
这些年,NLP常见的预训练模型剖析_文预训练模型
赞
踩
“预训练-微调”(pre-training and fine-tune) 已经成为解决NLP任务的一种新的范式。基于预训练语言模型的词表示由于可以建模上下文信息,进而解决传统静态词向量不能建模“一词多义”语言现象的问题。传统的词向量有one-hot(杜热编码)、词袋模型(TF_IDF)、N-Gram、Word2Vec、Glove等,其中word2vec和Glove是属于word embedding。
- one-hot:每个单词都创建一个长度等于词汇量的零向量,在相应单词的位置上置为1。缺点 :效率低下、且向量稀疏。(未联系上下文,忽略词和词之间的联系)
- 词袋模型(TF-IDF):将每篇文章看成一袋子词,忽略每个词出现的顺序,将文本以词为单位分开,并将每篇文章表示成一个长向量,计算每个词在原文章中的重要性。(未联系上下文,忽略词和词之间的联系)
- N-gram:将连续出现的n个词组成的词组也作为一个单独特征放到向量表示中去。(增加了词和词之间的联系,未考虑词性变化)
- Word2Vec:通过上下文来学习语义信息。常见模型有CBOW和Skip-gram,CBOW是通过上下文出现的词语去预测中心词,训练速度较快。Skip-gram是通过当前词去预测上下文中的各词生成概率,对罕见词的训练效果比较好。缺点:(1)由于词和向量是一对一的关系,所以多义词的问题无法解决(2)Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化(学习了语义信息,能学习到一些同义词,但是也存在一些缺点)
- Glove:以矩阵分解方法为基础,通过对包含整个语料统计信息的矩阵进行分解,得到每个单词对应的实数向量。
相比较Word2Vec和Glove区别的可以参考:Word2Vec 与 GloVe 技术浅析与对比
基于传统词向量模型的不足(一词多义问题,在简单的word embedding里边一个词只有一个embedding,但是在生活中,存在一词多义),在2018年后,出现了新的一批模型(基于上下文的word embedding)。常见的预训练模型有
1.ELMo
ELMo(Embedding from Language Models)的缩写,在2018年发表的论文《Deep Contextualized Word Embeddings》,提出了ELMo的思想。ELMo是采用双向的Bi-LSTM对输入进行训练,单词特征E可以通过传统词向量方式实现,每一个lstm层都将单词特征与其上文词向量和下文词向量进行拼接作为当前的输入向量,其中第一层lstm获取句法特征,第二层lstm获取语义特征。 在进行下游任务时,获取之前模型训练的3个embedding(包括单词向量E,第一层LSTM的输出,第二层LSTM的输出),进行加权求和后输入下游任务中。
ELMO虽然能够看到上下文信息,但是它只能看到单向的上下文信息,这样说是因为ELMO中前向lstm和后向lstm的网络是完全独立的,也就是说当使用前向lstm训练时,词 t 看不到 t+1及之后的所有词,同理使用后向lstm训练时,词 t 看不到 t - 1及之前的所有词,因此本质上来说它依然只能看到单向信息,所谓的“双向”只是将两个方向的信息进行拼接而已。这是ELMO的局限性。
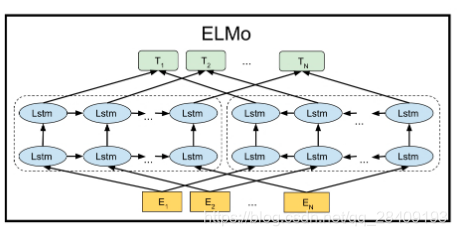
ELMo有三个特点:
1. 学习的是word token的词向量,根据上面的定义,word token与具体的上下文有关,不再是静态的word type的词向量;
2. 使用很长的上下文进行学习,而不像word2vec一样使用较小的滑动窗口,所以ELMo能学到长距离词的依赖关系;
3. 使用双向的语言模型进行学习,并使用网络的所有隐藏层作为这个词的特征表示。
2.GPT(单向语言模型)
GPT(Generative Pre-training Transformer)是OpenAI发布的,目前发布了三个版本:GPT-1、GPT-2、GPT-3。
GPT 是使用 Transformer 的 Decoder 模块构建进行半监督训练(无监督的预训练和有监督的微调),与原生Transformer相比,GPT对其中每个解码器的结构做了简化:在Transformer中,每个解码器模块中包括掩膜多头自注意力(Masked Multi-Head Attention)、编码-解码注意力(Encode-Decode Attention)和全连接前馈网络(Feed Forward NN)三个模块。而GPT去掉了其中的编码-解码注意力模块,仅保留掩膜多头自注意力和全连接前馈网络两个模块。
(1)Masked Multi-Head Attention
- Attention
Attention是将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。在seq2seq中为了解决输入序列信息丢失的问题引入的。Attention的Query(Q)是decoder的内容、Key(K)和Value(V)是encoder的内容,q和k对齐了解码端和编码端的信息相似度。
步骤:
第一步: query 和 key 进行相似度计算,得到权值(sim(q,k))
第二步:将权值进行归一化,得到直接可用的权重(softmax(sim(q,k)))
第三步:将权重和 value 进行加权求和(sum(softmax(sim(q,k))))
- Self Attention
当模型处理句子中的每个词时,Self Attention 机制使得模型不仅能够关注这个位置的词,而且能够关注句子中其他位置的词,作为辅助线索,进而可以更好地编码当前位置的词。例如
The animal didn't cross the street because it was too tired在句子中,我们能够分析出来it是指代the animal ,但是机器不知道,self Attention就是让it 和the animal关联起来。总体计算公式为:
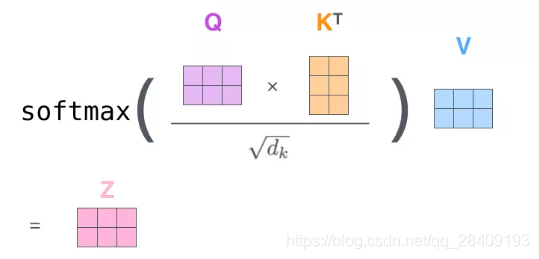
第 一 步是:对输入编码器的每个词向量,都创建 3 个向量,分别是:Query 向量,Key 向量,Value 向量。这 3 个向量是词向量分别和 3 个矩阵相乘得到的,而这个矩阵是我们要学习的参数。
例:两个词向量为例,输入向量和权重W(Q,K,V)向量相乘,得到3个向量q,k,v。

第 2 步,是计算 Attention Score(注意力分数)。假设我们现在计算第一个词 Thinking 的 Attention Score(注意力分数),需要根据 Thinking 这个词,对句子中的其他每个词都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的每个词放置多少的注意力。从图上看,就是q1*k1+q1*k2
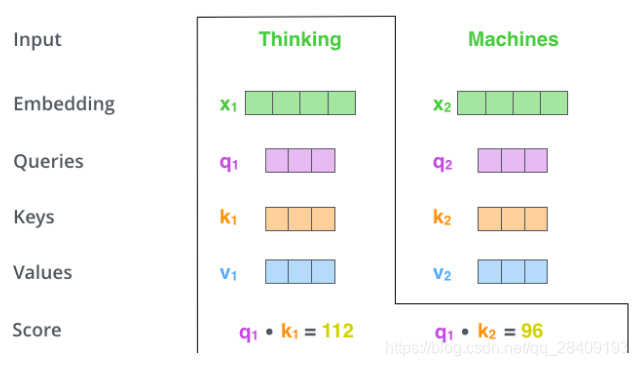
第 3 步就是把每个分数除以 ( 是 Key 向量的长度)。你也可以除以其他数,除以一个数是为了在反向传播时,求取梯度更加稳定。(下图中的8是多头里边的8组注意力)
第 4 步,接着把这些分数经过一个 Softmax 层,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于 1。

第 5 步,得到每个位置的分数后,将每个分数分别与每个 Value 向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的,这样我们就忽略了这些位置的词。
第 6 步是把上一步得到的向量相加,就得到了 Self Attention 层在这个位置(这里的例子是第一个位置)的输出。

- Multi-Head Attention
一组注意力机制是一个head,多组注意力机制就是多头(Multi-Head),多头注意力的好处:
1、它扩展了模型关注不同位置的能力。
2、多头注意力机制赋予 attention 层多个“子表示空间”(一个头是一个子表示空间)。

由四部分组成:
-
用linear并分拆成Multi head(作者就将512维向量拆成8份,每64维得到一个向量);
-
经过Scaled-Dot-Product Attention生成n(8)个B矩阵;
-
concat,新增一个权重系数,将b1,...,bn,合并成B传入下一层;
-
再增加一层Linear Layer。
- Masked Self-Attention
Masked Multi-Head Attention只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置。
因为解码器是要预测未来,因此,当前词后边的词是不存在的,需要将当前词后边的词向量的K置为无穷。
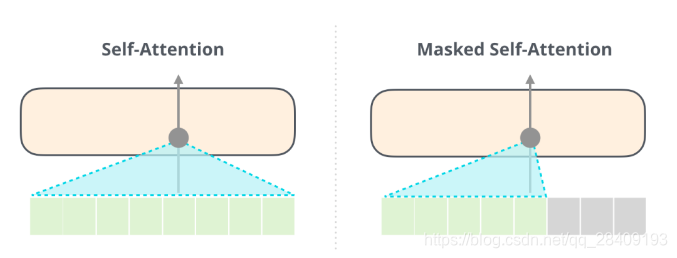
(Self-Attention 和 Masked Self-Attention 的区别)
假设模型只有2个token作为输入,且正在进行第二个token的计算,则将最后两个token屏蔽(masked),将未来的token评分为0。
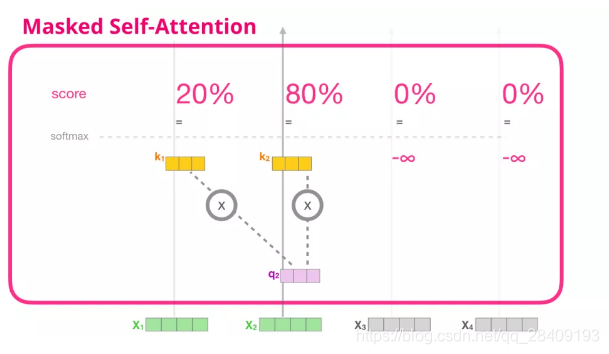
这个屏蔽(masking)是通过attention mask的矩阵进行的,在q.k之后,softmax之前进行,将需要屏蔽的单元格设置为负无穷大或者一个非常大的负数。然后按照self Attention的计算方式完成后续计算。

(2)Feed Forword NN
(3)位置编码
GPT-2和GPT的不同有:
1. GPT-2去掉了fine-tuning层:不再针对不同任务分别进行微调建模,而是不定义这个模型应该做什么任务,模型会自动识别出来需要做什么任务
2. 增加数据集:GPT-2收集了更加广泛、数量更多的语料组成数据集。该数据集包含800万个网页,大小为40G。
3. 增加网络参数:GPT-2将Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量更是达到了15亿
4. 调整transformer:将layer normalization放到每个sub-block之前,并在最后一个Self-attention后再增加一个layer normalization。
3.BERT(双向语言模型)
BERT(Bidirectional Encoder Representations from Transformers)是Google发表的论文,基于Transformers-encoder的双向编码表示模型。BERT是Transformers应用的一次巨大的成功。在该模型提出时,其在NLP领域的11个方向上都大幅刷新了SOTA。其模型的主要特点可以归纳如下:
- 基于Transformer。Transformer的提出将注意力机制的应用发挥到了极致,同时也解决了基于RNN的注意力机制的无法并行计算的问题,使超大规模的模型训练在时间上变得可以接受;
- 双向编码。其实双向编码不是BERT首创,但是基于Transformer与双向编码结合使这一做法的效用得到了最充分的发挥;
- 使用MLM(Mask Language Model)能够获取上下文相关的双向特征表示;NSP(Next Sentence Prediction)擅长处理句子或段落的匹配任务,进而实现多任务训练的目标。
- 迁移学习。BERT模型展现出了大规模数据训练带来的有效性,而更重要的一点是,BERT实质上是一种更好的语义表征,相较于经典的Word2Vec,Glove等模型具有更好词嵌入特征。在实际应用中,我们可以直接调用训练好的BERT模型作为特征表示,进而设计下游任务。
Bert有两种不一样规模的模型:Bert(base)是12个encoder,768个隐藏层单元和12个heads,Bert(large)是24个encoder,1024个隐藏层单元和16个heads,原Transformer有配置是6个encoder,512个隐藏层单元和8个heads。
特殊标识:[cls]在样本Input的开头,就是classification的意思,可以理解为用于下游的分类任务。
[sep]用于做句子的分割符,在每个句子的结尾。
(1)Transformer-Encoder
与Transformer的模型的encoder一致。特点是(1)Multi-head Attention(2)feed forward NN(3)残差网络 (4)位置编码 等。
- Multi-Head self attention:多头机制类似于“多通道”特征抽取,self attention通过attention mask动态编码变长序列,解决长距离依赖(无位置偏差)、可并行计算;
- Feed-forward :在位置维度计算非线性层级特征;
- Layer Norm & Residuals:加速训练,使“深度”网络更加健壮;
(2)MLM(Mask Language Model)
为了实现深度双向表示,我们采用了随机按百分比遮挡(masking)输入数据(Input token),然后预测被遮挡的数据(masked token)。论文中是随机屏蔽每个句子15%的token,但是有两个缺点
- 因为[mask]在fine-tuning不被看见,因此在pre-training和fine-tuning是不匹配的。为了减轻这个,我们会进行以下操作,而不是全部用[mask]替换。例:the dog is hairty
80%:使用[mask] token替换单词,the dog is hairty->the dog is [mask]
10%:使用其他词随机替换单词,the dog is hairty->the dog is apple
10%:保持单词不改变,the dog is hairty->the dog is hairty,目的是评估真实值和预测值之间的差据
- 使用MLM之后每个批次只有15%的词被预测,这意味着模型需要更多的预训练步骤进行处理,收敛速度要比left-to-right模型(GPT)要慢。
(3)NSP(Next Sentence Prediction)
类似于QA(问答)、NLI(自然语言推断)的下游任务需要理解两个文本序列之间的关系,我们提出来NSP任务(可以从任何语料库里生成)。我们从每个预训练样本中选择两个句子A和B,在B中,有50%是真实的A的next sentence内容,50%是从语料库随机选取的,例如图,摘自论文:

Bert的不足:
-
生成任务表现不佳:预训练过程和生成过程的不一致,导致在生成任务上效果不佳;
-
采取独立性假设:没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计(不是密度估计);
-
输入噪声[MASK],造成预训练-精调两阶段之间的差异;
-
无法文档级别的NLP任务,只适合于句子和段落级别的任务;
-
不适合处理NLG任务;由于BERT本身在预训练过程和生成过程的不一致,并没有做生成任务的相应机制,导致在生成任务上效果不佳,不能直接应用于生成任务。如果将BERT或者GPT用于Seq2Seq的自然语言生成任务,可以分别进行预训练编码器和解码器,但是编码器-注意力-解码器结构没有被联合训练,BERT和GPT在条件生成任务中只是次优效果。
4.ERINE
ERNIE(Enhanced Representation through kNowledge IntEgration)是百度提出的语义表示模型,同样基于Transformer Encoder,相较于BERT,其预训练过程利用了更丰富的语义知识和更多的语义任务,在多个NLP任务上取得了比BERT等模型更好的效果。
ERINE有两个版本:
ERINE1.0(主要更改MLM模块):
-
在预训练阶段引入知识(实际是预先识别出的实体),引入3种[MASK]策略预测:
-
Basic-Level Masking:跟BERT一样,对subword进行mask,无法获取高层次语义;
-
Phrase-Level Masking:mask连续短语;
-
Entity-Level Masking:mask实体;
-
-
在预训练阶段引入了论坛对话类数据
-
利用对话语言模式(DLM, Dialogue Language Model)建模Query-Response对话结构,将对话Pair对作为输入,引入Dialogue Embedding标识对话的角色,利用对话响应丢失(DRS, Dialogue Response Loss)学习对话的隐式关系,进一步提升模型的语义表示能力。
-
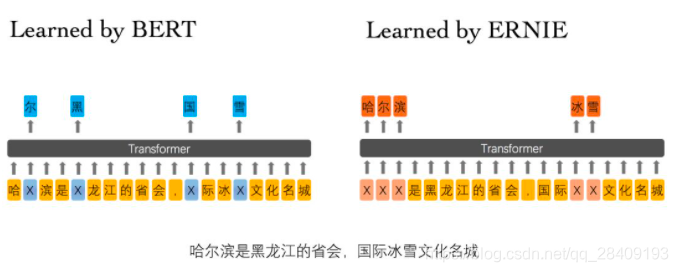
BERT在预训练过程中使用的数据仅是对单个字符进行屏蔽,例如图3所示,训练Bert通过“哈”与“滨”的局部共现判断出“尔”字,但是模型其实并没有学习到与“哈尔滨”相关的知识,即只是学习到“哈尔滨”这个词,但是并不知道“哈尔滨”所代表的含义;而ERNIE在预训练时使用的数据是对整个词进行屏蔽,从而学习词与实体的表达,例如屏蔽“哈尔滨”与“冰雪”这样的词,使模型能够建模出“哈尔滨”与“黑龙江”的关系,学到“哈尔滨”是“黑龙江”的省会以及“哈尔滨”是个冰雪城市这样的含义。
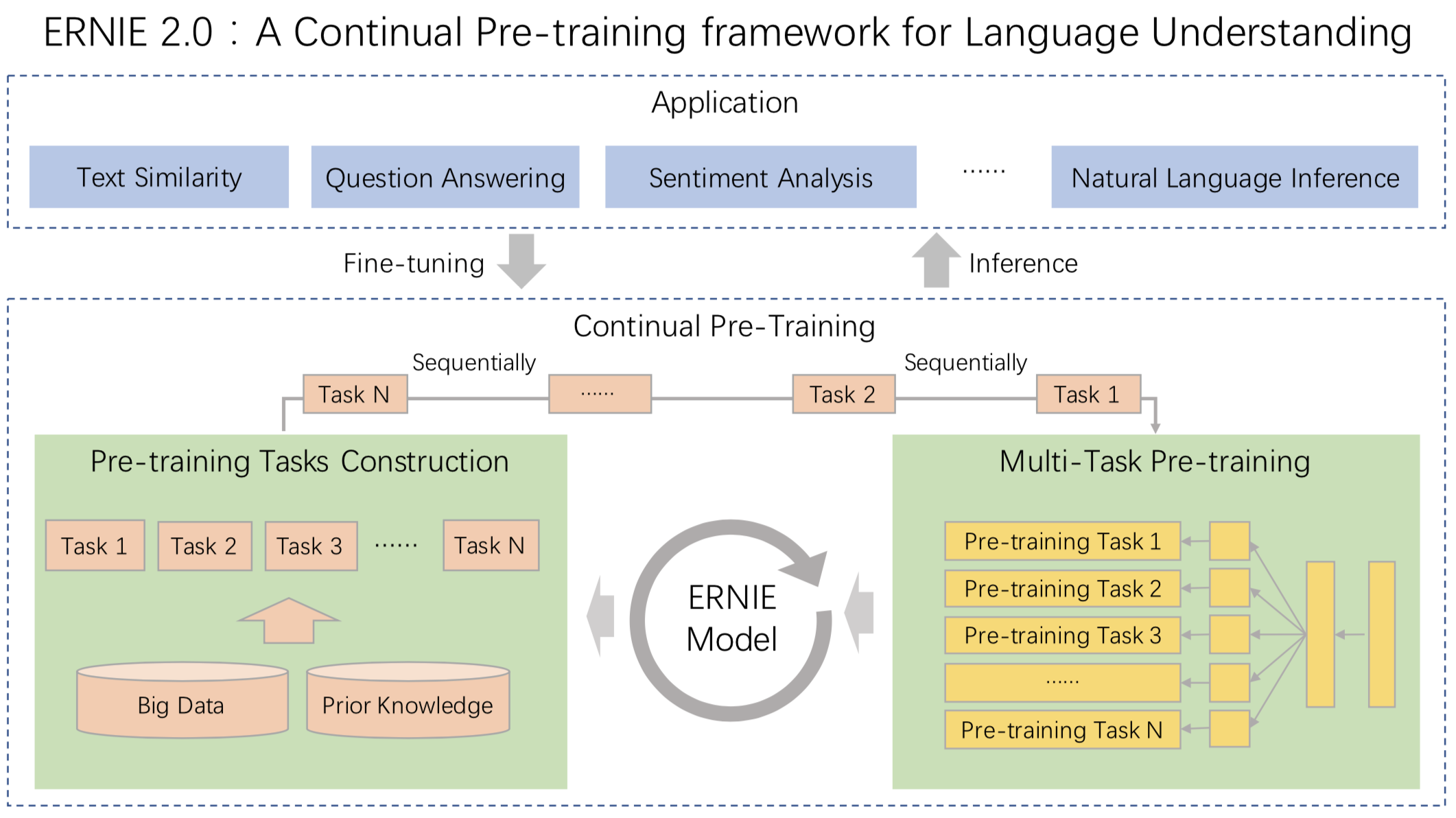
ERINE2.0:
在预训练阶段引入多任务学习,预训练包括了三大类学习任务,分别是:
- 词法层任务:学会对句子中的词汇进行预测。
- 语法层任务:学会将多个句子结构重建,重新排序。
- 语义层任务:学会判断句子之间的逻辑关系,例如因果关系、转折关系、并列关系等。
5.XLNET
XLNET是自回归(AR)语言模型,GPT和GPT-2都是AR语言模型。AR语言模型的优点是擅长NLP生成任务。因为在生成上下文时,通常是正向的。AR语言模型在这类NLP任务中很自然地工作得很好。但是AR语言模型有一些缺点,它只能使用前向上下文或后向上下文,这意味着它不能同时使用前向上下文和后向上下文。BERT被归类为自动编码器(AE)语言模型。AE语言模型的目的是从损坏的输入中重建原始数据。XLNet提出了一种新的方法,让AR语言模型从双向的上下文中学习,避免了AE语言模型中mask方法带来的弊端。
改进点:
(1)排列语言模型(Permutation LM)
PLM的本质是LM联合概率的多种分解机制的体现,将LM的顺序拆解推广到随机拆解,但是需要保留每个词的原始位置信息,遍历其中的分解方法,并且模型参数共享,就可以学习到预测词上下文。
(2)two-stream self-Attention
two-stream self-Attention解决了没有目标位置信息的问题。
(3)Transformer-XL

