
- 1rust OJ实战
- 2postman测试接口各种类型传值_postman传值
- 3CNN实现花卉图片分类识别_基于cnn的花卉识别
- 4消息认证码--数字签名--证书_ipv4消息认证码
- 5SpringBoot--什么是RPC_springboot rpc
- 6【AI绘画工具分别有哪些?】
- 7斯坦福CS193U-虚幻4C++课程学习笔记(14)_虚幻4 bindufunction
- 8【Python入门系列】第十八篇:Python自然语言处理和文本挖掘_python 文字挖掘
- 9六个思考维度:DDD + SpringBoot工程九层结构图解与实战_springboot项目结构图
- 10面向端到端自动驾驶的稀疏感知通用架构探索_pv-based cross-attention
多目标跟踪算法,零基础极速入门(一)_vitbat
赞
踩
目前为止,我们已经推出了《从零开始学习 深度学习》和《从零开始学习模型部署》系列教程,方便大家入门算法开发。
欢迎大家进抠抠裙:
deeplearningYYDS裙3:1015081610
威信裙需先jia个人威信:deeplearningYYDS 经审核后进入。
话不多说,进入实操:
一、首先说多目标跟踪
多目标跟踪处理的对象是视频,从视频的第一帧到最后一帧,里边有多个目标在不断运动。多目标跟踪的目的就是将每个目标和其他目标进行区分开来,具体方法是给每个目标分配一个 ID,并记录他们的轨迹。
刚开始接触,可能觉得直接将目标检测的算法应用在视频的每一帧就可以完成这个任务了。实际上,目标检测的效果是很不稳定的,其实最大的区别在于,仅仅使用目标检测无法给对象分配 ID,并且跟踪能够优化整个跟踪过程,能让目标框更加稳定。
多目标跟踪中一个比较经典的和深度学习结合比较好的方法就是 DetectionBased Tracking,对前后两帧进行目标检测检测,然后根据得到的前后两帧的所有目标进行匹配,从而维持 ID。初学者接触比较多的就是 SORT 和 Deep SORT。
二、MOT16 数据集
MOT16 数据集是在 2016 年提出来的用于衡量多目标跟踪检测和跟踪方法标准的数据集,专门用于行人跟踪。官网地址是:https://motchallenge.net/
从官网下载的数据是按照以下的文件结构进行组织的:


在 MOT16 数据集中,是包含了检测得到的框的,这样是可以免去目标检测这个部分,提供统一的目标检测框以后,然后可以比较目标跟踪更关注的部分,而不用在花费精力在目标检测上。
- seqinfo.ini
在每个子文件夹中都有这个,主要用于说明这个文件的一些信息,比如长度,帧率,图片的长和宽,图片的后缀名。

- det.txt
这个文件中存储了图片的检测框的信息 (检测得到的信息文件),部分内容展示如下:

从左到右分别代表:
• frame: 第几帧图片
• id: 这个检测框分配的 id,在这里都是-1 代表没有 id 信息
• bbox(四位): 分别是左上角坐标和长宽
• conf:这个 bbox 包含物体的置信度,可以看到并不是传统意义的 0-1,分数越高代表置信度越高• MOT3D(x,y,z): 是在 MOT3D 中使用到的内容,这里关心的是 MOT2D,所以都设置为-1可以看出以上内容主要提供的和目标检测的信息没有区别,所以也在一定程度上可以用于检测器的训练。 - gt.txt
这个文件只有 train 的子文件夹中有,test 中没有,其中内容的格式和 det.txt 有一些类似,部分内容
如下:

从左到右分别是:
• frame: 第几帧图片
• ID: 也就是轨迹的 ID,可以看出 gt 里边是按照轨迹的 ID 号进行排序的
• bbox: 分别是左上角坐标和长宽
• 是否忽略:0 代表忽略
• classes: 目标的类别个数(这里是驾驶场景包括 12 个类别),7 代表的是静止的人。
第 8 个类代表错检,9-11 代表被遮挡的类别

• 最后一个代表目标运动时被其他目标包含、覆盖、边缘裁剪的情况。
总结:
• train 中含有的标注信息主要来自 det.txt 和 gt.txt。test 中只含有 det.txt。
• det.txt 含有的有用信息有:frame, bbox, conf
• gt.txt 含有的有用信息有:frame,bbox, conf, id, class
• output.txt(使用 deepsort 得到的文件) 中含有的有用信息有:frame,bbox, id - MOT 中的评价指标

评价出发点:
• 所有出现的目标都要及时能够找到;
• 目标位置要尽可能与真实目标位置一致;
• 每个目标都应该被分配一个独一无二的 ID,并且该目标分配的这个 ID 在整个序列中保持不变。
评价指标数学模型:评价过程的步骤:
1)建立目标与假设最优间的最优一一对应关系,称为 correspondence
2)对所有的 correspondence,计算位置偏移误差
3)累积结构误差 a. 计算漏检数 b. 计算虚警数(不存在目标却判断为目标)c. 跟踪目标发生跳变的次数

MOTA(Multiple Object Tracking Accuracy)
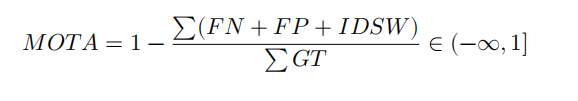
FN 为 False Negative, FP 为 False Positve, IDSW 为 ID Switch, GT 是 Ground Truth 物体的数量。
MOTA 主要考虑的是 tracking 中所有对象匹配错误,主要是 FP,FN,IDs. MOTA 给出的是非常直观的衡量跟踪其在检测物体和保持轨迹时的性能,与目标检测精度无关。
MOTA 取值小于 100,但是当跟踪器产生的错误超过了场景中的物体,MOTA 可以变为负数。
ps: MOTA&MOTP 是计算所有帧相关指标后再进行平均的,不是计算每帧的 rate 然后进行 rate 平均。
MOTP(Multiple Object Tracking Precision)
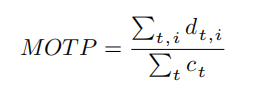
d 为检测目标声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/176040
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

