
- 1unet网络python代码详解_Keras:Unet网络实现多类语义分割方式
- 2【Linux】Centos 8 服务器部署:阿里云域名注册、域名解析、个人网站 ICP 备案详细教程_网站域名和服务器
- 3烂泥:学习ubuntu远程桌面(一):配置远程桌面
- 4素数判断函数 c_在c++中if(mrun.currentfloor!=index)什么意思
- 5【Java】Spring Boot 配置 PageHelper分页插件_springboot分页插件pagehelper
- 6【v8初体验】利用yolov8训练COCO数据集或自定义数据集
- 7记一次用Sublime Text 4 配置LaTeX写作环境_latex sublime
- 8Git如何回退到某个提交_git还原到某个提交
- 9面试:大数据和深度学习之间的关系是什么?
- 10Sublime text3保存自动编译TypeScript_sublime3 typescript插件
Transformer and Self-Attention(Pytorch实现)_self-attention pytorch
赞
踩
1. Attention
Attention函数的本质可以描述为:将查询(query)和一组键值(key-value)对映射到输出(output)。

从本质上理解,Attention是从大量信息中筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
2. Self-Attention
而自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。具体讲就是,一个序列中的每个词都要和该序列中的所有词进行attention计算,目的是学习序列内部的词依赖关系,捕获句子的内部结构和相关性。这里主要参考Attention is all you need这篇论文中的实现方式进行介绍。
论文中,具体实现的self-attention机制为 Scaled Dot-Product Attention.

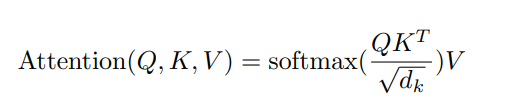
自注意力机制计算过程可以归纳为如下步骤:
- 将输入单词转化成嵌入向量表示形式;
- 根据每个词的嵌入向量分别得到q, k, v三个向量;
- 计算score:这里采用点积的计算方式得到value对应的分数 s c o r e = q ⋅ k score = q \cdot k score=q⋅k;
- 为了梯度的稳定,得到分数后,Transformer对每一个权重分数除以 d k \sqrt{d_k} dk ;
- softmax激活函数,得到value对应的权重分数;
- 结果与v进行点积,得到每个输入向量的评分v,最后对v进行求和得到最终的输出结果。

实际的计算过程中,q, k, v会以矩阵的形式进行计算,分别对应公式中的Q,K和V。
实现代码如下:
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super (ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) #size:[batch_size, n_heads, len_q, len_k], 这里len_q和len_k相等,为序列长度
scores.masked_fill_(attn_mask, -1e9) #对mask中数值为1的位置,填充数值
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. Multi-Head Attention
多头注意力机制可以让网络模型关注到来自不同位置的不同表示子空间的信息,


在多头注意力机制中,Q,K,V的形状大小分别为:
Q: [len_q, d_model]
K: [len_k, d_model]
V: [len_k, d_model]
其中设定len_q=len_k,对应序列长度,d_model对应特征维度。
此外,上式中参数
W
i
Q
,
W
i
K
,
W
i
V
W_i^Q, W_i^K, W_i^V
WiQ,WiK,WiV分别对应三个线性变换层,形状大小分别对应:
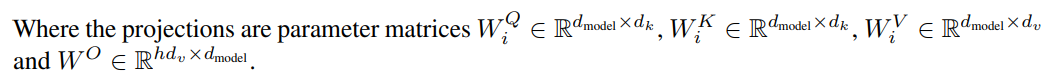
实现代码如下:
class MultiHeadAttention(nn.Module): def __init__(self): super(MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads) self.W_K = nn.Linear(d_model, d_k * n_heads) self.W_V = nn.Linear(d_model, d_v * n_heads) self.linear = nn.Linear(n_heads * d_v, d_model) self.layer_norm = nn.LayerNorm(d_model) def forward(self, Q, K, V, attn_mask): # Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model] residual, batch_size = Q, Q.size(0) q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size, n_heads, len_q, d_k] k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size, n_heads, len_k, d_k] v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size, n_heads, len_k, d_v] attn_mask = attn_mask.unsequeeze(1).repeat(1, n_heads, 1, 1) # attn_mask: [batch_size, n_heads, len_q, len_k] # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k] context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask) context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v] output = self.linear(context) # output: [batch_size x len_q x d_model] return self.layer_norm(output + residual), attn

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4. Transformer

Transformer模型使用encoder-decoder网络架构,主要包含encoder编码器部分和decoder解码器部分。
4.1 Encoder
encoder由多个(原文中使用6个)相同的编码器层堆叠组成,每个encoder layer包含两个子层,分别为多头自注意力子层和position-wise全连接前馈网络子层。
该全连接网络层包含两个线性变换,中间经过一个ReLU激活层。具体实现代码如下:
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
# inputs: [batch_size, len_q, d_model]
residual = inputs
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2))) # 因为conv1需要的输入维度为d_model,所以需要进行transpose
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
代码执行过程对照原文更加容易理解。
下面实现encoder layer部分:
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
# enc_inputs ot same Q, K, V 其实也可以理解为输入数据经过三个线性变换分别得到Q,K,V
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, len_q, d_model]
return enc_outputs, attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
接下来为Encoder代码:
class Encoder(nn.Module): def __init__(self): super(Encoder, self).__init__() self.src_emb = nn.Embedding(src_vocab_size, d_model) self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_len+1, d_model), freeze=True) self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) def forward(self, enc_inputs): # enc_inputs: [batch_size, source_len] enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1, 2, 3, 4, 0]])) # 位置编码只是用了包含五个词的输入序列替代,可以根据实际数据进行更改。 enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) enc_self_attns = [] for layer in self.layers: enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) enc_self_attns.append(enc_self_attn) return enc_outputs, enc_self_attns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Encoder的输入由两部分组成,一个对应序列中每个词的embedding 表示,另一部分对应每个词在句子中的位置信息编码(Positional Encoding),这两部分分别对应上述代码中self.src_emb和self.pos_emb。其中位置信息编码通过下式得到:
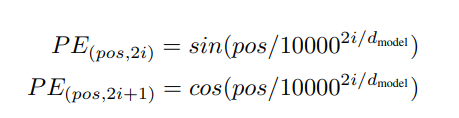
p
o
s
pos
pos表示position,
i
i
i表示维度,即位置编码的每一个维度对应一个正弦曲线值。实现代码如下:
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.2 Decoder
Decoder同样包含6个相同的层,与encoder不同的是,每个decoder layer包含三个子层,多出的一层由于对encoder部分的输出数据进行处理。
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Decoder中包含多个Decoder Layer层,具体代码如下:
class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_len+1, d_model), freeze=True) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs: [batch_size, target_len] dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor[[5, 1, 2, 3, 4]]) dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) dec_enc_attn_mask = get_attn_pad_mask((dec_inputs, enc_inputs)) dec_self_attns, dec_enc_attns = [], [] for layer in self.layers: dec_ouputs, dec_self_attn, dec_enc_attn = layer(dec_ouputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) return dec_ouputs, dec_self_attns, dec_enc_attns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5. Transformer
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, src_vocab_size, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6. 补充,masked_self_attention
Transformer中,主要有两个地方会用到掩码这一机制,一个是Attention_mask,也可以称为subsequent_mask,用于在训练过程中解码的时候掩盖掉当前时刻之后的信息;第二个是Padding Mask,对一个batch中不同长度的序列在Padding得到相同长度后,对Padding部分的信息进行掩盖。具体解释可参见Transformer中是否需要进行mask
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(0) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k)
def get_attn_subsequent_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequent_mask = np.triu(np.ones(attn_shape), k=1) # 上三角矩阵
subsequent_mask = torch.from_numpy(subsequent_mask).byte()
return subsequent_mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

