- 1鸿蒙HarmonyOS开发实战—多媒体开发(音频开发 一)_鸿蒙播放声音 开发
- 2用UGUI制作HUD_unity hud ugui
- 3Gen-AI 的知识图和分析(无需图数据库)_gen ai
- 4用于三维点云语义分割的标注工具和城市数据集
- 5【Unity小技巧】可靠的相机抖动及如何同时处理多个震动(附项目源码)_cinemachine相机抖动
- 6QtCreator不识别安卓手机解决_qtscrcpy连不上手机
- 7Microsoft .NET框架糅合各种编程语言,开创Web新时代_.net语言合作
- 82023新年倒计时(付源码)_pycharm2023倒计时
- 9windows11内置微软copilot国内能用吗?一切来看下!_win 11 copilot登录不了
- 10caffe层解析之softmaxwithloss层_caffe softmaxwithloss
【深度学习入门系列】 pytorch实现多层感知机(MLP)(内含分类、回归任务实例)_pytorch mlp
赞
踩
众所周知,sklearn提供了MLP函数。个人认为这个东西虽然蛮好用的——有的时候比你自己写的效果都好,但是,不是长久之计。通过Pytorch能建立自定义程度更高的人工神经网络,往后在网络里面加乱七八糟的东西都很方便(比如GA/PSO求解超参之类的、比如微调模型架构之类的)。本文将不再对MLP的理论基础进行赘述,直接介绍MLP的具体搭建方法。
0. BP和MLP
在做这个之前,我突然想到一个问题
我现在出了一篇 MLP 的文章,要不要再出一个 BP 的?
沉默……
这俩有什么区别啊???
跟某知名大博主讨论了一下,感觉大概是这样的:
我们先明确3个概念:
- BP:BP的全称是back propagation(反向传播算法),这并不是一个神经网络。
- BP神经网络:用了BP算法的神经网络。
- MLP:多层感知机,也就是我们说的神经网络。
那么我们不难发现,所谓的BP神经网络其实应该是(BP-MLP )
<=> BP神经网络 = BP算法 + MLP(多层感知机)
也就是说,BP 和 MLP 本身是平行的两个概念,不是一件事;它们是 BP 神经网络这个事物的两个不同的方面。
猜测
最开始的时候,神经网络方面的知识还不够丰富,这个时候人们把刚开始的那个简单的结构称作MLP。
随着时间的流逝,人们发现了反向传播算法(BP),这个时候开始强调训练方法了,所以将其相关的神经网络称为BP神经网络。
再往后,因为人们都用BP了,BP不那么新那么火了,这个时候又开始强调模型结构了,就出现了乱七八糟的其他神经网络。
1 分类
1.0 数据集
数据集我采用的是之前接手的一个保险理赔项目。
目标是判断用户是不是来骗保的,给了一大堆特征,这里我就不详细解释是哪些特征了,这篇文章主要负责搭建模型。
归一化之后发现数据还是非常稀疏的,而且看着可能二值化效果会不错,嫌麻烦,不尝试了,就直接拿这个用也没什么大问题。
是一个4分类任务,结果可能没2分类好看,这跟项目的数据也有关,本身数据也比较脏、噪声也比较多,感觉特征与 label 之间的联系也不是特别紧密。不过问题不大,我们的重心还是放在搭网络上。
数据集缺点还包括样本不平衡,确实会影响结果。
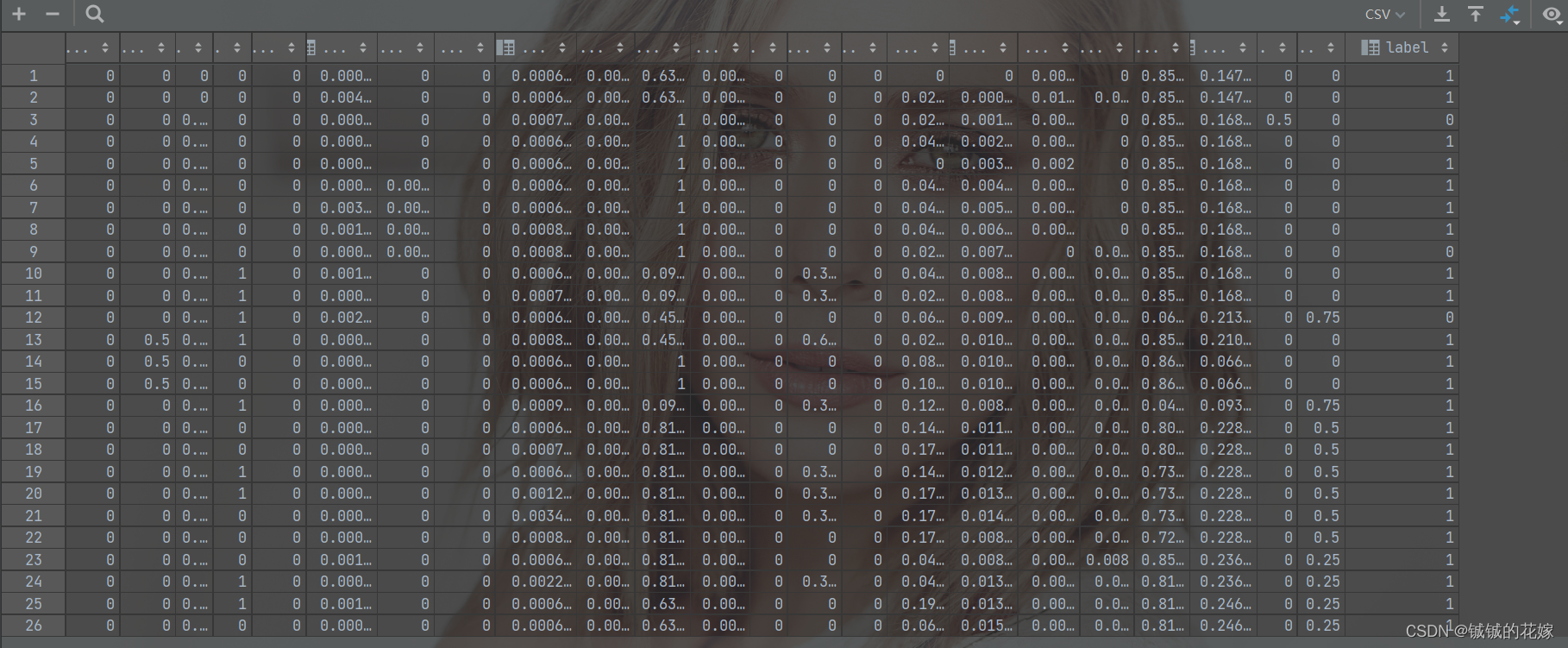
data.csv (36221x24)=> 已经包括 label 了
1.1 网络架构
torch 输出的架构如下
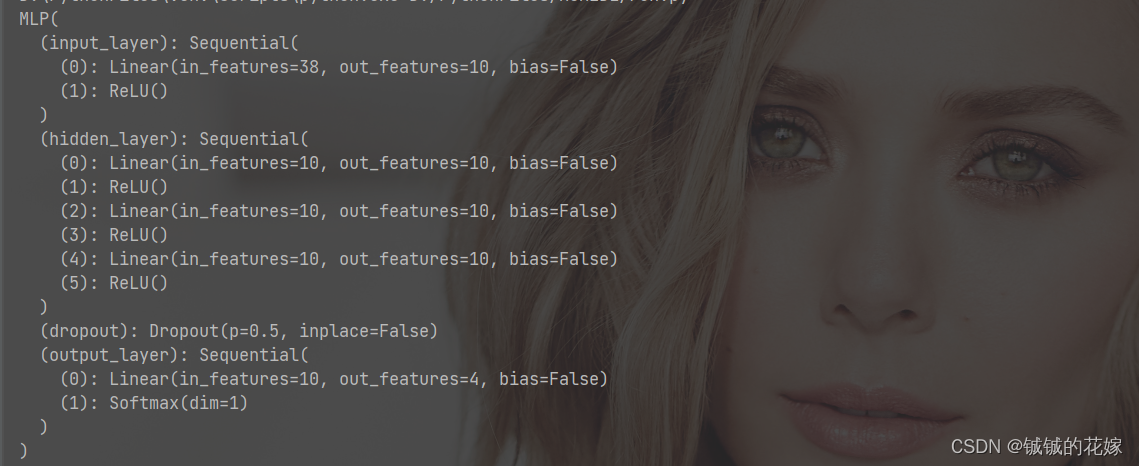
一共是4层隐藏层(10->10->10->10)
也尝试过 128->64->16 和一些大的复杂的多层感知机,效果反而没这个好,从混淆矩阵看能发现过拟合了。
1.2 代码
分类任务的相关文件如下
MLP_clf.py 分类模型架构
data.csv 分类数据集
run.py 主函数
utils.py 相关函数和类
- 1
- 2
- 3
- 4
run.py
import os import numpy import torch import random from utils import Config, CLF_Model, REG_Model from clf_model.MLP_clf import MLP # 随机数种子确定 seed = 1129 random.seed(seed) numpy.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False os.environ['PYTHONHASHSEED'] = str(seed) # 分类 if __name__ == '__main__': # 读数据 config = Config( data_path="dataset_clf/data.csv", name="MLP", batch_size=128, learning_rate=0.000005, epoch=200 ) # 搭模型 clf = MLP( input_n=len(config.input_col), output_n=len(config.output_class), num_layer=4, layer_list=[10,10,10,10], dropout=0.5 ) print(clf) # 训练模型并评价模型 model = CLF_Model(clf, config) model.run()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
MLP_clf.py
import torch from torch.nn import Linear, ReLU, ModuleList, Sequential, Dropout, Softmax, Tanh import torch.nn.functional as F class MLP(torch.nn.Module): # 默认三层隐藏层,分别有128个 64个 16个神经元 def __init__(self, input_n, output_n, num_layer=3, layer_list=[128, 64, 16], dropout=0.5): """ :param input_n: int 输入神经元个数 :param output_n: int 输出神经元个数 :param num_layer: int 隐藏层层数 :param layer_list: list(int) 每层隐藏层神经元个数 :param dropout: float 训练完丢掉多少 """ super(MLP, self).__init__() self.input_n = input_n self.output_n = output_n self.num_layer = num_layer self.layer_list = layer_list # 输入层 self.input_layer = Sequential( Linear(input_n, layer_list[0], bias=False), ReLU() ) # 隐藏层 self.hidden_layer = Sequential() for index in range(num_layer-1): self.hidden_layer.extend([Linear(layer_list[index], layer_list[index+1], bias=False), ReLU()]) self.dropout = Dropout(dropout) # 输出层 self.output_layer = Sequential( Linear(layer_list[-1], output_n, bias=False), Softmax(dim=1), ) def forward(self, x): input = self.input_layer(x) hidden = self.hidden_layer(input) hidden = self.dropout(hidden) output = self.output_layer(hidden) return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
util.py
import sys import numpy as np import pandas as pd import torch import torch.nn.functional as F from matplotlib import pyplot as plt from sklearn import metrics from sklearn.metrics import mean_squared_error, r2_score from sklearn.model_selection import train_test_split import time from datetime import timedelta # 一个数据格式。感觉这玩意好多余啊,但是nlp写多了就很习惯的写了一个上去 => 主要是不写没法封装 class Dataset(torch.utils.data.Dataset): def __init__(self, data_df): self.label = torch.from_numpy(data_df['label'].values) self.data = torch.from_numpy(data_df[data_df.columns[:-1]].values).to(torch.float32) # 每次迭代取出对应的data和author def __getitem__(self, idx): batch_data = self.get_batch_data(idx) batch_label = self.get_batch_label(idx) return batch_data, batch_label # 下面的几条没啥用其实,就是为__getitem__服务的 def classes(self): return self.label def __len__(self): return self.data.size(0) def get_batch_label(self, idx): return np.array(self.label[idx]) def get_batch_data(self, idx): return self.data[idx] # 存数据,加载数据用的 class Config: def __init__(self, data_path, name, batch_size, learning_rate, epoch): """ :param data_path: string 数据文件路径 :param name: string 模型名字 :param batch_size: int 多少条数据组成一个batch :param learning_rate: float 学习率 :param epoch: int 学几轮 """ self.name = name self.data_path = data_path self.batch_size = batch_size self.learning_rate = learning_rate self.epoch = epoch self.train_loader, self.dev_loader, self.test_loader = self.load_tdt() self.input_col, self.output_class = self.get_class() # 加载train, dev, test,把数据封装成Dataloader类 def load_tdt(self): file = self.read_file() train_dev_test = self.cut_data(file) tdt_loader = [self.load_data(i) for i in train_dev_test] return tdt_loader[0], tdt_loader[1], tdt_loader[2] # 读文件 def read_file(self): file = pd.read_csv(self.data_path, encoding="utf-8-sig", index_col=None) # 保险起见,确认最后一列列名为label file.columns.values[-1] = "label" self.if_nan(file) return file # 切7:1:2 => 训练:验证:测试 def cut_data(self, data_df): try: train_df, test_dev_df = train_test_split(data_df, test_size=0.3, random_state=1129, stratify=data_df["label"]) dev_df, test_df = train_test_split(test_dev_df, test_size=0.66, random_state=1129, stratify=test_dev_df["label"]) except ValueError: train_df, test_dev_df = train_test_split(data_df, test_size=0.3, random_state=1129) dev_df, test_df = train_test_split(test_dev_df, test_size=0.66, random_state=1129) return [train_df, dev_df, test_df] # Dataloader 封装进去 def load_data(self, data_df): dataset = Dataset(data_df) return torch.utils.data.DataLoader(dataset, batch_size=self.batch_size) # 检验输入输出是否有空值 def if_nan(self, data): if data.isnull().any().any(): empty = data.isnull().any() print(empty[empty].index) print("Empty data exists") sys.exit(0) # 后面输出混淆矩阵用的 def get_class(self): file = self.read_file() label = file[file.columns[-1]] label = list(set(list(label))) return file.columns[:-1], label # 跑clf用的,里面包含了训练,测试,评价等等的代码 class CLF_Model: def __init__(self, model, config): self.model = model self.config = config def run(self): self.train(self.model) def train(self, model): dev_best_loss = float('inf') start_time = time.time() # 模型为训练模式 model.train() # 定义优化器 optimizer = torch.optim.Adam(model.parameters(), lr=self.config.learning_rate) # 记录训练、验证的准确率和损失 acc_list = [[], []] loss_list = [[], []] # 记录损失不下降的epoch数,到达20之后就直接退出 => 训练无效,再训练下去可能过拟合 break_epoch = 0 for epoch in range(self.config.epoch): print('Epoch [{}/{}]'.format(epoch + 1, self.config.epoch)) for index, (trains, labels) in enumerate(self.config.train_loader): # 归零 model.zero_grad() # 得到预测结果,是一堆概率 outputs = model(trains) # 交叉熵计算要long的类型 labels = labels.long() # 计算交叉熵损失 loss = F.cross_entropy(outputs, labels) # 反向传播loss loss.backward() # 优化参数 optimizer.step() # 每100个迭代或者跑完一个epoch后,验证一下 if (index % 100 == 0 and index != 0) or index == len(self.config.train_loader) - 1: true = labels.data.cpu() # 预测类别 predict = torch.max(outputs.data, 1)[1].cpu() # 计算训练准确率 train_acc = metrics.accuracy_score(true, predict) # 计算验证准确率和loss dev_acc, dev_loss = self.evaluate(model) # 查看验证loss是不是进步了 if dev_loss < dev_best_loss: dev_best_loss = dev_loss improve = '*' break_epoch = 0 else: improve = '' break_epoch += 1 time_dif = self.get_time_dif(start_time) # 输出阶段性结果 msg = 'Iter: {0:>6}, Train Loss: {1:>5.3}, Train Acc: {2:>6.3%}, Val Loss: {3:>5.3}, Val Acc: {4:>6.3%}, Time: {5} {6}' print(msg.format(index, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve)) # 为了画图准备的,记录每个epoch的结果 if index == len(self.config.train_loader) - 1: acc_list[0].append(train_acc) acc_list[1].append(dev_acc) loss_list[0].append(loss.item()) loss_list[1].append(dev_loss) # 验证集评估时模型编程验证模式了,现在变回训练模式 model.train() # 20个epoch损失不变,直接退出训练 if break_epoch > 20: self.config.epoch = epoch+1 break # 测试 self.test(model) # 画图 self.draw_curve(acc_list, loss_list, self.config.epoch) def test(self, model): start_time = time.time() # 测试准确率,测试损失,测试分类报告,测试混淆矩阵 test_acc, test_loss, test_report, test_confusion = self.evaluate(model, test=True) msg = 'Test Loss: {0:>5.3}, Test Acc: {1:>6.3%}' print(msg.format(test_loss, test_acc)) print("Precision, Recall and F1-Score...") print(test_report) print("Confusion Matrix...") print(test_confusion) time_dif = self.get_time_dif(start_time) print("Time usage:", time_dif) def evaluate(self, model, test=False): # 模型模式变一下 model.eval() loss_total = 0 predict_all = np.array([], dtype=int) labels_all = np.array([], dtype=int) # 如果是测试模式(这一段写的不是很好) if test: with torch.no_grad(): for (dev, labels) in self.config.test_loader: outputs = model(dev) labels = labels.long() loss = F.cross_entropy(outputs, labels) loss_total += loss labels = labels.data.cpu().numpy() predict = torch.max(outputs.data, 1)[1].cpu().numpy() labels_all = np.append(labels_all, labels) predict_all = np.append(predict_all, predict) acc = metrics.accuracy_score(labels_all, predict_all) report = metrics.classification_report(labels_all, predict_all, target_names=[str(i) for i in self.config.get_class()[1]], digits=4) confusion = metrics.confusion_matrix(labels_all, predict_all) return acc, loss_total / len(self.config.dev_loader), report, confusion # 不是测试模式 with torch.no_grad(): for (dev, labels) in self.config.dev_loader: outputs = model(dev) labels = labels.long() loss = F.cross_entropy(outputs, labels) loss_total += loss labels = labels.data.cpu().numpy() predict = torch.max(outputs.data, 1)[1].cpu().numpy() labels_all = np.append(labels_all, labels) predict_all = np.append(predict_all, predict) acc = metrics.accuracy_score(labels_all, predict_all) return acc, loss_total / len(self.config.dev_loader) # 算时间损耗 def get_time_dif(self, start_time): end_time = time.time() time_dif = end_time - start_time return timedelta(seconds=int(round(time_dif))) # 画图 def draw_curve(self, acc_list, loss_list, epochs): x = range(0, epochs) y1 = loss_list[0] y2 = loss_list[1] y3 = acc_list[0] y4 = acc_list[1] plt.figure(figsize=(13, 13)) plt.subplot(2, 1, 1) plt.plot(x, y1, color="blue", label="train_loss", linewidth=2) plt.plot(x, y2, color="orange", label="val_loss", linewidth=2) plt.title("Loss_curve", fontsize=20) plt.xlabel(xlabel="Epochs", fontsize=15) plt.ylabel(ylabel="Loss", fontsize=15) plt.legend() plt.subplot(2, 1, 2) plt.plot(x, y3, color="blue", label="train_acc", linewidth=2) plt.plot(x, y4, color="orange", label="val_acc", linewidth=2) plt.title("Acc_curve", fontsize=20) plt.xlabel(xlabel="Epochs", fontsize=15) plt.ylabel(ylabel="Accuracy", fontsize=15) plt.legend() plt.savefig("images/"+self.config.name+"_Loss&acc.png")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
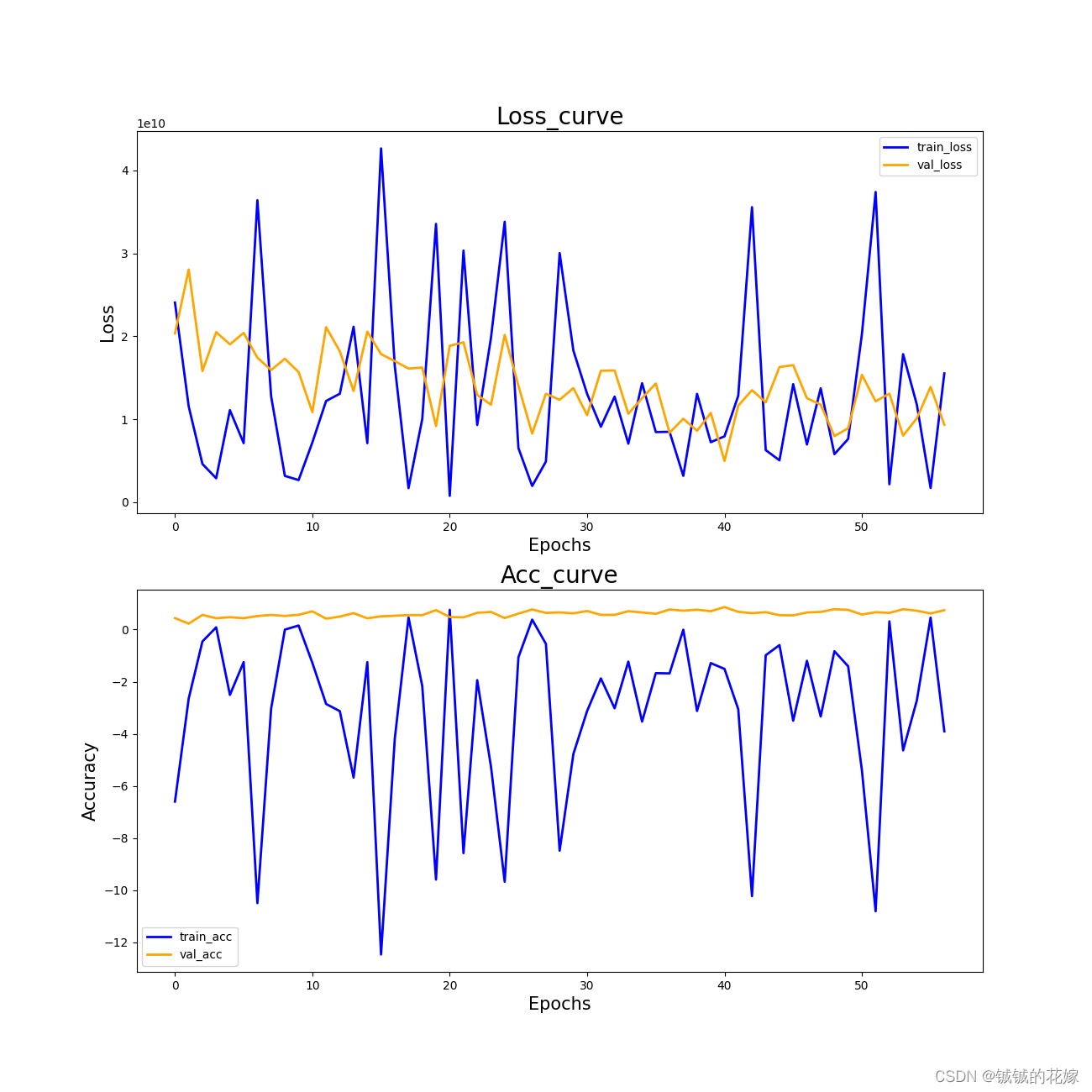
1.3 结果
训练ing……
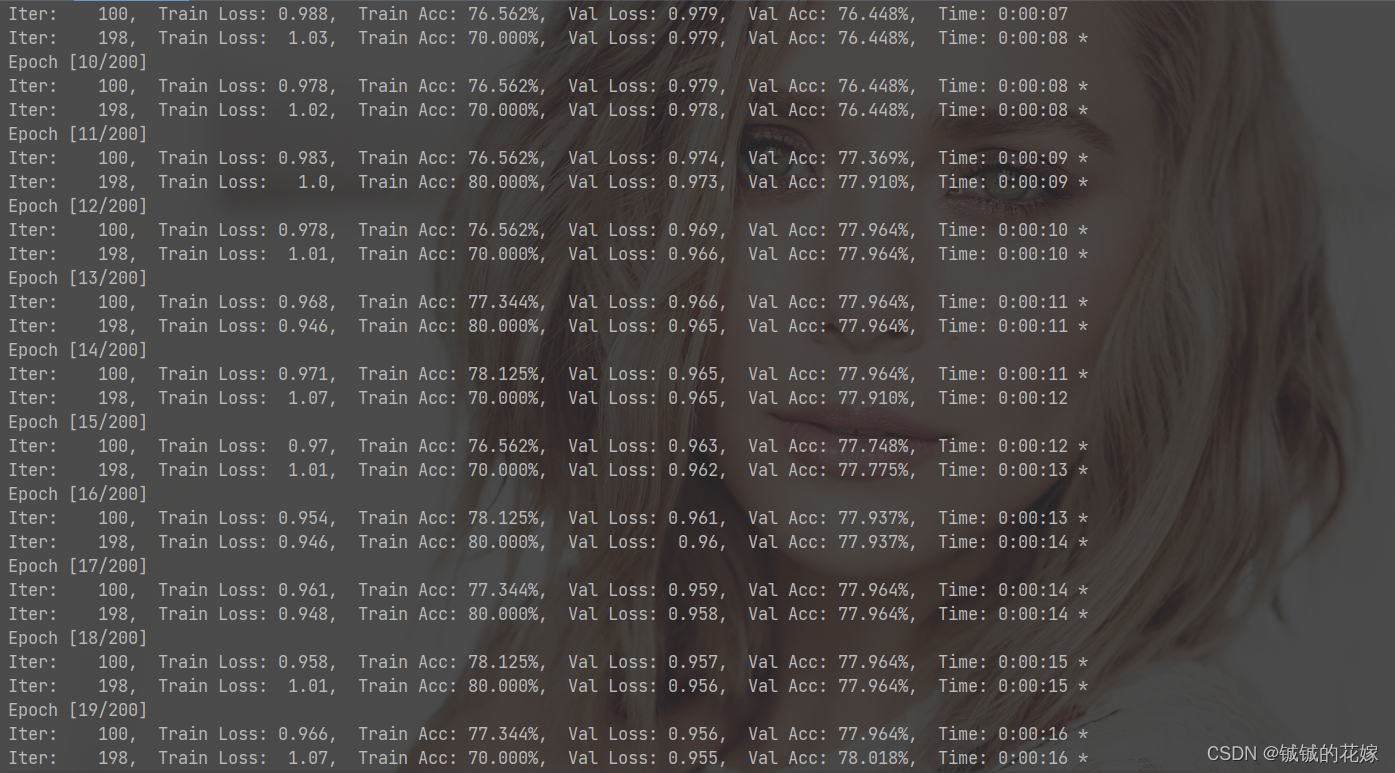
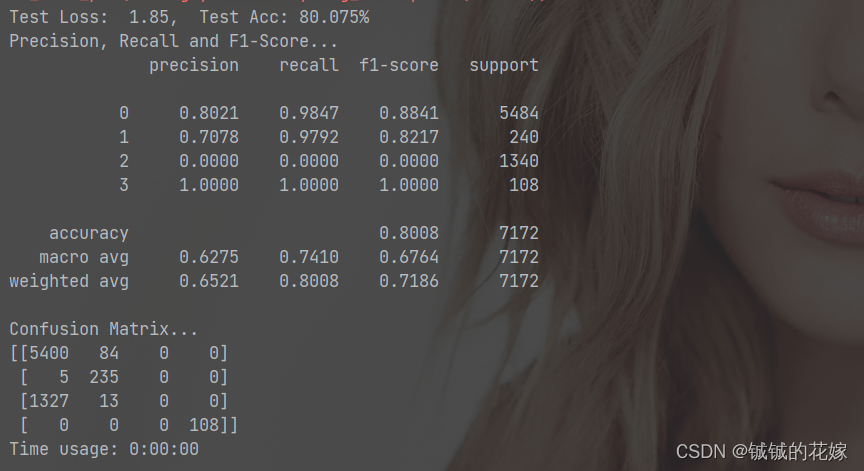
第三类的精确率感人,不过其他分类效果挺好的。感觉是数据集的问题,悄悄拿sklearn试了一下,就差1%。
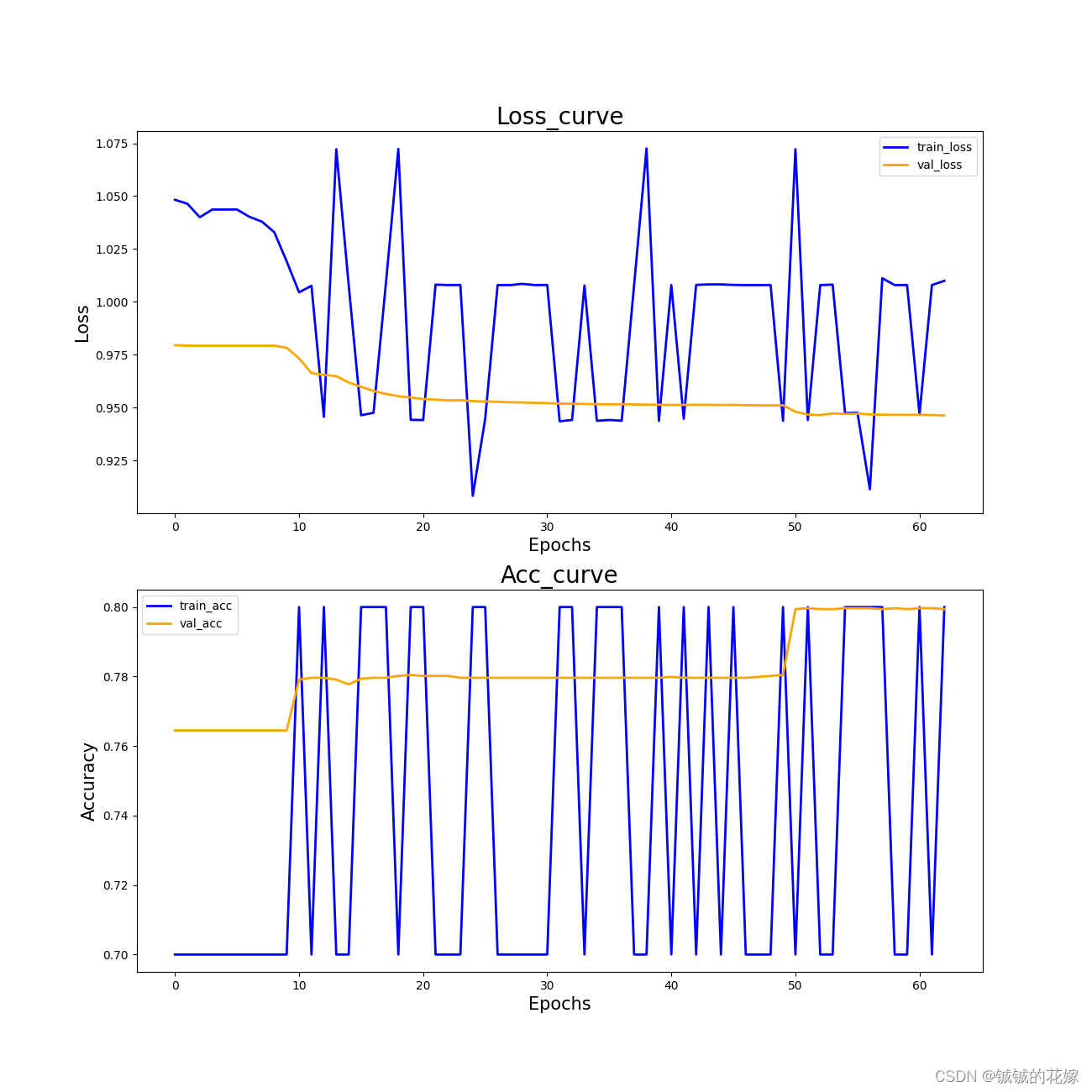
曲线如下(感觉不是正常的曲线,主要是数据集的问题,70%的数据区分度很大,剩下的很难辨认)
2 回归
2.0 数据集
用的2023美赛春季赛Y题数据,在原有的数据集上加了很多船的参数,再把两个 dataset 合一起。
预处理的操作简单暴力,重复值的行删掉,部分含空值多的行删掉,方便填充的随机森林下,不方便填充的直接暴力填0。
平时肯定是不能这么干的,但是这里我们只是需要一个数据集而已,重点还是模型。
data.csv(2793x39)=> 已经包括 label 了
label.csv(2793x1)
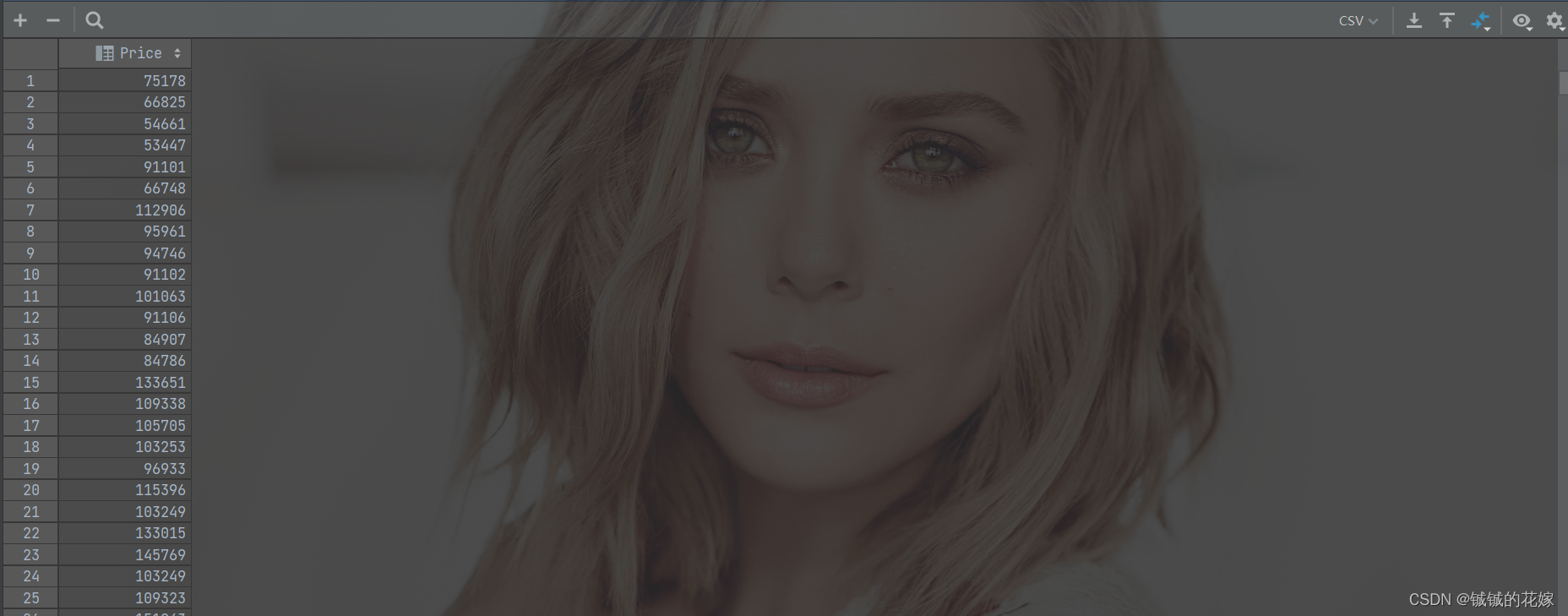
2.1 网络架构
torch 输出的架构如下

一共是4层隐藏层(512->128->32->8)
也尝试过 10->10->10 和一些大的复杂的多层感知机,效果都一般。
2.2 代码
回归任务的相关文件如下
data.csv 回归数据集
MLP_reg.py 回归模型架构
run.py 主函数
utils.py 相关函数和类
- 1
- 2
- 3
- 4
run.py
import os import numpy import torch import random from utils import Config, CLF_Model, REG_Model from clf_model.MLP_clf import MLP seed = 1129 random.seed(seed) numpy.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False os.environ['PYTHONHASHSEED'] = str(seed) from reg_model.MLP_reg import MLP # 回归 if __name__ == '__main__': config = Config( data_path="dataset_reg/data.csv", name="MLP", batch_size=16, learning_rate=0.015, epoch=200 ) # 看是几输出问题 reg = MLP( input_n=len(config.input_col), output_n=1, num_layer=4, layer_list=[512, 128, 32, 8], dropout=0.5 ) print(reg) model = REG_Model(reg, config) model.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
utils.py
import sys import numpy as np import pandas as pd import torch import torch.nn.functional as F from matplotlib import pyplot as plt from sklearn import metrics from sklearn.metrics import mean_squared_error, r2_score from sklearn.model_selection import train_test_split import time from datetime import timedelta # 一个数据格式。感觉这玩意好多余啊,但是nlp写多了就很习惯的写了一个上去 => 主要是不写没法封装 class Dataset(torch.utils.data.Dataset): def __init__(self, data_df): self.label = torch.from_numpy(data_df['label'].values) self.data = torch.from_numpy(data_df[data_df.columns[:-1]].values).to(torch.float32) # 每次迭代取出对应的data和author def __getitem__(self, idx): batch_data = self.get_batch_data(idx) batch_label = self.get_batch_label(idx) return batch_data, batch_label # 下面的几条没啥用其实,就是为__getitem__服务的 def classes(self): return self.label def __len__(self): return self.data.size(0) def get_batch_label(self, idx): return np.array(self.label[idx]) def get_batch_data(self, idx): return self.data[idx] # 存数据,加载数据用的 class Config: def __init__(self, data_path, name, batch_size, learning_rate, epoch): """ :param data_path: string 数据文件路径 :param name: string 模型名字 :param batch_size: int 多少条数据组成一个batch :param learning_rate: float 学习率 :param epoch: int 学几轮 """ self.name = name self.data_path = data_path self.batch_size = batch_size self.learning_rate = learning_rate self.epoch = epoch self.train_loader, self.dev_loader, self.test_loader = self.load_tdt() self.input_col, self.output_class = self.get_class() # 加载train, dev, test,把数据封装成Dataloader类 def load_tdt(self): file = self.read_file() train_dev_test = self.cut_data(file) tdt_loader = [self.load_data(i) for i in train_dev_test] return tdt_loader[0], tdt_loader[1], tdt_loader[2] # 读文件 def read_file(self): file = pd.read_csv(self.data_path, encoding="utf-8-sig", index_col=None) # 保险起见,确认最后一列列名为label file.columns.values[-1] = "label" self.if_nan(file) return file # 切7:1:2 => 训练:验证:测试 def cut_data(self, data_df): try: train_df, test_dev_df = train_test_split(data_df, test_size=0.3, random_state=1129, stratify=data_df["label"]) dev_df, test_df = train_test_split(test_dev_df, test_size=0.66, random_state=1129, stratify=test_dev_df["label"]) except ValueError: train_df, test_dev_df = train_test_split(data_df, test_size=0.3, random_state=1129) dev_df, test_df = train_test_split(test_dev_df, test_size=0.66, random_state=1129) return [train_df, dev_df, test_df] # Dataloader 封装进去 def load_data(self, data_df): dataset = Dataset(data_df) return torch.utils.data.DataLoader(dataset, batch_size=self.batch_size) # 检验输入输出是否有空值 def if_nan(self, data): if data.isnull().any().any(): empty = data.isnull().any() print(empty[empty].index) print("Empty data exists") sys.exit(0) # 后面输出混淆矩阵用的 def get_class(self): file = self.read_file() label = file[file.columns[-1]] label = list(set(list(label))) return file.columns[:-1], label # 跑reg用的,里面包含了训练,测试,评价等等的代码 class REG_Model: def __init__(self, model, config): self.model = model self.config = config def run(self): self.train(self.model) def train(self, model): dev_best_loss = float('inf') start_time = time.time() # 模型为训练模式 model.train() # 定义优化器 optimizer = torch.optim.Adam(model.parameters(), lr=self.config.learning_rate) acc_list = [[], []] loss_list = [[], []] # 记录损失不下降的epoch数,到达20之后就直接退出 => 训练无效,再训练下去可能过拟合 break_epoch = 0 for epoch in range(self.config.epoch): print('Epoch [{}/{}]'.format(epoch + 1, self.config.epoch)) for index, (trains, labels) in enumerate(self.config.train_loader): # 归零 model.zero_grad() # 得到预测结果 outputs = model(trains) # MSE计算要float的类型 labels = labels.to(torch.float) # 计算MSE损失 loss = torch.nn.MSELoss()(outputs, labels) # 反向传播loss loss.backward() # 优化参数 optimizer.step() # 每100个迭代或者跑完一个epoch后,验证一下 if (index % 100 == 0 and index != 0) or index == len(self.config.train_loader) - 1: true = labels.data.cpu() # 预测数据 predict = outputs.data.cpu() # 计算训练准确度 R2 train_acc = r2_score(true, predict) # 计算验证准确度 R2 和 loss dev_acc, dev_loss, dev_mse = self.evaluate(model) # 查看验证loss是不是进步了 if dev_loss < dev_best_loss: dev_best_loss = dev_loss improve = '*' break_epoch = 0 else: improve = '' break_epoch += 1 time_dif = self.get_time_dif(start_time) # 输出阶段性结果 msg = 'Iter: {0:>6}, Train Loss: {1:>5.3}, Train R2: {2:>6.3}, Val Loss: {3:>5.3}, Val R2: {4:>6.3}, Val Mse: {5:>6.3}, Time: {6} {7}' print(msg.format(index, loss.item(), train_acc, dev_loss, dev_acc, dev_mse, time_dif, improve)) # 为了画图准备的,记录每个epoch的结果 if index == len(self.config.train_loader) - 1: acc_list[0].append(train_acc) acc_list[1].append(dev_acc) loss_list[0].append(loss.item()) loss_list[1].append(dev_loss) # 验证集评估时模型编程验证模式了,现在变回训练模式 model.train() # 20个epoch损失不变,直接退出训练 if break_epoch > 20: self.config.epoch = epoch+1 break # 测试 self.test(model) # 画图 self.draw_curve(acc_list, loss_list, self.config.epoch) def test(self, model): start_time = time.time() # 测试准确度 R2,测试损失,测试MSE test_acc, test_loss, mse = self.evaluate(model, test=True) msg = 'Test R2: {0:>5.3}, Test loss: {1:>6.3}, Test MSE: {2:>6.3}' print(msg.format(test_acc, test_loss, mse)) time_dif = self.get_time_dif(start_time) print("Time usage:", time_dif) def evaluate(self, model, test=False): # 模型模式变一下 model.eval() loss_total = 0 predict_all = np.array([], dtype=int) labels_all = np.array([], dtype=int) # 如果是测试模式(这一段写的不是很好) if test: with torch.no_grad(): for (dev, labels) in self.config.test_loader: outputs = model(dev) labels = labels.to(torch.float) loss = torch.nn.MSELoss()(outputs, labels) loss_total += loss labels = labels.data.cpu().numpy() predict = outputs.data.cpu().numpy() labels_all = np.append(labels_all, labels) predict_all = np.append(predict_all, predict) # 不是测试模式 else: with torch.no_grad(): for (dev, labels) in self.config.dev_loader: outputs = model(dev) labels = labels.long() loss = torch.nn.MSELoss()(outputs, labels) loss_total += loss labels = labels.data.cpu().numpy() predict = outputs.data.cpu().numpy() labels_all = np.append(labels_all, labels) predict_all = np.append(predict_all, predict) r2 = r2_score(labels_all, predict_all) mse = mean_squared_error(labels_all, predict_all) if test: return r2, loss_total / len(self.config.test_loader), mse else: return r2, loss_total / len(self.config.dev_loader), mse # 算时间损耗 def get_time_dif(self, start_time): end_time = time.time() time_dif = end_time - start_time return timedelta(seconds=int(round(time_dif))) # 画图 def draw_curve(self, acc_list, loss_list, epochs): x = range(0, epochs) y1 = loss_list[0] y2 = loss_list[1] y3 = acc_list[0] y4 = acc_list[1] plt.figure(figsize=(13, 13)) plt.subplot(2, 1, 1) plt.plot(x, y1, color="blue", label="train_loss", linewidth=2) plt.plot(x, y2, color="orange", label="val_loss", linewidth=2) plt.title("Loss_curve", fontsize=20) plt.xlabel(xlabel="Epochs", fontsize=15) plt.ylabel(ylabel="Loss", fontsize=15) plt.legend() plt.subplot(2, 1, 2) plt.plot(x, y3, color="blue", label="train_acc", linewidth=2) plt.plot(x, y4, color="orange", label="val_acc", linewidth=2) plt.title("Acc_curve", fontsize=20) plt.xlabel(xlabel="Epochs", fontsize=15) plt.ylabel(ylabel="Accuracy", fontsize=15) plt.legend() plt.savefig("images/"+self.config.name+"_Loss&acc.png")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
MLP_reg.py
import torch from torch.nn import Linear, ReLU, ModuleList, Sequential, Dropout, Softmax, Tanh import torch.nn.functional as F class MLP(torch.nn.Module): def __init__(self, input_n, output_n, num_layer=2, layer_list=[16, 8], dropout=0.5): super(MLP, self).__init__() self.input_n = input_n self.output_n = output_n self.num_layer = num_layer self.layer_list = layer_list self.input_layer = Sequential( Linear(input_n, layer_list[0], bias=False), ReLU() ) self.hidden_layer = Sequential() for index in range(num_layer-1): self.hidden_layer.extend([Linear(layer_list[index], layer_list[index+1], bias=False), ReLU()]) self.dropout = Dropout(dropout) self.output_layer = Sequential( Linear(layer_list[-1], output_n, bias=False), # ReLU() # Softmax(dim=1), ) def forward(self, x): input = self.input_layer(x) hidden = self.hidden_layer(input) hidden = self.dropout(hidden) output = self.output_layer(hidden) output = output.view(-1) return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2.3 结果
训练ing……

R2 有0.73。怎么说呢,还可以吧,不高不低。
拿 sklearn 默认的 MLP 才-2.7400039908485083,SVR才-0.15191155233964238。

曲线如下(感觉不是正常的曲线,训练集太飘了=> 也可能是epoch不到位)