
- 1STM32输出PWM波形及LED呼吸灯_怎么把pwm传到led灯上
- 2机器学习-线性回归【手撕】
- 3类银河恶魔城学习记录1-5 CollisionCheck源代码 P32
- 4【windows核心编程】 4 进程
- 5Linux Ubuntu环境下 Intel Realsense D435I 驱动+ROS驱动安装配置_ros中配置d435i
- 6解决import ReactJson的报错Uncaught TypeError: Object(...) is not a function_react-json-view引入时报错
- 7SSM框架的学习与应用(Spring + Spring MVC + MyBatis)-Java EE企业级应用开发学习记录(第二天)Mybatis的深入学习_ssm企业级应用开发
- 8如何用adb命令启动安装的APK_用adb运行apk
- 9二分图匹配
- 10Word处理控件Aspose.Words功能演示:在 Python 中将 Word 文档转换为 PNG、JPEG 或 BMP_python aspose
1、电商数仓(用户行为采集平台)_实时数仓lg.sh
赞
踩
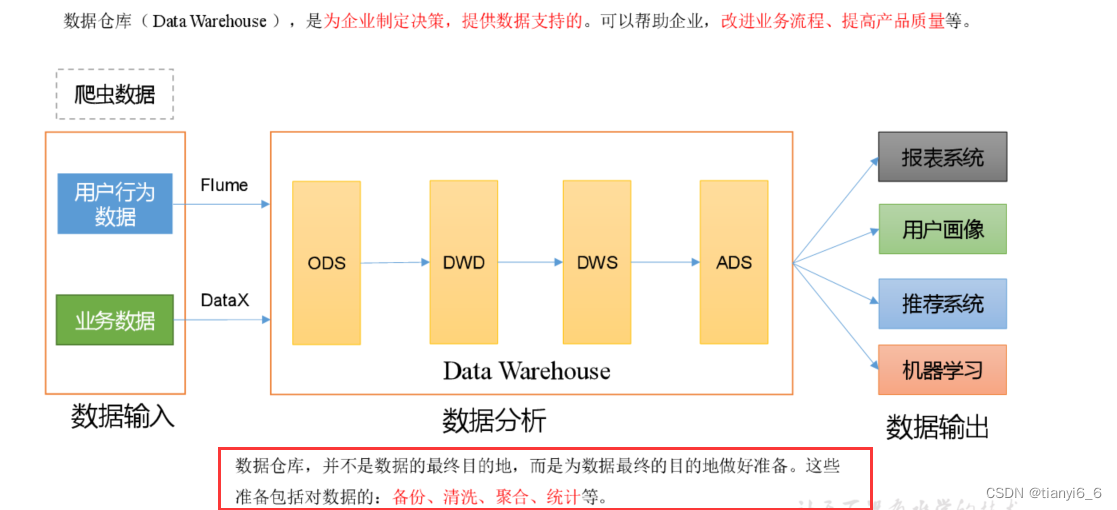
数据仓库概念
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等
业务数据
就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中
用户行为数据
用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
爬虫数据
通常是通过技术手段获取其他公司网站的数据。
项目需求及架构设计
项目需求分析
1)采集平台
(1)用户行为数据采集平台搭建
(2)业务数据采集平台搭建
2)离线需求
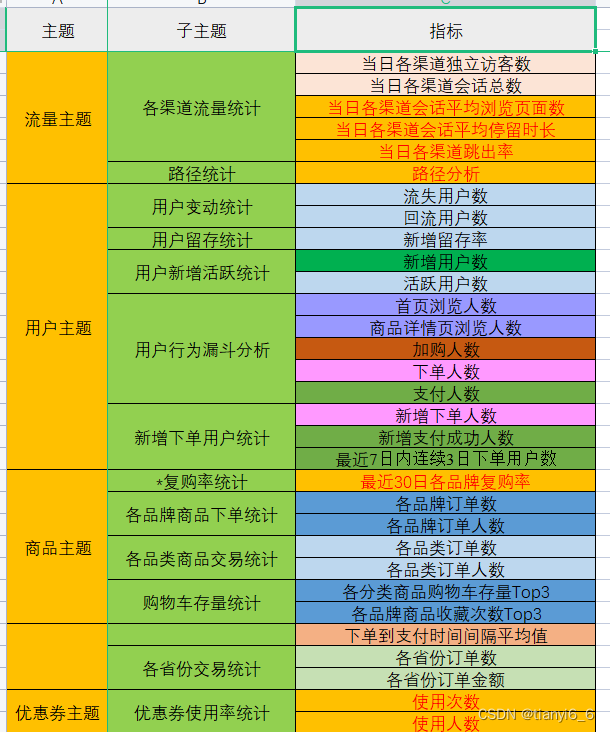
3)实时需求

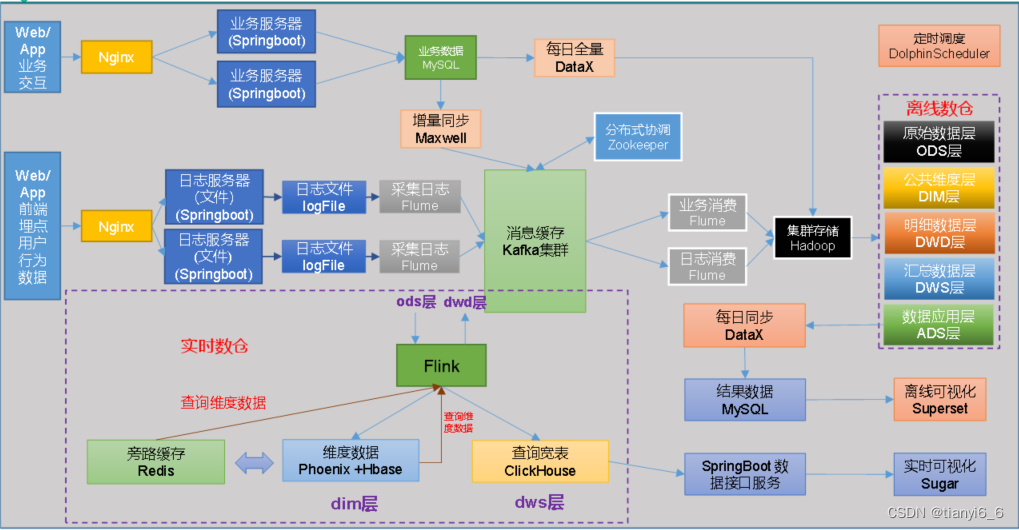
项目框架
技术选型

系统数据流程设计
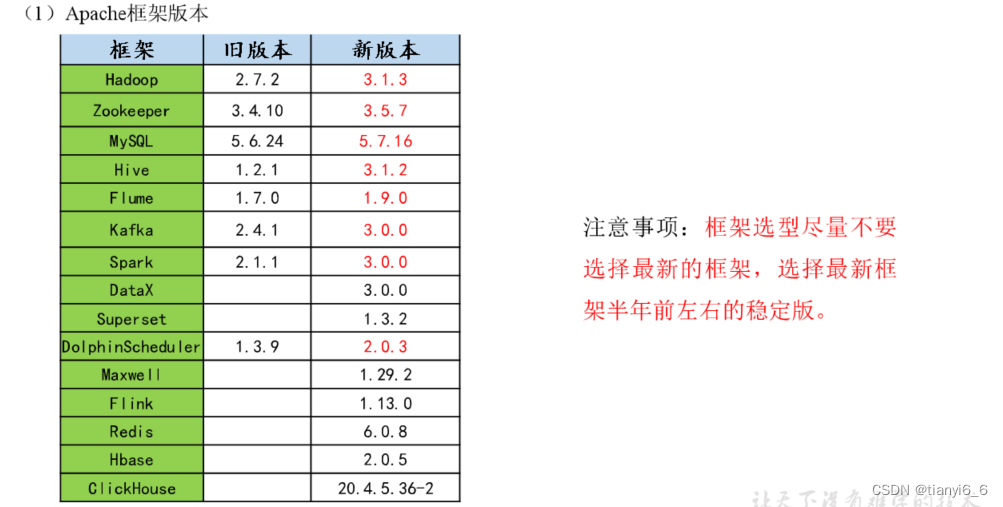
框架版本选型

集体版本型号
服务器选型

集群规模

集群资源规划设计
生产集群
(1)消耗内存的分开
(2)数据传输数据比较紧密的放在一起(Kafka 、Zookeeper)
(3)客户端尽量放在一到两台服务器上,方便外部访问
(4)有依赖关系的尽量放到同一台服务器(例如:Hive和mysql)
用户行为日志
用户行为日志的内容,主要包括用户的各项
行为信息以及行为所处的环境信息。收集这些信息的主要目的是优化产品和为各项分析统计指标提供数据支撑。收集这些信息的手段通常为埋点。
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点等。
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
用户行为日志内容
本项目收集和分析的用户行为信息主要有页面浏览记录、动作记录、曝光记录、启动记录和错误记录。
页面浏览记录
页面浏览记录,记录的是访客对页面的浏览行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及页面信息等。

动作记录
动作记录,记录的是用户的业务操作行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息 及动作目标对象信息等。

曝光记录
曝光记录,记录的是曝光行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及曝光对象信息等。

启动记录
启动记录,记录的是用户启动应用的行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、启动类型及开屏广告信息等。

错误记录
启动记录,记录的是用户在使用应用过程中的报错行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、以及可能与报错相关的页面信息、动作信息、曝光信息和动作信息。
用户行为日志格式
我们的日志结构大致可分为两类,一是
页面日志,二是启动日志。
页面日志
页面日志,以页面浏览为单位,即一个页面浏览记录,生成一条页面埋点日志。
一条完整的页面日志包含,一个页面浏览记录,若干个用户在该页面所做的动作记录,若干个该页面的曝光记录,以及一个在该页面发生的报错记录。除上述行为信息,页面日志还包含了这些行为所处的各种环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
{
"common": { -- 环境信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"is_new": "1", -- 是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [{ -- 动作(事件)
"action_id": "favor_add", -- 动作id
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"ts": 1585744376605 -- 动作时间戳
}
],
"displays": [{ -- 曝光
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1, -- 出现顺序
"pos_id": 2 -- 曝光位置
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2,
"pos_id": 1
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3,
"pos_id": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4,
"pos_id": 2
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5,
"pos_id": 1
}
],
"page": { -- 页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面ID
"sourceType": "promotion" -- 来源类型
},
"err": { --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
启动日志
启动日志以启动为单位,及一次启动行为,生成一条启动日志。一条完整的启动日志包括一个启动记录,一个本次启动时的报错记录,以及启动时所处的环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"is_new": "1",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
模拟数据
使用说明
1)将application.yml、gmall2020-mock-log-2021-10-10.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
(1)创建applog路径
[atguigu@hadoop102 module]$ mkdir /opt/module/applog
(2)上传文件到/opt/module/applog目录
2)配置文件
(1)application.yml文件
可以根据需求生成对应日期的用户行为日志。
[atguigu@hadoop102 applog]$ vim application.yml
修改如下内容
# 外部配置打开
logging.config: "./logback.xml"
#业务日期 注意:并不是Linux系统生成日志的日期,而是生成数据中的时间
mock.date: "2020-06-14"
#模拟数据发送模式
#mock.type: "http"
#mock.type: "kafka"
mock.type: "log"
#http模式下,发送的地址
mock.url: "http://hdp1/applog"
#kafka模式下,发送的地址
mock:
kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"
kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 200
#设备最大值
mock.max.mid: 500000
#会员最大值
mock.max.uid: 100
#商品最大值
mock.max.sku-id: 35
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 10
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
(2)path.json,该文件用来配置访问路径
根据需求,可以灵活配置用户点击路径。
[
{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":40 },
{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5 },
{"path":["home","good_detail"],"rate":10 },
{"path":["home" ],"rate":10 }
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(3)logback配置文件
可配置日志生成路径,修改内容如下
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.atgugu.gmall2020.mock.log.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" >
<appender-ref ref="console" />
</root>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
3)生成日志
(1)进入到/opt/module/applog路径,执行以下命令
[atguigu@hadoop102 applog]$ java -jar gmall2020-mock-log-2021-10-10.jar
(2)在/opt/module/applog/log目录下查看生成日志
[atguigu@hadoop102 log]$ ll
集群日志生成脚本
在hadoop102的/home/atguigu目录下创建bin目录,这样脚本可以在服务器的任何目录执行。
[atguigu@hadoop102 ~]$ echo $PATH
(1)在/home/atguigu/bin目录下创建脚本lg.sh
[atguigu@hadoop102 bin]$ vim lg.sh
- 1
(2)在脚本中编写如下内容
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-10-10.jar >/dev/null 2>&1 &"
done
- 1
- 2
- 3
- 4
- 5
注:
①/opt/module/applog/为jar包及配置文件所在路径
②/dev/null代表Linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
(3)修改脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 lg.sh
(4)将jar包及配置文件上传至hadoop103的/opt/module/applog/路径
(5)启动脚本
[atguigu@hadoop102 module]$ lg.sh
(6)分别在hadoop102、hadoop103的/opt/module/applog/log目录上查看生成的数据
[atguigu@hadoop102 logs]$ ls
app.2020-06-14.log
[atguigu@hadoop103 logs]$ ls
app.2020-06-14.log
用户行为数据采集模块
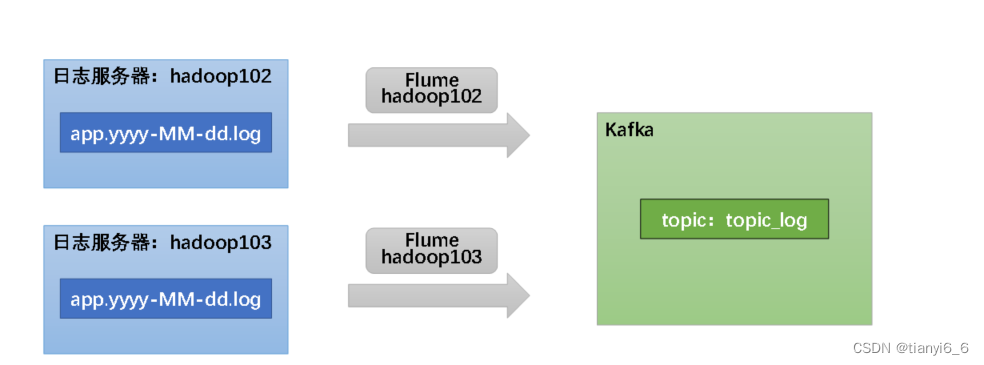
数据通道
Hadoop安装
https://blog.csdn.net/ztx22555/article/details/126339502
Zookeeper安装部署
https://blog.csdn.net/ztx22555/article/details/127296822
Kafka安装部署
https://blog.csdn.net/ztx22555/article/details/127299831
Flume安装部署
https://blog.csdn.net/ztx22555/article/details/127301513
日志采集Flume
日志采集Flume配置概述
按照规划,需要采集的用户行为日志文件分布在hadoop102,hadoop103两台日志服务器,故需要在hadoop102,hadoop103两台节点配置日志采集Flume。日志采集Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到Kafka。
此处可选择
TaildirSource和KafkaChannel,并配置日志校验拦截器。
选择TailDirSource和KafkaChannel的原因如下:
1)TailDirSource
TailDirSource相比ExecSource、SpoolingDirectorySource的优势
TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
ExecSource可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
SpoolingDirectorySource监控目录,支持断点续传。
2)KafkaChannel
采用Kafka Channel,省去了Sink,提高了效率。
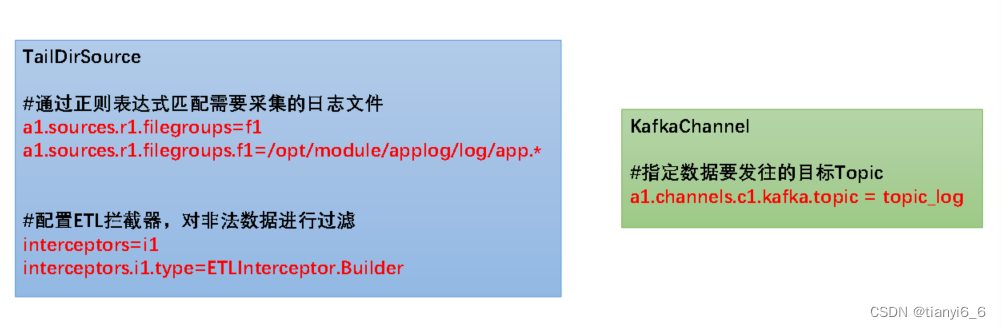
日志采集Flume关键配置如下:
日志采集Flume配置实操
1)创建Flume配置文件
在hadoop102节点的Flume的 job 目录下创建
file_to_kafka.conf
[atguigu@hadoop104 flume]$ mkdir job
[atguigu@hadoop104 flume]$ vim job/file_to_kafka.conf
2)配置文件内容如下
#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3)编写Flume拦截器
(1)创建Maven工程flume-interceptor
(2)创建包:com.atguigu.gmall.flume.interceptor
(3)在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
4)在com.atguigu.gmall.flume. 包下创建JSONUtil类
package com.atguigu.gmall.flume.utils;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.JSONException;
public class JSONUtil {
/*
* 通过异常判断是否是json字符串
* 是:返回true 不是:返回false
* */
public static boolean isJSONValidate(String log){
try {
JSONObject.parseObject(log);
return true;
}catch (JSONException e){
return false;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5)在com.atguigu.gmall.flume.interceptor包下创建ETLInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.atguigu.gmall.flume.utils.JSONUtil;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1、获取body当中的数据并转成字符串
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
//2、判断字符串是否是一个合法的json,是:返回当前event;不是:返回null
if (JSONUtil.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
6)打包
7)需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面。
日志采集Flume测试
1)启动Zookeeper、Kafka集群
2)启动hadoop102的日志采集Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
- 1
3)启动一个Kafka的Console-Consumer
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
- 1
4)生成模拟数据
[atguigu@hadoop102 ~]$ lg.sh
- 1
5)观察Kafka消费者是否能消费到数据
日志采集Flume启停脚本
1)分发日志采集Flume配置文件和拦截器
若上述测试通过,需将hadoop102节点的Flume的配置文件和拦截器jar包,向另一台日志服务器发送一份。
2)编写一个日志采集Flume进程的启停脚本
[atguigu@hadoop102 bin]$ vim f1.sh
- 1
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 f1.sh
4)f1启动
[atguigu@hadoop102 module]$ f1.sh start
5)f2停止
[atguigu@hadoop102 module]$ f1.sh stop

