
- 1基于Java开发的智慧养老管理系统详细设计和实现【附源码】_智慧养老系统详细设计说明书
- 2第一届大数据科学与工程国际会议,聚焦国际大数据技术最新进展
- 3spring eureka 服务实例实现快速下线快速感知快速刷新配置解析_eruka优雅下线
- 4EF数据库优先模式(一)
- 5Exception: ROM is missing for pong, see https://github.com/openai/atari-py#roms for instructions
- 6Hexo+Netlify快速搭建个人博客_netflix布置hexo
- 7调整Android手机的默认亮度_android源码文件中默认亮度在哪个xml文件中
- 8前端网页设计颜色使用原则_前端页面颜色
- 9基于AT89C51单片机的自动售货机系统设计(附仿真+C程序+原理图+论文等)_自动售货机代码原理
- 10kafka vs rabbitmq vs rocketmq对比_kafka vs rabbitmq vs rocketmq.pdf
AI测试 基于 AI 大模型的精准测试分享_基于ai大模型的精准测试
赞
踩


来源|TesterHome社区
作者(ID)|AMEAME
如何基于AI大模型进行精准测试,本文由 AMEAME 同学在TesterHome社区网站的分享。
一、问题提出
1.如何使用大模型解决日常工作中难以解决的问题?
2.大模型在自动化测试领域可以发挥什么作用?
3.如何利用大模型提前发现故障,并提升产品质量?
4.如何发现日常工作中难以察觉的故障?
团队现状:
A. 经常性的泄露一些修改 java 依赖引发的故障,在 maven 的 pom.xml 文件中修改一个依赖的版本号都可能引出故障
此类型的问题难以发现的原因:
-
方案层面:评估此类版本依赖修改成本较高,因为一项依赖的修改可能牵扯很多代码;
-
开发层面:因修改 pom.xml 文件依赖版本号操作小,无代码逻辑修改,开发自测场景不完整;
-
测试层面:QA 不了解具体代码和波及影响,很难确定测试范围,不知道哪些功能需要使用这些依赖;
-
自动化层面:通过自动化扫描异常日志,日志中存在大量干扰,导致自动化异常扫描精度不高;
-
成本高:即使评估出测试功能点,方案评估,开发实现,测试验证整个流程成本较高。
B. 没办法对所有的新增代码进行 CodeReview,Review 的效果一般,容易泄露在功能测试阶段无法发现的问题。
因此,针对上述原因,将大模型与当前自动化测试相结合,通过大模型自动化来防护此类问题就是本实践的目标。
二、解决思路
虽然该类问题难以发现,但也并不是毫无办法。
该类问题有个共同点:在 JVM 运行时,找不到某个依赖,会抛出:ClassNotFoundException,NoClassDefFoundError,IllegalAccessException,InstantiationException,NoSuchMethodError 等异常。
那我们收集到组件日志后是否就能规避这种问题呢?
答案肯定是不行的。举个例子:
例如团队内组件热部署探针运行在框架中,在热部署探针启停阶段,因探针在框架中提交的线程还在轮询,探针实例已经被销毁后,依旧会出现很多上面的异常来干扰判断,无法得出精确的结果,所以需要从提升精度的方向去优化。
以下是思考方向:
1.故障多出现于代码修改前后。
2.不同分支代码的差别可能导致新故障的出现。
如何去解决呢,想了以下几点:
1.如果能获取到 git 上面的代码提交记录,就能收集到热点代码。
2.能拿到不同分支代码的变化,就能收集到另一部分的热点代码。
然后还有最重要的一点,收集的异常信息和热点代码的映射如何建立呢?如果手动去建立 异常->依赖 的映射始终会滞后,出一次问题加一次不利于可持续发展,而且只有当在出问题时才能知道抛出的异常长什么样,难以完成该项目。
所以引入了大模型去帮我完成 异常->依赖 的建立。
三、实践过程
架构概述
实践过程采用了以下架构:
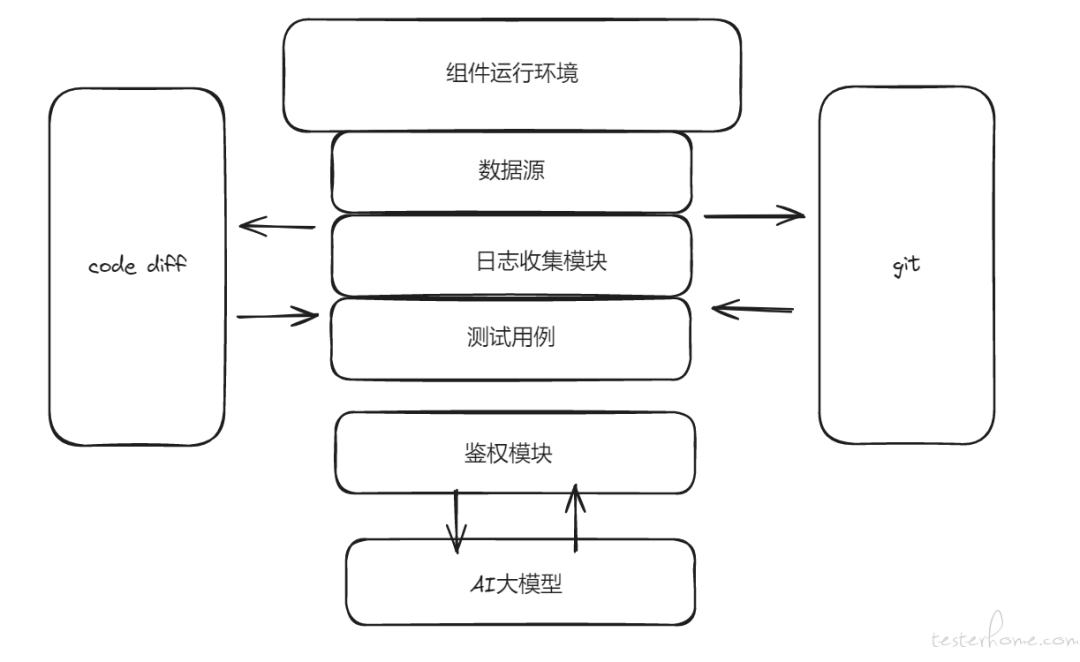
1.数据源层:项目组件运行在大环境下,利用大环境提供的基本数据源。
2.代码变更获取层:从 Git 仓库中获取代码变更信息,包括同分支增量对比和不同分支全量对比。
3.日志处理层:通过日志收集模块处理组件日志,提取异常信息。
4.AI 大模型交互层:向 AI 大模型提出针对性问题,并解析其回答。
5.结果处理与输出层:根据 AI 大模型的回答在缓存中寻找热点代码,记录日志,并发送邮件通知对应处理人。
针对pom.xml的实践步骤
1.获取大环境数据源:项目组件运行在大环境下,利用大环境提供的数据源进行后续操作。
2.获取代码变更:
-
从 Git 中获取 XX 项目 XX 分支的 XX 个提交记录。
-
遍历每个提交记录,获取修改的文件列表。
-
过滤出 maven 依赖类型的文件(如 pom.xml)。
3.解析修改文件:
-
对修改的文件进行分类处理,包括只增、只减、修改三种类型。
-
解析出代码修改内容,并将其缓存起来,作为热点代码。
4.日志处理:
-
通过日志收集模块下载组件实例的日志文件(包括.log 和.gz 格式)。
-
解压 gz 格式的日志文件,并将不同实例的日志进行汇总。
-
将日志按照级别(info, warn, error)进行分类。
-
提取 warn 和 error 级别日志中的异常堆栈信息。
-
对堆栈信息进行去重处理,减少后续处理的冗余数据。
5.与 AI 大模型交互:
-
根据提取的异常信息,向 AI 大模型提出针对性问题。
-
解析 AI 大模型的回答,获取可能的故障原因或解决建议
6.热点代码匹配与记录:
-
使用 AI 大模型的回答在缓存的热点代码中寻找相关匹配项。
-
如果找到匹配项,记录相关日志信息,包括匹配的热点代码和异常信息。
7.发送邮件通知:
-
将记录的日志信息整理成邮件格式。
-
发送邮件到对应处理人的邮箱,通知其关注并解决相关问题。
针对java文件的实践步骤
1.获取大环境数据源:同样利用大环境提供的数据源。
2.获取指定需求编号的代码变更:
-
从 Git 中获取指定需求编号的提交记录。
-
遍历每个提交记录,获取修改的文件列表。
-
过滤出.java 文件。
3.解析修改文件:
-
对修改的.java 文件进行类似 pom.xml 的解析操作。
-
分类处理只增、只减、修改的代码,并缓存热点代码。
4.与AI大模型交互:
-
根据需求背景和修改内容,向 AI 大模型提出针对性问题。
-
解析 AI 大模型的回答,获取可能的代码风险或优化建议。
5.结果输出:
将AI大模型的回答或解析结果输出到文件中,便于后续查看和分析。
通过上述实践过程,可以有效结合 AI 大模型与自动化测试技术,提升故障发现和产品质量的能力。同时,减少了人工审查和测试的工作量,提高了工作效率和准确性。
效果评价
针对pom.xml如下:
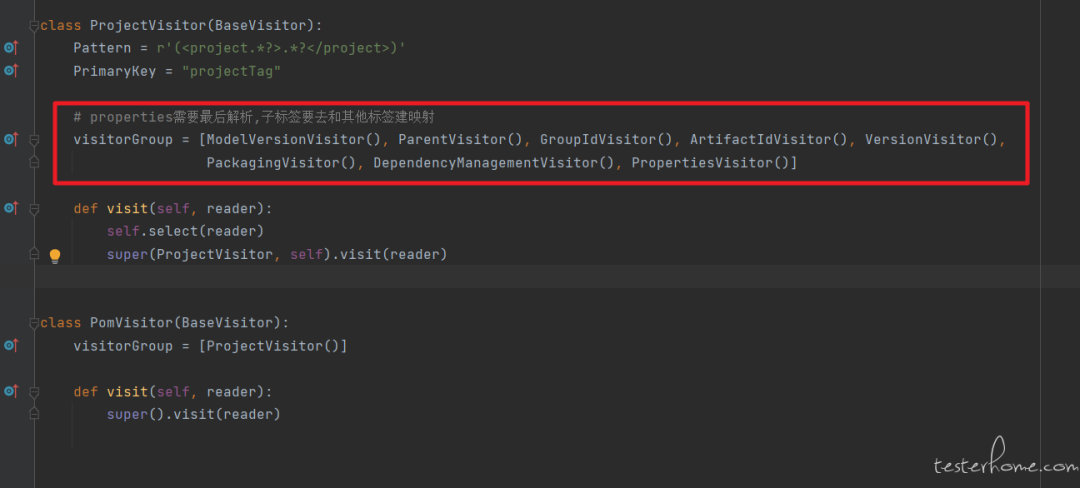
1.运行自动化测试用例,测试用例会从 git 库中获取指定项目指定分支的代码提交记录,进行解析和缓存。
-
在代码配置每个标签中的子标签,如需解析其他的标签,则新增一个标签类并重写查找该标签的正则表达式
-
按照新增或删除的配置和修改的配置(修改可能只会改一个结构体的一部分,需要找到对应完整的结构体)进行解析
-
缓存解析结果
2.收集环境上日志,拿到原始日志后进行分类
-
先把容器内的日志拷贝到节点上,通过 SSH 协议把日志下载到运行环境。组件可能有多个实例,获取所有实例日志。
-
把 GZ 日志包进行解压,对日志内容进行分类(info, warn, error),按照配置文件配置的异常类型在 warn 和 error 日志中进行查找
-
可能某些异常日志会很多(几个 G 日志),不方便查看,所以下面进行去重。
3.通过一些对字符串的算法,把 java 异常堆栈进行去重,同种类型的异常只保留一个,方便人工查看和邮件推送
4.把解析好异常堆栈向大模型提问,自定义模板的大模型提问见下:
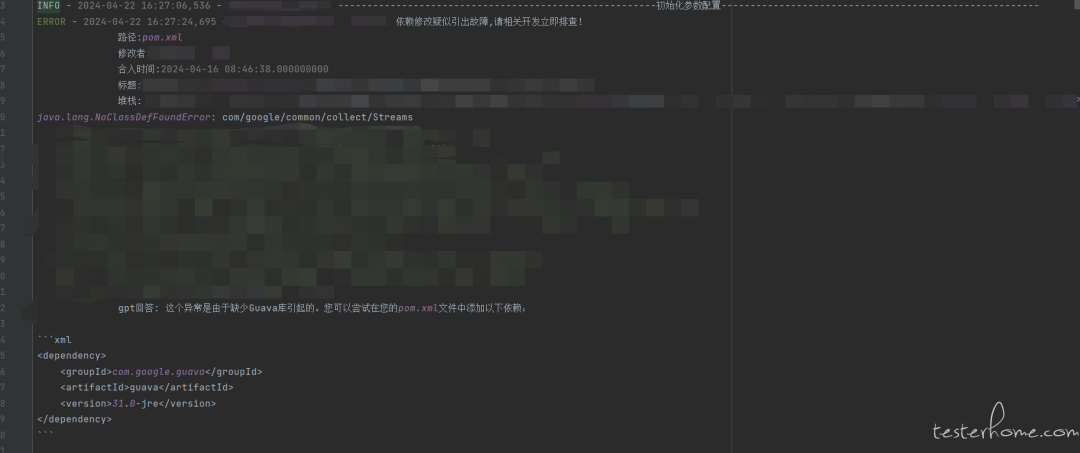
出现以下异常是缺少什么 maven 依赖: java.lang.ClassCastException: XXXXXX
大模型回答:
这个问题可能是由于你的项目缺少了 CGLIB 库引起的。你可以尝试在你的 pom.xml 文件中添加以下依赖:
<dependency> <groupId>cglib</groupId> <artifactId>cglib</artifactId> <version>3.3.0</version> </dependency>然后运行 mvn clean install 以重新构建你的项目并下载所需的依赖:
解析出答案中的依赖 groupId 和 artifactId 等关键字段,把解析出的依赖在热点代码中查找,找到了说明大概率引出故障!
针对java文件的自动化大模型CodeReview
实践过程
1. 运行自动化测试用例
测试用例会从 git 库中获取指定项目指定需求编号的代码提交记录,进行解析和缓存。
-
把每个 java 文件拿到后,把代码解析成抽象语法树(AST)。
-
依次解析各个节点,如 Class, Package, Import, Implement, Constructors, Field, Method 等。
-
对解析结果进行缓存,以便后续快速访问。
2. 并发请求 AI 大模型进行 CodeReview
获取需要使用的 Method 信息,以最大并发 20 的限制去请求 AI 大模型。以下是 prompt 模版的示例:
## 角色:代码评审专家
## 背景: 你是一位java语言专家级工程师,具备出色的代码审查能力,能够从多个方面评审代码。
## 任务: - 对指定代码进行系统化地审查。## 任务细节: 对代码能够从以下方面进行逐一审查:- 逻辑漏洞:评审代码逻辑是否有缺陷。遵守要求:排除因为没有判空而导致的空指针异常等,不评审因没有判空等而导致的漏洞,不进行入参为空的校验。- 代码结构:评审代码结构是否清晰、易于理解,变量和函数的命名是否规范。- 函数实现:评审函数实现是否正确、高效、安全,是否存在潜在的内存泄漏。- 异常处理:评审异常处理机制是否完善,是否存在可能引发异常或崩溃的代码。- 数据结构:评审代码中使用的数据结构是否合理,是否能满足实际需求。- 性能优化:评审代码中是否存在性能瓶颈,是否有不必要的计算和调用等问题,是否可以进行优化。- 资源泄露:评审代码中是否存在资源泄露,是否有文件流、线程池等未关闭情况。- 安全性:评审代码中是否存在安全漏洞,是否有防止SQL注入、XSS攻击等安全机制。- 可读性:评审代码是否清晰易于读懂,注释是否充分、准确、规范。## 任务输出: 评审代码存在的问题,并输出代码风险等级## 待评审代码[这里插入待评审的Java方法代码]3. 写入评审结果
把 AI 大模型返回的 CodeReview 结果写入文件,方便后续查看和分析。
评审结果
代码走查报告一、逻辑漏洞
在XXX方法中,XXXList values = new XXXList();被初始化为一个单例,然后在多线程环境下被多个线程共享。这可能导致线程安全问题,因为多个线程可能同时修改values的内容。根据方法内的使用情况来看,每个线程应该处理自己的XXXList实例,而不是共享一个。
countDownLatch.await();在调用时未设置超时时间,如果某个线程因为异常或其他原因未能执行countDown,那么主线程将永远等待下去,造成程序阻塞。
二、代码结构
代码结构基本清晰,但是使用了裸线程池和CountDownLatch,使得代码在并发控制上稍显复杂。建议使用更高级的并发工具,如CompletableFuture,以简化代码。
变量命名较为规范,但XXX方法作为lambda表达式中的匿名内部类调用,其参数列表过长,可以考虑封装成对象来传递。
三、函数实现
executor.submit中捕获了所有异常,但只是打印了日志,没有重新抛出或者对异常进行处理,这可能会导致调用者无法得知操作是否成功。
使用了CopyOnWriteArrayList来作为结果集合,这个数据结构适合读多写少的场景。然而,在本例中,写操作(添加元素)频繁发生,这可能会导致性能问题,因为每次写操作都会复制底层数组。如果并发写操作不多,可以考虑使用其他并发集合,如ConcurrentLinkedQueue。
四、异常处理
异常处理机制不完善,如上所述,捕获异常后只是打印了日志,并没有合适的错误处理逻辑。五、数据结构
CopyOnWriteArrayList的选择可能不是最佳的数据结构,如上所述,它可能不适合写操作频繁的场景。六、性能优化
由于使用了CopyOnWriteArrayList,且写操作频繁,可能会导致性能问题。建议考虑其他数据结构或并发控制策略。
线程池中的核心线程数设置为1,可能无法充分利用多核CPU资源,如果处理逻辑不是IO密集型的,考虑增加核心线程数。
七、资源泄露
代码中创建了线程池,但未在方法结束时关闭线程池。这可能导致资源泄露,因为线程池会一直存在,即使方法执行完毕。建议在方法结束时关闭线程池,或者使用try-with-resources语句(如果线程池实现了AutoCloseable接口)。八、安全性
代码中未看到明显的安全漏洞,如SQL注入或XSS攻击,但需要注意XXX和XXX方法内部是否有可能引入安全问题。九、可读性
代码整体可读性较好,但并发控制和异常处理部分可以进一步简化,以提高可读性。代码风险等级
综合上述评审,代码存在逻辑漏洞、资源泄露等问题,风险等级评定为中等偏高。建议对上述问题进行修复,以提高代码的健壮性和性能。这段代码线程泄露的问题当时没有测试到,从而在春节的时候泄露到外场去了 ,导致开发在春节还在排查问题。
还有一个问题是在修改后,通过大模型评审发现的,就是方法中 new 了个非线程安全的 List,并且线程池提交的多个线程都传入了这个 List,在处理逻辑中又进行了 add 的操作,所以可能会导致数据最后 add 少了或者直接抛出异常。
这些问题虽然很基础,但是如果没有进行代码走查,其实通过黑盒测试很难发现这两个问题,还是体现了该工具产生的价值!
4. 推送邮件
把评审风险为中或者高的结果推送到相关人员进行进一步的人工评审。
优势与效果
通过自动化进行大模型 CodeReview,可以显著减少人工审查的时间和成本,提高代码质量和安全性。在分钟级的时间内就能完成需求或故障修改的大模型 CodeReview,极大地提升了开发效率和代码稳定性。同时,通过并发请求AI大模型,可以充分利用计算资源,进一步提高审查速度。

