
- 1kali linux fuzz工具集简述
- 2c语言练习96:输入任意正整数n,显示出1到n之间的所有完数输出。_c语言输入n,输出1,3,6,10,15 2,5,9,14
- 3HarmonyOS实战—页面跳转_harmonyos基于js的toolbar切换页面
- 4吴恩达2021年版深度学习作业(编程作业)第一章Week2 assigment2_2_2021-1-9 吴恩达- cnn课后编程
- 5高德算法大赛亚军战队经验分享:将图像信息转化为多模态理解解题
- 6python图形模块_使用Python的scikit-image模块进行图像分割
- 7OpenAI魔改大模型,参数减少100倍!13亿参数InstructGPT碾压GPT-3
- 8python聊天机器人接口+前端界面展示_如何将人和人工智能在终端的聊天显示在前端
- 9用wordcloud和jieba生成中文词云_expected string or bytes-like object词云图
- 10鸢尾花python贝叶斯分类_高斯朴素贝叶斯方法进行鸢尾花分类
一种创新的白细胞检测方法:多级特征融合与变形自注意力DETR(MFDS-DETR)
赞
踩

论文:https://arxiv.org/abs/2401.00926
引言
在标准的医院血液检查中,传统的流程需要医生通过显微镜手动从患者的血液显微图像中分离白细胞,然后通过自动白细胞分类器对分离的白细胞进行分类,以确定血样中不同类型白细胞的数量和体积,从而帮助疾病诊断。这种方法不仅耗时且费力,而且由于诸如图像质量和环境条件等因素可能导致错误,这可能潜在地导致后续分类和误诊。当代白细胞检测方法在处理具有较少白细胞特征的图像以及不同白细胞之间尺度差异方面存在局限性,导致大多数情况下结果不满意。
为了解决这些问题,本文提出了一种创新的白细胞检测方法:多级特征融合与变形自注意力DETR(MFDS-DETR)。为了解决白细胞尺度差异问题,作者设计了一个高级筛选特征融合金字塔(HS-FPN),实现了多级融合。这种模型使用高级特征作为权重通过通道注意力模块过滤低级特征信息,然后将筛选的信息与高级特征合并,从而增强模型的特征表达能力。此外,作者通过在编码器中集成多尺度可变形自注意力模块并在解码器中使用自注意力和交叉可变形注意力机制来解决白细胞特征稀缺问题,有助于提取白细胞特征图的全局特征。
通过使用私有WBCDD、公共L1SC和BCCD数据集与其他最先进的白细胞检测模型进行比较,证明了所提出MFDS-DETR方法的有效性、优越性和通用性。
近年来,严重疾病的全球发病率如急性白血病等显著上升。这些疾病的初级诊断工具是常规血液测试,医生需要使用显微镜检查患者的血涂片显微图像。诊断基于白细胞的不同类型和比例。自动化白细胞分类通常作为血液学分析技术,用于对血液图像中的白细胞进行分类。这种技术通常通过检查形态、大小、色素和核仁特征等属性,准确地划分不同的白细胞类型。然而,白细胞分类模型的应用通常需要经验丰富的医生手动从患者的血液显微图像中分离白细胞,这是一个劳动密集且耗时的过程,容易出错。
此外,图像质量和环境条件等因素可能影响该过程,导致后续分类的潜在错误。这些错误可能误导医生的判断,导致患者安全问题。为了解决这些问题,研究行人一直在探索白细胞目标检测。本研究旨在自动准确地确定血液显微图像中白细胞的位置并计数不同类型的白细胞。这种方法可以加快医生的诊断和治疗决策过程,从而提高患者护理,具有非常重要的研究意义。
传统的白细胞目标检测在血液显微图像中常常遇到以下挑战:
不同的医院使用不同的设备捕捉血液图像,产生的图像具有不同的颜色配置。这种变化可能导致白细胞检测的效率降低。
白细胞图像中可识别特征的有限数量也提出了高效检测的障碍。
不同医院设备在不同放大 Level 下产生的血液图像中白细胞大小存在不一致性。此外,不同白细胞类型之间固有的尺寸差异也会加剧这些尺寸差距,从而对白细胞检测的有效性产生负面影响。
与其他自然图像相比,白细胞医学显微镜图像通常具有低分辨率和不同的成像模式。这些图像中目标与自然图像中的物体之间巨大的几何外观差异给传统的目标检测算法带来了显著的挑战。
为了解决与血液显微镜成像相关的白细胞目标检测所面临的挑战,本文提出了一种基于多级特征融合与变形自注意力DETR(MFDS-DETR)的方法。设计了一个高级筛选特征融合金字塔(HS-FPN),以促进多级融合,并考虑了白细胞和不同白细胞之间的尺寸差异的独特特性。在HS-FPN中,高级特征作为权重通过通道注意力模块过滤低级特征信息。过滤后的信息与高级特征合并,从而增强模型的特征表达能力。
此外,为了解决白细胞中特征稀缺问题,在编码器中引入了多尺度可变形自注意力机制。这有助于提取白细胞特征图的全局特征。接下来,使用自注意力和交叉可变形注意力机制,解码器从编码器的全局特征中学习要检测的目标。然后,在二分图中将解码器的输出与 GT 值进行匹配,以获取目标的位置和类别。这个过程实现了白细胞的自动检测。
与现有的白细胞检测方法相比,MFDS-DETR有效解决了显微镜血液图像中白细胞特征有限的挑战。此外,它减少了图像中不同白细胞之间尺寸差异对建模过程有效性的影响。本研究的贡献主要可以总结如下:
在细粒度白细胞检测领域,作者提出了一个名为MFDS-DETR的新颖方法。这种基于多尺度融合和可变形自注意力的方法由四个关键组成部分组成: Backbone 网络、高级筛选特征融合金字塔、编码器和解码器。
在作者团队的关联医学专业人士的指导下,作者为现有的公开可用的白细胞分类数据集LISC打上目标帧。作者还与作者的合作伙伴医院合作,开发了作者自己的白细胞检测数据集WBCCD,该数据集将通过作者GitHub仓库中的下载链接向其他研究行人提供。
白细胞检测领域的发展严重依赖于数据集的现状。现有的公开可用的LISC和BCCD白细胞数据集已经收集了很长时间,但规模较小且质量较差。因此,作者决定将作者的WBCCD数据集贡献给其他研究行人,为该领域的发展做出重要贡献。
作者提出了创新的HS-FPN。与基于自然图像的传统特征融合方法不同,这个模块是根据白细胞固有的尺寸差异进行设计的。这一重大转变极大地增强了模型在白细胞检测数据集上的特征表达能力。
作者提出的模型MFDS-DETR在白细胞检测方面优于其他先进和 Baseline 模型。这一点由在两个公共数据集LISC和BCCD以及作者持有的私有WBCCD白细胞细粒度检测数据集中获得的优秀检测结果所证实。这些结果强调了作者的模型的有效性和广泛适用性。
工作
卷积神经网络(CNN)系列模型是一种高效且精确的一阶段目标检测机制,在目标检测领域得到广泛应用。因此,它成为许多专注于白细胞目标检测的研究的组成部分。利用SSD和YOLOv3模型进行自动化白细胞检测,实现了对11种外围白细胞的检测。值得注意的是,白细胞图像只是血液图像的一个小部分。
为了解决当前检测方法在处理较小目标时的相对较差性能,提出了SO-YOLO,该模型首先使用CNN提取图像特征,然后使用YOLO进行白细胞目标检测。
为了进一步提高模型的性能,提出了MID-YOLO,这是一个用于白细胞图像的一阶段CNN检测器。该模型利用注意力机制,在公开的Raabin-WBC数据集上表现出优越的检测性能。使用EfficientNet作为 Backbone 网络来提高模型的效率和灵活性,并提出了TE-YOLOF检测器。
将这个问题应用于急性淋巴细胞白血病的诊断,通过使用YOLOv4目标检测算法,该算法目前被用作预筛选的重要辅助工具。提出了基于改进的YOLOv5的白细胞检测模型YOLOv5-CHE。该模型解决样本缺乏和类别差异问题,通过将坐标注意力机制集成到卷积层中,增强了模型的特征提取能力。
考虑到单模型使用可能导致偏差,设计了一个基于YOLOv3、YOLOv3-SPP和YOLOv3-tiny的集成模型,在IoU为0.5时,平均精确度(AP)达到88.6%。[7]提出了一种基于Twin-Fusion-Feature CenterNet(TFF-CenterNet)的白细胞检测方法,以减轻白细胞染色程度变化带来的问题。这种方法通过优化特征融合金字塔,解决了染色程度差异问题。
尽管单阶段目标检测模型的速度可能较低,但检测精度仍然落后于两阶段目标检测模型。使用Faster R-CNN进行目标检测,并实验性地证明了使用ResNet-50作为 Backbone 网络可以获得更高的识别准确性。
通过在特征融合金字塔模块中添加注意力机制,改进了Mask R-CNN模型的多尺度特征融合能力,从而提高了检测准确性。将YOLOv5与RetinaNet模型相结合,通过空间布置和表型特征准确量化淋巴细胞,并验证了网络性能,例如应用图像修改,如模糊、锐利、亮度和对比度等。使用YOLOv8与DETR进行数千白细胞的检测,并使用DETR在单张图像中处理多个主题以提高检测准确性。
然而,这些关于白细胞目标检测的研究使用卷积神经网络(CNNs)来提取特征,然后进行目标定位和分类。这种方法受到卷积运算符的影响,无法学习白细胞图像的全局特征,从而阻碍了外周血白细胞的准确定位和分类。此外,白细胞的检测效果受到以下两个挑战的限制:
- 与自然图像的成像技术不同,白细胞的医学显微镜图像具有低分辨率。与白细胞固有的特性相结合,这导致白细胞图像中通常特征不足。
- 不同医院的显微镜仪器放大倍数各异,白细胞的大小也不均匀,导致白细胞之间存在尺寸差距。
为了解决上述挑战,通常采用多尺度特征融合。这个过程涉及将深度特征与浅层特征融合,从而使浅层特征具有强大的语义信息。存在两种多尺度特征融合方法:并行多分支网络和串行跳跃连接结构。并行多分支网络通常使用不同的卷积来提取同一特征图的特征,然后使用拼接来融合提取的特征。这种思想体现在GoogLeNet的Inception模块中,它使用各种卷积来提取同一特征图的特征,然后按通道维度将它们组合。
类似地,SSPNet在三种不同的方式下对同一特征图进行池化,然后将它们拼接在一起以获得多尺度融合特征图。DeepLabv3+采用ASSP结构进行特征融合,通过空卷积在不同尺度上获得特征,并通过上采样进行尺度统一操作。TridentNet和Big-Little Net采用类似的策略,后者使用BL模块更灵活地处理不同尺度的信息。与并行拼接方法相反,串行跳跃连接结构通常针对 Backbone 网络中不同层的输出进行多尺度融合。
特征金字塔网络(FPN)通过以统一尺度上采样高级特征,然后将它们与底层特征相加来实现多尺度特征融合。然而,由于FPN对高级目标信息存在歧义,PANet在FPN之上添加了双向特征融合模块,以增强局部定位信息。基于这些方法,BiFPN提出了一种更简洁的双向特征融合,Balanced FPN在集成和优化所有尺度的特征之前将它们与原始尺度特征相加。CE-FPN通过利用高级语义特征和注意力机制进行选择性特征融合来改进集成和优化过程。FaPN还设计了特征选择和特征对齐模块来提高FPN中特征融合的准确性,以应对潜在的FPN特征错位问题。
尽管这些多尺度特征融合方法具有重要的参考价值,但它们本质上基于自然图像设计。虽然其中一些方法在白细胞检测方面有效,但它们没有考虑白细胞显微图像的实际特性,从而限制了模型的检测效果。作者提出的MFDS-DETR网络模型有效解决了这些局限性。该模型首先通过 Backbone 网络从白细胞显微图像中获取多尺度特征图,然后使用设计好的HS-FPN进行特征融合。它将多尺度可变形自注意力机制集成到编码器操作中,以获取白细胞显微图像的全局特征,并最终使用解码器获得白细胞的位置和类别。作者的创新模型使用高级特征作为权重来过滤低级特征,将过滤后的特征与高级特征融合,从而显著增强模型检测效果。
此外,通过将多尺度可变形自注意力机制用于提取图像特征,作者的模型显著降低了复杂性并提高了检测效果。
模型
MFDS-DETR模型的整体结构如图所示,包括四个关键组成部分: Backbone 网络、HS-FPN、编码器和解码器。
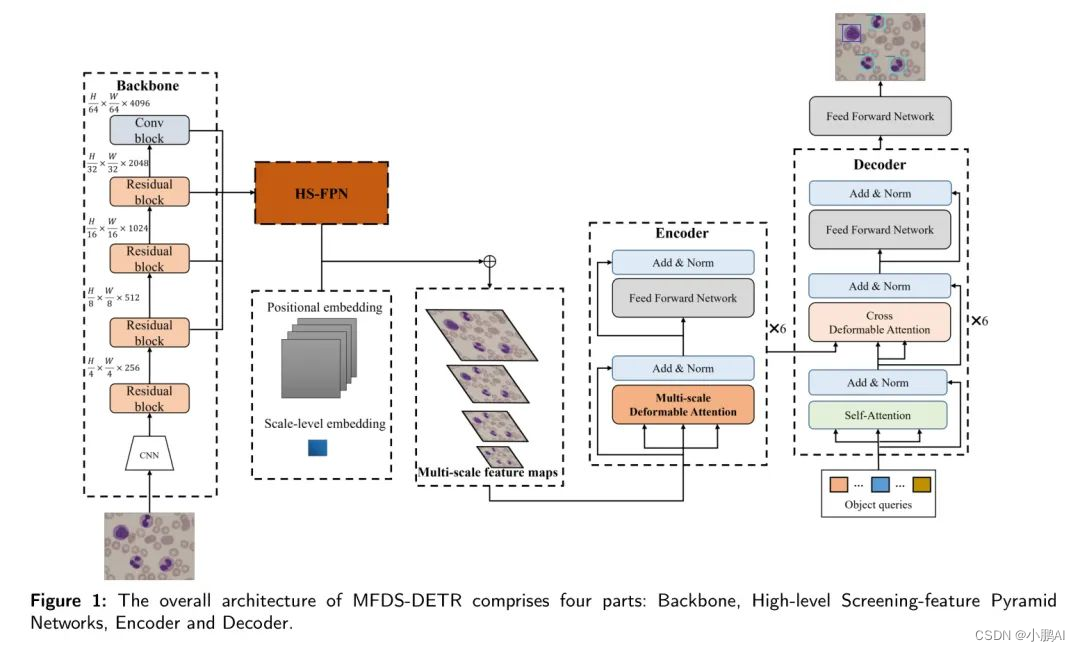
Backbone 网络的主要作用是提取白细胞的多种尺度图像特征,从而促进后续过程中的增强特征融合。HS-FPN是一个设计并改进的特性金字塔,用于容纳白细胞图像的特征,解决了白细胞图像中特征有限和白细胞直径差异的问题。HS-FPN通过使用HS-FPN中的通道注意力(CA)模块,将高级语义特征作为权重进行低级特征过滤。这些过滤后的特征按点与高级语义特征逐点相加,实现多尺度特征融合,从而最终提高模型的特征表达能力。编码器模块的主要功能是学习白细胞图像的全局特征。
通过集成多尺度可变形自注意力模块,模型可以学习白细胞图像在不同尺度下的全局特征。相反,解码器在输出与 GT 值之间进行二分图匹配,以确定目标的位置和类别。这通过使用自注意力和交叉可变形机制,从编码器的全局特征中学习要识别的物体来实现。
Backbone Network
MFDS-DETR的特征提取过程中,使用增强版的ResNet-50作为 Backbone 网络。ResNet-50利用残差连接来缓解梯度消失问题,从而促进收敛并解决深度神经网络通常伴随的退化问题。
由于白细胞图像中特征的缺乏,作者对原始ResNet-50模型进行了增强,通过在 Backbone 网络中添加了一个卷积模块。这个模块的设计是为了提取更深层次的语义信息,从而提高模型的检测效果。与ResNet-50类似,这个卷积模块首先通过11卷积使用11卷积块减少通道数量,然后通过33卷积缩减特征图大小,最后通过另一个11卷积增加通道数量。
High-level Screening-feature Pyramid Networks
在白细胞数据集中,白细胞识别任务受到多尺度问题的挑战,这使得模型难以准确地识别白细胞。这种复杂性源于不同类型白细胞的直径通常存在差异,即使在同一显微镜下,相同类型的白细胞在不同的显微镜下成像也可能看起来大小不同。
为了应对白细胞数据集中固有的多尺度挑战,作者开发了基于层次尺度的特征金字塔网络(HS-FPN)来实现多尺度特征融合。这使得模型能够捕获更全面的白细胞特征信息。
在白细胞数据集中,白细胞识别任务受到多尺度问题的挑战,这使得模型难以准确地识别白细胞。这种复杂性源于不同类型白细胞的直径通常存在差异,即使在同一显微镜下,相同类型的白细胞在不同的显微镜下成像也可能看起来大小不同。
为了应对白细胞数据集中固有的多尺度挑战,作者开发了基于层次尺度的特征金字塔网络(HS-FPN)来实现多尺度特征融合。这使得模型能够捕获更全面的白细胞特征信息。
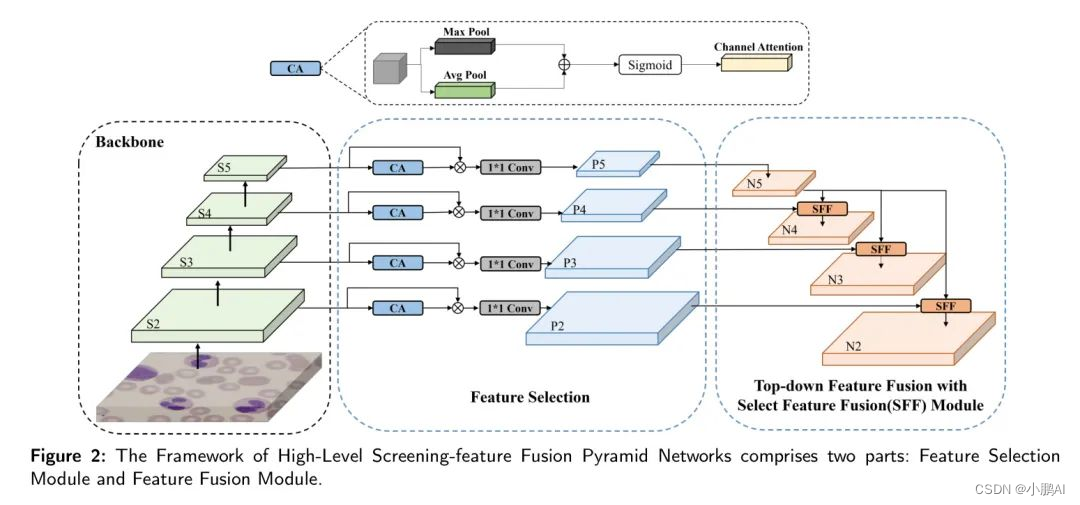
HS-FPN的结构如图2所示,包括两个主要组成部分:
- 特征选择模块;
- 特征融合模块。
首先,不同尺度的特征图在特征选择模块中经历筛选过程。然后,通过选择性特征融合(SFF)机制,这些特征图中的高级和低级信息协同地整合在一起。这种融合产生了具有丰富语义内容的特点,这对于检测白细胞显微图像中的细微特征非常有用,从而增强了模型的检测能力。关于SFF机制及其对模型性能的影响的详细说明将在随后的消融研究部分提供。
特征选择模块: 在这个过程中,CA模块和维度匹配(DM)模块起着关键作用。CA模块首先处理输入特征图。这个特征图经过两个池化层–全局平均池化和全局最大池化处理后,得到的结果特征被结合在一起。然后,使用Sigmoid激活函数来确定每个通道的权重值,从而得到每个通道的权重。
池化有许多基本用途:它降低特征图的维数并减少特征图的维度;消除冗余数据,压缩特征并减少参数数量;并实现翻译、旋转和尺度不变性。在CA模块中,全局平均池化和全局最大池化被用来计算每个通道的平均值和最大值。最大池化的主要目的是从每个通道中提取最相关的数据,而平均池化是为了均匀地从特征图中获取所有数据,以最小化过度损失。
因此,在CA模块中,将这两种池化方法结合使用,可以方便地从每个通道中提取最代表性的信息,同时最小化信息损失。过滤后的特征图随后通过乘以权重信息与相应尺度的特征图进行维度匹配来生成。在特征融合之前,跨各种尺度的特征图的维度匹配至关重要,因为它们具有不同的通道数。为了实现这一点,DM模块应用一个1*1卷积将每个尺度特征图的通道数减少到256。
特征融合模块: Backbone 网络生成的多尺度特征图包含丰富的语义信息,但目标定位相对较粗。相反,低尺度特征提供精确的目标位置,但包含有限语义信息。解决这个困境的常见方法是直接将上采样的高级特征和低尺度特征像素值求和,为每个层增加语义信息。然而,这种技术没有进行特征选择,只是将多个特征层的像素值简单相加。为了解决这一局限性,在本研究中,作者开发了SFF模块。该模块通过使用高级特征作为权重来过滤低尺度特征中包含的必要语义信息。
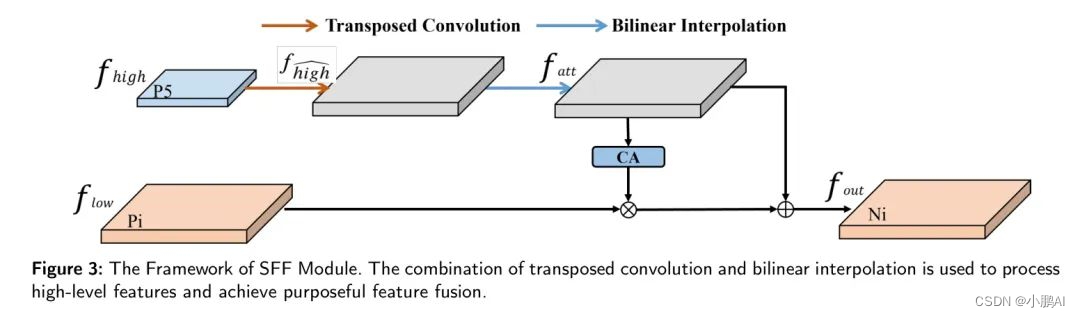
然后,为了统一高级特征和低尺度特征的维度,作者使用双线性插值来向上或向下采样高级特征。然后使用CA模块将高级特征转换为相应的注意力权重,以过滤低尺度特征,在获得具有相同维度的特征后。
在图像采样过程中,作者使用转置卷积和双线性插值相结合来恢复高级特征图的尺度。双线性插值简单且快速,能够直接操作图像的像素进行图像缩放。
转置卷积的优势包括:
- 通过可学习的参数适应数据,使得输出不仅放大特征图,而且以卷积的形式重构输入,这是通过在特征图扩展后通过填充零实现卷积运算;
- 它可以处理非均匀采样问题,通过在不同的输出图像位置采样输入图像的不同区域。
作者的消融实验进一步证实了转置卷积和双线性插值的组合优于仅使用双线性插值。
Encoder and Decoder
编码器在从白细胞图像中提取全局特征方面起着关键作用。编码器的输入是一个多级特征图,集成空间位置编码和尺度编码,如图1所示。编码器内的每一层都由一个可变形自注意力模块和一个前馈网络(FFN)组成。由于参考点位置对可变形自注意力有显著影响,因此它通过确定每个尺度像素点的中心坐标并进行归一化来初始化。一旦定义了参考点位置,多级可变形自注意力模块就会生成输出向量。
在本研究中,可变形自注意力配置为八个注意力头,每个头关注不同方向上的偏移。为了降低梯度消失的风险并加速模型收敛,使用加法和归一化(Add and Norm)方法中的残差结构来生成和归一化输出向量。
然后,这些输出向量经过FFN网络结构处理,这是一个多层感知机,负责扩展和减少维度,使模型能够学习特征之间的更多非线性相关性。在本研究中的消融实验表明,在MFDS-DETR模型中,六层编码器性能最佳。
解码器在建立各种检测到的特征表示之间的关系以及确定目标的准确位置和类别方面起着关键作用。如图1所示,解码器每一层由两个组件组成:自注意力特征提取模块和交叉注意力特征提取模块。自注意力特征提取模块包括一个自注意力模块和一个前馈网络(FFN),结构上类似于编码器中的组件。
然而,与编码器不同的是,交叉注意力特征提取模块的键和 Query 来自位置编码(Object Queries),而其值来自从编码器最后一层提取的全局特征。
实验
Dataset
为了验证模型,作者使用了三个数据集:白细胞检测数据集(WBCDD)、L1SC和BCCD。公开的L1SC和BCCD数据集用于评估模型的泛化能力。

相比之下,WBCDD数据集是专门为这项研究构建的。

图5显示了来自每个数据集的白细胞图像,而表1和表2详细列出了每个数据集中各种细胞类型的数量。
总结
在本文中,作者提出了MFDS-DETR模型,详细介绍了其网络结构和联合损失函数。网络结构包括 Backbone 网络、层次尺度特征金字塔网络(HS-FPN)、编码器和解码器。 Backbone 网络的主要功能是从白细胞图像中提取多尺度特征,从而实现后续多尺度特征融合。HS-FPN针对白细胞的特有特征进行了定制,采用了通道注意力模块,将高级特征图作为权重用于筛选低级特征。这些筛选后的特征与高级特征相融合,从而丰富了低级特征,并注入了重要的语义信息。编码器利用可变形自注意力提取图像的全局特征,而解码器则使用自注意力和交叉可变形注意力学习目标的定位。
此外,针对该模型设计的联合损失函数包括分类损失、回归损失和辅助损失。模型通过分类和回归损失进行优化,主要目标是确定最适合的匹配值。辅助损失有助于加速模型的收敛,通过在每个层计算解码器输出的分类和回归损失。
在随后的比较实验部分,作者将作者专门设计的MFDS-DETR模型与其他先进的白细胞目标检测模型进行了对比,使用的数据集有三个,分别是WBCDD、LISC和ALL-IDB,以证明作者模型的有效性和泛化能力。此外,作者在WBCDD数据集上进行了消融实验,以确定模型中关键组件的重要性,如位置编码、编码器、解码器和联合损失函数。最后,作者利用可视化和模型效果分析来进一步证实作者模型的有效性。
白细胞检测的进步受到可用数据集的大小和质量的限制。LISC数据集是一个长期公开的资源,但其规模较小。此外,BCCD数据集不仅标注了各种血细胞,还包括血小板,导致了一个密集而复杂的数据集,特点是目标粘附、遮挡和图像质量不佳。认识到这些限制,作者决定向领域内的研究行人发布WBCCD数据集,期望这个高质量的数据集能够推动白细胞检测领域的发展。
作者的研究对白细胞检测领域做出了重要贡献,但作者必须承认其局限性。为了提高MFDS-DETR模型的鲁棒性和泛化能力,未来的研究应致力于收集更大规模和更多样化的数据集以进行进一步验证。此外,考虑到医学影像技术和深度学习方法的快速发展,作者需要不断改进和适应作者的模型,以保持其在实际应用中的相关性和实用性。

