
热门标签
热门文章
- 1深度学习毕设项目 深度学习实现行人重识别 - python opencv yolo Reid_yolo 行人重识别
- 2MySQL存储引擎及索引机制
- 3【Web开发】Vue+Springboot项目服务器部署(环境搭建+部署流程)_vue+springboot项目如何部署
- 4RxJava应用_rxjava使用
- 5Node isRunning函数_is_running
- 6Qt对excel操作_qaxobject是什么模块的
- 7Mac 开启局域网smb文件共享(附全平台连接方法)_mac samba
- 8JavaWeb毕设分享100个(四)_基于javaweb的毕业设计选题
- 9如何在windows下运行.sh文件_windows .sh
- 10Android中实现如win7里边屏幕保护图案中三维文字的效果。_android 立体字
当前位置: article > 正文
Python爬取数据分析_header = { 'origin':
作者:AllinToyou | 2024-02-18 16:16:42
赞
踩
header = { 'origin':
一.python爬虫使用的模块
1.import requests
2.from bs4 import BeautifulSoup
3.pandas 数据分析高级接口模块
二. 爬取数据在第一个请求中时, 使用BeautifulSoup
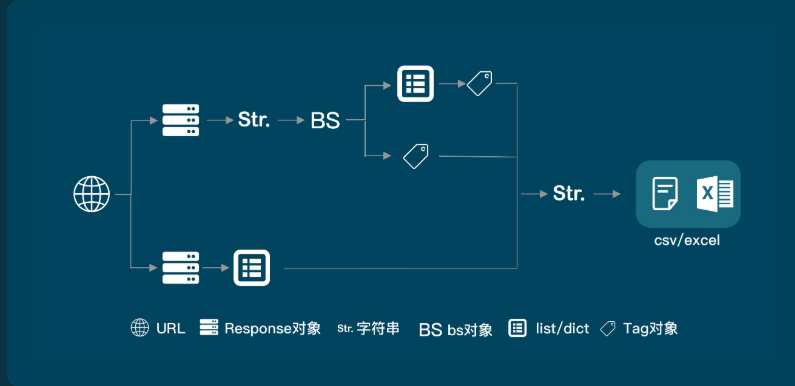
import requests
# 引用requests库
from bs4 import BeautifulSoup
# 引用BeautifulSoup库
res_movies = requests.get('https://movie.douban.com/chart')
# 获取数据
bs_movies = BeautifulSoup(res_movies.text,'html.parser')
# 解析数据
list_movies= bs_movies.find_all('div',class_='pl2')
# 查找最小父级标签
list_all = []
# 创建一个空列表,用于存储信息
for movie in list_movies:
tag_a = movie.find('a')
# 提取第0个父级标签中的<a>标签
name = tag_a.text.replace(' ', '').replace('\n', '')
# 电影名,使用replace方法去掉多余的空格及换行符
url = tag_a['href']
# 电影详情页的链接
tag_p = movie.find('p', class_=
推荐阅读
相关标签

