
热门标签
热门文章
- 1超详细!大模型面经指南(附答案)_大语言模型面经
- 2nn.embedding笔记
- 3visual studio 插件_程序员请收好:10个非常有用的Visual Studio Code插件
- 4java/jsp/ssm高校校园社交网络【2024年毕设】
- 5Appium在IDEA上运行时遇到的那些坑_no route found for /wd/hub/status
- 6低代码——前端进阶的必修课_第一次接触低代码
- 7Tensorflow2 lite 模型量化_converter.optimizations
- 8OpenSSL:DES加解密实战_openssl_decrypt(): failed to base64 decode the inp
- 9ChatGPT自动写了个AI办公office word插件,低配copilot,程序员看了焦虑。_office ai插件
- 10Stable Diffusion 手部修复成功了_sd 手部修复
当前位置: article > 正文
NLP作业02:课程设计报告_基于文本内容的垃圾短信识别技术的意义
作者:AllinToyou | 2024-04-07 08:24:05
赞
踩
基于文本内容的垃圾短信识别技术的意义
作业头
| 这个作业属于那个课程 | 自然语言处理 |
|---|---|
| 这个作业要求在哪里 | https://bbs.csdn.net/topics/615949583 |
| 我在这个课程的目标是 | 学习自然语言处理技术的基础理论和实现方法 |
| 这个作业在那个具体方面帮助我实现目标 | 学会调用模型,熟悉代码框架 |
| 参考文献 | http://t.csdn.cn/c6mBb |
作业内容:
基于文本内容实现垃圾短信识别,完成代码编写并撰写实验报告。
1.设计目的
1.1 保护用户权益:垃圾短信可能会泄露用户的个人信息,或者诱骗用户进行虚假交易,给用户造成经济损失和隐私泄露等问题。识别垃圾短信可以有效地保护用户的权益和利益。
1.2 提高工作效率:垃圾短信的数量庞大,如果没有识别机制,用户需要手动筛选和删除,浪费时间和精力。有了垃圾短信识别技术,可以自动过滤掉大部分垃圾短信,提高用户工作效率。
1.3 推动技术发展:垃圾短信识别需要自然语言处理等技术的支持,推动了这些技术的发展和应用,同时也为其他领域的应用提供了经验和思路。
总之,垃圾短信识别在现代社会中具有重要的意义,它可以保护用户权益,提高工作效率,促进营销发展,推动技术发展。
2.设计要求
基于文本内容的垃圾短信识别主要是利用算法从短信文本中提取特征,并训练一个分类模型,对新的短信进行分类判断,以达到过滤垃圾短信的目的。
3.设计内容
(1)数据抽取:抽取所需数据集;
(2)数据预处理:对数据进行文本去重、中文分词、停用词过滤处理;
(3)建模准备:将分词结果分别转换成文档-词条矩阵并划分测试集与训练集;(4)模型构建:构建贝叶斯、支持向量机、神经网络模型;
(5)模型评价:用精确率、召回率、Fl值对模型分类效果进行评价;
(6)模型优化与分析结果。
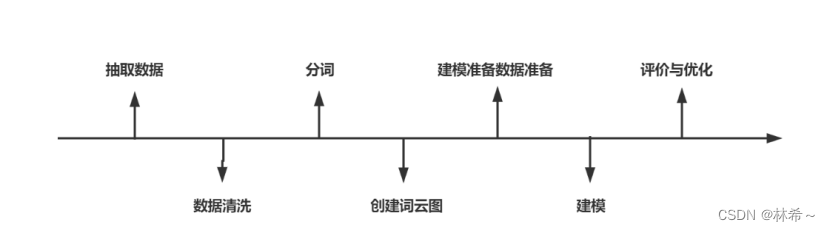
4.设计过程
4.1 简易流程图
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/377461
推荐阅读
相关标签

