
- 1前端-JS基础之判断_前端if判断
- 2Git工具使用、配置、团队开发_git graph 插件 配置
- 3打开 Java 新的大门,Solon v2.5.10 发布
- 4Error updating database. Cause: java.sql.SQLIntegrityConstraintViolationException: Duplicate entry_error updating database. cause: java.sql.sqlintegr
- 5蓝桥杯单片机零基础到国二经验分享_蓝桥杯单片机什么水平能得奖
- 6常见电脑显示器分辨率及其比例_1920x1440是几比几
- 7打印机-STM32版本 硬件部分
- 8c语言中ai是什么,AICODE在C语言教学中应用研究.doc
- 9php使用imagemagick处理图片圆角_php imagemagick圆角图片
- 10【数据结构】Map和Set_set和map
【2023-2024年最新教程】yolov5_obb: 旋转目标检测从数据制作到终端部署全流程教学_yolo旋转目标检测
赞
踩
导读
yolov5_obb 是 yolov5 目标检测框架的一个变种,支持旋转目标检测任务(Oriented Bounding Boxes,OBB),旨在生成更好拟合具有角度位置的物体预测结果。考虑到目前全网上关于此方面的资料相对较少,鱼龙混杂,不是比较老旧、乱七八糟,就是一言不合就付费查看,交钱看个寂寞,实在是不忍直视。因此,此篇博文旨在提供一个从数据集制作、划分、安装、训练、验证、部署保姆级教程,帮助大家从0到1快速完成项目的上手和开发,满足日常工作和学习的需求。
数据集制作
工具介绍
X-AnyLabeling不仅是一个标注工具,它还是自动数据标注未来的一大飞跃。它的设计不仅简化了标注过程,还集成了尖端的AI模型,以获得更出色的结果。X-AnyLabeling 专注于实际应用,力求提供一个工业级的、功能丰富的工具,可帮助开发人员自动标注和处理各种复杂任务的数据。
在最新的 v2.2.0 版本中,X-AnyLabeling 已经完美支持了旋转框的标注,同时提供全方位的角度显示,实操体验方面也与经典的 roLabelImg 完全保持一致,可无缝迁移,且支持直接导出 DOTA 格式的标签文件,无需转换一键训练。最后,工具中还提供了 yolov5_obb 自定义模型的加载运行,可极大提升数据标注效率,形成快速闭环。
喜欢的小伙伴欢迎点个
star,持续关注后续更丰富的功能更新。
工具安装
git clone https://github.com/CVHub520/X-AnyLabeling
cd X-AnyLabeling
pip install -r requirements.txt
# pip install -r requirements-gpu.txt
python anylabeling/app.py
- 1
- 2
- 3
- 4
- 5
使用教程
- 按下快捷键 “O” 来创建一个旋转形状。
- 打开编辑模式(快捷键:“Ctrl+J”)并单击选择旋转框。
- 通过快捷键 “zxcv” 旋转所选框,其中:
- z:大角度逆时针旋转
- x:小角度逆时针旋转
- c:小角度顺时针旋转
- v:大角度顺时针旋转
高级用法
此外,您可以使用训练好的模型批量预标记当前数据集。
- 按下快捷键 “Ctrl+A” 打开自动标注模式;
- 选择一个适当的默认模型或加载自定义模型。
- 按下快捷键 “Ctrl+M” 运行所有图像一次。
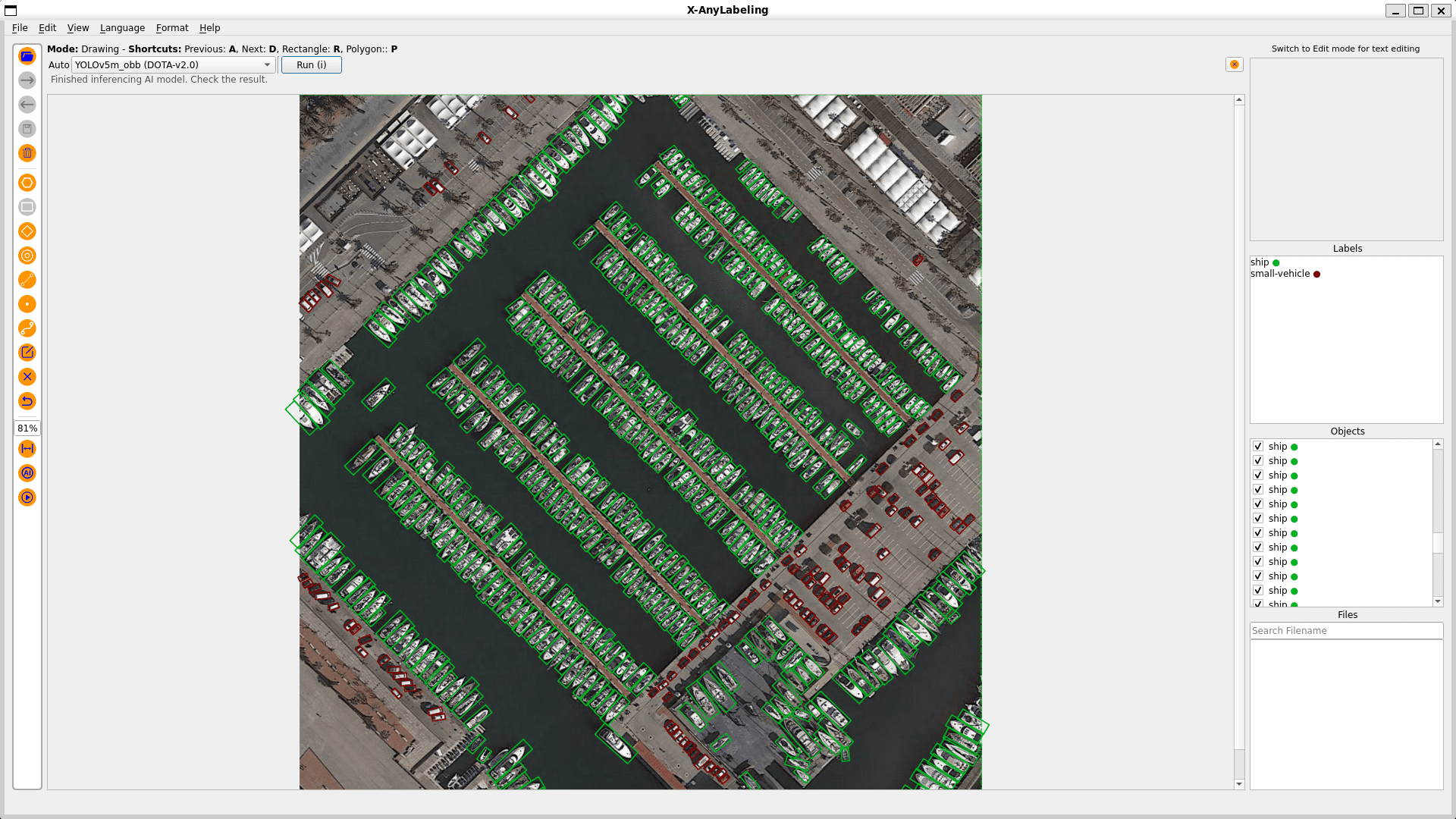
导出DOTA标签,请参考此文档。
入门指南
准备工作
-
环境要求
- Python 3.7+
- PyTorch ≥ 1.7
- CUDA 9.0或更高版本
- Ubuntu 16.04/18.04
-
安装开始
a. 创建一个conda虚拟环境并激活它:
conda create -n yolov5_obb python=3.8 -y
source activate yolov5_obb
- 1
- 2
b. 确保您的CUDA运行时API版本≤CUDA驱动程序版本。 (例如11.3 ≤ 11.4)
nvcc -V
nvidia-smi
- 1
- 2
c. 根据您的机器环境,根据官方说明安装PyTorch和torchvision,并确保cudatoolkit版本与CUDA运行时API版本相同,例如:
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu116
nvcc -V
python
>>> import torch
>>> torch.version.cuda
>>> exit()
- 1
- 2
- 3
- 4
- 5
- 6
d. 克隆最新版本的YOLOv5_OBB存储库。
git clone https://github.com/CVHub520/yolov5_obb.git
cd yolov5_obb
- 1
- 2
e. 安装yolov5-obb。
pip install -r requirements.txt
cd utils/nms_rotated
python setup.py develop # 或者 "pip install -v -e ."
- 1
- 2
- 3
注意:
- 对于Windows用户,请参考此问题,如果在你在生成 utils/nms_rotated_ext.cpython-XX-XX-XX-XX.so方面遇到困难。
- 需要注意的是,笔者这里对
poly_nms_cudaCUDA实现重构了一遍,如果你使用的是 hukaixuan19970627 实现的原始版本,大概率是会编译不通过,可参考着修改下,但建议直接使用此修改后的版本,避免冲突。
- DOTA_devkit [可选]
如果您需要分割高分辨率图像并进行评估,建议使用以下工具:
cd yolov5_obb/DOTA_devkit
sudo apt-get install swig
swig -c++ -python polyiou.i
python setup.py build_ext --inplace
- 1
- 2
- 3
- 4
数据集划分
准备自定义数据集文件
注意:确保标签格式为[polygon classname difficulty],例如,您可以将difficulty=0,除非另有说明。
x1 y1 x2 y2 x3 y3 x4 y4 classname diffcult
1686.0 1517.0 1695.0 1511.0 1711.0 1535.0 1700.0 1541.0 large-vehicle 1
- 1
- 2
- 3
然后,修改路径参数并运行此[脚本] (./divide.py),如果不需要拆分高分辨率图像。否则,您可以按以下步骤操作。
cd yolov5_obb
python DOTA_devkit/ImgSplit_multi_process.py
- 1
- 2
确保您的数据集组织在如下所示的目录结构中:
.
└── dataset_demo
├── images
│ └── P0032.png
└── labelTxt
└── P0032.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
最后,您可以创建一个自定义的数据yaml文件,例如[yolov5obb_demo.yaml] (./data/yolov5obb_demo.yaml)。
注意:
- DOTA是一个高分辨率图像数据集,因此需要在训练/测试之前进行分割,以获得更好的性能。
- 对于单类问题,建议添加一个"None"类,实际上将其变为一个2类任务,例如DroneVehicle_poly.yaml。
训练/验证/检测
在正式开始训练任务之前,请遵循以下建议:
- 确保将输入分辨率设置为32的倍数。
- 默认情况下,将批处理大小设置为8。如果将其增加到16或更大,请调整框丢失的缩放因子,以帮助收敛
theta。
-
要在多个GPU上使用分布式数据并行(DDP)模式进行训练,请参考此shell[脚本] (./sh/ddp_train.sh)。
-
要训练原始数据集演示,而不分割数据集,请参考以下命令:
python train.py \
--weights weights/yolov5n.pt \
--data data/task.yaml \
--hyp data/hyps/obb/hyp.finetune_dota.yaml \
--epochs 300 \
--batch-size 1 \
--img 1024 \
--device 0 \
--name /path/to/save_dir
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 要检测自定义图像文件/文件夹/视频,请参考以下命令:
python detect.py \
--weights /path/to/*.pt \
--source /path/to/image \
--img 1024 \
--device 0 \
--conf-thres 0.25 \
--iou-thres 0.2 \
--name /path/to/save_dir
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意:有关更多详细信息,请参考[此文档] (./docs/GetStart.md)。
部署
- 导出*.onnx文件:
python export.py \
--weights runs/train/task/weights/best.pt \
--data data/task.yaml \
--imgsz 1024 \
--simplify \
--opset 12 \
--include onnx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Python
- 使用onnxruntime检测导出的onnx文件:
python deploy/onnxruntime/python/main.py \
--model /path/to/*.onnx \
--image /path/to/image
- 1
- 2
- 3
C++
- 进入目录:
cd opencv/cpp
.
└── cpp
├── CMakeLists.txt
├── build
├── image
│ ├── demo.jpg
├── main.cpp
├── model
│ └── yolov5m_obb_csl_dotav15.onnx
└── obb
├── include
└── src
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意,建议使用OpenCV版本4.6.0或更新,v4.7.0已成功测试。
Eigen是一个高性能的C++模板库,专用于线性代数运算,支持矩阵和向量操作,具有自然的C++语法、无依赖性和跨平台特性,广泛应用于科学计算、图形学和机器学习等领域。
- 将图像和模型文件放在指定目录中。
- 根据您的特定要求和用例修改CMakeLists.txt、main.cpp和yolo_obb.h文件的内容。
- 运行演示:
mkdir build && cd build
cmake ..
make
- 1
- 2
- 3
对于 OpenVINO 或者 TensorRT 或者移动端部署,原理是一样的,只需要改下 engine 那块即可。
模型库

同时提供了 *.pt 和 *.onnx 文件,方便大家下载。

总结
今天为大家介绍了构建旋转目标检测任务的整个pipeline,如果你在这个过程中碰到任何问题,可在 github issue 反馈,需要交流学习的欢迎添加微信:ww10874,备注yolov5_obb,非诚勿扰。

