
- 1Python中的iter()与next()函数_calliter.__next__()
- 2Zabbix绘制流量拓扑图_zabbix 流量地图
- 3Anaconda3 下载安装及不同python环境配置(Linux/Windows)_如何下载到指定python版本的anaconda
- 4基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的智能监考系统(Python+PySide6界面+训练代码)
- 52022完整版:云计算面试题和答案(学习复习资料)_云计算售前面试
- 6pip换源命令(一行命令完成)
- 7Python打包exe和生成安装程序_python生产安装包
- 8Java项目:博客论坛管理系统(java+SpringBoot+JSP+LayUI+maven+mysql)_layui制作论坛列表带内容系统
- 9黑客爱用的HOOK技术大揭秘!_hook计算机是什么意思
- 10在 Java 中实现单例模式通常有两种方法_java两种单例创建
大汇总 | 9种基于神经辐射场NeRF的SLAM方法你都知道吗?
赞
踩
作者 | 秦通 编辑 | 算法邦
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【SLAM】技术交流群
后台回复【SLAM综述】获取视觉SLAM、激光SLAM、RGBD-SLAM等多篇综述!
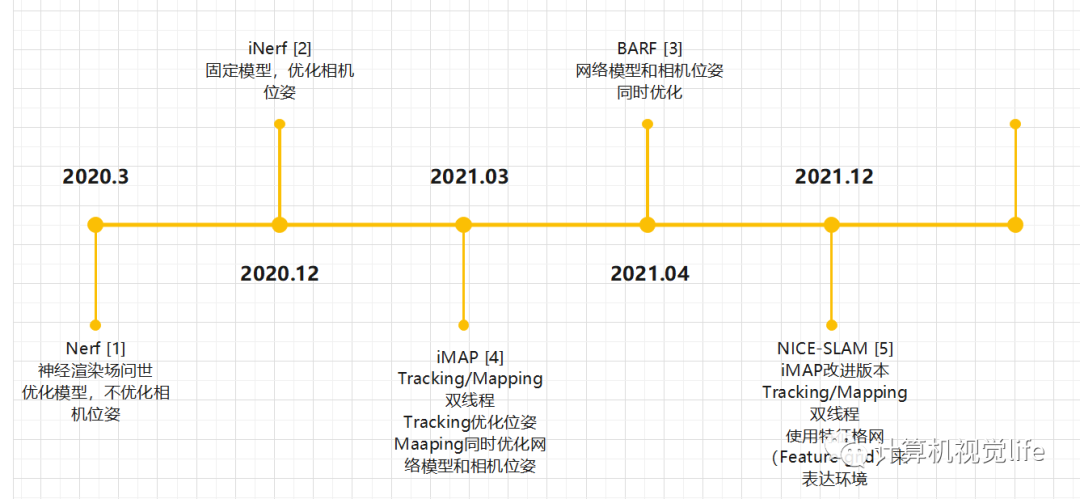
随着2020年NeRF[1]的横空出世,神经辐射场方法(Neural Radiance Fields)如雨后春笋般铺天盖地卷来。NeRF最初用来进行图像渲染,即给定相机视角,渲染出该视角下的图像。NeRF是建立在已有相机位姿的情况下,但在大多数的机器人应用中,相机的位姿是未知的。所以随后,越来越多的工作应用NeRF的技术同时估计相机位姿和对环境建模,即NeRF-based SLAM (Simultaneously localization and mapping)。
将深度学习与传统几何融合是SLAM发展的趋势。过去我们看到SLAM中一些单点的模块,被神经网络所替代,比如特征提取(super point), 特征匹配(super glue),回环(NetVlad)和深度估计(mono-depth)等。相比较单点的替代,NeRF-based方法是一套全新的框架,可以端到端的替代传统SLAM,无论是在设计方法还是实现架构上。
相较于传统SLAM,NeRF-based 的方法,优点在于:
没有特征提取,直接操作原始像素值。误差回归到了像素本身,信息传递更加直接,优化过程所见即所得。
无论是隐式还是显式的map表达都可以进行微分,即可以对map进行full-dense优化 (传统SLAM基本无法优化dense map,通常只能优化有限数量的特征点或者对map进行覆盖更新)
由此可见,NeRF-based的方法上限极高,可以对map进行非常细致的优化。但这类方法缺点也很明显:
计算开销较大,优化时间长,难以实时。
但无法实时也只是暂时性的问题,后续会有大量的工作,来解决NeRF-based SLAM实时性的问题。
SLAM学术界的泰斗,Frank Dallaert(https://dellaert.github.io/),gtsam的作者,也开始转行研究NeRF,可见NeRF的价值和对视觉SLAM的意义。Frank大佬写了一系列NeRF相关文章的综述。
https://dellaert.github.io/NeRF/
https://dellaert.github.io/NeRF21/
https://dellaert.github.io/NeRF22/
由于NeRF方向博大精深,文章众多,我重点挑选SLAM方向,结合自己粗浅的理解,总结一下NeRF-based SLAM工作。该领域发展较快,文章持续更新中... (有遗漏的经典工作请在评论区提醒补充)
首先是一张框架图,梳理了这几篇工作各自的创新点和之间的关联关系,帮助大家有个宏观上的概念。[2][3][4][5]是和SLAM有关的工作,[6][8]和[7][9]分别是渲染加速和训练加速的工作,与SLAM无直接关系,但其加速的部分可能被SLAM用到。
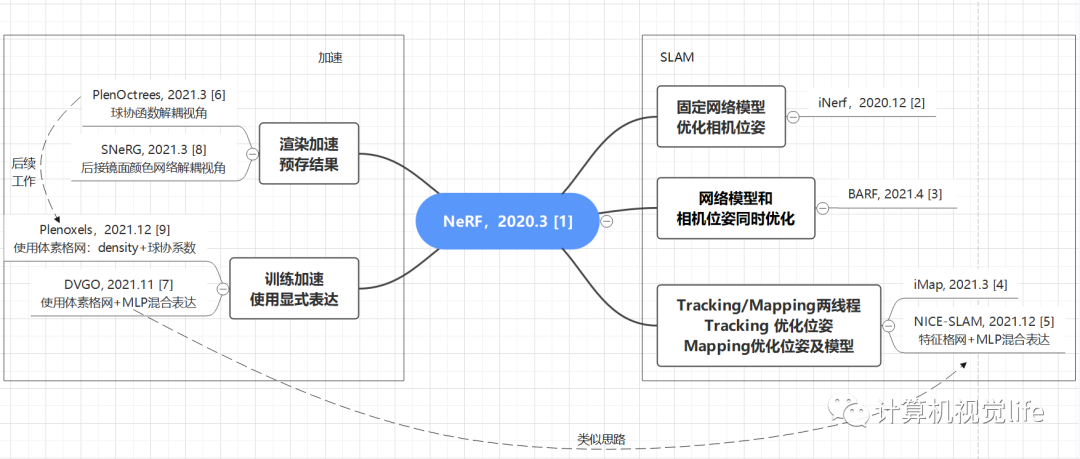
几篇Nerf-based SLAM工作的时间线:
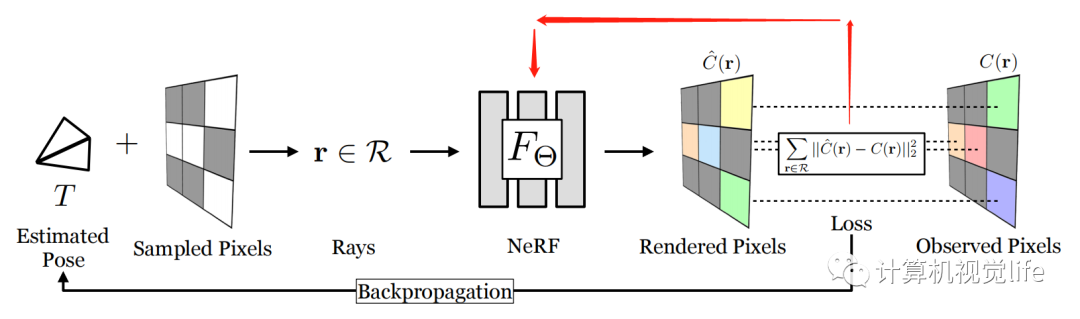
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. 2020.03 [1]

首先还是回顾一下经典的NeRF。NeRF选取一系列图片,这些图片的位姿已知。对像素射线上的点进行采样,每条射线采样几十个点(x,y,z,theta,phi),送入MLP网络(F_theta)。网络预测出该采样点的RGB和density(sigma)。再对射线上的点做辐射积分,得到该像素点的RGB值,和真值计算loss,梯度反传训练网络(F_theta)。该方法的优化的变量是MLP网络参数(F_theta),即场景表达隐含在网络当中。对相机的位姿不进行优化调整。
iNeRF: Inverting Neural Radiance Fields for Pose Estimation. 2020.12 [2]
iNeRF是第一个提出用NeRF model来做位姿估计的工作。iNeRF依赖一个已经提前建好的NeRF模型,F_theta。所以iNeRF并不算SLAM,而是一个已有模型下的重定位问题。和NeRF的区别在与,NeRF固定位姿,优化模型,loss反传到F_theta(如图红线所示);iNeRF固定模型,优化位姿,loss反传到pose 。
BARF : Bundle-Adjusting Neural Radiance Fields. 2021.04 [3]
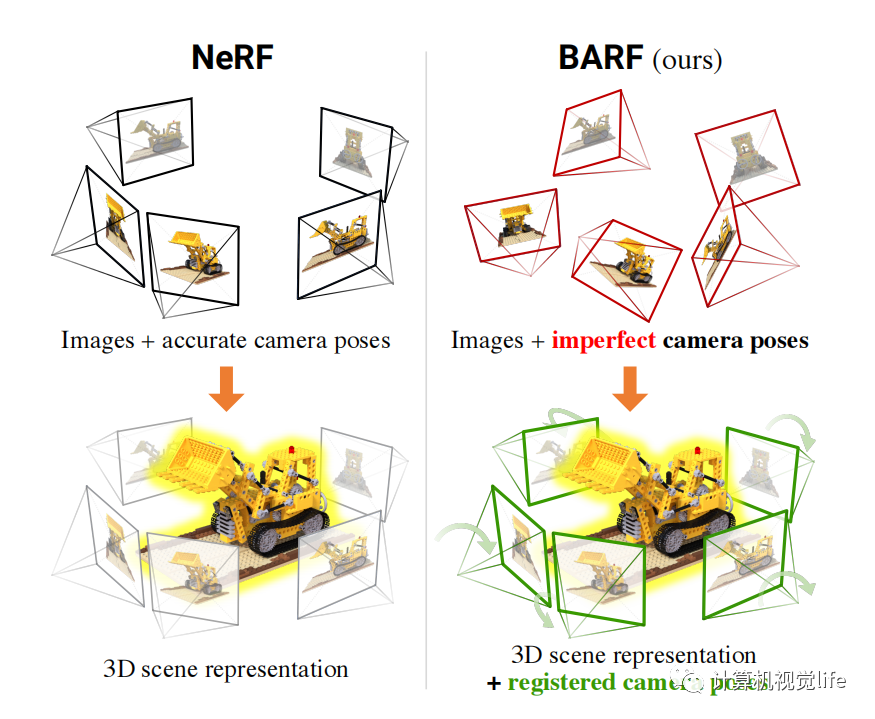
BARF这边篇文章同时优化网络模型和相机位姿,用神经渲染网络的方法实现了Bundle Adjustment。确切的说,该方法解决的是SfM (structure from motion)问题。该方法依赖一个粗糙的相机初始位姿,这个位姿可以通过col map等方法获得。通过网络迭代对模型和相机位姿进行精修。如果引入时序和帧间tracking,这将是一个不错的slam工作。
iMAP: Implicit Mapping and Positioning in Real-Time, 2021.03 [4]
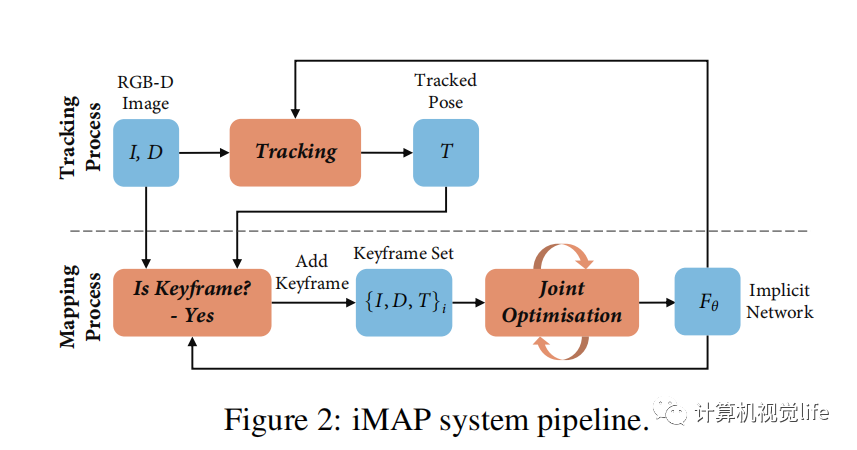 iMAP是真正意义上第一个NeRF-based SLAM 工作。iMAP使用的RGB-D图片,分为Tracking和Mapping两个线程。Tracking线程使用当前的模型,F_theta, 优化当前的相机位姿;判断该帧是不是关键帧,如果是关键帧,则关键帧的位姿和模型F_theta一同优化。iMAP的框架和传统SLAM类似,但核心的tracking和联合优化都有神经网络优化来完成。遗憾的是iMAP并未开源,但好消息是后面的工作nice-slam把iMAP的实现一同开源出来了。
iMAP是真正意义上第一个NeRF-based SLAM 工作。iMAP使用的RGB-D图片,分为Tracking和Mapping两个线程。Tracking线程使用当前的模型,F_theta, 优化当前的相机位姿;判断该帧是不是关键帧,如果是关键帧,则关键帧的位姿和模型F_theta一同优化。iMAP的框架和传统SLAM类似,但核心的tracking和联合优化都有神经网络优化来完成。遗憾的是iMAP并未开源,但好消息是后面的工作nice-slam把iMAP的实现一同开源出来了。
NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. 2021.12 [5]
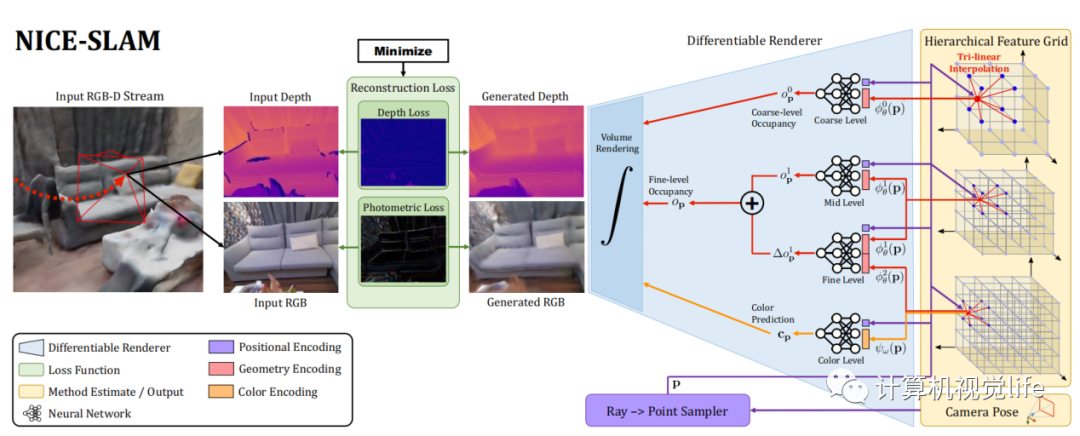 NICE-SLAM在iMAP的基础上做改动,作者不仅开源了自己这部分,也把iMAP的实现开源了出来。作者的主要改动是使用了特征格网(Feature Grid)+MLP这种显式+隐式混合的方法来表达环境。环境信息放在体素特征格网内,MLP作为decorder,将特征格网内蕴含的信息解码成occupancy和rgb。同时,作者还用了course-to-fine的思想,将特征格网分成粗、中和精细,以便更细致的表达。该方法比iMAP快了2-3倍,虽然具备了一定的实时性,但真正用起来还是离实时有一些距离。这是当前看到的最好、最完善的NeRF-based SLAM工作。
NICE-SLAM在iMAP的基础上做改动,作者不仅开源了自己这部分,也把iMAP的实现开源了出来。作者的主要改动是使用了特征格网(Feature Grid)+MLP这种显式+隐式混合的方法来表达环境。环境信息放在体素特征格网内,MLP作为decorder,将特征格网内蕴含的信息解码成occupancy和rgb。同时,作者还用了course-to-fine的思想,将特征格网分成粗、中和精细,以便更细致的表达。该方法比iMAP快了2-3倍,虽然具备了一定的实时性,但真正用起来还是离实时有一些距离。这是当前看到的最好、最完善的NeRF-based SLAM工作。
--------------------------渲染加速----------------------------
PlenOctrees for Real-time Rendering of Neural Radiance Fields, 2021.03 [6]
 PlenOctrees是一种对渲染加速的方法。加速的方法是训练好mlp这种隐式表达之后,将空间中所有点以及所有视角观察都放到网络中推理,保存记录下来。这样下次使用时,就不必在线使用网络推理,查找表即可,加快渲染速度。但由于网络输入有x,y,z,theta,phi五个自由度,穷举起来数量爆炸。所以作者改造网络,将视角theta,phi从网络输入中解耦出来。网络只输入x,y,z,输出density和球协系数。颜色通过视角乘以球协函数得到。这样网络变量的自由度从5下降到3,可以进行穷举保存。
PlenOctrees是一种对渲染加速的方法。加速的方法是训练好mlp这种隐式表达之后,将空间中所有点以及所有视角观察都放到网络中推理,保存记录下来。这样下次使用时,就不必在线使用网络推理,查找表即可,加快渲染速度。但由于网络输入有x,y,z,theta,phi五个自由度,穷举起来数量爆炸。所以作者改造网络,将视角theta,phi从网络输入中解耦出来。网络只输入x,y,z,输出density和球协系数。颜色通过视角乘以球协函数得到。这样网络变量的自由度从5下降到3,可以进行穷举保存。
SNeRG:Baking Neural Radiance Fields for Real-Time View Synthesis, 2021.03 [8]
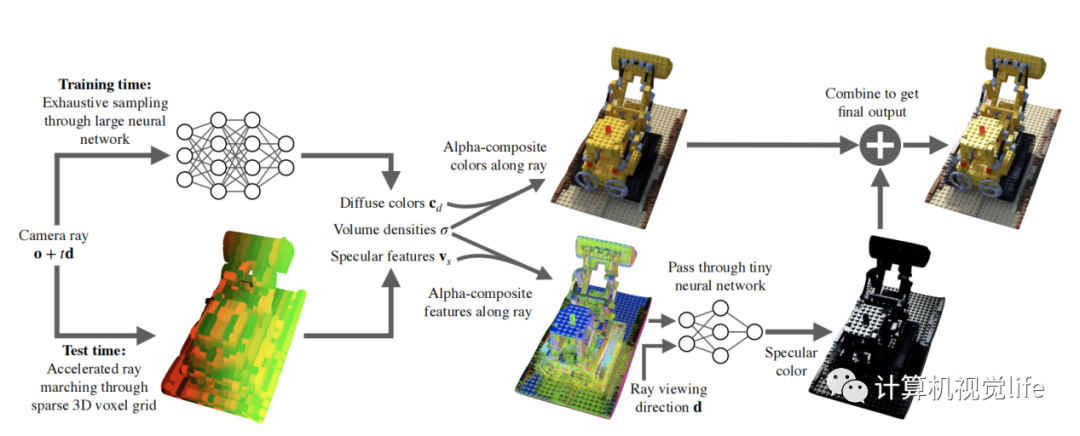 SNeRG和PlenOctrees类似,都是一种加速渲染的方法。Mlp训练好后,把与视角独立的信息存入3D体素格网内。在这篇文章中,作者把颜色分成固有颜色和镜面颜色,固有颜色与观察视角无关。网络输入3d坐标位置,输出体素密度,固有颜色,和镜面颜色特征向量。镜面颜色特征向量在通过一个小的网络,结合视角,解码成镜面颜色,加到最终的颜色上。与PlenOctrees一样,主干mlp网络都与视角解耦。PlenOctrees通过球协函数恢复视角颜色,SNeRG通过后接一个小网络恢复镜面颜色,在叠加到固有颜色上。
SNeRG和PlenOctrees类似,都是一种加速渲染的方法。Mlp训练好后,把与视角独立的信息存入3D体素格网内。在这篇文章中,作者把颜色分成固有颜色和镜面颜色,固有颜色与观察视角无关。网络输入3d坐标位置,输出体素密度,固有颜色,和镜面颜色特征向量。镜面颜色特征向量在通过一个小的网络,结合视角,解码成镜面颜色,加到最终的颜色上。与PlenOctrees一样,主干mlp网络都与视角解耦。PlenOctrees通过球协函数恢复视角颜色,SNeRG通过后接一个小网络恢复镜面颜色,在叠加到固有颜色上。
--------------------------训练加速----------------------------
DVGO: Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction. 2021.11 [7]
 DVGO提出了对网络训练进行加速的方法。作者发现,使用MLP这种隐式表达,训练速度慢但效果好;使用体素格网这种显式表达,速度快但效果差。所以DVGO提出了混合的体素格网的表示方法。对于占据密度(density),直接使用体素格网,插值就可以得到任何位置的占据密度;对于颜色,体素格网里面存储多维向量,多维向量先经过插值,后经过MLP解码成rgb值。这样网络在训练过程中,用到MLP的次数减少;MLP只翻译颜色,也可以做的很轻量化,所以训练速度大幅提升。
DVGO提出了对网络训练进行加速的方法。作者发现,使用MLP这种隐式表达,训练速度慢但效果好;使用体素格网这种显式表达,速度快但效果差。所以DVGO提出了混合的体素格网的表示方法。对于占据密度(density),直接使用体素格网,插值就可以得到任何位置的占据密度;对于颜色,体素格网里面存储多维向量,多维向量先经过插值,后经过MLP解码成rgb值。这样网络在训练过程中,用到MLP的次数减少;MLP只翻译颜色,也可以做的很轻量化,所以训练速度大幅提升。
Plenoxels: Radiance Fields without Neural Networks. 2021.12 [9]
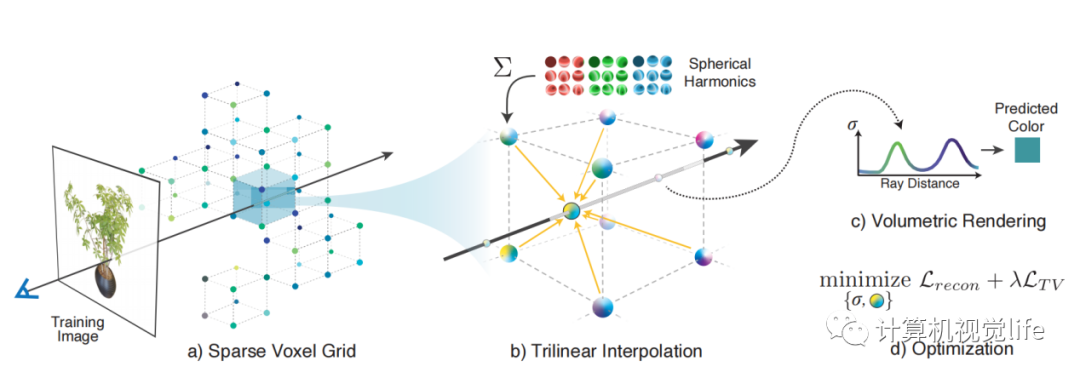 Plenoxels 是PlenOCtrees的后续工作。作者使用显式的格网来代替MLP。格网里面存储一维的density和球协系数。当有光线经过时,光线上的采样点的density和球协系数可由三线性插值得到。这样整个过程就摆脱了对神经网络的依赖,变成了完全显式的表达。由于去掉了神经网络MLP部分,训练速度大幅增加。作者强调神经辐射场的关键不是在于神经网络,而是在于可微分的渲染过程。
Plenoxels 是PlenOCtrees的后续工作。作者使用显式的格网来代替MLP。格网里面存储一维的density和球协系数。当有光线经过时,光线上的采样点的density和球协系数可由三线性插值得到。这样整个过程就摆脱了对神经网络的依赖,变成了完全显式的表达。由于去掉了神经网络MLP部分,训练速度大幅增加。作者强调神经辐射场的关键不是在于神经网络,而是在于可微分的渲染过程。
[1]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. 2020.03
[2]iNeRF: Inverting Neural Radiance Fields for Pose Estimation. 2020.12
[3]BARF : Bundle-Adjusting Neural Radiance Fields. 2021.04
[4]iMAP: Implicit Mapping and Positioning in Real-Time. 2021.03
[5]NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. 2021.12
[6]PlenOctrees for Real-time Rendering of Neural Radiance Fields. 2021.03
[7]Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction.2021.11
[8]Baking Neural Radiance Fields for Real-Time View Synthesis. 2021.03
[9]Plenoxels: Radiance Fields without Neural Networks. 2021.12

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

