
热门标签
热门文章
- 1Docker笔记:docker compose部署项目, 常用命令与负载均衡_docker-compose exec
- 2Codeforces Round #689 (Div. 2) C. Random Events(1500)
- 3软件测试八年测试开发经验面试28K公司后,吐血整理出高频面试题和答案!_软件测试八年面试
- 4浅谈(int)a、&a、(int)&a、(int&)a区别_c++中(int)a有什么用吗
- 5专业磁力种子下载工具 qBittorrent 安装架设教程linux开启24小时挂机下载_qbittorrent 下载元数据
- 6010_SpringBoot视图层技术thymeleaf-变量输出与字符串操作_thymeleaf截取字符串
- 7学习笔记之——3D Gaussian Splatting源码解读_3dgs运行代码
- 8实战 | OpenCV中更稳更快的找圆方法--EdgeDrawing使用演示(详细步骤 + 代码)_opencv edgedrawing
- 9什么是CrossOver软件 ?CrossOver 23支持多种Windows应用安装
- 10Docker是什么?有什么用?_docker是干什么的
当前位置: article > 正文
【AIGC】Llama2-7B-Chat模型微调_llama-2-7b-chat-hf-q4f32_1
作者:2023面试高手 | 2024-02-14 20:04:45
赞
踩
llama-2-7b-chat-hf-q4f32_1
环境
微调框架:LLaMA-Efficient-Tuning
训练机器:4*RTX3090TI (24G显存)
python环境:python3.8, 安装requirements.txt依赖包
一、Lora微调
1、准备数据集
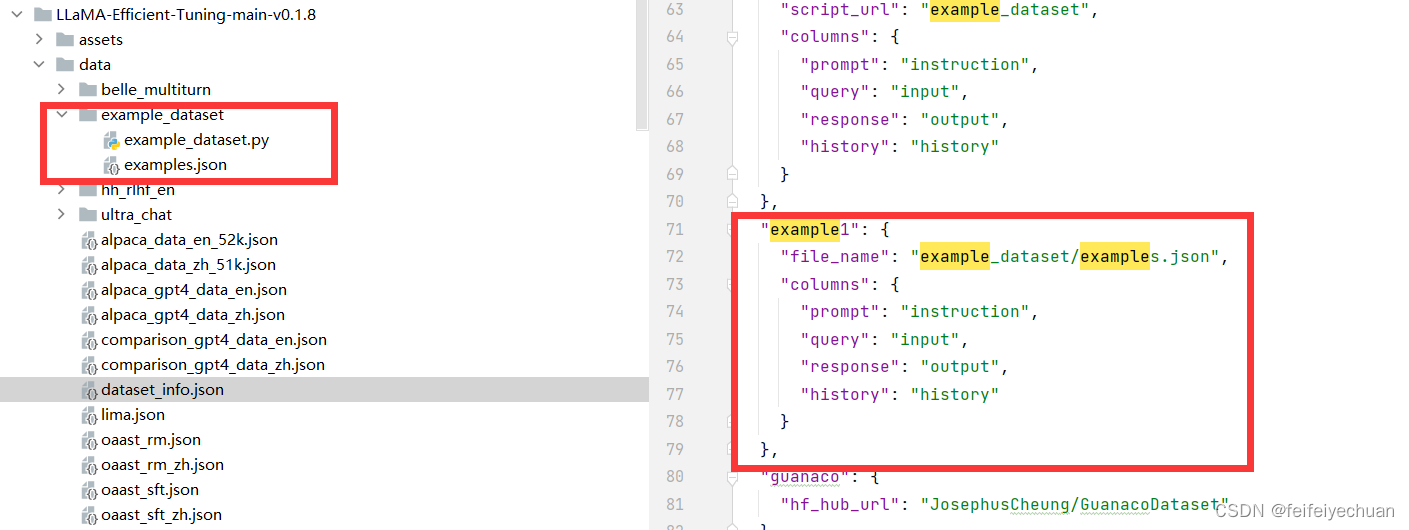
2、训练及测试
1)创建模型输出目录
mkdir -p models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model
- 1
2)创建deepspeed配置文件目录
mkdir -p models/baichuan2_13b_chat/deepspeed_config
- 1
3)创建deepspeed配置文件
vi models/llama2_7b_chat/llama-main/deepspeed_config/llama2_7b_chat_muti_gpus_01_epoch10.json
- 1
{ "bf16": { "enabled": true }, "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "scheduler": { "type": "WarmupDecayLR", "params": { "last_batch_iteration": -1, "total_num_steps": "auto", "warmup_min_lr": "auto", "warmup_max_lr": "auto", "warmup_num_steps": "auto" } }, "zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 2e9, "stage3_max_reuse_distance": 2e9, "stage3_gather_16bit_weights_on_model_save": true }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
4)训练模型
deepspeed --num_gpus 2 --master_port=9902 src/train_bash1.py \ --stage sft \ --model_name_or_path models/llama2_7b_chat/origin_model/Llama-2-7b-chat-hf \ --do_train \ --dataset example1 \ --template llama2 \ --finetuning_type lora \ --lora_target q_proj,v_proj \ --output_dir models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model \ --overwrite_cache \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 2 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_steps 500 \ --learning_rate 5e-5 \ --num_train_epochs 100.0 \ --plot_loss \ --bf16 \ --deepspeed models/llama2_7b_chat/llama-main/deepspeed_config/llama2_7b_chat_muti_gpus_01_epoch10.json
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

- 测试模型
python src/cli_demo.py \
--model_name_or_path models/llama2_7b_chat/origin_model \
--template baichuan2 \
--finetuning_type lora \
--checkpoint_dir models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model
- 1
- 2
- 3
- 4
- 5
6)启动服务
python src/web_demo1.py \
--model_name_or_path models/llama2_7b_chat/origin_model/Llama-2-7b-chat-hf \
--template llama2 \
--finetuning_type lora \
--checkpoint_dir models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model
- 1
- 2
- 3
- 4
- 5
3、注意事项:
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

