
- 1“好工作”的最关键指标:场景足够复杂、数据量足够大、杠杆率足够高
- 2Windows 实现mysql5.7 和 8.0 自由切换_5.7切8.0数据库脚本怎么改
- 3python结巴分词去掉虚词_结巴分词获取关键词时怎么过滤掉一些停用词?
- 4C++——用二叉链表实现一个二叉树_已知二叉树采用二叉链表结构,编写程序,要求建立一颗二叉树,并输出横向显示的树形
- 5有关组件的知识点(非常详细)_组件技术知识点
- 630个数据工程中最常用的Python库(上)
- 7推荐系统1--协同过滤_采用基于用户的推荐方法预测物品5的得分
- 8ThingsBoard 前端项目背景图片部件开发_thingsboard看板制作
- 9国内Hadoop相关的开源项目
- 10YC1090货车驱动桥的结构设计(有cad图)_半浮式半轴设计计算
【深度学习:人体姿态估计】计算机视觉人体姿态估计完整指南
赞
踩
【深度学习:人体姿态估计】计算机视觉人体姿态估计完整指南
当机器学习模型应用于图像和视频注释时,人体姿态估计 (HPE) 是一个强大的工具。
计算机视觉技术使机器能够执行高度复杂的图像和视频处理以及注释任务,这些任务模仿了人眼和大脑在几分之一秒内处理的内容。
在本文中,我们概述了机器学习模型和视频注释的人体姿态估计的完整指南,以及用例示例。
什么是人体姿态估计?
人体姿态估计 (HPE) 和跟踪是一项计算机视觉任务,随着计算能力和资源的不断增加,它变得越来越容易实施。它需要大量的计算资源和高度准确的算法模型来估计和跟踪人类的姿势和动作。
姿态估计涉及检测、关联和跟踪语义关键点。例如人脸上的关键点,例如嘴角、眼角和鼻子。或肘部和膝盖。借助姿态估计,计算机视觉机器学习 (ML) 模型可让您跟踪、注释和估计人类、动物和车辆的运动模式。
2D 人体姿态估计
2D 人体姿态估计估计 2D 位置,也称为图像和视频中人体关键点的空间位置。传统的 2D 方法使用手绘方法来识别关键点并提取特征。
早期的计算机视觉模型将人体简化为简笔画;想想艺术家用来绘制人体的小型木制模型的计算渲染。然而,一旦现代深度机器学习和基于人工智能的算法开始解决与人类姿态估计相关的挑战,就有了重大突破。我们将在本文中更详细地介绍这些模型和方法。
2D 人体姿态估计示例
2D 姿态估计仍然用于人体运动的视频和图像分析。它是基于 ML 和 AI 的注释分析模型最新进展背后的基础理论。2D 人体姿势估计用于医疗保健、人工智能驱动的瑜伽应用程序、机器人强化学习、动作捕捉、增强现实、运动员姿势检测等等。
2D 与 3D 人体姿态估计
在原始 2D 方法的基础上,3D 人体姿态估计可预测并准确识别三维 (3D) 中关节和其他关键点的位置。这种方法为整个人体提供了广泛的 3D 结构信息。3D 姿态估计有许多应用,例如 3D 动画、增强现实和虚拟现实创建以及动作预测。
可以理解的是,3D 姿势动画更耗时,尤其是当注释者需要花费更多时间在 3D 中手动标记关键点时。解决 3D 姿态估计的许多挑战的更流行的解决方案之一是 OpenPose,它使用神经网络进行实时注释。
人体姿态估计如何工作?
当注释者和机器学习算法、模型和系统使用人类姿势、方向和运动来精确定位和跟踪图像或视频中一个人或多个人的位置时,姿势估计就会起作用。
在大多数情况下,它是一个两步框架。首先,绘制一个边界框,然后使用关键点来识别和估计关节和其他特征的位置和运动。
机器学习中人类姿态估计的挑战
人体姿态估计具有挑战性。我们动态地移动,伴随着服装、面料、照明、任意遮挡、视角和背景的多样性。此外,视频中是否有多个人被分析,并了解一个或多个人或动物之间的运动动态。
姿态估计机器学习算法需要足够强大,以考虑每一种可能的排列。 当然,视频中的天气和其他跟踪对象可能会与人互动,使人类姿势估计更具挑战性。
最常见的用例是将机器学习模型应用于图像和视频中的人体运动注释的行业。体育、医疗保健、零售、安全、情报和军事应用是人体姿态估计视频和图像注释和跟踪最常应用的地方。
在进入用例之前,让我们快速浏览一下部署在人体姿态估计中最流行的机器学习模型。
用于人体姿态估计的流行机器学习模型
多年来,已经为人体姿态估计数据集开发了数十种机器学习 (ML) 算法模型,包括 OmniPose、RSN、DarkPose、OpenPose、AlphaPose (RMPE)、DeepCut、MediaPipe 和 HRNet 等。随着计算能力和 ML/AI 算法准确性的提高,随着数据科学家不断完善和迭代它们,新模型一直在不断发展。
在这些方法被开创之前,人类姿态估计仅限于勾勒出人类在视频或图像中的位置。它需要算法模型、计算能力和基于人工智能的软件解决方案的进步来准确估计和注释人体语言和动作。
好消息是,您通常将哪种算法模型与最强大、用户友好的机器学习或人工智能 (AI) 工具一起使用并不重要。借助 Encord 等基于 AI 的工具,这些模型中的任何一个都可以应用于注释和评估人体姿态估计图像和视频。
#1: OmniPose
OmniPose 是一个单程可训练框架,用于端到端多人姿态估计。它使用敏捷瀑布方法,其架构利用多尺度特征表示,可提高准确性,同时减少对后处理的需求。
包括上下文信息,并使用高斯热图调制进行联合定位。OmniPose 旨在实现最先进的结果,尤其是与 HRNet 结合使用(更多内容见下文)。
#2: RSN
残差步长网络(RSN)是一种创新方法,它“有效地聚合具有相同空间大小的特征(层内特征),以获得精细的局部表示,从而保留丰富的低层空间信息,并实现精确的关键点定位。
此方法使用姿态优化机 (PRM) 来平衡“输出特征中的局部和全局表示”之间的权衡,从而优化关键点特征。RSN 赢得了 2019 年 COCO Keypoint 挑战赛,并根据 COCO 和 MPII 基准记录了最先进的结果。
#3: DARKPose
DARKPose - 关键点的分布感知坐标表示 (DARK) 姿势 - 是一种改进传统热图的新方法。DARKPose 将“预测的热图解码为原始图像空间中的最终联合坐标”,并实现了“更有原则的分布感知解码方法”。生成更准确的热图分布,改善人体姿态估计模型结果。
#4: OpenPose
OpenPose 是一种流行的自下而上的机器学习模型,用于实时多人跟踪、估计和注释。它是一种开源算法,非常适合检测面部、身体、脚部和手部关键点。
OpenPose 是一个 API,可轻松与各种闭路电视摄像机和系统集成,其轻量级版本非常适合边缘设备。
#5: AlphaPose (RMPE)
也称为区域多人姿态估计 (RMPE),是一种用于姿态估计注释的自上而下的机器学习模型。它可以更准确地检测边界框内的人体姿势和运动模式。该架构适用于图像和视频中的单人和多人姿势。
#6: DeepCut
DeepCut 是另一种自下而上的方法,用于检测多人并准确定位图像或视频中的关节和这些关节的估计运动。它是为检测多人的姿势和运动而开发的,通常用于体育领域。
#7: MediaPipe
MediaPipe 是一个开源的“跨平台、可定制的直播和流媒体机器学习解决方案”,由 Google 开发和支持。MediaPipe 是一个强大的机器学习模型,专为面部检测、手部、姿势、实时眼动追踪和整体使用而设计。Google 在 Google AI 和 Google Developers Blog 上提供了大量深入的用例,甚至在 2019 年和 2020 年还举办了几次 MediaPipe Meetup。
#8: High-Resolution Net (HRNet)
高分辨率网络 (HRNet) 是一种用于姿态估计的神经网络,旨在更准确地找到图像或视频中的关键点(人体关节)。与其他算法模型相比,HRNet保持高分辨率表示,用于估计人类姿势和运动。因此,在为电视体育比赛拍摄的视频进行注释时,它是一种有用的机器学习模型。
MediaPipe 与 OpenPose
将一个模型与另一个模型进行比较需要尽可能准确和公平地设置测试条件。波兰AI/ML教育非营利组织 Hear.ai 进行了一项实验,将MediaPipe与OpenPose进行了比较,测试一个是否比另一个更准确检测视频中的手语。你可以在这里阅读它。
两者的准确性都被描述为“良好”,MediaPipe 在处理模糊、视频中的物体(手)变化速度和重叠/覆盖率时被证明更有效。在测试的某些时候,OpenPose 完全失去了检测。事实证明,与 OpenPose 合作具有足够的挑战性——出于多种原因——MediaPipe 显然是赢家。对这两个模型的其他比较得出了类似的结论。
现在让我们仔细看看如何实现机器学习视频标注的人体姿态估计。
如何实现机器学习视频标注的人体姿态估计

视频注释已经足够具有挑战性了,注释者需要处理诸如可变帧速率、重影帧、帧同步问题等困难。为了应对这些挑战,您需要一个视频注释工具,该工具可以处理任意长的视频并预处理视频,以减少帧同步问题。
将这些挑战与与人体姿态估计相关的层(识别关节、动态运动、多人、衣服、背景、照明和天气)相结合,您就会明白为什么强大的算法和计算能力对 HPE 视频注释至关重要。
因此,您需要一个具有以下功能的视频注释工具:
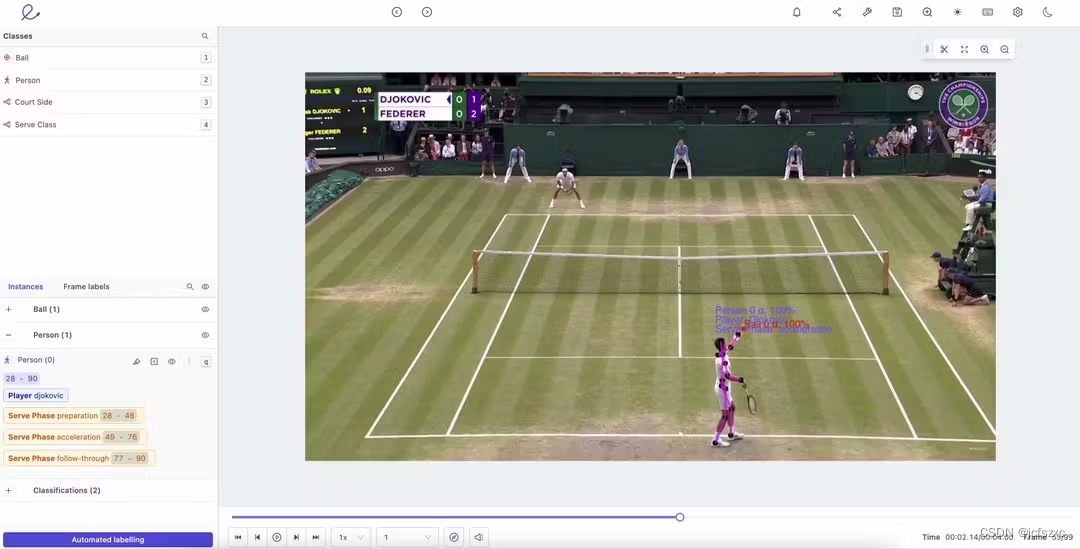
- 轻松定义用于姿态估计视频注释的对象基元。 例如,注释者可以清楚地定义和绘制人体上任何需要的关键点,例如关节或面部特征。
- 使用姿势中的关键点定义骨架模板。 创建骨架模板后,可以编辑这些模板并将其应用于机器学习模型。使用 Encord 的对象跟踪功能进行姿态估计,您可以大大减少任何项目开始时的手动注释工作量。借助功能强大且灵活的编辑套件,您可以减少模型所需的数据量,同时还可以在项目开发过程中手动编辑标签和关键点。
- 对象跟踪和姿态估计。 凭借强大的对象跟踪算法,合适的工具可以支持各种计算机视觉模式。考虑到人体运动和肢体语言,考虑了人体姿势估计的所有固有挑战,例如灯光、衣服、背景、天气,以及在一个视频中跟踪多个人的移动。
如何对姿态估计模型进行基准测试
对视频标注机器学习模型进行基准测试的一种方法是使用 COCO;上下文中的常见对象。
“COCO 是一个大规模的目标检测、分割和字幕数据集”,专为对象分割、上下文识别和超像素对象分割而设计。这是一个开源架构,由Microsoft,Facebook和几家AI公司支持。
研究人员和注释者可以应用此数据集来检测人体运动中的关键点,并在上下文中更准确地区分视频中的对象。除了人体运动跟踪和注释外,COCO在分析赛马视频时也很有用。
进行人体姿态估计时的常见错误
一些最严重的错误涉及在动物身上使用人类姿态估计算法和工具。自然地,动物的移动方式与人类完全不同,除了那些与我们共享最接近DNA的动物,例如大型灵长类动物。
但是,其他更常见的错误涉及使用错误的工具。无论使用哪种机器学习模型,使用错误的工具,都可能浪费数天或数周的注释。一两个帧同步问题,或者需要将较长的视频分解成较短的视频,可能会让注释团队付出高昂的代价。
可变帧、重影帧或计算机视觉工具无法准确标记关键点可能会对项目成果和预算产生负面影响。每个视频注释项目都会发生错误。作为项目负责人,使用最有效的工具和机器学习模型最大限度地减少这些错误是按时和按预算实现项目目标的最佳方式。
部署机器学习视频注释工具时的人体姿态估计用例
人体姿态估计、机器学习模型和工具在各行各业都非常有用。从体育到医疗保健;工作人员、利益相关者或注释者需要评估和分析人类运动模式和肢体语言的影响或预期结果的任何部门。
HPE 机器学习分析在体育分析、打击犯罪、军事、情报和反恐领域同样有用。政府、医疗机构和运动队在实施人体姿态估计注释项目时,经常使用基于人工智能和机器学习的视频注释工具。
这是另一个强大的、改善生活的例子,用于养老院领域的机器学习注释和跟踪。这是 Encord 对 Teton AI 首席技术官的采访,Teton AI 是一家计算机视觉公司,为丹麦各地的医院和护理院设计防坠落工具。Teton AI 使用 Encord 的 SDK 将相同的数据快速应用于不同的项目,利用 Encord 的姿态估计标记工具来训练一个更大的模型,然后将其应用于医院和疗养院。
正如你所看到的,人类姿态估计并非没有挑战。借助正确的计算机视觉、机器学习注释工具和算法模型,您可以在实施下一个视频注释项目时克服这些困难。

