
热门标签
热门文章
- 1TCN(Temporal Convolutional Network,时间卷积网络)
- 2分享10篇优秀论文,涉及图神经网络、大模型优化、表格分析_aaai2024论文在哪里看
- 3name ‘_C‘ is not defined(pytorch1.9.0在jupyter notebook上报错)_nameerror: name '_c' is not defined
- 4【深度强化学习】(4) Actor-Critic 模型解析,附Pytorch完整代码_actor critic
- 5ace2005 数据集预处理方法,oneie与JMEE方式_ace数据集
- 6【工具】1664- Codeium:强大且免费的AI智能编程助手
- 7景联文科技:2023人工智能数据标注行业现状分析?_数据标注接单平台2023
- 8数字人添加背景(heygen+剪映)_heygen数字人
- 9必读!信息抽取(Information Extraction)【关系抽取】_信息抽取和关系抽取一样吗
- 10codegeex和通义灵码辅助编程——以及通义灵码无法登陆的bug解决_codegeex 通义灵码
当前位置: article > 正文
LLaMA_llama csdn
作者:AllinToyou | 2024-04-07 06:01:50
赞
踩
llama csdn
LLaMA
1,llama
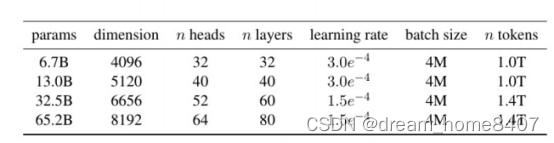
参数范围7B 13B 33B 65B
在万亿token上训练的模型,
2,研究重点
研究表明,最好的模型性能不是由最大的模型体积实现,而是在更多的数据上训练较小的模型实现
工作重点是通过使用比通常更多的token,训练一系列语言模型,
3,架构:
基于transforme架构,7B模型堆叠32个decoder模块,输入维度是4096,每个mutil head attention中头的个数32个,预训练模型是使用1T的token,
和transformer不同的是,为了提高训练的稳定性,作者对transformer子层的输入进行归一化,而不是输出部分,残差链结构在进行归一化,使用RMSNorm归一化函数,swiGLU激活函数,代替RELU
4,训练数据
练数据,全部来自公开数据集,不同领域混合数据,
英语commoncraw,fastText线性分隔器进行语言识别,并用ngram语言模型过滤低质量的内容,
c4,探索性实验中,实验者观察到使用不同的预处理数据集可以提高性能,去重和语言识别步骤,
ccnet的主要方法是质量过滤,去掉标点符号和网页中的单词和数字数量,去掉,
分 词 器,Sentence-Piece的 实 现

4,训练结果
当训练一个65b参数的模型时,我们的代码
在2048A100GPU上使用80GBRAM处理大约
380个令牌/秒/GPU。这意味着在我们包含1.4T
令牌的数据集上训练大约需要21天
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/376828?site
推荐阅读
相关标签

