
AiSQL特性在特定业务场景下的应用_ai sql
赞
踩
AiSQL是贝格迈思根据当前大数据时代的需求开发的新一代高性能分布式数据库。与传统数据库不同,AiSQL采用异构计算平台,通过分布式的架构设计来实现高性能和高可用。AiSQL作为一个分布式数据库系统,采用分布式架构设计、动态扩缩容机制、负载均衡策略、存储引擎优化设计、缓存设计、高性能事务处理设计,具有很强的容量和性能,支持海量数据的高并发处理与访问,能够满足许多企业对于可靠和高效的数据存储与处理能力的需求。在本文中,我们结合具体的业务场景来阐述AiSQL以下特性:追随者读取、读副本、xDCR、变更数据捕获、数据行级别地理分区。
一、追随者读取
现在业务系统需要处理的数据量越来越庞大,对后端的数据库性能要求越来越高。在金融、保险、电商等行业来说,业务系统一方面要进行海量的OLTP交易处理,另一方面还要处理占比很高的日常查询业务,比如在处理完基金份额的购买交易后,需要提供客户的基金份额持仓情况查询;处理完成银行账户资金转账交易后,需要提供客户的账户余额查询等。这些交易后的查询占比很高,与交易处理一起集中交给后端的数据库服务器,会给数据库服务器带来很大的压力。
AiSQL是分布式数据库,数据会自动进行哈希或范围分片,每个分片称为Tile,所有的Tile都有相应的副本,这些副本有1个Leader和数个Follower(具体数量由复制因子设置)组成,所有的Follower根据RAFT协议自动从Leader同步数据。默认情况下,所有的前端发来的SQL语句都由Leader负责,提供读写服务;Follower不对外提供服务,主要是在Leader失效的情况下,根据RAFT协议,在Follower中选举新的Leader,以保证数据库的高可用。
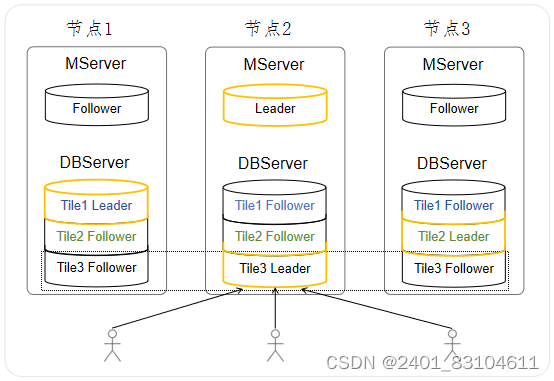
图1 默认只有Tile Leader对外提供SQL服务
为了缓解Tile Leader所在数据库服务器的压力,AiSQL提供追随者读取的特性:客户端将交易环节的SQL交由Tile Leader处理,日常查询交由Tile Follower处理,这样平滑的平衡了各个节点的工作负载,提高整体处理性能。Tile Follower可能无法完全更新所有更新,因此此设计可能会使用陈旧的数据进行响应,可以指定应用程序可以容忍的陈旧程度。启用后,只读操作可以由Follower处理,而不必转到Leader。
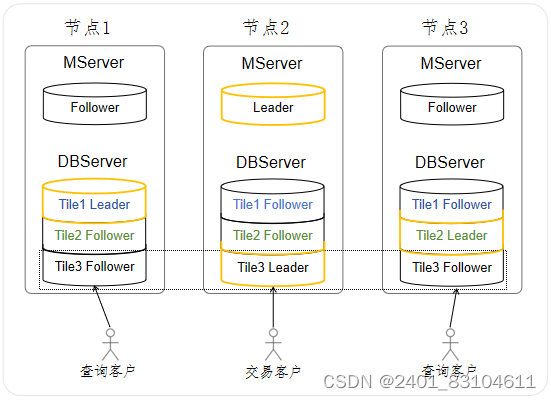
图2 启用追随者读取后工作负载
二、读副本
上文所述的特性是在节点级别实现的,当出现更大量级别的集中查询业务时可以使用AiSQL的读副本特性,这个特性是在集群级别实现的。比如说某集团公司业务当前集中在华南地区。为了响应国家一路一带业务,需要在西北地区开拓市场,根据市场营销策略预测,集团的客户管理系统、销售管理系统会在西北地区面临相当大的查询业务,目前的系统部署在华南地区,部署架构不足以支撑新开拓业务需求。AiSQL提供读副本特性:在集群级别提供只读副本,对外提供查询业务,缓解主集群的压力。因此,在不需要变动现有架构的基础上,仅需要在西北地区新增一套读副本集群就能满足需求。
在 AiSQL中,部署读副本集群将数据异步复制到不同区域。主集群节点之间的数据复制同步运行并保证强一致性。读副本集群从主集群异步复制数据并保证时间线一致性(具有有限的过时性)。同步复制的主集群可以接受对系统的写入,读副本集群为应用程序在远程区域就近提供低延迟读取服务,改善用户使用体验。读副本集群部署不会增加主集群写入延迟,因为写入不会同步将数据复制到读副本集群。相反,数据会异步复制到读副本集群。而且应用程序可以向读副本集群发送写入请求,但这些写入请求在内部重定向到主机群对应的Tile leader,应用程序不需要做变动,这极大的简化了代码开发、部署、运维工作。

图3 部署读副本集群就近为客户提供查询服务
三、xDCR
上文读副本特性数据只能由主集群单向向读副本集群异步传输,指向读副本集群的写入操作会在AiSQL内部重定向到主集群。如果需要在2个集群之间双向传输数据,可以使用AiSQL的xDCR功能。
跨集群(xDCR)部署提供跨两个数据中心或云区域的异步复制。使用xDCR部署,可以在两个集群(也就是数据中心)之间使用双向异步复制。它是在后台完成的,不会造成写入延迟。
xDCR也可以为灾难恢复部署,来实现数据中心级别的高可用。
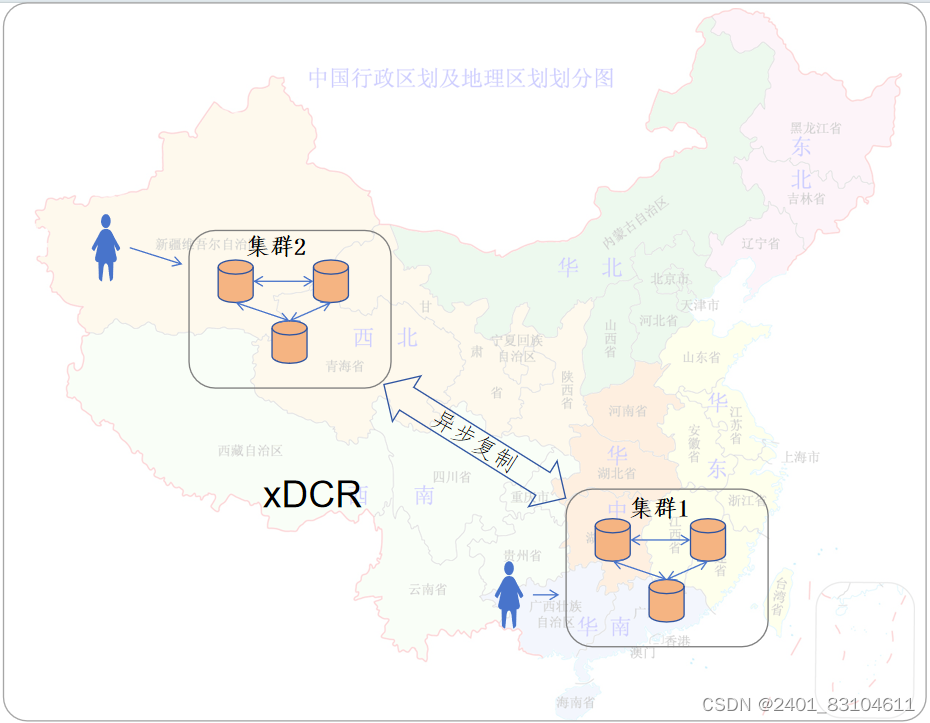
图4 部署xDCR实现2个集群双向复制数据
四、变更数据捕捉
上文的追随者读取、读副本、xDCR都是在AiSQL数据库之间实现数据传输,属于同构数据库之间的数据传输。如果客户的现有系统并不是AiSQL,而新开发的业务系统使用AiSQL,而且需要在新旧数据库之间同步数据,也就是异构数据库之间的数据传输,这如何来实现呢?
在这种业务场景下可以使用AiSQL的变更数据捕捉特性。在AiSQL数据库中,变更数据捕获是一组软件设计模式,用于确定和跟踪已更改的数据,以便可以使用更改的数据采取操作。AiSQL捕获对数据库中数据所做的更改,并将这些更改流式传输到外部进程、应用程序或其他数据库。变更数据捕获允许根据预写日志 (WAL) 跟踪AiSQL数据库中的更改并将其传播给下游使用者。可以捕获每个行级插入、更新和删除操作生成一个更改事件,并在单独的 Kafka 主题中发送每个表的更改事件记录。客户端应用程序读取与感兴趣的数据库表相对应的 Kafka 主题,并可以对从这些主题接收到的每个行级事件做出反应。
这种异构数据库之间的数据是双向的,可以从其他数据库(包括Oracle、MySQL、PostgreSQL、Redis等)传输数据到AiSQL,如图5,也可以从AiSQL传输数据到其他数据库,如图6。
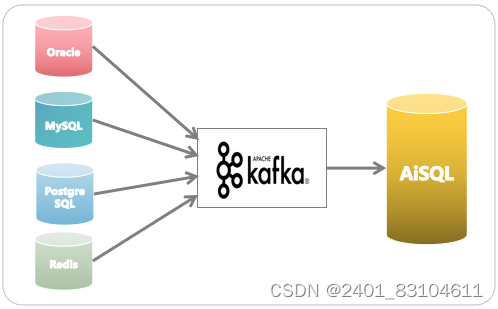
图5
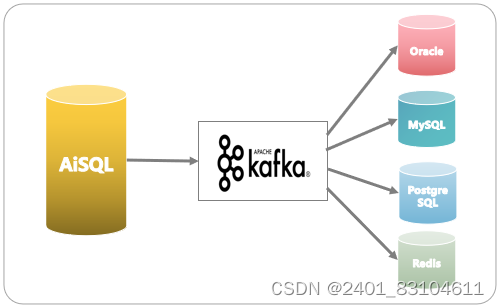
图6
五、数据行级别地理分区
前文所述的特性针对数据传输的颗粒度较粗,基本上是节点、集群级别,有没有更细粒度的特性?
下面介绍AiSQL的数据行级别地理分布特性,行级地理分区允许对用户表中的数据(每行级)固定到地理位置进行细粒度控制,从而允许在表行级管理数据驻留。实现业务数据就近低延迟部署、事务一致性、跨区域透明模式传输数据等特性。
地理分区允许将数据移至更靠近用户的位置,具有以下特点:
1.实现更低的延迟和更高的性能
2.满足数据驻留要求,将数据固定到区域以实现合规性,比如各国政府都要求本国客户数据必须保存在所在国。
具体是通过两个步骤完成的:
1.将表划分为用户定义的表分区。
2.通过为每个分区配置元数据,将这些分区固定到所需的地理位置。
比如某跨国集团的业务分布在中国、英国、加拿大,因业务需求需要存储客户必要的信息,相关国家都不允许将本国客户信息存储在国外。在这种情况下,可以使用AiSQL的数据行级别地理分区,实现同一个业务表的数据自动存储在合规的地理位置:中国客户的信息存储在中国,英国客户的信息存储在英国,加拿大客户的信息存储在加拿大。
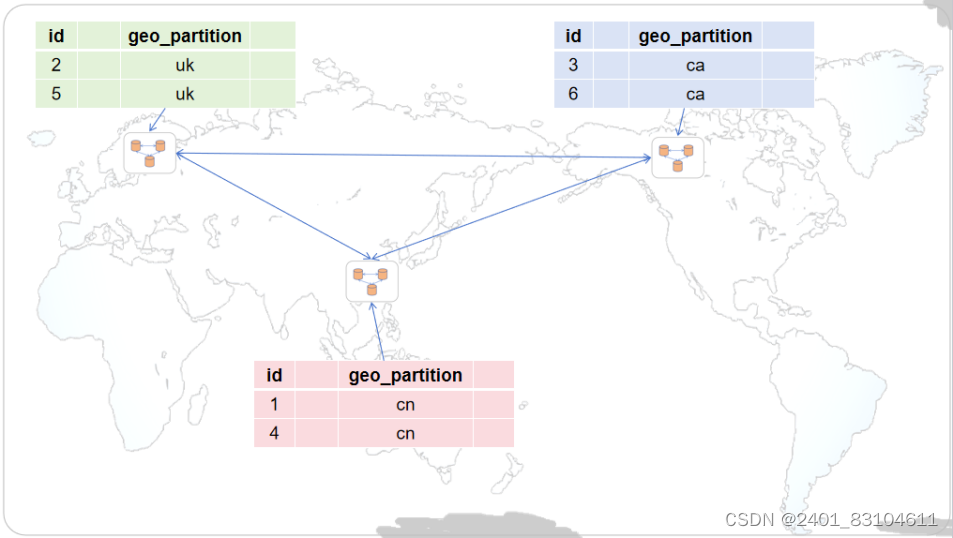
图7
综上所述,AiSQL具有追随者读取、读副本、xDCR、变更数据捕获、数据行级别地理分区特性,追随者读取提供节点级读取服务,读副本提供集群级读取服务,xDCR提供双向集群级读写服务,变更数据捕获提供异构数据库之间数据传输服务,数据行级别地理分区提供行级别的细粒度数据驻留服务,来满足各种业务场景。

