- 1趣图丨阿里p6大概啥水平?是不是不行?
- 2算法数据结构——动态规划算法(Dynamic Programming)超详细总结加应用案例讲解_动态规划 算法
- 3华为OD 2024 | 什么是华为OD,OD 薪资待遇,OD机试题清单_华为od|
- 4Pytorch to(device)_pytorch to device
- 5【AI工具】 一款多SOTA模型集成的高精度自动标注工具(直接安装使用,附源码)_ai模型 识别图片文本自动标注
- 6Python 如何实现计算函数斜率和梯度?【详细教学】_计算一条曲线各点的梯度
- 7云创大数据及其总裁刘鹏教授所编图书双双摘奖!
- 8程序员写博客如何赚钱「5大盈利方向」_技术博客赚钱 收益
- 9GoLang协程与通道---上_协程 通道
- 10Windows C++ 应用软件开发从入门到精通详解_软件入门
动手学强化学习第十三章(DDPG算法)_如何理解策略梯度(policy gradient)算法? 张斯俊
赞
踩
前言
本文理论部分主要来自知乎张斯俊的白话强化学习专栏,大佬这个专栏写的非常好对于我这种初学者提供了极大的帮助。专栏地址:
https://www.zhihu.com/column/c_1215667894253830144
代码部分主要来自动手学强化学习:https://hrl.boyuai.com/chapter/intro
DDPG,全称是deep deterministic policy gradient,深度确定性策略梯度算法。
1.DDPG算法的特点
1.是一种off policy算法与PPO等off policy算法相比有较高的样本效率。
2.它引入确定性策略(deterministic policy),对于actor输入一个状态,输出与随机性策略输出动作的概率不同,它输出的是一个确定性的动作。
3.看名称是一种策略梯度类算法,但其实是针对DQN只能应用在离散动作空间这一问题的改进,通过将状态输入给actor,actor输出使能使Q(s,a)最大的动作a。
4.DDPG算法相比与PPO算法实现起来不需要引入重要性采样等技术,实现起来简单但是不好调参。
2.算法框架
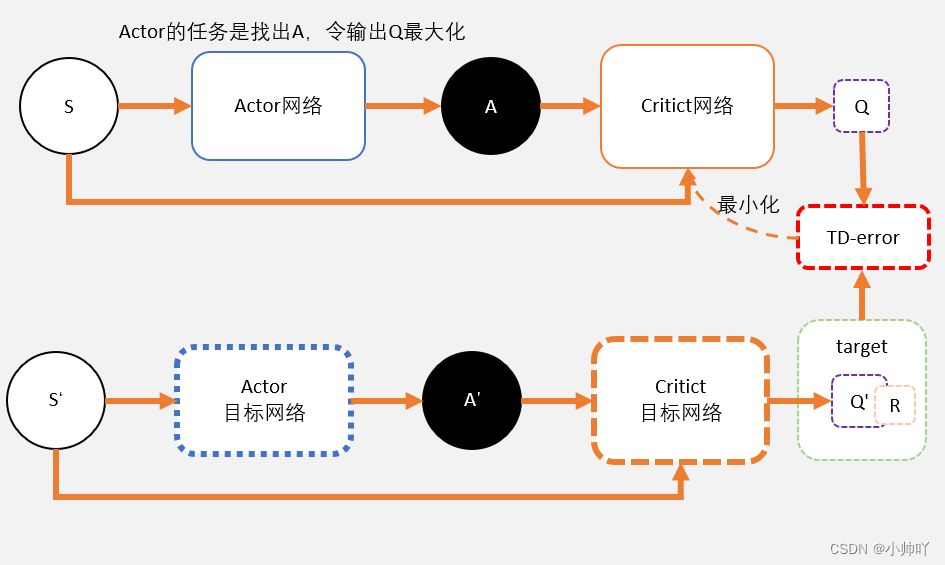
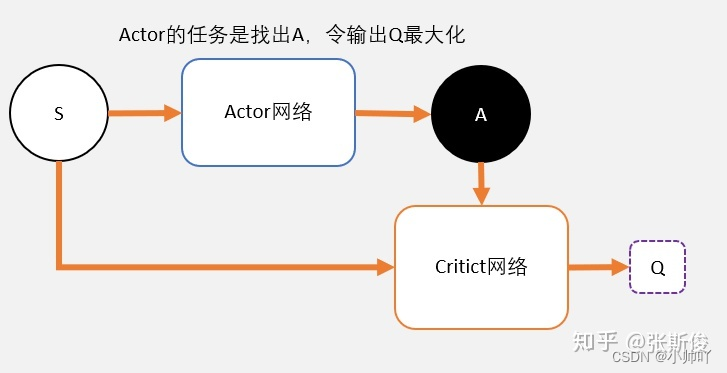
上图来自张斯俊博客
整体而言,需要定义一个actor网络,一个critic网络以及一个critic目标网络和一个critic目标网络。目标是调整actor网络的参数,使其输出能够使critic给出较高评价的动作;同时,需要通过TD-error更新critic网络的参数,使其对于状态动作对的评分更加准确。需要注意的是这里的critic是通过动作价值函数Q(s,a)而不是前面actor-critic中用状态价值函数V(s)来进行评估。
具体的训练流程:
(1)critic网络参数的更新:我们通过目标网络(critic目标网络和actor目标网络)输入St+1计算TD目标,然后通过critic网络输入St和At计算动作价值,之后两者之差即为TD-error,然后通过定义为MSE损失函数再进行梯度下降来更新critic网络参数。
(2)actor网络参数的更新:actor的目标是找到最优动作A使得Q输出最大,因此通过将状态S以及actor输出的A传入给critic得到的结果前面加负号,之后对其进行梯度下降进而实现actor参数的更新。
另外需要注意的是DDPG对于参数的更新使用的是一种软更新的方式。
3.伪代码以及代码实现
伪代码


代码实现:
来自动手学强化学习:https://hrl.boyuai.com/chapter/intro
使用pycharm打开的请查看:https://github.com/zxs-000202/dsx-rl
import random
import gym
import numpy as np
from tqdm import tqdm
import torch
from torch import nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
self.action_bound = action_bound # action_bound是环境可以接受的动作最大值
def forward(self, x):
x = F.relu(self.fc1(x))
return torch.tanh(self.fc2(x)) * self.action_bound
class QValueNet(torch.nn.Module): # Q(s,a)
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x, a):
cat = torch.cat([x, a], dim=1) # 拼接状态和动作
x = F.relu(self.fc1(cat))
return self.fc2(x)
class TwoLayerFC(torch.nn.Module):
# 这是一个简单的两层神经网络
def __init__(self,
num_in,
num_out,
hidden_dim,
activation=F.relu,
out_fn=lambda x: x):
super().__init__()
self.fc1 = nn.Linear(num_in, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, num_out)
self.activation = activation
self.out_fn = out_fn
def forward(self, x):
x = self.activation(self.fc1(x))
x = self.activation(self.fc2(x))
x = self.out_fn(self.fc3(x))
return x
class DDPG:
''' DDPG算法 '''
def __init__(self, num_in_actor, num_out_actor, num_in_critic, hidden_dim,
discrete, action_bound, sigma, actor_lr, critic_lr, tau,
gamma, device):
# self.actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
# self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
# self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
# self.target_critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
out_fn = (lambda x: x) if discrete else (
lambda x: torch.tanh(x) * action_bound)
self.actor = TwoLayerFC(num_in_actor,
num_out_actor,
hidden_dim,
activation=F.relu,
out_fn=out_fn).to(device)
self.target_actor = TwoLayerFC(num_in_actor,
num_out_actor,
hidden_dim,
activation=F.relu,
out_fn=out_fn).to(device)
self.critic = TwoLayerFC(num_in_critic, 1, hidden_dim).to(device)
self.target_critic = TwoLayerFC(num_in_critic, 1,
hidden_dim).to(device)
# 初始化目标价值网络并设置和价值网络相同的参数
self.target_critic.load_state_dict(self.critic.state_dict())
# 初始化目标策略网络并设置和策略相同的参数
self.target_actor.load_state_dict(self.actor.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),
lr=critic_lr)
self.gamma = gamma
self.sigma = sigma # 高斯噪声的标准差,均值直接设为0
self.action_bound = action_bound # action_bound是环境可以接受的动作最大值
self.tau = tau # 目标网络软更新参数
self.action_dim = num_out_actor
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state).item()
# 给动作添加噪声,增加探索
action = action + self.sigma * np.random.randn(self.action_dim)
return action
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(),
net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) +
param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'],
dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
next_q_values = self.target_critic(
torch.cat(
[next_states, self.target_actor(next_states)], dim=1))
q_targets = rewards + self.gamma * next_q_values * (1 - dones)
critic_loss = torch.mean(
F.mse_loss(
# MSE损失函数
self.critic(torch.cat([states, actions], dim=1)),
q_targets))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
actor_loss = -torch.mean(
self.critic(
# 策略网络就是为了使得Q值最大化
torch.cat([states, self.actor(states)], dim=1)))
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.soft_update(self.actor, self.target_actor) # 软更新策略网络
self.soft_update(self.critic, self.target_critic) # 软更新价值网络
actor_lr = 5e-4
critic_lr = 5e-3
num_episodes = 200
hidden_dim = 64
gamma = 0.98
tau = 0.005 # 软更新参数
buffer_size = 10000
minimal_size = 1000
batch_size = 64
sigma = 0.01 # 高斯噪声标准差
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = 'Pendulum-v0'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high[0] # 动作最大值
agent = DDPG(state_dim, action_dim, state_dim + action_dim, hidden_dim, False,
action_bound, sigma, actor_lr, critic_lr, tau, gamma, device)
return_list = rl_utils.train_off_policy_agent(env, agent, num_episodes,
replay_buffer, minimal_size,
batch_size)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
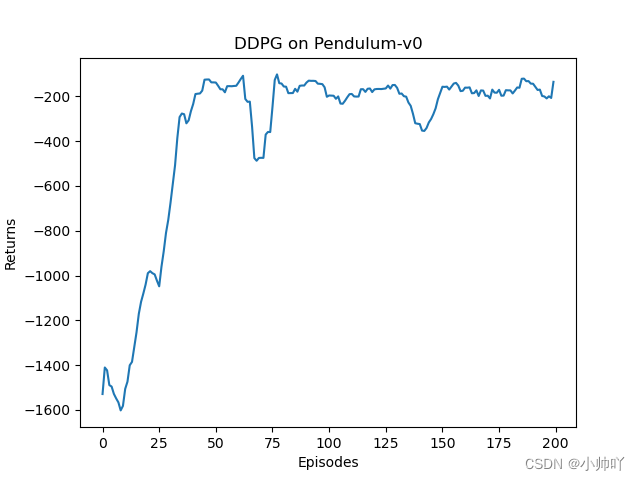
plt.title('DDPG on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DDPG on {}'.format(env_name))
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187