
- 1spring-boot-maven-plugin:介绍_lib-provided
- 2扩展卡尔曼滤波与粒子滤波例程
- 3postgresql 查找慢sql之二: pg_stat_statements_可以使用pg_stat_statements去查询运行时间长的sql语句。
- 4智能音响蓝牙调试经验_ap6212 pcm接口
- 5往linux内核函数挂钩子_linux内核任务切换时增加钩子函数
- 6c#如何根据时间戳校验本地系统时间_c#怎么获取被人修改了系统时间
- 7挑战UnityShader学习之三_工欲善其事必先利其器Standard面板详细解析和代码自定义_unity的standard
- 8chart.js使用学习——饼图/环形图_js chart.js绘制饼图
- 9Blob 下载类型 type 大全_blob.type
- 10Unity的粒子系统的界面官方手册英文翻译+使用注意知识_size by speed ue4中文
Transformer——decoder
赞
踩
上一篇文章,我们介绍了encoder,这篇文章我们将要介绍decoder
Transformer-encoder
decoder结构:
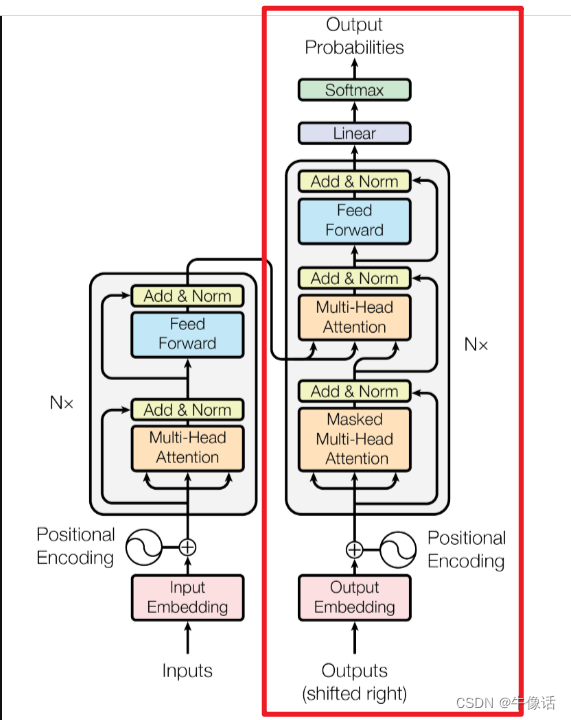
如果看过上一篇文章的同学,肯定对decoder的结构不陌生,从上面框中可以明显的看出:
-
每个Decoder Block有两个Multi-Head Attention层
-
第一个Multi-Head Attention层采用了Masked操作,所以叫多头掩码注意力模块
-
第二个Multi-Head Attention就是和encoder的一样,不过他的K、V矩阵输入源来自Encoder的输出编码矩阵,而Q矩阵是由多头掩码注意力层,经过Add &Norm层之后的输出计算来的
-
Add &Norm,和前面encoder的一样
-
feed forward,它包含一个全连接层,对输入特征进行非线性变换,并产生输出。在训练过程中,Feed Forward会根据损失函数的梯度进行参数更新,以优化模型的性能。他的输入层参数和Embedding的维度一样。
-
Linear,是一种简单的神经网络组件,通常用于处理线性可分的问题。它包含一个全连接层和一个激活函数,对输入进行线性变换,并产生输出。与Feed Forward不同,Linear在训练过程中不会根据损失函数的梯度进行参数更新,因为它的输出取决于输入的线性组合。Linear的长度,实际上就是你词向量的种类数量。
-
softMax,把linear的输出做分类概率运算,算出每种词向量的概率。
这里我们详细说一下多头掩码注意力模块,其他的和encoder中都一样,就不详细介绍了。
Masked Multi-Head Attention
在下面第9点介绍多头掩码注意力
在介绍之前,我们先来说一下transformer的训练过程,网上搜了很多,没有找到谁具体讲过,所以我就借助“文心一言”来进行了询问,大概了解了这个过程,但是不能保证正确,如果有知道同学看到了,欢迎给我留言。
-
先有encoder的输入“你好吗”(也就是问题)和decoder的输入“好的很”(也就是答案)。
-
把encoder的输入“你好吗”输入encoder中,把“你好吗“转化为Embedding,然后对Embedding添加position信息,decoder也同理。
-
把添加了pos的Em,做成6组QKV,那么总共就是18个QKV,然后每组都送入一个注意力模块,总共有6组注意力模块,这6组就称为多头注意力模块,然后把这6组的输出经过一个conact和Linear(具体可以看上一篇文章)合并后输出,这个输出就是注意力矩阵。
-
把注意力矩阵经过残差链接和归一化后,放入一个Feed Forward中后再使用一次残差链接和归一化,encoder的输出就有了。
-
接下来我们看decoder的输入,在transformer的训练中,我们使用的是Teacher Forcing方法,我们是告诉了transformer正确的答案是什么的,也就是“好得很”。
-
首先decoder会把encoder的输入做成QK,然后放入一个多头注意力模块中,接下来一直到Linear的操作,和encoder的一样。
-
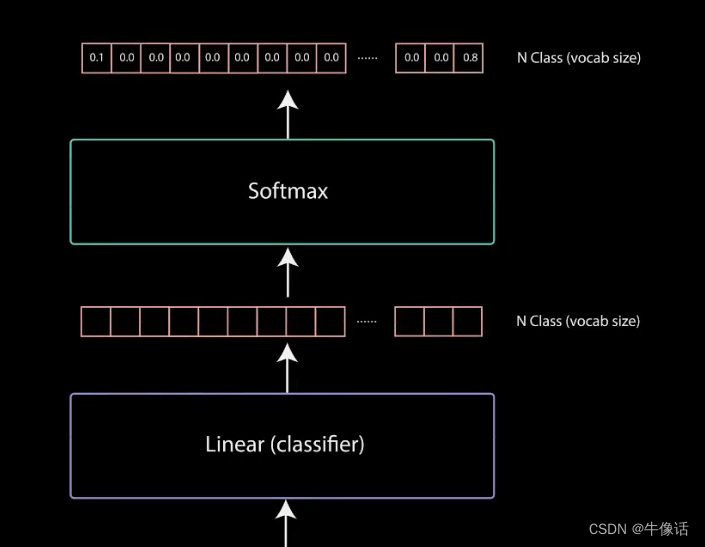
decoder中的Linear输入的方法和encoder的一样,可以参考上篇文章最后,不过linear的输出,是把所有的向量数据库中的数据给输出出来,最后是使用了softmax做分类器。从下图可以看出,Linear的输出,是和你的词向量类别有关,假设你的词向量类别有1w个,那么这里就会输出1w的类别,如下图
 然后使用softMax对着些输出做概率计算,就可以算出概率最大的词向量是哪个,softMax的计算,可以参考我的BP神经网络,大概方式类似于下面
然后使用softMax对着些输出做概率计算,就可以算出概率最大的词向量是哪个,softMax的计算,可以参考我的BP神经网络,大概方式类似于下面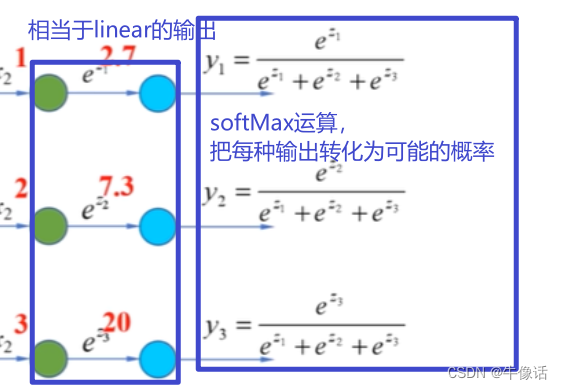
-
假如现在经过softMax的运算后,最大概率的字是"好",那么就把这个字和标准答案中的"好得很"对比一下,如果不是"好"字,那么就使用梯度下降法,反向去更新两个Feed forward和所有的QKV,更新完后回到decoder输入。
-
接下来把标准答案中的“好”直接输入到decoder的输入,下面是带有掩码的多头注意力
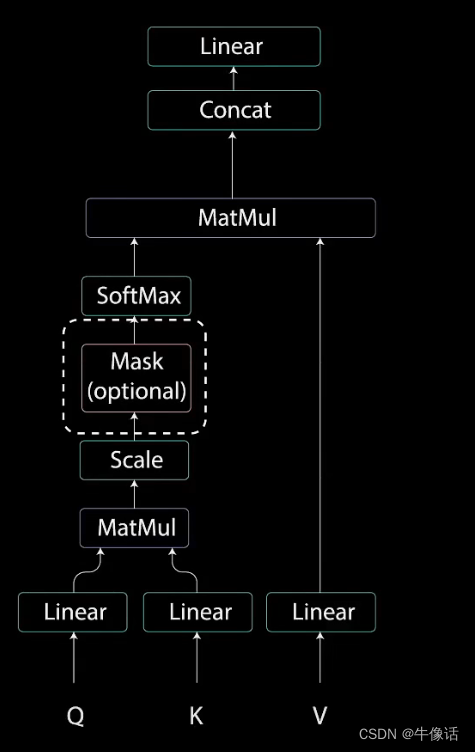
经过EM+pos,还有QKV后,我们把他输入了多头掩码注意力模块,这里为什么要加个掩码呢?掩码又是什么呢?我们看下面这张图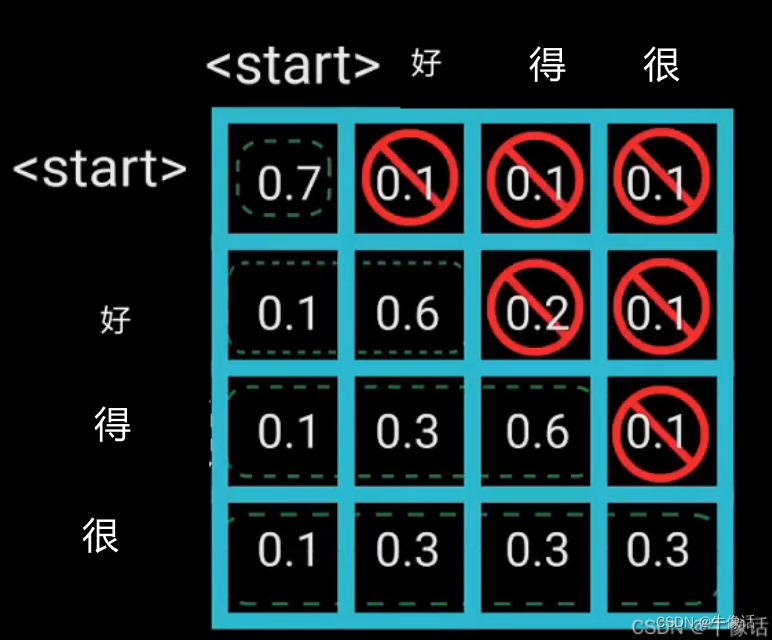
我们需要把"好"字加入到”你好吗”的后面,但是我们又不能让多头注意到“好”字后面“得很”,所以我们就需要把后面的字给遮起来,这个就是掩码。经过softMax的变化,可以看到下图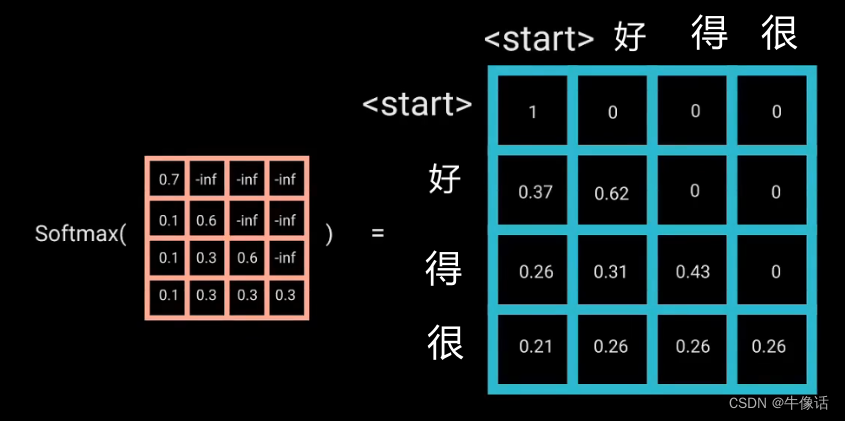
比如“好”字,后面的“得很”,都是0,说明好字只和前面的内容有关系,则接下来就是“好”字的[0.37,0.62,0,0]作为多头掩码的输出,也可以抽象的看成,是把“好”拼在了“你好吗”的后面,但是其实是“你好吗”作为QK,"好"作为V。 -
接下来就和上面的3一样,一直到softMax做出预测,如果是预测的不是“尼”,就反向更新梯度下降,如果是“尼”,则把“好尼”送入多头掩码中,然后把“好尼”拼在“你好吗”的后面。一直循环到softMax预测到结束标志。

