- 1python和PyTorch知识_pytorch 星号
- 2文本规范化
- 3C语言二进制常用逻辑运算符介绍与使用
- 4每日OJ题_回文串dp①_力扣647. 回文子串
- 5Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!
- 6web前端高频面试题:如何保证Redis缓存与数据库的同步?_redis如何实现与数据库保持同步
- 7如何注册Claude3?解决Claude3无海外手机号接收验证码的问题以及如何订阅Claude Pro_claude 注册
- 8将图像转换为文字_image caption
- 9【Java Queue】Java中队列Queue(PriorityQueue优先队列)接口 及 双端队列Deque(LinkedList链表、ArrayDeque)接口_java 接口中使用queue接收数据
- 10全球首位AI程序员诞生,将会对程序员的影响有多大?_全球首个ai程序员对未来工作场景的影响
中文文献:多模态知识图谱概述_知识图谱 多模态实体关系识别
赞
踩
中文文献:多模态知识图谱概述
一、定义
1、模态相关
多模态:同一实体的多种记录形式,同一实体虽然底层表征异构,但高层语义一致。数据之间存在语义差异与异质性。包括模式和数据,自上而下构造还是自底向上。
多模态实体链接:相同实体信息对齐。
需求:结合文本和视觉资源,增加噪声处理能力,扩大实体对齐和链接预测的范围,开展实体关系挖掘。
2、知识图谱相关
常规知识图谱已经做得很好了,特定领域尤其是中文方面的还不行。
可以弥补神经网络的不可解释性和数量方面的局限性。
专家系统是被淘汰的知识图谱。
医疗等领域需要解释性场景,知识图谱可以解释。
知识图谱把不同种类的信息连接在一起得到一个关系网络。
不断迭代修整;小规模实践;可视化图谱全貌。
知识图谱:基于图模型的关联网络知识表达。三元组描述客观世界中概念、实体及其关系,节点、边。
ontology本体:对概念和关系进行形式化描述,知识本体框架和三元组实例构成完整图谱。
多模态问题:语义鸿沟;异构鸿沟heterogeneity gap:指图像、文本等不同媒体的数据具有不同的特征表示形式,它们的相似性难以直接度量。且数据量大、数据分布稀疏,人工标注昂贵、数据缺失。
多模态学习:用深度学习的方法将多模态数据在同一高层语义表示空间进行对齐,以便进行对齐、比较和融合。一般把不同媒体的数据从各自独立的空间映射到一个第三方的公共空间中进行相似性度量,大多仅考虑两个模态数据,当同时面临三个或更多模态时,对于公共空间的寻找将面临一定的困难。
当前多模态主要在图像和文本。基于自然语言处理的:图像或文本作为实体或实体的属性,图像一般作为实体视觉的补充。其他信息以何种形式表示?现有一般文本实体链接其他模态的URL链接。基于计算机视觉的:在场景图谱基础上,分布式构建,场景图谱的图节点链接到文本知识图谱的相应实体或谓词
二、构建
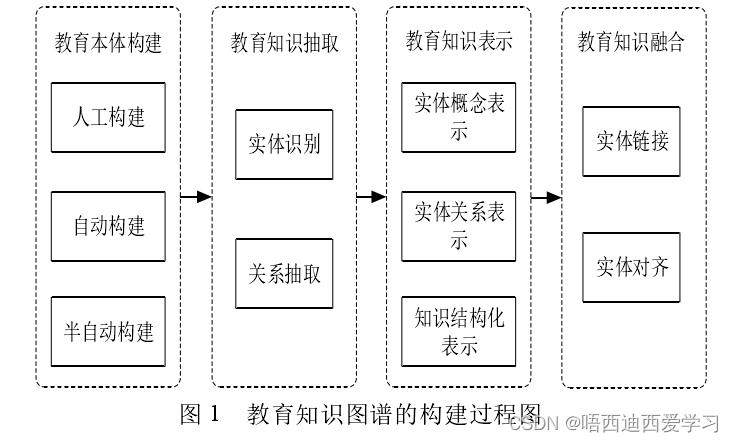
构建:信息抽取、知识融合、知识加工。
1、信息抽取
从无结构文本中抽取结构化(来源于链接数据或者数据库等的数据,通过图映射或者 D2R 转换的方法获取其中的实体以及关系)、半结构化(来源于表格、列表等有一定结构的数据,但还需要利用包装器进行处理才能获取知识)、非结构化(纯文本数据)数据。
对文本数据的信息抽取,主要有命名实体识别和关系识别两个模块。
- 实体识别
- 基于词典和规则:手工编写,只能识别已有,移植性差
- 基于特征模板:标注语料及选取特征
- 基于深度学习:序列标注
- 关系识别
- 基于模板:可扩展性差
- 监督学习:看做多分类,需要标注语料
- 半监督/无监督
除了文本,还有:
- 图像信息抽取
- 实体属性补充角度:利用关键词搜索对应图像进行补充,有局限性。
- 图像模态实体构建与视觉关系发现角度:主要关注在内容本身特征。细粒度图像目标识别。
- 声音
- 主要以实体属性形式存在,代表描述实体的一段音频。或者解析为文本用传统文本方法进行语义特征提取。
2、多模态表示学习
将文本或图像表示为计算机能理解的特征向量,减小模态信息的分布差距。
-
文本模态表示
最早one-hot,近年来transformer及其变体BERT流行。
-
图像模态表示
可以和文本采用相同框架分析。
-
声音模态表示
处理为数字信号序列,再进行特征向量提取。
同一模态存在富模态信息和缺失模态信息的不平等情况,可以分为联合/协同两种表示:
- 联合表示:多个模态的信息一起映射到一个统一的多模态向量空间; 同模态共作用语义表示,指融合各单模态的特征表示,以获得包含各模态语义信息的多模态表示。
- 协同表示:将多模态中的每个模态分别映射到各自的表示空间,映射后的向量之间满足一定的相关性约束。
- 与模态共作用语义表示相反,模态约束语义表示:用一个单模态表示结果去约束其他模态的表示,以使其他模态的表示能够包含该模态的语义信息。它并非融合各输入的信息,而是通过将输入模态的表示映射到目标模态的语义空间中,使得映射结果与语义相同的目标模态的相似性大于语义不同的目标模态,此类代表性的神经网络包括前馈神经网络和递归神经网络。
从图谱构建角度,MMKG表示学习可分为:
- 基于特征的方法:将多模态信息作为实体的辅助特征
- 基于实体的方法:将不同模态信息作为结构化知识的关系三元组,而不是预定的特征。
3、多模态实体链接
将从给定资源中抽取的实体对象链接到知识图谱中对应的实体中。从知识图谱中为给定的实体选择一组候选实体对象,然后根据相似度比较将实体链接到正确的实体对象。即进行匹配。
同一文本对应多张图像or同一图像对应多个文本
知识融合
对不同数据来源的数据进行融合,共指消解(消除同一实体在文本中的不同指代)和实体消歧(消除一个名称有多种语义的情况)。
数据模式定义 数据获取 数据预处理 实体识别 关系识别 多模态实体链接 。
4、其他
URI:统一资源标识。
知识链接:同一实体有不同mention;同一mention对应不同实体。时。结合更多信息进行消歧。
通用知识图谱:

领域知识图谱: