
- 12024最新版使用PyCharm搭建Anaconda_pycharm2024.1选择anaconda环境
- 2【Linux】目录结构详解_linux目录结构
- 3国内各种免费AI聊天机器人(ChatGPT)推荐(中)_chat人工智能免费入口
- 4数据仓库 vs 数据湖 vs 湖仓一体:如何基于自身数据策略,选择最合适的数据管理方案?
- 5unicode详解
- 6使用docker-compose部署springboot jar包_docker-compose部署定时任务jar包
- 7DRL--算法合集
- 8【洋哥带你玩转线性表(一)——顺序表】_typedef int datatype
- 9(附完整代码)Java学生信息管理系统结合图形界面展示_java学生管理系统代码
- 10java 邮件 附件_Java发送邮件(带附件)
Flink的安装、项目创建、任务打包和部署完整实现,任务实现使用JAVA语言_flink 搭建
赞
踩
Flink资源下载地址
一、本地模式安装Flink
1、在Linux服务上,创建flink文件夹
mkdir flink2、上传文件并解压
tar -zxvf flink-1.14.6-bin-scala_2.11.tgz
解压完成后,如图:

3、启动Flink
进入到解压目录下,执行以下脚本:
./bin/start-cluster.sh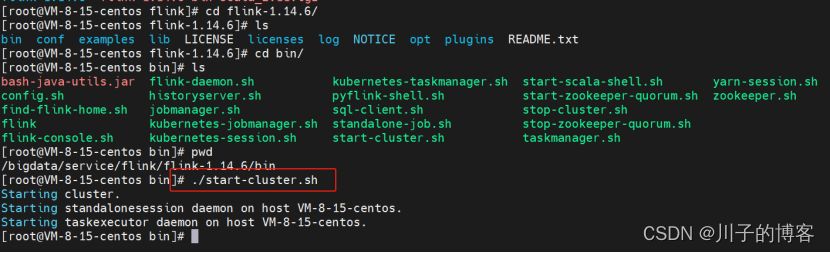
启动成功,通过jps查看服务信息:
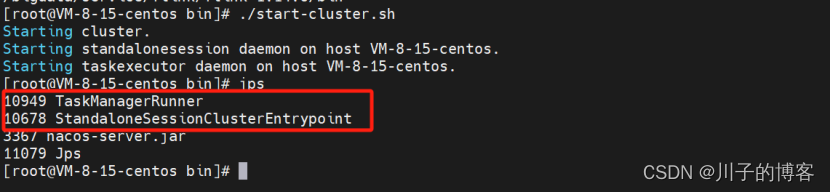
4、访问Flink
在浏览器中访问服务器8081端口即可查看Flink的WebUI,
比如http://82.xxx.xxx.xxx:8081/,从WebUI中可以看出,当前本地模式的Task Slot数量和TaskManager数量。访问结果如下图所示:
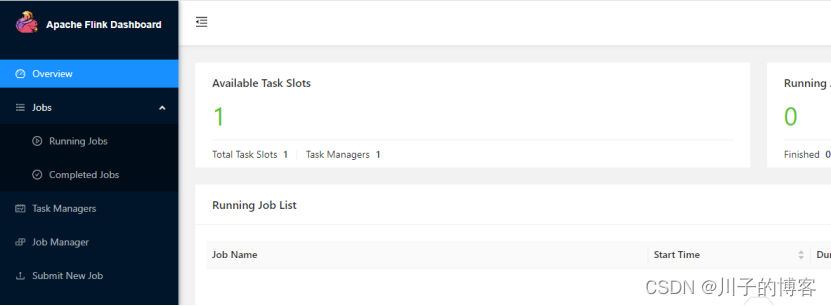
5、停止Flink
./bin/stop-cluster.sh二、创建Flink任务
1、不同的Main方法
创建Flink的main方法和Springboot项目中main方法的依赖是不同的,在pom.xml文件中需要注意。区别主要如下:
- Flink创建Java任务的main方法和Spring Boot的main方法之所以不同,是因为它们服务于不同的目的和框架。
- 在Flink中,创建Java任务的main方法主要用于定义和配置Flink作业的执行逻辑。这个main方法通常包含了Flink的核心API调用,例如创建数据源、定义转换操作和设置输出等。Flink作业的执行逻辑会在Flink集群上进行分布式计算。
- 而Spring Boot的main方法则是用于启动一个基于Spring框架的应用程序。Spring Boot主要用于开发Web应用或者其他类型的企业级应用。在Spring Boot的main方法中,你可以初始化Spring容器、配置各种组件、定义路由规则等。Spring Boot应用程序通常会运行在一个嵌入式的服务器上,如Tomcat或Jetty。
总结来说,Flink的main方法用于定义分布式计算任务的执行逻辑,而Spring Boot的main方法用于启动基于Spring框架的应用程序。
2、创建Flink项目
使用Maven命令创建一个项目,再使用Intellij Idea打开该项目,打开cmd输入:
| mvn org.apache.maven.plugins:maven-archetype-plugin:2.4:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.8.1 -DgroupId=com.myflink -DartifactId=flink-study-scala -Dversion=0.1 -Dpackage=quickstart -DinteractiveMode=false |
开始执行:
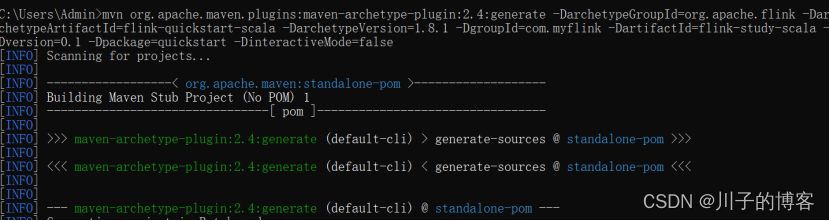

创建完成,目录结构:

三、创建Flink任务
实现kafka同步数据到sink,创建main方法,大致项目结构如下:
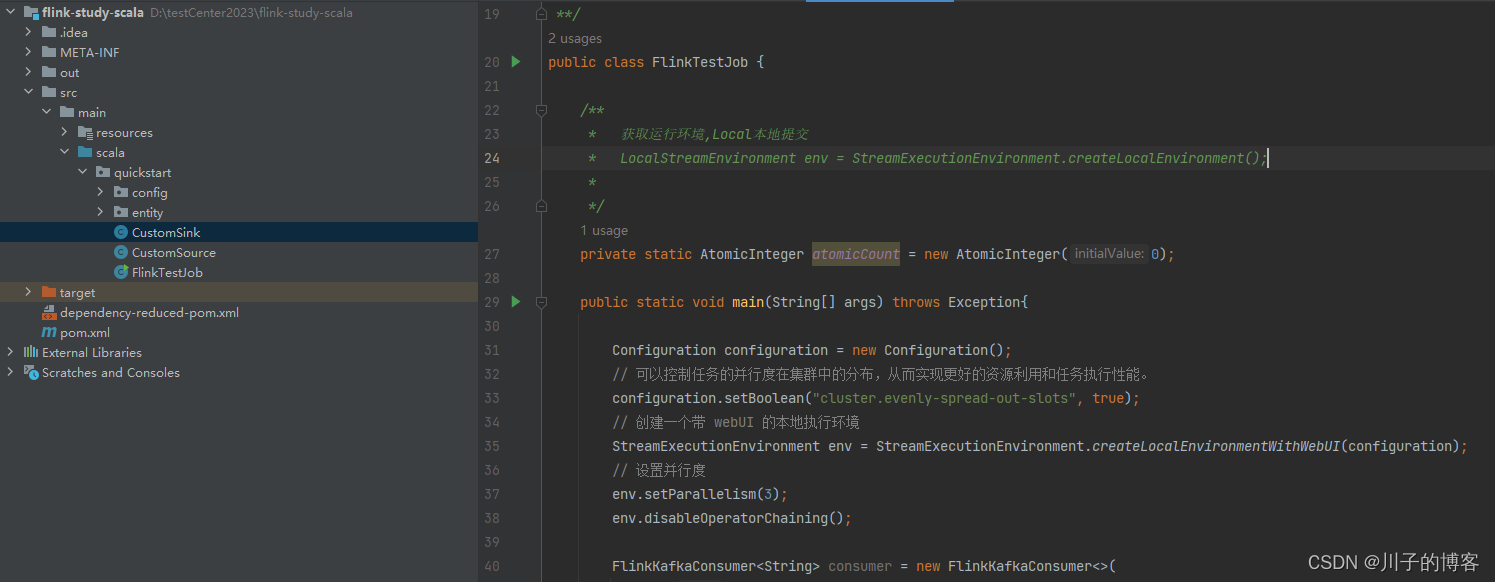
启动main方法,在kafka生产数据:
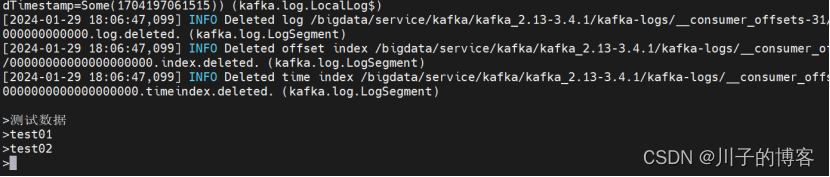
打印信息:

四、Flink任务打包
1、打开项目,找到project structure: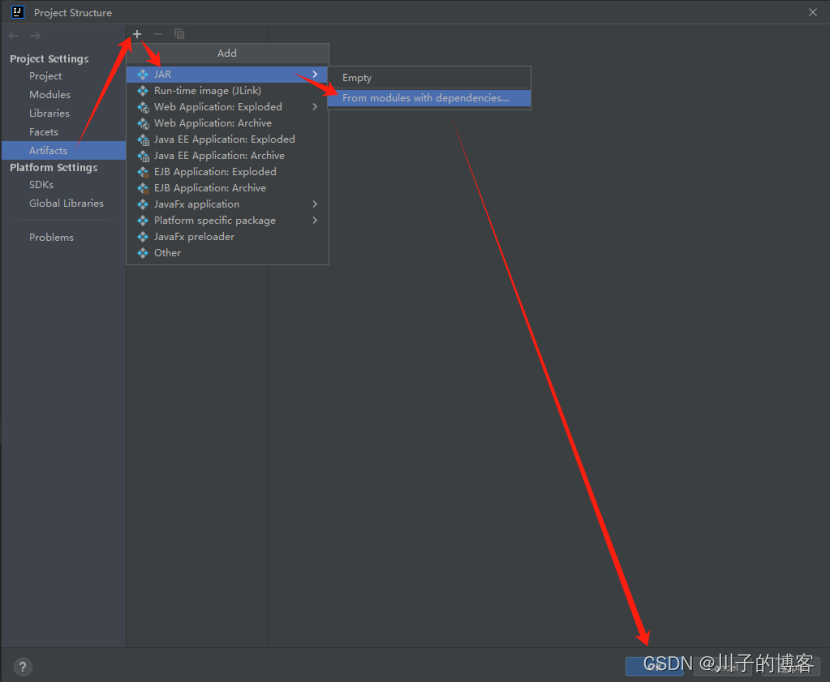
2、然后选择主类,点击应用Apply:
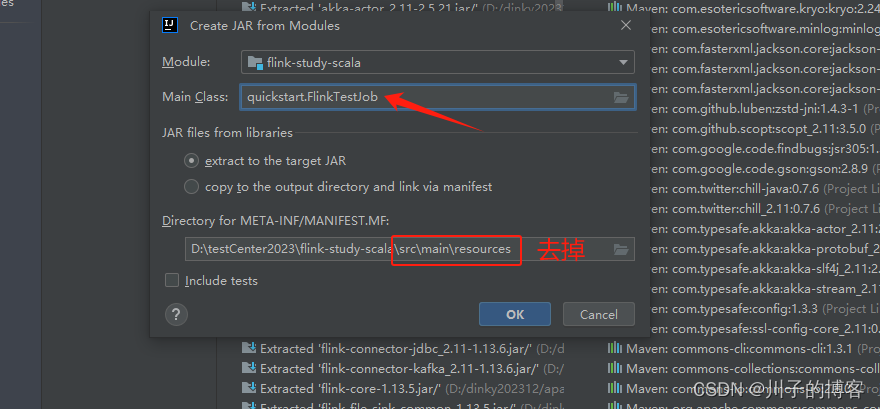
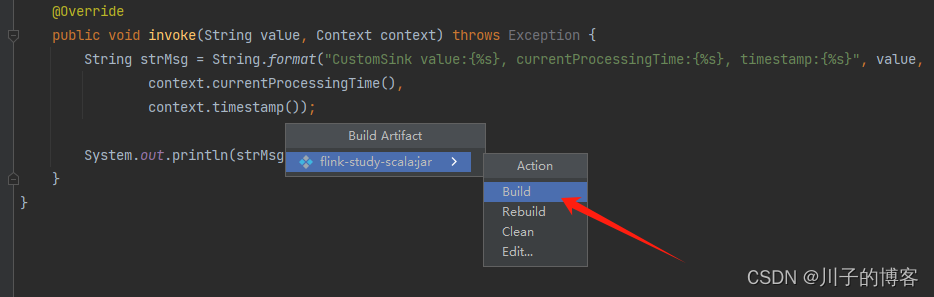
3、构建服务

然后会继续弹出,点击Build
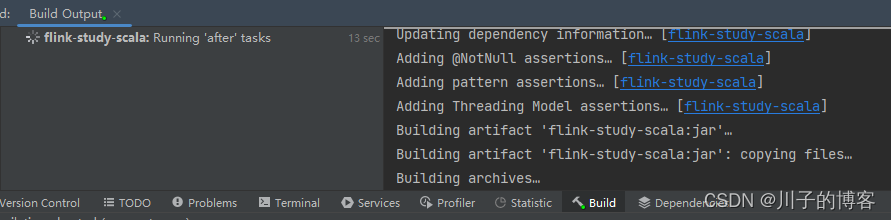
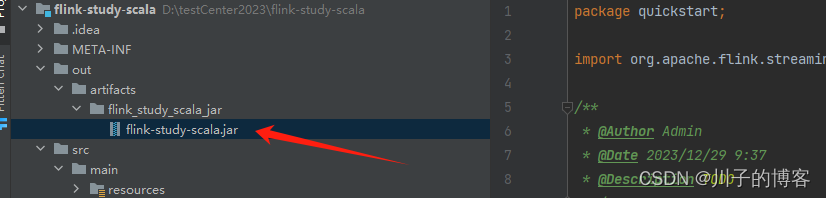
4、构建成功:
五、Flink任务部署
1、上传jar任务到flink-1.14.6/examples/streaming 目录下
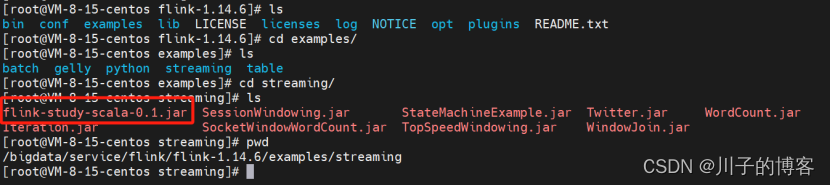
上传完成后,执行命令:
./bin/flink run examples/streaming/flink-study-scala-0.1.jar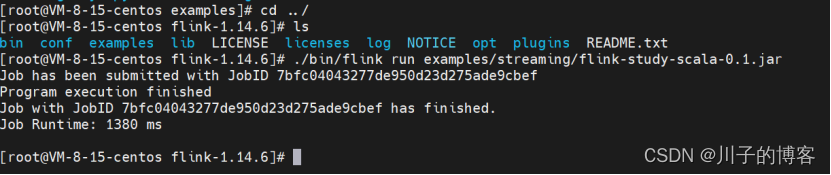
启动成功,访问页面
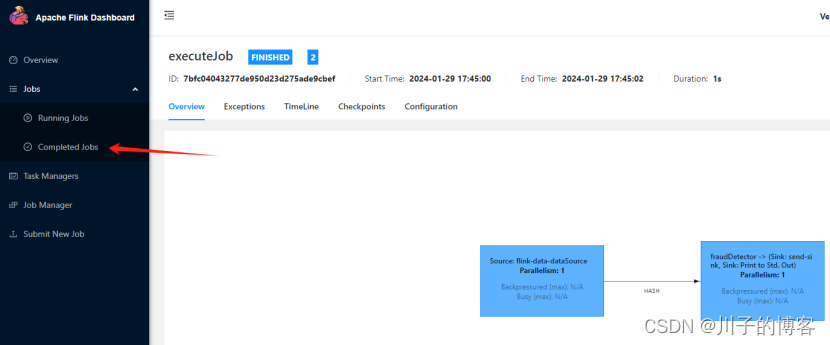
六、停止Flink任务
1、查询JobID:
./bin/flink list2、执行停止命令:
./bin/flink cancel f26d5469cf2015ef371350e77605d17b
到这里,Flink的本地模式安装、项目创建、任务打包和部署算是完成了,后续有资源条件了,再补充生产环境常用的Flink on YARN模式。

