
热门标签
热门文章
- 1深度学习——计算机视觉基础概念_视觉概念学习
- 2pytorch实现AlexNet(含完整代码)_pytorch alexnet
- 3Android 广播简单介绍
- 4KGBERT论文阅读(自用)_kg-bert
- 5Machine Learning week4-ANN(3)_4-ann 和 (r,2)nns
- 6Pycharm+PyQt5+Python3.5 开发环境配置(详细教程)_python 3.5
- 7VMware下克隆centos7后的网络配置及主机名问题_在centos上克隆的机器和原机器的主机名一样
- 8深入理解 word2vec 原理_word2vec原理
- 9yolov5从环境搭建到模型训练整过程_yolov5模型训练过程
- 10docker部署一个看板_docker wekan
当前位置: article > 正文
CVAE-GAN——生成0-9数字图像(Pytorch+mnist)
作者:羊村懒王 | 2024-04-04 14:16:03
赞
踩
CVAE-GAN——生成0-9数字图像(Pytorch+mnist)
1、简介
- CVAE-GAN(Conditional Variational Autoencoder Generative Adversarial Network)是一种混合型生成模型,结合了条件变分自编码器(CVAE)和生成对抗网络(GAN)的思想。
- 在CVAE-GAN中,CVAE的编码器和解码器被结合在一起,作为GAN的生成器,用于学习数据的潜在表示和生成数据。同时,GAN的判别器帮助训练生成器生成更逼真的数据。
- CVAE-GAN的工作方式如下:
- 编码器(Encoder):接收输入数据和条件信息,并将其映射到潜在空间中的潜在表示。
- 解码器(Decoder/Generator):接收从潜在空间中采样的潜在表示和条件信息,并生成与条件信息相关的数据样本。
- 判别器(Discriminator):接收真实样本和生成样本(包括条件信息),并尝试将它们区分开来。
- 损失函数:CVAE-GAN的损失函数通常包括两部分:一部分是CVAE的重构损失,用于确保生成数据与输入数据相似;另一部分是GAN的对抗损失,用于鼓励生成数据与真实数据分布相匹配。
- CVAE-GAN通过结合CVAE和GAN的优点,既可以学习数据的潜在表示,又可以生成高质量的数据样本,并且可以通过条件信息控制生成过程。这种结合使得CVAE-GAN在诸如图像生成、图像编辑等任务中具有很好的表现。
- 本文利用CVAE-GAN,输入数字图像和对应的标签。训练后,生成0-9数字图像。
 (epoch=10)
(epoch=10) (epoch=20)
(epoch=20)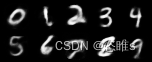 (epoch=30)
(epoch=30)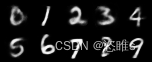 (epoch=40)
(epoch=40)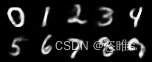 (epoch=50)
(epoch=50)
2、代码
2.1、生成器(Genration.py)
-
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- # 变分自编码器
- class CVAE(nn.Module):
- def __init__(self, input_size, num_classes):
- super(CVAE, self).__init__()
- self.num_classes = num_classes # 标签数量
- self.input_size = input_size
- self.potential_size = 64 # 潜在空间大小
- # 编码器层
- self.fc1 = nn.Linear(self.input_size + self.num_classes, 512) # 编码器输入层
- self.fc2 = nn.Linear(512, self.potential_size)
- self.fc3 = nn.Linear(512, self.potential_size)
- # 解码器层
- self.fc4 = nn.Linear(self.potential_size + self.num_classes, 512) # 解码器输入层
- self.fc5 = nn.Linear(512, self.input_size) # 解码器输出层
- # 编码器部分
- def encode(self, x):
- x = F.relu(self.fc1(x)) # 编码器的隐藏表示
- mu = self.fc2(x) # 潜在空间均值
- log_var = self.fc3(x) # 潜在空间对数方差
- return mu, log_var
- # 重参数化技巧
- def reparameterize(self, mu, log_var): # 从编码器输出的均值和对数方差中采样得到潜在变量z
- std = torch.exp(0.5 * log_var) # 计算标准差
- eps = torch.randn_like(std) # 从标准正态分布中采样得到随机噪声
- return mu + eps * std # 根据重参数化公式计算潜在变量z
- # 解码器部分
- def decode(self, z):
- z = F.relu(self.fc4(z)) # 将潜在变量 z 解码为重构图像
- return torch.sigmoid(self.fc5(z)) # 将隐藏表示映射回输入图像大小,并应用 sigmoid 激活函数,以产生重构图像
- # 前向传播
- def forward(self, x, y): # 输入图像 x,标签 y 通过编码器和解码器,得到重构图像和潜在变量的均值和对数方差
- x = torch.cat([x, y], dim=1)
- mu, log_var = self.encode(x)
- z = self.reparameterize(mu, log_var)
- z = torch.cat([z, y], dim=1)
- return self.decode(z), mu, log_var
- # 使用重构损失和 KL 散度作为损失函数
- def generator_loss(self, recon_x, x, mu, log_var): # 参数:重构的图像、原始图像、潜在变量的均值、潜在变量的对数方差
- MSE = F.mse_loss(recon_x, x.view(-1, self.input_size), reduction='sum') # 计算重构图像 recon_x 和原始图像 x 之间的均方误差
- KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # 计算潜在变量的KL散度
- return MSE + KLD # 返回二进制交叉熵损失和 KLD 损失的总和作为最终的损失值
2.2、判别器(Discriminator.py)
-
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- # 定义判别器类
- class Discriminator(nn.Module):
- def __init__(self, input_size, num_classes):
- super(Discriminator, self).__init__()
- self.num_classes = num_classes # 标签数量
- self.input_size = input_size
- # 判别器层
- self.fc1 = nn.Linear(self.input_size + self.num_classes, 512)
- self.fc2 = nn.Linear(512, 256)
- self.fc3 = nn.Linear(256, 1)
- def forward(self, x):
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- return torch.sigmoid(self.fc3(x))
2.3、训练(train.py)
-
- from Discriminator import Discriminator
- from Genration import CVAE
- import torch
- import torch.optim as optim
- import torchvision
- import torch.nn.functional as F
- from torchvision.utils import save_image
- # 生成0-9数字
- def sample_images(epoch):
- with torch.no_grad(): # 上下文管理器,确保在该上下文中不会进行梯度计算。因为在这里只是生成样本而不需要梯度
- number = 10
- # 生成标签
- sample_labels = torch.arange(10).long().to(device) # 0-9的标签
- sample_labels_onehot = F.one_hot(sample_labels, num_classes=10).float()
- # 生成随机噪声
- sample = torch.randn(number, latent_size).to(device) # 生成一个形状为 (64, latent_size) 的张量,其中包含从标准正态分布中采样的随机数
- sample = torch.cat([sample, sample_labels_onehot], dim=1) # 连接图片和标签
- sample = cvae_model.decode(sample).cpu() # 将随机样本输入到解码器中,解码器将其映射为图像
- save_image(sample.view(number, 1, 28, 28), f'sample{epoch}.png', nrow=int(number / 2)) # 将生成的图像保存为文件
- def generator_loss(recon_x, x, mu, log_var, discriminator_output):
- mse_loss = F.mse_loss(recon_x, x.view(-1, input_size), reduction='sum') # 计算重构图像 recon_x 和原始图像 x 之间的均方误差
- kld_loss = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
- gan_loss = F.binary_cross_entropy(discriminator_output, torch.ones_like(discriminator_output))
- return mse_loss + kld_loss + gan_loss
- def discriminator_loss_acc(real_output, fake_output):
- # 损失
- real_loss = F.binary_cross_entropy(real_output, torch.ones_like(real_output))
- fake_loss = F.binary_cross_entropy(fake_output, torch.zeros_like(fake_output))
- total_loss = real_loss + fake_loss
- # 精度
- real_pred = torch.round(real_output)
- fake_pred = torch.round(fake_output)
- real_acc = (real_pred == 1).sum().item() / real_output.numel()
- fake_acc = (fake_pred == 0).sum().item() / fake_output.numel()
- total_acc = (real_acc + fake_acc) / 2
- return total_loss, total_acc
- if __name__ == '__main__':
- batch_size = 512 # 批次大小
- epochs = 50 # 学习周期
- sample_interval = 10 # 保存结果的周期
- learning_rate = 0.001 # 学习率
- input_size = 784 # 输入大小
- num_classes = 10 # 标签数量
- latent_size = 64 # 噪声大小
- # 载入 MNIST 数据集中的图片进行训练
- transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) # 将图像转换为张量
- train_dataset = torchvision.datasets.MNIST(
- root="~/torch_datasets", train=True, transform=transform, download=True
- ) # 加载 MNIST 数据集的训练集,设置路径、转换和下载为 True
- train_loader = torch.utils.data.DataLoader(
- train_dataset, batch_size=batch_size, shuffle=True
- ) # 创建一个数据加载器,用于加载训练数据,设置批处理大小和是否随机打乱数据
- # 配置要在哪个设备上运行
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- cvae_model = CVAE(input_size, num_classes).to(device)
- dis_model = Discriminator(input_size, num_classes).to(device)
- optimizer_cvae = optim.Adam(cvae_model.parameters(), lr=learning_rate)
- optimizer_dis = optim.Adam(dis_model.parameters(), lr=learning_rate)
- for epoch in range(epochs):
- generator_loss_total = 0
- discriminator_loss_total = 0
- discriminator_acc_total = 0
- for batch_idx, (data, labels) in enumerate(train_loader):
- data = data.to(device)
- data = data.view(-1, input_size)
- labels = F.one_hot(labels, num_classes).float().to(device)
- # 更新判别器
- optimizer_dis.zero_grad()
- recon_batch, _, _ = cvae_model(data, labels) # 生成虚假数据
- fake_data = torch.cat([recon_batch, labels], dim=1)
- real_data = torch.cat([data, labels], dim=1)
- fake_output = dis_model(fake_data)
- real_output = dis_model(real_data)
- d_loss, d_acc = discriminator_loss_acc(real_output, fake_output) # 计算判别器损失和精度
- d_loss.backward()
- optimizer_dis.step() # 更新模型参数
- # 更新生成器
- optimizer_cvae.zero_grad()
- recon_batch, mu, log_var = cvae_model(data, labels)
- fake_data = torch.cat([recon_batch, labels], dim=1)
- fake_output = dis_model(fake_data)
- g_loss = generator_loss(recon_batch, data, mu, log_var, fake_output)
- g_loss.backward()
- optimizer_cvae.step()
- generator_loss_total += g_loss.item()
- discriminator_loss_total += d_loss.item()
- discriminator_acc_total += d_acc
- generator_loss_avg = generator_loss_total / len(train_loader)
- discriminator_loss_avg = discriminator_loss_total / len(train_loader)
- discriminator_acc_avg = discriminator_acc_total / len(train_loader)
- print('Epoch [{}/{}], Generator Loss: {:.3f}, Discriminator Loss: {:.3f}, Discriminator Acc: {:.2f}%'.format(
- epoch + 1, epochs, generator_loss_avg, discriminator_loss_avg, discriminator_acc_avg * 100))
- if (epoch + 1) % sample_interval == 0:
- sample_images(epoch + 1)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/359156
推荐阅读
相关标签

