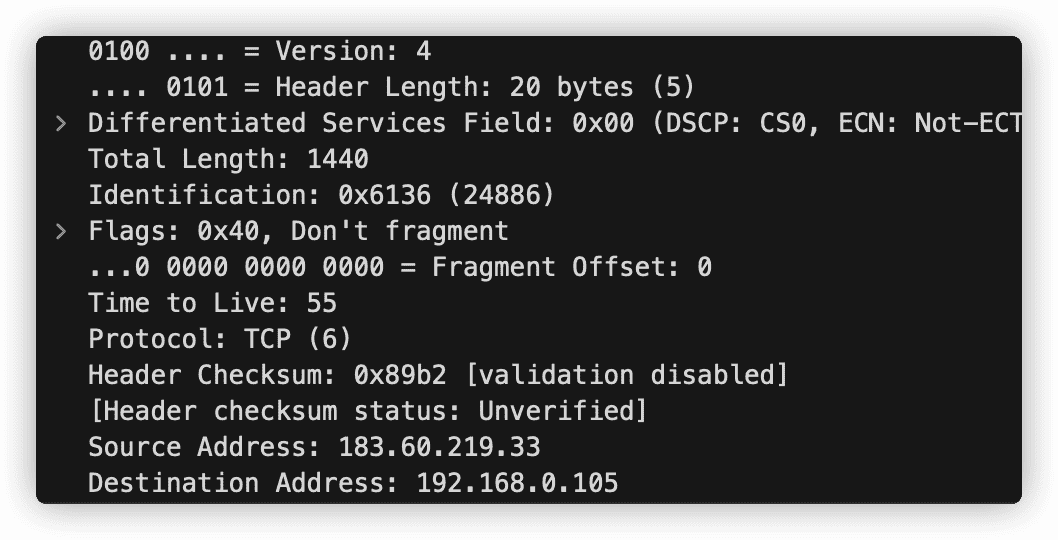
-
版本号。4比特规定了数据报的 IP 协议版本。路由器通过版本号确定如何解释 IP 数据报的剩余部分。
-
首部长度。一个 IPv4 数据报可包含一些可变数量的选项,故需要用4比特来确定 IP 数据报中载荷实际开始的地方。大多数数据报不包含选项,所以一般的 IP 数据报具有20字节的首部。
-
服务类型。服务类型(TOS)比特包含在 IPv4 首部中,以便使不同类型的 IP 数据报能相互区别开来。
-
数据报长度。这是 IP 数据报的总长度(首部加上数据),以字节计。因为该字节段长 16 比特,所以 IP 数据报的理论最大长度为 65535 字节。然而,数据报很少有超过 1500 字节的。
-
标识、标志、片偏移。这三个字段与 IP 分片有关。新版本的 IPv6 不允许在路由器上对分组分片。
-
寿命。寿命(Time-To-Live,TTL)字段用来确保数据报不会永远在网络中循环。每当一台路由器处理数据报时,该字段的值减1。若TTL为0,则该数据报必须丢弃。
-
协议。该字段通常仅当一个 IP 数据报到达其最终目的时才会有用。该字段值指示了 IP 数据报的数据部分应交给哪个特定的运输层协议。例如,值为6代表数据部分交给 TCP,值为17表明数据交给 UDP。在 IP 数据报中协议号所起的作用相当于运输层报文段中端口号字段所起的作用。协议号是将网络层与运输层绑定到一起,而端口号是将运输层和应用层绑定到一起。
-
首部检验和。首部检验和用于帮助路由器检测收到的 IP 数据报中的比特错误。首部检验和是这样计算的:将首部中的每 2个字节当做一个数,用反码算术对这些数求和。
路由器对每个收到的 IP 数据报计算其检验和,如果数据报首部中携带的检验和与计算得到的检验和不一致,则检测出是个差错并将其丢弃。分组到达的每台路由器上必须重新计算检验和并再次存放到原处。
运输层和网络层都有执行差错检测,这种重复检测有几种原因。首先,IP 层只对 IP 首部计算了检验和,而 TCP/UDP 检验和是对整个 TCP/UDP 报文段进行的。其次,TCP/UDP 与 IP 不一定都必须属于同一个协议栈。原则上,TCP 能够运行在一个不同的协议(如ATM)上,而 IP 能够携带不一定要传递给 TCP/UDP 的数据。
-
源和目的 IP 地址。当某源生成一个数据报时,它在源 IP 字段中插入它的 IP 地址,在目的 IP 地址字段中插入其最终目的地的地址。通常源主机通过 DNS 查找来决定目的地址。
-
选项。选项允许IP首部被扩展。首部选项很少使用。首部选项非常影响在路由器上的处理,在 IPv6 首部中已去掉 IP 选项。
-
数据(有效载荷)。IP 数据报中的数据字段包含要交付给目的地的运输层报文段(TCP或UDP)。该数据报也可承载其他类型的数据,如 ICMP 报文。
一个 IP 数据报有总长为 20 字节的首部(假设无选项)。如果数据报承载一个 TCP 报文段,则每个数据报共承载了总长 40 字节的首部(20字节的 IP 首部加上20字节的TCP首部)以及应用层报文。
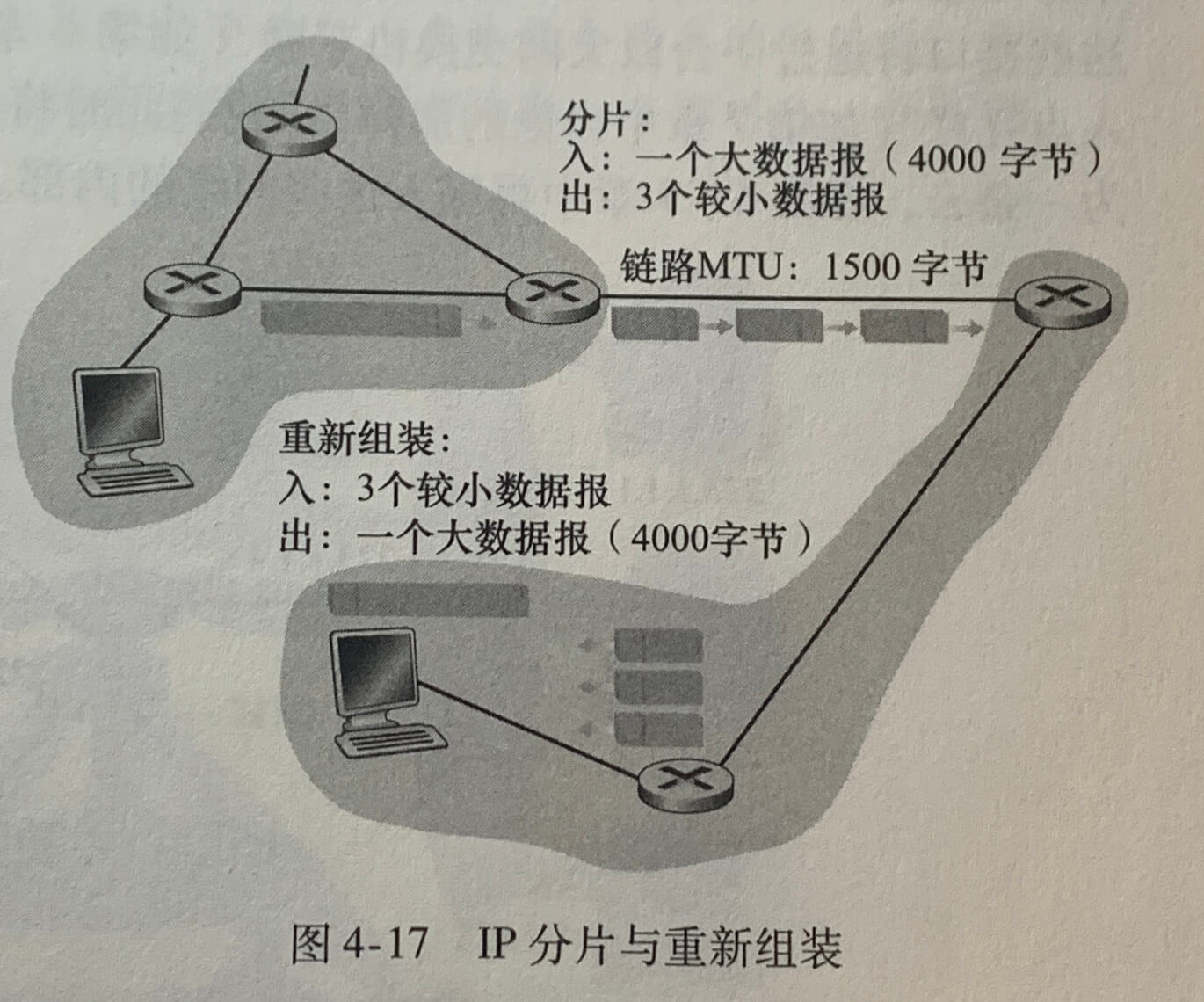
4.3.2 IPv4 数据报分片
并不是所有链路层都能承载相同长度的网络层分组。有的协议能承载大数据报,而有的协议只能承载小分组。一个链路层帧能承载的最大数据量叫做最大传送单元(Maximum Transmission Unit,MTU)。链路层协议的 MTU 严格地限制着 IP 数据报的长度。每种链路层协议可能具有不同的 MTU。
将过大的 IP 数据报挤进链路层帧的有效载荷字段的办法是将 IP 数据报中的数据分片成两个或更多个较小的 IP 数据报,用单独的链路层帧封装这些较小的 IP 数据报,然后通过输出链路发送这些帧。每个这些较小的数据报都称为片(fragment)。
片在其到达目的地运输层以前需要重新组装。IPv4 将数据报的重新组装工作放到端系统中,而没有放到网络路由器中,这是因为组装对路由器的性能影响较大。
当一台目的主机从相同源收到一系列数据报时,它需要确定这些数据报中的某些是否是一些原来较大的数据报的片。如果这些数据报是片的话,则它必须进一步确定何时收到最后一片,并且如何将这些接收到的片拼接到一起以形成初始的数据报。为了让目的主机执行这些重新组装任务,IPv4 的设计者将标识(identification)、标志和片偏移字段放在 IP 数据报首部中。
当生成一个数据报时,发送主机在为该数据报设置源和目的地址的同时贴上标识号。发送主机通常将它发送的每个数据报的标识号加1。当某路由器需要对一个数据分片时,形成的每个片具有初始数据报的源地址、目的地址与标识号。当目的地从同一发送主机收到一系列数据报时,它能够检查数据报的标识号以确定哪些数据报实际上是同一较大数据报的片。为了让目的主机确信它收到了初始数据报的最后一个片,最后一个片的标志被设置为0,而所有其他片的标志比特被设为1。为了让目的主机确定是否丢失了一个片,使用偏移字段指定该片应放在初始 IP 数据报的哪个位置。
4.3.3 IPv4编址
一台主机通常只有一条链路连接到网络;当主机的 IP 想发送一个数据报时,它就在该链路上发送。主机与物理链路之间的边界叫做接口(interface)。
路由器的任务是从链路上接收数据报并从某些其他链路转发出去,路由器必须拥有两条或更多条链路与它连接。路由器与它的任意一条链路之间的边界也叫做接口。一台路由器有多个接口,每个接口有其链路。因为每台主机与路由器都能发送和接收 IP 数据报,IP 要求每台主机和路由器接口拥有自己的 IP 地址。因此,从技术上讲,一个 IP 地址与一个接口相关联,而不是与包括该接口的主机或路由器相关联。
每个 IP 地址长度为 32 比特(等价为4字节),因此共有大约40亿个可能的 IP 地址。这些地址通常按所谓**点分十进制记法(dotted-decimal notation)**书写,即地址中的每个字节用它的十进制形式书写。例如:192.32.216.9。
在全球因特网中的每台主机和路由器上的每个接口,都必须有一个全球唯一的 IP 地址。然而,这些地址不能随意地自由选择。一个接口的 IP 地址的一部分需要由其连接的子网来决定。

上图中,最左侧的4个接口通过一个并不包含路由器的网络互联起来,该网络可能由一个以太网 LAN 互联,或者通过一个无线接入点互联。用 IP 术语来说,互联这3个主机接口与1个路由器接口的网络形成一个子网(subnet)。IP地址为这个子网分配了一个地址 223.1.1.0/24,其中的 /24 记法,有时称为子网掩码(network mask),指示 32 比特中的最左侧 24 比特定义了子网地址。因此子网 233.1.1.0/24 由 3 个主机接口和 1 个路由器接口(223.1.1.4)组成。任何其他要连到 223.1.1.0/24 网络的主机都要求其地址具有 223.1.1.xxx 的形式。图中还有 223.1.2.0/24 网络和 233.1.3.0/24 子网。

一个子网的 IP 定义并不局限于连接多台主机到一个路由器接口的以太网段。

上图中显示了3台通过点对点链路彼此互联的路由器,每台路由器有3个接口,每条点对点链路使用一个,一个用于直接将路由器连接到一对主机的广播链路。这里一共有6个子网,分别为 223.1.1.0/24 、 223.1.2.0/24 、 223.1.3.0/24 、 223.1.9.0/24 用于连接路由器 R1与R2的接口、 223.1.8.0/24 、223.1.7.0/24
子网定义:为了确定子网,分开主机和路由器的每个接口,产生几个隔离的网络岛,使用接口端接这些隔离的网络的端点。这些隔离的网络中的每一个都叫做一个子网(subnet)。
一个具有多个以太网段和点对点链路的组织(公司或学术机构)将具有多个子网,在给定子网上的所有设备都具有相同的子网地址。
因特网的地址分配策略被称为无类别域间路由选择(Classless Interdomain Routing,CIDR)。
当使用子网寻址时,32比特的 IP 地址被划分为两部分,并且也具有点分十进制数形式a.b.c.d/x,其中x指示了地址的第一部分中的比特数。形式为a.b.c.d/x的地址的 x 最高比特构成了 IP 地址的网络部分,并且经常被称为该地址的前缀(prefix)。一个组织被分配一块连续的地址,即具有相同前缀的一段地址,在这种情况下,该组织内部的设备的 IP 地址将共享共同的前缀。

上图中一个 ISP 将8个组织连接到因特网,Fly-By-Night-ISP向外界通告,它应该发送所有地址的前20比特与 200.23.16.0/20 相符的数据报。外界不需要知道该地址块还存在8个其他组织(每个组织有自己的子网),这种使用单个网络前缀通告多个网络的能力通常称为地址聚合(address aggregation),也称为路由聚合(route aggregation)或路由摘要(route summarization)。

上图中,为了让组织1通过Fly-By-Night-ISP辅助的ISPs-R-Us与因特网相连,让ISPs-R-Us通告组织1的地址块200.23.18.0/23。
一个地址的剩余 32-x 比特可认为是用于区分该组织内部设备的,其中的所有设备具有相同的网络前缀。当该组织内部的路由器转发分组时,才会考虑这些比特。这些较低阶比特可能(或可能不)具有另外的子网结构。
在 CIDR 被采用之前,IP 地址的网络部分被限制为长度为8、16或24比特,这种被称为**分类编址(classful addressing)**的编址方案。具有8、16和24比特子网地址的子网分别被称为A、B和C类网络。一个IP地址的网络部分正好为1、2或3字节的要求,在支持数量迅速增加的具有小规模或中等规模子网的组织方面出现了问题。一个C类(/24)子网技能容纳 2 8 − 2 = 254 2^8-2=254 28−2=254 台主机,这对于许多组织来说太小了。一个B类(/16)子网可支持多达 65534 台主机。分类编制的缺点:比方说一个有2000台主机的组织通常被分给一个B类地址,这就导致B类地址空间的迅速损耗以及所分配的地址空间的利用率低下,因为剩下的超过63000个地址却不能被其他组织使用。
IP 广播地址 255.255.255.255,当一台主机向该地址发送数据报时,该报文会交付给同一个网络中的所有主机。路由器也会有选择地向邻近的子网转发该报文。
1.获取一块地址
为了获取一块 IP 地址用于一个组织的子网内,某网络管理员首先会与他的 ISP 联系,该 ISP 可能会从已分给它的更大地址块中提供一些地址。ISP 向因特网名字和编号分配机构(Internet Corporation for Assigned Names and Numbers,ICANN)获取地址块。非营利的 ICANN 组织的作用不仅是分配 IP 地址,还管理 DNS 根服务器。ICANN 向区域性因特网注册机构(如 ARIN、RIPE、APNIC 和 LACNIC)分配地址,这些机构处理本区域内的地址分配/管理。
2.获取主机地址:动态主机配置协议
某组织一旦获得了一块地址,它就可为本组织内的主机与路由器接口逐个分配 IP 地址。系统管理员通常手工配置路由器中的 IP 地址。主机地址也能手动配置,但是这项任务目前更多的是使用动态主机配置协议(Dynamic Host Configuration Protocol,DHCP)来完成。DHCP 允许主机自动获取(被分配)一个 IP 地址。网络管理员能够配置 DHCP,以使某给定主机每次与网络连接时能得到一个相同的 IP 地址,或者某主机将被分配一个临时的 IP 地址(temporary IP address),每次与网络连接时该地址也许是不同的。除了主机 IP 地址分配外,DHCP 还允许一台主机得知其他信息,例如它的子网掩码、它的第一跳路由器(常称为默认网关)与它的本地 DNS 服务器的地址。
DHCP具有将主机连接进一个网络的网络相关方面的自动能力,故被称为即插即用协议或零配置协议。DHCP 还广泛地用于住宅因特网接入网、企业网与无线局域网中,其中的主机频繁地加入和离开网络。
DHCP 是一个客户- 服务器协议。客户通常是新到达的主机。在最简单场合下,每个子网都拥有一台 DHCP 服务器。如果某子网中没有服务器,则需要一个 DHCP 中继代理(通常是一台服务器),这个代理知道用于该网络的 DHCP 服务器的地址。
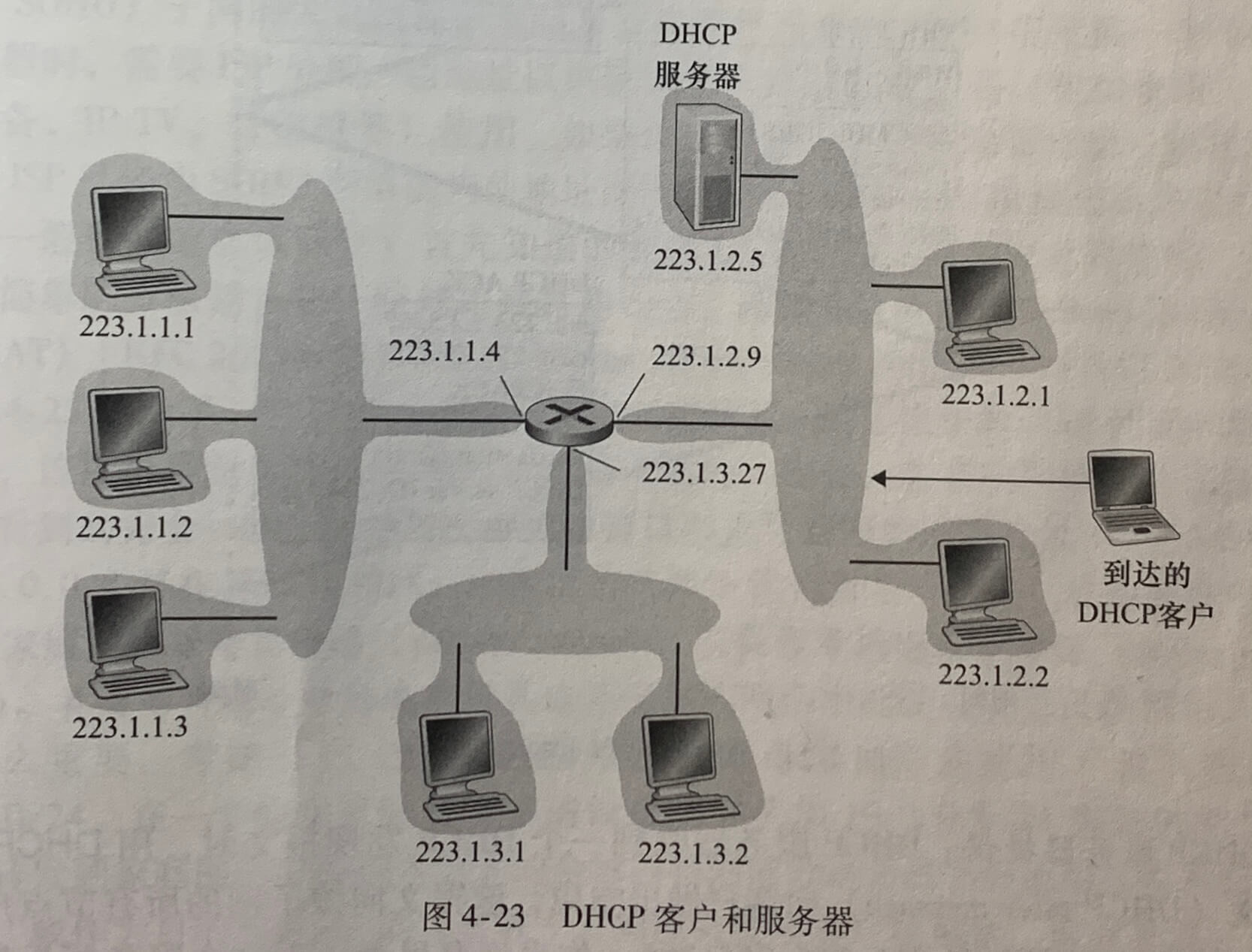
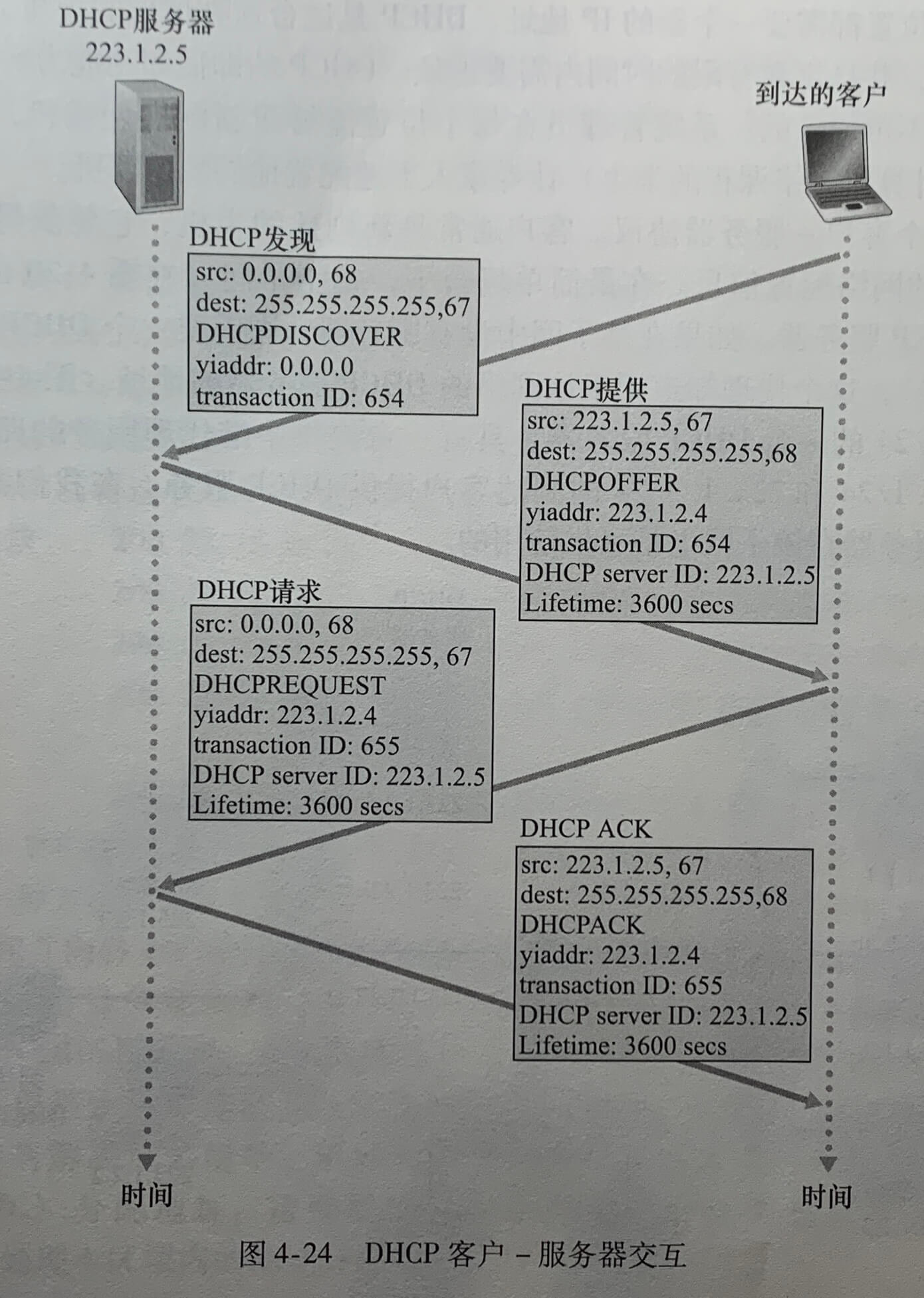
上图中,yiaddr指示分配给该新到达客户的地址。对于一个新到达的主机而言,DHCP 协议是一个4个步骤的过程:
- DHCP 服务器发现。一台新到达的主机的首要任务是发现一个要与其交互的 DHCP 服务器,通过使用**DHCP发现报文(DHCP discover message)**来完成,客户在 UDP 分组中向端口 67 发送该发现报文,该 UDP 分组封装在一个 IP 数据报中。使用广播目的地址 255.255.255.255 并使用“本主机”源地址 0.0.0.0。DHCP 客户将该 IP 数据报传递给链路层,链路层将该帧广播到所有与子网连接的节点。
- DHCP 服务器提供。DHCP 服务器收到一个 DHCP 发现报文时,用DHCP提供报文(DHCP offer message)向客户响应,该报文向该子网的所有结点广播(255.255.255.255)。因为在子网中可能存在几个 DHCP 服务器,该客户也许会发现它处于能在几个提供者之间进行选择的优越位置。每台服务器提供的报文包含有收到发现报文的事务 ID、向客户推荐的 IP 地址、网络掩码以及IP地址租用期(address lease time),即IP地址有效的时间量。服务器租用期通常设置为几小时或几天。
- DHCP 请求。新到达的客户从一个或多个服务器提供中选择一个,并向选中的服务器提供用**DHCP请求报文(DHCP request message)**进行响应,回显配置的参数。
- DHCP ACK。服务器用**DHCP ACK报文(DHCP ACK message)**对 DHCP请求报文响应,证实所要求的参数。
一旦客户收到 DHCP ACK 后,交互便完成,该客户能够在租用期内使用 DHCP 分配的 IP 地址。因为客户可能在该租用期超时后还希望使用这个地址,所以 DHCP 还提供了一种机制以允许客户更新它对一个 IP 地址的租用。
4.3.4 网络地址转换
随着小型办公室、家庭办公室(Small Office,Home Office,SOHO)子网的大量出现,意味着每当一个 SOHO 想安装一个 LAN 以互联多台设备时,需要 ISP 分配一组地址以供该 SOHO 的所有 IP 设备使用。如果该子网变大,则需要分配一块较大的地址,而如果 ISP 已经为 SOHO 网络的当前地址范围分配过一块连续地址,使用**网络地址转换(Network Address Translation,NAT)**可以解决这个问题。

上图中 10.0.0.0/24 这些地址用于家庭网络等专用网络(private network)或具有专用地址的地域(realm with private address)。具有专用地址的地域是指其地址仅对该网络中有意义的网络。在一个给定家庭网络中的设备能够使用 10.0.0.0/24 彼此发送分组,然而转发到家庭网络之外进入更大的全球因特网的分组显然不能使用这些地址,因为有数十万的网络使用着这块地址,所以 10.0.0.0/24 地址仅在给定的网络中才有意义。
NAT 使能路由器对于外部世界来说甚至不像一台路由器。相反 NAT 路由器对外界的行为就如同一个具有单一 IP 地址的单一设备。上图中,所有离开家庭路由器流向更大因特网的报文都拥有一个源 IP 地址 138.76.29.7,且所有进入家庭的报文都拥有同一个目的 IP 地址 138.76.29.7。NAT 使能路由器对外界隐藏家庭网络的细节。路由器从 ISP 的 DHCP 服务器得到它的地址,并且路由器运行一个 DHCP 服务器。
如果从广域网到达 NAT 路由器的所有数据报都有相同的目的 IP 地址,那么NAT 路由器通过一张NAT转发表来知道某个分组应转发给哪个内部主机。
上图中,10.0.0.1 的用户请求 128.119.40.186(80端口)上的一个 Web 页面,主机 10.0.0.1 为其指派了(任意)源端口号 3345 并将该数据报发送到 LAN 中。NAT路由器收到该数据报,为该数据报生成一个新的源端口号 5001,将源 IP 替代为其广域网一侧接口的 IP 地址 138.76.29.7,且将源端口 3345 更换为新端口 5001。当生成一个新的源端口号时,NAT 路由器可选择任意一个当前未在 NAT 转换表中的源端口号。(NAT 协议支持超过 60000 个并行使用路由器广域网一侧单个 IP 地址的连接)路由器中的 NAT 也在它的 NAT 转换表中增加一表项。Web 服务器并不知道刚到达的包含 HTTP 请求的数据报已被 NAT 路由器进行改装,它会发回一个响应报文,其目的地址是 NAT 路由器的 IP 地址,目的端口是 5001。当该报文到达 NAT 路由器时,路由器使用目的 IP 地址与目的端口号从 NAT 转换表中检索出家庭网络浏览器使用的适当 IP 地址(10.0.0.1)和目的端口号(3345)。路由器重写该数据报的目的 IP 地址与目的端口号,并向家庭网络转发该数据报。
NAT 已成为因特网的一个重要组件,成为所谓中间盒,它运行在网络层并具有与路由器十分不同的功能。中间盒并不执行传统的数据报转发,而是执行诸如 NAT、流量流的负载均衡、流量防火墙等功能。
关注安全性——检查数据报:防火墙和入侵检测系统
对抗恶意分组攻击的两种流行的防御措施是防火墙和入侵检测系统(IDS)。(今天大多数接入路由器具有防火墙能力。)防火墙检查数据报和报文段首部字段,拒绝可疑的数据报进入内部网络。防火墙也能基于源和目的 IP 地址以及端口号阻挡分组。此外,防火墙能够配置为跟踪 TCP 连接,仅许可属于批准连接的数据报进入。
IDS 能够提供另一种保护措施。IDS 通常位于网络的边界,执行“深度分组检查”,不仅检查数据报(包括应用层数据)中的首部字段,而且检查其有效载荷。IDS 具有一个分组特征数据库,这些特征是已知攻击的一部分。随着新攻击的发现,该数据库自动更新特征。当分组通过 IDS 时,IDS 视图将分组的首部字段和有效载荷与其特征数据库中的特征相匹配。如果发现了这样的一种匹配,就产生一个告警。入侵防止系统(IPS)与 IDS 类似,只是除了产生告警外还实际阻挡分组。
4.3.5 IPv6
在20世纪90年代早期,因特网工程任务组就开始致力于开发一种替代 IPv4 的协议。由于新的子网和 IP 节点以惊人的增长率连到因特网上(并被分配唯一的 IP 地址),32比特的 IP 地址空间即将用尽。为了应对这种对大 IP 地址空间的需求,开发了一种新的 IP 协议,即 IPv6。IPv4 地址在什么时候会被完全分配完是一个相当有争议的问题。
1. IPv6 数据报格式

IPv6 引入的最重要的变化显示在其数据报格式中:
- 扩大的地址容量。IPv6将 IP 地址长度从 32 比特增加到 128 比特。这就确保全世界将不会用尽 IP 地址。IPv6还引入了一种称为**任播地址(anycast address)**的新型地址,这种地址可以使数据报交付给一组主机中的任意一个,
- 简化高效的40字节首部。40 字节定长首部允许路由器更快地处理 IP 数据报。一种新的选项编码允许进行更灵活的选项处理。
- 流标签。该字段可以用于“给属于特殊流的分组加上标签,这些特殊流是发送方要求进行特殊处理的流,如一种非默认服务质量或需要实时服务的流”。
以下是 IPv6 中定义的字段:
- 版本。4比特字段用于标识 IP 版本号。
- 流量类型。8比特字段与 IPv4 中看到的 TOS(服务器类型)含义相似。
- 流标签。20比特的字段用于标识一条数据报的流,能够对一条流中的某些数据报给出优先权,或者它能够用来对来自某些应用(如 IP 语音)的数据报给出更高的优先权,以优于来自其他应用的数据报。
- 有效载荷长度。16比特作为一个无符号整数,给出了 IPv6 数据报中跟在定长的 40 字节数据报首部后面的字节数量。
- 下一个首部。该字段标识数据报中的内容(数据字段)需要交付给哪个协议(UDP 或 TCP)。
- 跳限制。转发数据报的每台路由器将对该字段的内容减1。如果跳限制计数达到0,则该数据报将被丢弃。
- 目的地址和源地址。
- 数据。IPv6 数据报的有效载荷部分。当数据报到达目的地时,该有效载荷就从 IP 数据报中移出,并交给下一个首部字段中指定的协议处理。
IPv4 数据报中出现的几个字段在 IPv6 数据报中已不复存在:
- 分片/重新组装。IPv6 不允许在中间路由器上进行分片与重新组装。这种操作只能在源与目的地执行。如果路由器收到的 IPv6 数据报因太大而不能转发出链路上的话,则路由器只需丢掉该数据报,并向发送方发回一个“分组太大”的 ICMP 差错报文即可。发送方重新使用较小长度的 IP 数据报重新发送。分片与重新组织是一个耗时的操作,该功能从路由器中删除并放到端系统中能大大加快网络中的 IP 转发速度。
- 首部检验和。因为因特网层中的运输层和数据链路层协议执行了检验操作,设计者觉得在网络层中该功能有些多余,IPv4 中每台路由器上都需要重新计算首部检验和,为了加快 IP 分组的快速处理,故去掉。
- 选项。选项在 IPv6 并没有消失,而是可能出现在由“下一个首部”指出的位置上。删除选项字段使得 IP 首部定长的40字节。
2.从 IPv4 到 IPv6 的迁移
IPv6 能向后兼容,但已部署的具有 IPv4 能力的系统不能够处理 IPv6 数据报,可以采用以下几种方法:
-
宣布一个标志日,指定某个日期和时间进行升级。
-
建隧道(tunneling)。
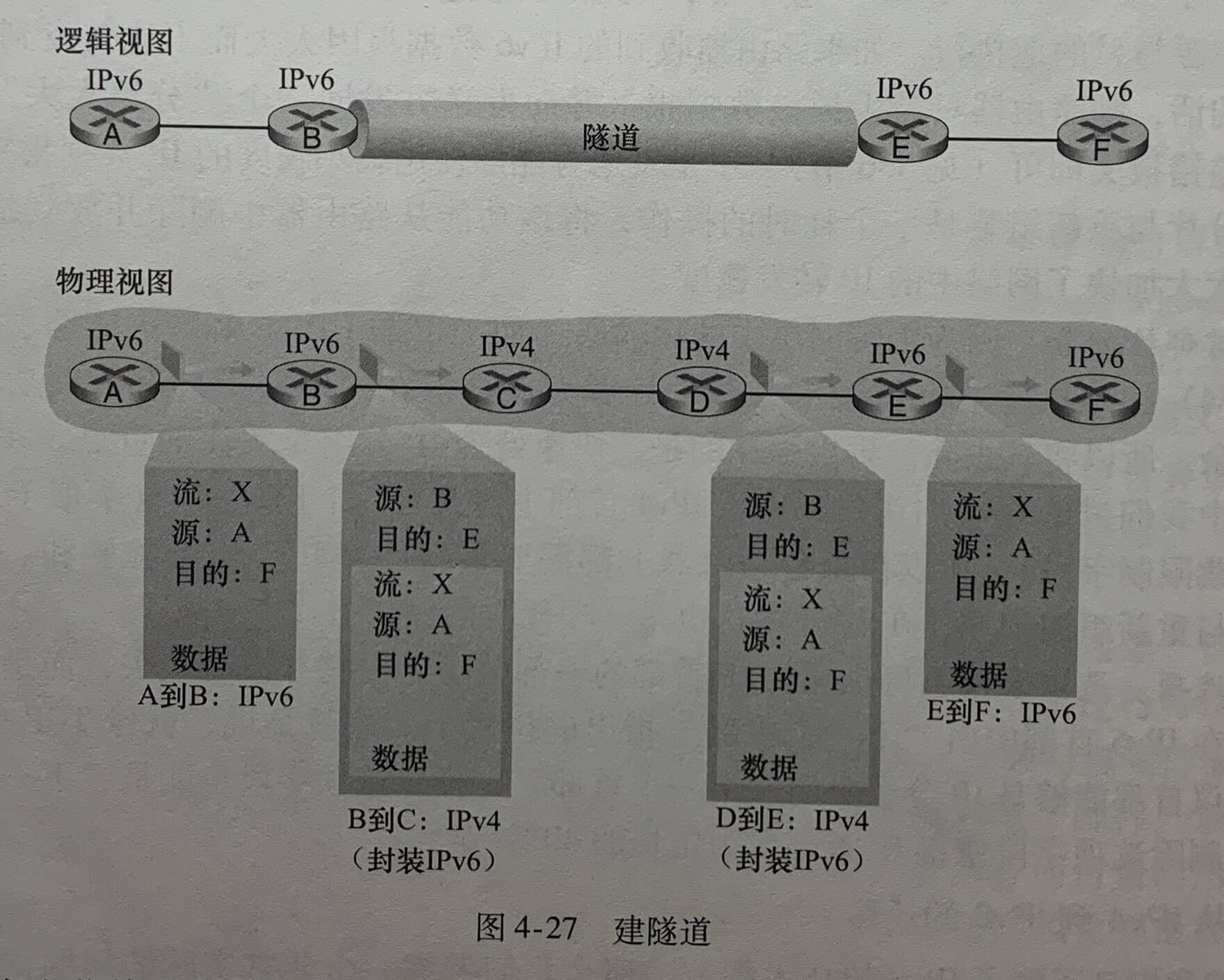
将两台 IPv6 路由器之间的中间 IPv4 路由器的集合称为一个隧道(tunnel)。借助于隧道,在隧道发送端的 IPv6 结点将整个 IPv6 数据报放到一个 IPv4 数据报的数据(有效载荷)字段中。该 IPv4 数据报的地址设为指向隧道接收端的 IPv6 结点,再发送给隧道的第一个节点。隧道中的中间 IPv4 路由器在它们之间为该数据报提供路由,就像对待其他数据报一样。隧道接收端的 IPv6 收到该 IPv4 数据报并确认该数据报含有 IPv6 数据报,从中取出然后再为该 IPv6 数据报提供路由。
更换网络层协议就如同更换一栋房子的地基,非常困难。而更换应用层协议如同给房子重新刷一层漆,这是相对容易的的事。
4.4 通用转发和SDN
匹配加动作范式,“动作”能够包含:将分组转发到一个或多个输出端口、跨越多个通向服务的离开接口进行负载均衡分组、重写首部值(像 NAT 一样)、有意识地阻挡/丢弃某个分组(像防火墙一样)、为进一步处理和动作向某个特定的服务器发送一个分组(像 DPI 一样)、等等。
在通用转发中,一张匹配加动作表将基于目的地的转发表一般化了。转发设备描述为“分组交换机”而不是第三层的“路由器”或第二层“交换机”。这是 SDN(软件定义网络)文献中被广泛采用的术语。

上图中,每台分组交换机包含一张匹配加动作表,该表由远程控制器计算、安装和更新。
匹配加动作转发表在 OpenFlow 中称为流表(flow table),它的每一个表项包括:
- 首部字段值的集合,入分组将与之匹配。
- 计数器集合(当分组与流表项匹配时更新计数器)。这些计数器可以包括已经与该表项匹配的分组数量,以及自从该表项上次更新依赖的时间。
- 当分组匹配流表项时所采取的动作集合。
4.4.1 匹配

上图显示了11个分组首部字段和入端口 ID,该 ID 能被 OpenFlow 1.0 中的匹配加动作规则所匹配。OpenFlow 的匹配抽象允许对来自三个层次的协议首部所选择的字段进行匹配。源 MAC 和目的 MAC 地址是与帧的发送和接收接口相关联的链路层地址;
入端口是指分组交换机上接收分组的输入端口。流表项也支持通配符形式,如 128.19.*.* 。并非所有的首部字段都能被匹配,这些与功能和复杂性有关。
4.4.2 动作
如果流表项有多个动作,那么将以表中规定的次序执行。其中最为重要的动作可能是:
- 转发。一个入分组可以转发到一个特定的物理输出端口,广播到所有端口,或通过所选的端口集合进行多播。
- 丢弃。
- 修改字段。在分组被转发到所选的输出端口之前,分组首部 10 个字段(除 IP 协议字段外的所有第二、三、四层的字段)中的值可以重写。
4.4.3 匹配加动作操作中的OpenFlow例子

第5章 网络层:控制平面
5.1 概述
4.1节已经讲述了转发表和流表的计算、维护和安装这些工作的两种可能的方法:
-
每路由器控制。每路由器控制的方法在因特网中已经使用了几十年。

-
逻辑集中式控制。控制器经一种良好的协议与每台路由器中的一个控制代理(CA)进行交互,以配置和管理该路由器的转发表。CA 一般具有最少的功能,其任务是与控制器通信并且按控制器命令行事。这些 CA 既不能直接相互交互,也不能主动参与计算转发表。这是每路由器控制和逻辑集中式控制之间的关键差异。

5.2 路由选择算法
路由选择算法(routing algorithm),其目的是从发送方到接收方的过程中确定一条通过路由器网络的好的路径(等价于路由)。通常,一条好路径指具有最低开销的路径。

路由选择算法的目标是找出从源到目的地间的最低开销路径。最短路径(shortest path),即在源和目的地之间的具有最少链路数量的路径。
路由选择算法的一种分类方式是根据该算法是集中式还是分散式来划分:
- 集中式路由选择算法(centralized routing algorithm)用完整的、全局性的网络知识计算出从源到目的地之间的最低开销路径。该算法以所有节点之间的连通性及所有链路的开销为输入。集中式算法具有关于连通性和链路开销方面的完整信息。具有全局状态信息的算法被称作链路状态(Link State,LS)算法,因为该算法必须知道网络中每条链路的开销。
- 分散式路由选择算法(decenteralized routing algorithm),路由器以迭代、分布式的方式计算出最低开销路径。没有节点拥有关于所有网络链路开销的完整信息。相反,每个节点仅有与其直接相连链路的开销知识即可开始工作。通过迭代计算过程以及与相邻节点的信息交换,一个节点逐渐计算出到达某目的节点或一组目的节点的最低开销路径。一个称为距离向量(Distance-Vector,DV)算法的分散式路由选择算法,每个节点维护到网络中所有其他节点的开销(距离)估计的向量。通过相邻路由器之间交互式报文交换,适合于那些路由器直接交互的控制平面。
路由选择算法的第二种分类根据算法是静态的还是动态的进行分类。在**静态路由选择算法(static routing algorithm)**中,路由随时间的变化非常缓慢,通常是人工进行调整(如人为手工编辑一条链路开销)。**动态路由选择算法(dynamic routing algorithm)**随着网络流量负载或拓扑发生变化而改变路由器选择路径。一个动态算法可周期性地运行或直接响应拓扑或链路开销的变化而运行。
路由选择算法的第三种分类方式是根据它是负载敏感还是负载迟钝进行划分。在负载敏感算法(load-sensitive algorithm)中,链路开销会动态地变化以反映出底层链路的当前拥塞水平。如果当前拥塞的一条链路与高开销相联系,则绕开该拥塞链路来选择路由。早期的 ARPAnet 路由选择算法就是负载敏感的,所以遇到了许多难题。当今的因特网路由器选择算法(如 RIP、OSPF 和 BGP)都是负载迟钝的(load-insensitive),因为某条链路的开销不明确地反应其当前(或最近)的拥塞水平。
5.2.1 链路状态路由选择算法
在链路状态算法中,网络拓扑和所有的链路开销都是已知的。每个节点向网络中所有其他节点广播链路状态分组来完成的,其中每个链路状态分组包含它所连接的链路的标识和开销。这经常是由链路状态广播(link state broadcast)算法来完成。节点广播的结果是所有节点都具有该网络的统一、完整的视图。于是每个节点都能够像其他节点一样,运行 LS 算法并计算出相同的最低开销路径集合。

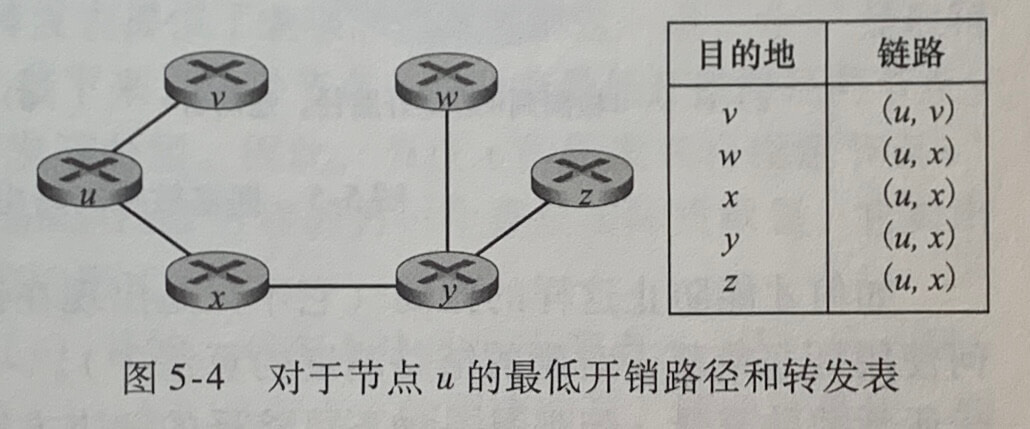
当 LS 算法终止时,对于每个节点,我们都得到从源节点沿着它的最低开销路径的前一节点。对于每一前一节点,我们又有它的前一节点,以此方式我们可以构建从源节点到所有目的节点的完整路径。通过对每个目的节点存放从u到目的地的最低开销路径上的下一跳节点,在一个节点中的转发表则能够根据此信息而构建。
5.2.2 距离向量路由选择算法
**距离向量(Distance-Vector,DV)**算法是一种迭代的、异步的和分布式的算法,而 LS 算法是一种使用全局信息的算法。
(分布式)每个节点都要从一个或多个直接相连邻居接收某些信息,执行计算,然后将其计算结果分发给邻居。(迭代)此过程一直要持续到邻居之间无更多信息要交换为止。(异步)不要求所有节点相互之间步伐一致地操作。
节点具有的唯一信息是它到直接相连邻居的链路开销和它从邻居接收到的信息。每个节点等待来自任何邻居的更新,当接收到一个更新时计算它的新距离向量并向它的邻居分布其新距离向量。在实践中许多类似 DV 的算法被用于多种路由协议中,包括因特网的 RIP 和 BGP、ISO IDRP、Novell IPX 和早期的 ARPAnet。
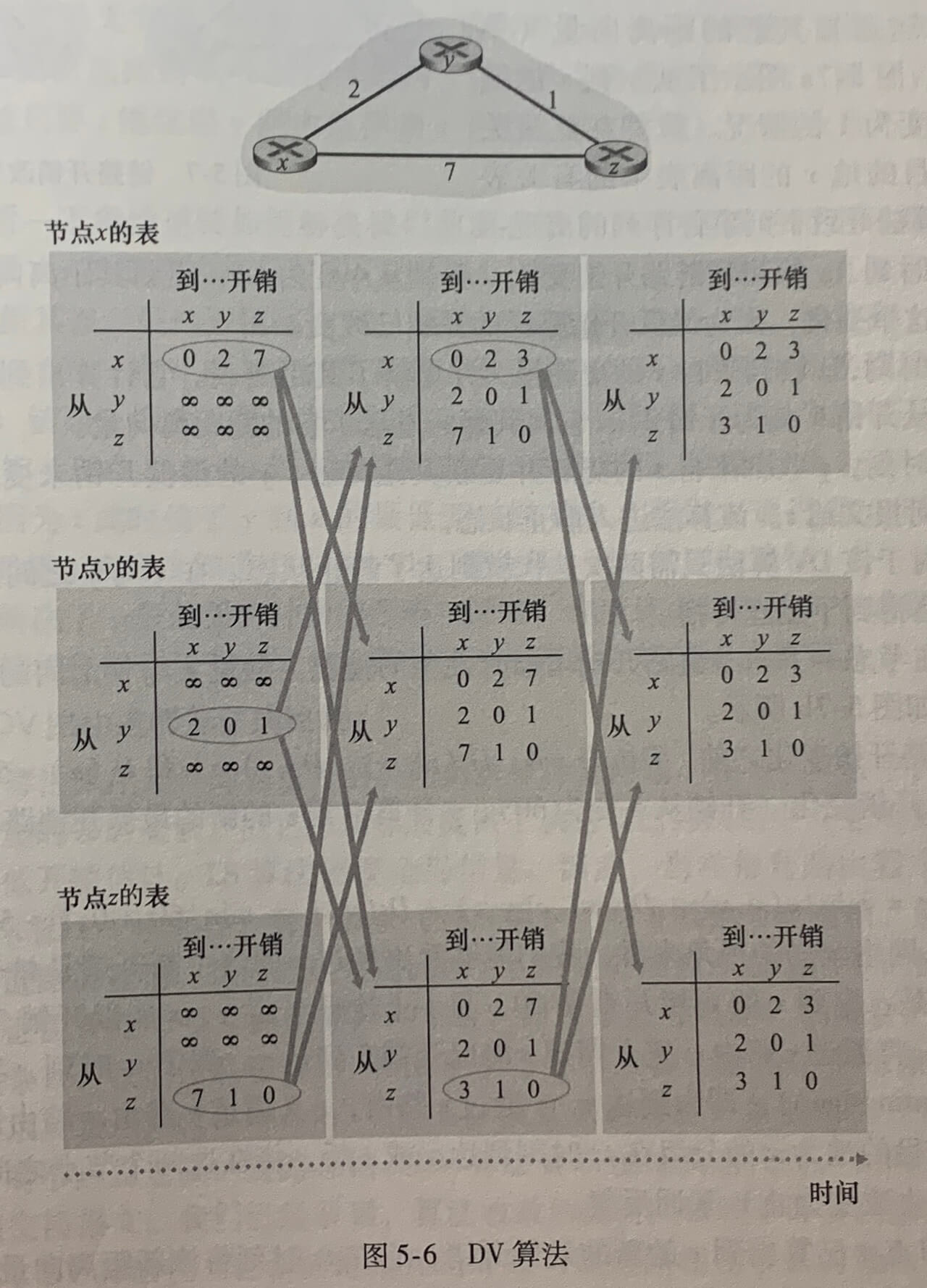
上图中,最左边一列显示了这3个节点各自的初始路由选择表。如左上角的节点x的路由选择表,该表的第二三行表示最近从节点y和z收到的距离向量。初始化后,每个节点向它的两个邻居发送其距离向量。在接收到该更新后,每个节点重新计算它自己的距离向量。在节点重新计算它们的距离向量后,它们再次向其邻居发送它们的更新的距离向量
1.距离向量算法:链路开销改变与链路故障
当一个运行 DV 算法的节点检测到从它自己邻居的链路开销发生变化时,它就更新其距离向量,并且如果最低开销路径的开销发生了变化,向邻居通知其新的距离向量。
2.距离向量算法:增加毒性逆转
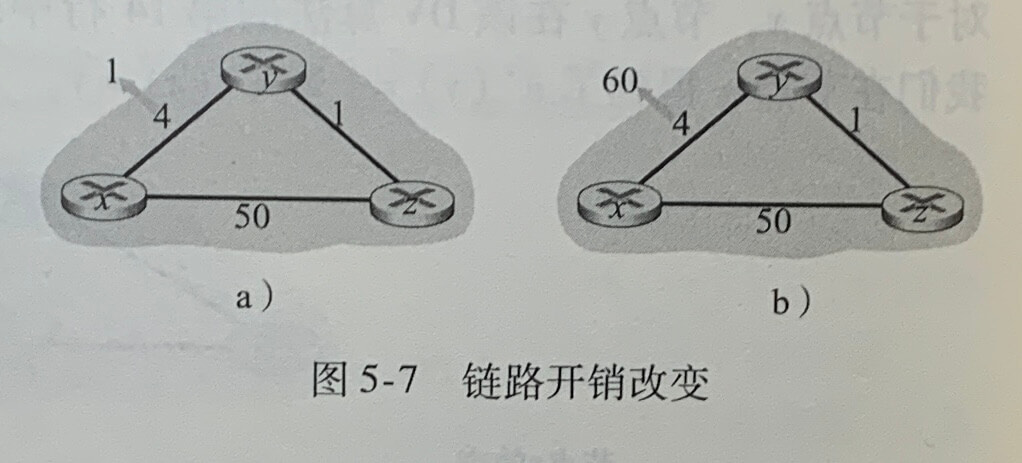
上图b中,当链路的开销增大时,在t0时刻,将出现z到y的路由选择环路(routing loop),即y想通过z到x,而z又通过y路由。此过程还会出现无穷技术问题。
为了解决该问题,可以使用毒性逆转技术加以避免,如果z通过y路由选择到目的地x,则z通告y它到x的距离是无穷大,此时y将不会通过z到达x。当涉及到3个或更多节点时,将无法用毒性逆转检测到。
3.LS 与 DV 路由选择算法的比较
DV 和 LS 算法采用互补的方法来解决路由选择计算问题。在 DV 算法中,每个节点仅与它的直接相连的邻居交谈,但它为邻居提供了从它自己到网络中(它所知道的)所有其他节点的最低开销估计。LS 算法需要全局信息。当在每台路由器中实现时,每个节点经广播与所有其他节点通信,但仅告诉他们与它直接相连链路的开销。
两个算法没有一个是明显的赢家,他们的确都在因特网中得到了应用。
5.3 因特网中自治系统内部的路由选择:OSPF
- 规模。随着路由器数目变得很大,涉及路由选择信息的通信、计算和存储的开销将高得不可实现。在所有路由器之间广播连通性和链路开销更新所要求的负担是巨大的。在如此大量的路由器中迭代的距离向量DV算法将永远无法收敛。
- 管理自制。因特网是 ISP 的网络,其中每个 ISP 都有它自己的路由器网络。ISP 通常希望按自己的意愿运行路由器,或对外部隐藏其网络的内部组织面貌。
这两个问题都可以通过将路由器组织进**自治系统(Autonomous System,AS)**来解决,每个 AS 由一组通常处在相同管理控制下的路由器组成。通常在一个 ISP 中的路由器以及互联它们的链路构成一个 AS。然而也有某些 ISP 将它们的网络划分为多个 AS。一个自治系统由其全局唯一的 AS 号(ASN)所标识。就像 IP 地址那样,AS 号由 ICANN 区域注册机构所分配。
在相同 AS 中的路由器都运行相同的路由选择算法并且有彼此的信息。在一个自治系统内部运行的路由选择算法叫做自治系统内部路由选择协议(intra-autonomous system routing protocol)。
**开放最短路径优先(OSPF)**路由选择及其关系密切的协议 IS-IS 都被广泛用于因特网的 AS 内部路由选择。OSPF 中路由选择协议规范是公众可用的。
OSPF 是一种链路状态协议,它使用洪泛链路状态信息和 Dijkstra 最低开销路径算法。使用 OSPF,一台路由器构建了一幅关于整个自治系统的完整拓扑图。每台路由器在本地运行 Dijkstra 的最短路径算法,以确定一个以自身为根结点到所有子网的最短路径树。各条链路开销是由网络管理员配置的。
使用 OSPF 时,路由器向自治系统内所有其他路由器广播路由选择信息,而不仅仅是向其相邻路由器广播。每当一条链路的状态发生变化是(如开销的变化或连接/中断状态的变化),路由器就会广播链路状态信息。即使链路状态未发生变化,它也要周期性地广播链路状态。
OSPF 的优点有以下:
- 安全。使用鉴别,仅有受信任的路由器能参与一个 AS 内的 OSPF 协议,因此可以防止恶意入侵者将不正确的信息注入路由器表中。鉴别分为两类,简单的和 MD5 的。简单鉴别是以明文方式包括口令,并不是非常安全。MD5 鉴别基于配置在所有路由器上的共享秘密密钥。对发送的每个 OSPF 分组附加秘密密钥的 OSPF 分组内容计算 MD5 散列值。路由器收到分组后,使用预配置的秘密密钥计算出该分组的 MD5 散列值,并与该分组携带的散列值进行比较,验证该分组的真实性。
- 多条相同开销的路径。当到达某目的地的多条路径具有相同的开销时,OSPF 允许使用多条路径。
- 对单播与多播路由选择的综合支持。多播 OSPF 提供对 OSPF 的简单扩展,以便提供多播路由选择。MOSPF 使用现有的 OSPF 链路数据库,并为现有的 OSPF 链路状态广播机制增加了一种新型的链路状态通告。
- 支持在单个 AS 中的层次结构。一个 OSPF 自治系统能够层次化地配置多个区域。每个区域都运行自己的 OSPF 链路状态路由选择算法,区域内的每台路由器都向该每个区域都运行自己的 OSPF 链路状态路由选择算法,区域内的每台路由器都向该区域内的所有其他路由器广播其链路状态。在每个区域内,一台或多台区域边界路由器负责为流向区域以外的分组提供路由选择。在 AS 中只有一个 OSPF 区域配置成主干区域。主干区域的主要作用是为该 AS 中其他区域之间的流量提供路由选择。该主干总是包含本 AS 中的所有区域边界路由器,并且可能还包含一些非边界路由器。在 AS 中的区域间的路由选择要求分组先路由到一个区域边界路由器,然后通过主干路由到位于目的区域边界路由器,进而再路由到最终目的地。
5.4 ISP之间的选择:BGP
自治系统间路由选择协议(inter-autonomous system routing protocol)涉及多个 AS 之间的协调,所以 AS 通信必须运行相同的 AS 间路由选择协议。在因特网中,所有的 AS 运行相同的 AS 间路由选择协议,称为边界网关协议(Border Gateway Protocol,BGP)
BGP 是所有因特网中最为重要的,因为正是这个协议将因特网中数以千计的 ISP 黏合起来。BGP 是一种分布式和异步的协议。
5.4.1 BGP 的作用
对位于相同 AS 中的目的地而言,在路由器转发表中的表项由 AS 内部路由选择协议所决定,对于位于该 AS 外部的目的地则使用 BGP 来处理。
在 BGP 中,分组并不是路由到一个特定的目的地址,相反是路由到 CIDR(无类别域间路由选择)化的前缀,每个前缀表示一个子网或一个子网的集合。在 BGP 的世界中,一个目的地可以采用如 138.16.68/22 的形式。
作为一种 AS 间的路由选择协议,BGP 为每台路由器提供了一种完成以下任务的手段:
- 从邻居 AS 获得前缀的可达性信息。BGP 允许每个子网向因特网的其余部分通告它的存在。BGP 确保在因特网中的所有 AS 知道该子网。
- 确定到该前缀的“最好的”路由。为了确定最好的路由,该路由器将本地运行一个 BGP 路由选择过程。
5.4.2 通告 BGP 路由信息
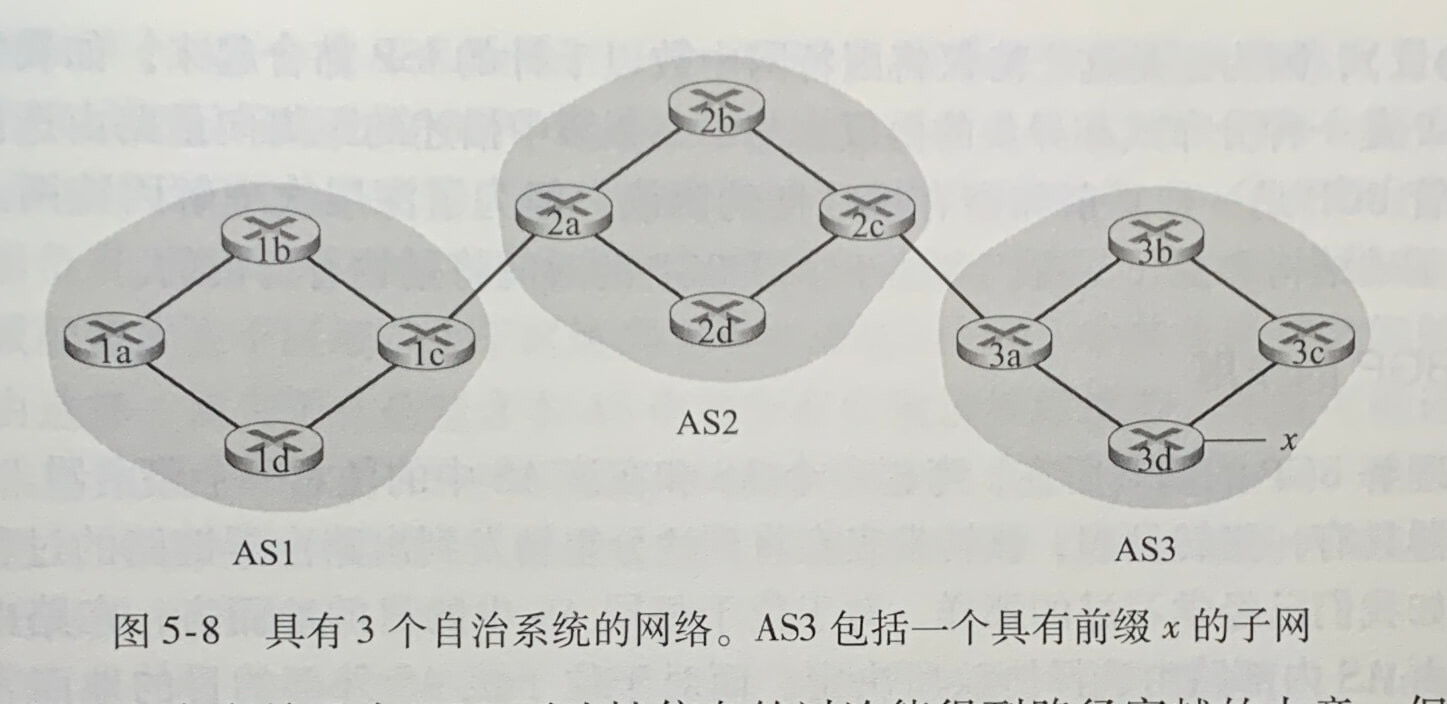
如上图,AS3 包括一个具有前缀x的子网。对于每个 AS,每台路由器要么是一台网关路由器(gateway router),要么是一台内部路由器(internal router)。网关路由器是一台位于 AS 边缘的路由器,它直接连接到在其他 AS 中的一台或多台路由器。内部路由器仅连接在它自己 AS 中的主机和路由器。例如,在 AS1 中路由器 1c 是网关路由器,1a、1b 和 1d 是内部路由器。

在 BGP 中,每对路由器通过使用 179 端口的半永久 TCP 连接交换路由选择信息。每条直接连接以及所有通过该连接发送的 BGP 报文,称为BGP连接(BGP connection)。此外,跨越两个 AS 的 BGP 连接称为**外部BGP(eBGP)连接,而在相同 AS 中的两台路由器之间的 BGP 会话称为内部BGP(iBGP)**连接。
5.4.3 确定最好的路由
因特网中的路由器常常接收到很多不同的可能路径的可达性信息。接下来讨论一台路由器如何在这些路径之间进行选择。
当路由器通过 BGP 连接通告前缀时,它在前缀中包括一些BGP属性(BGP attribute)。前缀及其属性称为路由(route)。AS-PATH 属性包含了通告已经通过的 AS 的列表,为了生成 AS-PATH 的值,当一个前缀通过某 AS 时,该 AS 将其 ASN 加入 AS-PATH 中的现有列表。BGP 路由器还使用 AS-PATH 属性来检测和防止通告环路;
NXET-HOP 是 AS-PATH 起始的路由器接口的 IP 地址。
1.热土豆路由选择

热土豆路由选择依据的思想是:尽可能快地将分组送出其 AS,而不担心其 AS 外部到目的地余下部分的开销。
2.路由器选择算法
在实践中,BGP 使用了一种比热土豆路由选择更为复杂但却结合了其特定的算法。
- 路由被指派一个**本地偏好(local preference)**值作为其属性之一。一条路由的本地偏好可能由该路由器设置或可能由在相同 AS 中的另一台路由器学习到。本地偏好属性的值是一种策略决定,它完全取决于该 AS 的网络管理员。
- 从余下的路由中(所有都具有相同的最高本地偏好值),将选择具有最短 AS-PATH 的路由。
- 从余下的路由中(所有都具有相同的最高本地偏好值和相同的 AS-PATH 长度),使用热土豆路由选择,即选择具有最靠近 NEXT-HOP 路由器的路由。
- 如果仍留下多条路由,该路由器使用 BGP 标识符来选择路由。
5.4.4 IP任播
除了作为因特网的 AS 间路由选择协议外,BGP 还常被用于实现 IP 任播(anycast)服务,该服务通常用于 DNS 中。
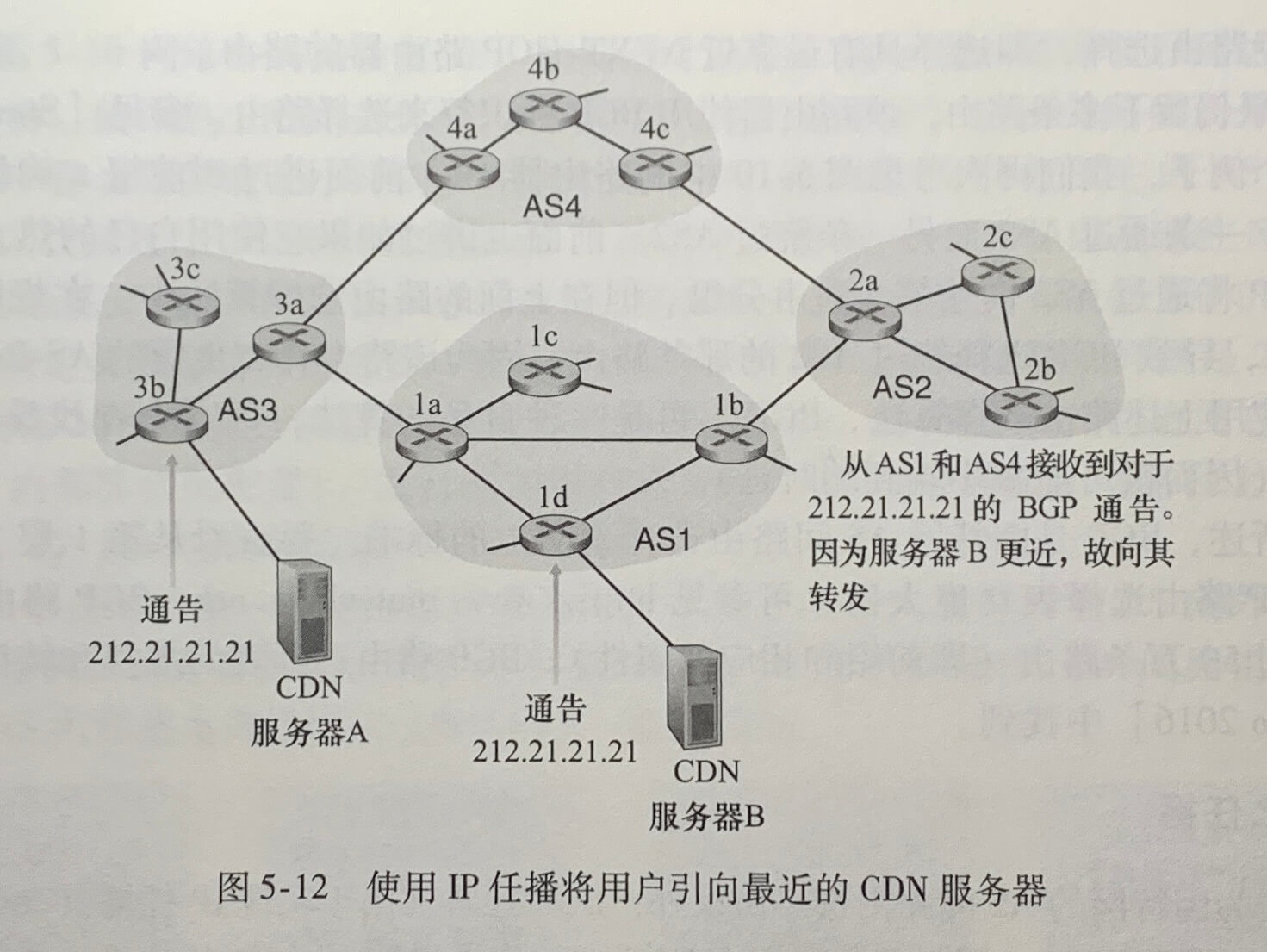
在 IP 任播配置阶段,CDN 公司为它的多台服务器指派相同的 IP 地址,并且使用标准的 BGP 从这些服务器的每台来通告该 IP 地址。当某台 BGP 路由器收到对于该 IP 地址的多个路由通告,它将这些通告处理为对相同的物理位置提供不同的路径。当配置其路由选择表时,每台路由器将本地化地使用 BGP 路由选择算法来挑选到该 IP 地址的“最好的”路由。
实践中 CDN 通常选择不使用 IP 任播,因为 BGP 路由选择变化能够导致相同的 TCP 连接的不同分组到达 Web 服务器的不同实例。但 IP 任播被 DNS 系统广泛用于将 DNS 请求指向最近的根 DNS 服务器。当前根 DNS 服务器有13个 IP 地址。但对应于这些地址的每一个,有多个 DNS 根服务器,其中有些地址具有 100 多个 DNS 根服务器分散在世界各个角落。
5.4.5 路由选择策略
为什么会有不同的 AS 间和 AS 内部路由选择协议?
该问题的答案触及了 AS 内与 AS 间的路由选择目标之间差别的本质:
- 策略。一个给定 AS 产生的流量不能穿过另一个特定的 AS。
- 规模。在一个 AS 内,可扩展性不是关注的焦点。
- 性能。由于 AS 间路由选择是面向策略的,因此所有路由的质量通常是次要关心的问题。
5.4.6 拼装在一起:在因特网中呈现
一台路由器从 BGP 知道了通往某个 IP 地址(比如你公司)的前缀。具体而言,当你的公司与本地 ISP 签订合同并且获得了分配的前缀(即一个地址范围),你的本地 ISP 将使用 BGP 向与之连接的 ISP 通告你的前缀。这些 ISP 将依次使用 BGP 来传播该通告。最终,所有的因特网路由器将得知你的前缀。
5.5 SDN控制平面
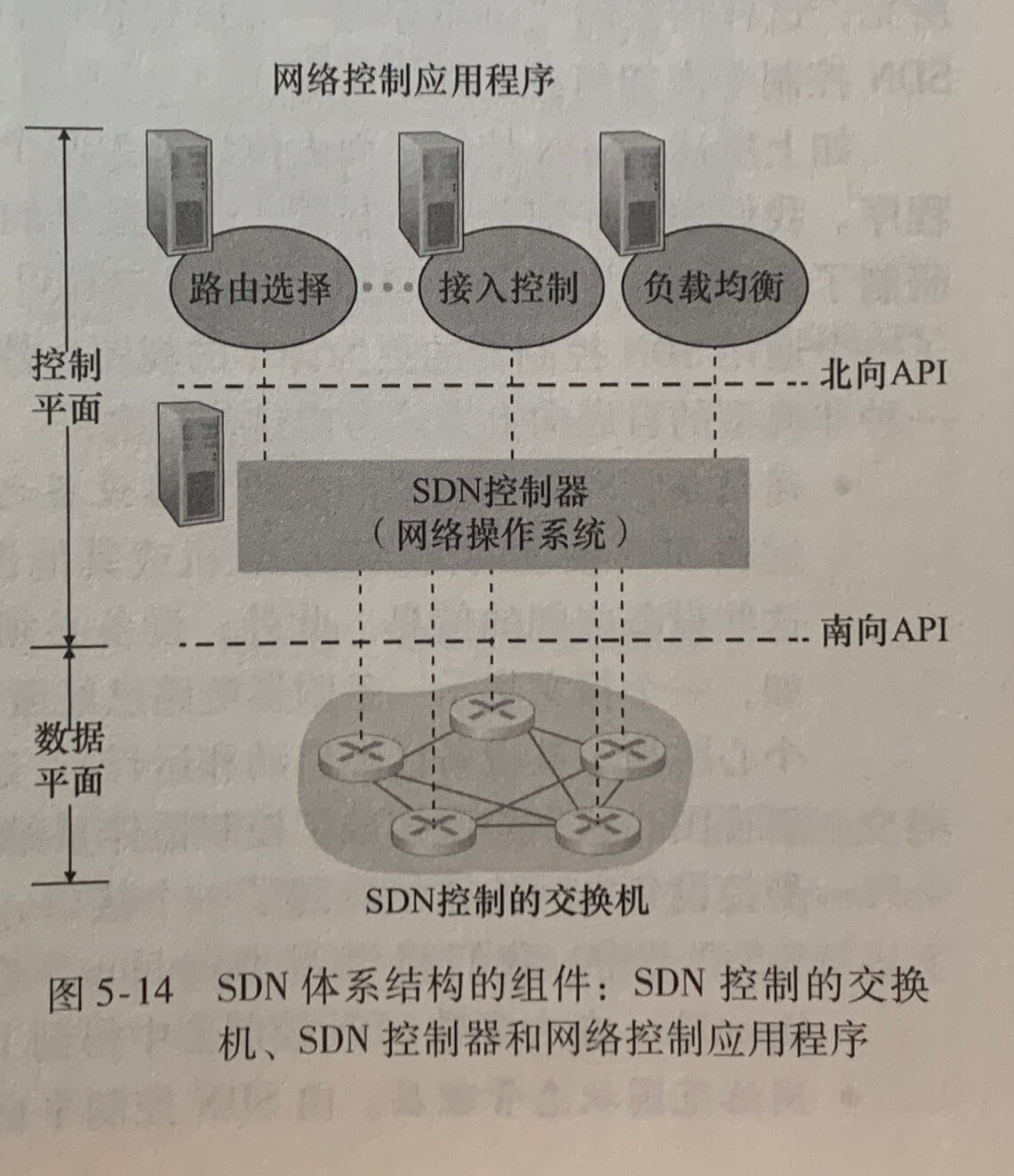
SDN 体系结构具有 4 个关键特征:
- 基于流的转发。SDN 控制的交换机的分组转发工作,能够基于运输层、网络层或链路层首部中任意数量的首部字段值进行。传统方法中 IP 数据报的转发仅依据数据报的目的 IP 地址进行。分组转发规则被精确规定在交换机的流表中;SDN 控制平面的工作是计算、管理和安装所有网络交换机中的流表项。
- 数据平面与控制平面分离。数据平面由网络交换机组成,交换机是相对简单的设备,该设备在他们的流表中执行“匹配加动作”的规则。控制平面由服务器以及决定和管理交换机流表的软件组成。
- 网络控制功能:位于数据平面交换机外部。与传统的路由器不同,软件在服务器上执行,该服务器与网络交换机截然分开且与之远离。如上图,控制平面自身由两个组件组成:一个 SDN 控制器,以及若干网络控制应用程序。控制器维护准确的网络状态信息(例如,远程链路、交换机和主机的状态);为运行在控制平面中的网络控制应用程序提供这些信息;提供方法,这些应用程序通过这些方法能够监视、编程和控制下面的网络设备。
- 可编程的网络。通过运行在控制平面中的网络控制应用程序,该网络是可编程的。这些应用程序代表 SDN 控制平面的“智力”。
SDN 表示了一种意义重大的网络功能的“分类”,即数据平面交换机、SDN 控制器和网络控制应用程序是分离的实体,该实体可以由不同的产商和组织机构所提供。
5.5.1 SDN 控制平面:SDN 控制器和 SDN 网络控制应用程序
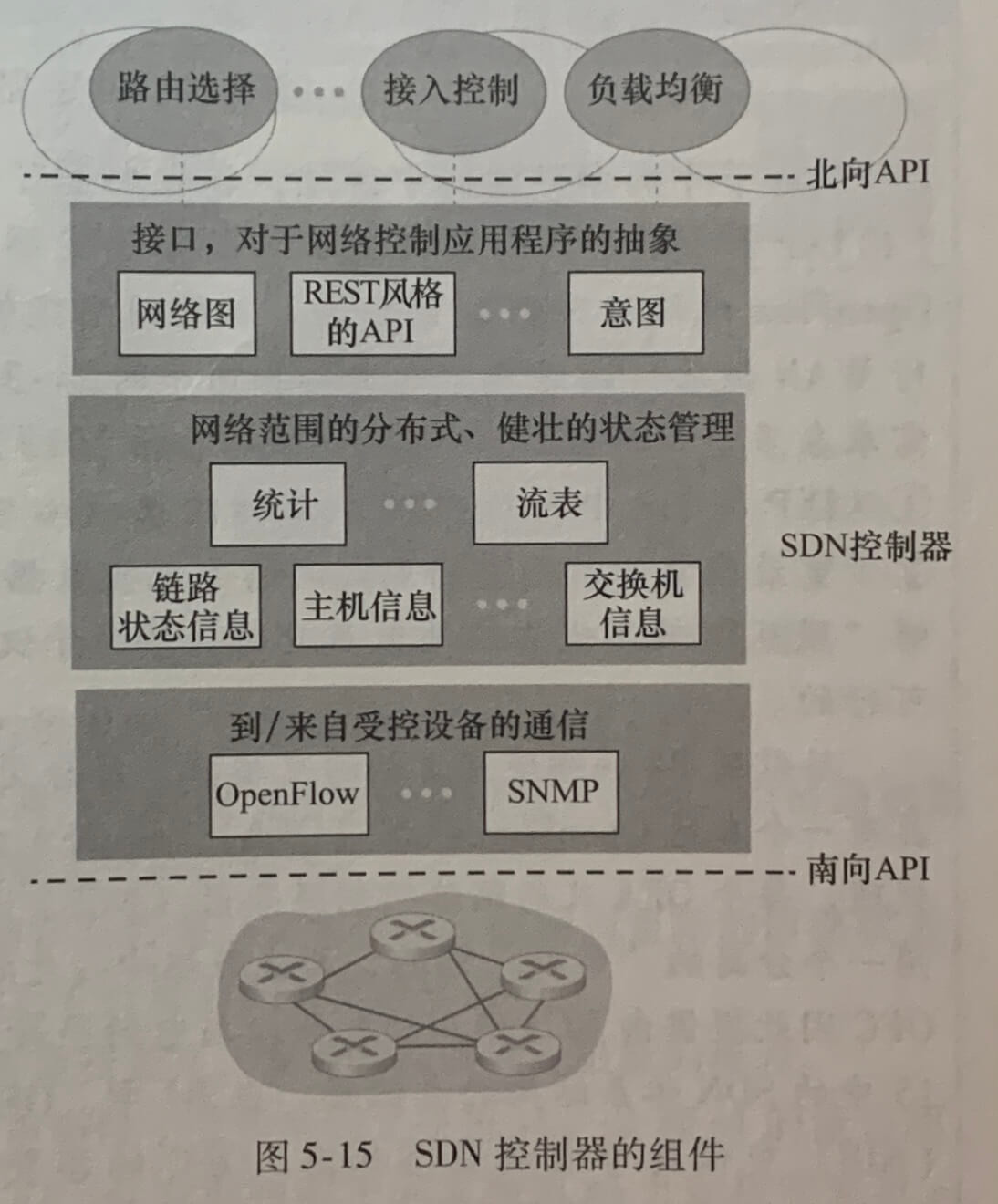
控制器的功能可大体组织为3个层次:
- 通信层:SDN 控制器和受控网络设备之间的通信。SDN 控制器要控制远程 SDN 使能的交换机、主机或其他设备的运行,需要一个协议来传送控制器与这些设备之间的信息。此外,设备必须能够向控制器传递本地观察到的事件(例如,一个报文指示一条附属链路已经激活或停止,一个设备刚刚加入了网络等等)。这些事件向 SDN 控制器提供该网络状态的最新视图。这个协议(OpenFlow)构成了控制器体系结构的最底层。
- 网络范围状态管理层。由 SDN 控制平面所做出的最终控制决定,将要求控制器具有有关网络的主机、链路、交换机和其他 SDN 设备的最新状态信息。
- 对于网络控制应用程序层的接口。控制器通过它的“北向”接口与网络控制应用程序交换。该 API 允许网络控制应用程序在状态管理层之间读/写网络状态和流表。
5.5.2 OpenFlow协议
OpenFlow 协议运行在 SDN 控制器和 SDN 控制的交换机或其他实现的 OpenFlow API 的设备之间。OpenFlow 协议运行在 TCP 之上,使用 6654 的默认端口号。从控制器到受控交换机的重要报文有下列这些:
- 配置。该报文允许控制器查询并设置交换机的配置参数。
- 修改状态。该报文由控制器所使用,以增加/删除或修改交换机流表中的表项,并且设置交换机端口特性。
- 读状态。该报文被控制器用于从交换机的流表和端口收集统计数据和计数器值。
- 发送分组。该报文被控制器用于在受控交换机从特定的端口发送出一个特定的报文。
从受控交换机到控制器流动的重要报文有下列这些:
- 流删除。该报文通知控制器已删除一个流表项。
- 端口状态。交换机用该报文向控制器通知端口状态的变化。
- 分组入。一个分组到达交换机端口,并且不能与任何流表项匹配,那么这个分组将被发送给控制器进行额外处理。
5.5.3 数据平面和控制平面交互的例子

上图揭示了相比与传统的每路由器控制,SDN控制器能够随心所欲地定制流表,因此能够实现它喜欢的任何形式的转发。
5.6 ICMP:因特网控制报文协议
因特网报文控制协议(ICMP),被主机和路由器用来彼此沟通网络层的信息。ICMP 最典型的用途是差错报告。
ICMP 报文承载在 IP 分组中,作为 IP 有效载荷承载,就像 TCP 与 UDP 报文段作为 IP 有效载荷被承载那样。ICMP 在 IP 数据报中的上层协议编码为1。
ICMP 报文有一个类型字段和一个编码字段,并且包含引起该 ICMP 报文首次生成的 IP 数据报的首部和前8个字节(以便发送方能确认引发该差错的数据报)。

ping 程序发送一个 ICMP 类型 8 编号 0 的报文到指定主机。看到回显(echo)请求,目的主机发回一个类型 0 编码 0 的 ICMP 回显回答。
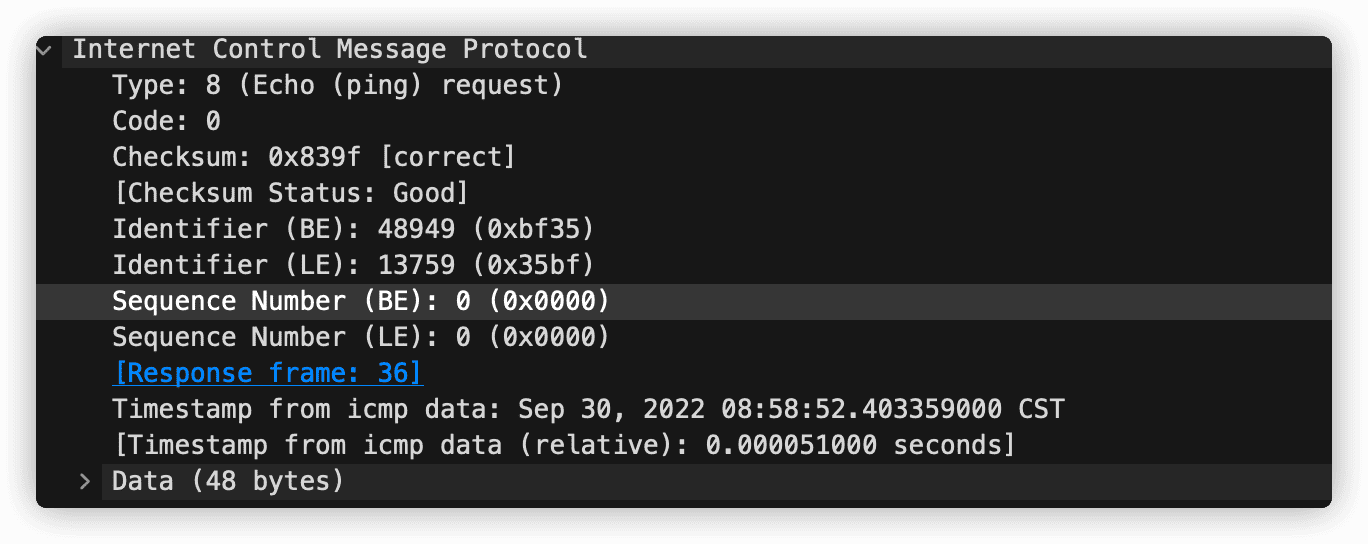
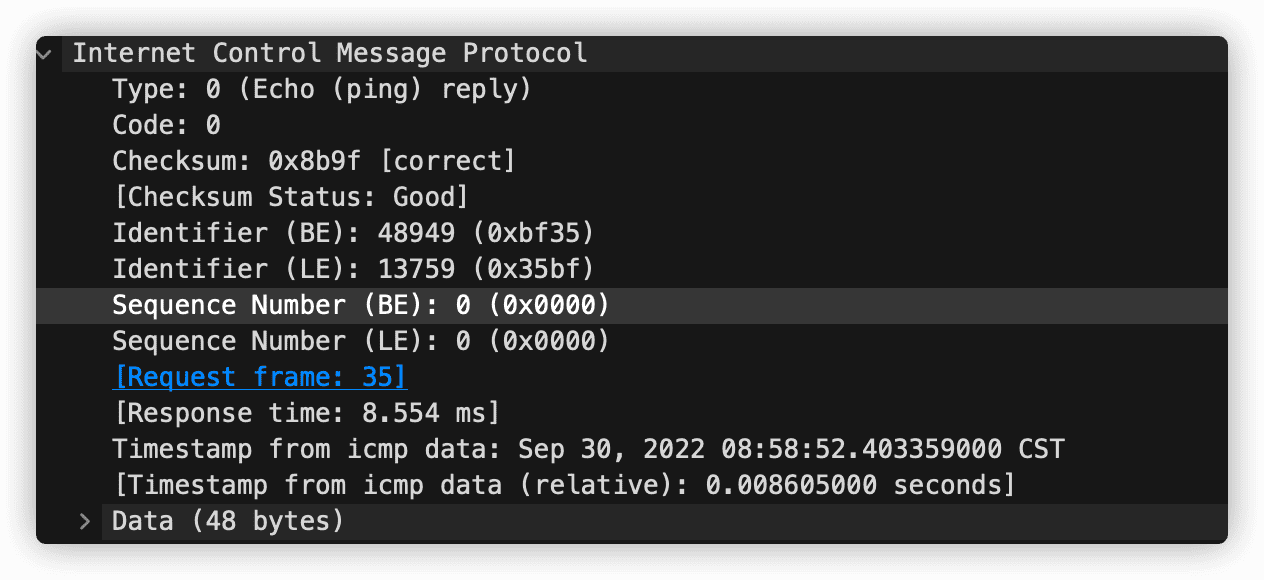
第一章介绍的Traceroute程序,该程序用来追踪一台主机到世界上任意一台主机之间的路由,它是通过 ICMP 报文来实现的。通过向目的主机发送一个不可达 UDP 端口号的 UDP 报文段。第一个数据报的 TTL 为 1,第二个为2,以此类推,当收到编号 3 类型3 的 ICMP 报文时,即不再发送探测分组。
5.7 网络管理和SNMP
网络管理定义:网络管理包括了硬件、软件和人类元素和设置、综合和协调,以监视、测试、轮询、配置、分析、评价和控制网络及网元资源,用合理的成本满足实时性、运营性和服务质量的要求。
5.7.1 网络管理框架
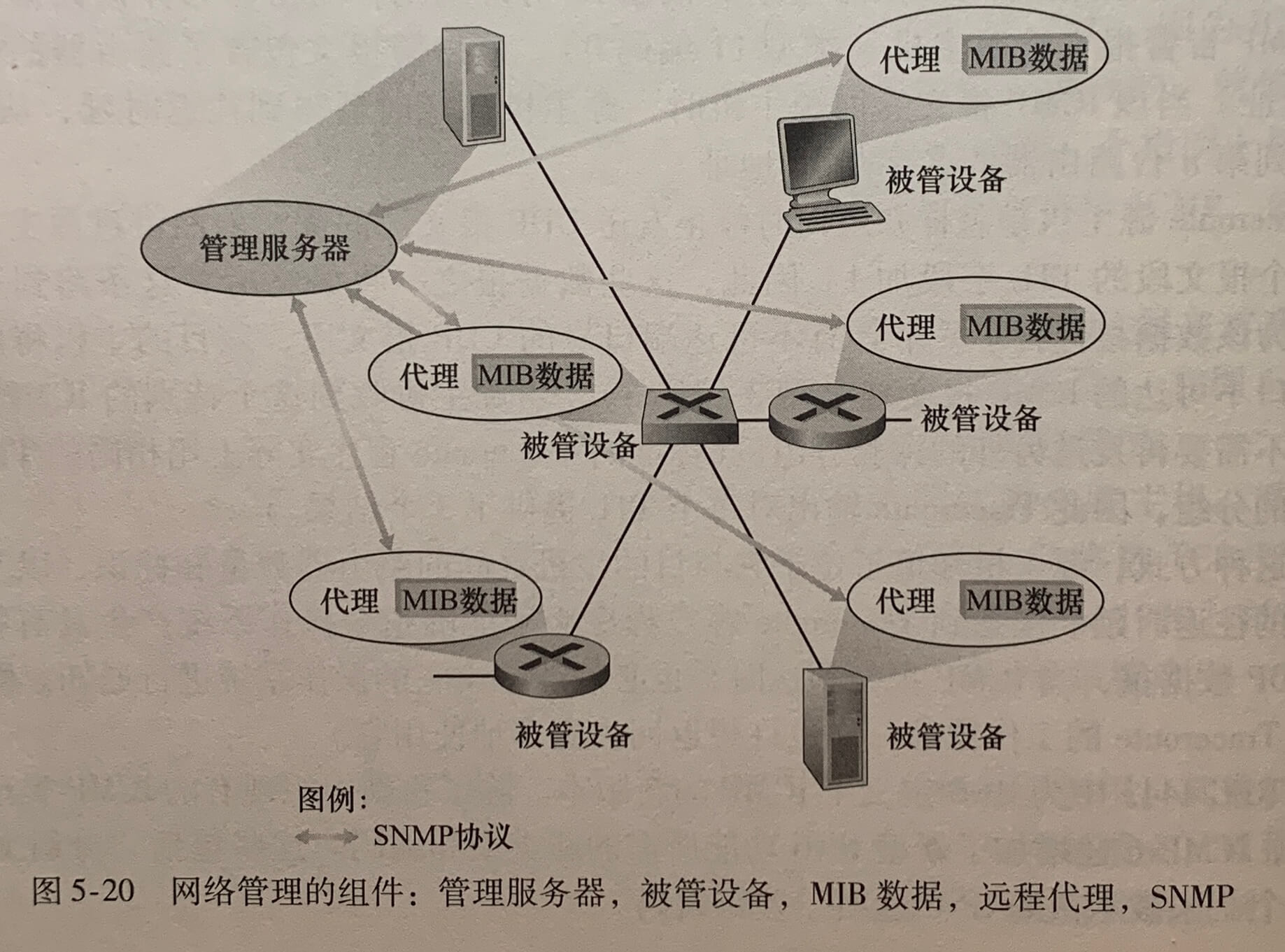
- 管理服务器(managing server)是一个应用程序,通常有人的参与,并运行在运营中心(NOC)的集中式网络管理工作站上。
- 被管设备(managed device)是网络准备的一部分(包括它的软件),位于被管理的网络中。被管设备可以是一台主机、路由器、交换机、中间盒、调制解调器、温度计或其他联网的设备。在一个被管设备中,有几个所谓被管对象。这些被管对象是被管设备中硬件的实际部分和用于这些硬件及软件组织的配置参数。
- 一个被管设备中的每个被管对象的关联信息收集在管理信息库(Management Information Base,MIB)中,这些信息的值可供管理服务器所用。
- 在每个被管设备中还驻留有网络管理协议(network management agent),它是运行在被管设备中的一个进程,该进程与管理服务器通信,在管理服务器的命令和控制下在被管设备中采取本地动作。
- 网络管理协议(network management protocol)运行在管理服务器和被管设备之间,允许管理服务器查询被管设备的状态,并经过其代理间接地在这些设备上采取动作。
5.7.2 简单网络管理协议
**简单网络管理协议(Simple Network Management Protocol)**版本2是一个应用层协议,用于在管理服务器和代理管理服务器执行的代理之间传递网络控制和信息报文。SNMP使用的是请求响应模式。
第6章 链路层和局域网
6.1 链路层概述
运行链路层协议的任何设备均称为节点(node)。节点包括主机、路由器、交换机和 WiFi 接入点。沿着通信路径连接相邻节点的通信信道称为链路(link)。在通过特定的链路时,传输节点将数据报封装在链路层帧中,并将该帧传送到链路中。
6.1.1 链路层提供的服务
链路层协议能够提供的可能服务包括:
- 成帧(framing)。在网络层数据经链路层传送之前,链路层协议将其用链路层帧封装起来。一个帧由一个数据字段和若干首部字段组成,其中网络层数据报就插在数据字段中。帧的结构由链路层协议规定。
- 链路接入。**媒体访问控制(Medium Access Control,MAC)**协议规定了帧在链路上传输的规则。MAC 协议用于协调多个节点的帧传输。
- 可靠交付。当链路层协议提供可靠交付服务时,它保证无差错地经链路层移动每个网络层数据报。与运输层可靠交付服务类似,链路层的可靠交付服务通常是通过确认和重传取得的。链路层可靠交付服务通常用于易于产生高差错率的链路,例如无线链路,其目的是本地纠正一个差错,而不是通过运输层或应用层协议迫使进行端到端的数据重传。对于低比特差错的链路,包括光纤、同轴电缆和许多双绞铜线连理,链路层可靠交付可能会被认为是一种不必要的开销。由于这个原因,许多有线的链路层协议不提供可靠交付服务。
- 差错检测和纠正。当帧中的一个比特作为1传输时,接收方节点中的链路层硬件可能不正确地将其判断为0,反之亦然。这种比特差错是由信号衰减和电磁噪声导致的。因为没有必要转发一个有差错的数据报,所以许多链路层协议提供一种机制来检查这样的比特差错。通过让发送节点在帧中包括差错检测比特,让接收节点进行差错检查。链路层的差错检测通常更复杂,并且用硬件实现。差错纠正类似于差错检测,区别在于接收方不仅能检测帧中出现的比特差错,而且能够准确地确定帧中的差错出现的位置。
6.1.2 链路层在何处实现
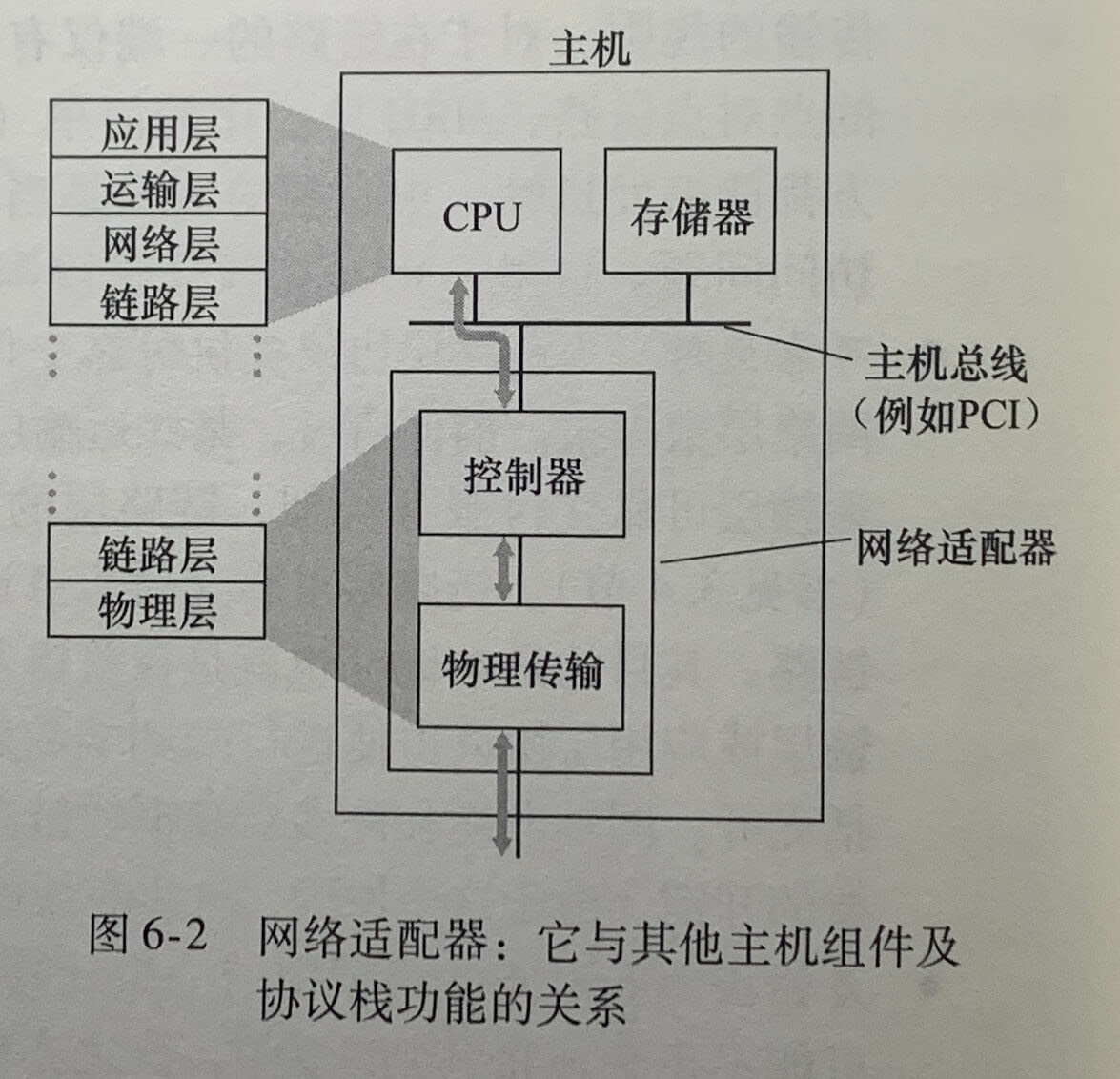
上图是一个典型的主机体系结构。链路层的主体部分是在网络适配器(network adapter)中实现的,网络适配器有时也称为网络接口卡(Network Interface Card,NIC)。位于网络适配器核心的链路层控制器通常是一个实现了许多链路层服务(成帧、链路接入、差错检测等)的专用芯片。因此,链路层控制器的许多功能是用硬件实现的。
直到20世纪90年代后期,大部分网络适配器还是物理上分离的卡,但越来越多的网络适配器被综合进主机的主板。
在发送端,控制器取得了由协议栈较高层生成并存储在主机内存中的数据报,在链路层帧中封装该数据报,然后遵循链路接入协议将该帧传进通信链路中。在接收端,控制器接收了整个帧,抽取出网络层数据报。如果链路层执行差错检测,则需要发送控制器在该帧的首部设置差错检测比特,由接收控制器执行差错检测。
尽管大部分链路层是在硬件中实现的,但部分链路层是在运行于主机 CPU 上的软件中实现的。链路层的软件组件实现了高层链路层功能,如组装链路层寻址信息和激活控制器硬件。在接收端,链路层软件响应控制器中断,处理差错条件和将数据报向上传递给网络层。所以,链路层是硬件和软件的结合体,即此处是协议栈中软件与硬件交接的地方。
6.2 差错检测和纠正技术
比特差错检测和纠正(bit-level error detection and correction),即对从一个节点发送到另一个物理上连接的邻近节点的链路层帧中的比特损伤进行检测和纠正,它们通常是链路层提供的两种服务。
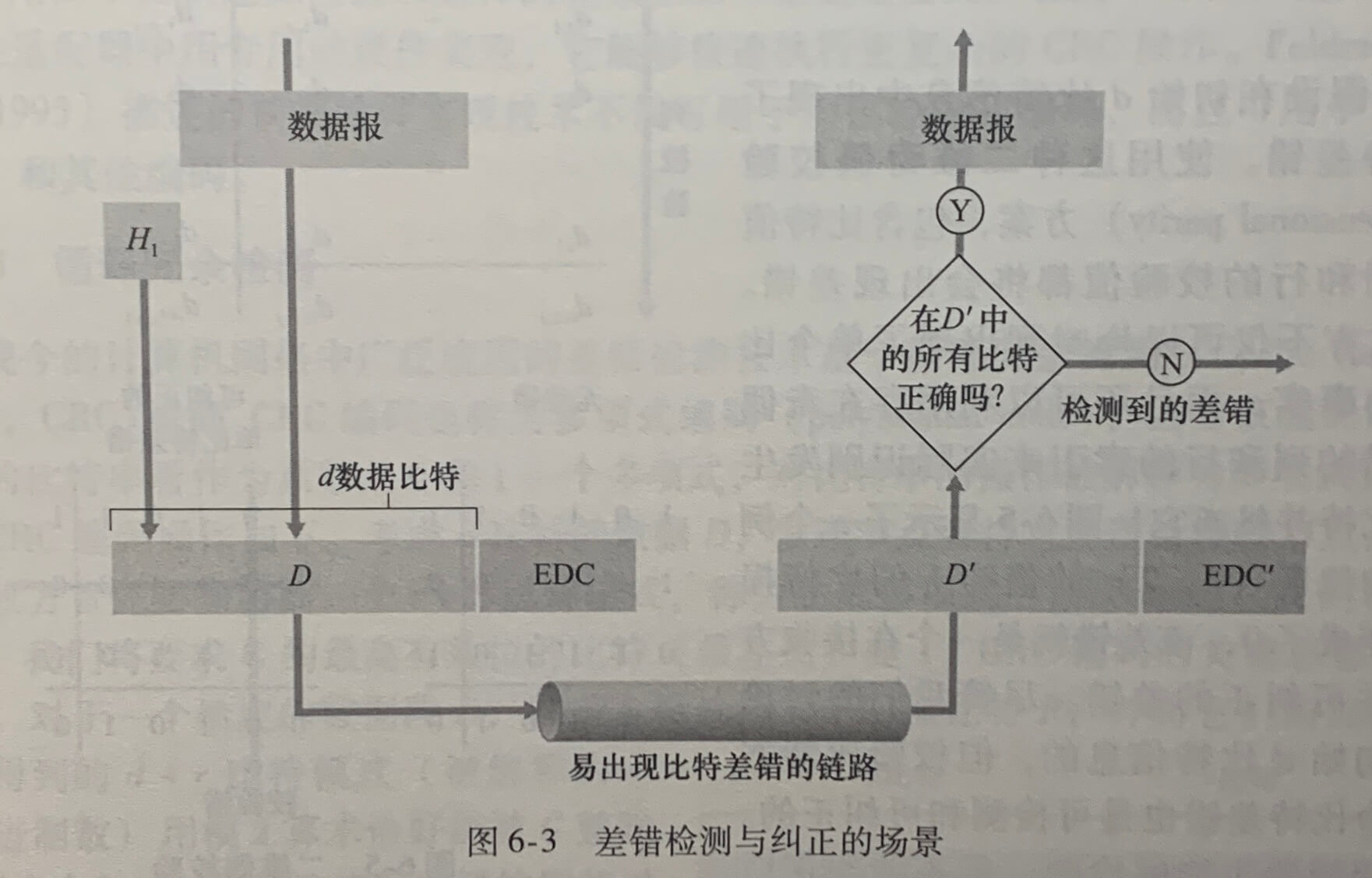
上图中,在发送节点,为了保护比特免受差错,使用**差错检测和纠正比特(Error-Detection and-Correction,EDC)**来增强数据D。通常,要保护的数据不仅包括网络层传递下来的数据报,还包括链路层帧首部中的链路级的寻址信息、序号和其他字段。
3种在传输数据中检测差错的技术:奇偶校验(它用来描述差错检测 和纠正背后隐含的基本思想)、检验和方法(它通常更多地应用于运输层)和循环冗余检测(它通常更多地应用在适配器中的链路层)
6.2.1 奇偶校验

采用单个奇偶校验位方式,接收方只需要数一数接受的 d+1 比特中1的数目即可。如果在采用偶校验方案中发现了奇数个值为1的比特,接受方知道至少出现了一个比特差错。

二维奇偶校验能够检测(但不能纠正)一个分组中两个比特差错的任何组合。
接收方检测和纠正差错的能力被称为前向纠错(Forward Error Correction,FEC)。这些技术通常用于如音频CD这样的音频存储和回放设备中。
6.2.2 检验和方法
检验和就是将k比特整数加起来,并且用得到的和作为差错检测比特。**因特网检验和(Internet checksum)**就是基于这种方法,即数据的字节作为16比特的整数对待并求和。这个和的反码形成了携带在报文段首部的因特网检验和。
6.2.3 循环冗余检测
现今的计算机网络中广泛应用的差错检测技术基于循环冗余检测(Cyclic Redundancy Check,CRC)编码。CRC 编码也称为多项式编码(polynomial code),该编码能够将要发送的比特串看作为系数是0和1 一个多项式,对比特串的操作被解释为多项式算术。

6.3 多路访问链路和协议
两种网络链路:
- **点对点链路(point-to-point link)**由链路一端的单个发送方和链路另一端的单个接收方组成。许多链路层协议都是为点对点链路设计的,如点对点协议(point-to-point protocol,PPP)和高级数据链路控制(high-level data link control,HDLC)。
- 广播链路(broadcast link),它能够让多个发送和接收节点都连接到相同的、单一的、共享的广播信道上。当任何一个节点传输一个帧时,信道广播该帧,每个其他节点都收到一个副本。以太网和无线局域网是广播链路层技术的例子。广播信道通常用于局域网中。
传统的电视广播是一个方向的广播(即一个固定的节点向许多接收节点传输),而计算机网络广播信道上的节点即能够发送也能够接收。
多路访问协议(MAC),即节点通过这些协议来规范它们在共享的广播信道上的传输行为。
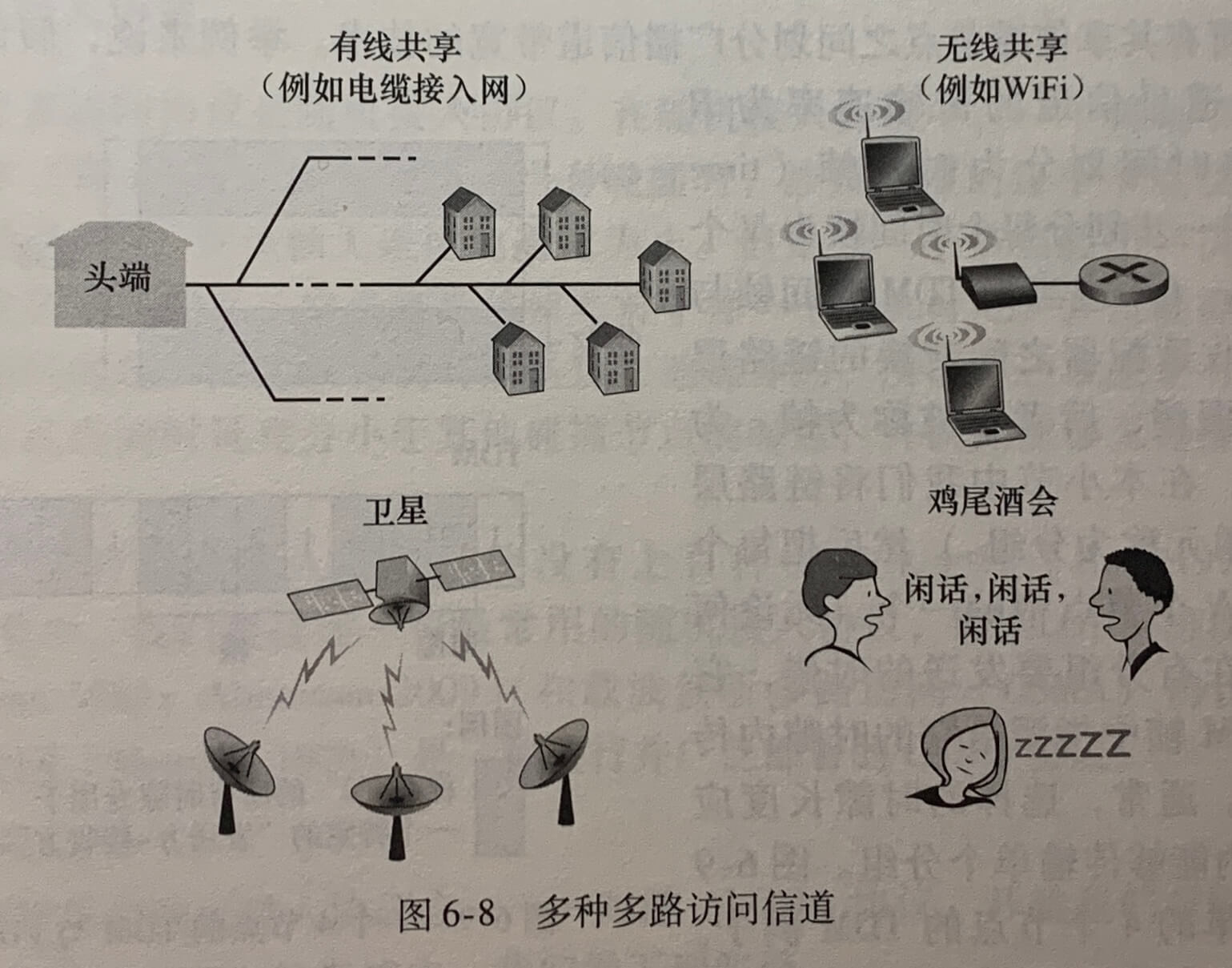
因为所有的节点都能够传输帧,当所有节点同时接到多个帧,传输的帧在所有的接收方处发生碰撞(collide)。当碰撞发生时,没有一个接收节点能够有效地获得任何传输的帧;碰撞的帧的信号纠缠在一起,涉及此次碰撞的所有帧都丢失了,在碰撞时间间隔中的广播信道被浪费了。多路访问协议专门用于解决该问题。
多路访问协议可划分为 3 种类型:
- 信道划分协议(channel partitioning protocol)
- 随机接入协议(randm access protocol)
- 轮流协议(taking-turns protocol)
6.3.1 信道划分协议
三种信道划分协议:
-
时分多路复用(TDM)
让每个结点在每个帧时间内得到了专用的传输速率R/N bps。它解决了碰撞问题且非常公平,而缺陷是节点被限制与 R/N bps 的传输速率,即使当它是唯一有分组要发送的节点时。其次是节点必须总是等待它在传输序列中的轮次。
-
频分多路复用(FDM)
FDM 和 TDM 具有相同的优缺点。
-
码分多址(Code Division Multiple Access,CDMA)
CDMA 对每个节点分配一种不同的编码。每个节点用它唯一的编码来对它发送的数据进行编码。CDMA 网络能让不同的节点同时传输,且它们各自相应的接收方仍然能正确接收发送方编码的数据比特(假设接收方知道发送方的编码),而不在乎其他节点的干扰传输。
CDMA 在军用系统已使用了一段时间,目前也广泛地用于民用,尤其是蜂窝电话中。
6.3.2 随机接入协议
在随机接入协议中,一个传输节点总是以信道的全部速率R进行发送。当有碰撞时,涉及碰撞的每个节点反复地重发它的帧,到该帧无碰撞地通过为止。
当一个节点经历一次碰撞时,它不必立即重发该帧,而是在重发该帧之前等待一个随机时延。涉及碰撞的每个节点独立地选择随机时延。
最常用的随机接入协议:
-
ALOHA协议
-
载波侦听多路访问(CSMA)协议
以太网是一种流行并广泛部署的 CSMA 协议。
1.时隙ALOHA
时隙ALOHA的操作是:
- 当节点有一个新帧要发送时,它等到下一个时隙开始并在该时隙传输整个帧。
- 如果没有碰撞,该节点成功地传输它的帧。
- 如果发送碰撞,该节点在时隙结束之前检测到这次碰撞。该节点以概率p在后续的每个时隙中重传它的帧,直到该帧被无碰撞地传输出去。
由于重传是随机的,由计算可得时隙ALOHA的实际传输速率是0.37R bps。
2.ALOHA
在纯ALOHA中,当一帧首次到达,节点立刻将该帧完整地传输进广播信道。如果一个传输的帧与一个或多个传输经历了碰撞,这个节点立即以概率p重传该帧。否则,该节点等待一个帧传输时间,等待之后将以概率p传输该帧。
纯ALOHA协议的最大效率为1/(2e)。
3.载波侦听多路访问(CSMA)
CSMA有两个重要的规则:
- 载波侦听(carrier sensing),即一个节点在传输前先听信道,如果来自另一个节点的帧正向信道上发送,节点则等待直到检测到一小段时间没有传输,然后开始传输。
- 碰撞检测(collision detection),即当一个传输节点在传输时一直在监听此信道。如果它检测到另一个节点正在传输干扰帧,它就停止传输。
这两个规则包含在**载波侦听多路访问(Carrier Sense Multiple Access,CSMA)和具有碰撞检测的CSMA(CSMA with Collision Detection,CSMA/CD)**协议族中。

上图中,信道传播时延导致碰撞。
4.具有碰撞检测的载波侦听多路访问(CSMA/MA)
当碰撞节点数量较少时,重新开始传输的时间间隔较短;反之亦然。
5.CSMA/CD效率
当只有一个节点有一个帧发送时,该节点能满速率传输。如果传播时延为0,碰撞的节点将立即中止而不会浪费信道。信道在大多数时间都会有效地工作。
6.3.3 轮流协议
和随机接入协议一样,有几十种轮流协议(taking-turns protocol)。其中每一个协议又有很多变种。这里讨论两种重要的协议。
**轮询协议(polling protocol)要求将这些节点之一被指定为主节点。主节点以循环的方式轮询(poll)**每个节点。它先向节点1发送一个报文,告诉节点1能够传输的帧的最多数量。在节点1传输了某些帧后,它告诉节点2能够传输的帧的最多数量。(主节点通过观察在信道上是否缺乏信号,来决定一个节点何时完成了帧的发送)。
轮询协议消除了困扰随机接入协议的碰撞和空时隙,轮询取得了高得多的效率。但它的缺点是引入了轮询时延,即通知一个节点所需的时间。另外一个缺点是如果主节点出现故障,整个信道将变得不可操作。802.15协议和蓝牙协议就是轮询协议的例子。
令牌传递协议(token-passing protocol),在这种协议中没有主节点。一个称为**令牌(token)**的小的特殊帧在节点之间以某种固定的次序进行交换。例如节点1传给节点2,节点2传给节点3,节点N传给节点1,以此类推。当一个节点收到令牌时如果它有要发送的帧,则它发送最大数目的帧数,然后将令牌转发给下一个节点。令牌传递是分散的且有很高的效率。它的缺点也很明显,就是如果一个节点出了问题,可能会使整个信道崩溃。
令牌传递协议的例子有光纤分布式数据接口(FDDI)协议和IEEE 802.5 令牌环协议。
6.3.4 DOCSIS:用于电缆因特网接入的链路层协议
下面将电缆接入网作为一个多路访问协议的例子。1.2.1节讲过,一个电缆接入网通常在电缆网头端将几千个住宅电缆调制解调器与一个**电缆调制解调器端接系统(Cable Modem Termination System,CMTS)**连接。
DOCSIS使用 FDM 将下行(CMTS到调制解调器)和上行(调制解调器到CMTS)网络段划分为多个频率信道。每个上行和下行均为广播信道。CMTS在下行信道中传输的帧被所有在信道上做接收的电缆调制解调器接收到;然而因为仅有单一的CMTS在下行行道上传输,不存在多路访问问题。但在上行方向,多个电缆调制解调器共享到CMTS的相同上行信道(频率),因此可能出现碰撞。

上图中,每条上行信道被划分为时间间隔(类似于TDM),每个时间间隔包含一个微时隙序列,电缆调制解调器可在该微时隙中向 CMTS 传输。CMTS 在下行信道上通过发送称为 MAP 报文的控制报文,指定哪个电缆调制解调器能够在微时隙中传输由控制报文指定的时间间隔。由于微时隙明确分配给电缆调制解调器,故CMTS能够确保在微时隙中没有碰撞传输。
CMTS 通过让电缆调制解调器在专用于此目的的一组特殊的微时隙间隔内向 CMTS 发送微时隙请求帧来知道哪个电缆调制解调器有数据要发送。微时隙请求帧以随机接入方式传输,故可能相互碰撞。电缆调制解调器如果没有下一个下行控制报文中收到对请求分配的响应的话,就推断它的微时隙请求帧经历了一次碰撞。当推断出一次碰撞,电缆调制解调器使用二进制指数回退将其微时隙请求帧延缓到以后的时隙重新发送。
6.4 交换局域网
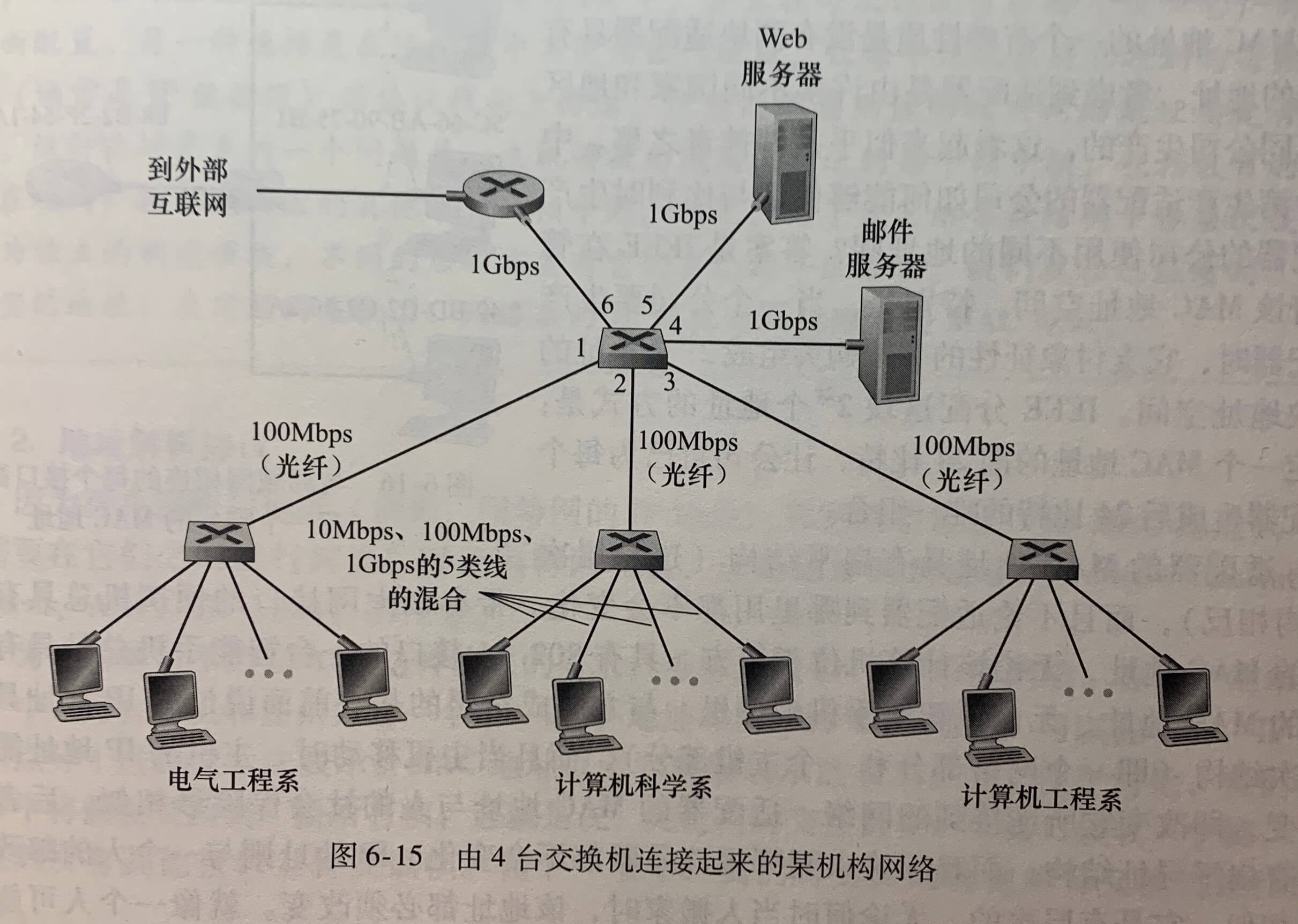
上图中显示了一个交换局域网连接了3个部门,两台服务器和一台与4台交换机连接的路由器。因为这些交换机运行在链路层,所以它们交换链路层帧,不识别网络层地址。
6.4.1 链路层寻址和地址解析协议(ARP)
主机和路由器具有链路层地址。
1.MAC地址
事实上,并不是主机或路由器具有链路层地址,而是它们的适配器(即网络接口)具有链路层地址。因此,具有多个网络接口的主机或路由器将具有与之相关联的多个链路层地址,就像它也具有与之相关联的多个 IP 地址一样。然而,链路层交换机并不具有与它们的接口(这些接口是与主机和路由器相连的)相关联的链路层地址。这是因为链路层交换机的任务是在主机与路由器之间承载数据报;交换机透明地执行该项任务。主机或路由器不必明确地将帧寻址到其间的交换机。

链路层地址有各种不同的称呼:LAN地址(LAN address)、物理地址(physical address)或MAC地址。
大多数局域网(包含以太网和802.11无线局域网)的 MAC 地址长度为 6 字节,共有 2 48 2^{48} 248个MAC地址,通常使用十六进制表示法,地址的每个字节被表示为一对十六进制数。尽管 MAC 地址被设计为永久的,但用软件改变一块适配器的 MAC 地址现在是可能的。
MAC 地址的一个有趣性质是没有两块适配器具有相同的地址。IEEE 管理着该 MAC 地址空间。当一个公司要生产适配器时,它支付象征性的费用购买组成 2 24 2^{24} 224个地址的一块地址空间。IEEE分配这块 2 24 2^{24} 224地址是固定一个 MAC 地址的前 24 比特,让公司自己为每个适配器生成后 24 比特的唯一组合。
适配器的 MAC 地址具有扁平结构,而且不论适配器到哪里用都不会变化。带有以太网接口的便携机总具有相同的 MAC 地址,无论该计算机位于何方。具有 802.11 接口的一台智能手机总是具有相同的 MAC 地址,不论该智能手机到哪里。与之形成对照的是,IP地址具有层次结构,而且当主机移动时,主机的IP地址需要改变,即改变它所连接到的网络。MAC地址可类比身份证号,IP地址可类比邮政地址。就像一个人可能发现邮政地址和身份证号码都有用那样,一台主机具有一个网络层地址和一个 MAC 地址是有用的。
当某适配器要向某些目的适配器发送一个帧时,发送适配器将目的适配器的 MAC 地址插入到该帧中,并将该帧发送到局域网上。一台交换机偶尔将一个入帧广播到它的所有接口。一块适配器可以接收一个并非向它寻址的帧。当适配器接收到一个帧时,将检查该帧中的目的 MAC 地址是否与它自己的 MAC 地址匹配,如果不匹配则丢弃该帧,而不会向上传递该网络层数据报。
有时某些发送适配器想要让局域网上的所有其他适配器来接收并处理它打算发送的帧,此时发送适配器将插入连续48个为1比特组成的一个特殊的 MAC 广播地址。
2.地址解析协议ARP
**地址解析协议(Address Resolution Protocol,ARP)**的任务是在网络层地址和链路层地址之间进行转换。
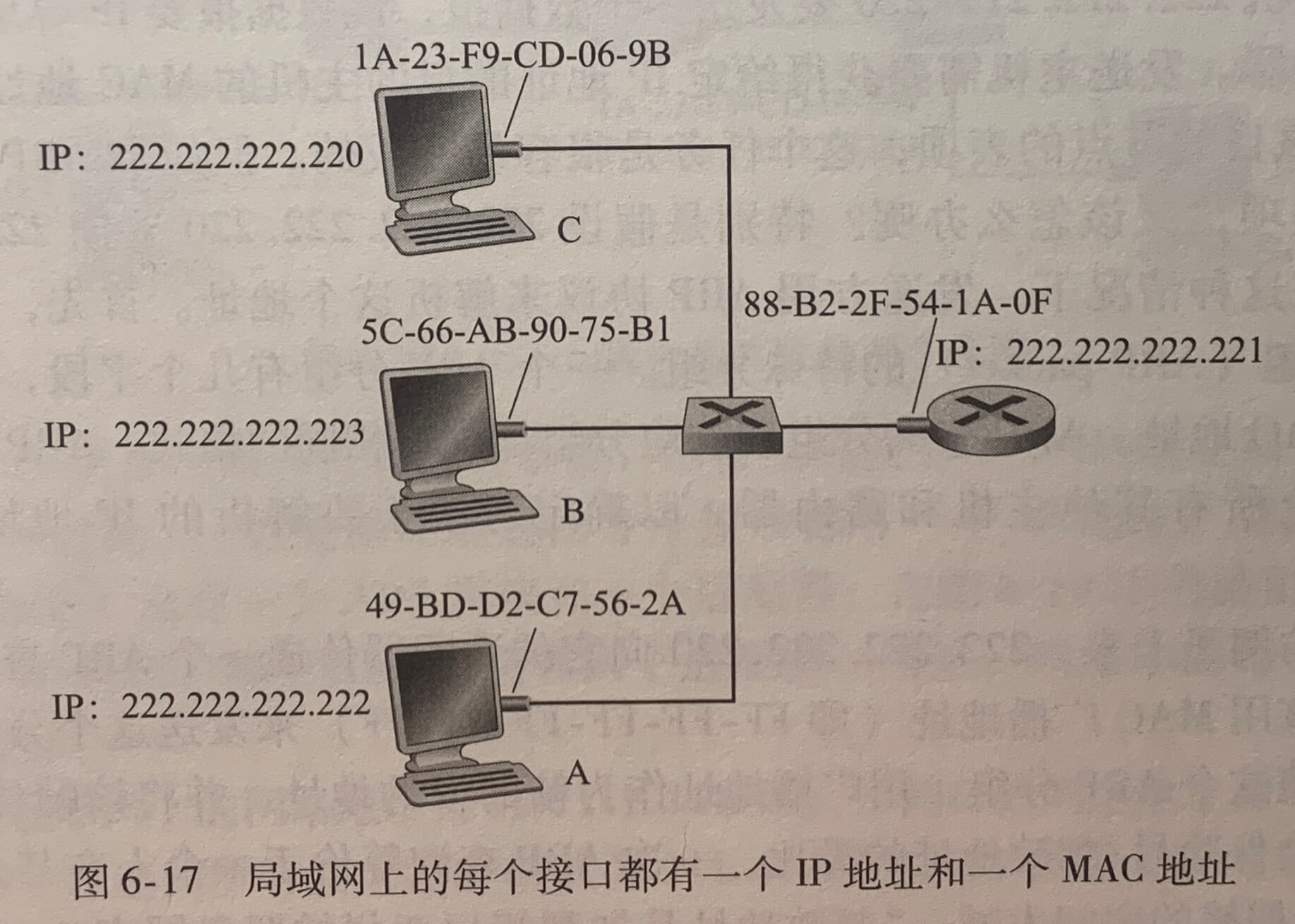
上图中,假设主机C向主机A发送IP数据报,为了发送数据报,该源必须向它的适配器不仅提供 IP 数据报,而且要提供目的主机A的 MAC 地址。为了获取主机A的 MAC 地址,主机C中的 ARP 模块将取在相同局域网上的任何 IP 地址作为输入,然后返回相应的 MAC 地址。
ARP 将一个 IP 地址解析为一个 MAC 地址。在很多方面它和 DNS 类似。这两种解析之间的一个重要区别是,DNS为因特网中任何地方的主机解析主机名,而 ARP 只为同一个子网上的主机和路由器接口解析 IP 地址。
每台主机或路由器在其内存中具有一个ARP表,这张表包含 IP 地址到 MAC 地址的映射关系。这张表不必为该子网上的每台主机和路由器都包含一个表项。假如发送主机的ARP表没有接收主机的MAC 地址,发送方构造一个称为ARP分组的特殊分组。一个 ARP 分组有几个字段,包括发送和接收 IP 地址及 MAC 地址。ARP 查询分组和响应分组都具有相同的格式。ARP 查询分组的目的是询问子网上所有其他主机和路由器,以确定对应于要解析的 IP 地址的那个 MAC 地址。
发送方向它的适配器传递一个 ARP 查询分组,并使用 MAC 广播地址(FF-FF-FF-FF-FF-FF)来发送这个分组,适配器将该帧传输进子网中。当其他所有适配器接收到时,这些 ARP 模块会检查它的 IP 地址是否与 ARP 分组中的目的 IP 地址相匹配。与之匹配的一个给查询主机发送回一个带有所希望映射的响应 ARP 分组。发送方收到后将更新它的 ARP 表,并发送它的 IP 数据报。

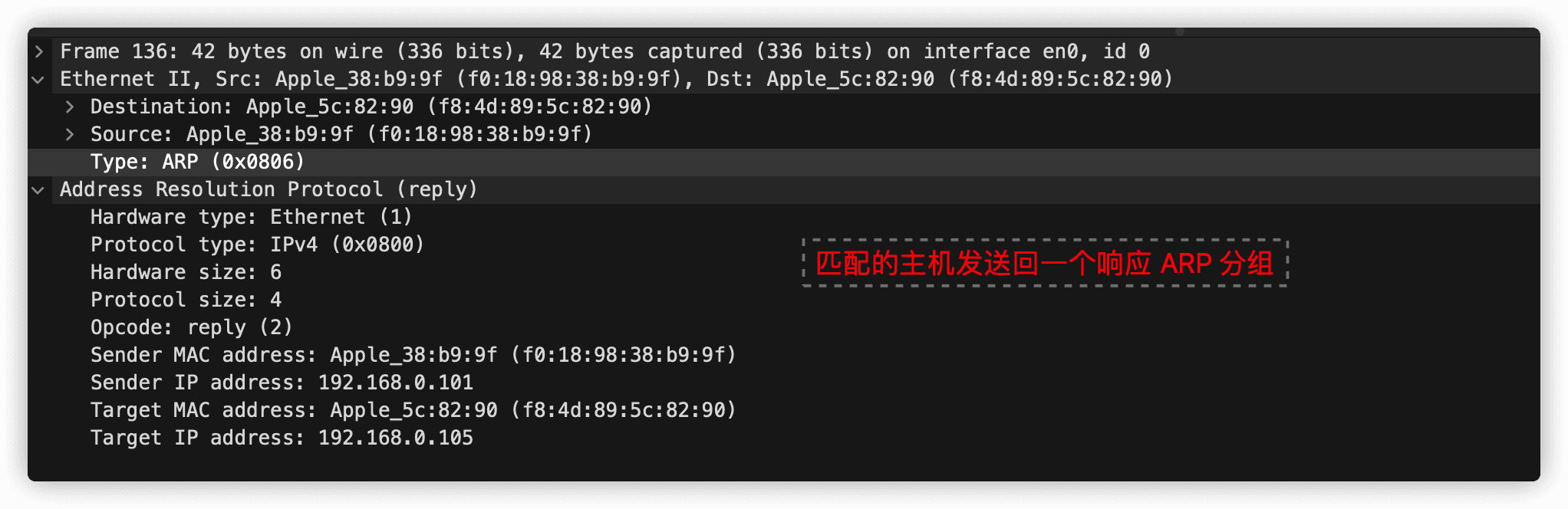
ARP即不属于链路层协议也不属于网络层协议,而是跨越链路层和网络层边界两边的协议。
3.发送数据报到子网以外
上述描述了一台主机向相同子网上的另一台主机发送一个数据报时 ARP 的操作过程。接下来讲下向子网外的主机发送数据报时的情况。

假设 IP 111.111.111.111 要向 IP 222.222.222.222 发送数据报,发送方将数据报(数据报的IP地址指向 222.222.222.222 即接收方)传输给它的适配器时,适配器使用的 MAC 地址不是接收方的 MAC 地址,而是路由器(网关)(IP 111.111.111.110)的 MAC 地址,当路由器接收到该帧时,把该帧传输到路由器的网络层,路由器解析 IP 地址之后将该数据报通过转发表查询出要被转发的接口,然后路由器将数据报传递给它的适配器,适配器获取的 MAC 地址此时才是 IP 222.222.222.222 的 MAC 地址。发送方通过 ARP 获取路由器的 MAC 地址,路由器也通过 ARP 获取 接收方的 MAC 地址。
6.4.2 以太网
以太网几乎占领着现有的有线局域网市场。在20世纪80年代和90年代早期,以太网面临着来自其他局域网技术包括令牌环、FDDI和ATM的挑战。今天,以太网是到目前为止最流行的有线局域网技术。
- 20世纪70年代发明的初始的以太局域网,使用同轴电缆总线来互联节点。总线拓扑的以太网是一种广播局域网,即所有传输的帧传送到与该总线连接的所有适配器并被其处理。
- 到了20世纪90年代后期,使用的是一种基于集线器的星形拓扑以太网。集线器是一种物理层设备,它作用于各个比特而不是作用于帧。当表示0或1的比特到达一个接口时,集线器重新生成这个比特,并将其能力强度放大后将该比特向其他所有接口传输出去。如果某集线器同时从两个不同的接口收到帧,将出现一次碰撞,生成该帧的结点必须重新传输该帧。
- 到21世纪初,以太网继续使用星形拓扑,但位于中心的集线器被**交换机(switch)**所替代。交换机是“无碰撞的”,也是名副其实的存储转发分组交换机,与运行在高至第三层的路由器不同,交换机仅运行在第二层。

1.以太网帧结构

- 数据字段(46~1500字节)。这个字段承载 IP 数据报。以太网的最大传输单元(MTU)是1500字节。
- 目的地址(6字节)。这个字段包含目的适配器的 MAC 地址。如果适配器收到帧的目的地址是它的 MAC 地址或是广播地址,它将该帧的数据字段传递给网络层,反之丢弃。
- 源地址(6字节)。
- 类型字段(2字节)。类型字段允许以太网复用多种网络层协议。实际上,主机能够使用除了 IP 以外的其他网络层协议。该类型字段和网络层数据报中的协议字段、运输层报文段的端口号字段相类似,所有这些字段都是为了把一层中的某协议与上一层的某协议结合起来。
- CRC(4字节)。CRC(循环冗余检测)字段的目的是使得接收适配器检测帧中是否引入了差错。
- 前同步码(8字节)。以太网帧以一个 8 字节的前同步码(Preamble)字段开始。前同步码的前 7 字节都是 10101010;最后一个字段是 10101011。前同步码的前 7 字段用于“唤醒”接收适配器,并且将它们的时钟和发送方的时钟同步。前同步码的第 8 个字段的最后两个比特警告接收适配器,重要的内容就要到来了。
所有的以太网技术都向网络层提供无连接服务。这种第二层的无连接服务类似于 IP 的第三层数据报服务和 UDP 的第四层无连接服务。
以太网技术都向网络层提供不可靠服务。当接收适配器收到来自发送适配器的一个帧,接收适配器对该帧执行 CRC 校验,如果该帧通过校验,它从该帧中取出数据报传向网络层,但接收适配器不会发送确认帧,而如果该帧没有通过校验,接收适配器则丢弃该帧,当做没事发生一样。在链路层缺乏可靠的传输有助于使得以太网简单和便宜,但这也意味着传递到网络层的数据报流会出现间隙。
如我们在第3章学习到的,接收主机是否会处理这个间隙,取决于使用的是TCP还是UDP,UDP能看到这个间隙但不会处理,而TCP会通过可靠数据传输来保证数据的正确性,即让发送主机重传。从某种意义上来说,以太网的确重传了数据,但是以太网并不知道正在传输的数据的一个全新的数据报还是一个重传的数据报。
2.以太网技术
以太网具有许多不同的协议特色,如10BASE-T、10BASE-2、100BASE-T、1000BASE-LX和10GBASE-T。这些以及许多其他的以太网技术在多年中被IEEE 802.3 CSMA/CD 工作组标准化了。首字母的第一部分指该标准的速率:10、100、100或10G,分别代表10Mbps、100Mbps等等。“BASE”指基带以太网,这意味着该物理媒体仅承载以太网流量。该字母缩写词的最后一部分指物理媒体本身;以太网是链路层也是物理层的规范,并且能够经各种物理媒体(包括同轴电缆、铜线和光纤)承载。一般而言,“T”指双绞铜线。
早期的以太网限制在500米长度之内,通过使用**转发器(repeater)(也称中继器)**能够得到更长的运行距离,转发器是一种物理层设备,它在输入端接收信号并在输出端再生该信号。
在20世纪90年代中期,以太网被标准化为100Mbps。初始的以太网 MAC 协议和帧格式保留了下来,但更高的速率的物理层被定义为用铜线和用光纤。100Mbps以太网用双绞铜线距离限制为100米,用光纤距离限制为几千米。

吉比特以太网是对10Mbps和100Mbps以太网标准的扩展。40Gbps以太网提供40000Mbps的总数据速率,与大量已经安装的以太网设备基础保持完全兼容。吉比特以太网最初工作于光纤之上,现在能够工作在5类UTP线缆上。
6.4.3 链路层交换机
交换机的任务是接收入链路层帧并将它们转发到出链路。交换机自身对子网中的主机和路由器是透明的。也就是说,某主机/路由器向其他主机/路由器发送一个帧时,并不知道交换机会接受该帧并将它转发到另一个节点。这些帧到达该交换机的输出接口之一的速率可能暂时会超过该接口的链路容量,为了解决这个问题,交换机输出接口设有缓存,这非常类似于路由器接口为数据报设有缓存。
1.交换机转发和过滤
**过滤(filtering)**是决定一个帧应该转发到某个接口还是应当将其丢弃的交换机功能。**转发(forwarding)是决定一个帧应该被导向哪个接口,并把该帧移动到那些接口的交换机功能。交换机的过滤和转发借助于交换机表(switch table)**完成。许多现代的分组交换机能够被配置,以基于第二层目的 MAC 地址或第三层的 IP 目的地址进行转发。

2.自学习
交换机的交换机表是自动、动态和自治地建立的,没有网络管理员或来自配置协议的任何干预。
- 交换机表初始为空。
- 当每个接口接收到入帧时,交换机将其存储到表中,包括1.源MAC地址;2.该帧到达的接口;3.当前时间。
- 一段时间过后(老化期),交换机没有收到该地址作为源地址的帧,则在表中删除这个地址。
交换机是即插即用设备,它们不需要网络管理员或用户的干预。交换机是双工的,这意味着任何交换机接口都能够同时发送和接收。
3.链路层交换机的性质
交换机的优点:
- 消除碰撞。交换机缓存帧不会在网段上同时传输多于一个帧。
- 异质的链路。交换机将链路彼此隔离。因此局域网中的不同链路能够以不同的速率运行并且能够在不同的媒体上运行。
- 管理。
4.交换机和路由器比较
路由器是使用网络层地址转发分组的存储转发分组交换机。交换机和路由器最大的不同是它用 MAC 地址转发分组。交换机是第二层的分组交换机,而路由器是第三层的分组交换机。

现代的“匹配加动作”交换机能够转发基于帧的目的 MAC 地址的第二层帧,也能转发使用数据报目的 IP 地址的第三层数据报。
交换机的优点是即插即用,还具有相对高的分组过滤和转发速率。缺点是对于广播风暴并不提供任何保护措施(即如果某主机出了故障并传输没完没了的以太网广播帧流,该交换机将转发所有这些帧,使得整个以太网崩溃)。路由器的优点对第二层的广播风暴提供防火墙保护。缺点是不是即插即用的,需要进行配置才能使用,且路由器处理每个分组的时间通常比交换机更长,因为它需要处理高达第三层的字段。
6.4.4 虚拟局域网
具有等级结构如图6-15的交换局域网,具有以下缺点:
- 缺乏流量隔离。
- 交换机的无效使用。
- 管理用户。
**虚拟局域网(Virtula Local Network,VLAN)**可以用于解决以上难题。支持 VLAN 的交换机允许经一个单一的物理局域网基础设施定义多个虚拟局域网。在一个 VLAN 内的主机仿佛它们与交换机连接。在一个基于端口的 VLAN 中,交换机的端口(接口)由网络管理员来划分为组,每个组构成一个 VLAN,在每个 VLAN 中的端口形成一个广播域。
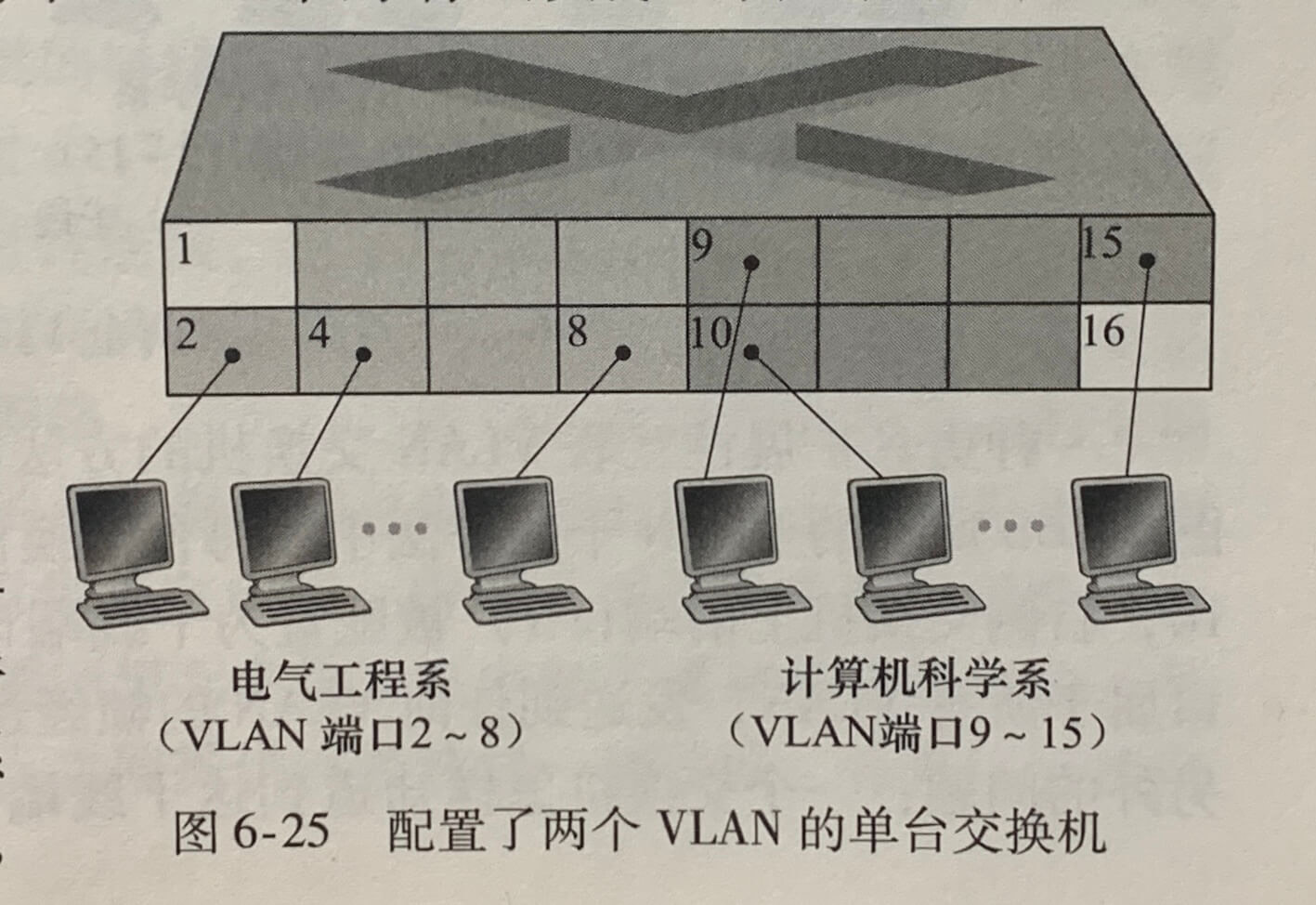
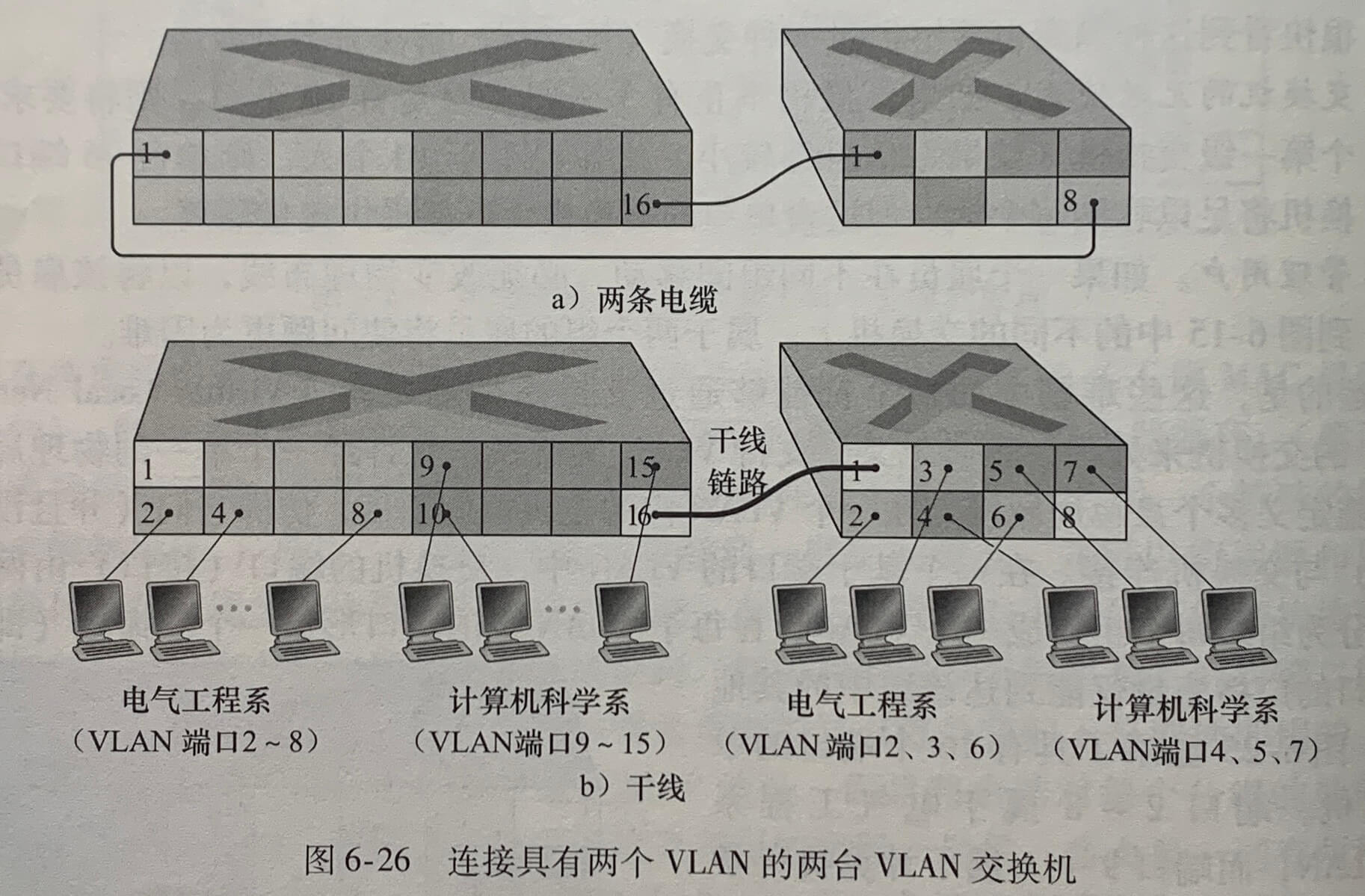
上图中,一种更具扩展性互联 VLAN 交换机的方法称为VLAN干线连接(VLAN trunking)。
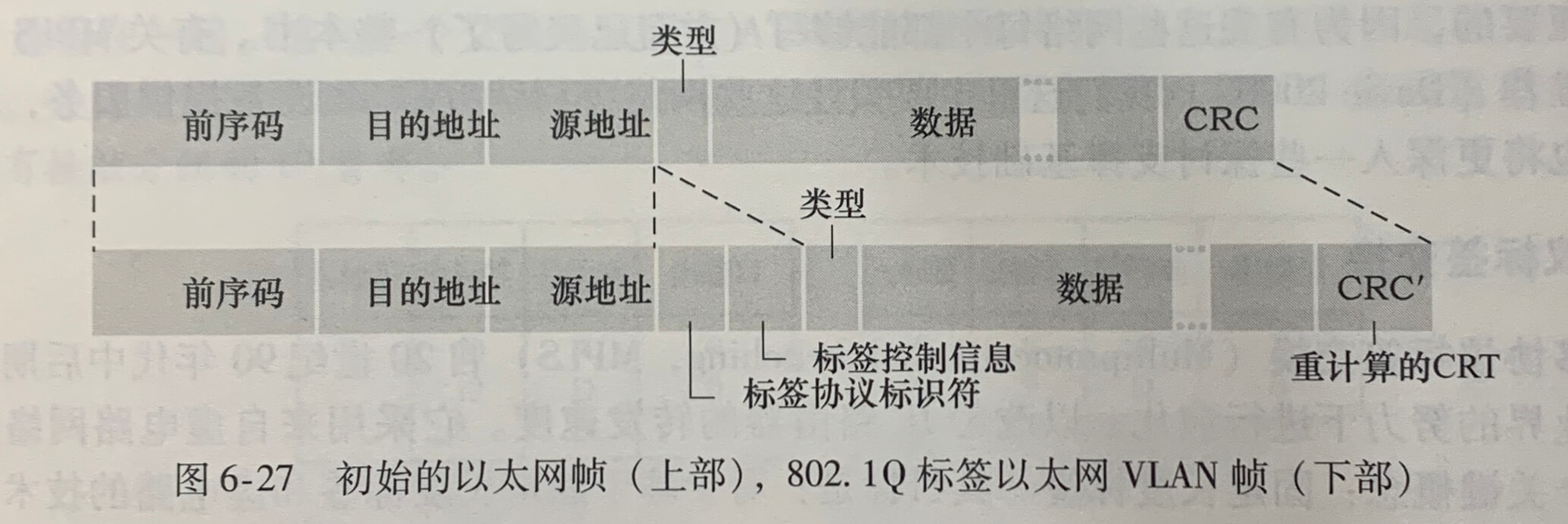
6.5 链路虚拟化:网络作为链路层
**多协议标签交换(Mutiprotocol Label Switching,MPLS)**网络是一种分组交换的虚电路网络,它们有自己的分组格式和转发行为。它自20世纪90年代中后期在一些产业界的努力下进行演化,以改善 IP 路由器的转发速度。它采用固定长度标签和虚电路的技术,在不放弃基于目的地 IP 数据报转发的基础设施前提下,当可能时通过选择性地标识数据报并允许路由器基于固定长度的标签(不基于IP地址)转发数据报来增强其功能。

上图中在第二层首部和第三层首部之间加入了 MPLS 首部。一个 MPLS 加强的帧仅能在两个均为 MPLS 使能的路由器(标签交换路由器)之间发送。
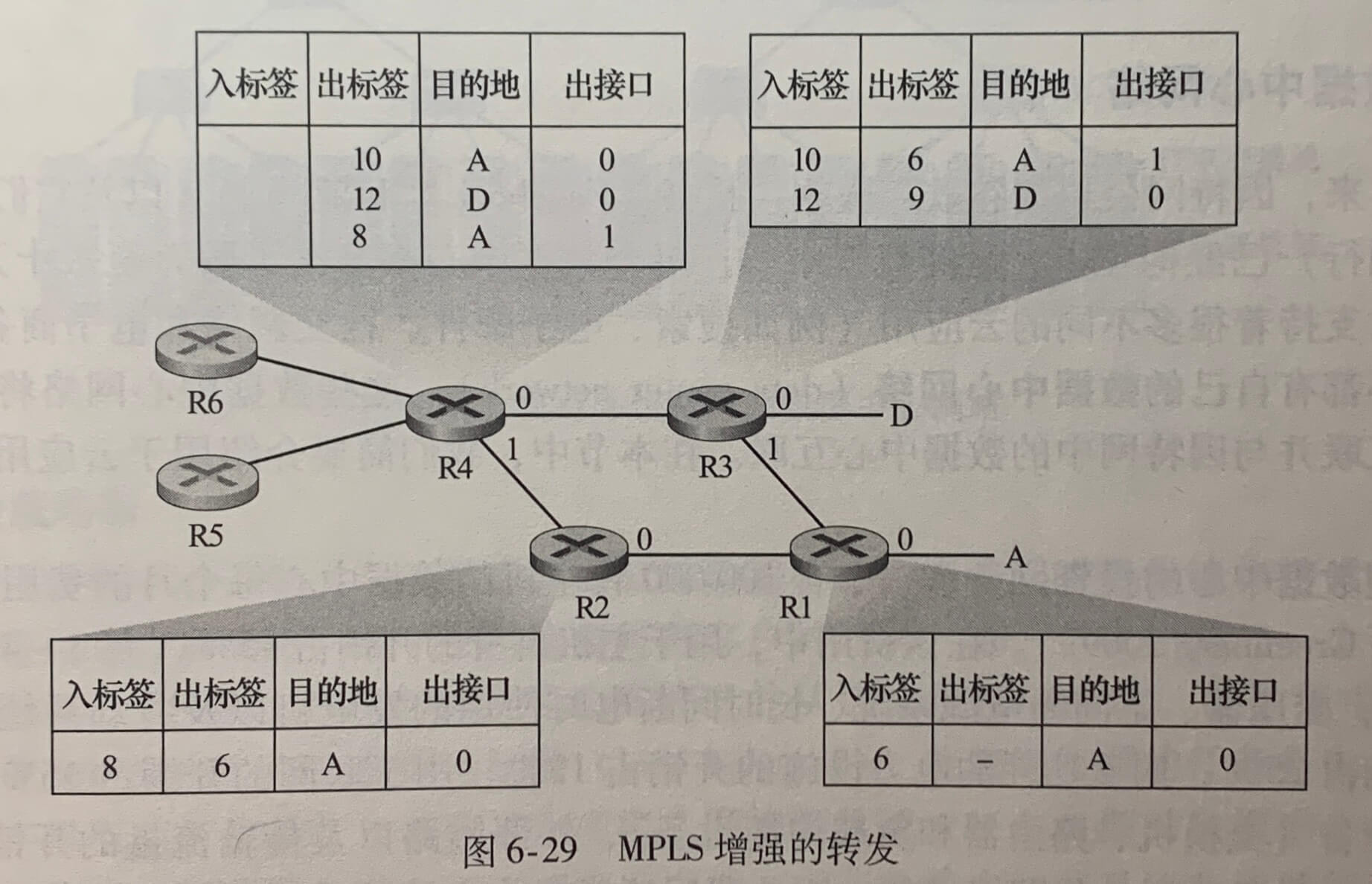
MPLS 能够并且被用于实现虚拟专用网(Virtual Private Network,VPN)。ISP 使用它的 MPLS 使能网络将用户的各种网络连接在一起。
6.6 数据中心网络
近年来,因特网公司如谷歌、微软、腾讯、阿里等等已经构建了大量的数据中心。每个数据中心都容纳了数万至数十万台主机,并且同时支持着很多不同的云应用。每个数据中心都有自己的数据中心网络(data center network),这些数据中心网络将其内部主机彼此互联并与因特网中的数据中心互联。
数据中心中的主机称为刀片(blade),一般是包括 CPU、内存和磁盘存储的商用主机。主机被堆叠在机架上,每个机架一般堆放20~40台刀片。在每个机架顶部有一台交换机,它们与机架上的主机互联,并与其他数据中心的其他交换机互联。机架上的每台主机都有一块与 TOR 交换机连接的网卡,每台 TOR 交换机有额外的端口能够与其他 TOR 交换机连接。目前主机通常用 40Gbps 的以太网连接到它们的 TOR 交换机。每台主机也会分配一个自己的数据中心内部的 IP 地址。
数据中心网络支持两种类型的流量:在外部客户与内部主机之间流动的流量,以及内部主机之间流动的流量。为了处理外部客户与内部主机之间流动的流量,数据中心网络包括了一台或多台边界路由器(border router),它们将数据中心网络与公共因特网相连。数据中心网络需要将所有机架彼此互联,并将机架与边界路由器连接。
1.负载均衡
一个云数据中心,如谷歌能同时提供搜索、电子邮件和视频等应用。每一个应用与一个 IP 关联。在数据中心内部,外部请求被定向到一个负载均衡器(load balancer)。负载均衡器负责向主机分发请求,以主机当前的负载作为函数来在主机之间均衡负载。负载均衡器常被称为“第四层交换机”。负载均衡器不仅平衡主机间的工作负载,还提供类似 NAT 的功能,将外部 IP 地址转换为内部适当主机的 IP 地址,然后将反方向流向客户的分组按照相反的转换进行处理。这防止客户直接接触主机,从而具有隐藏网络内部结构和防止客户直接与主机交互等安全性益处。
2.等级体系结构
等级体系结构的优点是支持快速扩容主机,缺点是随着层级越多,网络的速率在高并发时将越来越慢。
3.数据中心网络的发展趋势
为了降低数据中心的费用,同时提高其在时延和吞吐量上的性能,有以下几个发展趋势。
一种方法是采用**全连接拓扑(fully connected topology)**来替代交换机和路由器的等级结构。

另外一个主要的趋势就是采用基于船运集装箱的模块化数据中心(Modular Data Center,MDC)。在一个 MDC 中,在一个标准的 12 米船运集装箱内,工厂构建一个“迷你数据中心”并将集装箱运送到数据中心的位置。每一个集装箱都有多达数千台主机。多个集装箱彼此互联,同时也和因特网连接。
6.7 回顾:Web页面请求的历程

场景:Bob在他的便携机上访问www.google.com网站。
6.7.1 准备:DHCP、UDP、IP和以太网
假设Bob的便携机用一根以太网电缆连接到学校的以太网交换机,交换机与学校的路由器相连。学校的路由器与comcast.net的ISP相连。comcast ISP 为学校提供 DNS 服务。DHCP 服务器运行在路由器中。
首先 Bob 的便携机与网络相连时,DHCP 协议为便携机分配 IP 地址。
6.7.2 仍在准备:DNS和ARP
之后,便携机将通过 DNS 获取google的 IP 地址,首先发送 DNS 查询报文,发送报文通过网关路由器,为了获取网关路由器的MAC地址,使用 ARP 协议获取,之后将该帧发送到网关路由器(IP地址是 DNS 服务器的地址,MAC 地址是网关路由器的 MAC 地址)。
6.7.3 仍在准备:域内路由选择到DNS服务器
网关路由器接收该帧并抽取包含 DNS 查询的 IP 数据报,路由器查找转发表并将 IP 数据报放置到链路层帧中,发往 Comcast 的路由器。
DNS 服务器根据 IP 地址查询 DNS 数据库中的数据,假设该权威 DNS 服务器缓存了该记录,该 DNS 服务器发回一个主机名映射到 IP 地址的 DNS 回答报文。Bob的便携机从 DNS 报文中抽取主机名对应的 IP 地址。
6.7.4 Web客户-服务器交互:TCP和HTTP
便携机有了 IP 地址,它能够生成 TCP 套接字与google.com的 TCP 执行三次握手,便携机发送 SYN 报文段,服务器获取到 SYN 报文之后生成一个连接套接字,并产生一个 SYNACK 报文段并返回。便携机收到之后,终于可以开始向web服务器发送字节了,Bob的浏览器生成HTTP GET 报文,HTTP GET 报文则写入套接字,GET 报文成为一个 TCP 报文段的载荷,该 TCP 报文段放置进一个数据报中,并交付到www.google.com。
服务器获取到 HTTP GET 报文,生成一个 HTTP 响应报文,并将报文放进 TCP 套接字中并返回。最终Bob的Web浏览器从套接字读取 HTTP 响应,显示了 Web 页面。
第7章 无线网络和移动网络
7.1 概述
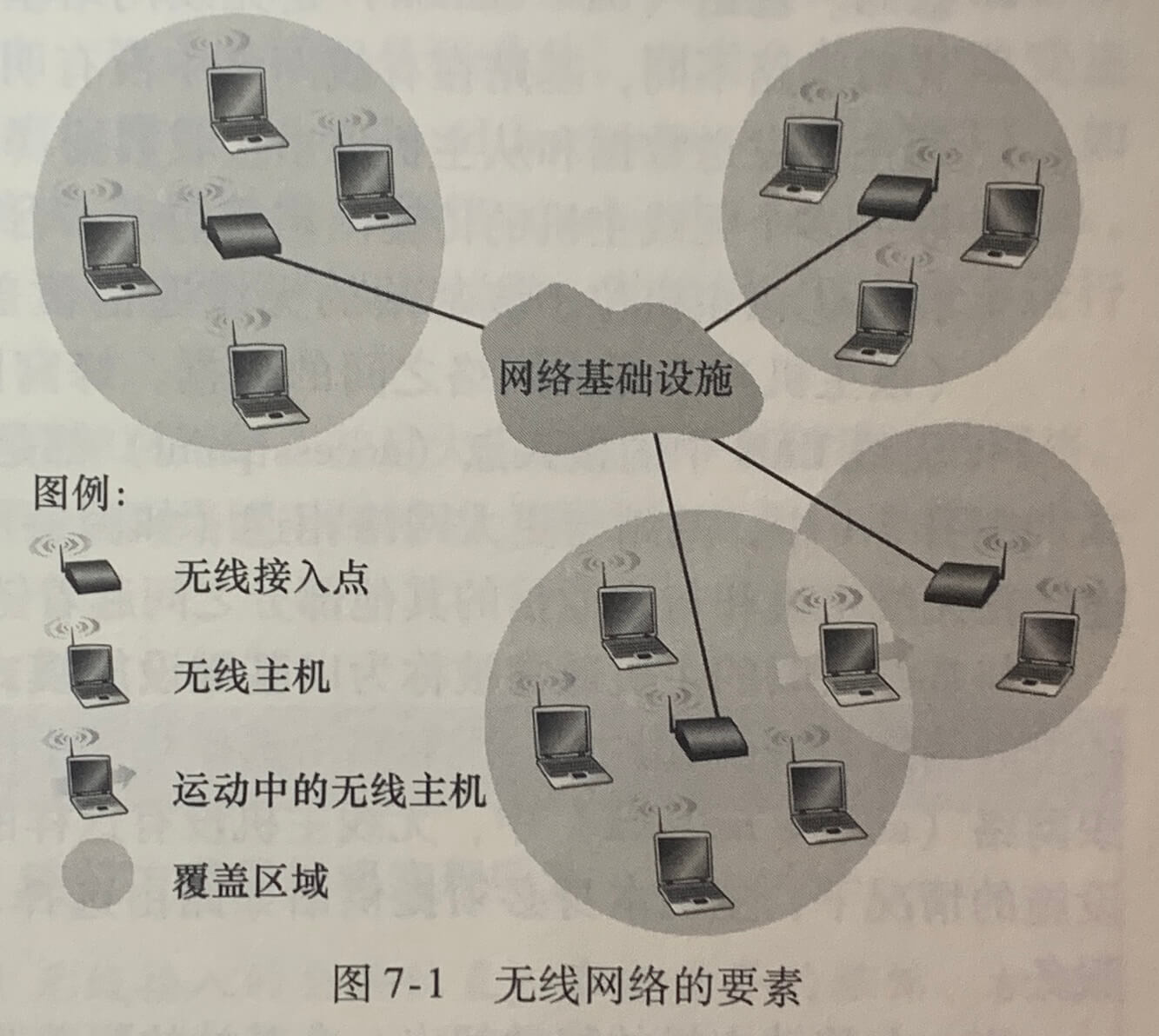
无线网络的要素:
-
无线主机。无线主机可以是便携机、掌上机、智能手机或者桌面计算机。
-
无线链路。主机通过无线通信链路连接到一个基站或者另一台无线主机。不同的无线链路技术具有不同的传输速率和能够传输不同的距离。
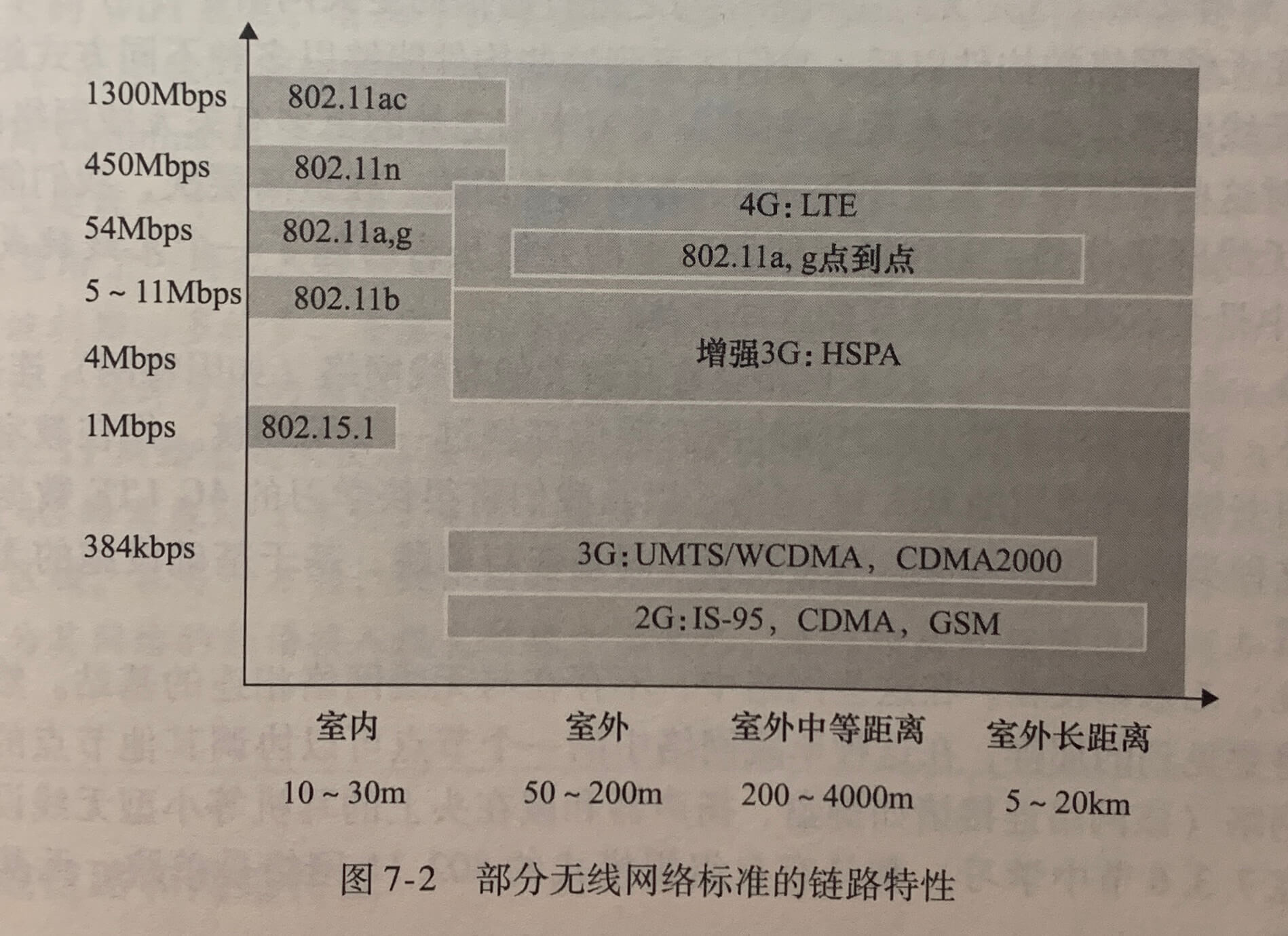
-
**基站(base station)是无线网络基础设施的一个关键部分。与无线主机和无线链路不同,基站在有线网络中没有明确的对应设备。它负责向与之关联的无线主机发送数据和从主机那接收数据。基站通常负责协调与之相关联的多个无线主机的传输。当我们说一台无线主机与某基站“相关联”时,则是指:1.该主机位于该基站的无线通信覆盖范围内;2.该主机使用该基站中继它和更大网络之间的数据。蜂窝网络中的蜂窝塔(cell tower)**和802.11 无线 LAN 中的接入点都是基站的例子。
与基站关联的主机通常被称为以**基础设施模式(infrastructure mode)**运行,所有传统的网络服务(如地址分配和路由选择)都由网络向通过基站相连的主机提供。
当一台移动主机和移动超过一个基站的覆盖范围而到达另一个基站的覆盖范围后,它将改变其接入到更大网络的连接点。
-
网络基础设施。这是无线主机希望与之进行通信的更大网络。
在最高层次,根据两个准则来对无线网络分类:1.在该无线网络中的分组是否跨越一个无线跳或多个无线跳;2.网络中是否有诸如基站这样的基础设施。
-
单跳,基于基础设施。这些网络具有与较大的有线网络(如因特网)连接的基站。该基础与无线主机之间的所有通信都经过一个无线跳。在家、咖啡屋所使用的802.11网络,以及4G LTE 数据网络都属于这种类型。
-
单跳,无基础设施。在这些网络中,不存在与无线网络相连的基站。在这种单跳网络中的一个节点可以协调其他节点的传输。蓝牙网络和具有自组织模式的802.11网络是单跳、无基础设施的网络。
-
多跳,基于基础设施。在这些网络中,一个基站表现为以有线方式与较大网络相连。某些无线传感网络和所谓**无线网状网络(wireless mesh network)**就属于这种类型。
-
多跳,无基础设施。在这些网络中没有基站,并且节点为了到达目的地可能必须在几个其他无线节点之间中继报文。节点也可能是移动的,在多个节点中改变连接关系,一类网络被称为移动自组织网络(mobile ad hoc network,MANET)。
7.2 无线链路和网络特征
有线链路和无线链路的重要区别:
- 递减的信号强度。电磁波在穿过物体时强度将减弱。即使在自由空间中,信号仍将扩散,信号强度随着发送方和接收方距离的增加而减弱(路径损耗)。
- 来自其他源的干扰。在同一频段发送信号的电波源将相互干扰。
- 多径传播。当电磁波的一部分受物体和地面反射,在发送方和接收方之间走了不同长度的路径,则会出现多径传播(multipath propagation),这使得接收方的信号变得模糊。
无线链路中的比特差错将比有线链路中更为常见。因此,无线链路协议不仅采用有效的 CRC 错误检测码,害采用了链路层的 ARQ 协议来重传受损的帧。
接收无线信号的主机收到一个电磁信号,而该信号是发送方传输的初始信号的退化形式和环境中的背景噪声的结合,其中的信号退化是由于衰减和多路径传播以及其他因素所引起的。**信噪比(Signal-to-Noise Ratio,SNR)**是所收到的信号和噪声强度的相对测量。SNR 的度量单位通常是分贝(dB)。
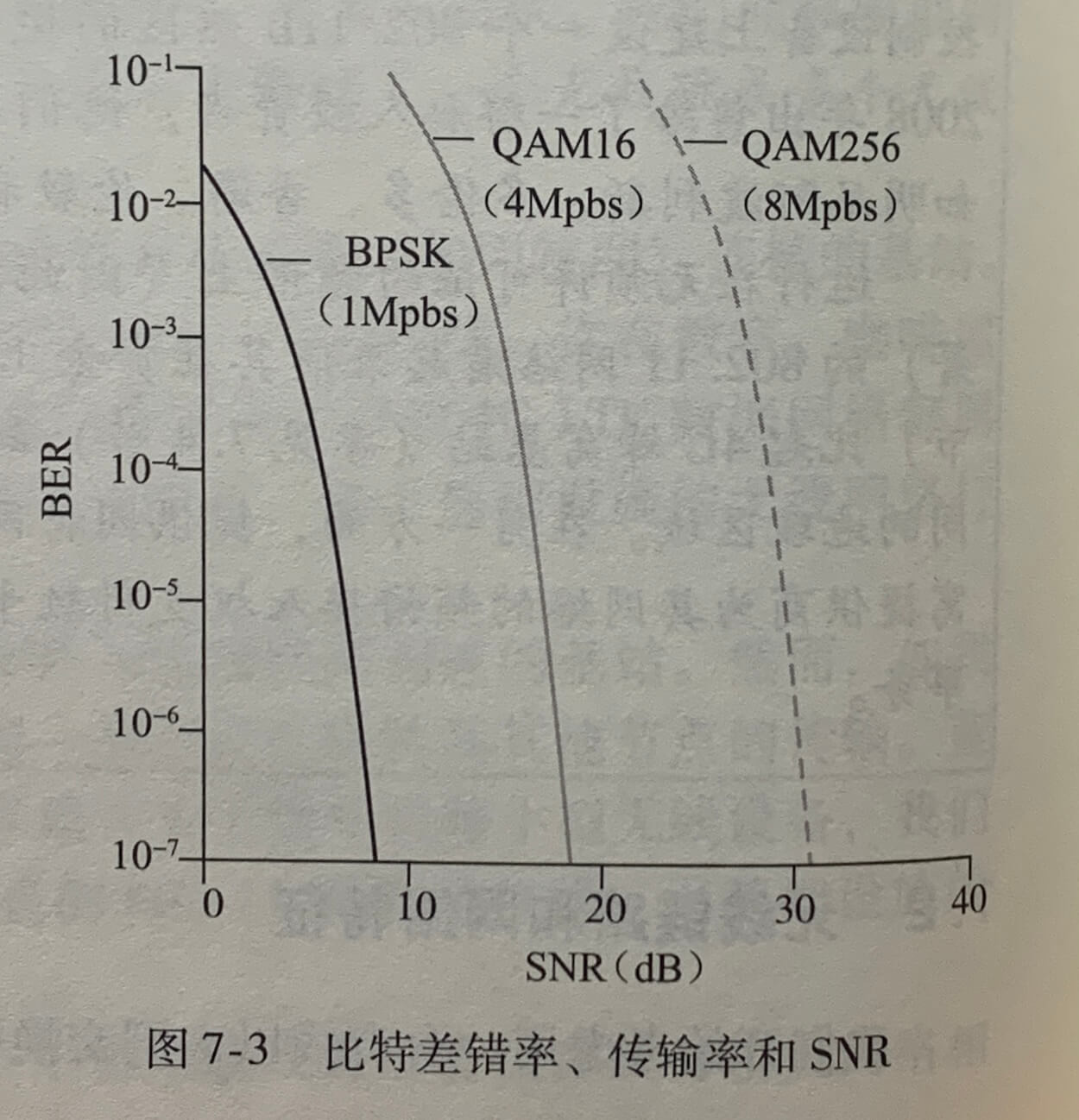
- 对于给定的调制方案,SNR 越高,比特率差错(BER)越低。发送方增加它的输出功率就能够增加 SNR。当该功率超过某个阀值时,几乎不会有实际增益。
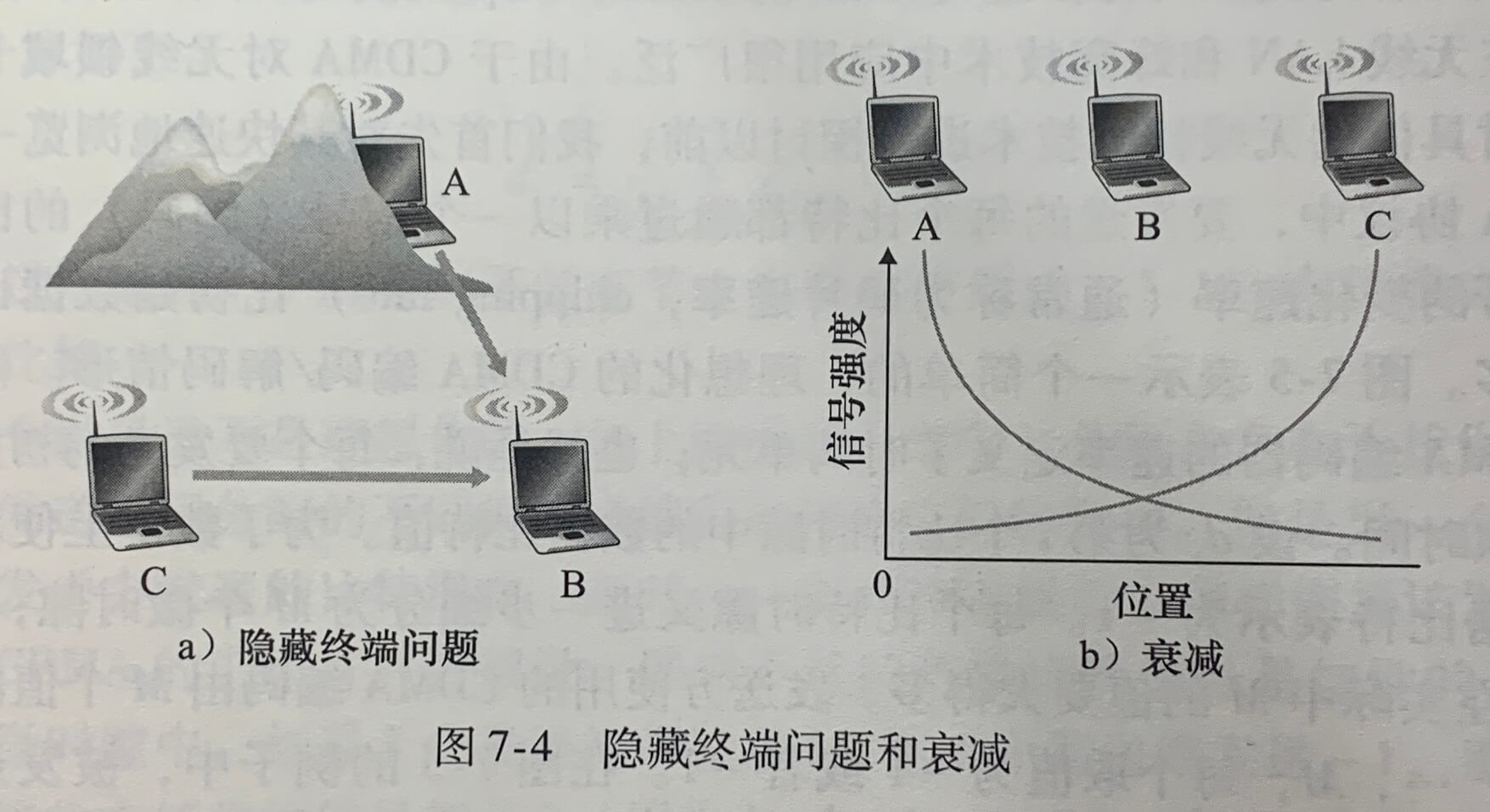
上图中,假设A和C在向B传输数据,环境的物理阻挡可能会妨碍A和C互相听到对方的传输。隐藏终端问题和衰减使得多路访问在无线网络中的复杂性远高于在有线网络的情况。
码分多址(CDMA)
码分多址属于信道划分协议族,它在无线 LAN 和蜂窝技术中应用广泛。在 CDMA 协议中,要发送的每个比特都通过乘以一个信号(编码)的比特来进行编写,这个信号的变化速率(码片速率)比初始数据比特序列的变化速率快得多。

码分多址的优点在于能忽略来自其他发送方的干扰,哪怕几个发送方同时在传输数据,接收方都能根据聚合的信号恢复一个给定的发送方发送的数据。
7.3 WiFi:802.11无线LAN
**IEEE 802.11 无线LAN(也称WiFi)**协议族中有几套有关无线 LAN 的 802.11 标准。
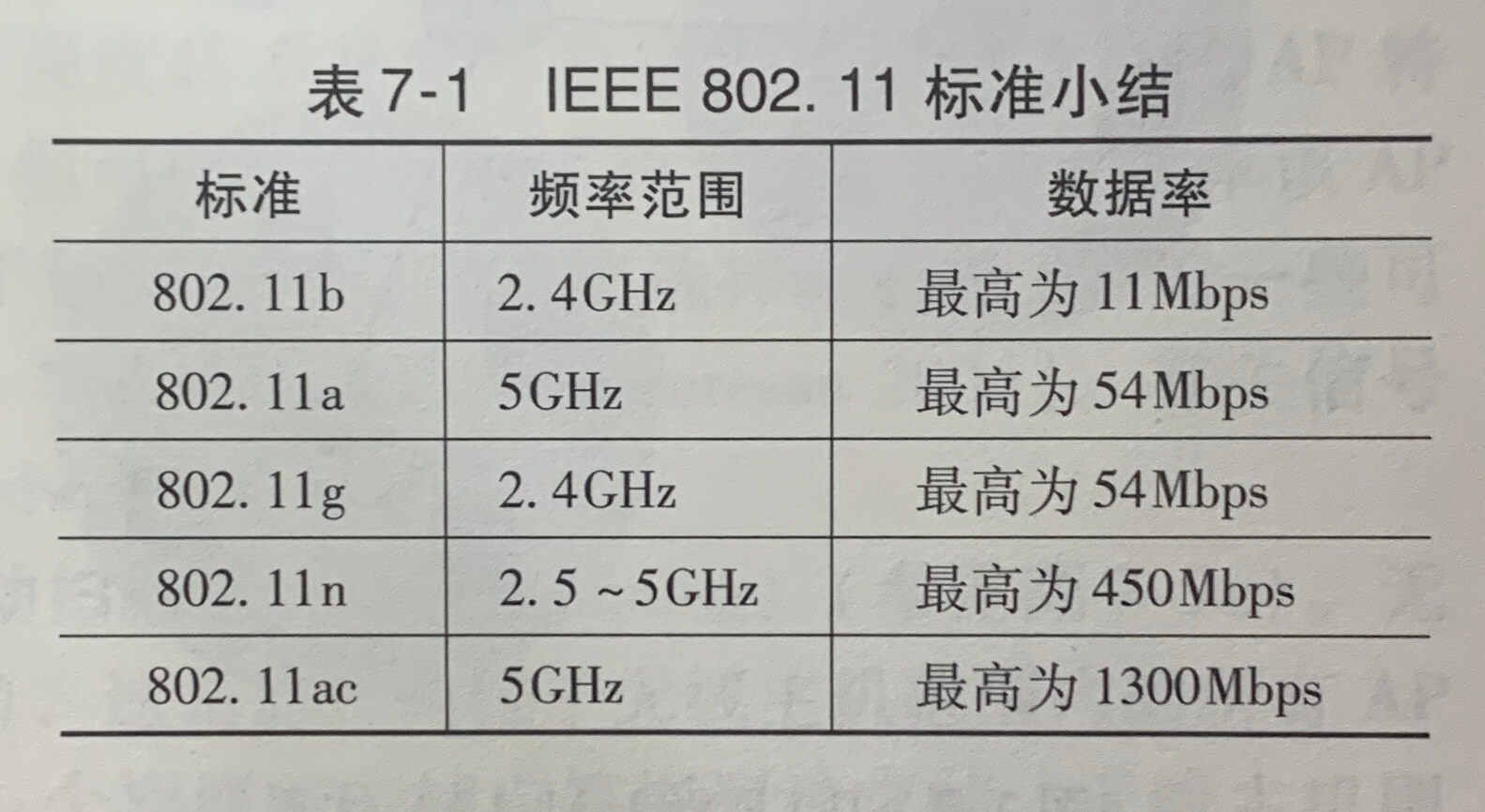
不同的802.11标准具有相同的媒体访问协议CSMA/CA和相同的帧结构,它们还具有减少其传输速率的能力以伸展到更远的距离,而且还支持向后兼容。
2.4GHz频段是一种无须执照的频段,在此频段上,使用2.4GHz的电话和微波炉等802.11设备可能会争用该频段的频谱。在5GHz频段,对于给定的功率等级802.11 LAN有更短的传输距离,并且受多径传播的影响更大。
7.3.1 802.11体系结构

802.11体系结构的基本构件模式是基本服务集(Basic Service Set,BSS),一个 BSS 包含一个或多个无线站点和一个称为接入点(Access Point,AP)的中央基站(base station)。
与以太网设备类似,每个 802.11 无线站点都具有一个6字节的 MAC 地址,该地址存储在该站适配器(即 802.11 网络接口卡)的固件中,每个 AP 的无线接口也具有一个 MAC 地址。该地址由 IEEE 管理。
信道与关联
当网络管理员安装一个 AP 时,管理员为该接入点分配一个单字或双字的服务集标识符(Service Set Identifier,SSID)(相当于 WiFi 名称)。管理员还需要为该 AP 分配一个信道号,比如2.4GHz或5GHz。在85MHz的频段内,802.11 定义了11个部分重叠的信道。当且仅当两个信道由4个或更多信道隔开时它们才无重叠。
802.11 标准要求每个 AP 周期性地发送信标帧(beacon frame),每个信标帧包括该 AP 的 SSID 和 MAC 地址。无线站点为了得知正在发送信标帧的 AP,扫描11个信道,找出来自可能位于该区域的 AP 所发出的信标帧。通过信标帧了解到可用 AP 后,无线主机选择一个 AP 用于关联。
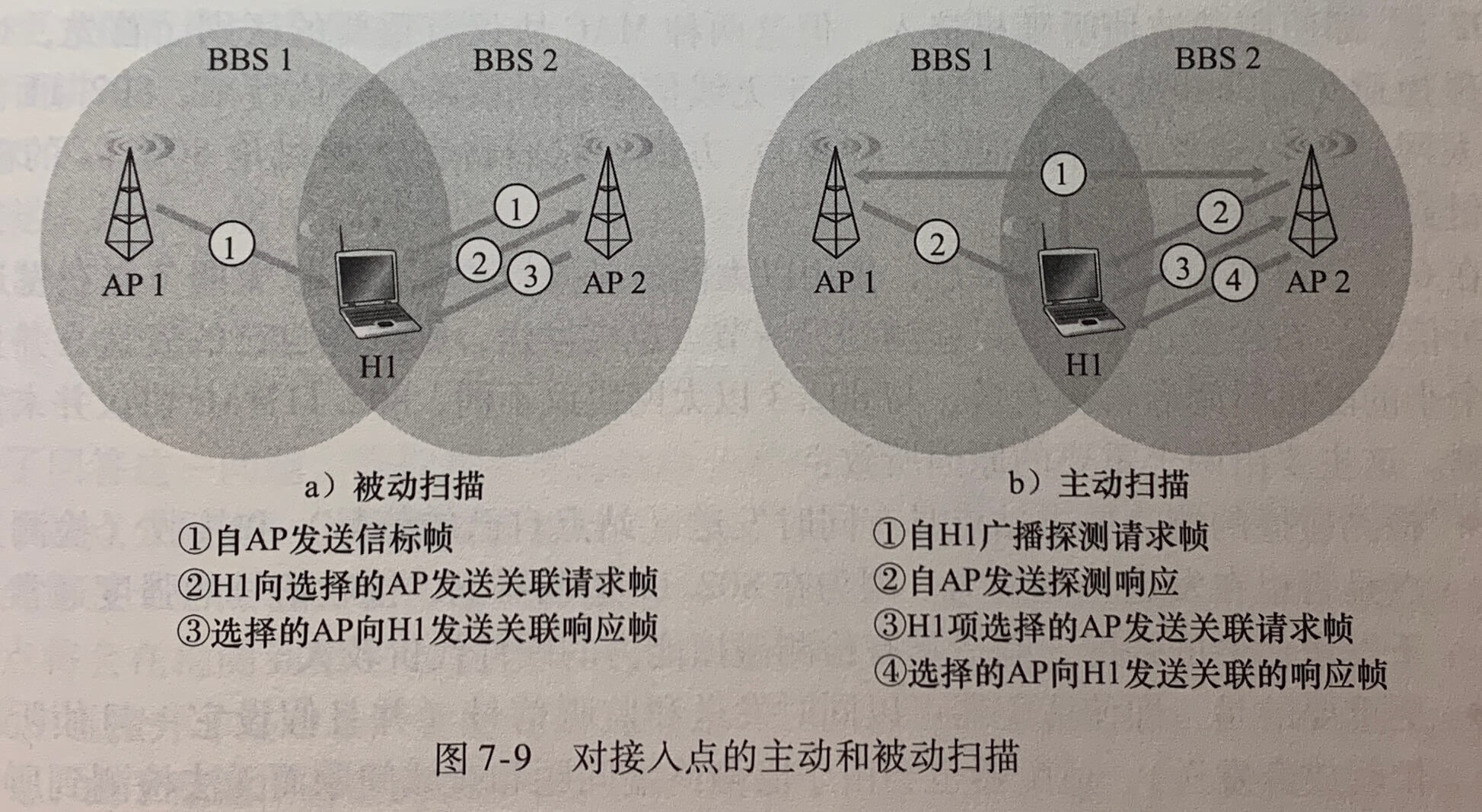
上图中,扫描信道和监听信标帧的过程被称为被动扫描(passive scanning)。无线主机也通过广播探测帧才实现主动扫描(active scanning)。
7.3.2 802.11 MAC地址
因为许多无线设备或 AP 自身可能希望同时经过相同信道传输数据帧,因此需要一个多路访问协议来协调传输。802.11 无线LAN使用的多路访问协议是 CSMA/CA(带碰撞避免的载波侦听多路访问)。由于无线信道具有相对较高的误比特率,因此 802.11 相比以太网使用了链路层确认/重传(ARQ)方案。
与 802.3 以太网协议不同,802.11 MAC 协议并未实现碰撞检测,有两个主要原因:
- 检测碰撞的能力要求站点具有同时发送和接收的能力,在 802.11 适配器上,接收信号的强度通常远远小于发送信号的强度。
- 适配器由于隐藏终端问题和衰减问题而无法检测到所有的碰撞。

由于802.11 无线 LAN 不使用碰撞检测,一旦站点开始发送一个帧,它就完全的发送该帧(即不会停下来),所以 802.11 会尽可能避免碰撞。802.11 MAC 使用**链路层确认(link-layer acknowledgment)**方案,目的站点收到一个通过 CRC 校验的帧后,它等待一个短帧间间隔(SIFS)的一小段时间,然后发回一个确认帧。如果发送站点在给定的时间内未收到确认帧,它假定出现了错误并重传该帧。
1.处理隐藏终端:RTS和CTS
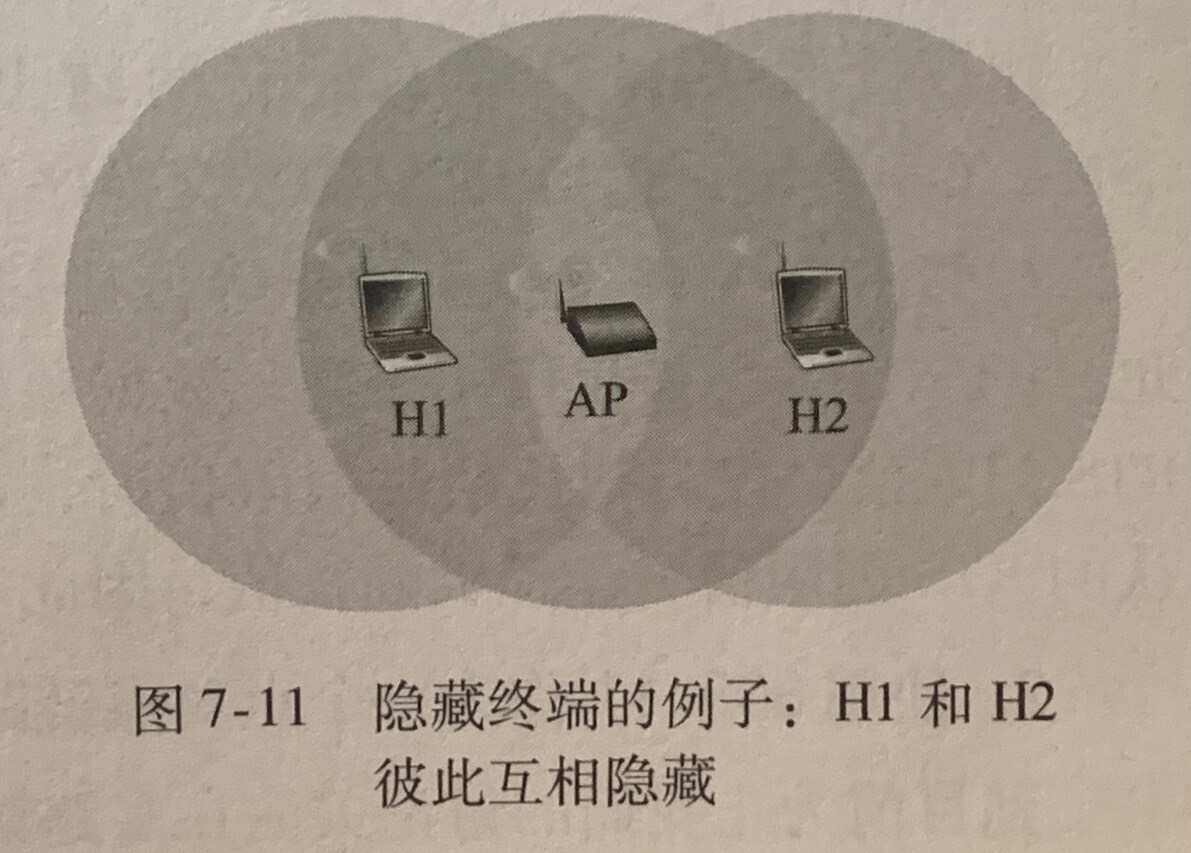
上图中,尽管每个无线站点对 AP 都不隐藏,两者彼此却是隐藏的。为了在隐藏终端情况下避免碰撞,IEEE 802.11 协议允许站点使用一个短**请求发送(Request to Send,RTS)控制帧和一个短允许发送(Clear to Send,CTS)**控制帧来预约对信道的访问。
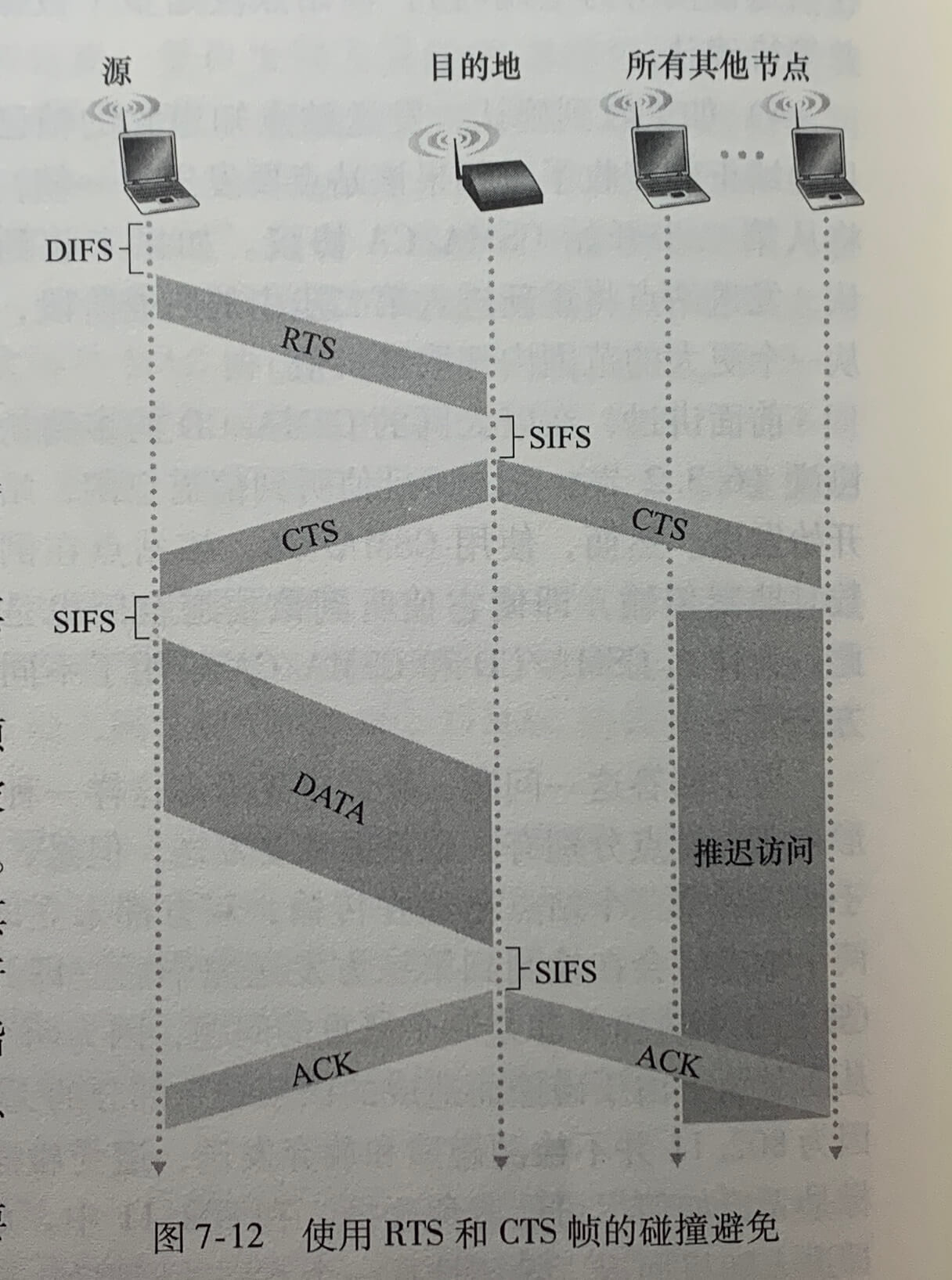
当发送方要发送一个 DATA 帧时,它先向 AP 发送一个 RTS 帧,指示传输 DATA 帧和确认(ACK)帧需要的总时间。当 AP 收到 RTS 帧后,它广播一个 CTS 帧作为响应。该帧由两个目的:给发送方明确的发送许可,也指示其他站点在预约期内不要发送。
RTS 和 CTS 的使用能够在两个重要方面提高性能:
- 隐藏终端问题被环境了,因为长 DATA 帧只有在信道预约后才被传输。
- 因为 RTS 和 CTS 帧较短,涉及 RTS 和 CTS 帧的碰撞将仅持续短 RTS 和 CTS 帧的持续期。
RTS/CTS 交换仅仅用于为长数据帧预约信道,在实际中,每个无线站点可以设置一个 RTS 门限值,仅当帧超过门限值时,才使用 RTS/CTS 序列。
7.3.3 IEEE 802.11帧

在上图中,帧上面的数字代表以字节计的长度。在帧控制字段中,每个子字段上面的数字代表以比特计的长度。
-
有效载荷和CRC字段
帧的核心是有效载荷,它通常是由一个 IP 数据报或者 ARP 分组组成。尽管这一字段允许的最大长度为 2312 字段,但它通常小于 1500 字节。CRC 可以让接收方检测所收到帧中的比特错误。
-
地址字段
802.11 帧有4个地址字段,每个字段包含6字节的 MAC 地址。地址4用于在自组织模式下互相转发。
- 地址2是传输该帧的站点的 MAC 地址。
- 地址1是要接收该帧的无线站点的 MAC 地址。
- 地址3是在 BSS(基本服务集)中路由器接口的 MAC 地址。
AP 是链路层设备,它不能理解 IP 地址,必须连接路由器才能通网。
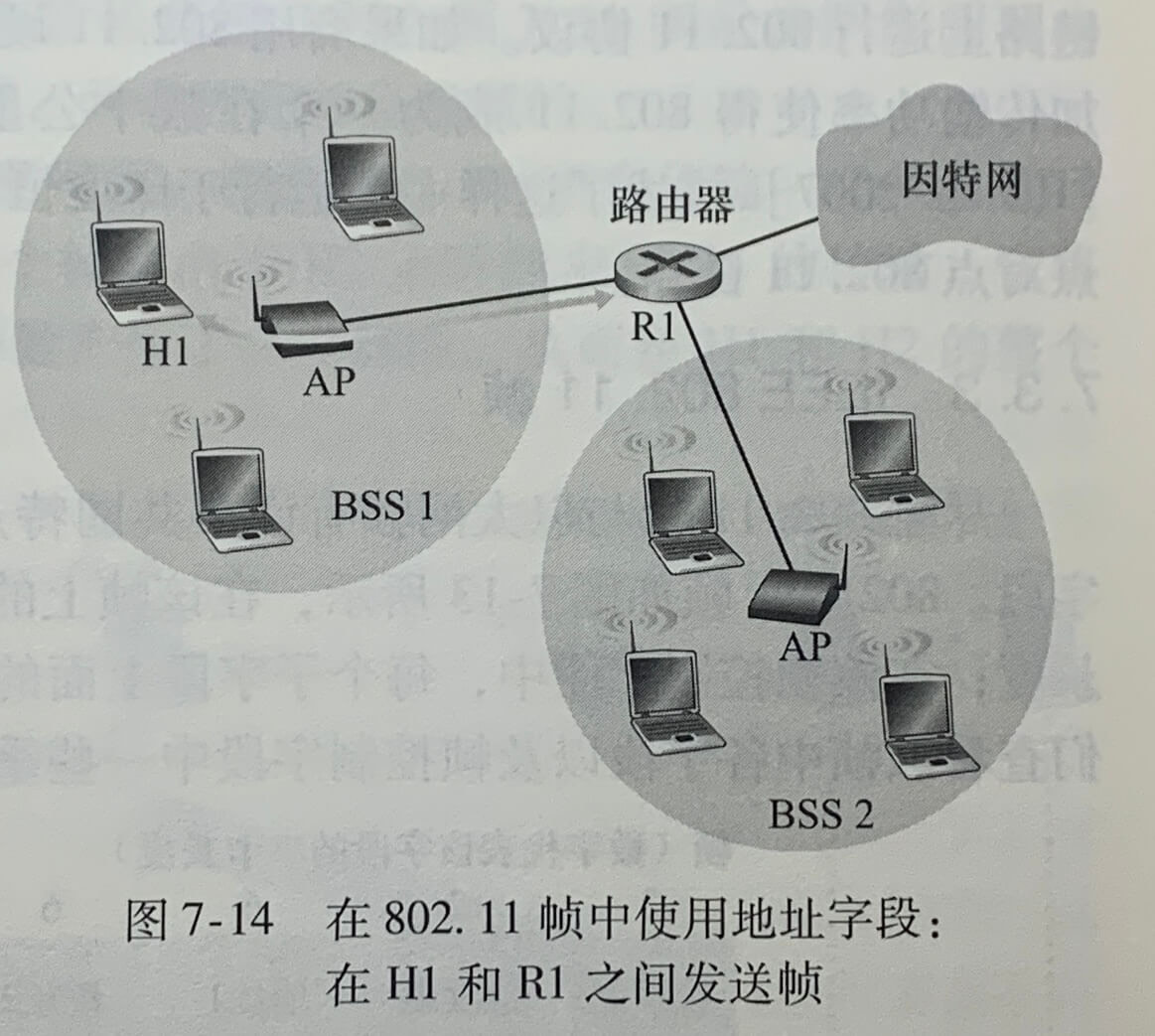
上图中,考虑H1发送数据报到R1的过程,H1生成一个 802.11 帧,H1的 MAC 地址为地址1,AP的 MAC 地址为地址2,R1的 MAC 地址为地址3。当 AP 接收到该帧后,将其转换成以太网帧,该帧的源地址是 H1的 MAC 地址,目的地址是 R1 的 MAC 地址。
地址3在 BSS 和有线局域网互联中起着关键作用。
-
序号、持续期和帧控制字段
使用序号可以使接收方区分新传输的帧和以前帧的重传。802.11 帧中的序号字段在链路层与第3章中运输层中的该字段有着完全相同的目的。
持续期值的作用是预约信道的时间。(在数据帧和 RTS 及 CTS 帧中均存在)。
帧控制中,类型和子类型字段用于区分关联、RTS、CTS、ACK和数据帧。WEP 字段指示是否使用加密。
7.3.4 在相同的IP子网中的移动性
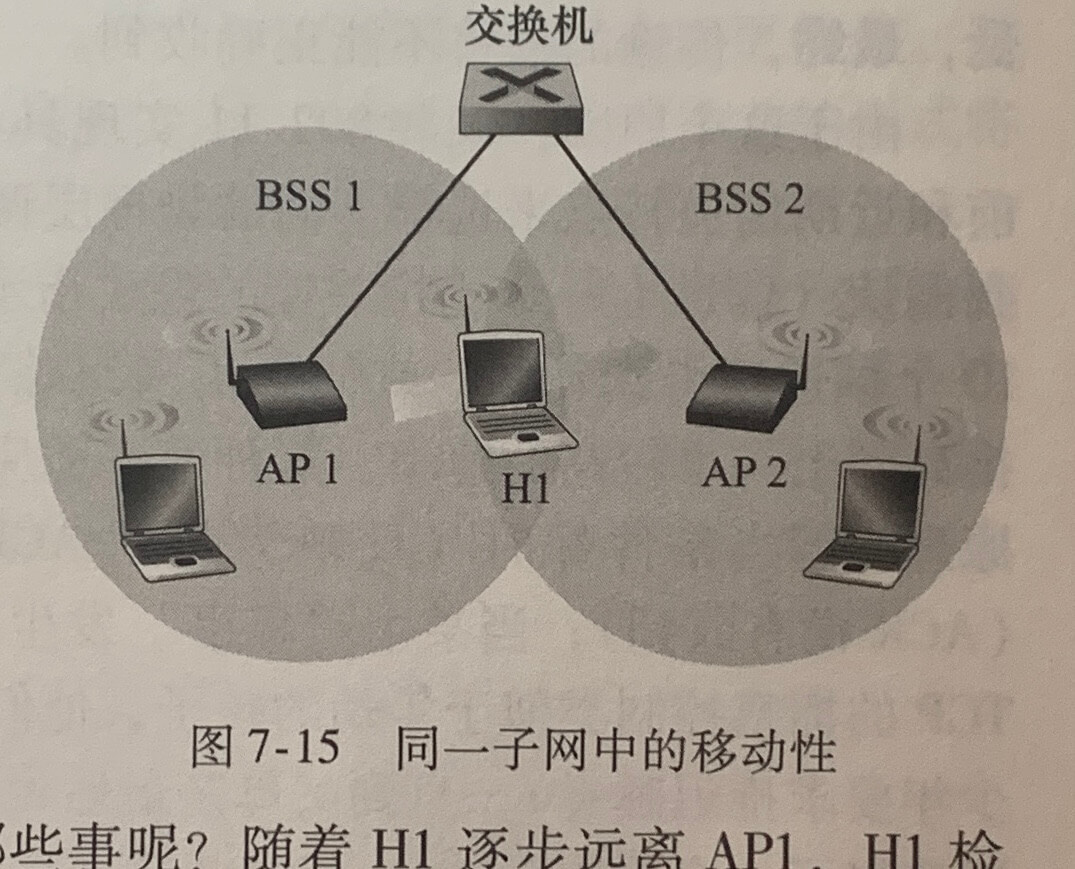
考虑H1在两个BSS(基础服务集)之间移动,由于两个AP连接的是交换机,所以它们属于同一个IP子网,目前802.11f标准小组正在开发一个 AP 间的协议来处理这些以及相关的问题。
7.3.5 802.11中的高级特色
以下讲的能力并不是完全特定于 802.11 标准,这是由不同的厂商来实现,以便提高他们的竞争能力。
-
802.11速率适应
由于离基站越远,SNR(信噪比)越低,BER(误比特率)将越来越高,最终,传输的帧将不能正确收到。一种速率自适应能力可以用于解决次问题,它与 TCP 的拥塞控制原理有些相似,根据 ACK 来提高或降低传输速率。
-
功率管理
7.3.6 个人域网络:蓝牙和ZigBee
-
蓝牙
IEEE 802.15.1 网络以低功率和低成本在小范围内运行。它本质上是一个低功率、小范围、低速率的“电缆替代”技术,用于计算机与无线键盘、鼠标或其他外部设备扬声器、头戴式耳机等互联,而 802.11 是一个较高功率、中等范围、较高速率的“接入”技术。802.15.1 网络有时被称为无线个人域网络(Wireless Personal Area Network,WPAN)。
802.15.1 网络以 TDM 方式工作于无须许可证的 2.4GHz 无线电波段,每个时隙长度为625μs。在每个时隙内,发送方利用79个信道中的一个进行传输,同时从时隙到时隙以一个已知的伪随机方式变更信道。这种被称作**跳频扩展频谱(FHSS)**的信道跳动的形式将传输及时扩展到整个频谱。802.15.1 提供高达 4Mbps 的速率。
802.15.1 网络是自组织网络。不需要网络基础设施来互联 802.15.1 设备。
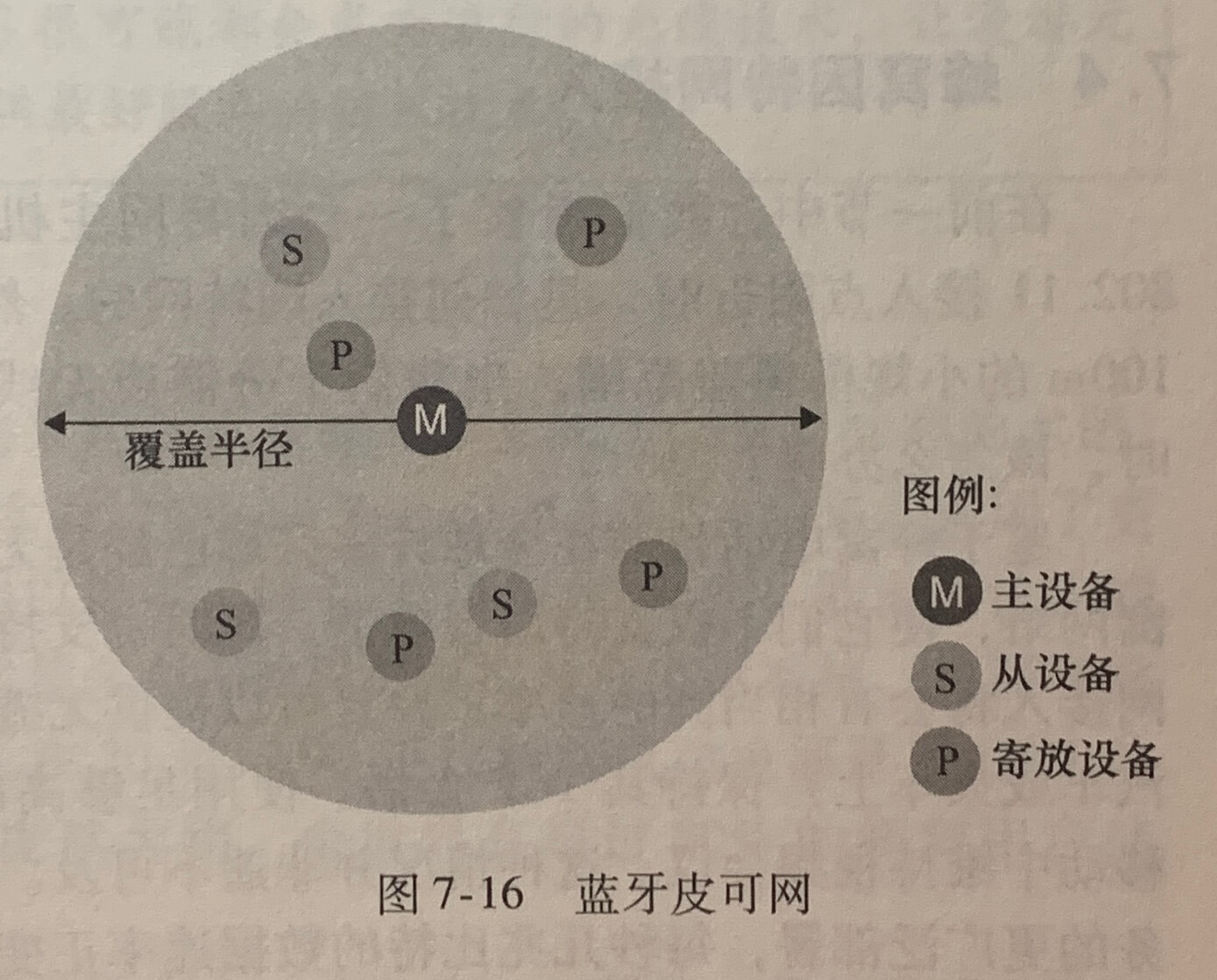
-
ZigBee
802.14.5 被称为ZigBee,ZigBee 较之蓝牙其服务目标是低功率、低数据率、低工作周期的应用。ZigBee 适合如家庭温度和光线传感器等非常简单、低功率、低工作周期、低成本设备。ZigBee定义了20kbps、40kbps、100kbps和250kpbs的信道速率,这取决于信道的频率。
7.4 蜂窝因特网接入
7.4.1 蜂窝网体系结构概述
全世界有超过80%的蜂窝用户使用全球移动通信系统(GSM)。GSM被分类为几代,第一代(1G)系统是模拟 FDMA 系统,其专门用于语音通信,目前几乎绝迹。初始的 2G 系统也是为语音而设计,但后来还拓展了数据(即因特网)的支持(2.5G)。3G 系统也支持语音和数据,但更为强调数据能力和更高速的无线电接入链路。4G系统基于 LTE 技术,其特征为全 IP 核心网络。
2G 蜂窝网体系结构:语音与电话网连接
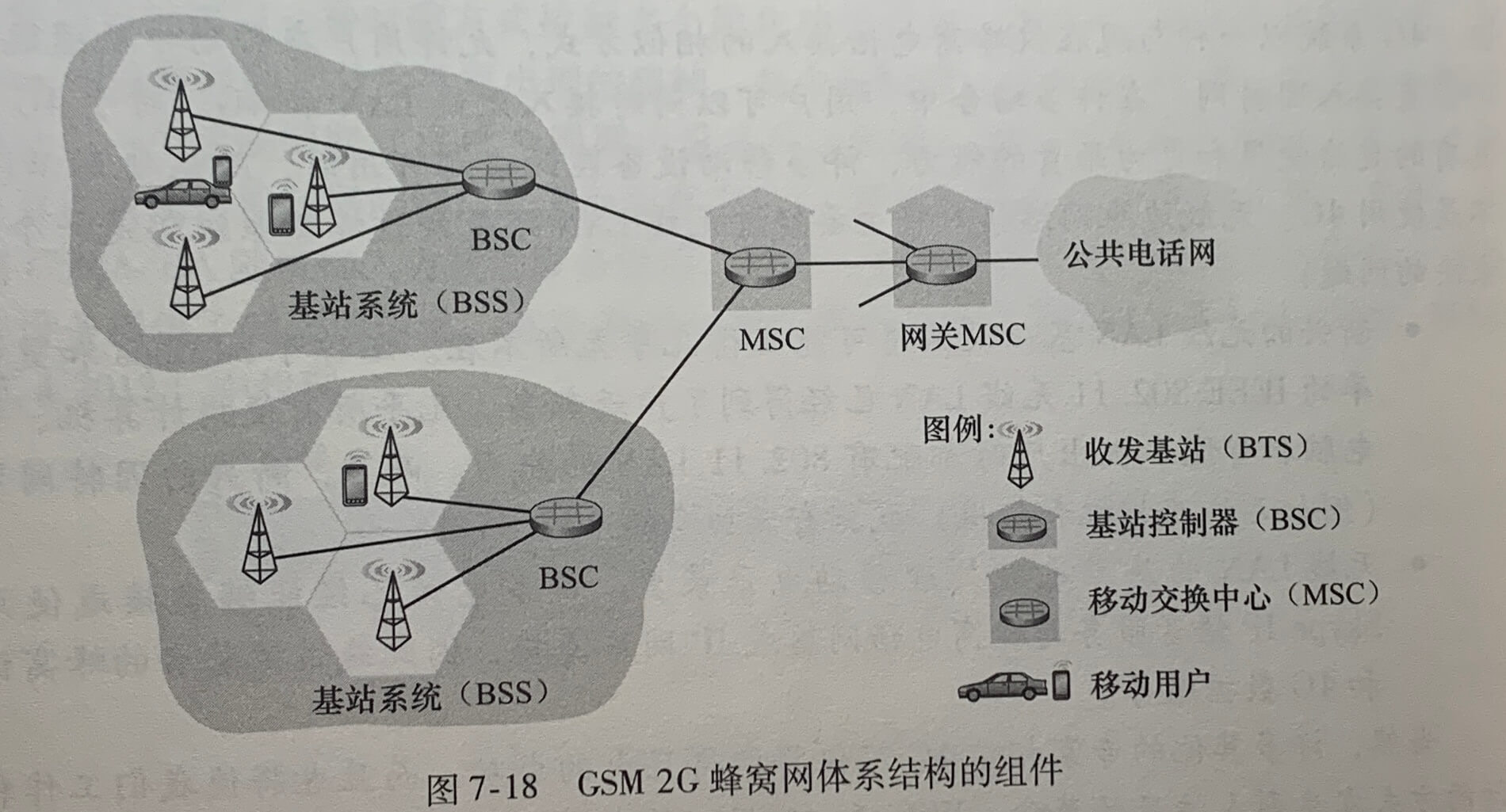
一个蜂窝(cellular)网覆盖的区域被分成许多称作小区(cell)的地理覆盖区域。每个小区包含一个收发基站(Base Transceiver Station,BTS),负责向位于小区内的移动站点发送或接收信号。一个小区的覆盖区域取决于 BTS 的发射功率、用户设备的传输功率、小区中的障碍建筑以及基站天线的高度。
2G 蜂窝系统的 GSM标准对空中接口使用了组合的 FDM/TDM(无线电)。GSM 系统由多个 200kHz 的频带组成,每个频带支持8个 TDM 呼叫。GSM 以 13kbps 和 12.2kbps 的速率编码。
一个 GSM 网络的基站控制器(Base Station Controller,BSC)通常服务与几十个收发基站。BSC 的责任是为移动用户分配 BTS 无线信道,执行寻呼(paging),执行移动用户的切换。基站控制器及其控制的收发基站共同构成了GSM基站系统(Base Station System,BSS)。
在用户鉴别和账户管理以及呼叫建立和切换中,**移动交换中心(Mobile Switching Center,MSC)**起着决定性的作用。
7.4.2 3G蜂窝数据网:将因特网扩展到蜂窝用户

1.3G核心网
3G核心蜂窝数据网将无线电接入网连接到公共因特网。核心网与蜂窝语音网的组件协作。不去触动现有核心 GSM 蜂窝语音网,增加与现有蜂窝语音网平行的附加蜂窝数据功能。
3G核心网有两类节点:服务通用分组无线服务支持节点(SGSN)和网关GPRS支持节点(GGSN)。GPRS表示分组无线服务,这是一种在2G网络中的早期蜂窝数据服务。SGSN负责向位于其连接的无线电接入网中的移动节点交付数据报。GGSN起着网关的作用,将多规格SGSN连接到更大的因特网。
2.3G无线电接入网:无线边缘
**3G无线电接入网(radio access network)**是我们作为3G用户看见的无线第一跳网络。**无线电网络控制器(Radio Network Controller,RNC)**通常控制几个小区的收发基站。
7.4.3 走向4G:LTE
4G 较之 3G 有两个重要的创新:一个全 IP 核心网和一个加强的无线电接入网。
1.4G系统体系结构:一个全IP核心网
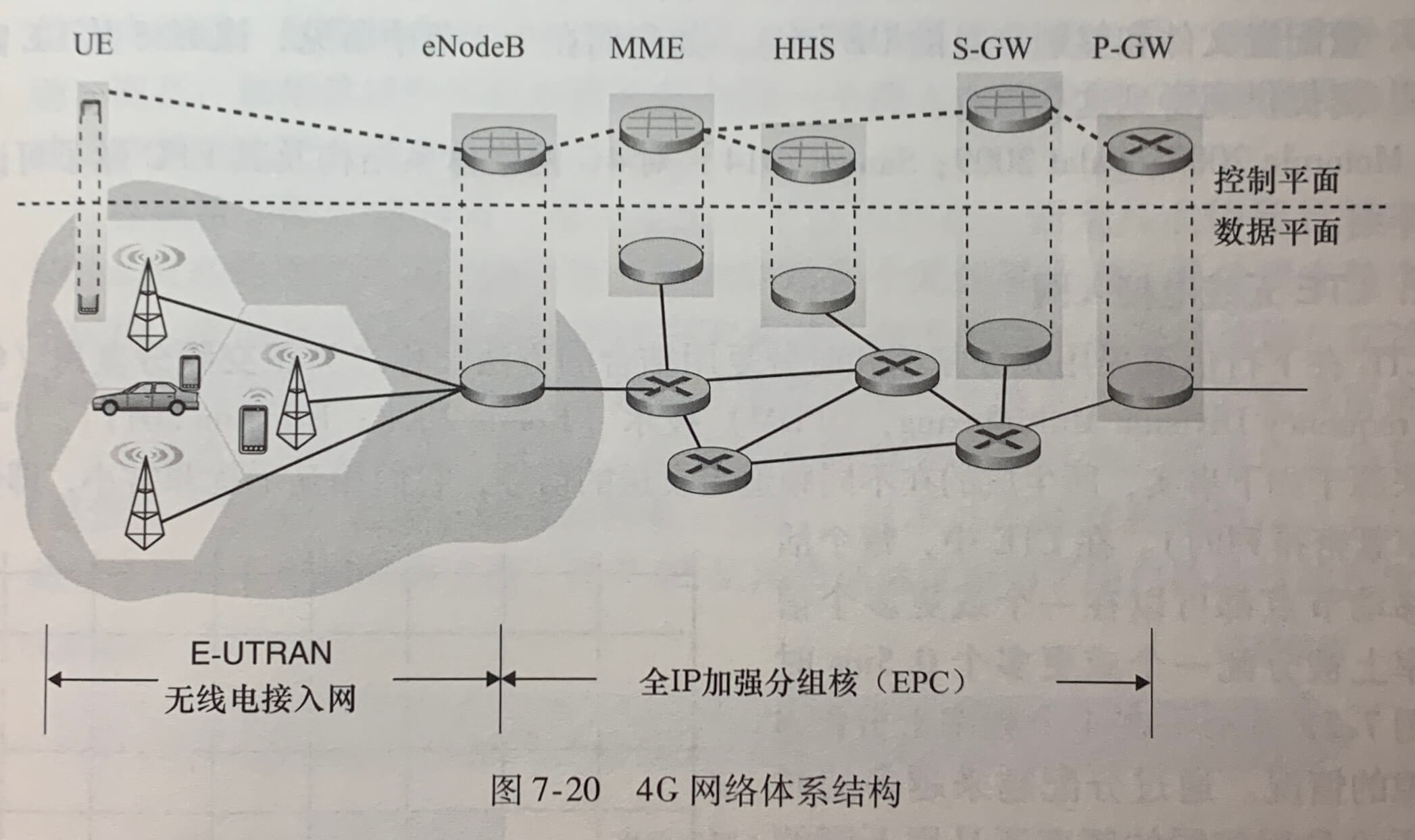
4G 体系结构有两个重要的高层次观察:
- 一种统一的、全 IP 网络体系结构。全部包括语音和数据都承载在 IP 数据报中。
- 4G 数据平面与 4G 控制平面的清晰分离。
- 无线电接入网与全 IP 核心网之间的清晰分离。
4G 体系结构的主要组件如下:
- eNodeB是 2G 基站和 3G 无线电网络控制器的逻辑后代。它的数据平面作用是在 UE(用户)和 P-GW(网关)之间(经 LTE 无线电接入网)转发数据报。UE 数据报在 eNodeB 被封装,通过 4G 网络的全 Ip 加强分组核(EPC)以隧道的形式传输到 P-GW。在控制平面中,eNodeB 代表 UE 来处理注册和移动性信令流量。
- 分组数据网络网关(Packet Data Network Gateway,P-GW)给 UE 分配 IP 地址,并且保证服务质量(QoS)实施。
- 服务网关(S-GW)是数据平面移动性锚点,即所有 UE 流量将通过 S-GW 传递。S-GW 也执行收费/记账功能以法定的流量拦截。
- 移动性管理实体(MME)代表位于它所控制单元中的 UE,执行连接和移动性管理。
- 归属用户服务(Home Subscriber Server,HSS)包括了漫游接入能力、服务质量配置文件和鉴别信息的 UE 信息。
2.LTE 无线电接入网
长期演进技术(Long Term Evolution,LTE)在下行信道采用频分复用和时分复用结合的方法,称之为**正交频分复用(OFDM)**技术。它们相互干扰非常小,即使当信道频率紧密排列时。
7.5 移动管理:原理

对于应用程序来说,维持相同的 IP 地址将会带来便利,移动性将变得不可见,应用程序不必关心 IP 地址潜在的变化。
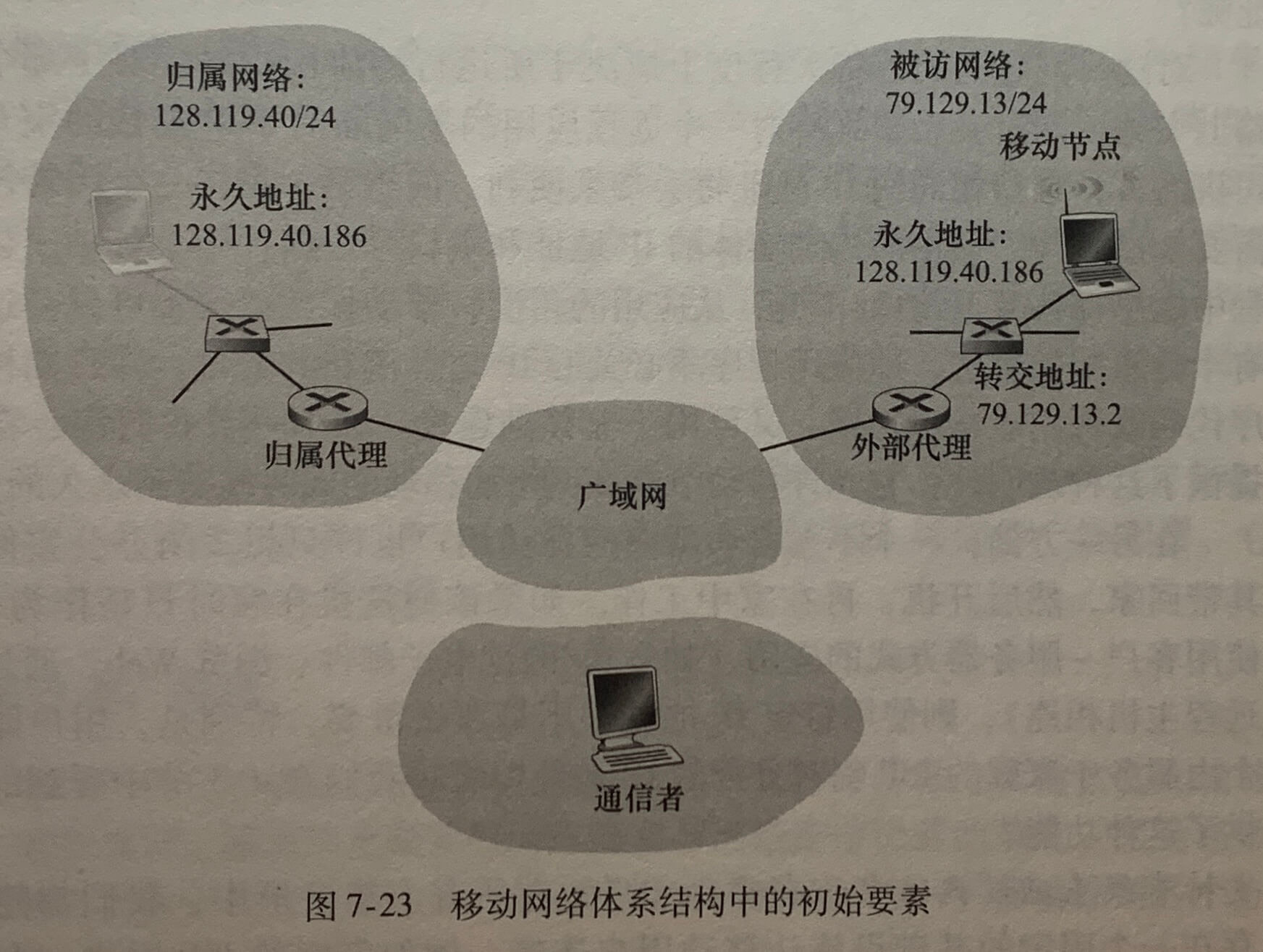
在一个网络环境中,一个移动节点(如一台便携机或智能手机)的永久居所被称为归属网络(home network),在归属网络中代表移动节点执行移动管理功能的实体叫归属代理(home agent)。移动节点当前所在网络叫做外部网络(foreign network)或被访网络(visitied network),在外部网络中帮助移动节点做移动管理功能的实体称为外部代理(foreign agent)。
7.5.1 寻址
外部代理的作用之一就是为移动节点创建一个所谓的转交地址(Care-Of Address,COA),该 COA 的网络部分与外部网络的网络部分相匹配。一个移动节点可与两个地址相关联,即永久地址和 COA,COA有时称为外部地。
7.5.2 路由选择到移动节点
1.移动节点的间接路由选择
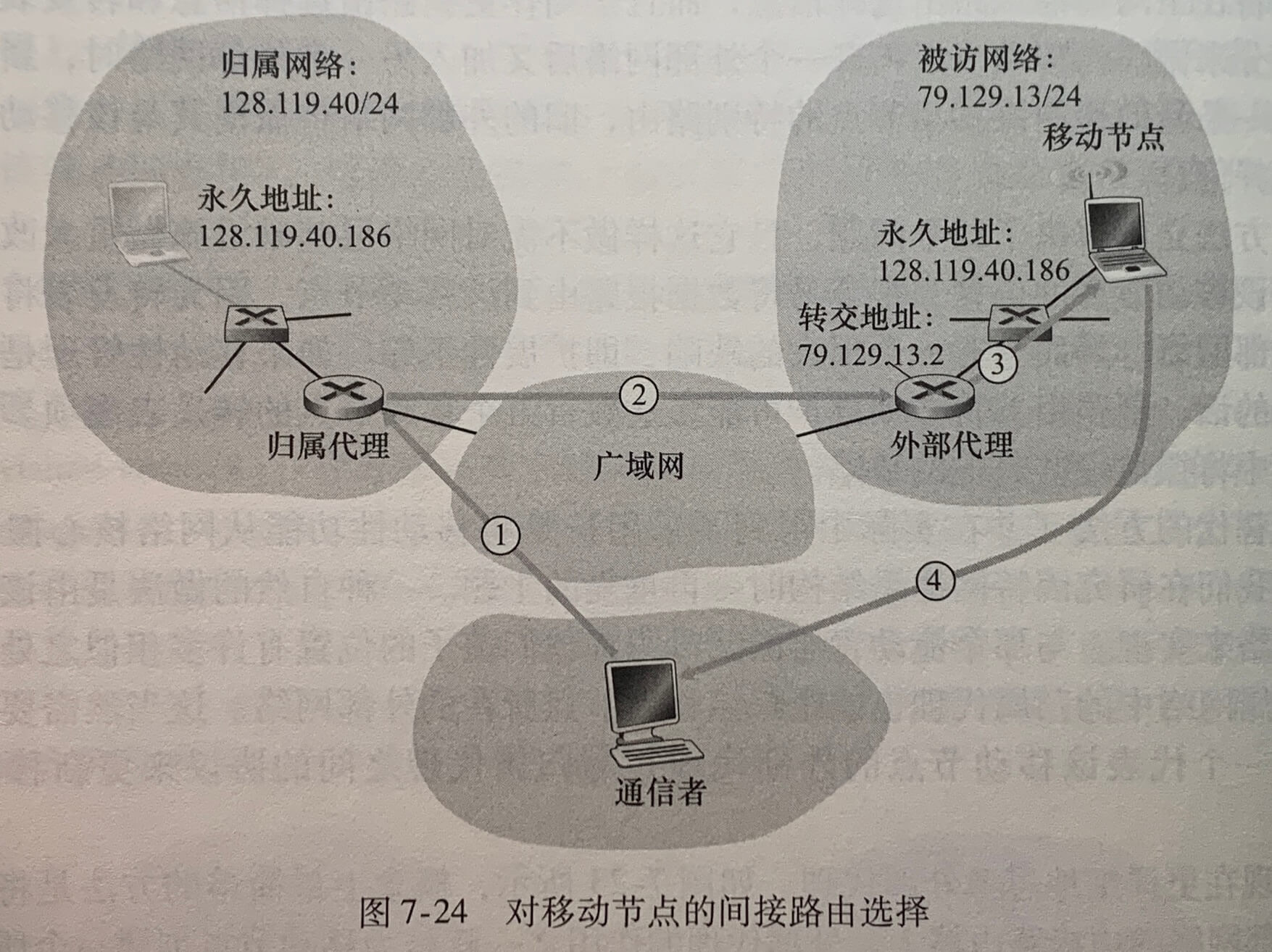
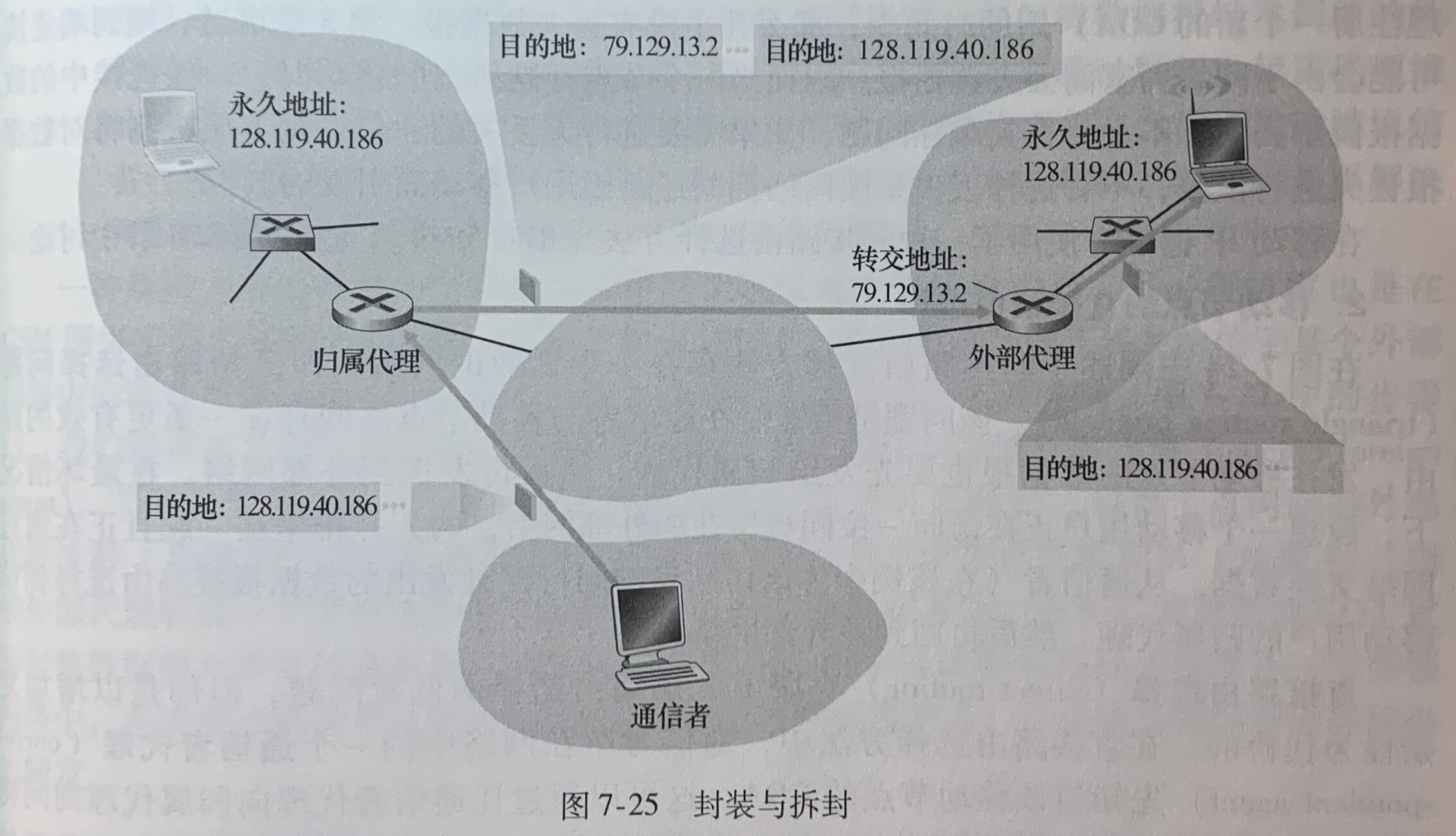
2.移动节点的直接路由选择
间接路由存在一个三角路由选择问题的低效问题。直接路由选择可以克服这个问题,但却以增加复杂性为代价。


7.6 移动IP
移动 IP 标准由三部分组成:
- 代理发现。
- 向归属代理注册。
- 数据报的间接路由选择。
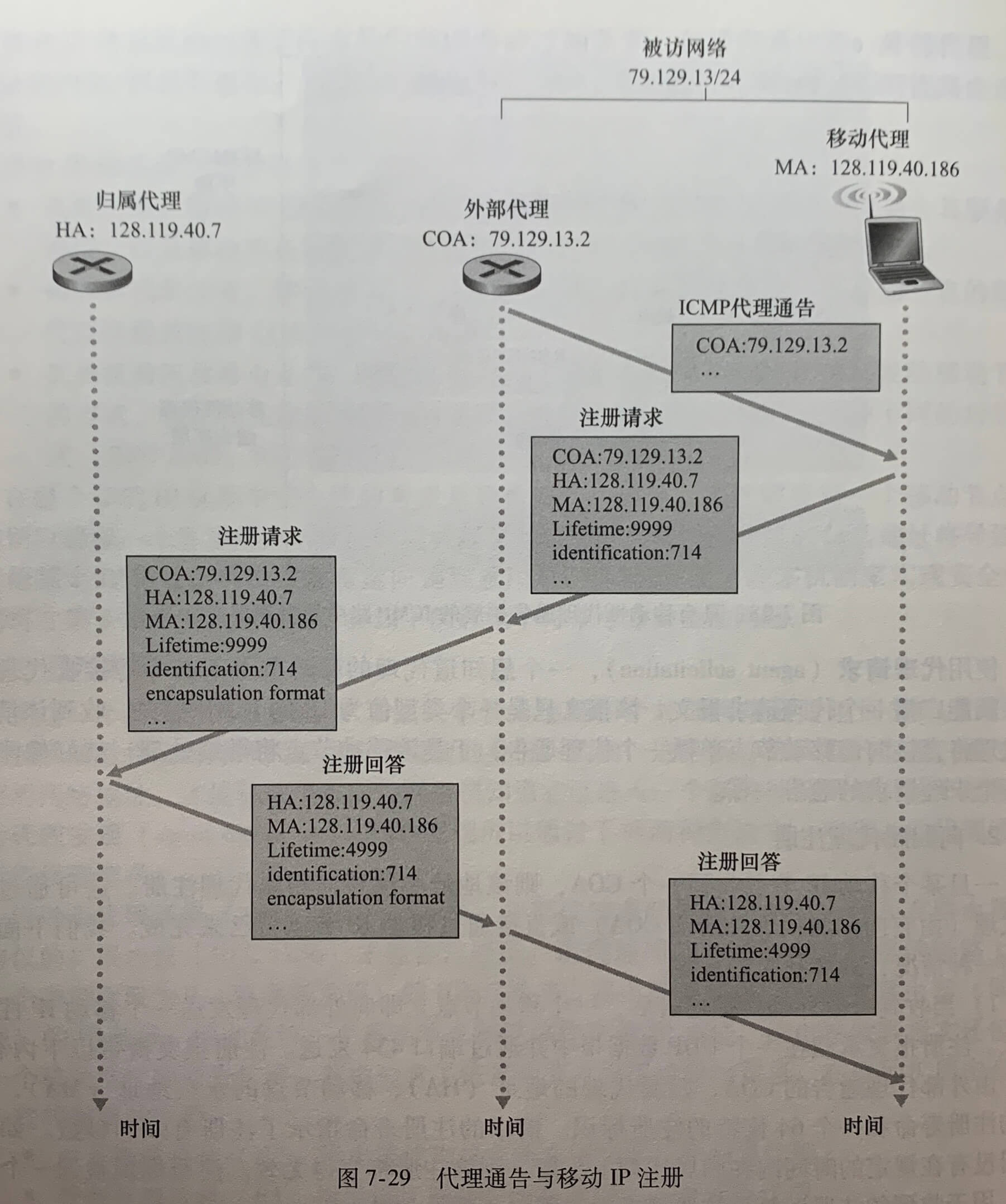
7.7 管理蜂窝网中的移动性
与移动 IP 类似,GSM(全球移动通讯系统)采用了一种间接路由选择方法,首先将通信者的呼叫路由选择到移动节点的归属网络,再从那到达被访网络。移动用户的归属网络被称作该移动用户的归属公共地域移动网络(home Public Land Mobile Network,home PLMN)。移动用户向某个蜂窝网提供商订购了服务,该蜂窝网就成为了这些用户的归属网络(比如我的手机的归属网络是联调)。被访问的PLMN,称为被访网络(visited network),是移动用户当前所在网络。
- 归属网络维护一个称作**归属位置注册器(Home Location Register,HLR)的数据库,其中包括它每个用户的永久蜂窝电话号码以及用户个人概要信息。HLR也包括这些用户当前的位置信息。如果一个移动用户当前漫游到另一个提供商的蜂窝网络中,HLR中将包含足够多的信息来获取被访网络中移动用户的呼叫应该路由选择到的地址。当一个呼叫定位到一个移动用户后,通信者将与归属网络中称为网关移动服务交换中心(Gateway Mobile services Switching Center,GMSC)(也称为归属MSC)**的特殊交换机联系。
- 被访网络维护一个称作**访问者位置注册(Visitor Location Register,VLR)**的数据库。VLR为每一个当前在其服务网络中中的移动用户包含一个表项,VLR表项因此随着移动用户进入或离开网络而出现或消失。VLR通常与移动交换中心(MSC)在一起,该中心协调到达或离开被访网络的呼叫建立。
在实际中,一个服务商的蜂窝网络将为其用户提供归属网络服务,同时为在其他蜂窝服务商订购服务的移动用户提供被访网络服务。
7.7.1 对移动用户呼叫的路由选择
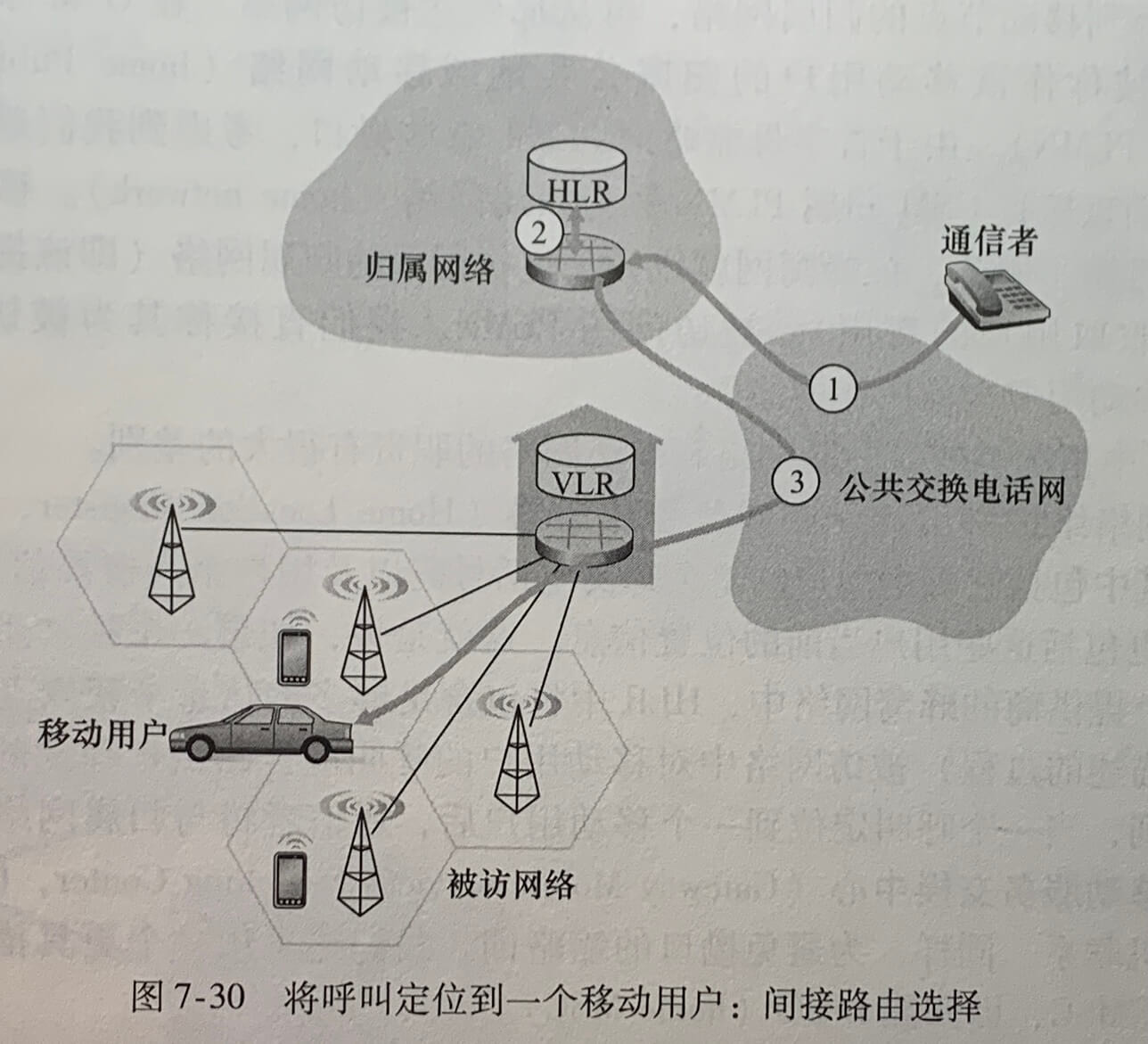
- 通信者拔打移动用户的电话号码(电话号码是固定的,用户是移动的),号码中的前几位数字将全局判别移动用户的归属网络。呼叫从通信者通过公共交换电话网到达移动用户归属网络中的归属MSC。
- 归属MSC收到该呼叫并查询HLR来确定移动用户的位置,在最简单的情况下,HLR返回移动站点漫游号码(Mobile Station Roaming Number,MSRN)(称为漫游号)。这个号码与移动用户的永久电话号码不同,永久电话号码与用户的归属网络相关联,而漫游号码是短暂的:当一个用户进入被访网络后,会给移动用户临时分配一个漫游号码。漫游号码的作用相当于移动IP中转交地址COA的作用,它和COA一样对通信者和移动用户是不可见的。如果HLR不具有该漫游号码,它返回被访网络中VLR的地址。在这种情况下,归属MSC需要查询VLR以便获取移动节点的漫游号码。
- 给定一个漫游号码,归属MSC通过网络到达被访网络的MSC建立呼叫的第二步。至此,该呼叫已经完成,从通信者到达归属MSC,再从归属MSC到达被访MSC,然后到达为移动用户提供服务的基站。
当一个移动电话切换或进入一个由新的VLR所覆盖的被访网络后,移动用户必须向被访网络注册,这是通过在移动用户和VLR之间交换信令报文来实现的。被访VLR随后又向移动用户的HLR发送一个位置更新请求报文。这一报文告知HLR可以用来联系移动用户的漫游号码或者VLR地址。作为这个交换的一部分,VLR同样从HLR那里获取移动用户的信息,以及确定被访网络应该给予移动用户扫码样的服务。
7.7.2 GSM中的切换

在于一个基站相关联期间,移动用户周期性地测量来自当前基站和临近它的可以“听得到”的基站的信号强度,这些测量以每秒1~2次的频率报告给移动用户的当前基站。
上图是一个在同个MSC时切换BS的情况。
上图是当一个移动用户移动到一个不同于旧BS(基本服务)的、与不同的MSC关联的BS中时,并且当这种MSC之间的切换多次发送时的情况。GSM定义了锚MSC(anchor MSC),锚MSC是呼叫首次开始时移动用户所访问的MSC,因此它在整个呼叫持续过程中保持不变。在整个呼叫期间,不论移动用户进行了多少次MSC间的切换,呼叫总是从归属MSC路由选择到锚MSC,然后再到移动用户当前所在的被访问MSC。因此,在任何情况下,通信者和移动用户之间至多有3个MSC。
另一种方法则不用维持从锚MSC到当前MSC的单一MSC跳,将直接链接移动用户访问的MSC。
7.8 无线和移动性:对高层协议的影响
在有线和无线网络中的网络层均为上层提供了同样的尽力而为服务模式。
无线对运输层的影响:由于在无线网络中比特错误比在有线网络中普遍得多,当这样的比特差错或切换丢失发生时,没理由让TCP发送方降低其拥塞窗口,此时路由器的缓存的确可能完全是空的。
第8章 计算机网络中的安全
8.1 什么是网络安全
**安全通信(secure communication)**具有下列所需要的特性:
- 机密性(confidentiality)。仅有发送方和希望的接收方能够理解传输报文的内容。因为窃听者可以截获报文,这必须要求报文在一定程度上进行加密(encrypted),使截取的报文无法被截获者所理解。
- 报文完整性(message integrity)。
- 端点鉴别(end-point authentication)。发送方和接收方都应该能证实通信过程所涉及的另一方,以确信通信的另一方具有其所声称的身份。
- 运行安全性(operational security)。
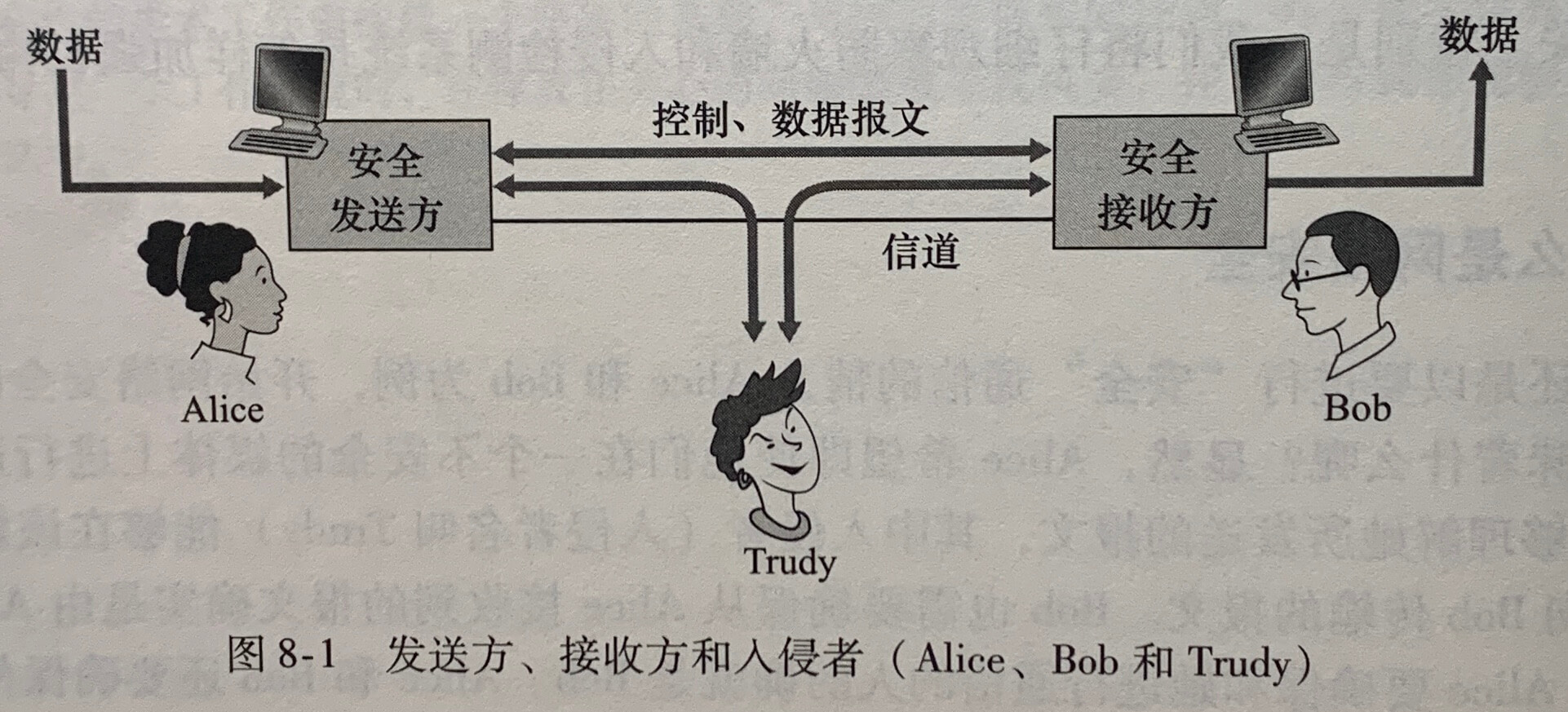
入侵者能够潜在的执行下列行为:
- 窃听-监听并记录信道上传输的控制报文和数据报文。
- 修改、插入或删除报文或报文内容。
8.2 密码学的原则
密码技术使得发送方可以伪装数据,使入侵者不能从截取到的数据中获得任何信息。

报文的最初形式是明文(plaintext,cleartext),使用加密算法(encryption algorithm)加密其明文报文,生成的加密报文被称为密文(ciphertext)。现代密码系统中,包括因特网上所使用的那些,加密技术本身是已知的,即公开发行的、标准化和任何人都可使用的,即使对潜在的入侵者也是如此。
上图中,Alice提供了一个密钥(key) K A K_A KA,它是一串数字或字符,作为加密算法的输入。加密算法以密钥和明文报文m为输入,生成密文作为输出。Bob将为**解密算法(decryption algorithm)**提供密钥 K B K_B KB,将密文和Bob的密钥作为输入,输出初始明文。
在**对称密钥系统(symmetric key system)中,Alice和Bob的密钥是相同的并且是秘密的。在公开密钥系统(public key system)**中,使用一对密钥,一个密钥为Bob和Alice所知(实际上为全世界所知),另一个密钥只有Bob或Alice知道(不是双方都知道)。
8.2.1 对称密钥密码体制
凯撒密码(Caesar cipher)将明文报文中的每个字母用字母表中该字母后的第k个字母进行替换,这里的k的值就是密钥。凯撒密码的一种改进方法是单码代替密码,它的区别是并非按照规则的模式进行替换。它的缺点是如果入侵者具有某些该报文的可能内容的知识,则破解该密码就会更为容易。
根据入侵者所拥有的信息分为三种不同的情况:
- 唯密文攻击。有些情况下,入侵者只能得到截取的密文,也不了解明文报文的内容。
- 已知明文攻击。当入侵者知道(明文、密文)的一些匹配时,我们称为对加密方式的已知明文攻击。
- 选择明文攻击。入侵者能够选择某一明文报文并得到该明文报文对应的密文形式。
500年前,发明了多码代替密码(polyalphabetic encryption),这种技术是对单码替代密码的改进。代码替代密码的基本思想是使用多个单码替代密码,一个单码替代密码用于加密某明文报文中一个特定位置的字母。因此,在某明文报文中不同位置出现的相同字母可能以不同的方式编码。比如密码以 C 1 C 2 C 1 C 1 C_1C_2C_1C_1 C1C2C1C1编码。

1. 快密码
在现代社会中,对称加密技术有两种类型:流密码(stream cipher)和块密码(block cipher)。使用块密码的因特网协议加密有PGP(用于安全电子邮件)、SSL(用于使TCP连接更安全)和IPsec(用于使网络层传输更安全)。
在块密码中,要加密的报文被处理为k比特的块。例如,如果k=64,则报文被划分为64比特的块,每块被独立加密。为了加密一个块,该密码采用了一对一映射表,将k比特的明文映射为k比特快的密文。假设k=3,因此块密码将3比特输入(明文)映射为3比特输出(密文)。下图给出了3比特可能的映射,这是一个一对一的映射,即对每种输入都有不同的输出。例如报文010110被加密成101000。

当k=3时,一共有 2 3 = 8 2^3=8 23=8种映射输入。这8种输入能够排列为40320种不同方式。我们能够将这些映射的每种设为一个密钥,如果Alice和Bob都知道该映射(密钥),他们能够加密和解密他们之间发送的报文。
对这种密码的蛮力攻击即通过使用所有映射来尝试解密密文。仅使用40320种映射(当k=3),这能够在一台桌面PC上迅速完成。为了挫败蛮力攻击,块密码通常使用大得多的块,由64比特甚至更多比特组成。对于全表块密码,当k值比如等于64时,将要求Alice和Bob维护一张具有 2 6 4 2^64 264个输入值的表,这是一个难以实现的任务,此外,假如Alice和Bob改变密钥,他们将不得不重新生成该表,全表块密码在所有输入和输出之间提供预先决定的映射是不可能实现的。
为了解决上述问题,块密码通常使用函数模拟随机排列表。如下图琐事,当k=64时,该函数首先将64比特块划分为8个块,每个块由8比特组成。每个8比特块由一个“8比特到8比特”表处理,这是个可管理的长度。
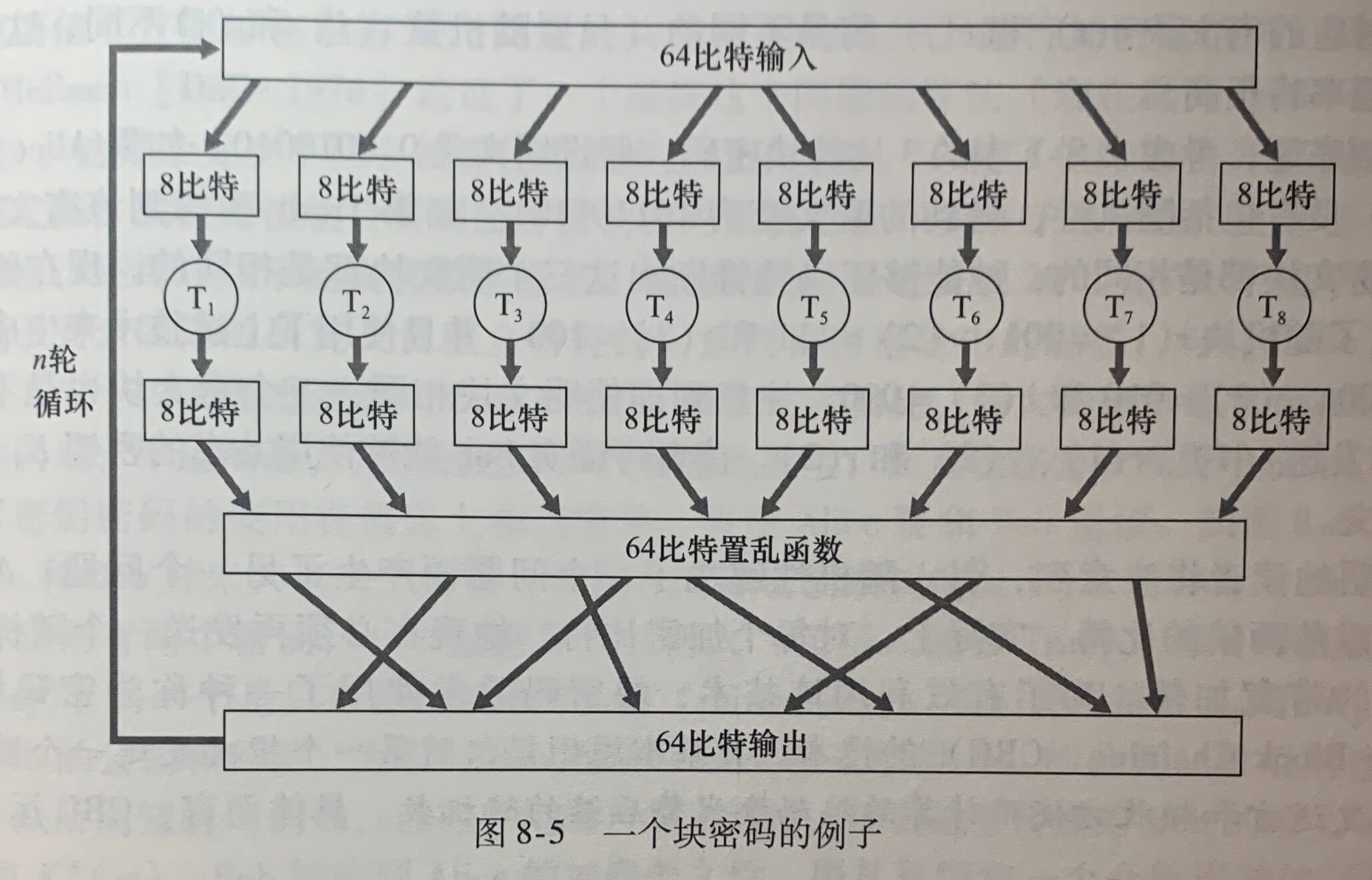
目前有一些流行的块密码,包括DES(Data Encryption Standard,数据加密标准)、3DES和AES(Advanced Encryption Standard,高级加密标准)。这些标准都使用了函数。一个算法的密钥决定了特定“小型表”映射和该算法内部的排列。
2.密码块链接
在计算机网络应用各种,通常需要加密长报文。如果使用前面描述的块密码,将出现一个微妙而重要的问题,比如两个或更多块中的明文可能是“HTTP/1.1”,对于这些相同的块,块密码将产生相同的密文,攻击者可能通过识别相同的密文块和利用支撑协议结构的知识,解密整个报文。
为了解决这个问题,可以在密文中混入某些随机性,使得相同的明文块产生不同的密文块。假设m(i)为明文块,c(i)为密文块,发送方以第i块生成一个随机的k比特数r(i),并且计算 c ( i ) = K s ( m ( i ) ⨁ r ( i ) ) c(i)=K_s(m(i)\bigoplus r(i)) c(i)=Ks(m(i)⨁r(i)),这里使用异或的方式。因为接收方收到c(i)和r(i),它能够计算 m ( i ) = K s ( c ( i ) ⨁ r ( i ) ) m(i)=K_s(c(i)\bigoplus r(i)) m(i)=Ks(c(i)⨁r(i))而恢复每个明文块。引入随机性会导致需要传输以前两倍的比特,为了有效利用该技术,块密码通常使用一种称为**密码块链接(Cipher Block Chaining,CBC)**的技术。基本思想是仅随第一个报文发送一个随机值,然后让发送方和接收方使用计算的编码块代替后续的随机数。CBC需要在协议中提供一种机制,以从发送方向接收方分发IV(初始向量c(0))。
8.2.2 公开密钥加密
对称密码的一个困难就是双方必须共享密钥达成一致,这样做的前提是需要提前通信(假定是安全的),通信双方能够在没有预先商定的共享密钥的条件下进行加密通信吗?1976年,Diffie和Hellman发明了一种完全不同、极为优雅的安全通信算法(现在称为Diffie-Hellman密钥交换),开创了如今的公开密钥系统的发展之路。公开密钥有很多很好的特性,使得它不仅可以用于加密,还可以用于鉴别和数字签名。

如上图所示,Alice和Bob并未共享一个密钥,Bob有两个密钥,一个是世界任何人都可以得到的公钥(public key),另一个是只有Bob知道的私钥(private key)。 K B + K{^+_B} KB+和 K B − K{^-_B} KB−来表示公钥和私钥。为了与Bob通信,Alice先取得Bob的公钥,然后用这个公钥和一个众所周知(标准化)的加密算法加密要传递给Bob的报文m,Bob收到Alice的加密报文后,用其私钥和一个众所周知的解密算法解密Alice的加密报文,即 K B − ( K B + ( m ) ) = K B + ( K B − ( m ) ) = m K{^-_B}(K{^+_B}(m))=K{^+_B}(K{^-_B}(m))=m KB−(KB+(m))=KB+(KB−(m))=m。
1.RSA
RSA算法几乎已经成了公开密钥密码的代码词。
2.会话密钥
RSA所要求的指数运算是相当耗费时间的过程,形成对比的是,DES用软件实现要比RSA快100被,用硬件实现要快1000~10000倍。所以,在实际应用中,RSA通常与对称密钥密码结合起来使用。例如,Alice选择一个用于加密数据本身的密钥(称为会话密钥(session key)),Alice需要把这个会话密钥告知Bob,这是他们在对称密钥密码(如DES或AES)中所使用的共享对称密钥。Alice可以使用Bob的RSA公钥来加密该会话密钥,Bob收到该RSA加密的会话密钥c后,解密得到会话密钥,Bob此时已经知道Alice将要用于加密数据传输的会话密钥了。
8.3 报文完整性和数字签名
**报文完整性(message integrity)**也称为报文鉴别。假设Bob收到一个报文(这可能已经加密或可能是明文),并且他认为这个报文是由Alice发送的,为了鉴别这个报文,Bob需要证实:
- 该报文的确源自Alice。
- 该报文在到Bob的途中没有被篡改。
8.3.1 密码散列函数
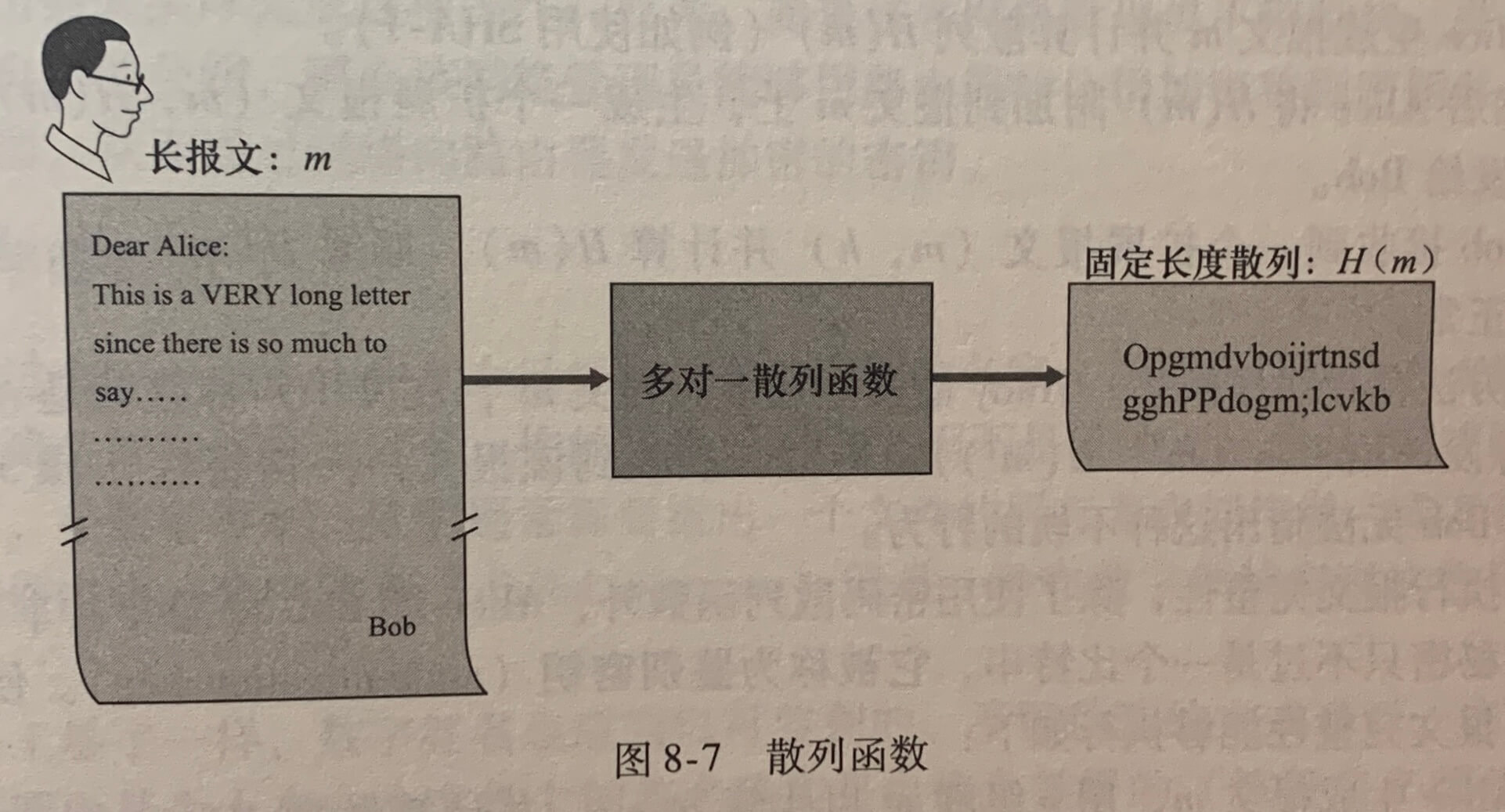
散列函数以m为输入,并计算得到一个称为散列的固定长度的字符串H(m)。因特网检验和和CRC都满足这个定义。**密码散列函数(cryptographic hash function)**要求具有下列附加的性质:
-
找到任意两个不同的报文x和y,H(x)永远不可能等于H(y)。
这种性质意味着入侵者在计算上不可能用其他报文替换由散列函数保护的报文。
Ron RIvest的MD5散列算法如此正在广泛使用。这个算法通过4步过程计算得到128比特的散列。
- 填充——先填1,然后填足够多的0,直到报文长度满足一定的条件;
- 添加——在填充前添加一个用64比特表示的报文长度;
- 初始化累加器;
- 循环——对报文的16字节进行4轮处理。
目前正使用的第二个主要散列算法是安全散列算法SHA-1(Security Hash Algorithm)。这个算法的原理类似于MD4设计中所使用的的原理,MD4是MD5的前身。SHA-1生成一个160比特的报文摘要。较长的输出长度可使SHA-1更安全。
8.3.2 报文鉴别码
如果只使用密码散列函数,Trudy也能够生成虚假报文并让Bob无法猜出这种不轨的行为。除了使用密码散列函数外,Alice和Bob需要共享鉴别密钥(authentication key)。
- Alice生成报文m,用s(鉴别密钥)级联m生成m+s,计算散列H(m+s),H(m+s)被称为报文鉴别码(Message Authentication Code,MAC)。
- Alice将MAC附加到报文m上,生成扩展报文(m,H(m+s))发给Bob。
- Bob由于知道s,根据扩展报文计算报文鉴别码。如果H(m+s)=h。则一切正常。
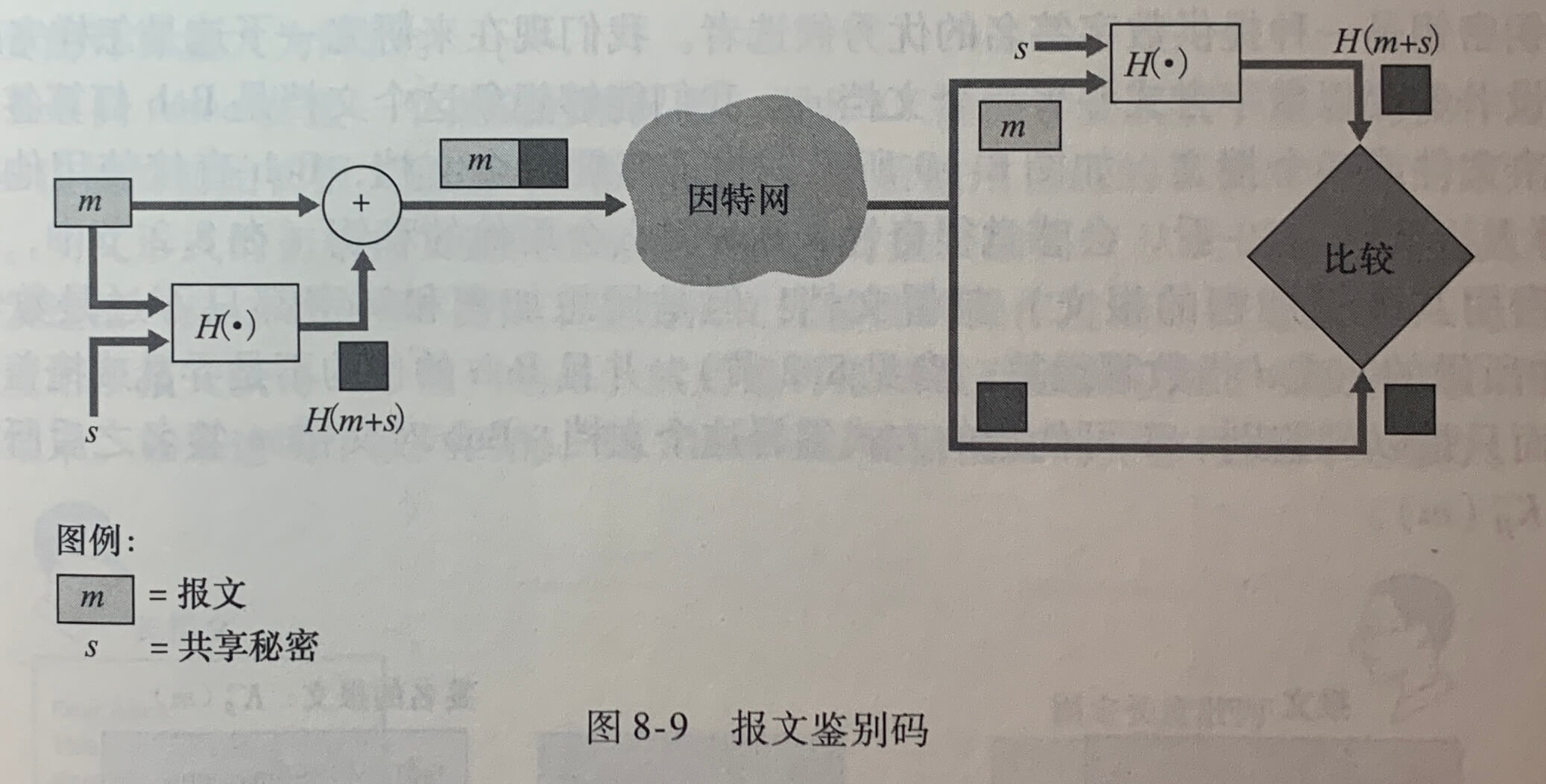
这里还有个问题,通信实体如何分发这个共享的鉴别密钥呢?可以通过公钥加密进行分发。
8.3.3 数字签名
在数字领域,人们通常需要指出一个文件的所有者或创作者,或者表明某人认可一个文件内容。**数字签名(digital signature)**就是一种在数字领域实现这些目标的密码技术。正如手工签字一样,数字签名也应当以可鉴别的、不可伪造的方式进行。也就是说,必须能够证明由某个人在一个文件上的签名确实是由该人签署的(该签名必须是可证实的),且只有那个人能够签署那个文件(该签名无法伪造)。
公钥是一种提供数字签名的优秀方案。Bob用它的私钥对一个文件或一个报文进行签署即 K B − ( m ) K{^-_B}(m) KB−(m),由于Alice只能用Bob的公钥解开这个数字签名即 K B + ( K B − ( m ) ) = m K{^+_B}(K{^-_B}(m))=m KB+(KB−(m))=m。
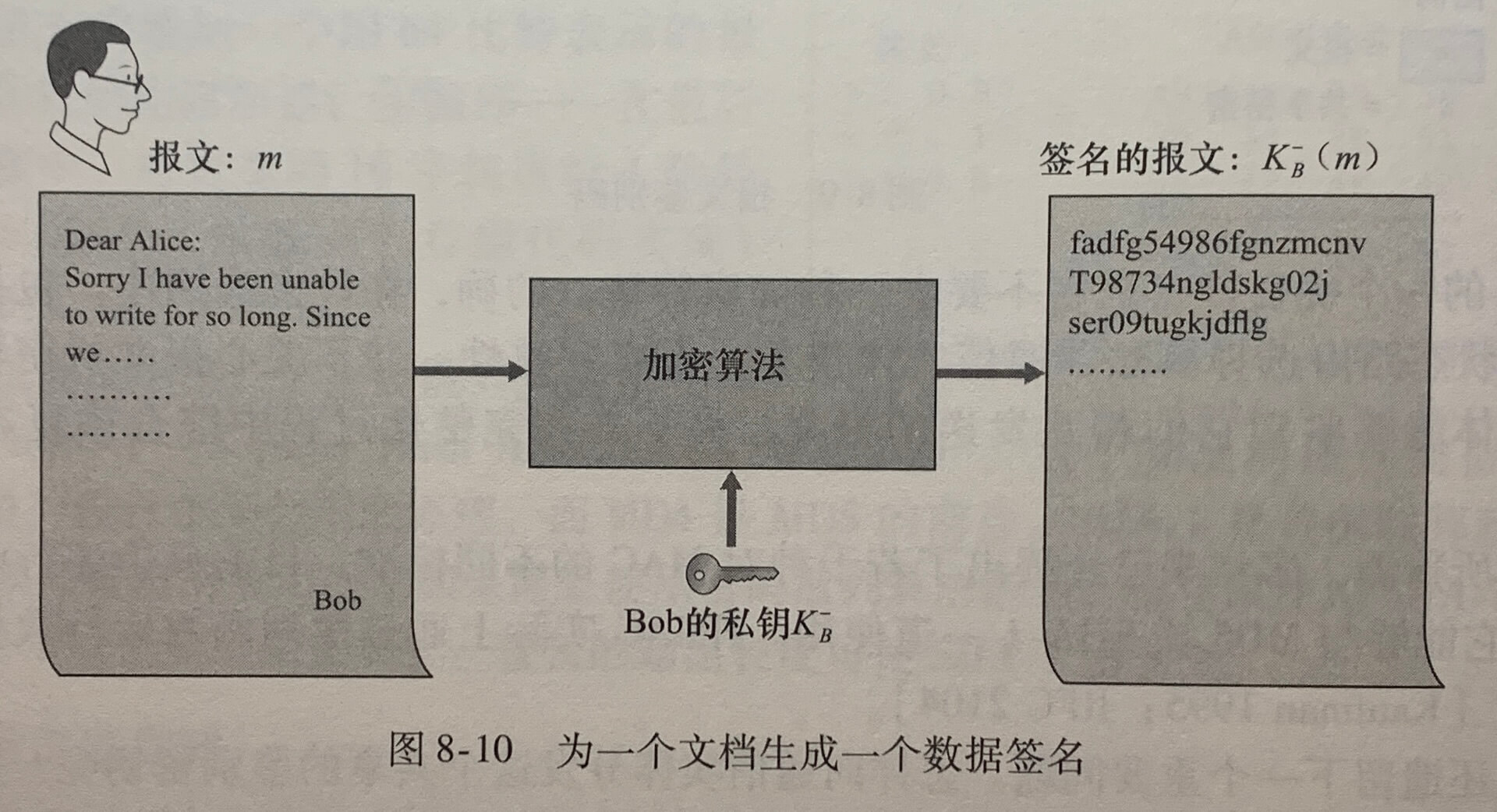
不过由于加密和解密的计算代价昂贵,用来对数据进行数字签名的开销非常大,因此更好的方式是使用对报文使用散列函数并进行数字签名,因为散列函数相比报文会小得多,所需要的计算量大大降低。
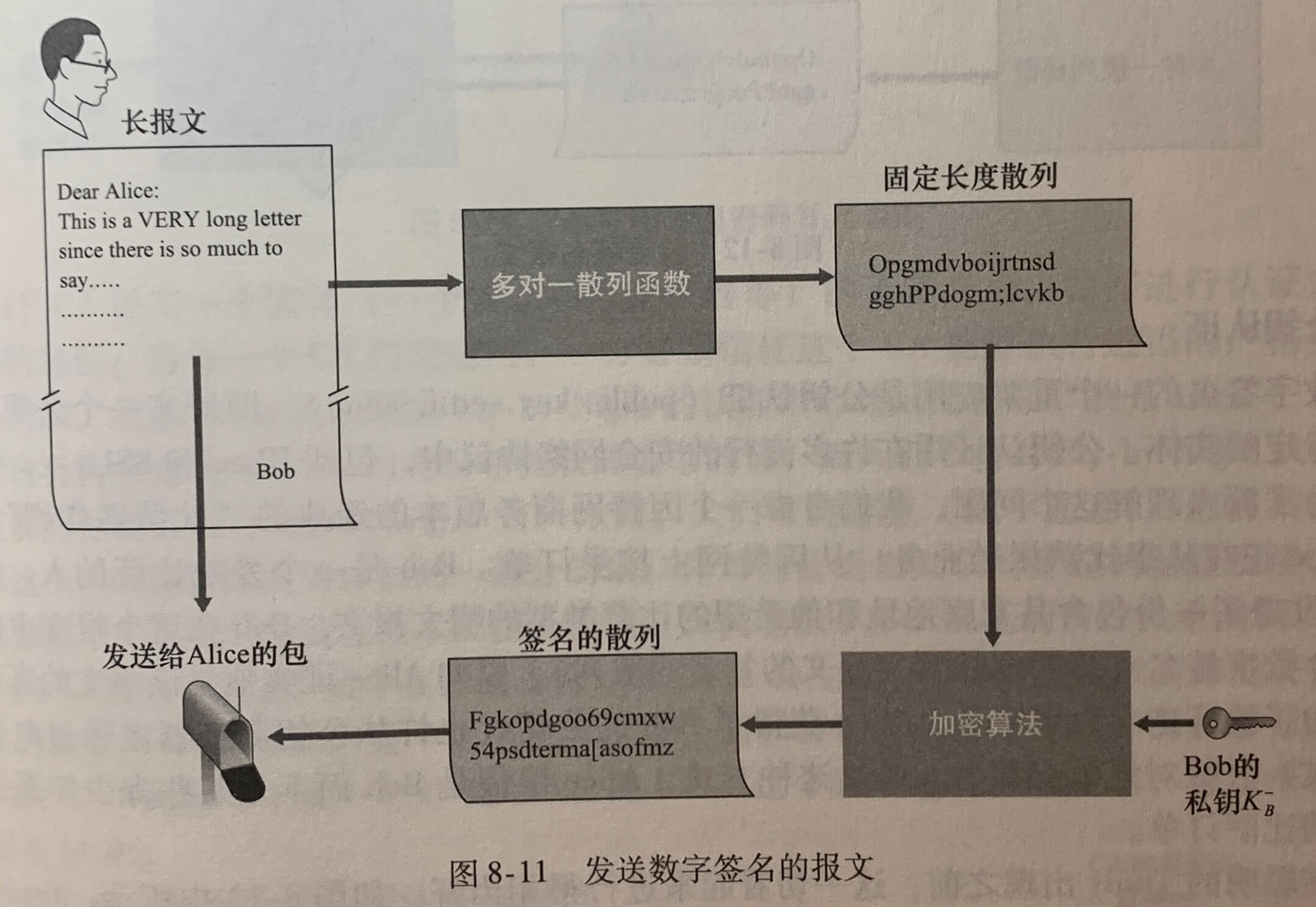
上图中,Bob让他的初始报文通过一个散列函数,然后用它的私钥对散列进行数字签名,明文形式的初始报文连同已经数字签名的报文摘要被发送给Alice。
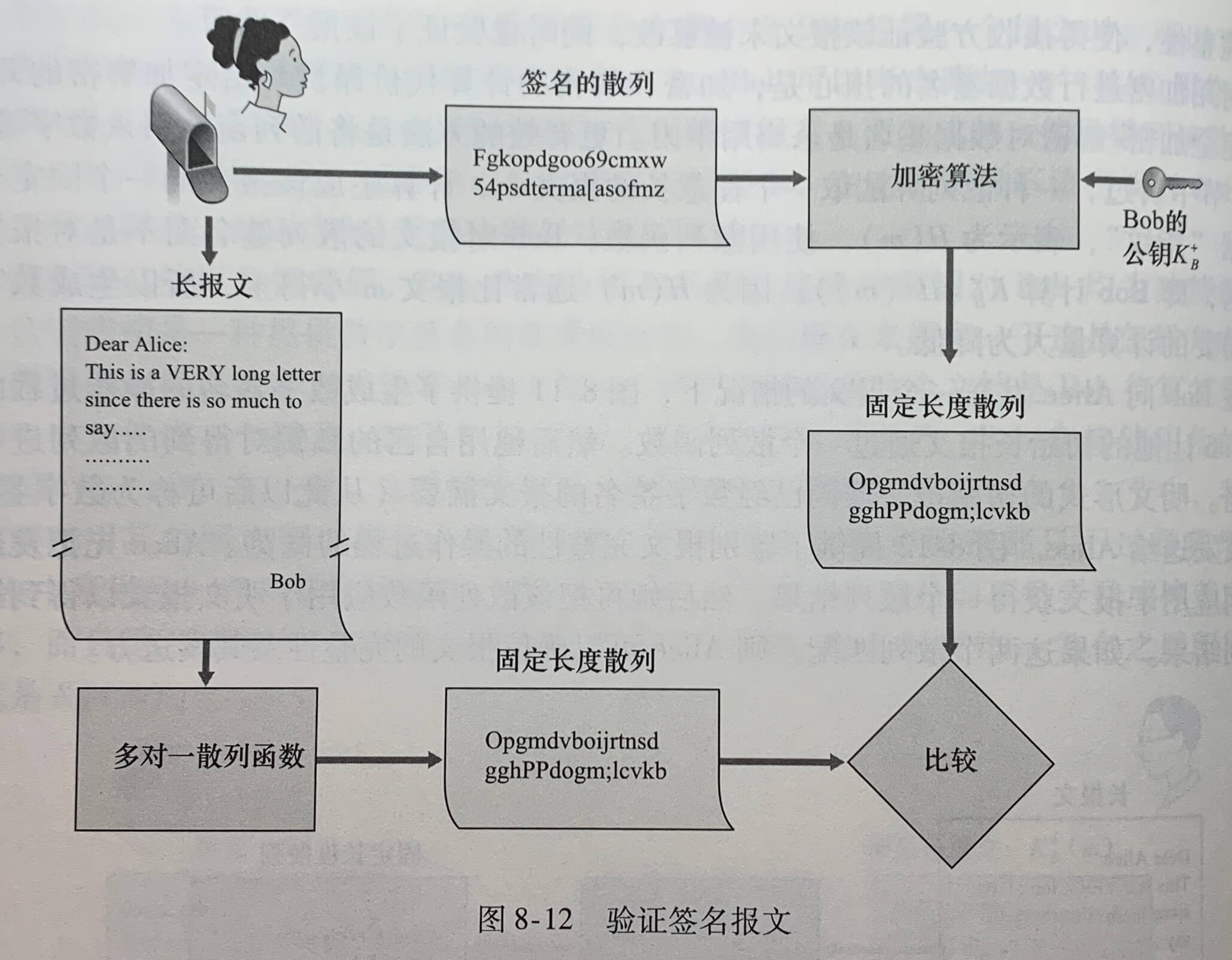
OSPF使用的是MAC。
公钥认证
**公钥认证(public key certification)**证实一个公钥属于某个特定的实体,公钥认证用在许多流行的安全网络协议中,包括IPsec和SSL。
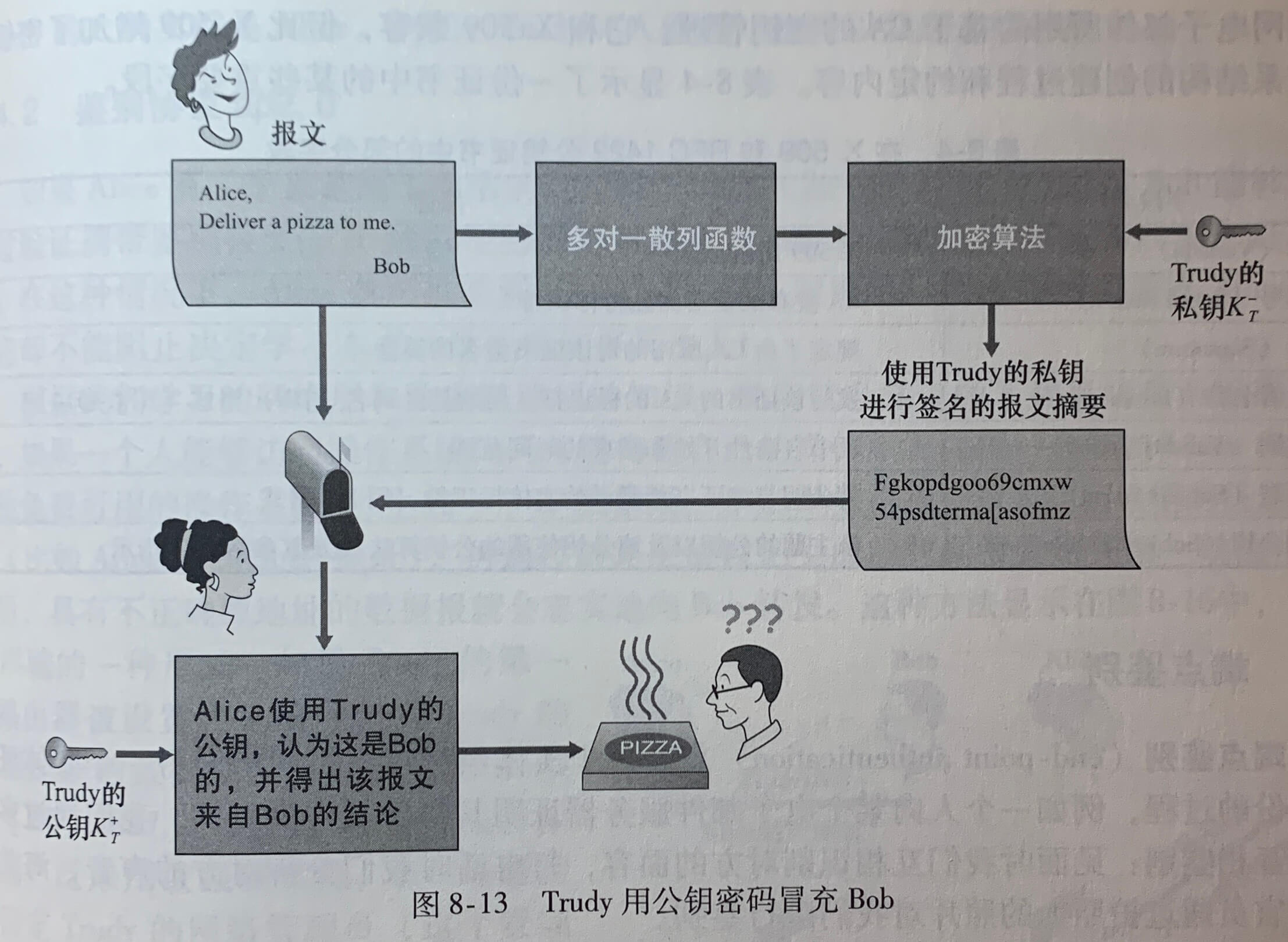
上图中,是一场没有使用公钥认证导致的恶作剧。因此,要使公钥密码要用,需要能够证实你具有的公钥实际上就是与你要通信的实体(人员、路由器、浏览器等)的公钥。
公钥与特定实体绑定通常是由**认证中心(Certification Authority,CA)**完成的,CA的职责是使识别和发行证书合法化。CA具有下列作用:
- CA证实一个实体(一个人、一台路由器等)的真实身份。当与一个CA打交道时,一方必须信任这个CA能够执行适当的严格身份验证。
- 一旦CA验证了某个实体的身份,这个CA会生成一个将其身份和实体的公钥绑定起来的证书(certificate)。这个证书包含这个公钥和公钥所有者全局唯一的身份标识信息。由CA对这个证书进行数字签名。

使用CA之后,Bob会将CA签署的证书发送给Alice,Alice使用CA的公钥来核对Bob证书的合法性并提取Bob的公钥。

8.4 端点鉴别
**端点鉴别(end-point authertication)**就是一个实体经过计算机网络向另一个实体证明其身份的过程。鉴别应当在报文和数据交换的基础上,作为某鉴别协议的一部分独立完成。鉴别协议通常在两个通信实体运行其他协议(例如HTTP、TCP或SMTP)之前运行。鉴别协议首先建立相互满意的各方的标识,仅当鉴别完成之后,各方才继续下面的工作。下列讲解各种ap(authentication protocol)鉴别协议的逐步式的演化。
8.4.1 鉴别协议ap1.0

8.4.2 鉴别协议 ap2.0

ap2.0 Bob通过Alice的IP来鉴别Alice,但如果Trudy可以修改它的第一跳路由器,则Trudy也可以假装成Alice。
8.4.2 鉴别协议 ap3.0

鉴别的一种经典方法是使用秘密口令。口令是鉴别者和被鉴别者之间的一个共享秘密。Gmail、Telnet、FTP和许多其他服务使用口令鉴别。ap3.0的缺点是如果Trudy窃听Alice的通信,则得到Alice的口令。
8.4.4 鉴别协议 ap3.1
我们完善协议ap3.0的下一个想法自然就是加密口令了。通过加密口令,我们能够防止Trudy得知Alice的口令。但其实ap3.1无法解决鉴别问题。Bob受制于回放攻击(playback attack):Trudy只需监听Alice的通信,并记录下该口令的加密版本,并向Bob回放该口令的加密版本,以假装她就是Alice。
8.4.5 鉴别协议 ap4.0
ap3失败的原因是Bob无法判断Alice是否还活跃。前面讲过的TCP三次握手协议也是处理相同的问题,TCP服务器选择一个很长时间内都不会再次使用的初始序号,然后把这个序号发给客户,然后等待以包含这个序号的ACK报文段来响应。此处我们能够为鉴别目的采用同样的思路。
**不重数(nonce)**是在一个协议的生存期只使用一次的数。ap4.0以如下方式使用一个不重数:
- Alice向Bob发送报文“我是Alice”。
- Bob选择一个不重数R,然后发给Alice。
- Alice使用她与Bob共享的对称密钥来加密这个不重数,然后把加密的不重数发给Bob。这个不重数用于确定Alice是活跃的。
- Bob解密接收到的报文。如果解密得到的不重数等于他发送给Alice的那个不重数,则可鉴别Alice的身份。
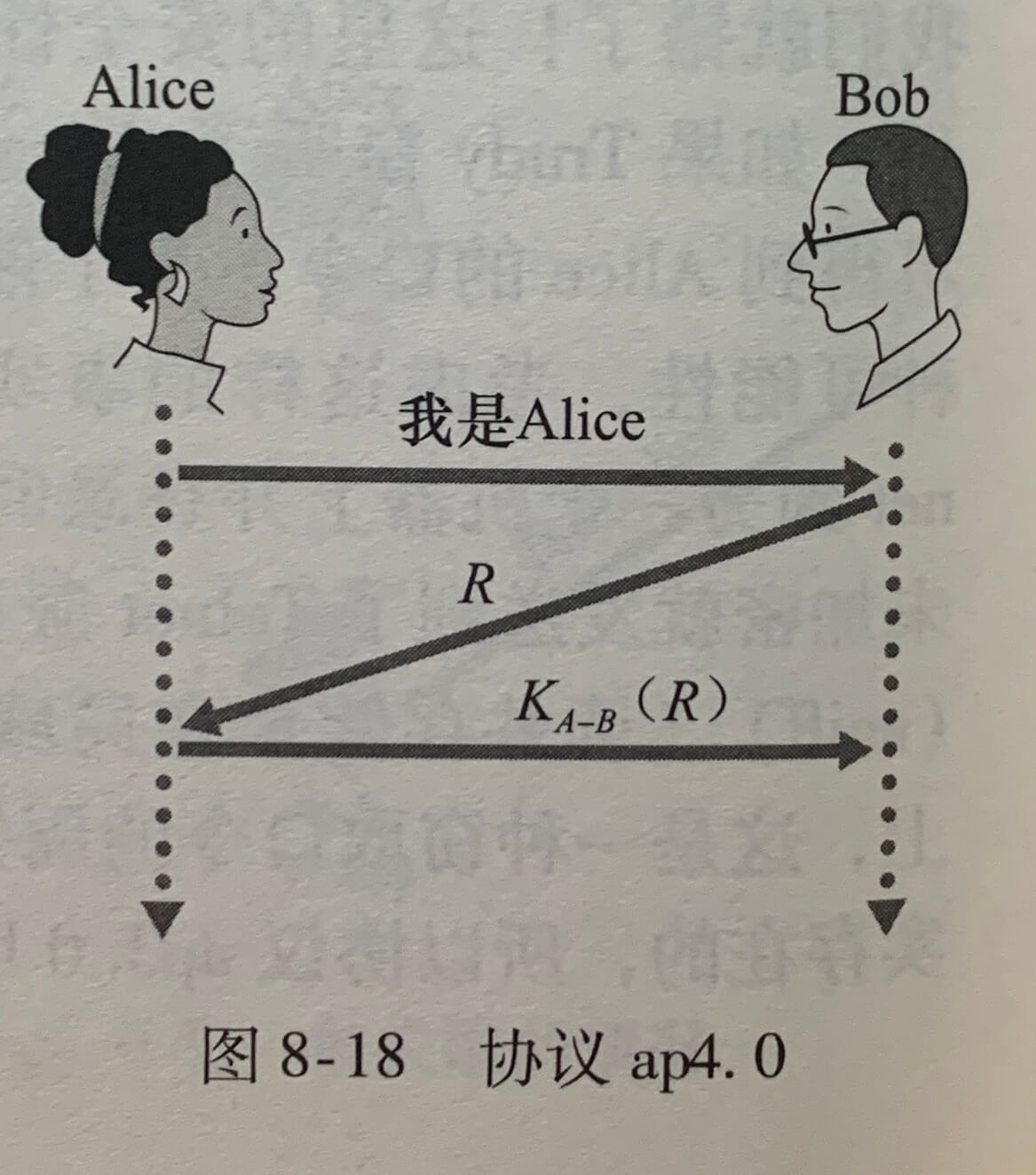
8.5 安全电子邮件
为因特网协议上面4层的任一层提供安全性服务是可能的。当为某一特定的应用层协议提供安全性时,则使用这一协议的应用程序将能得到一种或多种安全服务,诸如机密性、鉴别或完整性。为某一运输层协议提供安全性时,则所有使用这一协议的应用程序都可以得到该运输层协议所提供的安全性服务。在基于主机到主机的网络层提供安全性时,则所有运输层报文段(包括应用层数据)都可以得到该网络层所提供的安全服务。当基于一条链路提供安全性时,则经过这个链路传输的所有帧中的数据都得到了该链路提供的安全性服务。
8.5.1 安全电子邮件
一个安全电子邮件系统需要提供的安全特性:
- 机密性
- 发送方鉴别
- 报文完整性
- 接收方鉴别
提供机密性的最直接方式是使用对称密钥技术(如DES或AES)加密所传输的报文,但分发对称密钥非常困难。因此考虑使用公钥密钥密码(例如RSA),公钥密钥加密的缺点是效率相对低下,尤其对于长报文。为了克服效率问题,考虑使用会话密钥。1.Alice选择一个随机对称会话密钥 K s K_s Ks;2.用这个对称密钥加密她的报文m;3.用Bob的公钥 K B + K{^+_B} KB+加密这个对称密钥;4.级联该加密的报文和加密的对称密钥以形成一个“包”;5.向Bob的电子邮件地址发送这个包。当Bob收到这个包时:1.他使用其私钥 K B − K{^-_B} KB−得到对称密钥 K s K_s Ks;2.使用这个对称密钥 K s K_s Ks解密报文m。

设计完机密性的安全电子邮件系统后,我们设计另一个提供发送方鉴别和报文完整性的系统。这里先撇开机密性,只关心发送方鉴别和报文完整性。这里使用数字签名和报文摘要。1.Alice对她要发送的报文m应用一个散列函数H(例如MD5),从而得到一个报文摘要;2.用她的私钥 K A − K{^-_A} KA−对散列函数的结果进行签名,从而得到一个数字签名;3.把初始报文(未加密)和该数字签名级联起来生成一个包;4.向Bob的电子邮件发送这个包。当Bob接收到这个包时:1.他将Alice的公钥 K A + K{^+_A} KA+应用到被签名的报文摘要上;2.将该操作的结果与他自己对该报的散列H进行比较。
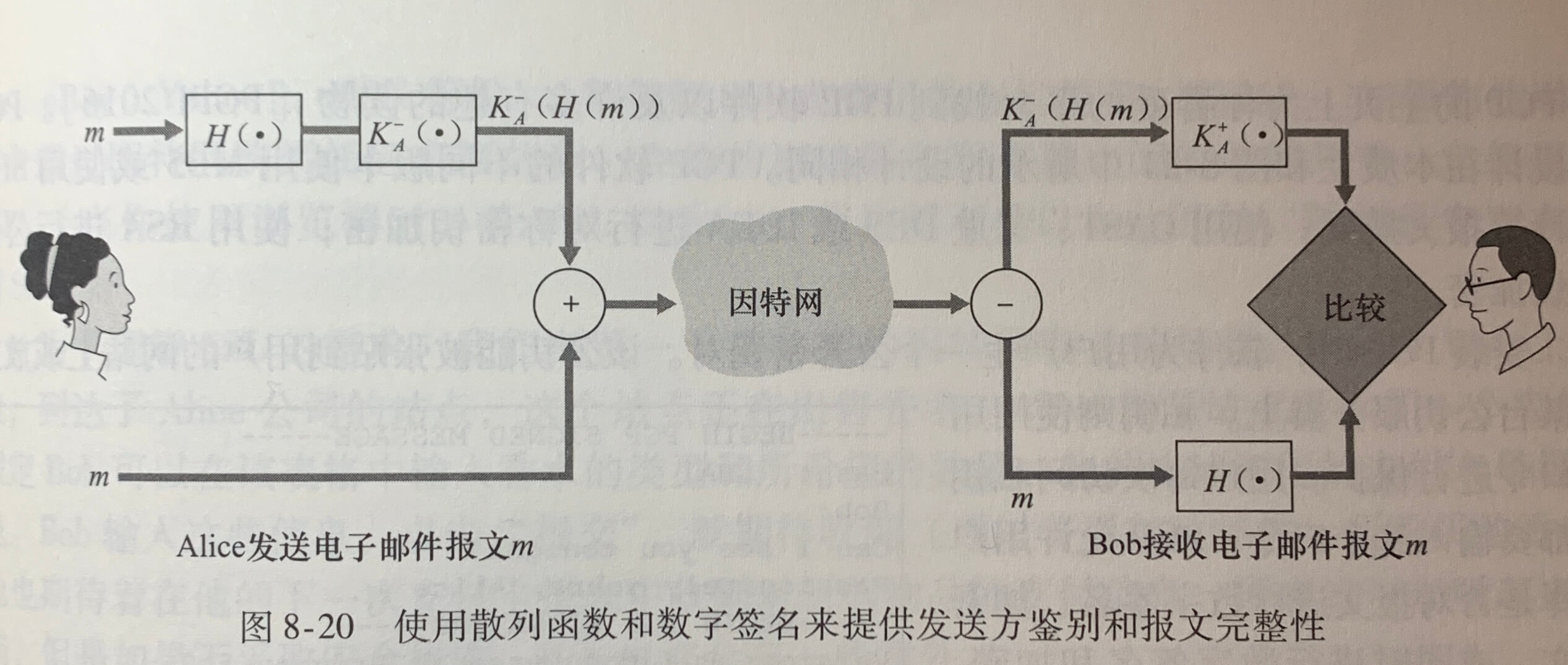
现在我们考虑设计一个提供机密性、发送方鉴别和报文完整性的电子邮件系统。这可以通过图8-19和图8-20的过程结合起来实现。Alice首先生成一个预备包,它与图8-20中包完全相同,其中包含她的初始报文和该报文数字签名过的散列。然后Alice把这个预备包看作一个报文,再用图8-19的发送方的步骤发送这个新报文。Bob收到这个报文后,他首先应用图8-19的右侧的步骤,再应用图8-20右侧的步骤。在这一方案中,Alice两次使用了公钥密钥:一次用了她的私钥,一次用了Bob的公钥。类似地,Bob也使用了两次公钥密钥:一次他的私钥,一次Alice的公钥。
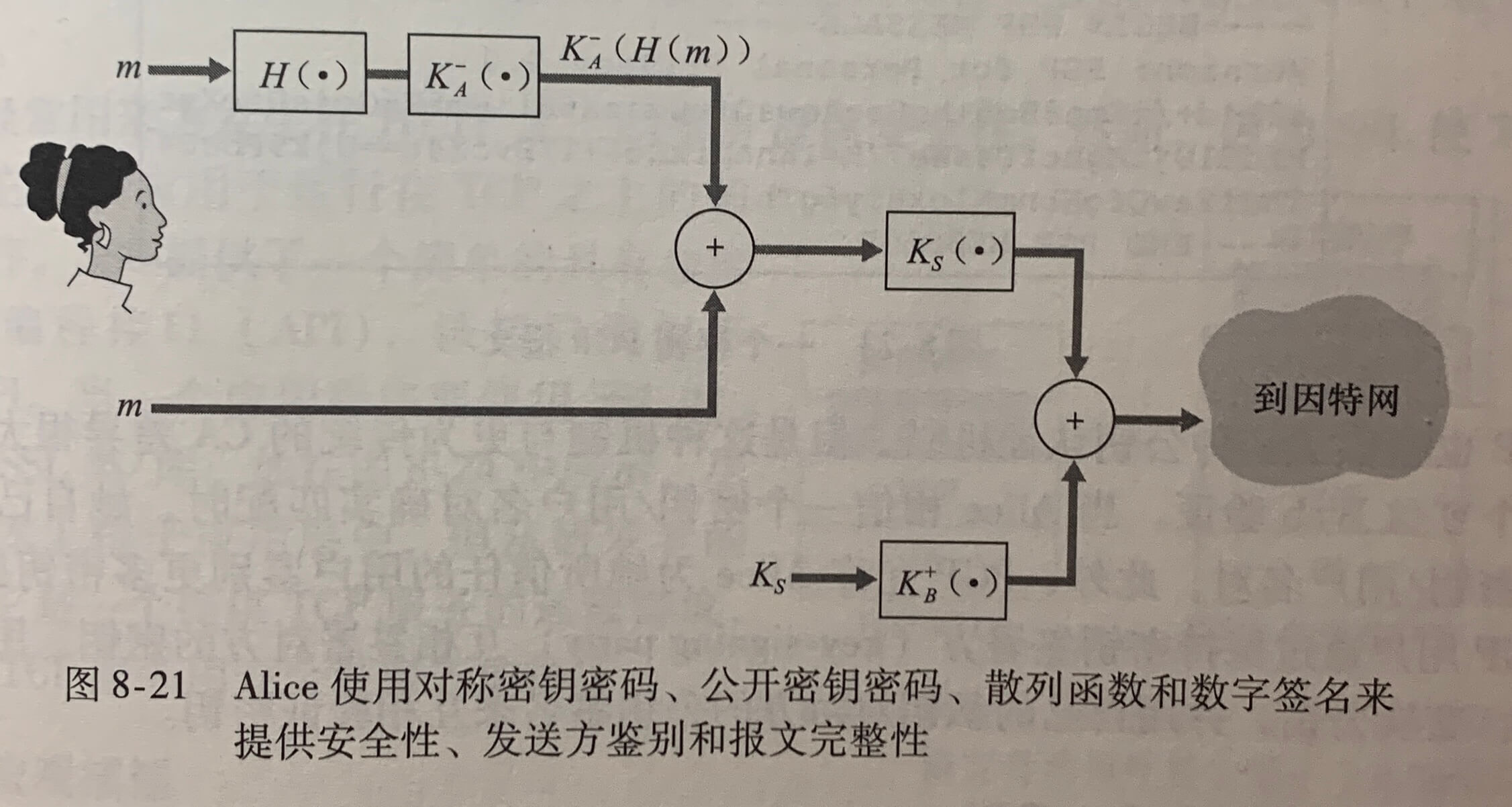
8.5.2 PGP
PGP(Pretty Good Privacy)是电子邮件加密方案的一个范例。PGP的设计在本质上和图8-21中所示的设计相同。
8.6 使TCP连接安全:SSL
这一节考察密码技术如何用安全性服务加强TCP,该安全性服务包括机密性、数据完整性和端点鉴别。TCP的这种强化版本通常被称为安全套接字层(Secure Socket Layer,SSL)。SSL版本3的一个稍加修改的版本被称为**运输层安全性(Transport Layer Security,TLS)**已经由IETF标准化。
SSL得到了所有流行Web浏览器和Web服务器的支持,并基本上被用于所有因特网商业站点。SSL通过采用机密性、数据完整性、服务器鉴别和客户鉴别来强化TCP。
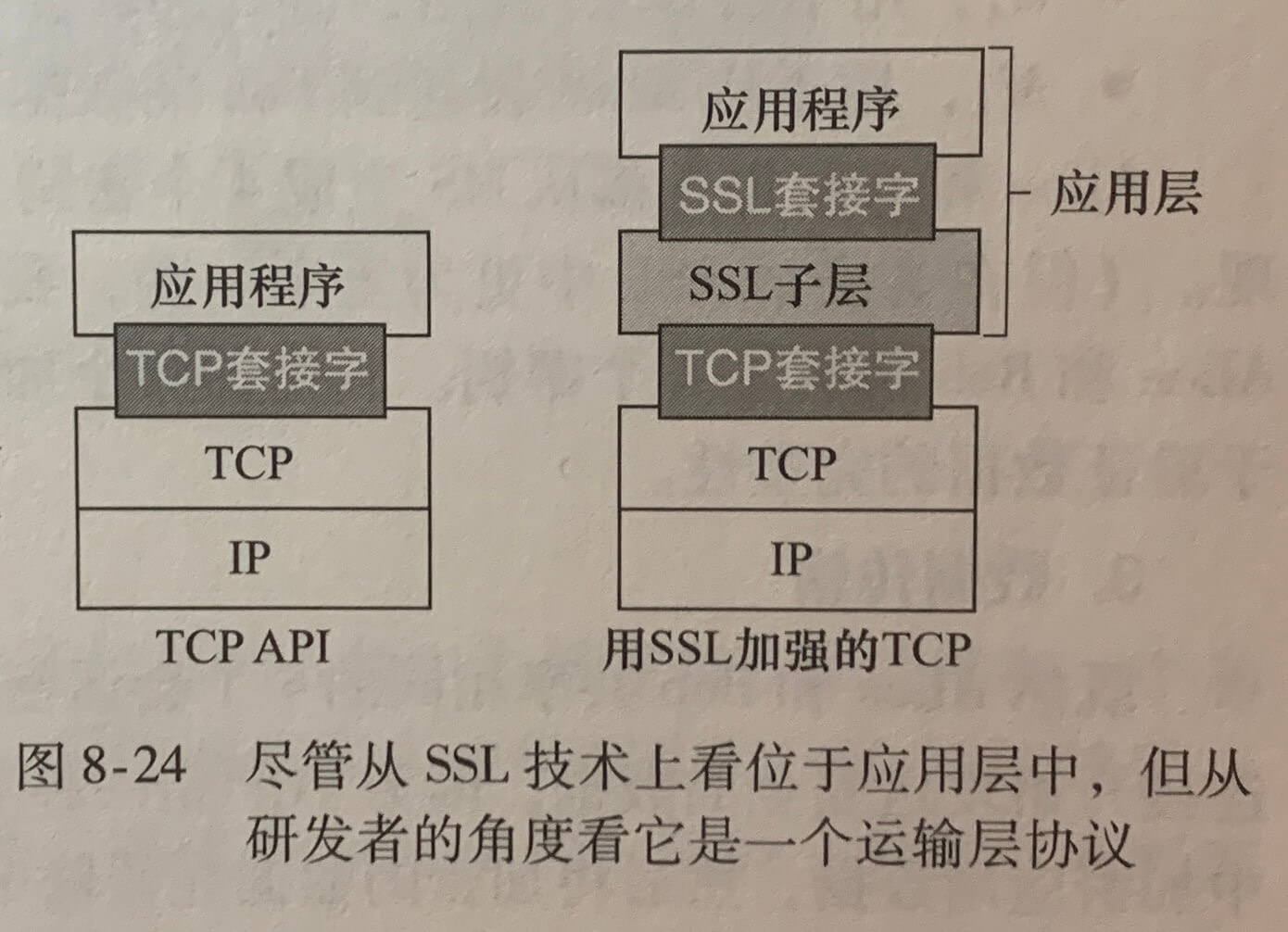
SSL经常用来为发生在HTTP之上的事物提供安全性。然而,因为SSL使TCP安全了,因此它能被应用于运行在TCP之上的任何应用程序。SSL提供了一个简单的具有套接字的应用编程接口(API),该接口类似于TCP的API。当一个应用程序要使用SSL时,它包括了SSL类/库。从研发者的角度看SSL是一个提供TCP服务的运输协议。
8.6.1 宏观描述
我们从描述一个简化的SSL版本开始。我们将SSL的简化版称为“类SSL”。类SSL(和SSL)具有三个阶段:握手、密钥导出和数据传输。我们现在描述针对一个客户(Bob)和一个服务器(Alice)之间的通信会话的这三个阶段,其中Alice具有私有/公钥对和将她的身份与其公钥绑定的证书。
1.握手

在握手阶段,Bob需要:1.与Alice创建一条TCP连接;2.验证Alice是真实的Alice;3.发送给Alice一个主密钥,Bob和Alice持用该主密钥生成SSL会话所需的所有对称密钥。一旦创建了TCP连接,Bob就向Alice发送一个hello报文。Alice用她的证书进行响应,证书中包含了她的公钥。然后Bob产生一个主密钥(MS)(该MS仅用于这次SSL会话),用Alice的公钥加密该MS以生成加密的主密钥(EMS)并发送给Alice。Alice用她的私钥解密该EMS从而得到MS,在这个阶段后,Bob和Alice均知道了用于这次SSL会话的主密钥。
2.密钥导出
MS此时已由Bob和Alice共享用作后续加密和数据完整性检查的对称密钥。但是使用不同的密码密钥,并且对于加密和完整性检查也使用不同的密钥,通常认为更为安全。因此,Alice和Bob都使用MS生成4个密钥:
- E B E_B EB,用于从Bob发送到Alice的数据的会话加密密钥。
- M B M_B MB,用于从Bob发送到Alice的数据的会话MAC(报文鉴别码)密钥。
- E A E_A EA,用于从Alice发送到Bob的数据的会话加密密钥。
- M A M_A MA,用于从Alice发送到Bob的数据的会话MAC(报文鉴别码)密钥。
Alice和Bob每人都从MS生成4个密钥。其中两个加密密钥将用于加密数据;两个MAC密钥将用于验证数据的完整性。
3.数据传输
TCP是一种字节流协议。SSL将数据流分割成记录,对每个记录附加一个MAC用于完整性检查,然后加密该“记录+MAC”。为了生成MAC,Bob将数据连同密钥 M B M_B MB放入一个散列函数中,为了加密“记录+MAC”这个包,Bob使用他的会话加密密钥 E B E_B EB,然后将加密的包传递给TCP经因特网传输。
假定Trudy是一名“中间人”,他能够在Bob和Alice之间发送的TCP报文段流中插入、删除和替换报文段。比如Trudy俘获Bob发送的两个报文段,颠倒这两个报文段的次序,调整TCP报文段的序号(这些未被加密),此时将引发数据错乱。可以使用序号的方式解决该问题。SSL采用如下的方式,Bob维护一个序号计数器,计数器从0开始,Bob每发送一个SSL记录就加1。Bob并不实际在记录中包括一个序号,但当他计算MAC时,他把该序号包括在MAC的计算中,所以MAC是数据+MAC密钥 M B M_B MB+当前序号的散列。Alice跟踪Bob的序号,通过在MAC的计算中包括适当的序号,使她验证一条记录的完整性。
5. SSL记录

SSL记录由类型字段、版本字段、长度字段、数据字段和MAC组成。前三个字段是不加密的。类型字段指出该字段是握手报文还是包括应用数据的报文。它也用于关闭SSL连接。
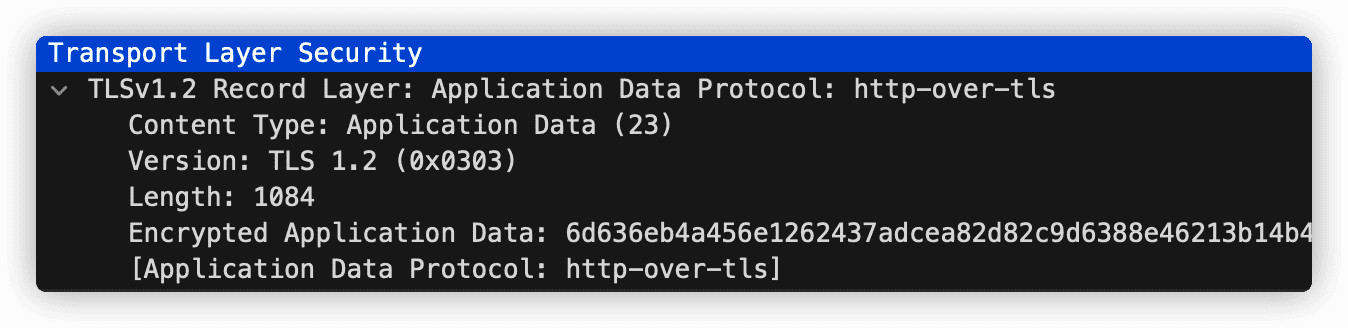
上图是一个数据报文和一个握手报文。
8.6.2 更完整的描述
前面涉及了类SSL,这一节讲解完整的SSL。
1.SSL握手
SSL并不强制Alice和Bob使用一种特定的对称密钥算法、一种特定的公钥算法或一种特定的MAC。SSL允许Alice和Bob在握手阶段在SSL会话开始时就密码算法取得一致。此外,在握手阶段,Alice和Bob彼此发送不重数,不重数被用于4个会话密钥的生成。真正的SSL握手如下:
-
客户发送它支持的密码算法的列表,连同一个客户的不重数。
-
从该列表中,服务器选择一种对称算法(例如AES)、一种公钥算法(例如具有特定密钥长度的RSA)和一种MAC算法。它把它的选择以及证书和一个服务器不重数返回给客户。

-
客户验证该证书,提取服务器的公钥,生成一个前主密钥(Pre-Master Secret,PMS),用服务器的公钥加密该PMS并发送给服务器。
-
使用相同的密钥导出函数,客户和服务器独立地从PMS和不重数中计算出主密钥(MS)。然后该MS被切片以生成两个密码和两个MAC密钥。之后客户和服务器之间发送的所有报文均被加密和鉴别。
-
客户发送所有握手报文的一个MAC。
-
服务器发送所有握手报文的一个MAC。
最后两个步骤使握手免受篡改危害。由于第一步中客户提供算法列表时还没有被加密,以明文形式发送,Trudy作为中间人可以从列表中删除较强算法迫使客户选择较弱的算法,为了防止这种篡改攻击,步骤5客户发送一个级联它已发送和接收的所有握手报文的MAC。服务器比较这个MAC与它接收和发送的握手报文的MAC,如果不一致则终止该连接。类似地,服务器也发送握手报文的MAC用于客户检查不一致性。
在步骤1和步骤2中使用的不重数,是为了防止重放攻击。假设Trudy嗅探了Alice和Bob之间的所有报文,第二天Trudy冒充Bob向Alice发送正好是前一天Bob向Alice发送的相同的报文序列。如果Alice没有使用不重数,她将以前一天发送的完全相同的序列报文进行响应。如果Alice是一个电子商务服务器,她将认为Bob进行第二次认购。另一方面,在协议中包括了一个不重数,Alice将对每个TCP会话发送不同的不重数,使得这两天的加密密钥不同。因此,当Alice接受到来自Trudy重放的SSL记录时,该记录将无法通过完整性检查。总而言之,在SSL中,不重数用于防御“连接重放”,而序号用于防御在一个进行中的会话中重放个别分组。
2.连接关闭
如果Bob直接使用底层的TCP连接(通过发送FIN报文段)来终止该SSL会话,则会造成截断攻击(truncation attack)。此时Trudy可以介入一个SSL会话中并用TCP FIN过早地结束该会话。解决该问题的办法是在类型字段中指出该记录是否是用于终止该SSL会话(尽管SSL类型是以明文形式发送的,但在接收方使用了记录的MAC对它进行鉴别)。
8.7 网络层安全性:IPsec和虚拟专用网
IP安全(IP Security)协议常被称为IPsec,它为网络层提供安全性。IPsec为任意两个网络层实体(包括主机和路由器)之间的IP数据报提供安全。许多机构(公司、政府部分等等)使用IPsec创建了运行在公共因特网之上的虚拟专用网(Virtual Private Network,VPN)。
现在考虑网络层提供机密性的意义,在网络实体对之间(例如两台路由器之间,两台主机之间或路由器和主机之间)具有网络层机密性,发送实体加密它发送给接收实体的所有数据报的载荷。这种载荷可以是一个TCP报文段、一个UDP报文段、一个ICMP报文段等等。从一个实体向其他实体发送的所有数据报将隐性于任何可能嗅探该网络的第三方,发送的数据报包括电子邮件、Web网页、TCP握手报文和管理报文。正因为如此,网络层安全性被认为提供了“地毯覆盖”。
IPsec提供了机密性、源鉴别、数据完整性和重放攻击防护。
8.7.1 IPsec和虚拟专用网
**专用网络(private network)**是指部署一个单独的物理网络,该网络包括路由器、链路和DNS基础设施且与公共因特网分离。专用网络可能耗资巨大,因为需要购买、安装和维护物理网络基础设施。
不同于部署和维护一个专用网络,如今许多机构在现有的公共因特网上创建VPN。使用VPN,机构办公室之间的流量经公共因特网而不是经物理上独立的网络发送。办公室之间的流量在进入公共因特网之前进行加密以提供机密性。
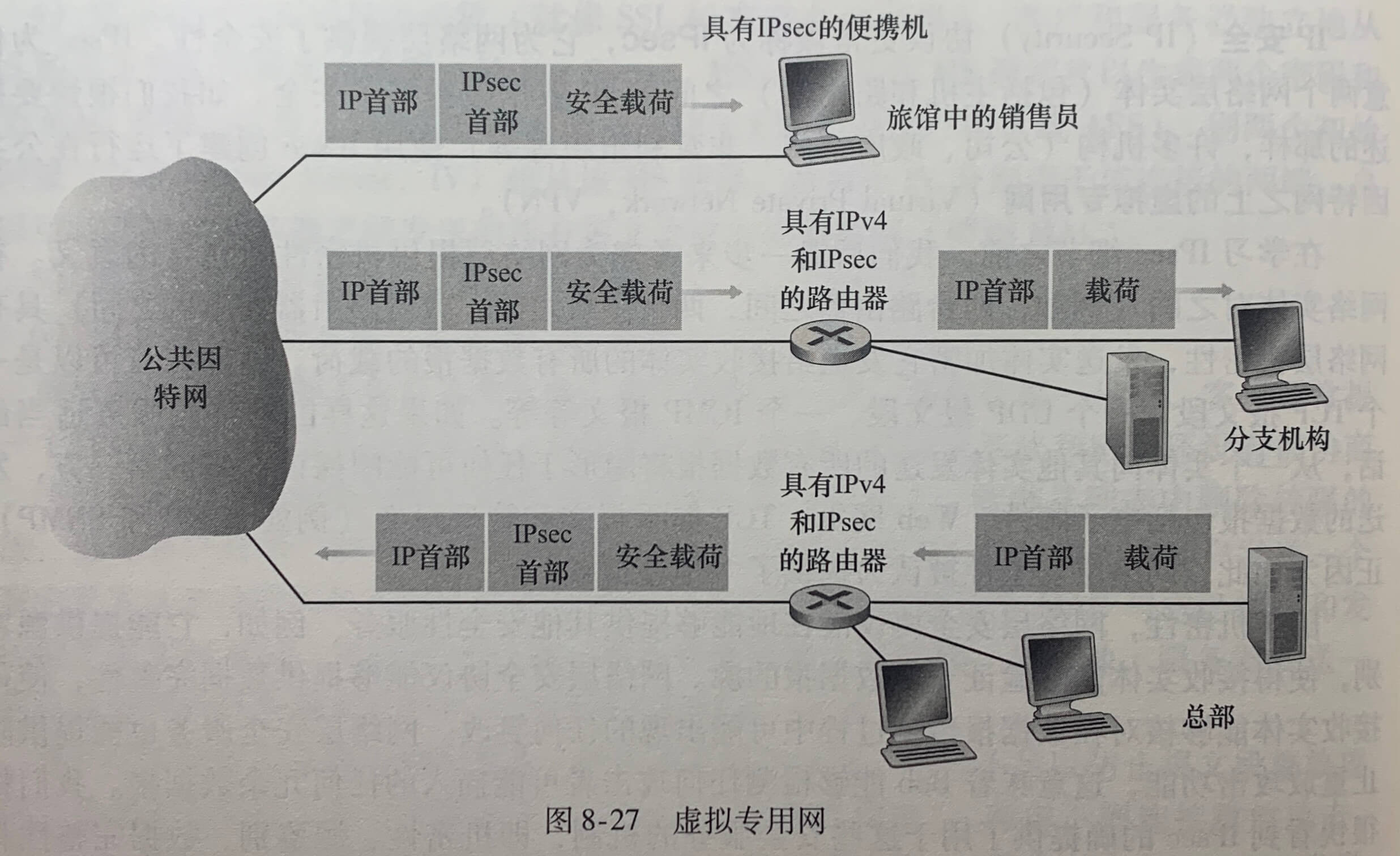
上图中,当总部中的一台主机向某旅馆中的某销售员发送一个IP数据报时,总部中的网关路由器将经典的IPv4转换成IPsec数据报并发送到公共因特网。该IPsec数据报实际上具有传统的IPv4首部,因此在公共因特网中的路由器处理该数据报,仿佛它对路由器而言是一个普通的IPv4数据报。不过IPsec数据报的载荷包括一个IPsec首部(被用于IPsec处理),还有一个被加密的安全载荷。当IPsec到达销售员的便携机时,便携机的操作系统解密载荷(并提供其他安全性服务,如验证数据完整性),并将解密的载荷传递给上层协议(例如TCP或UDP)。
8.7.2 AH协议和ESP协议
IPsec是一个相当复杂的整体,它被定义为10多个RFC文档。在IPsec协议族中,有两个主要协议:**鉴别首部(Authentication Header,AH)协议和封装安全性载荷(Encapsulation Security Payload,ESP)**协议。当某源IPsec实体(通常是一台主机或路由器)向一个目的实体(通常也是一台主机或路由器)发送安全数据报时,它可以使用AH或ESP来做到。AH协议提供源鉴别和数据完整性服务,但不提供机密性服务。ESP协议提供源鉴别、数据完整性和机密性服务。机密性通常对VPN和其他IPsec应用是至关重要的,所以ESP协议的使用比AH协议要广泛得多。后面将专门关注ESP协议。
8.7.3 安全关联
IPsec数据报在网络实体之间发送,在从源实体向目的实体发送IPsec数据报之前,源和目的实体创建了一个网络层的逻辑连接,这个逻辑连接称为安全关联(Security Asociation,SA)。一个SA是一个单工逻辑连接(从源到目的地是单向的)。如果两个实体需要互相发送安全数据报,需要创建两个SA,每个方向一个。
并非从网关路由器或便携机发送进因特网的数据报都是IPsec,例如总部中的一台主机要访问公共因特网中的某Web服务器(网关路由器将发送经典的IPv4数据报和安全的IPsec数据报进入因特网)。
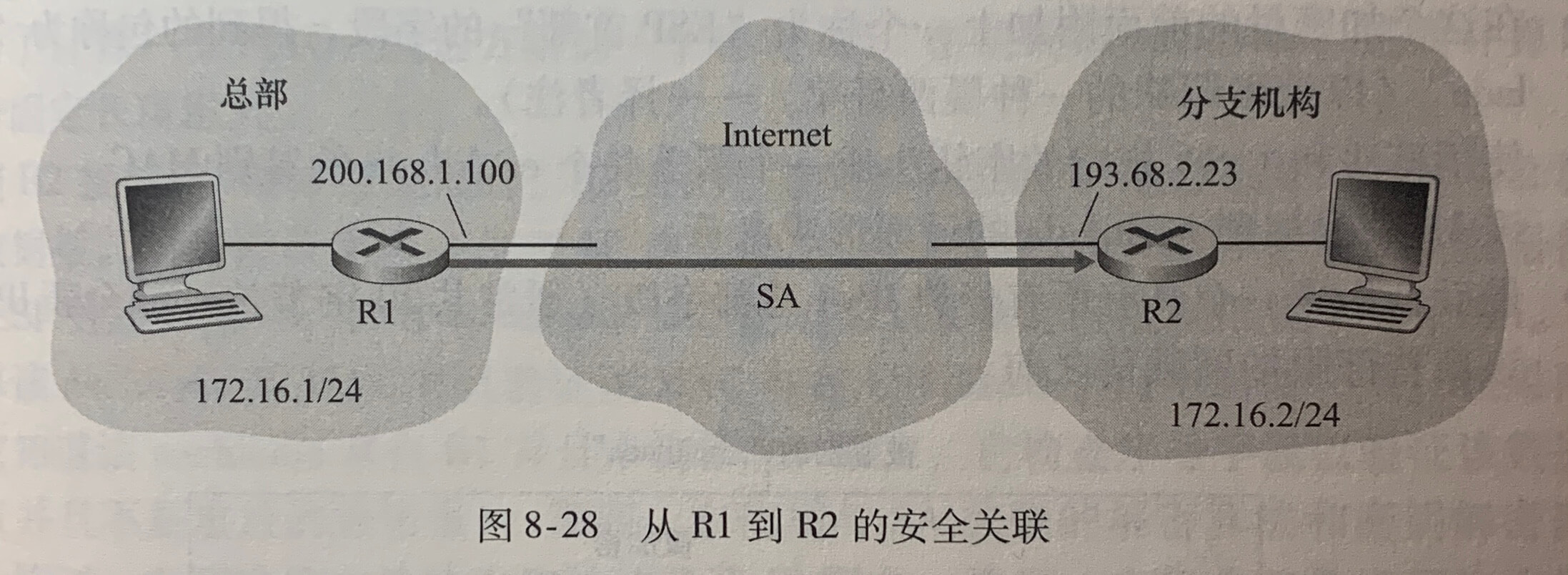
现在考察下SA的“内部”,如上图,路由器R1将维护有关该SA的状态信息,这将包括:
- SA的32比特的标识符,称为安全参数索引(SPI)。
- SA的初始接口(200.168.1.100)和SA的目的接口(193.68.2.23)。
- 将使用的加密类型。
- 加密密钥。
- 完整性检查的类型。
- 鉴别密钥。
路由器R1需要构建一个IPsec数据报经过这个SA转发,它访问该状态信息以决定它应当如何鉴别和加密该数据报。路由器R2将维护对此SA的相同的状态信息,并将使用该信息鉴别和加密任何从该SA到达的IPsec数据报。
一个IPsec实体(路由器或主机)经常维护许多SA的状态信息,一个IPsec实体在它的**安全关联数据库(Security Association Database,SAD)**中存储其所有SA的状态信息,SAD是实体操作系统内核中的一个数据结构。
8.7.4 IPsec数据报
IPsec有两种不同的分组形式,一种用于隧道模式(tunnel mode),另一种用于运输模式(transport mode)。更适合VPN的隧道模式比运输模式拥有更广泛的部署。为了进一步讲清IPsec和避免许多难题,这里专门关注隧道模式。一旦掌握隧道模式,运输模式也就很容易了。

上图显示的是IPsec数据报的分组格式。参考图8-28,假设总部向机构发送一个数据报,路由器R1从总部主机收到普通IPv4数据报,路由器R1使用下列方法将普通数据报转换成IPsec数据报:
- 在初始IPv4数据报(它包括初始首部字段)后面附上一个“ESP尾部”字段。
- 使用算法和由SA规定的密钥加密该结果。
- 在这个加密量的前面附上一个称为“ESP首部”的字段,得到的包称为“enchilada”(以辣椒调味的一种墨西哥菜)。
- 使用算法和由SA规定的密钥生成一个覆盖整个enchilada的鉴别MAC。
- 该MAC附加到enchilada的后面形成载荷。
- 最后,生成一个具有所有经典IPv4首部字段(通常共20字节长)的全新IP首部并附加到载荷之前。
得到的IPsec数据报是一个货真价实的IPv4数据报,它具有传统的IPv4首部字段后跟一个载荷。注意,新的IP首部不并使用IPv4首部的源地址和目的地址,而是使用SA的初始接口和目的接口作为源IP地址和目的IP地址,还有一个是协议号不会被设置为TCP、UDP或SMTP,而是设置为50,指示这是一个使用ESP协议的IPsec数据报。
在R1将IPsec数据报发送进公共因特网之后,它在到达R2之前将通过许多路由器,这些路由器中的每个将处理该数据报,将像它是一个普通数据报一样,因为在微秒首部的目的IP地址是R2,所以该数据报的最终目的是R2。
现在来观察enchilada的组成,ESP尾部由三个字段组成,由于块密码要求被加密的报文必须为块长度的整数倍,所以需要对齐填充(由无意义的字节组成)。填充长度指示接收实体插入的填充是多少。下一个首部字段指示包含在载荷数据字段中数据的类型(例如UDP)。ESP首部以明文发送,SPI字段指示接收实体该数据报属于哪个SA,接收实体则能够用该SPI索引其SAD以确定适当的鉴别/解密算法和密钥。序号字段用于防御重放攻击。
当R2接收到IPsec数据报时,看到目的IP地址是R2自身,因此将处理该数据报。R2看到协议字段是50因此对该数据报施加IPsec ESP处理,如下:
- 针对enchilada,R2使用SPI以确定该数据报属于哪个SA。
- 计算该enchilada的MAC并且验证该MAC与在ESP MAC字段中的值一致
- 检查序号字段以验证该数据报是新的
- 使用于SA关联的解密算法和密钥解密该加密单元
- 删除填充并抽取初始的普通IP报文
- 朝着最终目的将该初始数据报转发进分支机构网络。
除了SAD(安全关联数据库)之外,IPsec实体还维护另一个数据结构(安全策略库(Security Policy Database,SPD)),它指示哪些类型的数据报将被IPsec处理,并且对这些将被IPsec处理的数据报应当使用哪个SA。
8.7.5 IKE:IPsec中的密钥管理
**因特网密钥交换(Internet Key Exchange,IKE)**协议用于自动生成SA。IKE与SSL中的握手有某些类似。每个IPsec实体具有一个整数,该整数包含该实体的公开密钥。如同使用SSL一样,IKE协议让两个实体交换证书,协商鉴别和加密算法,并安全地交换用于在IPsec SA中生成会话密钥的密钥材料。与SSL不同的是,IKE应用两个阶段来执行这些任务。
8.8 使无线LAN安全
在无线网络中安全性是特别重要的关注因素,因为这时携带数据帧的无线电波可以传播到远离包含无线基站和主机的建筑物以外的地方。
8.8.1 有线等效保密(WEP)
有线等效保密(WEP)意欲提供类似于在有线网络中的安全性水平。
WEP的安全性问题较多,无法进行完整性技术检测、会造成密钥泄漏等等。
8.8.2. IEEE 802.11i
IEEE 802.11i提供了强得多的加密形式、一种可扩展的鉴别机制集合以及一种密钥分发机制。

如上图,除了无线客户和接入点外,802.11i定义了一台鉴别服务器,AP能够与它通信。鉴别服务器与AP的分离使得一台鉴别服务器服务于许多AP,降低AP的成本和复杂性。
802.11i运行分为4个阶段:
- 发现。在发现阶段,AP通告它的存在以及它能够向无线客户节点提供的鉴别和加密形式。客户则请求它希望的特定鉴别和加密形式。此阶段客户还没被鉴别,也还没有加密密钥。
- 相互鉴别和主密钥(MK)生成。鉴别发生在无线客户和鉴别服务器之间,接入点起到一个中继的作用,在客户和鉴别服务器之间转发报文。
- 成对主密钥(Pairwise Master Key,PMK)生成。MK是一个仅为客户和鉴别服务器所知的共享密钥,它们都使用MK来生成一个次密钥,即成对主密钥(PMK)。鉴别服务器向AP发送该PMK。
- 临时密钥(Temporal Key,TK)生成。使用PMK,无线客户和AP现在能够生成附加的、将用于通信的密钥。TK将被用于执行经无线链路向任意远程主机发送数据的链路级的加密。
8.9 运行安全性:防火墙和入侵检测系统
在计算机网路中,当通信流量进入/离开网络时要执行安全检查、做记录、丢弃和转发,这些工作都由被称为防火墙、入侵检测系统(IDS)和入侵防止系统(IPS)的运行设备来完成。
8.9.1 防火墙
**防火墙(firewall)**是一个软硬的结合体,它将一个机构的内部网络与整个因特网隔离开,允许一些数据分组通过而阻止另一些分组通过。防火墙具有3个目标:
-
从外部到内部和从内部到外部的所有流量都通过防火墙。
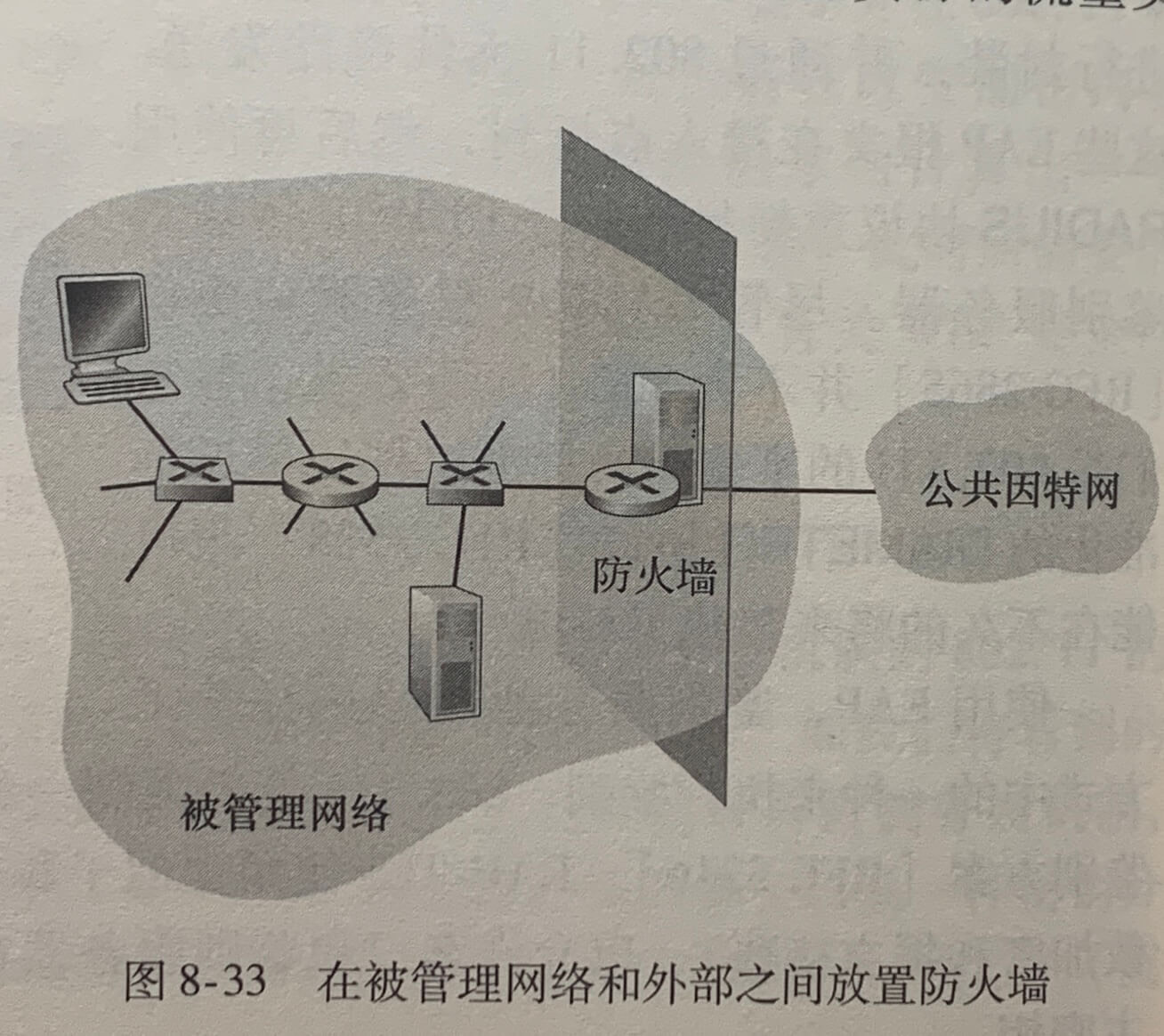
-
仅被授权的流量(由本地安全策略定义)允许通过。
-
防火墙自身免于渗透。
防护墙能够分为3类:传统分组过滤器(traditional packet filter)、状态过滤器(stateful filter)和应用程序网关(application gateway)。
1.传统的分组过滤器
如上图所示,一个机构通常都有一个将其内部网络与其ISP相连的网关路由器。所有离开和进入内部网络的流量都要经过这个路由器,这个路由器正是分组过滤出现的地方。分组过滤器独立地检查每个数据报,然后基于管理员特定的规则决定该数据报应当允许通过还是丢弃。过滤决定通常基于下列因素:
- IP源或目的地址。
- 在IP数据报中的协议类型字段:TCP、UDP、ICMP、OSPF等。
- TCP或UDP的源和目的端口。
- TCP标志比特:SYN、ACK等。
- ICMP报文类型。
- 数据报离开或进入网络的不同规则。
- 对不同路由器接口的不同规则。
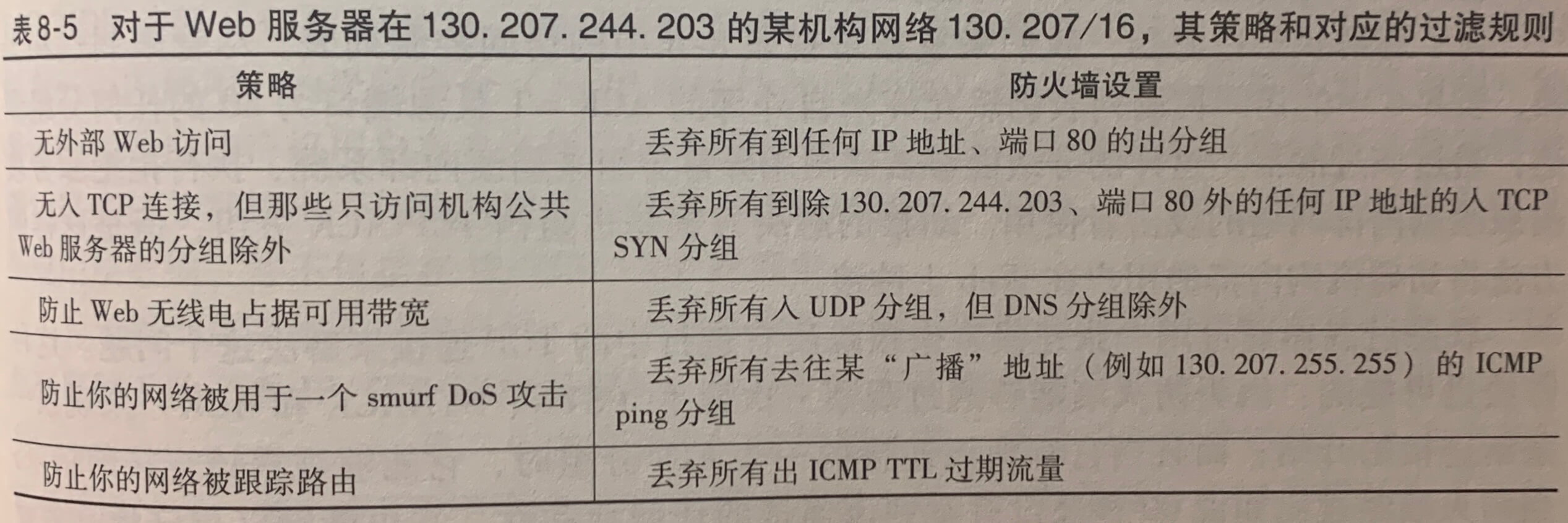
2.状态分组过滤器
传统的分组过滤器容易被异常分组崩溃内部系统、执行拒绝服务攻击或绘制内部网络的攻击者使用。状态过滤器通过用一张连接表来跟踪所有进行中的TCP连接来解决这个问题。
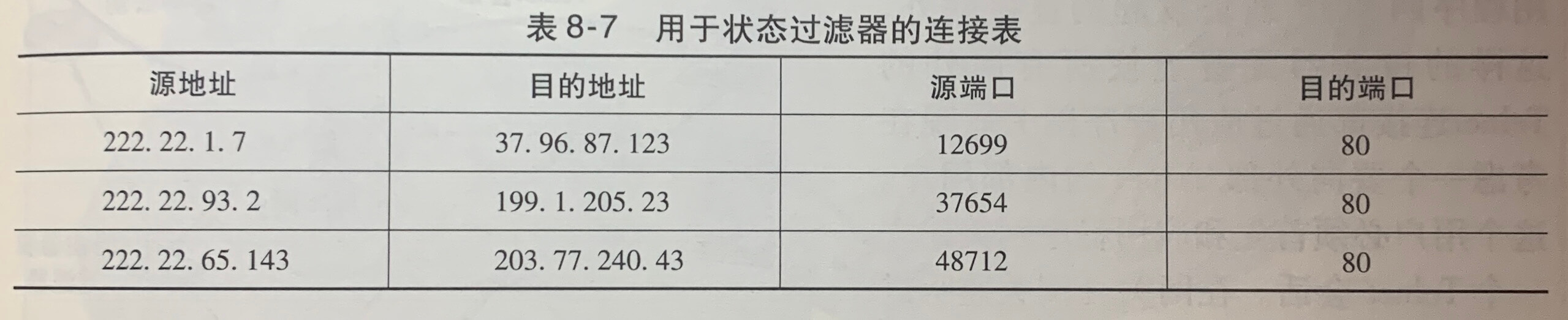
上表中显示了当前有3条进行中的TCP连接,所有的连接都从该机构内部发起的。此外,该状态过滤器在它的访问控制表中包括了一个新栏,即“核对连接”。
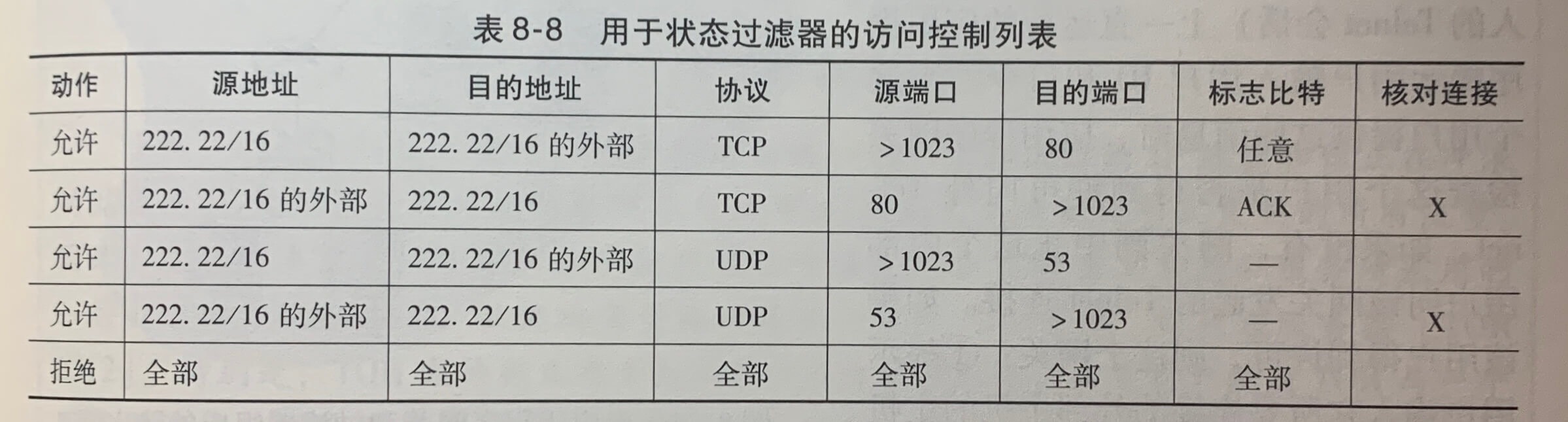
当外部的分组要进入该网络时,需要在上表中进行核对连接,如果不属于核对连接,则抛弃该分组,从而达到阻止异常分组的目的。
3.应用程序网关
应用程序网关除了看IP/TCP/UDP首部外,还基于应用数据来做策略决定。一个**应用程序网关(application gateway)**是一个应用程序特定的服务器,所有应用程序(入和出)都必须通过它。多个应用程序网关可以在同一主机上运行,但是每一个网关都是有自己的进程的单独服务器。

内部网络通常由多个应用程序网关,例如Telnet、HTTP、FTP和电子邮件网关。事实上,一个机构的邮件服务器和Web高速缓存都是应用程序网关。
匿名与隐私
当要访问一个有争议性的Web网站时,并且1.不想向该Web网络透露你的IP地址;2.不想要你的本地ISP知道你正在访问该站点;3.不想要你的本地ISP看到你正在与该站点交换的数据。
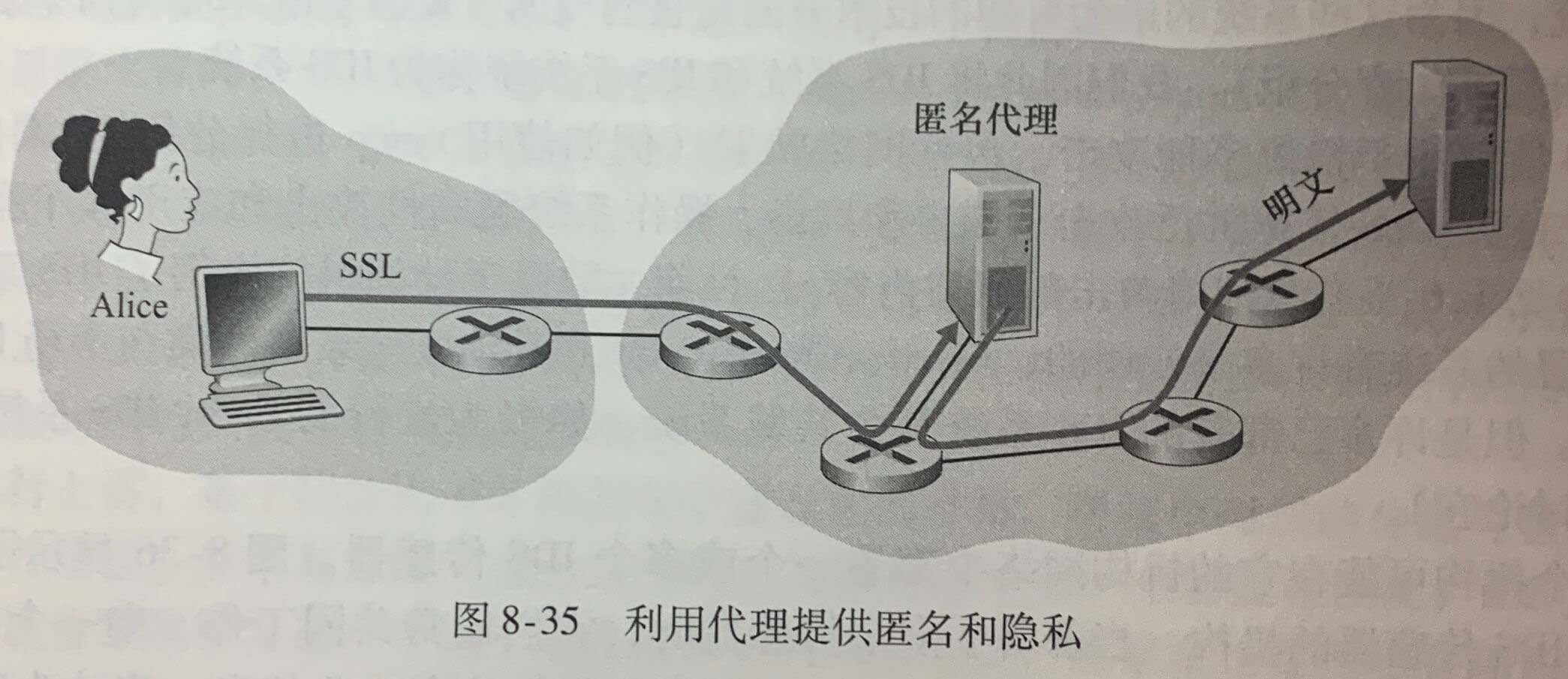
为了获得隐私和匿名,可以使用如上图所示的一种可信代理服务器和SSL的组合。首先与可信代理建立一条SSL连接,然后在该连接中向所希望的站点的网页发送一个HTTP请求。当代理接收到该SSL加密的HTTP请求,它解密请求并向Web站点转发该明文HTTP请求。接下来Web站点响应该代理,该代理经过SSL再向你转发该响应。该Web站点看到的是代理的IP地址,因此获取了对该站点的匿名访问。并且因为和代理之间的所有流量均被加密,本地ISP将无法通过对访问的站点做日志和记录交换的数据来侵犯隐私。今天许多公司提供了这种代理服务。
这个方案的缺点是代理将知道你的一切,这取决于代理的可信度。
8.9.2 入侵检测系统
为了检测多种攻击类型,我们需要执行深度分组检查,即查看首部字段以外的部分,深入查看分组携带的实际应用数据。应用程序网关常被做深度分组检查,而一个应用程序网关仅对一种特定的应用程序执行这种检查。
这为另一种设备提供了商机,即一种不仅能够检查所有通过它传递的分组的首部,而且能执行深度分组检查的设备。当观察到潜在恶意流量时能产生告警的设备称为入侵检测系统(Intrusion Detection System,IDS)。滤除可疑流量的设备称为入侵防止系统(Intrusion Prevention System,IPS)。将这两个系统统称为IDS系统。
IDS能够用于检测多种攻击,包括网络映射(例如使用nmap进行分析)、端口扫描、TCP栈扫描、Dos带宽洪泛攻击、蠕虫和病毒、操作系统脆弱性攻击和应用程序脆弱性攻击。目前,数以千计的机构应用了IDS系统。

上图中,一个机构可能在它的机构网络中部署一个或多个IDS传感器。该机构将其网络划分为两个区域:一个高度安全区域,由分组过滤器和应用程序网关保护,并且由IDS系统监视;一个较低度安全区域(称为非军事区(DeMilitarized Zone,DMZ)),该区域仅由分组过滤器保护,但也由IDS系统监视。DMZ包括了该机构需要与外部通信的服务器。
放置多个IDS传感器的目的是让每个传感器处理更少的数据,这将易于维护。
IDS系统大致可分类为基于特征的系统(signature-based system)或基于异常的分组(anomaly-based system)。基于特征的IDS维护一个范围广泛的攻击特征数据库。每个特征是与一个入侵活动相关联的规则集。基于特征的IDS嗅探每个通过它的分组,将每个嗅探的分组与数据库中的特征进行比较。它的限制在于要求根据以前的攻击知识来产生一个准确的特征,它对新攻击缺乏判断力。而基于异常分组最大的特点是它们不依赖现有攻击的以前知识,比如ICMP分组不寻常的百分比或端口扫描和ping掠过导致指数型突然增长等等,在另一方面,区分正常流量和统计异常流量是一个极具挑战性的问题。迄今为止,大多数部署的IDS主要是基于特定的。
Snort
Snort是一种公共域开放源码的IDS,现有部署达几十万。它能够运行在Linux、UNIX和Windows平台上。它使用了通用的嗅探接口libpcap,Wireshark和许多其他分组嗅探器也使用了libpcap。它能够轻松处理100Mbps的流量;
Snort有巨大的用户社区和维护其特征数据库的安全专家。通常在一个新攻击出现后的几小时内,Snort社区就编写并发布一个攻击特征,然后它就能被分布在全世界的数十万Snort部署者下载。
第9章 多媒体网络
9.1 多媒体网络应用
任何应用音频或视频的网络应用称为多媒体网络应用。
9.1.1 视频的性质
视频最为显著的特点或许是它的高比特率(high bit rate)。经因特网分发的视频的典型传输速率从用于低质量视频会议的100kbps到用于流式高分辨率电影的3Mbps。

视频的另一个重要特点是它能被压缩,因而要在视频质量与比特率间进行折中。视频是一个图像序列,图像通常以恒定的速率显示。比特率越高,图像质量越好,总体用户视觉体验也越好。
我们能够使用压缩来生成相同视频的多重版本,每个版本有不同的质量等级。用户能够根据他们的当前可用带宽来决定要观看哪个版本。
9.1.2 音频的性质
数字音频的带宽需求比视频低得多。我们考虑模拟音频是如何转换为数字信号的:
- 模拟音频信号首先以某种固定速率采样,例如每秒8000个样本。每个采样值是一个任意的实数。
- 然后每个采样值被“四舍五入”为有限个数值中的一个。
- 每个量化值由固定数量的比特表示。
上面描述的基本编码技术称为脉冲编码调制(Pulse Code Modulation,PCM)。语音编码通常采用PCM,采样速率为每秒8000个样本,每个样本用8比特表示,得到64kbps的速率。音频光盘(CD)也使用PCM,采样速率为每秒44100个样本,每个样本16比特表示。
然而,PCM编码的语音和音乐很少在因特网中使用,取得代之的是使用压缩技术来减小流的比特速率。人类语音能被压缩小于10kbps并仍然可懂。一种接近CD质量立体声音乐的流行压缩技术是MPEG 1 第3层,更通常的叫法是MP3。MP3编码器通常能够压缩为许多不同的速率;128kbps是最常使用的编码速率,能够产生非常小的声音失真。一种相关的标准是高级音频编码(Advanced Audio Coding,AAC),该标准随苹果公司而流行起来。与视频一样,音频能够以不同的比特率生成多重版本的预先录制的音频流。
9.1.3 多媒体网络应用的类型
多媒体应用分为三大类:1.流式存储音频/视频;2.会话式IP语音/视频;3.流式实况音频/视频。
1.流式存储音频和视频
在这类应用中,依赖的媒体是预先录制的视频(如电影、电视节目)预先录制的体育赛事或预先录制的用户生成的视频(如YouTube)等等。这些预先录制的视频放置在服务器上,用户向服务器发送请求按需观看视频。许多因特网公司今天提供流式视频,包括YouTube、Netflix、Amazon等。流式存储视频具有三个关键的不同特色:
- 流。在流式存储视频应用中,客户开始从服务器接收文件几秒之后,通常就开始播放视频。这意味着当客户从视频的一个位置开始播放时,与此同时正在从服务器接收该视频的后续部分,这种技术被称为流(streaming),它避免了在开始播放之前必须下载整个视频。
- 相互作用。用户可以对媒体内容进行暂停、重新配置、前进等操作。从客户提出这种请求到响应时间应该小于几秒。
- 连续播放。
为了提供连续的播放,网络为流式应用提供的平均吞吐量必须至少与该视频本身的比特率一样大。
2.会话式IP语音和视频
在因特网上的实时会话式语音通常称为因特网电话(Internet telephony),它类似于传统的电路交换电话服务。它也常被称为IP语音(Voice-over-IP,VoIP)。会话式视频与之类似。今天的大多数语音和视频会话式系统允许生成具有三个或更多个参与者的会议。语音和视频会话式应用是高度时延敏感的。
另一方面,会话式多媒体应用容忍丢包,即偶尔的丢失只会在音频/视频回放时偶尔出现干扰信号,而且这些丢失经常可以部分或者全部地隐藏。
3.流式实况音频和视频
这类应用类似于传统的电台广播和电视,只是它通过因特网来传输而已。这些应用允许用户接收从世界上任何角落发出的实况无线电广播和电视传输。实况是类似于广播的应用,这种应用通常是用CDN来实现的。每个实况多媒体须提供大于该视频消耗速率的平均吞吐量,一个用户能容忍的时延最多为10秒。本书不涉及流式实况媒体,因为用于流式实况媒体的许多技术都类似于流式存储媒体所使用的的技术。
9.2 流式存储视频
流式视频系统分为三种类型:UDP流(UDP streaming)、HTTP流和适应性HTTP流(adaptive HTTP steaming)。今天的大多数系统应用都使用HTTP流和适应性HTTP流。
这三种形式的视频流的共同特定是广泛使用了客户端应用缓存,以此来缓解变化的端到端时延和变化的服务器和客户之间可用带宽量的影响。

9.2.1 UDP流
使用UDP流,服务器通过UDP以一种稳定的速率记录下视频块,用与用户的视频消耗速率相匹配的速率传输视频。由于无TCP的速率控制的限制,UDP流通常使用很小的客户端缓存,空间维持小于1秒视频就足够了。
在将视频块传递给UDP之前,服务器将视频块封装在运输分组中,该运输分组是专门为传输音频和视频设计的,使用了**实时传输协议(Real-Time Transport Protocol,RTP)**或某种类似(可能是专用)的方案。
UDP流的另一种不同性质是,除了服务器到客户的视频流外,两者间还并行地维护一个单独的控制连接,通过该连接,客户可发送有关会话状态变化的命令(如暂停、重新开始、重定位等)。这种控制连接在许多方面类似于FTP控制连接,**实时流协议(Real-Time Streaming Protocol,RTSP)**是一种用于这样的控制连接的流行开放协议。
UDP流有三个重大不足:
- 由于服务器和控制之间的可用带宽无法预测且是变化的,恒定速率UDP流不能提供连续的播放。
- 它要求如RTSP(实时流协议)服务器这样的媒体控制服务器,以对每个进行中的客户会话处理客户到服务器的交互请求和跟踪客户状态,这增加了部署大规模的按需视频系统的总体成本和复杂性。
- 许多防火墙配置为阻塞UDP流量,防止这些防火墙后面的用户接收UDP视频。
9.2.2 HTTP流
在HTTP流中,视频直接作为具有一个特定URL的普通文件存储在HTTP服务器上。当用户要看视频时,客户和服务器之间建立一个TCP连接,并且发送一个对该URL的HTTP GET请求。服务器则尽可能快地在HTTP响应报文中发送该视频文件。以TCP拥塞控制和流控制允许的尽可能快的速率进行处理。在客户端上,字节收集在一个客户应用缓存中。一旦在缓存中字节数量超过了预选设定的阀值,该客户应用程序就开始播放,具体而言,它周期性地从客户应用缓存中抓取视频帧,对帧解压缩并在用户屏幕上显示它们。
在TCP上使用HTTP也使得视频穿越防火墙和NAT更为容易。HTTP流消除了因需要媒体控制服务器(如RTSP服务器)带来的不变,减少了在因特网上大规模部署的成本。
1.预取视频
客户端缓存可用于缓解变化的端到端时延和变化的可用带宽的影响。
2.客户应用缓存和TCP缓存
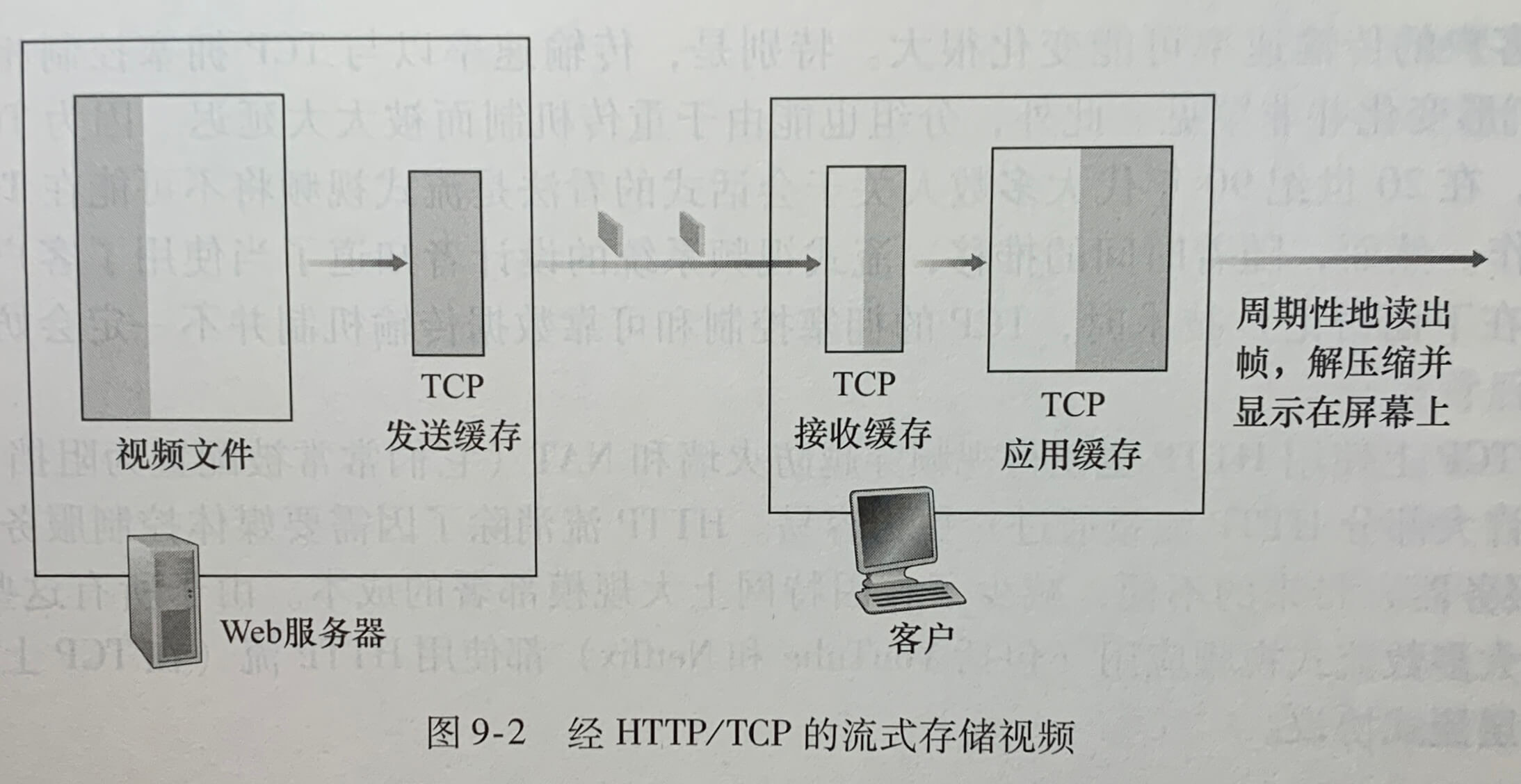
上图中,因为TCP发送缓存已满,服务器立刻防止从视频文件向套接字发送更多的字节。
当流播放视频期间用户暂停视频时,在暂停期间,比特未从用户应用缓存中删除,客户应用缓存有限,由于它一直接收服务器的比特,这将导致它最终变满,这将反过来引起对服务器的“反向压力”,最终服务器传输会被阻塞,直到用户恢复该视频。
事实上,甚至在常规的播放过程中,如果客户端视频消耗速率比服务器发送速率慢,这也将迫使服务器降低其速率。因此,当使用HTTP流时,一个满的客户应用缓存间接地对服务器到客户能发送的视频速率施加了限制。
3.流式视频的分析
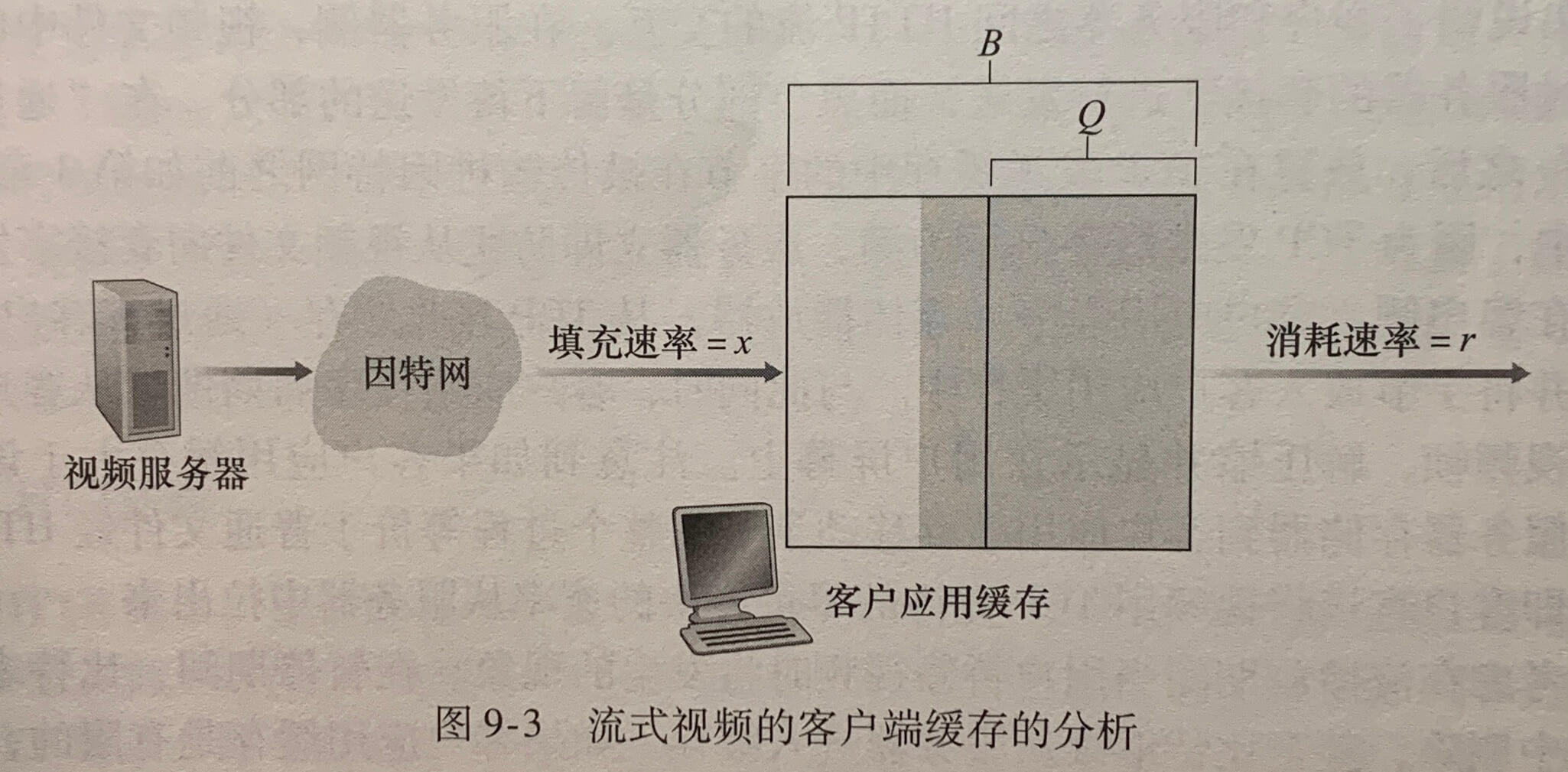
上图中,B表示客户应用缓存的长度(以比特计),Q表示在客户应用缓存开始播放之前必须被缓存的比特数量,r表示视频消耗速率。我们假定客户缓存都为非空,服务器以一种恒定速率x发送比特。因此,建立Q比特所需的时间(初始缓存时延)是 t p = Q / x t_p=Q/x tp=Q/x。
当网络中可用速率小于视频速率时,播放将在连续播放期和停滞播放之间进行变动。
4.视频的早期中止和重定位
HTTP流系统经常利用HTTP GET请求报文中的HTTP字节范围首部(HTTP byterange header),该首部指示了客户当前要从所希望的视频中获取的字节范围。当用户重定位到一个新位置时,客户发送一个新HTTP请求,用字节范围首部指出服务器应当从文件的哪个字节起发送数据。当服务器收到该新的HTTP请求时,它能够忘记任何较早的请求,而是由字节范围请求中指示的字节开始发送。
由于重定位会造成网络带宽和服务器资源的浪费,许多流系统仅使用了长度适当的客户应用缓存,或者将限制在HTTP请求中使用字节范围首部预取的视频数量。
9.3 IP语音
会话式视频在许多方面类似于VoIP,除了它包括参与者的视频以及他们的语言一台。
9.3.1 尽力而为服务的限制
这些应用对分组时延、时延抖动和丢包非常敏感。接收方必须更仔细地判断:1.什么时候播放一个块;2.如何处理一个丢失块。
1.丢包
考虑由VoIP应用产生的一个UDP报文段,这个UDP报文段封装在IP数据报中。由于数据报需要经过路由器的缓存,当缓存已满时该IP数据报将被丢弃。通过TCP而不是UDP发送分组可以消除丢失。然而,重传机制对于诸如VoIP这样的会话式实时音频应用通常认为是不可接受的,因为它增加了端到端时延。此外,当丢包发生后,TCP的拥塞控制会降低传输速率。由于这些原因,几乎所有现有的VoIP应用默认运行在UDP上。
分组的丢失并不会造成灾难,实际上这取决于语音是如何编码和传输的以及接收方隐藏丢包的方式,,1%~20%的丢包率是可以忍受的。
2.端到端时延
**端到端时延(end-to-end delay)**是以下因素的总和:路由器的传输、处理和排队时延,链路中的传播时延和端系统的处理时延。对于实时会话式应用,例如VoIP,人对于小于150ms的端到端时延是察觉不到的,不过超过400ms将妨碍语言谈话的交互性。VoIP应用程序的接收方通常忽略时延超过特定阀值的任何分组,因此,时延超过该阀值的分组等效于丢弃。
3.分组时延抖动
端到端时延的一个关键因素是一个分组在网络路由器中经历的变化的排队时延。不同的分组可能会有波动,这个现象称为时延抖动。时延抖动可以通过使用序号、时间戳和播放时延来消除。
9.3.2 在接收方消除音频的时延抖动
- 为每个块预先计划一个时间戳(timestamp)。发送方用每个块产生的时刻为它加上时间印记。
- 在接收方**延迟播放(delaying playout)**块。
1.固定播放时延
使用固定播放时延,接收方试图在块产生正好q ms后播放它。因此如果一个块在时刻t打上时间戳,接收方在t+q播放这个块,假设这个块在那个时间已经到达。在预定播放时间之后到达的分组将被丢弃,并被认为已经丢失。
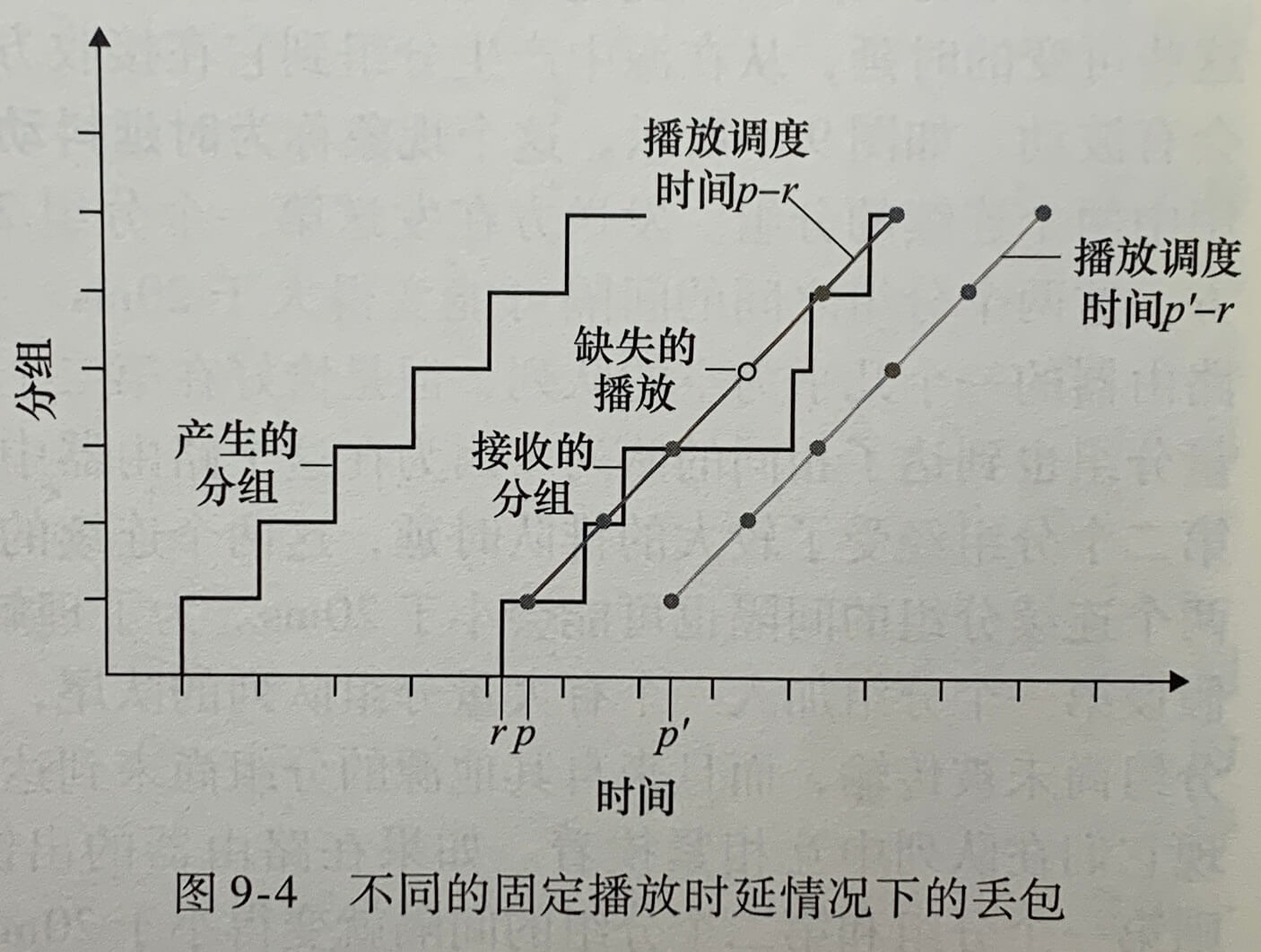
2.适应性播放时延
在每个话音突峰期的开始相应地调整播放时延。
9.3.3 从丢包中恢复
丢包定义:如果某分组不能到达接收方或者在它调度的播放时间之后才到达,该分组则丢失。
两种类型的丢包预期方案是前向纠错(Forward Error Correction,FEC)与交织(interleaving)。
1.前向纠错
FEC的基本思想是给初始的分组流增加冗余信息。以稍微增加传输速率为代价,这些冗余信息可以用来重建一些丢失分组的近似或者准确版本。现在概括两种简单的FEC机制。第一种机制是每发送n个块之后,发送一个冗余编码的块。这个冗余块通过异或n个初始块来获得。以这种方式,在这n+1个分组的组中,如果任何一个分组丢失,接收方能够完全重建丢失的分组。但是如果这一组中有两个或更多分组丢失,接收方则无法重建丢失的分组。不过这个简单的方案增加了播放时延,因为接收方在能够播放之前必须等待收到整个组的分组。
第二个FEC机制是发送一个较低分辨率的音频流作为冗余信息。例如,发送方可能创建一个标称的音频流和一个相应的低分辨率、低比特率的音频流。这个低音频流被认为是冗余信息。发送方通过从这个标称中取出第n个块并附加第(n-1)个块的冗余信息,以构建第n个分组。以这种方式,只要没有连续分组的丢失,接收方都可以通过播放和后续分组一起到达的低比特率编码块来隐藏丢失。此方案的缺点是附加的块增加了传输带宽和播放时延。
2.交织
发送方在传输之前对音频数据单元重新排序,使得最初相邻的单元在传输流中以一定距离分离开来。交织可以减轻丢包的影响。

交织能够明显地提高音频流可感觉到的质量。它的开销也较低。交织明显的缺点是增加了时延。这限制了它在如VoIP这样的会话式应用中的使用,然而它能够很好地处理流式存储视频。交织的一个主要优点是它不增加流的带宽需求。
3.差错掩盖
差错掩盖方案视图为丢失的分组产生一个与初始分组类似的替代物。由于音频信号呈现出大量的短期自相似性,故该方案是可行的。这些技术适合于工作在相对小的丢包率(低于15%)和小分组(4~40ms)的情况。最简单的方式是分组重复,即用在丢失之前刚到达的分组的副本来代替丢失的分组。这种方法的计算复杂度低,且工作得相当好。另外一种是内插法,它使用在丢失之前和之后的音频内插形成一个合适分组来隐藏丢失。内插法比分组重复稍微好一些,但是显然需要更高的计算强度。
9.3.4 学习案例:使用Skype的VoIP
Skype客户都有许多自行支配的不同编解码器,这些编解码器能够以宽泛的速率和质量对媒体进行编码。Skype的视频速率从用于低质量会话的低至30kbps到用于高质量会话的高于1Mbps左右。一般而言,Skype语言质量好于由有线电话系统提供的“POTS(简单老式电话服务)”的质量。在默认字体下,Skype通过UDP发送音频和视频分组。控制分组经TCP发送,并且当防火墙阻挡UDP流时,媒体分组也通过TCP发送。Skype对于经UDP发送的语音和视频流使用FEC(前向纠错)处理丢包恢复。

Skype以一些创新方式使用P2P技术。
9.4 实时会话式应用的协议
实时会话式应用(包括VoIP和视频会议)引人入胜并且非常流行。本节讨论用于实时会话式应用的RTP和SIP。
9.4.1 RTP
在前一节中,我们知道VoIP应用的发送端在将块传递给运输层之前为它们附加上首部字段。这些首部字段包括了序号和时间戳。**RTP(实时传输协议)**能够用于传输通用格式,如用于声音的PCM、ACC和MP3,用于视频的MPEG和H.263。它也可以用于传输专用的声音和视频格式。目前,RTP在许多产品和研究原型中得到广泛实现。它也是其他重要的实时交互协议(如STP)的补充。
1.RTP基础
RTP通常运行在UDP上。发送端在RTP分组中封装媒体块,然后在UDP报文段中封装该分组,然后将该报文段递交给IP。接收端从UDP报文段中提取出这个RTP分组,然后从RTP分组中提取出媒体块,并将这个块传递给媒体播放器来解码和呈现。
发送端在每个语音数据块的前面加上一个RTP首部,RTP首部包括音频编码的类型、序号和时间戳。RTP首部通常是12字节。音频块和RTP首部一起形成RTP分组。在接收端,应用程序从它的套接字接口收到该RTP分组,从RTP分组中提取出该音频块,并且使用RTP分组的首部字段来适当地解码和播放该音频块。
如果一个应用程序集成了RTP,而非专用方案,则该应用程序将更容易和其他网络的多媒体应用程序互操作。RTP经常和SIP一起使用,SIP是一种因特网电话的重要标准。
RTP不提供任何机制来确保数据的及时交付,或者提供其他服务质量保证。RTP封装的东西仅为端系统所见。路由器不区分携带RTP分组的数据报和不携带RTP分组的IP数据报。
2.RTP分组首部字段

- 有效载荷类型用于确认音频或视频的编码格式。
- 序号用于接收方检测丢包和恢复分组序列。
- 同步源标识符(SSRC)标识了RTP流的源。通常在RTP会话中的每个流都有一个不同的SSRC。SSRC不是发送方的IP地址,而是当新的流开始时随机分配的一个数。
9.4.2 SIP
**会话发起协议(Session Initiation Protocol,SIP)**是一个开放和轻型的协议,其功能如下:
- 提供了在主叫者和被叫者之间经IP网络创建呼叫的机制。它允许主叫者通知被叫者它要开始一个呼叫。它允许参与者约定媒体编码,也允许参与者结束呼叫。
- 提供了主叫者确定被叫者的当前IP地址的机制。
- 提供了用于呼叫管理的机制,这些机制包括在呼叫期间增加新媒体流、在呼叫期间改变编码、在呼叫期间邀请新的参与者、呼叫转移和呼叫保持等。
1.向已知IP地址建立一个呼叫
上图中,Alice使用PC,且要呼叫Bob,Bob也使用PC。我们假设Alice知道Bob PC的地址。Alice首先向Bob发送一个INVITE报文(通过UDP发送给SIP的周知端口5060),INVITE报文包括了对Bob的标识,Alice当前的IP地址、Alice希望接收的音频的知识,以及她希望在端口38060接收RTP分组的指示。之后Bob发送一个SIP响应报文。注意到:Alice和Bob准备使用不同的编码机制。在接收到Bob的响应后,Alice发送SIP确认报文。在这个SIP事务之后,他们可以交谈了。
从上述简单例子中总结出:1.SIP是一个带外协议,即发送和接收SIP报文使用了一个不同于发送和接收媒体数据的套接字。2.SIP报文本身是可读的ACSII,这与HTTP报文类似。3.SIP要求所有的报文都要确认,因此它能够在UDP或TCP上运行。
2.SIP地址
SIP地址可以类似电子邮件地址的方式,例如sip: bob@domain.com。SIP地址要可以包括在Web页面中,访问者点击该URL即可发起INVITE报文。
3.SIP报文
上图是一个INVITE的SIP报文,任何时候SIP设备会附加上一个Via首部来指示该设备的IP地址。Call-ID唯一地表示该呼叫。
4.名字翻译和用户定位
现在我们假设Alice只知道Bob的电子邮件地址bob@doamin.com。在此情况下,Alice需要获取Bob正在使用的设备的IP地址。Alice创建一个INVITE报文,并将该报文发送给一个SIP代理。该代理将以一个SIP回答来响应。该回答中可能包含Bob正在使用的设备的IP地址,该回答也可以包含Bob的语音信箱的IP地址或一个Web页面的URL。代理返回的结果页可能取决于呼叫者:如果呼叫是Bob的妻子发出的,它可能接受该呼叫,并提供IP地址;如果呼叫是Bob的岳母发出的,它可能用指向“我正在睡觉”的Web页面的URL来响应。
SIP用户都有一个相关联的SIP注册器,任何时候用户在设备上发起SIP应用时,该应用给注册器发送一个SIP注册报文以告知它现在的IP地址。注册器会跟踪Bob的IP地址,无论何时只要Bob切换到一个新的SIP设备也是如此。注册器和DNS权威名字服务器类似:DNS服务器将固定的用户名翻译到固定的IP地址;SIP注册器把固定的人识别标志翻译为一个动态的IP地址。SIP注册器和SIP代理通常运行在同一台主机上。
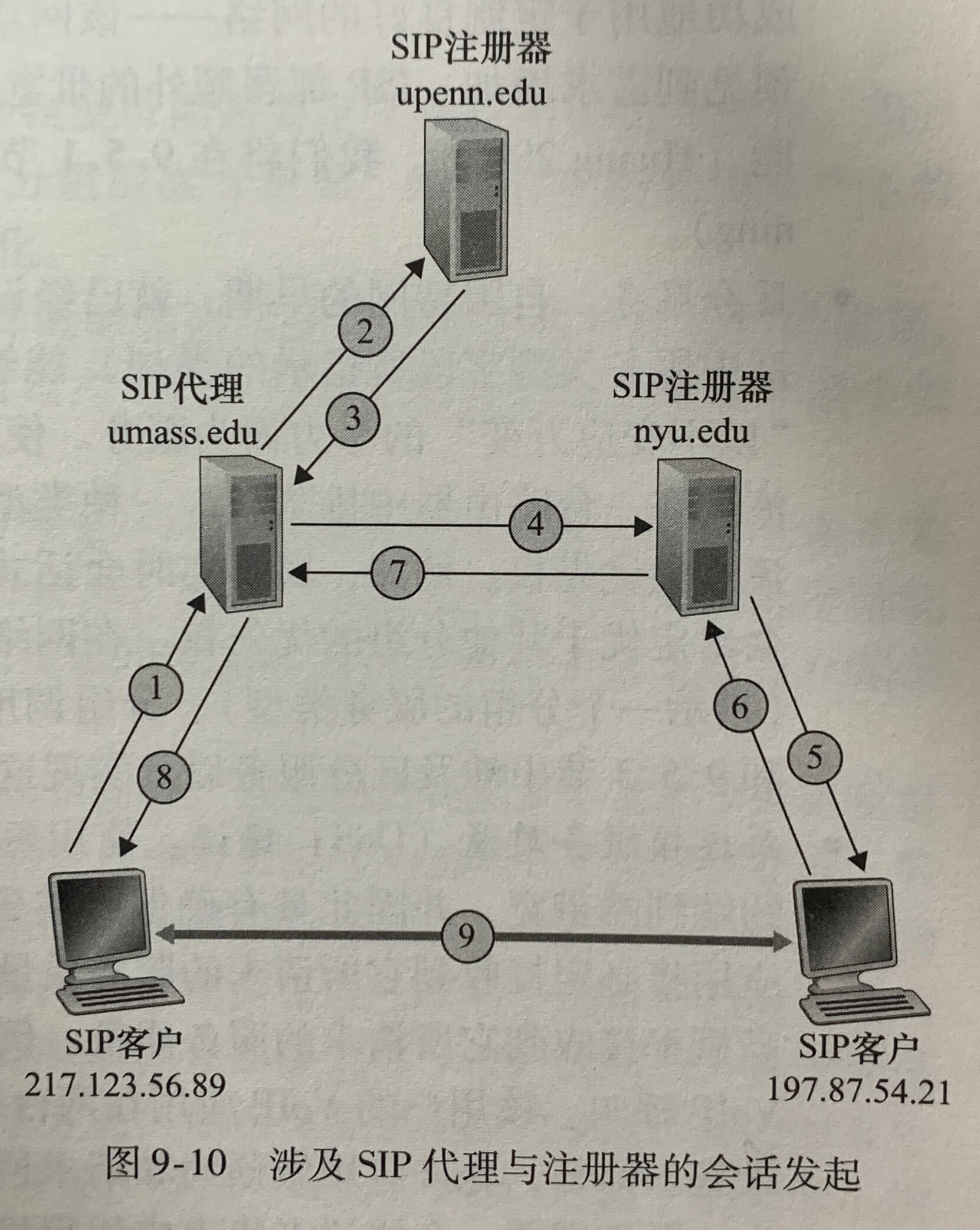
SIP通常是一个发起和结束呼叫的信令协议,它能够用于视频会议呼叫和基于文本的会话。
9.5 支持多媒体的网络
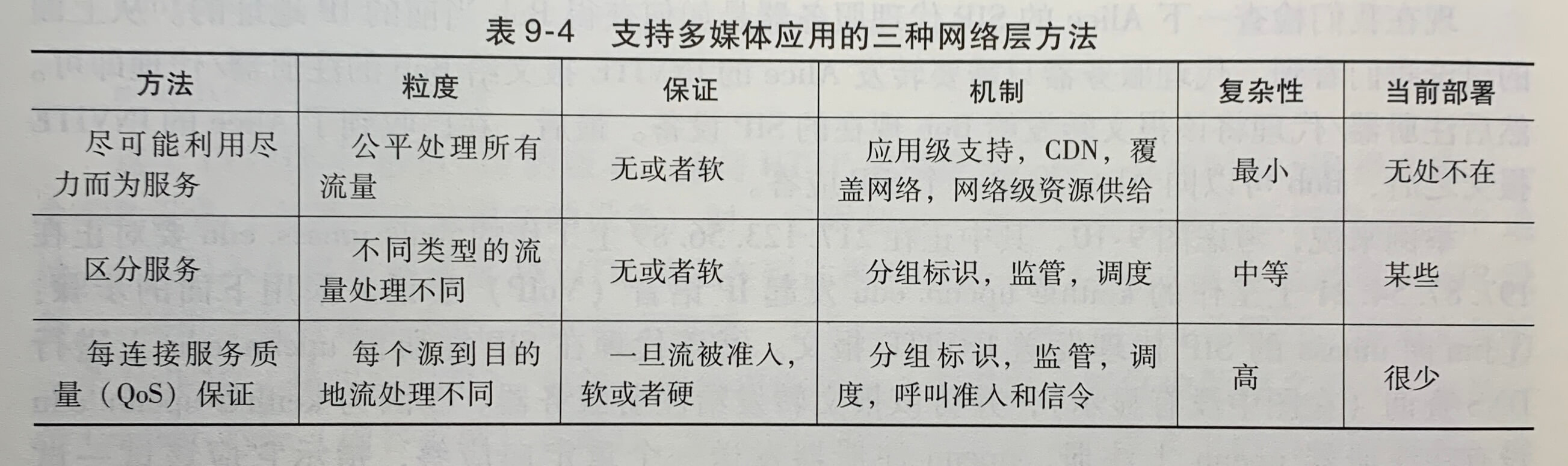
硬保证意味着应用将必定接收到它所请求的服务质量。软保证意味着应用将以高概率接收到它所请求的服务质量。
9.5.1 定制尽力而为网络
改善多媒体应用质量的第一种方法就是“在问题上砸钱”,因此直接避免资源竞争即可。这种方法常用于解决有关资源受限的任何问题。
9.5.2 提供多种类型的服务
将流量划分为多种类型,并为这些不同类型的流量提供不同等级的服务。理想情况下,一种服务要与各类流量有隔离度,以保护一种流量类型免受其他流量类型干扰。
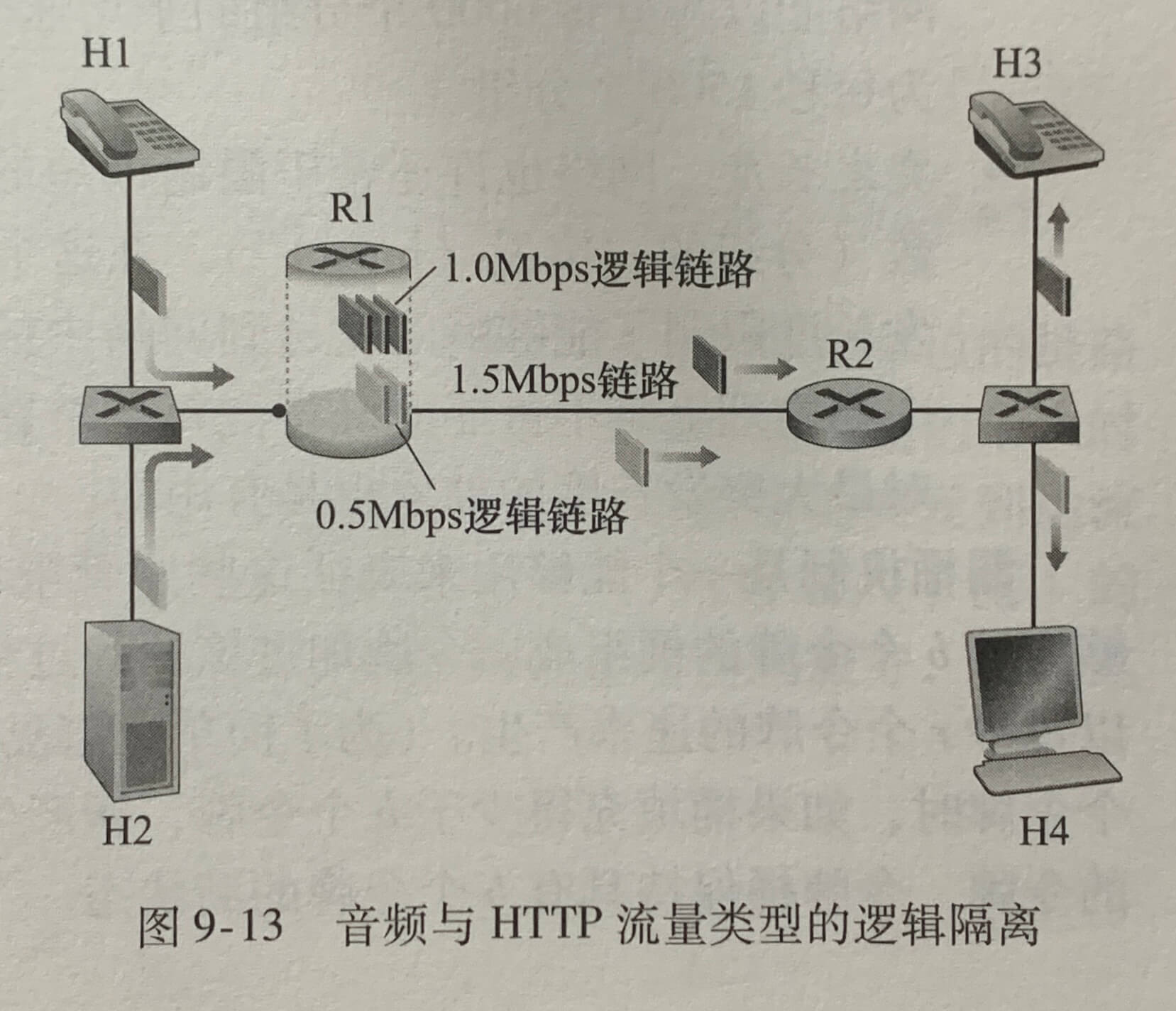
监管分组流的3个重要的监管准则:
- 平均速率。网络可能希望限制一个流的分组能够发送到网络中的长期平均速率(每个时间间隔的分组数)。
- 峰值速率。平均速率约束了一个相对长的时间内能够发送到网络中的流量,而峰值约束限制了一个较短时间内能够发送的最大分组数。
- 突发长度。

上图中,假设一个分组向网络传输之前,必须首先从令牌桶中去除一个令牌。令牌产生速率r用于限制分组能够进入网络的长期平均速率。

9.5.3 区分服务
因特网区分服务(Diffserv)体系结构就是在因特网中以一种可扩展性方式用不同的方法处理不同类型流量的能力。区分服务体系结构由两个功能元素的集合所组成:
- 边界功能:分组分类和流量调节。在IPv4或者IPv6分组首部中的区分服务(DS)字段被设置为某个值。
- 核心功能:转发。
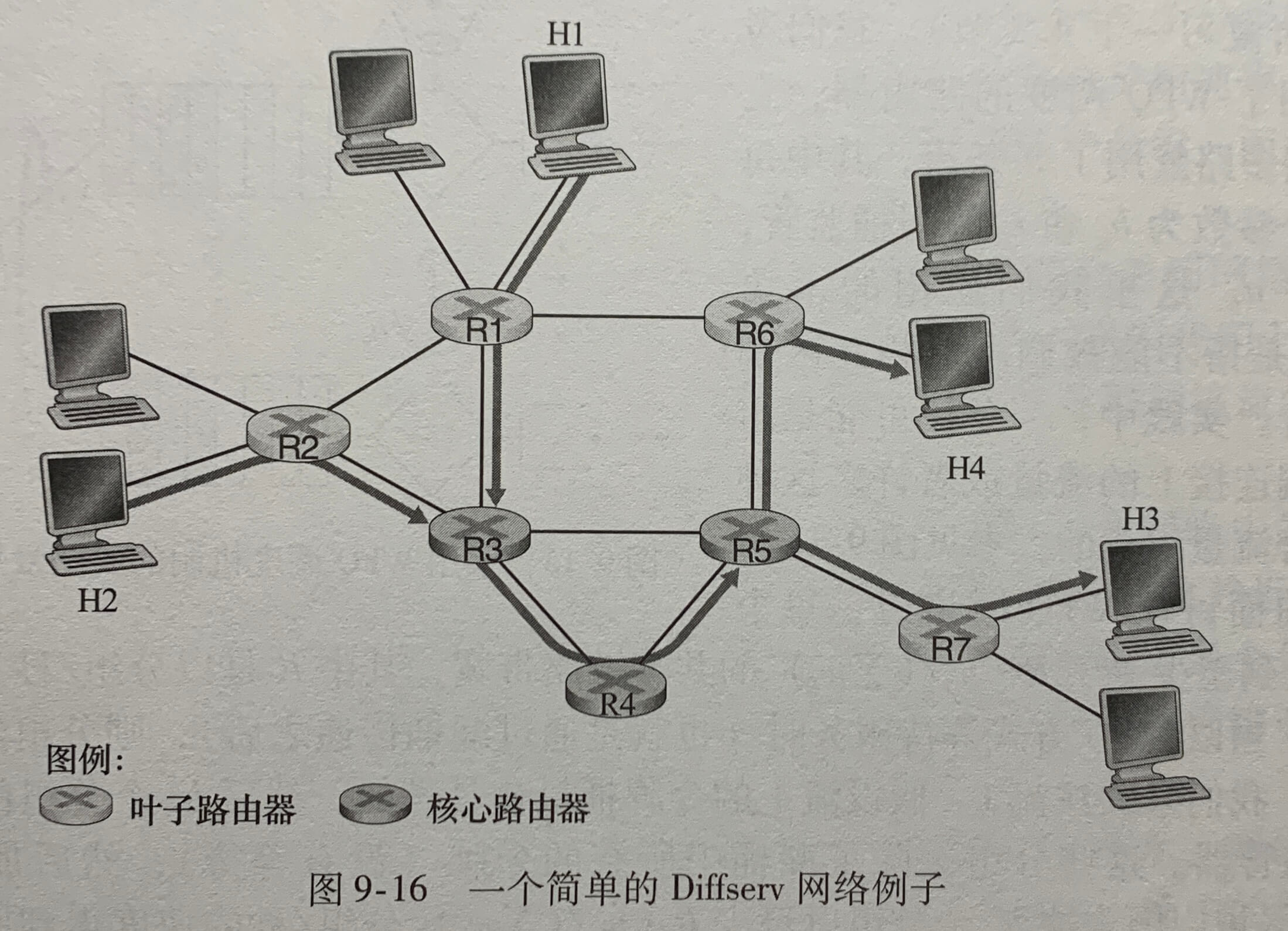

上图显示了边缘路由器中分类和标记功能的逻辑视图。到达边缘路由器的分组首先被分类。分类器根据一个或多个分组首部字段的值(例如源地址、目的地址、源端口、目的端口和协议ID)来选择分组,并引导该分组去做合适的标记功能。
9.5.4 每连接服务质量保证:资源预约和呼叫准入

电话网是一个执行呼叫阻塞的网络例子,即如果要求的资源(在电话网的情况下是一个端到端的电路)不能分配给该呼叫,该呼叫就被阻塞了,且返回给用户一个忙信号。如果一个流没有分配到足够的QoS来使自己可用,允许它进入网络没有任何好处。
让流申告它的QoS需求,然后让网络接受该流或者阻塞该流的过程称为**呼叫准入(call admission)**过程。
![[计算机网络]--MAC/ARP/DNS协议_mac地址欺骗arp欺骗攻击](https://img-blog.csdnimg.cn/direct/e63669185525402a8917335a49e5a9de.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

