
- 1react18+antd5从0到1的后台管理系统(三)_react-antd 创建管理后台教程
- 2vue3中使用sass实现切换主题功能_vue3.0项目中使用scss动态切换页面主题风格
- 3MySQL 事务原理分析
- 4PyQt5最全55 树控件之添加、修改、删除树控件中的节点_python tree insert 子节点加号
- 5【Matlab】基于指标的多目标优化算法之ISDE+_isde算法
- 6Python学习篇33-Python操作Excel存储数据_python中保存excel的命令
- 7麒麟服务器各版本进入单用户和急救模式_银河麒麟 按 e
- 8蓝桥杯中必知的python基础知识_蓝桥杯python组能学到什么
- 9「Spring Boot 系列」05. Spring Boot Profiles(多环境配置)_springboot profiles多环境
- 10用docker安装emby的详细步骤
神仙打架——号称是性能最强的中英文百亿参数量开源模型Baichuan-13B他来了!_generationconfig.from_pretrained
赞
踩
下午开个会的功夫看到新闻推送一条最新的大模型相关的项目开源发布了,到底是怎么个事我们来一起看下。
官方项目地址在这里,如下所示:
可以看到:才刚刚过去十几分钟的时间就已经有超过500的star量了。
就在不久前的6月15日,百川智能才刚刚发布其第一款70亿参数量的中英文语言模型Baichuan-7B。当时的版本便已经拿下多个世界权威Benchmark榜单同量级测试榜首;同样作为开源大模型,据说清华北大都已经用上了。仅仅时隔25天,更大、更强的版本再次袭来,不得不说,王小川在技术上的动作是有够紧锣密鼓的了。
baichuan-7B官方项目地址在这里,如下所示:
目前已经有超过4.3k的star量了。
模型仓库地址在这里,如下所示:
Baichuan-7B是由百川智能开发的一个开源的大规模预训练模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。如果希望使用Baichuan-7B(如进行推理、Finetune等),我们推荐使用配套代码库Baichuan-7B。
模型评测结果如下所示:
| Model 5-shot | Average | Avg(Hard) | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|---|
| GPT-4 | 68.7 | 54.9 | 67.1 | 77.6 | 64.5 | 67.8 |
| ChatGPT | 54.4 | 41.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| Claude-v1.3 | 54.2 | 39.0 | 51.9 | 61.7 | 52.1 | 53.7 |
| Claude-instant-v1.0 | 45.9 | 35.5 | 43.1 | 53.8 | 44.2 | 45.4 |
| BLOOMZ-7B | 35.7 | 25.8 | 31.3 | 43.5 | 36.6 | 35.6 |
| ChatGLM-6B | 34.5 | 23.1 | 30.4 | 39.6 | 37.4 | 34.5 |
| Ziya-LLaMA-13B-pretrain | 30.2 | 22.7 | 27.7 | 34.4 | 32.0 | 28.9 |
| moss-moon-003-base (16B) | 27.4 | 24.5 | 27.0 | 29.1 | 27.2 | 26.9 |
| LLaMA-7B-hf | 27.1 | 25.9 | 27.1 | 26.8 | 27.9 | 26.3 |
| Falcon-7B | 25.8 | 24.3 | 25.8 | 26.0 | 25.8 | 25.6 |
| TigerBot-7B-base | 25.7 | 27.0 | 27.3 | 24.7 | 23.4 | 26.1 |
| Aquila-7B* | 25.5 | 25.2 | 25.6 | 24.6 | 25.2 | 26.6 |
| Open-LLaMA-v2-pretrain (7B) | 24.0 | 22.5 | 23.1 | 25.3 | 25.2 | 23.2 |
| BLOOM-7B | 22.8 | 20.2 | 21.8 | 23.3 | 23.9 | 23.3 |
| Baichuan-7B | 42.8 | 31.5 | 38.2 | 52.0 | 46.2 | 39.3 |
评测对比结果如下:

Demo代码实例如下所示:
- from transformers import AutoModelForCausalLM, AutoTokenizer
-
- tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-7B", trust_remote_code=True)
- model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-7B", device_map="auto", trust_remote_code=True)
- inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
- inputs = inputs.to('cuda:0')
- pred = model.generate(**inputs, max_new_tokens=64,repetition_penalty=1.1)
- print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
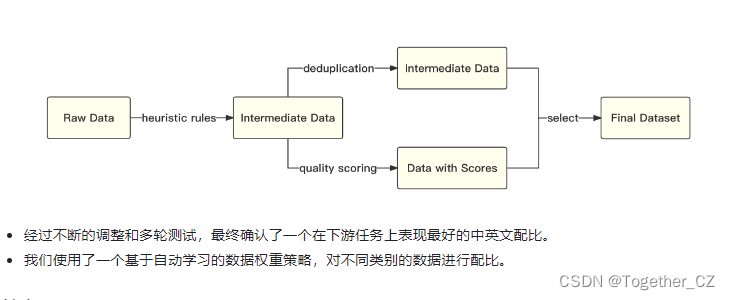
整体处理流程如下所示:
关于7B的介绍就到这里,接下来我们来看今天重点关注的13B。
这里可以看到官方带来了Baichuan-13B-Base和Baichuan-13B-Chat两款模型,这里给出来所有模型的下载地址。
首先是Baichuan-13B-Base,地址在这里,如下所示:
Baichuan-13B-Base为Baichuan-13B系列模型中的预训练版本,经过对齐后的模型可见Baichuan-13B-Chat。
Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。Baichuan-13B 有如下几个特点:
更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
同时开源预训练和对齐模型:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
更高效的推理:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。不得不说完全开源商用这个还是很值得点赞的。
Baichuan-13B-Chat为官方发布的对话版本,地址在这里,如下所示:

Baichuan-13B-Chat为Baichuan-13B系列模型中对齐后的版本,预训练模型可见Baichuan-13B-Base。Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。Baichuan-13B 有如下几个特点:
更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
同时开源预训练和对齐模型:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
更高效的推理:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
这里简单看下官方提供的许可协议:
《Baichuan-13B 模型商用许可协议》


《Baichuan-13B 模型社区许可协议》


官方评测结果如下所示:
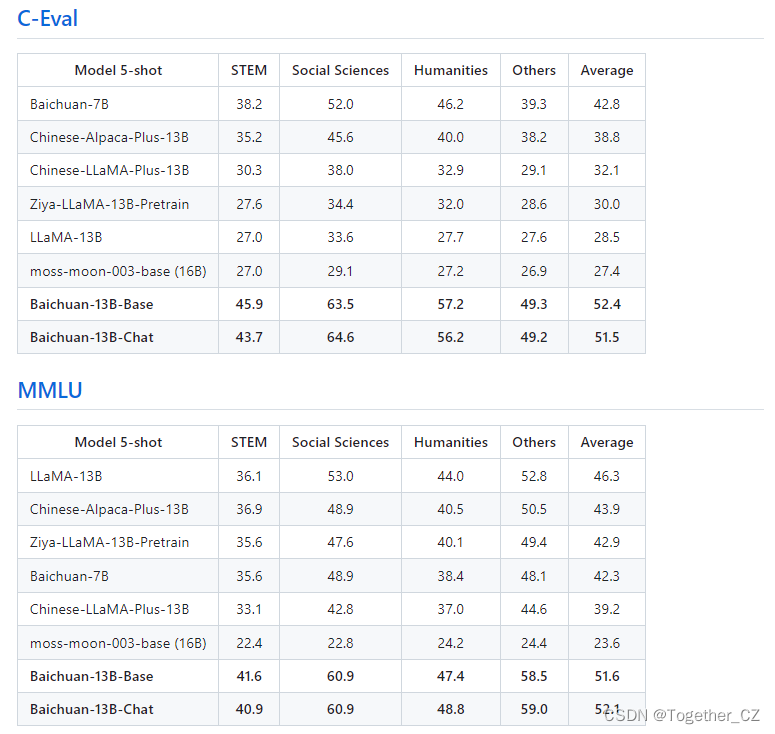
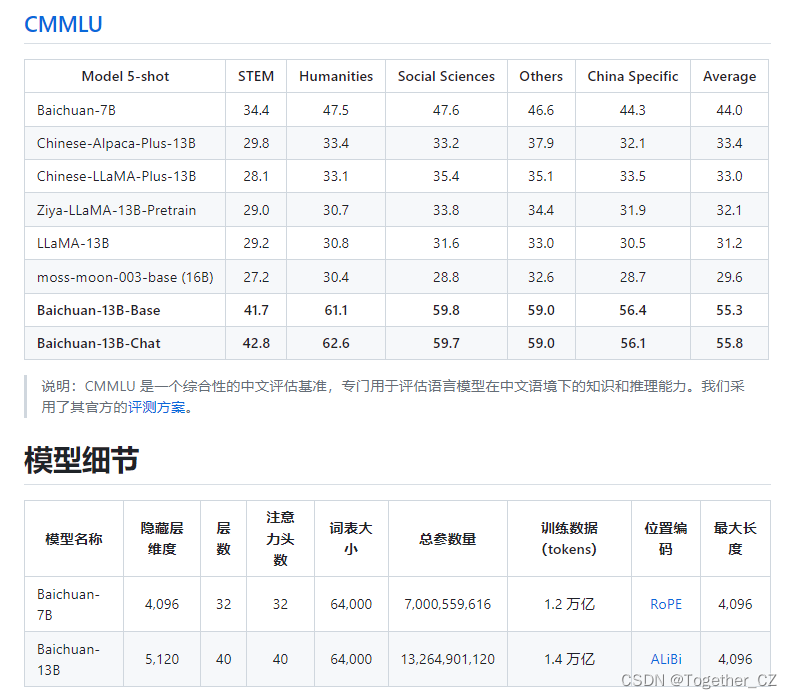
Baichuan-7B使用的位置编码方法是RoPE,感兴趣的话可以阅读下面的论文:
《RoFormer: Enhanced Transformer with Rotary Position Embedding》

Baichuan-13B使用的位置编码方式是ALiBi,详情可以研读下面的论文:
《Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation》

Demo代码实例如下所示:
- import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
- from transformers.generation.utils import GenerationConfig
- tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
- model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
- model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
- messages = []
- messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
- response = model.chat(tokenizer, messages)
- print(response)
- 乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上
Baichuan-13B 支持 int8 和 int4 量化,用户只需在推理代码中简单修改两行即可实现。请注意,如果是为了节省显存而进行量化,应加载原始精度模型到 CPU 后再开始量化;避免在from_pretrained时添加device_map='auto'或者其它会导致把原始精度模型直接加载到 GPU 的行为的参数。
如需使用 int8 量化:
- model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
- model = model.quantize(8).cuda()
同样的,如需使用 int4 量化:
- model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
- model = model.quantize(4).cuda()
量化前后占用显存情况如下:
| Precision | GPU Mem (GB) |
|---|---|
| bf16 / fp16 | 26.0 |
| int8 | 15.8 |
| int4 | 9.7 |
量化后在各个 benchmark 上的结果和原始版本对比如下:
| Model 5-shot | C-Eval | MMLU | CMMLU |
|---|---|---|---|
| Baichuan-13B-Base | 52.4 | 51.6 | 55.3 |
| Baichuan-13B-Base-int8 | 51.2 | 49.9 | 54.5 |
| Baichuan-13B-Base-int4 | 47.6 | 46.0 | 51.0 |
简单看下官方的实例效果吧:
【内容创作】
- 用户:
- 你是一个内容创作者,编写一段关于对马斯克和比尔盖茨访问中国视角的短视频脚本
-
- Baichun-13B-Chat:
- 探索马斯克与比尔·盖茨的中国之旅
-
- 镜头1:(背景音乐)画面切入,展示中国的繁华都市景象。
-
- 旁白:欢迎来到我们的节目,今天我们将带您一起了解两位科技巨头——埃隆·马斯克和比尔·盖茨在中国的一次特殊访问。
-
- 镜头2:(背景音乐)画面切换至马斯克和比尔·盖茨抵达中国的机场。
-
- 旁白:这次访问是他们首次共同踏上中国的土地,他们将在这里展开一场关于科技创新、环保和教育的对话。
-
- 镜头3:(背景音乐)画面展示马斯克和比尔·盖茨参观一家电动汽车制造厂。
-
- 旁白:在这次访问中,他们首先参观了一家电动汽车制造厂,了解了中国在新能源汽车领域的最新发展。
-
- 镜头4:(背景音乐)画面展示马斯克和比尔·盖茨参加一场关于人工智能的论坛。
-
- 旁白:随后,他们参加了关于人工智能的一场论坛,探讨了这一领域的发展趋势及其对未来的影响。
-
- 镜头5:(背景音乐)画面展示马斯克和比尔·盖茨参观一所学校。
-
- 旁白:在这次访问中,他们还参观了一所学校,了解了中国在教育领域的创新实践。
-
- 镜头6:(背景音乐)画面展示马斯克和比尔·盖茨接受媒体采访。
-
- 旁白:最后,他们在媒体采访环节表示,希望通过这次访问,能够为中美两国在科技创新、环保和教育等领域的合作提供一些启示。
-
- 镜头7:(背景音乐)画面切回繁华都市景象。
-
- 旁白:这就是马斯克和比尔·盖茨的中国之行,他们的访问不仅让我们看到了中国在科技创新方面的巨大潜力,也为我们提供了关于未来发展的更多思考。感谢收看,我们下期再见!
【广告文案】
- 用户:
- 请以销售员的角色,将洗衣液的干净、无残留、无异味以及除菌等优点进行推销
-
- Baichun-13B-Chat:
- 尊敬的顾客,您好!我是一名洗衣液销售员,非常高兴为您介绍我们这款产品。我们的洗衣液具有以下几个显著优点:
-
- 干净:我们的洗衣液采用了先进的洗涤技术,能够深入衣物纤维,有效去除各种污渍,让您的衣物焕然一新。同时,它不会对衣物的颜色和质地造成任何损害,让您的衣物保持原有的品质。
-
- 无残留:与传统的洗衣粉相比,我们的洗衣液在清洗过程中不会产生过多的泡沫,因此清洗后的衣物更加柔软,不会有黏腻的感觉。此外,它的去污能力强,能彻底洗净衣物上的污渍,避免了传统洗衣粉容易残留在衣物上的问题。
-
- 无异味:我们的洗衣液采用天然植物提取物作为原料,不含有害化学物质,因此在使用过程中不会产生刺鼻的气味。即使是敏感肌肤的人群也可以放心使用,让您的衣物散发出淡雅的清香。
-
- 除菌:为了满足现代人对健康生活的需求,我们的洗衣液特别添加了高效除菌成分,能够有效杀灭衣物上的细菌,保护您和家人的身体健康。无论是婴幼儿的衣物还是贴身内衣,都可以放心使用。
-
- 总之,我们的洗衣液凭借其干净、无残留、无异味以及除菌等优点,成为了广大消费者的首选。如果您还没有尝试过我们的产品,那么现在就是最好的时机。相信它一定会给您带来全新的洗衣体验!
-
-
-
-
-
-
-
-
-
- 用户:
- 准备一份以宠物食品为主题的报告,包括潜在消费者,市场规模,市场机遇,及盈利模式等内容
-
-
- Baichun-13B-Chat:
-
- 一、引言
-
- 随着人们生活水平的提高和对宠物的关爱程度不断加深,宠物食品行业得到了快速发展。本报告将对宠物食品行业的潜在消费者、市场规模、市场机遇以及盈利模式等方面进行分析,以期为相关企业提供有益的参考信息。
-
- 二、潜在消费者
-
- 1. 养宠人群:随着养宠人数的增加,宠物食品的需求也在不断增长。根据统计数据显示,2019年中国城镇养宠(犬猫)人口数量已达7355万人,同比增长4.6%。预计到2023年,这一数字将达到8742万人。
-
- 2. 新生代消费者:新生代消费者在消费观念上更加注重健康、环保和个性化,这使得他们更愿意为宠物购买高品质的食品。此外,他们也更倾向于通过网络平台了解和购买宠物食品。
-
- 三、市场规模
-
- 1. 根据国家统计局数据,2019年我国宠物食品市场规模达到了1,020亿元人民币,同比增长约10%。预计到2023年,市场规模将达到1, 500亿元人民币。
-
- 2. 从产品类型来看,宠物干粮市场占比最高,约占总市场的70%;其次是宠物湿粮,占比约为20%;宠物零食市场占比约为10%。
-
- 四、市场机遇
-
- 1. 功能性宠物食品:随着消费者对健康的关注度不断提高,具有特定功能的宠物食品如处方粮、减肥粮等需求逐渐增大。
-
- 2. 天然有机宠物食品:越来越多的消费者倾向于选择天然、无添加剂的宠物食品,这也为市场带来了新的商机。
-
- 3. 定制化宠物食品:针对不同品种、年龄、体型的宠物,推出定制化的宠物食品,满足消费者个性化需求。
-
- 五、盈利模式
-
- 1. 传统销售渠道:通过超市、宠物店、电商平台等传统渠道销售宠物食品。
-
- 2. 直销模式:通过自建网站或与第三方平台合作,直接向消费者销售宠物食品。
-
- 3. 会员制:通过设立会员制度,为会员提供专属优惠和服务,增加客户粘性。
-
- 4. 增值服务:提供宠物美容、寄养、训练等附加服务,实现多元化盈利。
-
- 六、结论
-
- 宠物食品行业具有巨大的市场潜力和发展空间。企业应抓住市场机遇,关注消费者需求变化,创新产品
【精准问答】
- 用户:
- 世界上第二高的山是什么山
-
- Baichun-13B-Chat:
- 乔戈里峰(K2) 海拔8611米,位于喀喇昆仑山脉的中巴边境上,是中国以外登山者的最大考验,也是世界上最难征服的山峰之一。它的高度仅次于珠穆朗玛峰,位居世界第二。
-
-
- 用户:
- 意兴阑珊是什么意思
-
- Baichun-13B-Chat:
- "意兴阑珊"是一个汉语成语,它的意思是形容一个人兴致不高,兴趣减弱。这个词通常用来描述一个人在某个活动中失去了原有的热情和兴趣。
-
-
- 用户:
- 请问强化学习里面的Reward Shaping是什么意思
-
- Baichun-13B-Chat:
- 奖励塑造(Reward Shaping)是强化学习中的一个概念,它是指通过调整环境或设计特定的奖励函数来引导智能体(Agent)学习到更符合人类期望的行为。在传统的强化学习中,智能体通过与环境交互来学习最优策略,但这种方法可能导致智能体学习到一些次优甚至不良行为。
-
- 奖励塑造的目的是为了解决这个问题,通过人为地调整奖励函数,使得智能体更容易学到我们希望它学会的行为。这可以通过以下几种方式实现:
-
- 1. 增加正向奖励:当智能体表现出期望行为时,给予其更多的奖励,以鼓励这种行为。
- 2. 减少负向奖励:当智能体表现出不期望行为时,减少对其进行惩罚,降低其对这种行为的偏好。
- 3. 引入新奖励:为智能体提供额外的奖励,以便更好地引导其学习特定行为。
- 4. 改变奖励分布:通过调整奖励函数,使其具有不同的奖励分布,从而影响智能体的学习过程。
-
- 总之,奖励塑造是一种通过调整环境和奖励函数来引导智能体学习更好行为的方法,有助于提高强化学习的性能。
【语言理解】
- 用户:
- 小张给领导买了一个礼物说,说“意思一下”,领导说“什么意思”,小张回答说:“没什么意思,就是随便意思意思”。请依次解读一下小张说的这几个“意思”的含义。
-
- Baichun-13B-Chat:
- 1. 第一个“意思”:指的是小张送给领导的那个礼物,表示他已经买了这个礼物并准备送给他。
- 2. 第二个“意思”:指的是小张对领导的一种礼貌和尊重,表示自己并没有忘记他的身份和地位,在购买礼物时也考虑到了这一点。
- 3. 第三个“意思”:指的是小张对于这次赠送礼物的行为本身的态度,即不希望这件事情引起过多的关注或争议,只是想表达一种心意而已。
接下来找时间具体部署一下体验一下实际效果吧。

