
- 1使用微软Phi-3-mini模型快速创建生成式AI应用
- 2Kafka—ISR机制_kafka isr机制
- 3el-date-picker日期选择控件少一天的问题_datepicker选择的日期相差一天
- 42020-12-08 执行npm install报错:npm ERR! fatal: unable to connect to github.com:_linux npm err! fatal: unable to access '': proxy c
- 5PyTorch学习笔记(一)基本建模流程_pytorch plot_function
- 6自然语言处理:ChatGPT 背后的关键技术
- 7MySQL中的sum函数用法实例详解_mysql sum
- 8解决微信小程序报错:request 合法域名校验出错 如若已在管理后台更新域名配置,请刷新项目配置后重新编译项目,操作路径:“详情-域名信息”的方法_开发者工具域名校验
- 9Mac OS平台Clion不支持bits/stdc++.h头文件的解决方法_clion不能用strcpy_s
- 10Codeforces Round #788 (Div. 2)题解_codeforces round 788 (div. 2) f
【2023研电赛】安谋科技企业命题三等奖作品: 短临天气预报AI云图分析系统
赞
踩
本文为2023年第十八届中国研究生电子设计竞赛安谋科技企业命题三等奖分享,参加极术社区的【有奖活动】分享2023研电赛作品扩大影响力,更有丰富电子礼品等你来领!,分享2023研电赛作品扩大影响力,更有丰富电子礼品等你来领!
团队介绍
参赛单位:长沙理工大学
队伍名称:星星梦队
指导老师:文勇军
参赛队员:梅硕,韦慧敏,吴佳欣
获得奖项:三等奖
1 系统可行性分析
1.1 研究背景及意义
我国气候灾害频繁,准确预报和及时预警对社会至关重要。本研究致力于利用深度学习技术,特别是自注意力和Transformer模型,来进行雷达回波图像的时间序列预测,以提高极端天气预测的准确性和时效性。
在此背景下,本研究在二维图像序列中尝试了自注意力和Transformer的应用。我们将卷积自注意力机制与Transformer编码器相结合,实现了雷达回波图像序列的特征聚合和增强。这种方法不仅在时间特征方面表现出色,还兼顾了空间信息的提取,有助于更好地捕捉序列的变化特征。
综上所述,本研究在极端天气预测领域取得了重要进展,通过深度学习技术的创新应用,为提升极端天气预测的准确性和及时性提供了有力手段。

1.2 作品难点与创新点
本作品针对雷达回波图像外推在短时临近降雨预报中的挑战展开研究。传统方法难以捕捉复杂的回波变化,因此采用深度学习技术,以自注意力和Transformer为核心,实现了回波图像序列的特征聚合和时间序列预测。卷积自注意力机制的引入,使模型能更好地理解云层变化。该方法不仅增强时间特征,还综合考虑了空间信息,对极端天气预测有显著提升。综合模型结合Marshall-Palmer公式计算雨量预测。另外,设计了基于Django的web可视化系统,提供实时降雨预报,为国家防灾减灾工作提供支持。
1.3 方案论证与设计
深度学习在图像识别领域广泛应用,研究者尝试将其应用于雷达回波外推任务。针对雷达回波图像的特点,有人使用卷积神经网络(CNN)和循环神经网络(RNN)等模型进行处理。通过基于二维和三维卷积神经网络的方法,从时间和空间维度提取特征,实现雷达回波外推。此外,为解决图像模糊问题,研究引入生成算法,如生成对抗网络(GAN)和变分自编码器(VAE)。这些方法能够更好地捕捉序列数据的时空依赖关系,提高预测准确性。
在此背景下,Google团队提出了Vision Transformer(VIT)模型,将自注意力和Transformer模型应用于计算机视觉。受其启发,本系统将卷积自注意力机制(CSA)应用于Transformer编码子网络,用于雷达回波序列处理。通过该方法,结合时间和空间信息,对序列特征进行聚合和增强。处理后的特征交给基于ConvLSTM的Seq2Seq结构完成外推任务,实现了雷达回波预测。
综上所述,深度学习在雷达回波外推中有广泛应用,结合卷积自注意力和Transformer的方法在时间和空间上进行特征提取和建模,有望提高天气预测精度。
2 系统详细设计
2.1 系统算法模型设计
本系统算法模型要完成的工作为:从过去时段雷达图中提取特征,并通过神经网络从特征中学习雷达图随时间变化的规律,并生成未来时段的预测雷达图像,进而根据预测图像由 Z-R 关系得出具体的气象预测。本系统算法模型实现以下三个部分:
(1)雷达回波图像特征的处理
(2)根据已获取的特征信息对未来图像进行预测与生成
(3)对生成图像准确度与图片质量进行优化
本设计主要构建了特征增强网络与回波图像外推网络共同组成的卷积自注意力回波外推模型。模型总体结构如图所示:

2.1.1雷达图像特征的提取
本系统使用卷积自注意力机制(CSA)构建 Transformer 编码子网络,处理雷达回波序列,对雷达回波图像进行特征的提取
传统的自注意力机制主要被用于文本序列处理,与词嵌入后的 Embedding 向量相比,在处理图像形式的输入时,网络需要同时考虑输入的空间信息。卷积形式的自注意力层以图像整体作为处理对象,避免了简单的拉平操作带来的图像空间特征损失。
当下计算机视觉领域大多数的自注意力计算方法都基本依循nonlocal-module的模式,即将二维图片堆叠后后送入注意力层,这种方式的自注意力计算建模的是单张图片内像素点间的注意力分布关系。但在序列领域,自注意力机制还要建模序列时间步之间的关系。为了达到这一目标,CSA将加入注意力运算的最小计算单位固定在了包含通道、宽、高的3D图片张量。
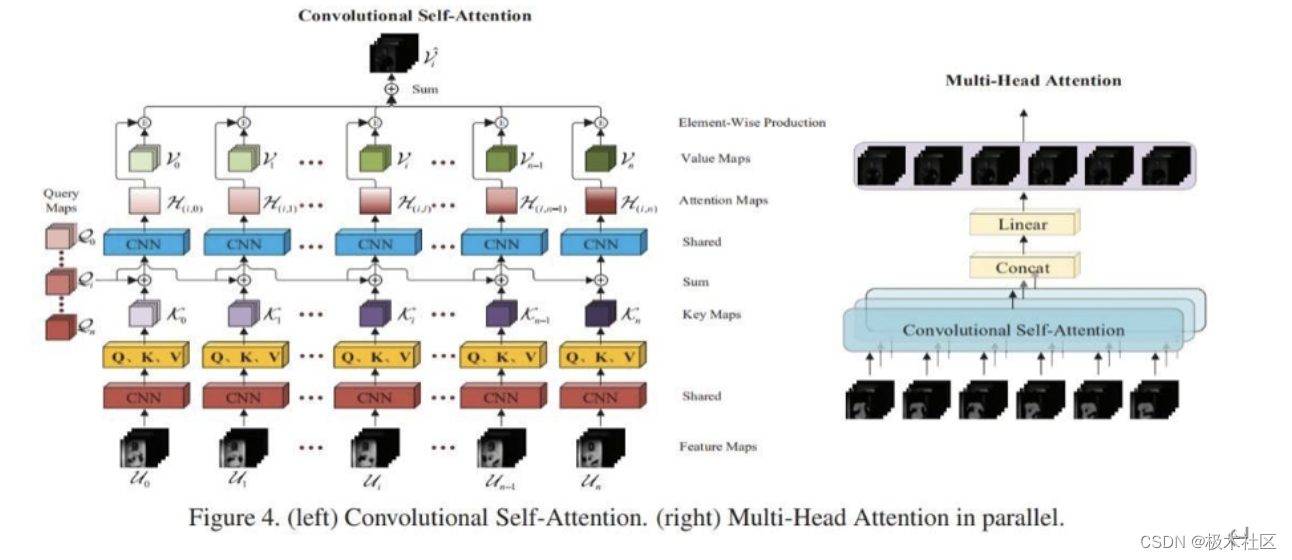
2.1.2 雷达图像特征的处理
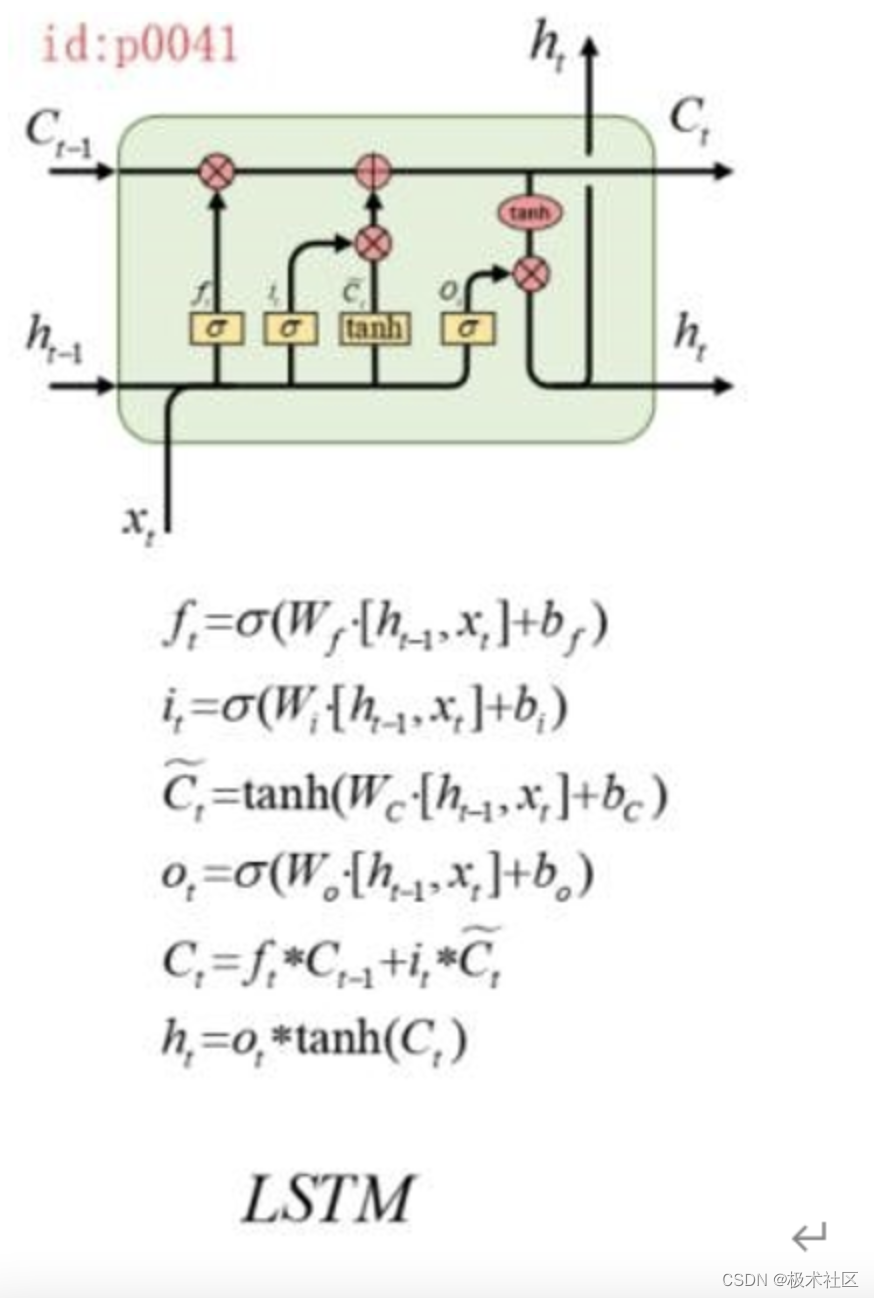
考虑到样本为连续时间步的图像序列,本课题拟采取深度学习中用以处理序列问题的 Seq2Seq 模型。以多层 LSTM 作为模型编解码网络,在编码网络中将各时间步隐藏变量 Z 的作为网络输入,学习其长期依赖与短期输入影响,并将各层最后一个 LSTM 细胞的细胞状态 Ct 作为作为解码网络的初始状态,对未来时间步对应的隐藏变量 Z 进行预测。
(1)LSTM 细胞:LSTM 细胞由“遗忘门”、“输入门”、“输出门”三个部分组成,由图所示,C 表示各 LSTM 细胞的细胞状态(cell state),h 表示各细胞传递出的隐藏状态(hidden state)。遗忘门接收上个细胞的细胞状态与隐藏状态,并决定在多大程度下将其纳入影响考虑范围;输入门通过对输入序列与遗忘门运算结果进行计算,得到备选向量,并将之作为本 LSTM 细胞的内部参数,最后将之通过输出门进行输出。LSTM 细胞结构如下图:
2.1.3 预测图像生成与优化
针对现有预测图像较为模糊的问题,研究预测图像质量优化方法。主要研究内容包括:软性注意力机制、生成对抗网络鉴别器模型,构建预测图像质量优化的解决方案,获得清晰度较高、包含较多特征信息的输出雷达回波图序列。
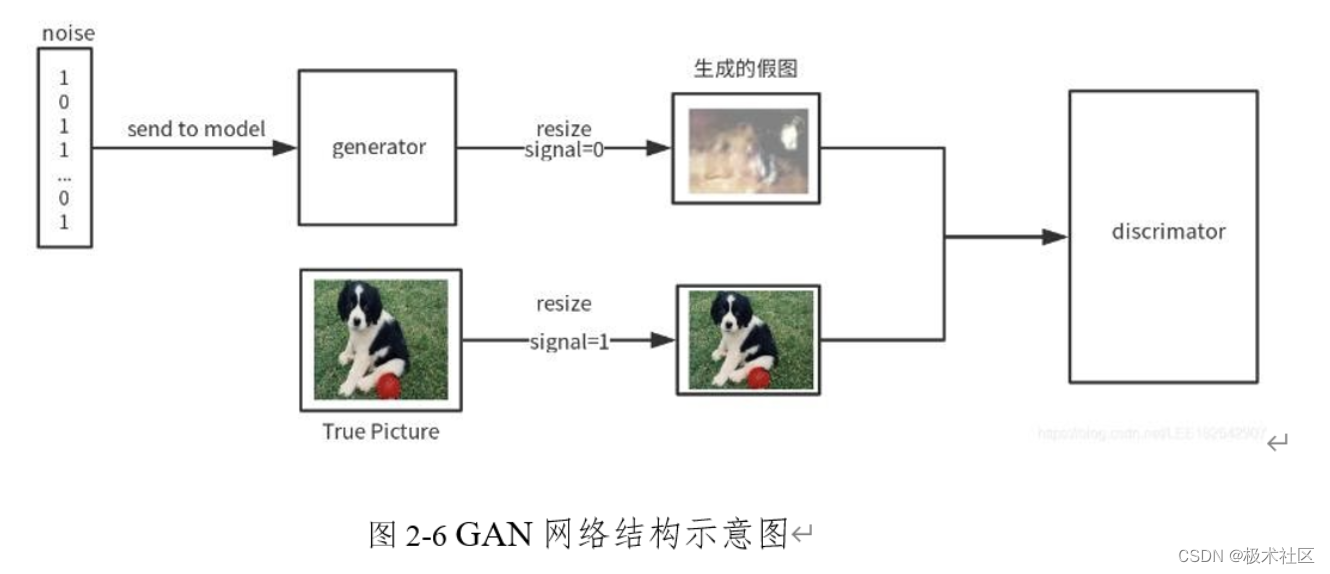
生成对抗网络:生成对抗网络(GAN)作为一种非监督学习方式,是由生成器G、分类器D这两套独立的神经网络所组成。生成器G用于生成假样本,分类器D 用于分辨生成器G所生成样本是真实数据还是虚假数据。每一次判断的结果都会作为反向传播的输入到G、D之中,如果D判断正确,那就需要调整G的参数从而使得生成的假数据更为逼真;如果D判断错误,则需调节D的参数,避免下次类似判。
断出错。训练会一直持续到两者进入到一个均衡和谐的状态。GAN模型的最终目的是得到一个质量较高的自动生成器和一个判断能力较强的分类器。
本项目的预测优化核心思想为:将前步预测生成操作视为GAN的生成器,将预测出图像视为假数据,与对应时间步的真实数据共同输入分类器D进行博弈,从而通过反向传播不断优化预测图形生成过程的中间参数,进而让得到的雷达回波预测图像更为可信。
在预测图像生成方面,当前被广泛采用的模型都有一定程度的模糊效应,对后续的降雨量预测准确度产生影响。因图片质量同为分类器判别时考虑的重要因素,故在此过程中可以达到优化图片清晰度的目的。GAN网络结构示意图如下图:
2.2 系统前端框架设计
为了让用户获得更好的用户体验,对预测结果获得更加直观的感受。系统设计了前端的展示界面。将进行实验所采集的样本和预测结果直接展示给用户和管理员。
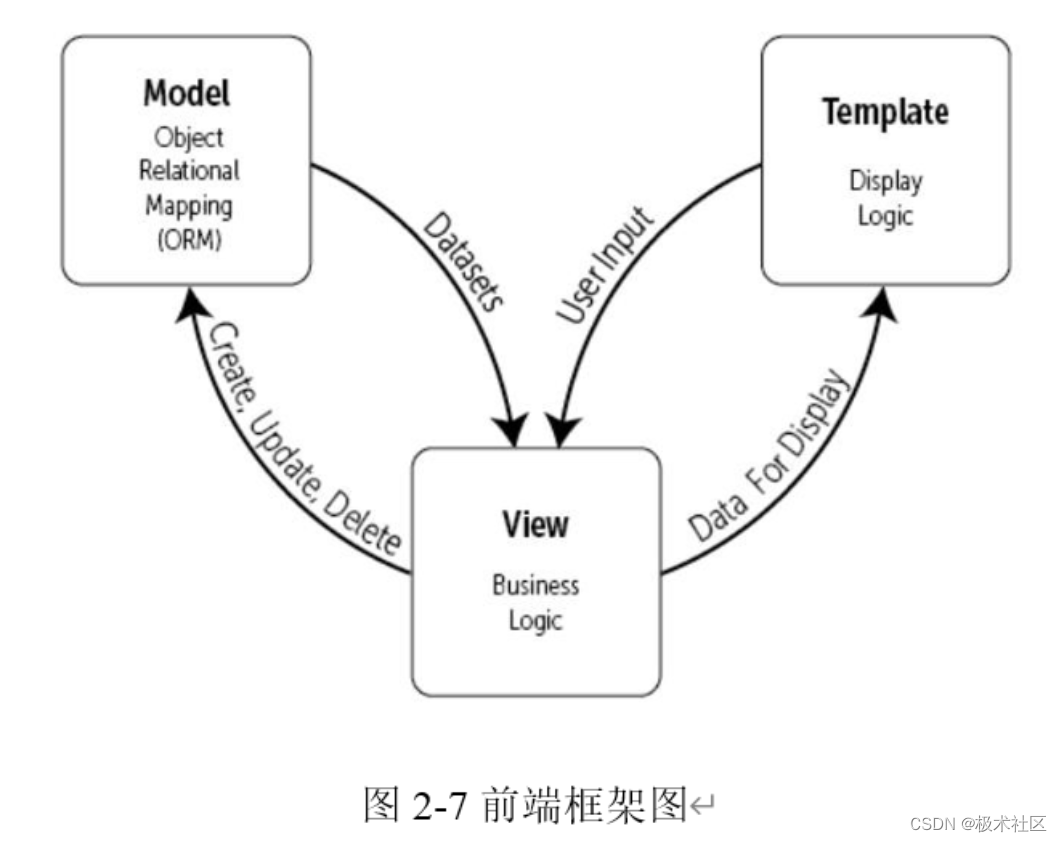
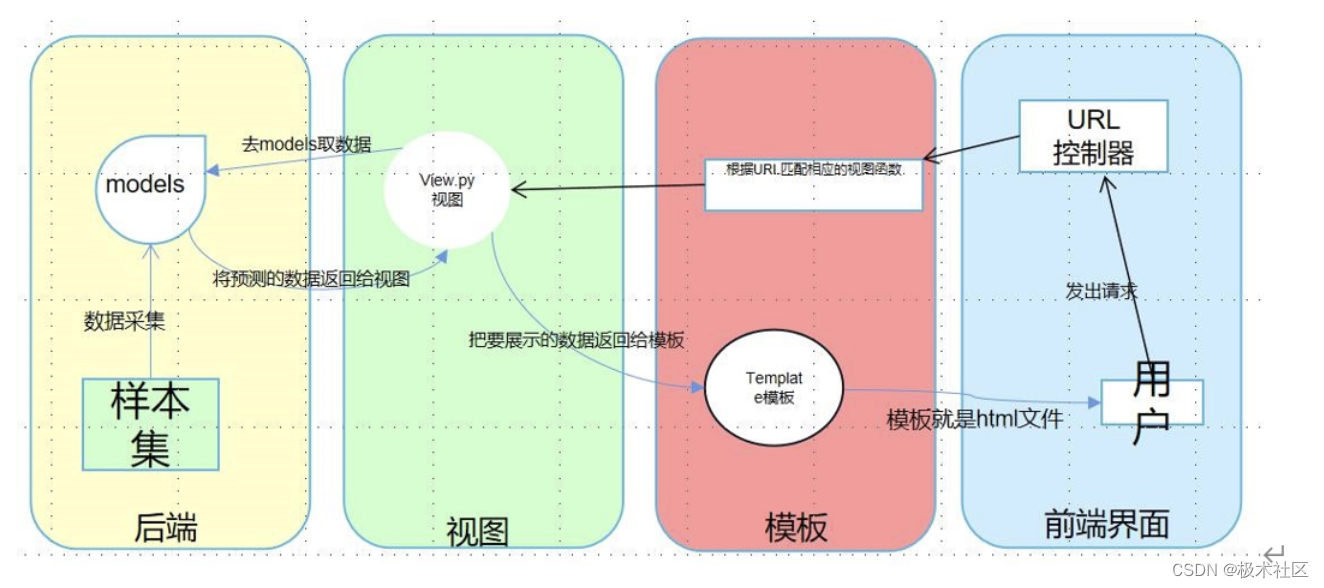
本次设计采用了 Django 作为系统的 web 应用框架。Django 是一个由 Python 编写的一个开放源代码的 Web 应用框架。Django 框架为了保证各组件之间的松耦合关系采用了 MTV 模式。
M 表示模型(Model):编写程序应有的功能,负责业务对象与数据库的映射(ORM)。
T 表示模板(Template):负责如何把页面(html)展示给用户。
V 表示视图(View):负责业务逻辑,并在适当时候调用 Mode 和 Template。
除了以上三层之外,还需要一个 URL 分发器,它的作用是将一个个 URL 的页面请求分发给不同的 View 处理,View 再调用相应的 Model 和 Template。
MTV 的响应模式如下所示:
系统运作的整体流程:
用户通过前端界面向我们的服务器发起一个请求(request),这个请求通过 url 映射到与之对应的视图函数:
a.如果不涉及到数据调用,那么这个时候视图函数直接返回一个模板也就是一个网页给用户。
b.如果涉及到数据调用,那么视图函数调用模型,模型去数据库查找数据。
在数据库得到样本的参数之后,使用训练好的模型对未来的雷达回波图像进行预测得到预测的结果,然后逐级返回。视图函数把返回的样本和预测结果填充到模板中空格中,最后返回网页给用户。用户操作流程图:
总结
当谈及序列建模和特征提取,自注意力机制和Transformer模型无疑是近年来引人瞩目的技术。虽然自注意力在文本领域已经取得了显著成就,但在二维图像领域的应用仍相对有限。而本模型不仅在二维图像领域尝试了自注意力的应用,还将其与Transformer编码器相结合,取得了令人振奋的结果,实现了对雷达回波序列的有效特征提取和建模,为序列预测任务带来了新的思路和方法。这一研究不仅丰富了自注意力的应用领域,也为序列建模领域的发展贡献了有益的探索。
参加极术社区的【有奖活动】分享2023研电赛作品扩大影响力,更有丰富电子礼品等你来领!,分享2023研电赛作品扩大影响力,更有丰富电子礼品等你来领!
更多研电赛作品分享请关注IC技术竞赛作品分享.

