
- 1使用PyQt5开发图形界面应用程序时,可能需要同时处理多个任务并显示多个窗口_pyqt 同时2个窗口
- 2NLP(七十七)文本补全中的动态提示(Dynamic Prompting)_文本补全 预测缺失词语的语义
- 3Redis配置参数详解_repl-diskless-sync no
- 4GlusterFS:优秀开源分布式存储系统_glusterfs的分布式文件存储系统的创新点
- 5树莓派存储方案_比树莓派更专业的HMI设计解决方案——MYDY6ULXHMI评测
- 6Leetcode|并查集+count|1319. 连通网络的操作次数_并查集 count
- 7Datawhale 动手学大模型应用开发 第四五章笔记 向量数据库 / Prompt / 检索chain / 记忆_大模型如何将prompt和向量数据库进行检索
- 8prompt提示词:影响力营销文案,让AI 帮你写营销文案
- 9fatal: detected dubious ownership in repository at ‘D:/HBuilderProjects/uni-shop-2‘_is owned by: 's-1-5-32-544' but the current user i
- 10团队协作方法之:高效使用任务故事墙_软件开发任务墙
中文语言能力评测基准「智源指数」问世:覆盖17种主流任务,19个代表性数据集,更全面、更均衡...
赞
踩

来源:AI科技评论
作者:琰琰
编辑:青暮
人工智能大模型时代,评测基准成为大模型发展的风向标。从扁平到全面系统,从简化到多重维度,智源指数CUGE旨在尝试为大模型评测设计一张全面评估综合能力的新考卷。
人工智能领域有两大权威基准,一是在CV圈引爆深度学习的ImageNet,二是见证BERT掀起预训练风潮的GLUE。
作为自然语言理解的通用评估标准,GLUE在一定程度上能够反映NLP 模型性能的高低。2018年,BERT在GLUE基准刷新了11项任务指标。自那之后,预训练+微调的2-Stage模式在NLP领域蔚然成风,GLUE也因此一炮而红,成为公认最具权威性的机器语言能力评估基准之一。
GLUE评估体系由纽约大学、华盛顿大学、DeepMind等机构联合推出。2019年,GLUE在预训练模型评估方面日渐乏力,随后SuperGLUE应运而生,并凭借多样化任务,全方位的考察能力受到产学界的广泛追捧。
无独有偶,随着超大规模预训练语言模型的兴起,也对SuperGLUE的评估能力提出更高要求,尤其是面对悟道、源1.0等滚滚而来的中文大模型。
12月30日,北京智源研究院在位于「宇宙中心」的智源大厦举办了首场 BAAI—NLP Open Day 活动。会上,中国工程院院士、清华大学教授、中国人工智能学会理事长戴琼海,北京语言大学教授、国家语言文字工作委员会原副主任李宇明,清华大学教授、智源研究院自然语言处理重大研究方向首席科学家孙茂松,智源研究院副院长曹岗同国内NLP科学家和青年学者一起,重磅发布了机器中文语言能力评测基准——智源指数CUGE。
CUGE,取自Chinese LanguageUnderstanding and Generation Evaluation的首字母缩写,代表着兼顾自然语言理解(NLU)与自然语言生成(NLG)两大任务体系的中文语言能力评测标准。它涵盖7种重要语言能力、17个主流任务、19个代表性数据集。
孙茂松教授表示,我们希望站在已有相关工作的基础上,构建出更全面均衡的机器语言评测体系,在学术上指引中文大规模预训练模型的发展方向,同时,也希望通过不断提高评测体系的科学性和权威性,更好地帮助研究者把更多精力放在模型本身的改进上,提升对模型发展的指导性。
1
为什么要做「智源指数」?
如戴琼海院士所言,如果说NLP是人工智能皇冠上的一颗明珠,建立科学的评价标准就需要寻找这颗明珠的指北针,如果方向错了,走的越远偏离越多,而且很有可能找不到。
所以,在NLP技术极速发展的过程中,其评价体系也需要亦步亦趋。
纵观NLP发展历程,预训练语言模型无疑是一个里程碑式的突破点。孙茂松教授表示,“自监督学习预训练模型+任务相关的精微调整”的适配方案初步掌握了通用语言能力的密码,是未来NLP领域最具前景的新范式。而面对试图掌握通用语言能力的预训练模型,以英文为代表的GLUE,对中文并不能够作出全面、科学的有效评测。这也是智源学者合力研发「智源指数」的一个重要原因。

预训练语言模型,其最大的价值是把深度学习推向了互联网上近乎无穷无尽的大规模数据——互联网上任何一个任何类型的文本,不需要人工标注就可以直接学习,而在此之前,深度学习训练仅限于特定任务的有标注数据。有了充足的底层“燃料”,预训练模型的规模也随之急剧膨胀,如今超大规模智能语言模型参数量达到了万亿级。
计算机如何评判机器的语言能力,需要科学有效的评价体系。NLP模型的评价标准最早可以追溯到图灵测试,后来逐渐演进到更为具体的基准任务和数据集。进入预训练时代后,GLUE/SuperGLUE一直被视为NLP评测方面的事实性标准,并在预训练发展历程中发挥了重要的指引作用。
然而,随着预训练模型逐渐向超大规模演进,GLUE仍停留在自然语言理解层面,不支持语言生成、多语言、数学推理等其他重要语言能力。
上个月,Google 在自然语言处理顶级会议NeurIPS 2021 投稿了一篇名为AI and the Everythingin the Whole Wide World Benchmark的文章,揭示了GLUE/SuperGLU等“通用”评估基准的若干局限性,包括任务设计过于武断、数据集/任务集组合太随意,数据范围受限等等。

论文地址:https://arxiv.org/abs/2111.15366
文章指出,数据基准测试本就是封闭的、主观的且基于有限数据构造的。但由于大家长期接受并强调用于“通用”能力评测的设定,“通用”反倒成为了掩护,开发基准的人以此为借口,逃避报告基准数据细节(如数据源、可能存在的偏向性)的责任。
与此同时,正因为基准对“通用”能力的评估被夸大,直接导致研究者们不假思索地去追求算法在基准评估中的性能指标。盲目“刷榜”而来的算法,忽略了指标与真实世界的匹配,也无法解决相关的现实问题。
针对这篇质疑 Benchmark 公平性的文章,刘知远教授表示,谷歌并没有否认Benchmark在模型发展中的价值,而是说,如今这些Benchmark与原本的指引作用出现了一些偏差,而这也是为什么智源指数强调未来需要持续改进的原因。

对于传统主流榜单基于机器在有限采样上的强表达能力,给予“远超人类水平”的成绩,刘知远表示:“ 传统主流榜单为行业发展做出了巨大贡献,我们期待在巨人的肩膀上继续进步。如果Benchmark包含的数据集,长期一成不变,指引的作用必然会越来越小,因为任何事物发展到最后都会形成内卷。就像高考,分数很重要,但能力的持续提升才是我们进行所有指标衡量的最终目的。”
在刘知远教授看来,模型与基准的发展是辩证统一的过程,我们不能站在某个结点,否定其过去的效用。人工智能的自然语言处理评测,本身是一个科学开放的事情,只要我们持续思考和探索,一定会做的越来越好。未来,智源指数每年会更新数据集,并以智源作为平台发布机器语言能力发展报告,向学术共同体传达未来需要一起改进和努力的方向。
同时,国内大模型研究产业如火如荼,但目前用于中文语言能力评测的基准却少之又少,刘知远教授认表示,他们希望智源指数,通过更科学有效地的评测体系帮助产学界更好地指引中文预训练模型的发展方向。同时,为国内NLP发展构建公正客观的基准生态,促进整个行业和领域的进步。
2
「全面均衡」的语言评测基准
为了使中文机器语言能力评测体系更全面、更系统,智源指数包含高质量中文自然语言处理(NLP)数据集、排行榜与在线评测平台,创造性的设计了多层次维度的评测方案。
报告地址:arxiv.org/pdf/2112.13610.pdf
网站地址:cuge.baai.ac.cn
针对传统侧重语言理解能力,评测框架体系扁平化,缺乏系统性多样性,以及过于专注平均数据集性能,覆盖的语言能力、任务和数据集偏少等普遍特点。
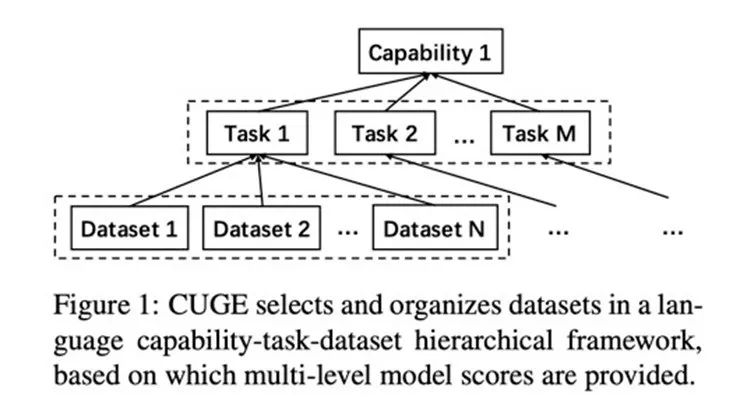
智源指数定位「中文语言」,覆盖自然语言理解和生成两大任务体系,按照「能力- 任务- 数据集」的层次结构筛选和组织高质量数据集,为机器语言能力提供更加全面系统和多层多维的评测标准。
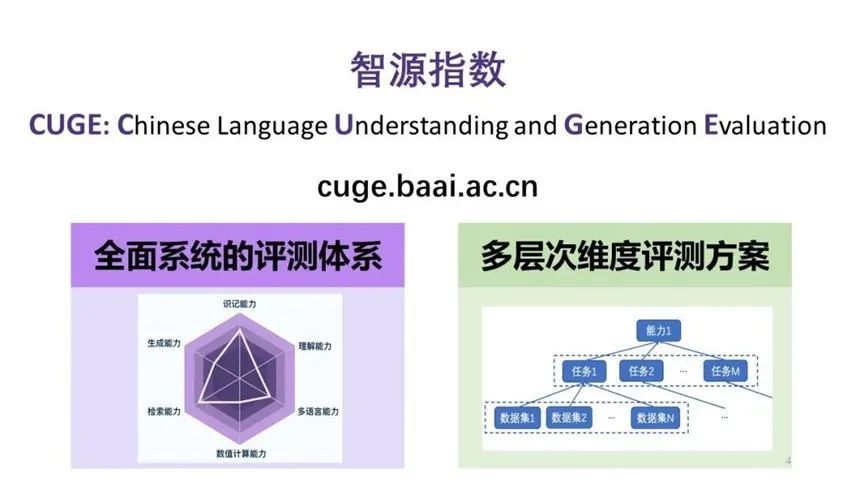
在评分策略上,传统评测基准通常直接将不同数据集上的得分平均得到总体得分,评测维度较为单一。而智源指数基于层次结构,提供了模型在数据集、任务、能力、总体不同层次维度的得分,并通过语言能力雷达图,直观地展示模型语言能力。
一般而言,将不同数据集上的不同指标直接平均,会受到不同数据集和指标不同特性的影响,最终得分也容易被少数得分变化幅度较大的数据集和指标主导,难以有效地全面衡量模型的语言能力进展。
智源指数采用归一化方法计算得分,参考标准基线模型(mT5-small)的得分,计算参评模型的相对得分,最大程度消除不同数据集和指标特性影响。目前智源发布的大规模预训练模型CPM-2,以及mT5-small/large/XXL的评测结果已经在智源指数榜单上公布。
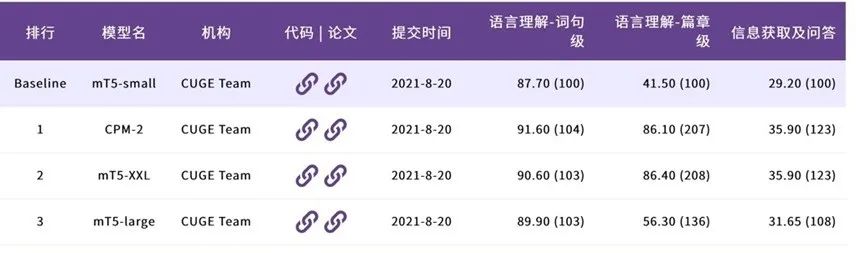
以上可以看出,预训练模型在不同的语言能力表现的差异较大,通用的语言智能仍然有非常大的提升空间。
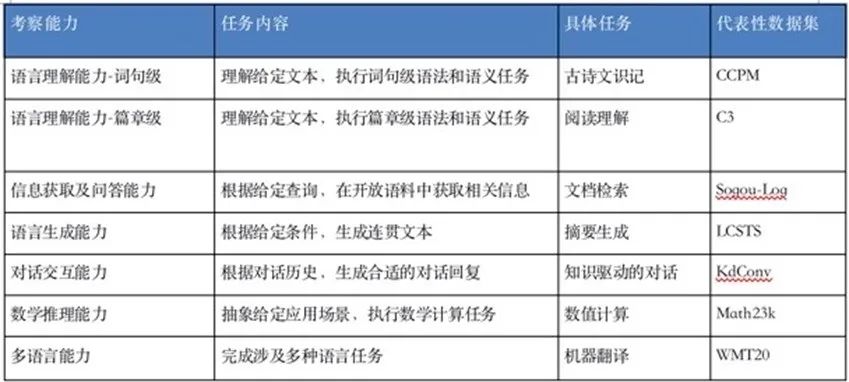
我们知道,基准任务和数据集支持着自然语言处理能力的开发和评估,是NLP工具的驱动力。智源指数覆盖了7 种重要语言能力,17 个主流自然语言处理任务,19个高质量数据集,分别为:

语言理解-词句级:中文分词、中文分词和词性标注、古诗文识记、命名实体识别、实体关系抽取;
语言理解-篇章级:幽默检测、故事情节完形填空、阅读理解;
信息获取及问答:反向词典、开放域问答、文档检索;
语言生成:摘要生成、数据到文本生成;
对话交互:知识驱动的对话生成;
多语言:机器翻译、跨语言摘要;
数学推理:数值计算。
为了让研究人员方便快捷参与评测,智源指数为每个语言能力选择代表性任务和数据集,组成精简榜。相当于在7种语言能力下,为每个语言能力提供一个数据集。包括:
「智源指数」的一个重要的核心点是如何构建高质量、大跨度的标注语言资源库。在发布会现场,山西大学谭红叶教授和北京语言大学杨尔弘教授介绍了两个特色大规模数据集的标注规则和数据质量。
其中,面向可解释评测的高考于都理解数据集GCRC,汇集近10年高考阅读理解测试题包含5000多篇文本、8700多道选择题(约1.5万个选项)。标注信息涉及信息句子级支持事实、干扰项(不正确选项)错误原因、回答问题所需推理能力为三类,可从中间推理、模型能力两方面进行可解释评价。
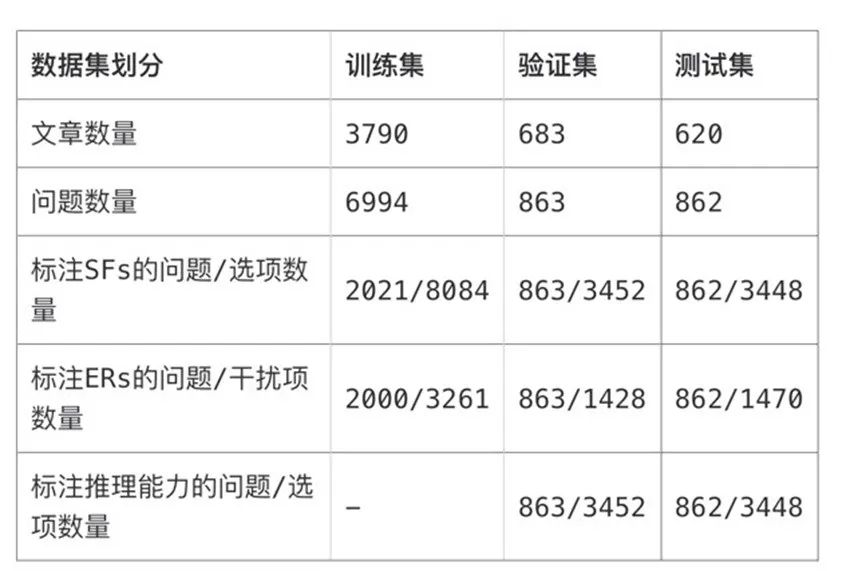
二是面向汉语学习者文本多维标注数据集YACLC。该数据集由北京语言大学、清华大学、北京师范大学、云南师范大学、东北大学、上海财经大学等机构联合构建,其训练集规模高达8000条,每条数据包括原始句子及其多种纠偏标注与流利标注。验证集和测试集规模都为1000条,每条数据包括原始句子及其全部纠偏标注与流利标注。
基于单数据集的榜单能力,未来智源指数还将定期吸纳最新优秀数据集。刘知远表示说,他们还将结合现有的行业力量,建立用户面向数据集和评测结果的反馈、讨论机制,构建起中文高质量数据集社区,推动中文自然语言处理的发展。
3
中文大模型的「风向标」
整个人工智能发展过程中,高质量数据集,科学地评测体系都发挥了重要的作用。当时深度学习在CV领域的崛起,是因为AlexNet模型在ImageNet数据集上刷新SOTA,引发了整个学术界,产业界对深度学习的关注。
类似地,中文自然语言处理要想取得重大突破,至少要知道如何“量化”突破,所以科学标准很重要。此外,一个好的「智源指数」不仅要测计算机的语言能力,更重要的是能够指出计算机的语言能力的发展方向。
刘知远表示,“期待CUGE的指引可以帮助更多中文大模型,寻找到新的突破方向。对于智源指数的发展,我们需要做好顶层设计,放式地吸引更多的优秀学者和机构,不断构建、发布、吸纳更多高质量的中文数据集,才有望建立权威的评测标准。”
为了更好地去支持智源指数的发展,智源研究院搭建了「智源指数工作委员会」,由孙茂松担任主任,穗志方和杨尔弘担任副主任。

目前,委员会单位已经吸纳了国内在自然语言处理方面10余家优势单位,接近20个相关优势研究组,去针对智源指数不断进行改进,力求更加科学、规范、高质量地推进中文自然语言处理技术的标准评测。
智源研究院表示,未来将通过持续的机制创新和服务保障,以“功成不必在我”的理念,建立起更有效的系统化研究环境,促进智源学者们不断成就新发明、新突破,共同创造经得起时间检验的人工智能技术创新和产业“代表作”。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


