
- 1阿里面试官终于把多年总结的Java八股文PDF版分享出来了,帮我金九银十拿下4个offer_java八股文第三版pdf
- 2rustdesk 自建服务器配置 docker方案_rustdesk docker
- 3HttpRunner自动化测试工具之录制工具使用--使用抓包工具通过命令转成yml文件_获取har文件,并转换未yaml文件
- 4微信小程序中常见的事件理解_微信小程序事件
- 5Android 加解密类Cipher_android cipher
- 6零基础读懂Stable Diffusion
- 7uniapp封装网络请求
- 8【Python+Selenium学习系列2-2】Selenium安装WebDriver:ChromeDriver与谷歌浏览器版本快速匹配_最新版120_chromedriver 120
- 9基于JavaSpringBoot+Vue+uniapp微信小程序实现鲜花商城购物系统_基于微信小程序的花店鲜花商城系统
- 10nginx反向代理模块配置详解_nginx 反向代理配置(一)
训练个人专属ChatGPT!港科大开源LMFlow:3090单卡5小时
赞
踩
本文来源 机器之心编辑部
拥有自己的 AI 大模型!开源项目 LMFlow 支持上千种模型,提供全流程高效训练方案。
2022 年 11 月 30 日,OpenAI 推出 ChatGPT,令人没想到的是,这个对话模型在 AI 圈掀起一股又一股讨论狂潮。英伟达 CEO 黄仁勋将其比喻为人工智能领域的 iPhone 时刻;比尔・盖茨盛赞 ChatGPT 在人工智能历史上的意义不亚于 PC 或互联网的诞生。
尽管 ChatGPT 在各个方面表现惊人,但其高昂的训练成本以及海量的训练数据等,都给想要进入该领域的人设下层层关卡。就拿算力来说,ChatGPT 经由微软专门建设的 AI 计算系统训练,总算力消耗约为 3640 PF-days。而在推理阶段,以今年 1 月份独立访客平均数 1300 万计算,ChatGPT 对应的芯片需求为 3 万多块英伟达 A100 GPU,初始投入成本约为 8 亿美元,每天光是花掉的电费就要 5 万美元。就连科技巨头微软在帮 OpenAI 打造 ChatGPT 时都因为算力不足而被迫暂停了一些其他项目。
科技大厂尚且如此,对于普通人来说更是难上加难。
因此在 ChatGPT 问世的这段时间里,许多人开始对科研的方向和未来感到迷茫:如何能够参与通用人工智能研究,在这个新的时代找到自己的优势?很多人都希望有能力训练一个只属于自己的 AI 大模型,但尽管国内外已有许多类 GPT 产品,对于普通的学者、研究者和程序员来说,这样的产品仍不足以适应每一个人的需求。
一方面,从头预训练的成本是我们普通人和小规模公司所无法承受的。另一方面,基于 API 的黑盒封装不是完美的解决方案。虽然我们可以很容易地基于 API 开发自己的应用,但使用效果和自定义程度往往不尽人意。因此,从头预训练和基于 API 开发都不是最佳方式。
接下来我们为大家介绍的开源项目 LMFlow,不需要从头预训练,只需要以 finetune 作为切入点即可。
项目地址:https://github.com/OptimalScale/LMFlow
项目介绍
该项目由香港科技大学统计和机器学习实验室团队发起,致力于建立一个全开放的大模型研究平台,支持有限机器资源下的各类实验,并且在平台上提升现有的数据利用方式和优化算法效率,让平台发展成一个比之前方法更高效的大模型训练系统。
此外,该项目的最终目的是帮助每个人都可以用尽量少的资源来训练一个专有领域的、个性化的大模型,以此来推进大模型的研究和应用落地。
在 LMFlow 的加持下,即便是有限的计算资源,也能让使用者针对专有领域支持个性化训练。基于 70 亿参数的 LLaMA,只需 1 张 3090、耗时 5 个小时,就可以训练一个专属于自己的个性化 GPT,并完成网页端部署。开源库作者们已经利用这个框架单机训练 330 亿参数的 LLaMA 中文版,并开源了模型权重用于学术研究。训练得到的模型权重可以通过该网页端即刻体验问答服务 (lmflow.com)。
lmflow.com 地址:http://lmflow.com/
使用 LMFlow,你也有能力训练一个只属于自己的模型!每个人可以根据自己的资源合理选择训练的模型,用于问答、陪伴、写作、翻译、专家领域咨询等各种任务。模型和数据量越大,训练时间越长,效果越佳。目前该研究也在训练更大参数量(650 亿)和更大数据量的中文版模型,效果还会持续提升。
其实,很早之前 LMFlow 的作者们就已认识到 finetune 的重要性。InstructGPT [1] 中就涵盖了 supervised fine-tuning 和 alignment(比如 RLHF)这两种 finetune 技术。然而,目前的开源代码库要么聚焦于某个模型(比如 LLaMA [2]),要么聚焦于某种特定的技术(比如 instruction tuning)。还没有一个库能够支持在海量模型上快速应用多种 finetune 技术。
现在,LMFlow 迈出了这个方向的第一步。通常,ChatGPT 的训练包括至少以下几个步骤:pretrain → supervised tuning → instruction tuning → alignment。LMFlow 库利用现有的开源大模型,支持这套流程的所有环节和灵活组合。这意味着 LMFlow 库为我们建立了一条通向完整训练链的桥梁。

接下来我们来了解一下实际使用 LMFlow 的体验。
使用体验
据作者介绍,LMFlow 拥有四大特性:可扩展、轻量级、定制化和完全开源。基于此,用户可以很快地训练自己的模型并继续进行二次迭代。这些模型不仅限于最近流行的 LLaMA,也包括 GPT-2、Galactica 等模型。
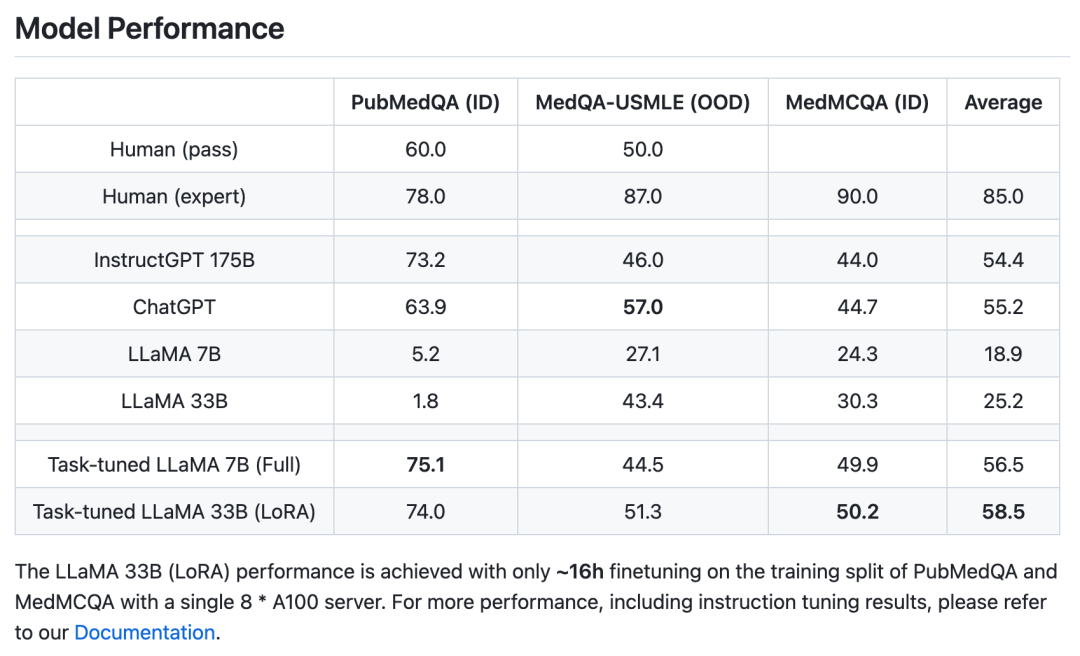
前面我们已经提到:基于该开源库,用户只需使用单卡 3090,就能对 LLaMA-7b 模型进行微调,用时 5 个小时训练得到一个能够流畅对话的问答模型。进一步,如果使用更多资源对更大的 LLaMA-33b 模型进行微调,即可大大提升回答的质量!

不仅如此,在特定的专家领域(以医疗为例),只需微调 6 个 A100 * 天,就能够获得和 ChatGPT 相当甚至更好的效果。值得注意的是,ChatGPT 则具有 1750 亿的参数量,而这里性能相当的最小模型规模只有不到二十分之一,大大节约计算资源。
接下来是真正的上手实验。使用 conda 安装必要的依赖后,即可上手体验。
- git clone https://github.com/OptimalScale/LMFlow.git
- cd LMFlow
- conda create -n lmflow python=3.9 -y
- conda activate lmflow
- conda install mpi4py
- pip install -e .
安装和准备数据集的过程非常顺利,如此便捷是因为作者们贴心地提供了一键下载数据集的方式。只需要运行一个 bash 脚本就能下载所需的数据集,非常方便!
- cd data
- bash download.sh all
- cd -
准备好了数据集之后,接下来就是模型训练。训练过程也大大简化,普通用户只需要执行一次 bash 脚本,即可轻松完成(非常适合小白入坑)。作者们还开放了训练好的模型下载,如果你不想自己训练模型,可以下载作者提供的 checkpoint 并进行推理。
- cd output_models
- bash download.sh medical_ckpt
- cd -
在此基础上,作者们还提供了基于 huggingface 模型或本地 checkpoint 的问答机器人脚本。一键运行即可与你训练的模型开始对话:

如果在使用过程中遇到任何问题,欢迎通过 github issue 或 github 主页的微信群联系作者团队。
在当下大家都纷纷投入到预训练大模型的竞赛中时,LMFlow 提供了一个很好的启示:大多数普通玩家没有预训练大模型的资源,但仍旧可以参与到这场使用和研究大模型的浪潮中来。正如他们的口号所说:「让每个人都能训得起大模型(Large Language Model for All)。」
参考文献
[1] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[2] Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
欢迎加入 GAN/扩散模型 —交流微信群 !
扫描下面二维码,添加运营小妹好友,拉你进群。发送申请时,请备注,格式为:研究方向+地区+学校/公司+姓名。如 扩散模型+北京+北航+吴彦祖

请备注格式:研究方向+地区+学校/公司+姓名

点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!

