
- 1正交试验法用例设计_正交试验设计
- 2【雕爷学编程】Arduino智能家居之使用Arduino Uno和ESP32模块连接到WiFi网络_esp32devkv1 aduno
- 3拉取Docker镜像时提示 no space left on device 问题解决_you're not using the default seccomp profile
- 4Python的核心知识点整理大全66(已完结撒花)
- 5【OpenCV--视频文件相关操作】_cap.read()
- 6C语言中putchar()函数的使用
- 7Object Detection︱RCNN、faster-RCNN框架的浅读与延伸内容笔记_rcnn进化
- 8基于PyTorch机器学习与深度学习实践应用与案例分析_基于pytorch编写的利用深度强化学习解决任务卸载和边缘计算问题
- 9flutter text 左对齐_flutter中行(Row)子控件设置间距和左右对齐
- 10css为透明图片设置阴影_css图片透明底阴影
OpenCV与机器学习:使用opencv和sklearn实现线性回归
赞
踩
前言
线性回归是一种统计分析方法,用于确定两种或两种以上变量之间相互依赖的定量关系。在统计学中,线性回归利用线性回归方程(最小二乘函数)对一个或多个自变量(特征值)和因变量(目标值)之间的关系进行建模。
线性回归主要分为一元线性回归和多元线性回归。一元线性回归涉及两个变量,其关系可以用一条直线近似表示。而多元线性回归则涉及两个或两个以上的自变量,因变量和自变量之间是线性关系。线性回归的目标是找到一个数学公式,能够尽可能完美地组合所有自变量,以接近目标值。
线性回归
生成数据
一般来说我们会借助sklearn当中的linear_model来实现线性回归,我们首先生成一个可以用于线性回归的数据。
import numpy as np
x = np.linspace(0, 10, 100)
y_hat = x * 5 + 5
np.random.seed(42)
y = x * 5 + 20 * (np.random.rand(x.size) - 0.5) + 5
- 1
- 2
- 3
- 4
- 5
- 6
其中x是数据,而y_hat是我们希望回归得到的回归值(由于这里是自己生成数据,所以这个值我们是知道的,处理现实问题时,这个值我们一般是不知道的)。y是采用随机数生成的用于训练的标签值,我们通过x和y进行线性回归,最终目的是回归出y_hat。
画图展示数据
为了更好的展现效果,下面我们使用matplotlib画一下图
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(10, 6))
plt.plot(x, y_hat, linewidth=4)
plt.plot(x, y, 'x')
plt.xlabel('x')
plt.ylabel('y')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
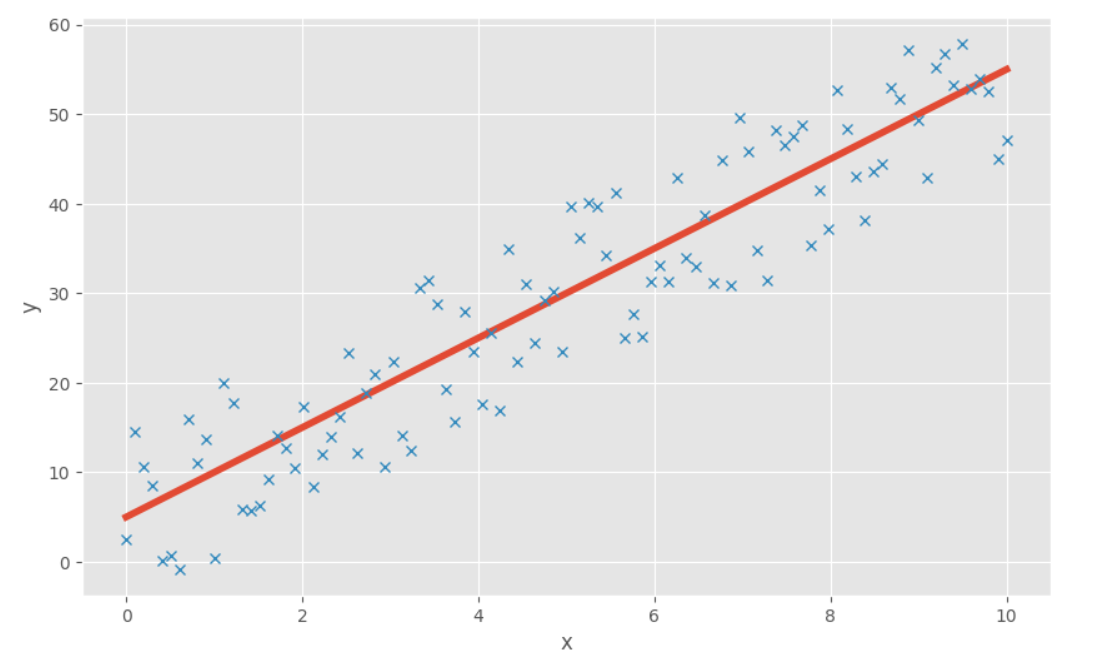
其中蓝色的点代表的就是数据,而红色的直线就是我们经过线性回归应当得到的结果(最终结果有可能会有些偏差,但一般和这条红线相近)
划分数据并训练
依旧是借助sklearn中的model_selection.train_test_split对数据集进行划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
- 1
- 2
- 3
使用sklearn进行回归
使用sklearn的训练十分的简单,如果熟悉sklearn可以发现,这个过程非常符合sklearn的使用风格。
from sklearn import linear_model
linreg = linear_model.LinearRegression()
linreg.fit(x_train.reshape(-1, 1), y_train.reshape(-1, 1))
y_sklearn = linreg.predict(x.reshape(-1, 1))
- 1
- 2
- 3
- 4
- 5
- 6
使用OpenCV进行回归
我们可以借助cv2.fitLine用一条线拟合。该函数可以取下列参数:
points:这是一条直线必须拟合的点集。
distType:这是M-估计所使用的距离。
param:这是数值参数(C),用于某些类型的距离。我们将
其保持为0,这样就可以选择一个最优值。
reps:这是原点到直线的距离准确率。0.01是reps的一个不错的
默认值。
aeps:这是角度的准确率。0.01是aeps的一个不错的默认值。
我们以distTypeOptions来暂存distType可以取的各种参数。
import cv2
distTypeOptions = [cv2.DIST_L2,\
cv2.DIST_L1,\
cv2.DIST_L12,\
cv2.DIST_FAIR,\
cv2.DIST_WELSCH,\
cv2.DIST_HUBER
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
为了更加方便的观察不同参数的不同效果,我们直接设置参数后拟合并显示。distTypeLabels对应的就是不同参数的图例,用于标识使用的参数,colors则是设置显示的颜色,points是通过列表推导的方式获得数据和标签相匹配的一对对元组。
distTypeLabels = ['DIST_L2', 'DIST_L1', 'DIST_L12',
'DIST_FAIR', 'DIST_WELSCH','DIST_HUBER']
colors = ['g', 'c', 'm', 'y', 'k', 'b']
points = np.array([(xi, yi) for xi, yi in zip(x_train, y_train)])
- 1
- 2
- 3
- 4
- 5
cv2.fitLine并没有直接用于预测的函数,返回的是[vxl, vyl, xl, yl],通过计算才可以得出预测结果。
plt.figure(figsize=(10, 6))
plt.plot(x, y_hat, linewidth=2, label='Ideal')
plt.plot(x, y, 'x', label='Data')
for i in range(len(colors)):
distType = distTypeOptions[i]
distTypeLabel = distTypeLabels[i]
c = colors[i]
[vxl, vyl, xl, yl] = cv2.fitLine(np.array(points, dtype=np.int32), distType, 0, 0.01, 0.01)
y_cv = [vyl[0]/vxl[0] * (xi -xl[0]) + yl[0] for xi in x]
plt.plot(x, y_cv, c=c, linewidth=2, label=distTypeLabel)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
随后我们也将sklearn的图像画上去,进行对比
y_sklearn = list(y_sklearn.reshape(1, -1)[0])
plt.plot(x, list(y_sklearn), c='0.5', linewidth=2, label='Scikit-Learn API')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc='upper left')
- 1
- 2
- 3
- 4
- 5
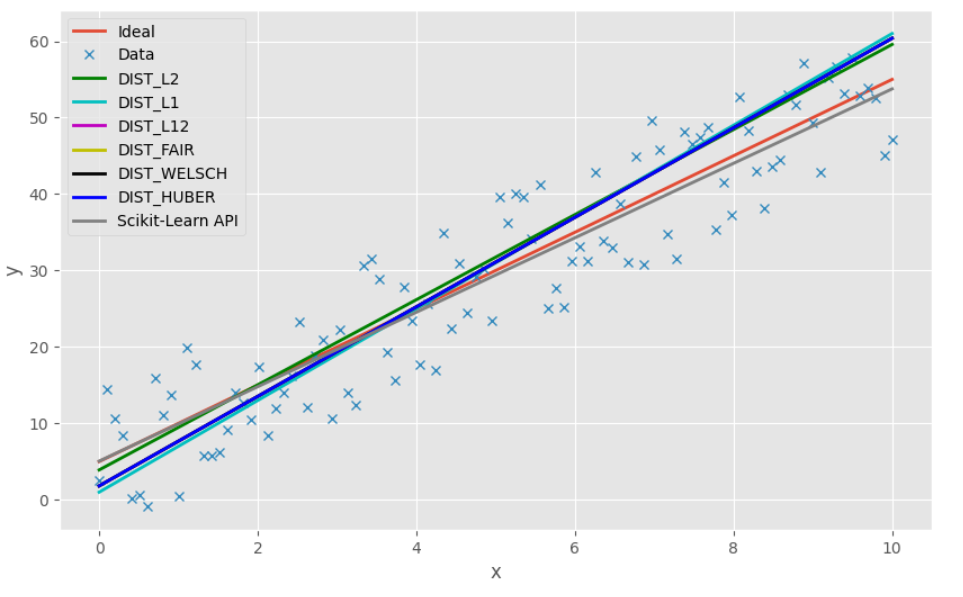
可以看出,虽然差距不大,但sklearn的表现效果最佳。

