
- 1pytorch加载数据集-DataLoader解析以及一个通用的数据集加载模板_train_loader的用法
- 22023最新!QQ接入ChatGpt!!!保姆级教程_chatgpt接入qq
- 3Huawei EROFS 初探_erofs: (device dm-6): mounted with opts: , root in
- 4关于使用pip时报错:ImportError: cannot import name ‘InvalidSchemeCombination’ from ‘pip._internal.exceptions_importerror: cannot import name 'invalidschemecomb
- 5Java中阻塞队列类型介绍_boundedpriorityblockingqueue
- 6osg名词解释_osg::clearnode
- 7Ubuntu20.04系统配置Pytorch环境(GPU版)_ubuntu20.04安装pytorch gpu
- 8navicat连接异常,错误编号2059-authentication plugin…_navicat连接mysql出现2059错误
- 9华为荣耀7android+os+耗电,华为鸿蒙OS升级半个多月后,好评度虽高,但“差评”也很扎心!...
- 10c#模拟键盘鼠标操作_c# sendmessage模拟鼠标键盘
炼丹5至7倍速,使用Mac M1 芯片加速pytorch完全指南_mac炼丹
赞
踩
2022年5月,PyTorch官方宣布已正式支持在M1芯片版本的Mac上进行模型加速。官方对比数据显示,和CPU相比,M1上炼丹速度平均可加速7倍。
哇哦,不用单独配个GPU也能加速这么多,我迫不及待地搞到一个M1芯片的MacBook后试水了一番,并把我认为相关重要的信息梳理成了本文。
公众号后台回复关键词:M1,可获取本文jupyter notebook源代码。
一,加速原理
-
Question1,Mac M1芯片 为什么可以用来加速 pytorch?
因为 Mac M1芯片不是一个单纯的一个CPU芯片,而是包括了CPU(中央处理器),GPU(图形处理器),NPU(神经网络引擎),以及统一内存单元等众多组件的一块集成芯片。由于Mac M1芯片集成了GPU组件,所以可以用来加速pytorch.
-
Question2,Mac M1芯片 上GPU的的显存有多大?
Mac M1芯片的CPU和GPU使用统一的内存单元。所以Mac M1芯片的能使用的显存大小就是 Mac 电脑的内存大小。
-
Question3,使用Mac M1芯片加速 pytorch 需要安装 cuda后端吗?
不需要,cuda是适配nvidia的GPU的,Mac M1芯片中的GPU适配的加速后端是mps,在Mac对应操作系统中已经具备,无需单独安装。只需要安装适配的pytorch即可。
-
Question4,为什么有些可以在Mac Intel芯片电脑安装的软件不能在Mac M1芯片电脑上安装?
Mac M1芯片为了追求高性能和节能,在底层设计上使用的是一种叫做arm架构的精简指令集,不同于Intel等常用CPU芯片采用的x86架构完整指令集。所以有些基于x86指令集开发的软件不能直接在Mac M1芯片电脑上使用。

二,环境配置
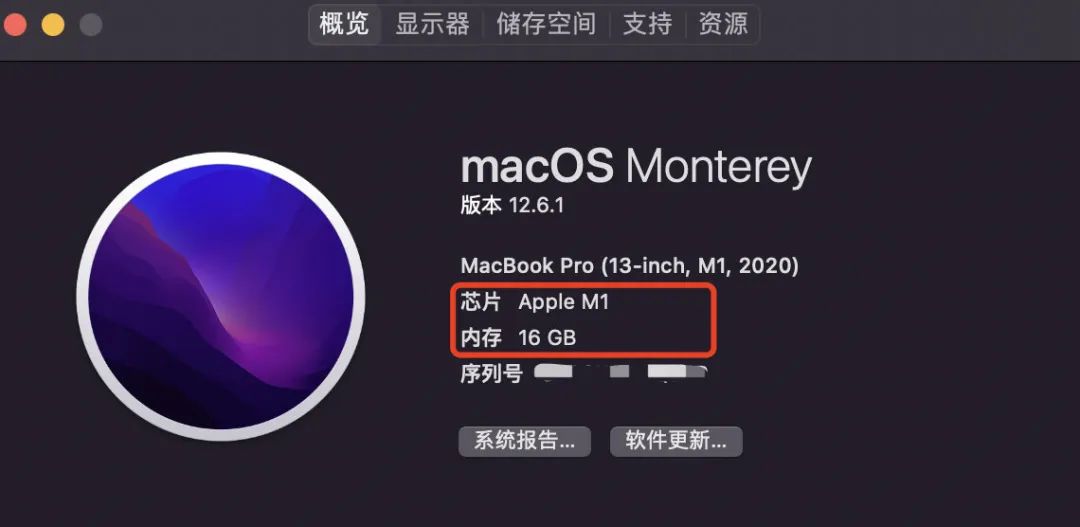
0,检查mac型号
点击桌面左上角mac图标——>关于本机——>概览,确定是m1芯片,了解内存大小(最好有16G以上,8G可能不太够用)。
1,下载 miniforge3 (miniforge3可以理解成 miniconda/annoconda 的社区版,提供了更稳定的对M1芯片的支持)
https://github.com/conda-forge/miniforge/#download
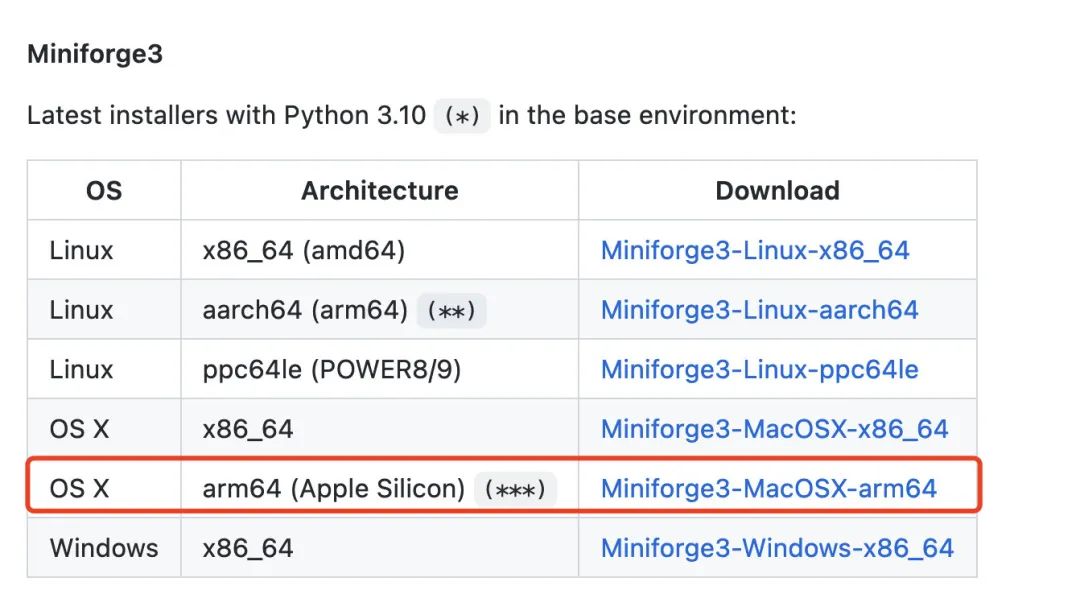
备注: annoconda 在 2022年5月开始也发布了对 mac m1芯片的官方支持,但还是推荐社区发布的miniforge3,开源且更加稳定。
2,安装 miniforge3
- chmod +x ~/Downloads/Miniforge3-MacOSX-arm64.sh
- sh ~/Downloads/Miniforge3-MacOSX-arm64.sh
- source ~/miniforge3/bin/activate
3,安装 pytorch (v1.12版本已经正式支持了用于mac m1芯片gpu加速的mps后端。)
pip install torch>=1.12 -i https://pypi.tuna.tsinghua.edu.cn/simple4,测试环境
- import torch
-
- print(torch.backends.mps.is_available())
- print(torch.backends.mps.is_built())
如果输出都是True的话,那么恭喜你配置成功了。
三,范例代码
下面以mnist手写数字识别为例,演示使用mac M1芯片GPU的mps后端来加速pytorch的完整流程。
核心操作非常简单,和使用cuda类似,训练前把模型和数据都移动到torch.device("mps")就可以了。
- import torch
- from torch import nn
- import torchvision
- from torchvision import transforms
- import torch.nn.functional as F
-
-
- import os,sys,time
- import numpy as np
- import pandas as pd
- import datetime
- from tqdm import tqdm
- from copy import deepcopy
- from torchmetrics import Accuracy
-
-
- def printlog(info):
- nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
- print("\n"+"=========="*8 + "%s"%nowtime)
- print(str(info)+"\n")
-
-
- #================================================================================
- # 一,准备数据
- #================================================================================
-
- transform = transforms.Compose([transforms.ToTensor()])
-
- ds_train = torchvision.datasets.MNIST(root="mnist/",train=True,download=True,transform=transform)
- ds_val = torchvision.datasets.MNIST(root="mnist/",train=False,download=True,transform=transform)
-
- dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=2)
- dl_val = torch.utils.data.DataLoader(ds_val, batch_size=128, shuffle=False, num_workers=2)
-
-
- #================================================================================
- # 二,定义模型
- #================================================================================
-
-
- def create_net():
- net = nn.Sequential()
- net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=64,kernel_size = 3))
- net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
- net.add_module("conv2",nn.Conv2d(in_channels=64,out_channels=512,kernel_size = 3))
- net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
- net.add_module("dropout",nn.Dropout2d(p = 0.1))
- net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
- net.add_module("flatten",nn.Flatten())
- net.add_module("linear1",nn.Linear(512,1024))
- net.add_module("relu",nn.ReLU())
- net.add_module("linear2",nn.Linear(1024,10))
- return net
-
- net = create_net()
- print(net)
-
- # 评估指标
- class Accuracy(nn.Module):
- def __init__(self):
- super().__init__()
-
- self.correct = nn.Parameter(torch.tensor(0.0),requires_grad=False)
- self.total = nn.Parameter(torch.tensor(0.0),requires_grad=False)
-
- def forward(self, preds: torch.Tensor, targets: torch.Tensor):
- preds = preds.argmax(dim=-1)
- m = (preds == targets).sum()
- n = targets.shape[0]
- self.correct += m
- self.total += n
-
- return m/n
-
- def compute(self):
- return self.correct.float() / self.total
-
- def reset(self):
- self.correct -= self.correct
- self.total -= self.total
-
- #================================================================================
- # 三,训练模型
- #================================================================================
-
- loss_fn = nn.CrossEntropyLoss()
- optimizer= torch.optim.Adam(net.parameters(),lr = 0.01)
- metrics_dict = nn.ModuleDict({"acc":Accuracy()})
-
-
- # =========================移动模型到mps上==============================
- device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
- net.to(device)
- loss_fn.to(device)
- metrics_dict.to(device)
- # ====================================================================
-
-
- epochs = 20
- ckpt_path='checkpoint.pt'
-
- #early_stopping相关设置
- monitor="val_acc"
- patience=5
- mode="max"
-
- history = {}
-
- for epoch in range(1, epochs+1):
- printlog("Epoch {0} / {1}".format(epoch, epochs))
-
- # 1,train -------------------------------------------------
- net.train()
-
- total_loss,step = 0,0
-
- loop = tqdm(enumerate(dl_train), total =len(dl_train),ncols=100)
- train_metrics_dict = deepcopy(metrics_dict)
-
- for i, batch in loop:
-
- features,labels = batch
-
- # =========================移动数据到mps上==============================
- features = features.to(device)
- labels = labels.to(device)
- # ====================================================================
-
- #forward
- preds = net(features)
- loss = loss_fn(preds,labels)
-
- #backward
- loss.backward()
- optimizer.step()
- optimizer.zero_grad()
-
- #metrics
- step_metrics = {"train_"+name:metric_fn(preds, labels).item()
- for name,metric_fn in train_metrics_dict.items()}
-
- step_log = dict({"train_loss":loss.item()},**step_metrics)
-
- total_loss += loss.item()
-
- step+=1
- if i!=len(dl_train)-1:
- loop.set_postfix(**step_log)
- else:
- epoch_loss = total_loss/step
- epoch_metrics = {"train_"+name:metric_fn.compute().item()
- for name,metric_fn in train_metrics_dict.items()}
- epoch_log = dict({"train_loss":epoch_loss},**epoch_metrics)
- loop.set_postfix(**epoch_log)
-
- for name,metric_fn in train_metrics_dict.items():
- metric_fn.reset()
-
- for name, metric in epoch_log.items():
- history[name] = history.get(name, []) + [metric]
-
-
- # 2,validate -------------------------------------------------
- net.eval()
-
- total_loss,step = 0,0
- loop = tqdm(enumerate(dl_val), total =len(dl_val),ncols=100)
-
- val_metrics_dict = deepcopy(metrics_dict)
-
- with torch.no_grad():
- for i, batch in loop:
-
- features,labels = batch
-
- # =========================移动数据到mps上==============================
- features = features.to(device)
- labels = labels.to(device)
- # ====================================================================
-
- #forward
- preds = net(features)
- loss = loss_fn(preds,labels)
-
- #metrics
- step_metrics = {"val_"+name:metric_fn(preds, labels).item()
- for name,metric_fn in val_metrics_dict.items()}
-
- step_log = dict({"val_loss":loss.item()},**step_metrics)
-
- total_loss += loss.item()
- step+=1
- if i!=len(dl_val)-1:
- loop.set_postfix(**step_log)
- else:
- epoch_loss = (total_loss/step)
- epoch_metrics = {"val_"+name:metric_fn.compute().item()
- for name,metric_fn in val_metrics_dict.items()}
- epoch_log = dict({"val_loss":epoch_loss},**epoch_metrics)
- loop.set_postfix(**epoch_log)
-
- for name,metric_fn in val_metrics_dict.items():
- metric_fn.reset()
-
- epoch_log["epoch"] = epoch
- for name, metric in epoch_log.items():
- history[name] = history.get(name, []) + [metric]
-
- # 3,early-stopping -------------------------------------------------
- arr_scores = history[monitor]
- best_score_idx = np.argmax(arr_scores) if mode=="max" else np.argmin(arr_scores)
- if best_score_idx==len(arr_scores)-1:
- torch.save(net.state_dict(),ckpt_path)
- print("<<<<<< reach best {0} : {1} >>>>>>".format(monitor,
- arr_scores[best_score_idx]),file=sys.stderr)
- if len(arr_scores)-best_score_idx>patience:
- print("<<<<<< {} without improvement in {} epoch, early stopping >>>>>>".format(
- monitor,patience),file=sys.stderr)
- break
- net.load_state_dict(torch.load(ckpt_path))
-
- dfhistory = pd.DataFrame(history)
四,使用torchkeras支持Mac M1芯片加速
我在最新的3.3.0的torchkeras版本中引入了对 mac m1芯片的支持,当存在可用的 mac m1芯片/ GPU 时,会默认使用它们进行加速,无需做任何配置。
使用范例如下。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

