
AI周报丨微软打造Florence模型打破分类、检索等多项SOTA;微软打造Florence模型打破分类、检索等多项SOTA_florence-2 微软 达模型
赞
踩
- 热门论文 -
题目:ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
尽管多任务学习和自然语言处理迁移学习(NLP)最近取得了成功,但很少有研究系统地研究在训练前增加任务数量的效果。为了实现这一目标,本文介绍了ExMix即ExtremeMixe:一个跨越不同领域和任务族的107个受监督NLP任务的大规模集合。使用ExMix,我们研究了迄今为止规模最大的多任务预训练的效果,并分析了常见任务族之间的共同训练迁移。通过这一分析,我们表明,为多任务预训练手动策划一组理想的任务并不简单,而且多任务缩放本身可以极大地改进模型。最后,我们提出了ExT5:一个使用自监督范围去噪和监督ExMix的多任务目标预训练的模型。通过大量的实验,我们发现ExT5在SuperGLUE、GEM、Rainbow、闭卷QA任务以及ExMix之外的一些任务上优于强大的T5基线。ExT5还显著提高了预训练时的样本效率。
论文地址:
https://arxiv.org/pdf/2111.10952v1.pdf
- 热门工具 -
1. NLTK
NLTK(Natural Language Toolkit),自然语言处理工具包,在NLP(自然语言处理)领域中,最常使用的一个Python库。自带语料库,词性分类库。自带分类,分词功能。
此工具包兼容极链AI云平台,相关地址:
https://github.com/hb20007/hands-on-nltk-tutorial
2. CoreNLP
Corenlp提供了一系列用Java编写的自然语言分析工具。它可以采取原始的人文语言文本输入并给出基本形式的单词,他们的言论,无论是公司,人类等的名称,均衡和解释日期,时间和数字数量,标志着句子的结构在短语或单词依赖项方面,指示哪些名词短语是指同一实体。它最初是为英语开发的,但现在还提供了不同于(现代标准)阿拉伯语,(大陆)中文,法语,德语和西班牙语的不同水平。
此工具包兼容极链AI云平台,相关地址:
https://github.com/stanfordnlp/CoreNLP
- 程序员区 -
IntelliJ IDEA 2021.3 RC发布
新版本的一些亮点更新包括有:支持远程开发 (Beta),此功能允许软件工程师连接到运行IDE后端的远程计算机,并像在本地机器上一样处理位于该端的项目。故障排除IDE问题,查看诊断和修 IDE 问题的新的、更快的方法。Kotlin 调试器更新。
PhpStorm 2021.3 RC发布
除了即将发布的版本的新功能之外,此版本还介绍了 Remote Development,通过Remote Development,用户将可以连接到运行IDE后端的远程计算机,并处理位于该后端的项目,
Apache Kafka 2.7.2 发布
主要更新内容:升级 jetty-server 以修复 CVE-2021-34429;修复了如果任务在启动期间失败,则失败任务计数 JMX 指标不会更新;恢复 GlobalKTable 时的无限循环;修复了FileStreamSourceTask 缓冲区可以无限增长的错误等。
Apache Maven 3.8.4发布
此版本更新内容如下: 修复了Maven启动脚本(init)调用 which(1),这是一个 一个外部命令;恢复MNG-6843和MNG-7251的ThreadLocal方法;将 Jansi 升级到 2.4.0等。
Django 4.0 RC1发布
Django 4.0主要变化:默认时区实现zoneinfo;支持Python 3.8、3.9和3.10;Django 3.2.x系列是支持 Python 3.6和3.7的最后版本;引入新密码哈希函数scrypt,但因为需要更多内存OpenSSL 1.1+没有默认启用等。
- 大厂动态 -
9亿训练集、通用CV任务,微软打造Florence模型打破分类、检索等多项SOTA
来自微软的研究者另辟蹊径,提出了一种新的计算机视觉基础模型 Florence。在广泛的视觉和视觉 - 语言基准测试中,Florence 显著优于之前的大规模预训练方法,实现了新的 SOTA 结果。
面对多样化和开放的现实世界,要实现 AI 的自动视觉理解,就要求计算机视觉模型能够很好地泛化,最小化对特定任务所需的定制,最终实现类似于人类视觉的人工智能。计算机视觉基础模型在多样化的大规模数据集上进行训练,可以适应各种下游任务,对于现实世界的计算机视觉应用至关重要。
现有的视觉基础模型,如 CLIP (Radford et al., 2021)、ALIGN (Jia et al., 2021) 和悟道 2.0 等 ,主要侧重于将图像和文本表征映射为跨模态共享表征。近日来自微软的研究另辟蹊径提出了一种新的计算机视觉基础模型 Florence,将表征从粗粒度(场景)扩展到细粒度(对象),从静态(图像)扩展到动态(视频),从 RGB 扩展到多模态。
通过结合来自 Web 规模图像 - 文本数据的通用视觉语言表征, Florence 模型可以轻松地适应各种计算机视觉任务,包括分类、检索、目标检测、视觉问答(VQA)、图像描述、视频检索和动作识别。此外,Florence 在许多迁移学习中也表现出卓越的性能,例如全采样(fully sampled)微调、线性探测(linear probing)、小样本迁移和零样本迁移,这些对于视觉基础模型用于通用视觉任务至关重要。Florence 在 44 个表征基准测试中多数都取得了新的 SOTA 结果,例如 ImageNet-1K 零样本分类任务,top-1 准确率为 83.74,top-5 准确率为 97.18;COCO 微调任务获得 62.4 mAP,VQA 任务获得 80.36 mAP。

论文地址:https://arxiv.org/pdf/2111.11432v1.pdfFlorence
模型在有噪声的 Web 规模数据上以同一个目标进行端到端训练,使模型能够在广泛的基准测试中实现同类最佳性能。在广泛的视觉和视觉 - 语言基准测试中,Florence 显著优于之前的大规模预训练方法,实现了新的 SOTA 结果。
方法
构建 Florence 生态系统包括数据管护、模型预训练、任务适配和训练基础设施,如图 2 所示。
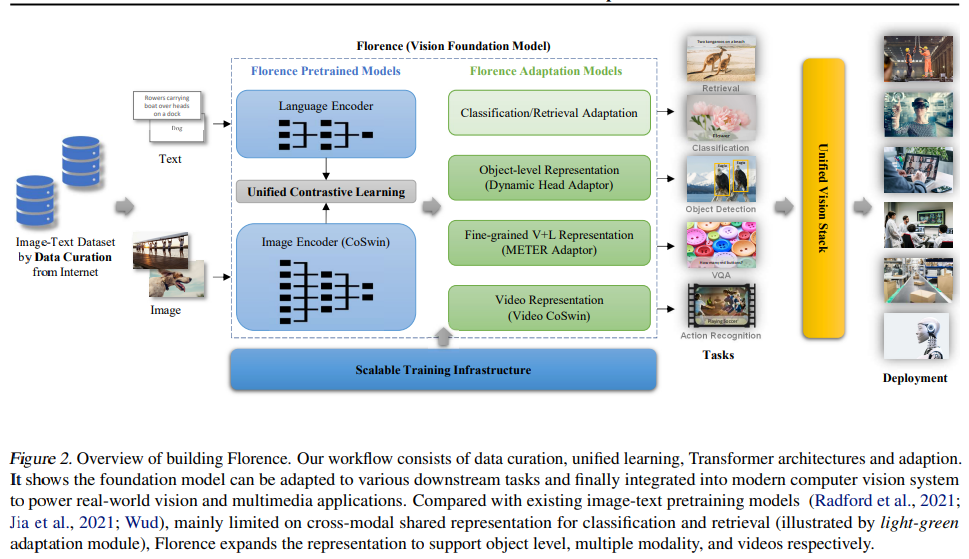
数据管护
由于大规模数据多样化对基础模型非常重要,因此该研究提出了一个包含 9 亿个图像 - 文本对的新数据集用于训练。由于网络爬取数据通常是具有噪音的自由格式文本(例如,单词、短语或句子),为了获得更有效的学习,该研究使用了 UniCL,这是 Yang 等人最近提出的「统一图像文本对比学习对象」,这种方法已经被证明其比对比和监督学习方法更优越。
模型预训练
为了从图像 - 文本对中学习良好的表示,该研究使用了包括图像编码器和语言编码器的两塔式(two-tower)架构。对于图像编码器,该研究选择了分层 Vision Transformer 。该研究所提架构在继承了 Transformer self-attention 操作性能优势的同时,这些分层架构对图像的尺度不变性进行了建模,并且具有相对于图像大小的线性计算复杂度,这是进行密集预测任务必不可少的属性。
任务适配
该研究使用 dynamic head adapter(Dai et al., 2021a)、提出的 video CoSwin adapter 从静态图到视频的时间、METER adapter 从图像到语言的模态变化,通过以上该研究将学习到的特征表示沿空间(从场景到对象)进行扩展。Florence 旨在通过小样本和零样本迁移学习来有效适配开放世界,并通过很少的 epoch 训练(例如在检索中)进行有效部署。用户可以根据自己的需求进行定制。
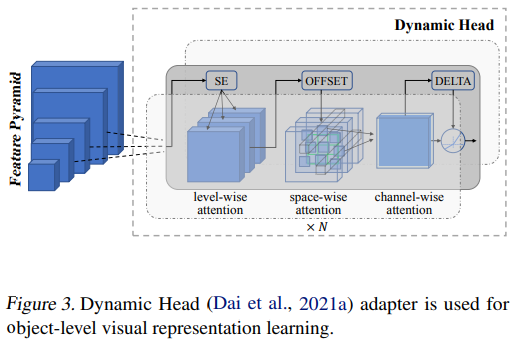
Dynamic Head (Dai et al., 2021a) adapter 用于对象级视觉表示学习。
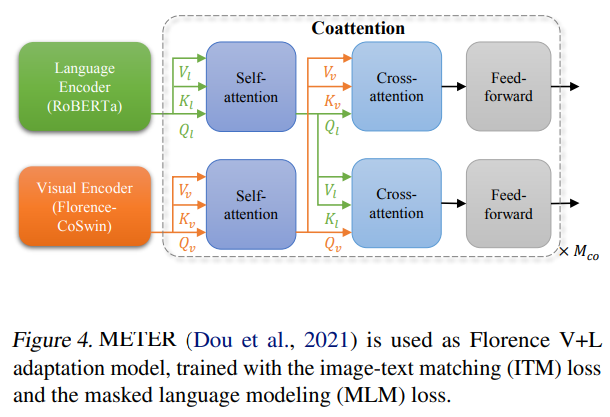
图 4. METER (Dou et al., 2021) 用作 Florence V+L 适配模型,使用图像文本匹配 (ITM) 损失和掩码语言建模 (MLM) 损失进行训练。
训练基础设施
从能源和成本方面考虑,以尽可能低的成本构建基础模型是至关重要的。该研究开发了可扩展的训练基础设施,以提高训练效率。Florence 训练基础设施由 ZeRO 、激活检查点、混合精度训练、梯度缓存等多项关键技术组成,从而大大减少了内存消耗,提高了训练吞吐量。
实验结果
该研究进行了多项实验,表明了 Florence 显著优于之前的大规模预训练方法。
分类中的零样本迁移
该研究在 ImageNet-1K 数据集和 11 个下游数据集上评估了 Florence 模型。表 1 显示了这 12 个数据集的结果,比较的模型包括 CLIP ResNet 、CLIP Vision Transformer 模型以及 FILIP-ViT,结果显示 Florence 在其中 9 个数据集上表现出色。该研究在 ImageNet-1K 上的零样本迁移方面取得了显着的提高,即 top-1 准确率为 83.74%(比 SOTA 结果高 5.6%),top-5 准确率为 97.18%。

线性评估
线性评估考虑了 11 个分类基准,这些基准同样也适用于零样本分类迁移。该研究将 Florence 与具有 SOTA 性能的模型进行了比较,包括 SimCLRv2、ViT、Noisy Student 和 CLIP 。
结果表明,Florence 优于现有的 SOTA 结果,不过在 CIFAR10、CIFAR100 这两个数据集上性能不如 EfficientNet-L2 。

ImageNet-1K 微调评估
该研究在 ImageNet ILSVRC-2012 基准(Deng et al., 2009)上评估了持续微调的性能,Florence 与几种模型的比较结果如下表 3 所示。Florence 模型的 Top-1 和 Top-5 准确率均优于 BiT(Kolesnikov et al., 2020)和 ALIGN(Jia 等人,2021 年)。Florence 的结果比 SOTA 模型(Dai et al., 2021c)稍差,但其模型和数据规模都比 Florence 大了 3 倍。

声临其境:清华大学和字节跳动提出Neural Dubber神经网络配音器,有望让影视后期效率倍增
影视配音是一项技术含量很高的专业技能。专业配音演员的声音演绎往往让人印象深刻。现在,AI 也有望自动实现这种能力。
近期,清华大学和字节跳动智能创作语音团队业内首次提出了神经网络配音器(Neural Dubber)。这项研究能让 AI 根据配音脚本,自动生成与画面节奏同步的高质量配音。相关论文 Neural Dubber: Dubbing for Videos According to Scripts 已入选机器学习和计算神经科学领域顶级学术会议 NeurIPS 2021。

论文地址:https://arxiv.org/abs/2110.08243
项目主页:https://tsinghua-mars-lab.github.io/NeuralDubber/
配音(Dubbing)广泛用于电影和视频的后期制作,具体指的是在安静的环境(即录音室)中重新录制演员对话的后期制作过程。配音常见于两大应用场景:第一个是替换拍摄时录制的对话,如拍摄场景下录制的语音音质不佳,又或者出于某种原因演员只是对了口型,声音需要事后配上;第二个是对译制片配音,例如,为了便于中国观众欣赏,将其他语言的视频翻译并配音为中文。
清华大学和字节跳动智能创作语音团队的这项研究主要关注第一个应用场景,即 “自动对话替换(ADR)”。在这一场景下,专业的配音演员观看预先录制的视频中的表演,并用适当的韵律(例如重音、语调和节奏)重新录制每一句台词,使他们的讲话与预先录制的视频同步。
为了实现上述目标,该团队定义了一个新的任务,自动视频配音(Automatic Video Dubbing, AVD), 从给定文本和给定视频中合成与该视频时序上同步的语音。
此前,行业内的很多研究是,根据给定语音生成与之同步的说话人的面部视频(Talking Face Generation)。而 AVD 任务正好相反,是用于生成与视频同步的语音,更加适用于真实的应用场景,因为影视作品拍摄的视频往往质量很高,并不希望再对其进行修改。
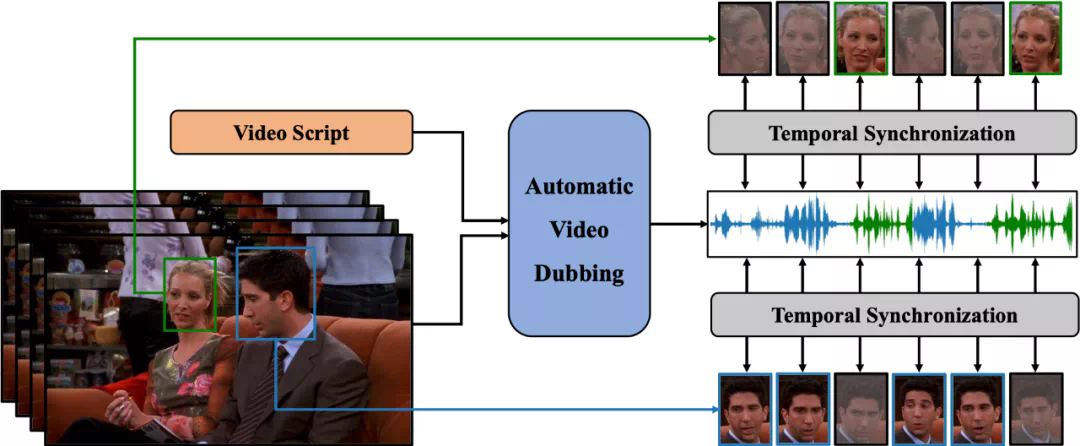
图 1:自动视频配音(AVD)任务示意图。
清华大学和字节跳动智能创作语音团队提出的神经网络配音器(Neural Dubber)旨在解决自动视频配音(AVD)任务。这是第一个解决 AVD 任务的神经网络模型:能够从文本中端到端地并行合成与给定视频同步的高质量语音。神经网络配音器是一种多模态文本到语音 (TTS) 模型,它利用视频中的嘴部运动来控制生成语音的韵律,以达到语音和视频同步的目的。此外,该工作还针对多说话人场景开发了基于图像的说话人嵌入 (ISE) 模块,该模块使神经网络配音器能够根据说话人的面部生成具有合理音色的语音。
具体的技术方法如下:
神经网络配音器(Neural Dubber)将 AVD 任务具体建模成如下形式:给定音素序列和视频帧序列,模型需要预测与视频同步的梅尔频谱序列。

图 2:神经网络配音器(Neural Dubber)的模型结构。
神经网络配音器(Neural Dubber)的整体模型结构如图 2 所示。首先,神经网络配音器应用音素编码器和视频编码器分别处理音素序列和视频帧序列。编码后,音素序列变成音素隐表示序列,视频帧序列变成视频隐表示序列。然后,音素隐表示序列和视频隐表示序列被输入到文本视频对齐器(Text-Video Aligner),得到经过扩展后的梅尔频谱隐表示序列,它与目标梅尔频谱序列的长度相同。该工作在文本视频对齐器中解决了音素和梅尔频谱序列长度不一致的问题。在多说话人场景时,模型会从视频帧序列中随机选择的一张人脸图像,输入到基于图像的说话人嵌入(Image-based Speaker Embedding, ISE)模块以生成基于图像的说话人嵌入。梅尔频谱隐表示序列会与 ISE 相加,并输入到可变信息适配器(Variance Adaptor)中以添加一些方差信息(例如,音高、音量(频谱能量))。最后,梅尔频谱解码器(Mel-spectrogram Decoder)将隐表示序列转换为梅尔频谱序列。
文本视频对齐器(Text-Video Aligner)
文本视频对齐器(图 2(b))可以找到文本和嘴部运动之间的对应关系,利用这种对应关系可以进一步生成与视频同步的语音。
在文本视频对齐器中,注意力模块学习音素序列和视频帧序列之间的对齐方式,并生成文本视频上下文特征序列。然后执行上采样操作以将此序列从与视频帧序列一样长扩展到与目标梅尔频谱序列一样长。
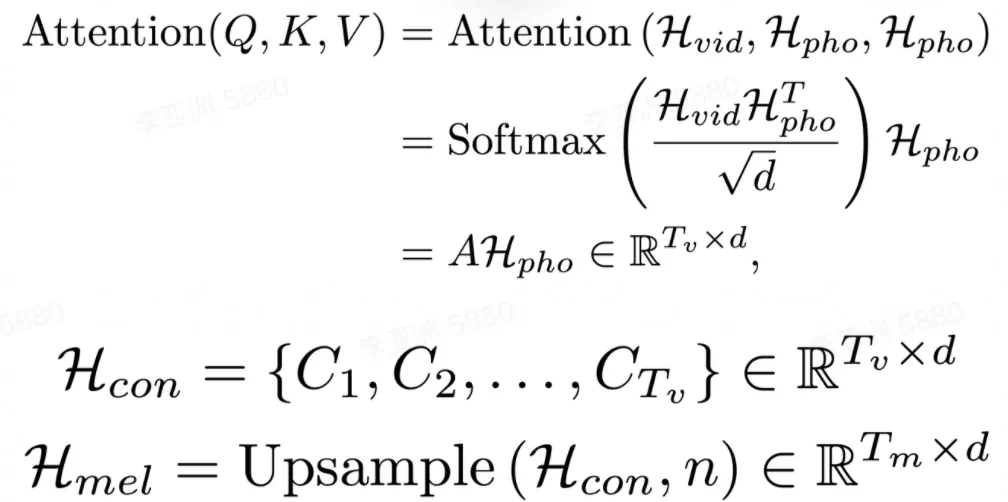
注意力模块中,视频隐表示序列用作查询。因此,注意力权重由视频显式地控制,并实现了视频帧和音素之间的时序对齐。获得的视频帧和音素之间的单调对齐有助于合成出的语音在细粒度(音素)级别上和视频同步。
之后,将文本视频上下文特征序列扩展到与目标梅尔频谱序列一样的长度。这样音素和梅尔频谱序列之间的长度不匹配问题,就在没有音素和梅尔频谱细粒度对齐监督的情况下得到解决。由于视频帧和音素之间的注意力机制,合成语音的速度和韵律由输入视频显式地控制,使得能够合成与视频同步的语音。
基于图像的说话人嵌入(Image-based Speaker Embedding)
在真实的配音场景中,配音演员需要为不同的表演者改变音色。为了更好地模拟 AVD 任务的真实情况,该研究提出了基于图像的说话人嵌入模块(图 2(c)),目标是在多说话人的场景中利用说话人的面部特征对合成语音进行不同音色的调节。就像人们可以从他人的外表(性别、年龄等)大致推断出对方说话的音色。
基于图像的说话人嵌入是一种新型的多模态说话人嵌入,能够从人脸图片生成说话人嵌入,该嵌入蕴含了图像中所能体现的说话人的声音特征。ISE 模块利用视频中人脸和语音的天然对应关系,采用自监督的方式进行训练,不需要说话人身份的监督。ISE 模块学习到人脸和声音特征的相关性,让神经网络配音器(Neural Dubber)能够产生具有合理音色的语音。合理指的是声音特征与从说话人面部推断出的各种属性(例如,性别和年龄等)相符。
实验和结果
在单说话人数据集 Chemistry Lectures 和多说话人数据集 LRS2 上的实验表明,神经网络配音器(Neural Dubber)可以生成与 SOTA 的 TTS 模型在音质方面相当的语音。最重要的是,定性和定量评估都表明,神经网络配音器可以通过视频控制合成语音的韵律,并生成与视频同步的高质量语音。

