
- 1SQL Server 2008 R2 数据库下载,安装,设置视频教程(SQL2008)_server 2008r2数据库下载
- 2记录坑:SpringDateJpa sql生成日期格式错误_jpa是sql 日期data类型
- 3解决问题:电脑已安装了git,vscode识别不到_vscode找不到git
- 4一文带你了解MySQL的MySQL的聚合函数使用
- 5地图开发笔记一
- 6如何打造一个高效的研发团队_如何打造研发引领团队
- 7Hadoop安装与伪分布式配置_头歌云计算配置开发环境 - hadoop安装与伪分布式
- 8daoker 简单操作
- 9wifi协议_wifi的协议和速度
- 10【Flutter】如何更改 Flutter 应用的启动图标_flutter_launcher_icons
Windows下Spark开发环境的搭建_windows搭建spark环境
赞
踩
1.Spark概述
- Spark是一个快速、通用、可扩展的大数据处理引擎,最初由加州大学伯克利分校的AMPLab开发。
- Spark提供了一种基于内存的分布式计算模型,能够在大规模数据集上进行高效的数据处理、机器学习和图形计算等任务。
- Spark支持多种编程语言,包括Java、Scala、Python和R等,同时也提供了丰富的API和工具,如Spark SQL、Spark Streaming、MLlib和GraphX等,方便开发人员进行数据处理和分析。
- Spark的优势在于其处理速度快、易于使用、可扩展性好,已经被广泛应用于大数据领域。
2.安装Java JDK
首先需要安装Java JDK,Spark运行需要Java 8或以上版本。可以从Oracle官网下载Java JDK安装包,安装过程中需要设置环境变量JAVA_HOME.
2.1 Java环境变量:
| JAVA_HOME | C:\java\jdk1.8.0_201 |
| 在PATH中添加 | %JAVA_HOME%\bin |
3.下载Spark
在Spark官网下载Spark二进制包,选择适合自己系统的版本,下载后解压到本地目录。
4.配置Spark环境变量
注意:如果下载的Spark版本>=2.3,建议进一步添加环境变量SPARK_LOCAL_HOSTNAME,值为localhost
| 系统环境变量中 | 添加SPARK_HOME | 值为Spark解压后的目录路径 如:D:\spark |
| 在Path中 | %SPARK_HOME%\bin | %SPARK_HOME%\sbin |
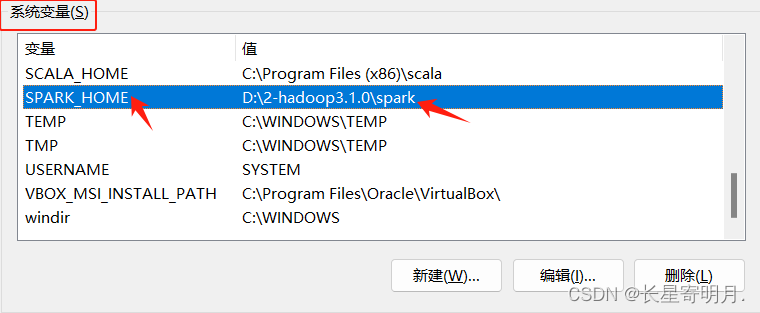
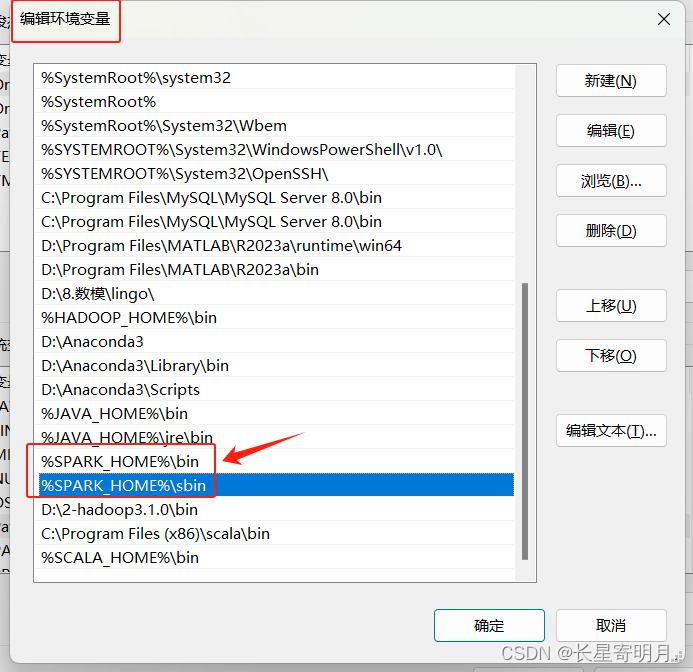
在环境变量配置完之后再进行文件配置:
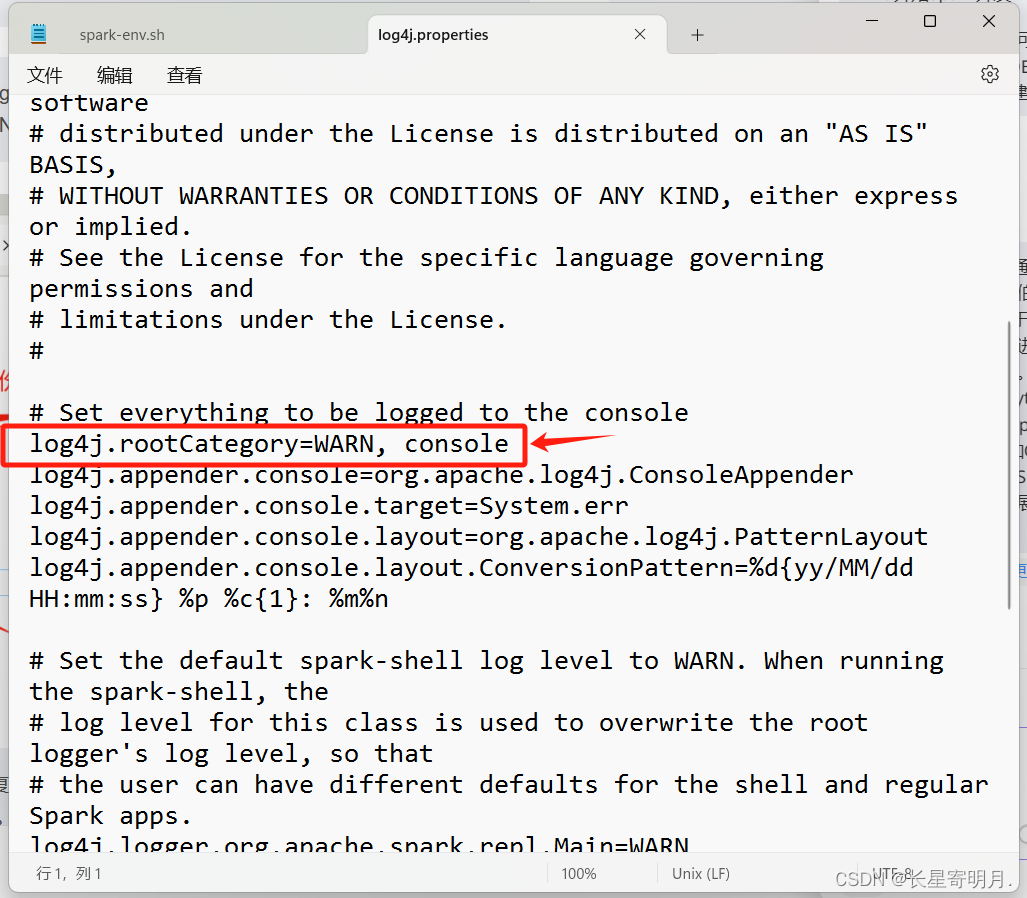
1.进入Spark的配置目录conf,复制一个log4j.properties.template文件并命名为log4j.properties,打开log4j.properties文件,进行如下修改
将配置文件中的:# log4j.rootCategory=INFO, console
修改为:log4j.rootCategory=WARN, console


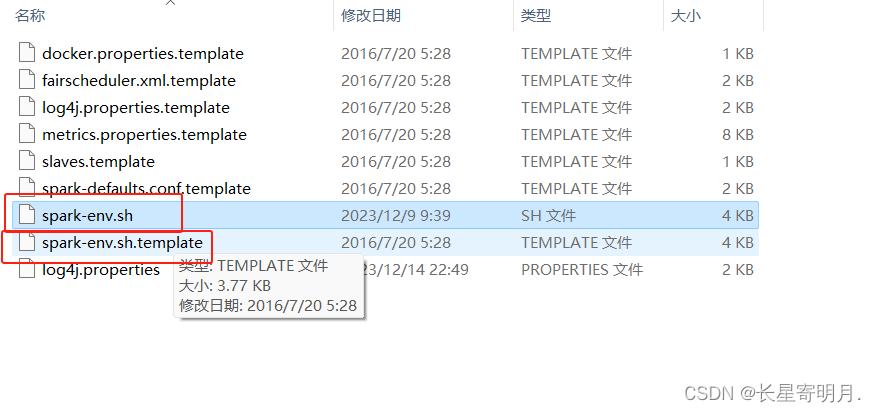
2.在Spark的配置目录conf,复制一个spark-env.sh.template文件并命名为spark-env.sh,打开并增加以下一行代码。
SPARK_LOCAL_IP = 127.0.0.1

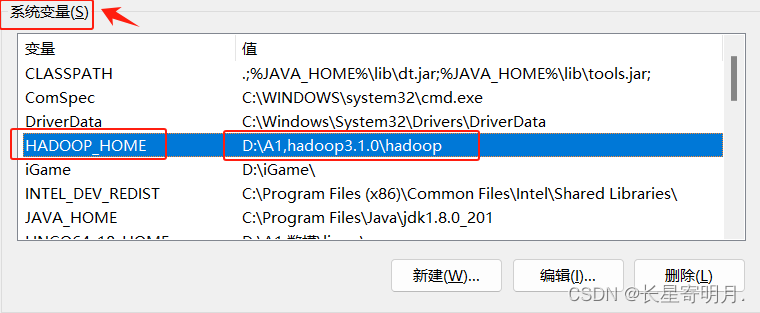
5.配置Hadoop环境变量
如果使用Hadoop作为分布式文件系统,需要配置Hadoop环境变量.
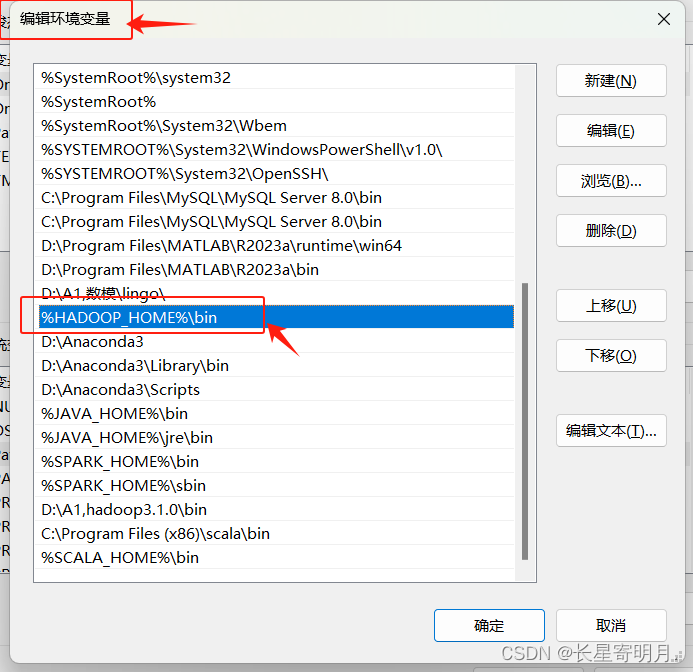
| 系统环境变量中 | HADOOP_HOME | 值为Hadoop解压后的目录路径, 如:D:\A1,hadoop3.1.0\hadoop |
| 在Path中 | %HADOOP_HOME%\bin |
6.测试Spark安装
win+R打开命令行窗口,输入spark-shell,如果出现Spark的交互式Shell,则说明Spark安装成功。

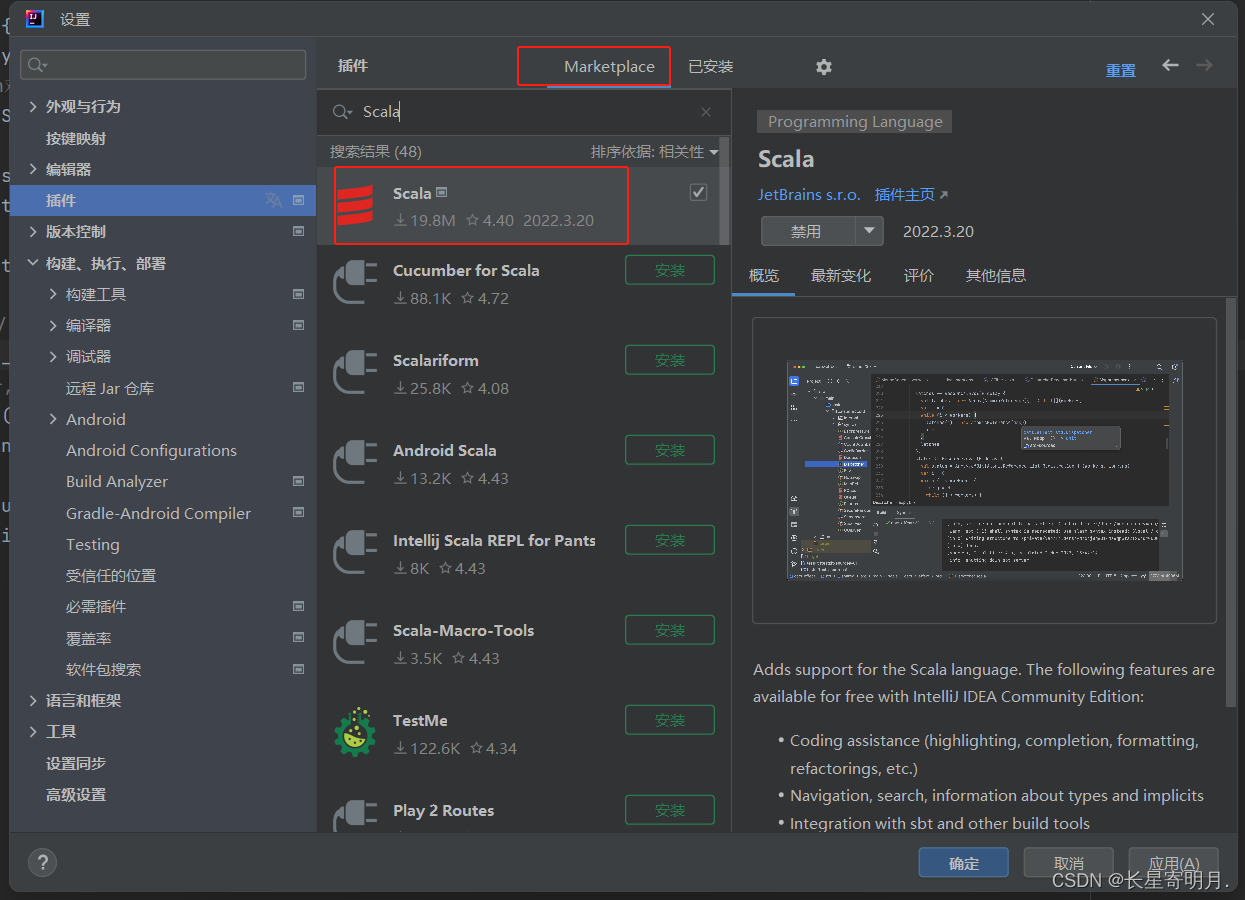
7.配置IDE开发环境
可以使用Eclipse或IntelliJ IDEA等IDE进行Spark开发,需要安装Scala插件和Spark插件。
安装步骤:
1.安装Scala插件:在IDE中选择菜单Help -> Eclipse Marketplace,搜索Scala插件,安装后重启IDE。
2.安装Spark插件:在IDE中选择菜单File -> Settings -> Plugins,搜索Spark插件,安装后重启IDE。
8.开始Spark开发
完成以上步骤后,就可以开始Spark开发了。可以使用Spark Shell或IDE进行开发和调试,也可以使用maven或sbt等构建工具进行项目管理和打包。


