
热门标签
热门文章
- 1python学习:zip文件_deflated lzma
- 2Bat脚本编写之Dos 基本操作命令_dos命令运行bat脚本怎么写
- 3Linux系统中常用的压缩、解压缩命令(tar、zip、gzip、bzip2、xz)_linux tar 压缩文件的时候忽略绝对路径 只压缩文件名
- 4WDS迁移注意事项
- 5香港高防服务器租用应该如何选择?
- 6Linux环境下Qt应用程序安装器(installer)制作_qtifw在linux中应用
- 7mysql数据库常用函数_使用mysql语句比较s1和s2两个字符串
- 8Go 工程化标准实践_go internal最佳实践
- 9理解RTF和RTX指标_asr rtf
- 10windows安装docker 异常解决_docker desktop requires windows 10 pro/enterprise/
当前位置: article > 正文
Python图像识别实战(四):搭建卷积神经网络进行图像二分类(附源码和实现效果)_pyhton 关于图像识别方面的代码案例
作者:AllinToyou | 2024-02-18 02:46:45
赞
踩
pyhton 关于图像识别方面的代码案例
前面我介绍了可视化的一些方法以及机器学习在预测方面的应用,分为分类问题(预测值是离散型)和回归问题(预测值是连续型)(具体见之前的文章)。
从本期开始,我将做一个关于图像识别的系列文章,让读者慢慢理解python进行图像识别的过程、原理和方法,每一篇文章从实现功能、实现代码、实现效果三个方面进行展示。
实现功能:
Python搭建卷积神经网络进行图像二分类
实现代码:
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
from collections import Counter
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import roc_auc_score
import itertools
from pylab import mpl
import seaborn as sns
class Solution():
#==================读取图片=================================
def read_image(self,paths):
os.listdir(paths)
filelist = []
for root, dirs, files in os.walk(paths):
for file in files:
if os.path.splitext(file)[1] == ".png":
filelist.append(os.path.join(root, file))
return filelist
#==================图片数据转化为数组==========================
def im_array(self,paths):
M=[]
for filename in paths:
im=Image.open(filename)
im_L=im.convert("L") #模式L
Core=im_L.getdata()
arr1=np.array(Core,dtype='float32')/255.0
list_img=arr1.tolist()
M.extend(list_img)
return M
def CNN_model(self,train_images, train_lables):
# ============构建卷积神经网络并保存=========================
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(128, 128, 1))) # 过滤器个数,卷积核尺寸,激活函数,输入形状
model.add(layers.MaxPooling2D((2, 2))) # 池化层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten()) # 降维
model.add(layers.Dense(64, activation='relu')) # 全连接层
model.add(layers.Dense(2, activation='softmax')) # 注意这里参数,我只有两类图片,所以是2.
model.summary() # 显示模型的架构
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
if __name__=='__main__':
Object1=Solution()
# =================数据读取===============
path1="D:\DCTDV2\dataset\\train\\"
test1 = "D:\DCTDV2\dataset\\test\\"
pathDir = os.listdir(path1)
pathDir=pathDir[1:5]
for a in pathDir:
path2=path1+a
test2=test1+a
filelist_1=Object1.read_image(path1+"Norm")
filelist_2=Object1.read_image(path2)
filelist_all=filelist_1+filelist_2
M=Object1.im_array(filelist_all)
train_images=np.array(M).reshape(len(filelist_all),128,128)#输出验证一下(400, 128, 128)
label=[0]*len(filelist_1)+[1]*len(filelist_2)
train_lables=np.array(label) #数据标签
train_images = train_images[..., np.newaxis] #数据图片
print(train_images.shape)#输出验证一下(400, 128, 128, 1)
# ===================准备测试数据==================
filelist_1T = Object1.read_image(test1+"Norm")
filelist_2T = Object1.read_image(test2)
filelist_allT = filelist_1T + filelist_2T
N = Object1.im_array(filelist_allT)
dict_label = {0: 'norm', 1: 'IgaK'}
test_images = np.array(N).reshape(len(filelist_allT), 128, 128)
label = [0] * len(filelist_1T) + [1] * len(filelist_2T)
test_lables = np.array(label) # 数据标签
test_images = test_images[..., np.newaxis] # 数据图片
print(test_images.shape) # 输出验证一下(100, 128, 128, 1)
# #===================训练模型=============
model=Object1.CNN_model(train_images, train_lables)
CnnModel=model.fit(train_images, train_lables, epochs=20)
# model.save('D:\电池条带V2\model\my_model.h5') # 保存为h5模型
# tf.keras.models.save_model(model,"F:\python\moxing\model")#这样是pb模型
# print("模型保存成功!")
# history列表
print(CnnModel.history.keys())
font = {'family': 'Times New Roman','size': 12,}
sns.set(font_scale=1.2)
plt.plot(CnnModel.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.savefig('D:\\DCTDV2\\result\\V1\\loss' + "\\" + '%s.tif' % a,bbox_inches='tight',dpi=600)
plt.show()
plt.plot(CnnModel.history['accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.savefig('D:\\DCTDV2\\result\\V1\\accuracy' + "\\" + '%s.tif' % a,bbox_inches='tight',dpi=600)
plt.show()
实现效果:
由于数据为非公开数据,仅展示几个图像的效果,有问题可以后台联系我。
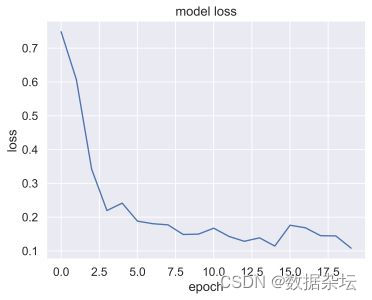
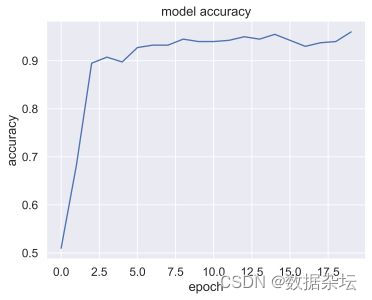
本人读研期间发表5篇SCI数据挖掘相关论文,现在在某研究院从事数据挖掘相关工作,对数据挖掘有一定的认知和理解,会不定期分享一些关于python机器学习、深度学习、数据挖掘基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
关注V订阅号:数据杂坛可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/103933
推荐阅读
相关标签

